Cukup sering kita ditanya mengapa kita tidak mengatur kompetisi untuk ilmuwan data. Faktanya adalah bahwa dari pengalaman kita tahu bahwa solusi di dalamnya sama sekali tidak berlaku untuk prod. Ya, dan untuk merekrut orang-orang yang akan berada di tempat terkemuka, itu tidak selalu masuk akal.
Persaingan seperti itu sering dimenangkan dengan bantuan yang disebut penumpukan Cina, ketika semua algoritma yang mungkin dan nilai-nilai hiperparameter diambil dengan cara kombinatorial, dan model yang dihasilkan menggunakan sinyal dari satu sama lain di beberapa tingkatan. Satelit biasa dari solusi ini adalah kompleksitas, ketidakstabilan, kesulitan dalam debugging dan dukungan, konsumsi sumber daya yang sangat tinggi dalam pelatihan dan peramalan, perlunya pengawasan manusia yang cermat dalam setiap siklus pelatihan model yang berulang. Masuk akal untuk melakukan ini hanya di kompetisi - demi kesepuluh ribu di metrik lokal dan posisi di klasemen.
Tetapi kami mencoba
Sekitar setahun yang lalu, kami memutuskan untuk mencoba menggunakan penumpukan dalam produksi. Diketahui bahwa model-model linier memungkinkan untuk mengekstraksi sinyal yang berguna dari teks-teks yang direpresentasikan sebagai sekumpulan kata-kata dan di-vektor-kan menggunakan tf-idf, terlepas dari dimensi besar vektor-vektor tersebut. Sistem kami telah melakukan vektorisasi seperti itu, oleh karena itu tidak terlalu sulit bagi kami untuk menggabungkan vektor untuk resume, lowongan dan, berdasarkan pada mereka, untuk mengajarkan regresi logistik sehingga ia memprediksi probabilitas seorang kandidat mengklik dengan resume yang diberikan untuk lowongan yang diberikan.
Kemudian ramalan ini digunakan oleh model utama sebagai fitur tambahan, karena model tersebut mempertimbangkan atribut-meta. Keindahannya adalah bahwa bahkan dengan ROC AUC 0.7, sinyal dari model meta-atribut seperti itu berguna. Implementasinya memberikan sekitar 2 ribu tanggapan per hari. Dan yang paling penting - kami menyadari bahwa kami dapat melanjutkan.
Model linier tidak memperhitungkan interaksi nonlinear antar fitur. Misalnya, tidak dapat memperhitungkan bahwa jika ada "C" di resume dan "programmer sistem" dalam lowongan, maka probabilitas respons menjadi sangat tinggi. Selain lowongan dan resume, selain teks, ada banyak bidang numerik dan kategoris, dan dalam resume teks dibagi menjadi banyak blok terpisah. Oleh karena itu, kami memutuskan untuk menambahkan ekstensi kuadrat fitur untuk model linier dan memilah-milah semua kombinasi vektor tf-idf dari bidang dan blok.
Kami mencoba tanda-tanda meta yang memprediksi kemungkinan respons dalam berbagai kondisi:
- dalam uraian tugas ada seperangkat istilah, kategori;
- Di bidang teks lowongan dan bidang teks resume, seperangkat istilah tertentu dijumpai;
- di bidang teks lowongan ada sejumlah istilah yang tidak memenuhi bidang teks resume;
- istilah-istilah tertentu muncul dalam lowongan, nilai kategori yang ditetapkan bertemu di resume;
- di lowongan dan resume, sepasang nilai kategori bertemu.
Kemudian, dengan bantuan pemilihan fitur, mereka memilih beberapa lusinan atribut meta yang memberikan efek maksimum, melakukan uji A / B dan melepaskannya ke dalam produksi.
Hasilnya, kami menerima lebih dari 23 ribu respons baru per hari. Beberapa atribut memasuki atribut teratas dalam kekuatan.
