
Bahasa baru dalam Ilmu Data. Julia adalah bahasa yang agak jarang di Rusia, meskipun telah digunakan di luar negeri selama 5 tahun (mereka mengejutkan saya juga). Tidak ada sumber dalam bahasa Rusia, jadi saya memutuskan untuk menjelaskan kasus Julia, diambil dari satu buku yang bagus. Cara terbaik untuk belajar bahasa adalah mulai menulis sesuatu di dalamnya.
Dan agar ini juga menarik perhatian, gunakan pembelajaran mesin.Halo habrozhitelam.
Beberapa waktu yang lalu, saya mulai belajar bahasa baru Julia. Yah, seperti baru. Ini adalah sesuatu antara Matlab dan Python, sintaksinya sangat mirip, dan bahasanya sendiri ditulis dalam C / C ++. Secara umum, sejarah penciptaan, apa, mengapa dan mengapa ada di Wikipedia dan dalam beberapa artikel tentang Habré.
Hal pertama yang memulai studi saya tentang bahasa - benar, Google on Coursera
kursus online google dalam bahasa Inggris. Di sana, tentang sintaksis dasar +, sebuah proyek mini tentang prediksi penyakit di Afrika ditulis secara paralel. Dasar-dasar dan latihan segera. Jika Anda memerlukan sertifikat, beli versi lengkap. Saya pergi secara gratis. Perbedaan antara versi ini adalah tidak ada yang akan memeriksa tes dan DZ Anda. Lebih penting bagi saya untuk berkenalan daripada sertifikat. (Baca macet 50 dolar)
Setelah itu saya memutuskan untuk membaca buku tentang Julia. Google mengeluarkan daftar buku dan mempelajari ulasan serta ulasan lebih lanjut, memilih salah satunya dan memesannya di Amazon. Versi buku selalu lebih bagus untuk dibaca dan digambar dengan pensil.
Buku ini disebut
Julia for Data Science oleh Zacharias Voulgaris, PhD. Kutipan yang ingin saya sajikan berisi banyak kesalahan ketik dalam kode yang saya perbaiki dan karenanya akan menyajikan versi yang berfungsi + hasil saya.
KNN
Ini adalah contoh penerapan algoritma klasifikasi untuk metode tetangga terdekat. Mungkin salah satu algoritma pembelajaran mesin tertua. Algoritma tidak memiliki fase pembelajaran dan cukup cepat. Artinya cukup sederhana: untuk mengklasifikasikan objek baru, Anda perlu menemukan "tetangga" yang serupa dari kumpulan data (database) dan kemudian menentukan kelas dengan memilih.
Saya akan segera memesan bahwa Julia memiliki paket yang sudah jadi, dan lebih baik menggunakannya untuk mengurangi waktu dan mengurangi kesalahan. Tetapi kode ini, dengan cara tertentu, menunjukkan sintaks Julia. Lebih mudah bagi saya untuk belajar bahasa baru dengan contoh daripada membaca ekstrak kering dari bentuk umum suatu fungsi.
Jadi, apa yang kita miliki di pintu masuk:
Data pelatihan X (sampel pelatihan),
label data pelatihan x (label yang sesuai),
data pengujian Y (pemilihan tes),
jumlah tetangga k (jumlah tetangga).
Anda akan membutuhkan 3 fungsi:
fungsi perhitungan jarak, fungsi klasifikasi dan
utama .
Intinya adalah: mengambil satu elemen dari array tes, menghitung jarak dari itu ke elemen-elemen dari array pelatihan. Kemudian kami memilih indeks elemen
k yang ternyata sedekat mungkin. Kami menetapkan elemen yang diuji untuk kelas yang paling umum di antara tetangga terdekat.
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1}) dist = 0 for i in 1:length(x) dist += (x[i] - y[i])^2 end dist = sqrt(dist) return dist end
Fungsi utama dari algoritma. Matriks jarak antara objek pelatihan dan sampel uji, label set pelatihan, dan jumlah "tetangga" terdekat datang ke input. Outputnya adalah label yang diprediksi untuk objek baru dan probabilitas masing-masing label.
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int) class = unique(labels) nc = length(class) #number of classes indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors M = typemax(typeof(distances[1])) #the largest possible number that this vector can have class_count = zeros(Int, nc) for i in 1:k indexes[i] = indmin(distances) #returns index of the minimum element in a collection distances[indexes[i]] = M #make sure this element is not selected again end klabels = labels[indexes] for i in 1:nc for j in 1:k if klabels[j] == class[i] class_count[i] +=1 end end end m, index = findmax(class_count) conf = m/k #confidence of prediction return class[index], conf end
Dan tentu saja, semua fungsinya.
Kami akan memiliki set pelatihan
X pada input, tanda pelatihan set
x , set tes
Y dan jumlah "tetangga"
k .
Pada output kami akan menerima label yang diprediksi dan probabilitas yang sesuai dari setiap penghargaan kelas.
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int) N = size(X,1) n = size(Y,1) D = Array(Float64,N) #initialize distance matrix z = Array(eltype(x),n) #initialize labels vector c = Array(Float64, n) #confidence of prediction for i in 1:n for j in 1:N D[j] = CalculateDistance(X[j,:], vec(Y[i,:])) end z[i], c[i] = Classify(D,x,k) end return z, c end
Pengujian
Mari kita uji apa yang kita dapatkan. Untuk kenyamanan, kami menyimpan algoritme dalam file kNN.jl.