Misalnya, dalam sistem pemberi rekomendasi, atribut teratas adalah
dalam model regresi logistik yang memfilter resume yang sesuai:- wilayah geografis dari resume;
- bidang profesional dari resume;
- perbedaan antara deskripsi pekerjaan dan pengalaman kerja baru-baru ini;
- perbedaan wilayah geografis dalam lowongan dan resume;
- perbedaan antara judul lowongan dan judul resume;
- perbedaan antara spesialisasi dalam lowongan dan dalam resume;
- kemungkinan bahwa pelamar dengan gaji tertentu dalam resume mengklik lowongan dengan gaji tertentu (meta-tanda pada regresi logistik);
- kemungkinan seseorang dengan nama resume tertentu akan mengklik lowongan dengan pengalaman kerja tertentu (meta-sign pada regresi logistik);
dalam model XGBoost memfilter resume yang relevan:- Seberapa mirip lowongan dan resume dalam teks;
- perbedaan antara nama lowongan dan nama resume dan semua posisi dalam pengalaman dalam resume, dengan mempertimbangkan interaksi teks akun;
- perbedaan antara judul lowongan dan judul dalam resume, dengan mempertimbangkan interaksi teks akun;
- perbedaan antara nama lowongan dan nama resume dan semua posisi dalam pengalaman resume, tanpa memperhitungkan interaksi teks akun;
- kemungkinan bahwa seorang kandidat dengan pengalaman kerja yang ditentukan akan pergi ke lowongan dengan nama itu (meta-tanda pada regresi logistik);
- perbedaan antara deskripsi pekerjaan dan pengalaman kerja sebelumnya dalam resume;
- seberapa banyak lowongan dan resume berbeda dalam teks;
- perbedaan antara deskripsi pekerjaan dan pengalaman kerja sebelumnya dalam resume;
- kemungkinan bahwa seseorang dari jenis kelamin tertentu akan menanggapi lowongan dengan nama tertentu (tanda meta pada regresi logistik).
dalam model peringkat di XGBoost:- probabilitas respons sesuai dengan istilah yang ada dalam nama lowongan dan tidak dalam judul dan posisi dari resume (meta-tanda pada regresi logistik);
- mencocokkan wilayah dari lowongan dan melanjutkan
- kemungkinan respons dengan persyaratan yang ada dalam lowongan dan tidak ada dalam resume (meta-sign pada regresi logistik);
- prediksi daya tarik lowongan untuk pengguna (meta-tag pada ALS);
- kemungkinan respons dengan persyaratan yang ada dalam lowongan dan resume (meta-sign pada regresi logistik);
- jarak antara nama lowongan dan posisi judul + dari resume, di mana istilah dibobot oleh tindakan pengguna (interaksi);
- jarak antara spesialisasi dari lowongan dan resume;
- jarak antara judul lowongan dan nama resume, di mana istilah dibobot oleh tindakan pengguna (interaksi);
- probabilitas respons pada interaksi tf-idf dari kekosongan dan spesialisasi dari resume (meta-tanda pada regresi logistik);
- jarak antara lowongan dan resume teks;
- DSSM dengan nama lowongan dan nama resume (meta-atribut pada jaringan saraf).
Hasil yang baik menunjukkan bahwa dari arah ini Anda masih dapat mengekstrak sejumlah tanggapan dan undangan per hari dengan biaya pemasaran yang sama.
Sebagai contoh, diketahui bahwa dengan sejumlah besar tanda, regresi logistik meningkatkan kemungkinan pelatihan ulang.
Mari kita gunakan untuk teks resume dan lowongan vectorizer tf-idf dengan kamus 10 ribu kata dan frasa. Kemudian dalam kasus ekspansi kuadratik dalam regresi logistik kami akan ada 2 * 10.000 + 10.000 bobot. Jelaslah bahwa dengan kesederhanaan seperti itu, bahkan kasus individual dapat secara signifikan mempengaruhi masing-masing berat individu "di resume ada kata langka ini-dan-itu - dalam lowongan ini-dan-itu, pengguna mengklik."
Oleh karena itu, sekarang kami mencoba membuat meta-tanda pada regresi logistik, di mana koefisien ekspansi kuadrat dikompresi menggunakan mesin faktorisasi. Bobot 10.000 m² kami direpresentasikan sebagai matriks vektor laten dengan dimensi, misalnya, 10.000x150 (di mana kami telah memilih dimensi vektor laten 150). Pada saat yang sama, kasus-kasus individual selama kompresi berhenti memainkan peran besar, dan model mulai lebih mempertimbangkan pola-pola yang lebih umum, daripada mengingat kasus-kasus tertentu.
Kami juga menggunakan meta-atribut pada jaringan saraf DSSM yang telah kami
tulis , dan pada ALS, yang juga kami
tulis , tetapi dengan cara yang disederhanakan. Secara total, pengenalan meta-atribut hingga saat ini telah memberi kami (dan pelanggan kami) lebih dari 44 ribu respons tambahan (arahan) terhadap lowongan per hari.
Akibatnya, skema susun model yang disederhanakan dalam rekomendasi pekerjaan untuk resume sekarang terlihat seperti ini:
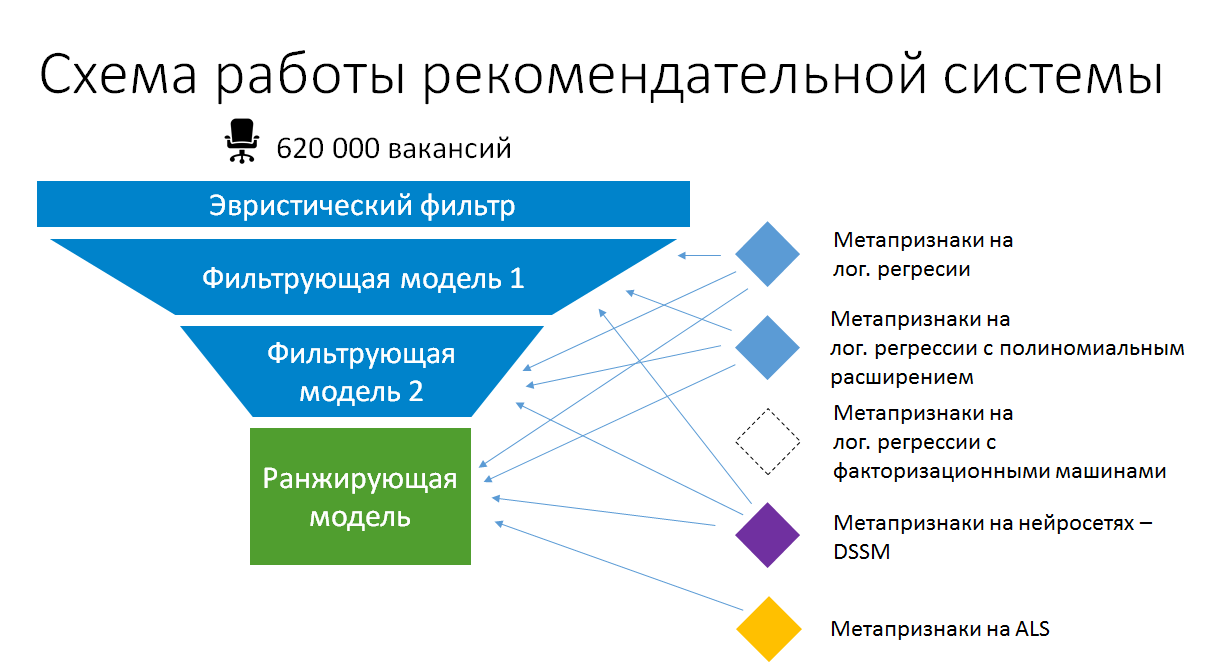
Jadi, menumpuk dalam produksi masuk akal. Tapi ini bukan susunan kombinatorial otomatis. Kami memastikan bahwa model berdasarkan atribut meta yang dibuat tetap sederhana dan memanfaatkan maksimum data yang ada dan menghitung atribut statis. Hanya dengan cara ini mereka dapat tetap berproduksi tanpa secara bertahap berubah menjadi kotak hitam yang tidak didukung, dan tetap dalam keadaan di mana mereka dapat dilatih ulang dan ditingkatkan.