Pangkalan tersebut dipinjam dari
Kursus Pembelajaran Mesin Terbuka . Dataset ini disebut Pengenalan Aktivitas Manusia Samsung. Data berasal dari accelerometer dan giroskop ponsel Samsung Galaxy S3, jenis aktivitas seseorang dengan ponsel di sakunya juga diketahui - apakah ia berjalan, berdiri, berbaring, duduk atau berjalan naik / turun tangga. Kami akan memecahkan masalah menentukan jenis aktivitas fisik secara tepat sebagai masalah klasifikasi.
Tag akan sesuai dengan yang berikut:
1 - berjalan
2 - memanjat tangga
3 - menuruni tangga
4 - kursi
5 - seseorang berdiri saat ini
6 - orang itu berbohong
include("kNN.jl") training = readdlm("samsung_train.txt"); training_label = readdlm("samsung_train_labels.txt"); testing = readdlm("samsung_test.txt"); testing_label = readdlm("samsung_test_labels.txt"); training_label = map(Int, training_label) testing_label = map(Int, testing_label) z = main(training, vec(training_label), testing, 7) n = length(testing_label) println(sum(testing_label .== z[1]) / n)
Hasil: 0.9053274516457415Kualitas dinilai dengan rasio objek yang diprediksi dengan benar terhadap seluruh sampel uji. Sepertinya tidak terlalu buruk. Tetapi tujuan saya lebih untuk menunjukkan Julia, dan bahwa ia memiliki tempat untuk berada di Ilmu Data.
Visualisasi
Selanjutnya, saya ingin mencoba memvisualisasikan hasil klasifikasi. Untuk melakukan ini, Anda perlu membuat gambar dua dimensi, memiliki 561 tanda dan tidak tahu mana yang paling signifikan. Oleh karena itu, untuk mengurangi dimensi dan desain data selanjutnya pada subruang ortogonal fitur, diputuskan untuk menggunakan
Principal Component Analysis (PCA). Di Julia, seperti halnya di Python, ada paket yang sudah jadi, jadi kami sedikit menyederhanakan hidup kami.
using MultivariateStats #for PCA A = testing[1:10,:] #PCA for A M_A = fit(PCA, A'; maxoutdim = 2) Jtr_A = transform(M_A, A'); #PCA for training M = fit(PCA, training'; maxoutdim = 2) Jtr = transform(M, training'); using Gadfly #shows training points and uncertain point pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point)) #predicted values for uncertain points from testing data z1 = main(training, vec(training_label), A, 7) pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point)) vstack(pl1, pl2)
Pada gambar pertama, set pelatihan dan beberapa objek dari set tes ditandai, yang perlu ditugaskan ke kelas mereka. Dengan demikian, gambar kedua menunjukkan bahwa benda-benda ini ditandai.

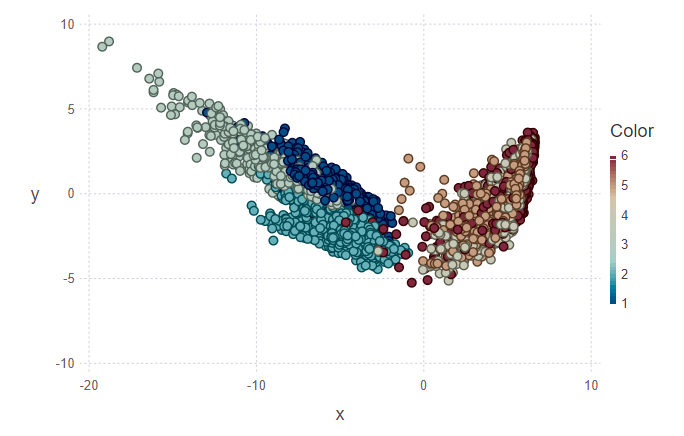
println(z[1][1:10], z[2][1:10]) > [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
Melihat gambar-gambar, saya ingin mengajukan pertanyaan "mengapa cluster seperti itu jelek?". Saya akan jelaskan. Cluster individu tidak digambarkan dengan sangat jelas karena sifat data dan penggunaan PCA. Untuk PCA, hanya berjalan dan menaiki tangga seperti satu kelas - kelas gerak. Dengan demikian, kelas kedua adalah kelas istirahat (duduk, berdiri, berbaring, yang tidak terlalu berbeda di antara mereka sendiri). Dan karena itu, pemisahan yang jelas dapat ditelusuri ke dalam dua kelas, bukan enam.
Kesimpulan
Bagi saya, ini hanyalah perendaman awal dalam Julia dan penggunaan bahasa ini dalam pembelajaran mesin. Omong-omong, di mana saya juga lebih cenderung menjadi amatir daripada seorang profesional. Tetapi sementara saya tertarik, saya akan terus mempelajari masalah ini lebih dalam. Banyak sumber asing bertaruh pada Julia. Baiklah, tunggu dan lihat.
PS: Jika itu menarik, saya dapat memberi tahu Anda di posting berikut tentang fitur sintaks, tentang IDE, dengan instalasi yang saya punya masalah.