
Berdasarkan hasil berbagai evaluasi operasional pusat data di seluruh dunia, Uptime Institute mencatat bahwa tingkat kepegawaian di pusat data sangat bervariasi dari satu tempat ke tempat lain. Pengamatan ini agak membingungkan, tetapi tidak mengejutkan. Sementara kepegawaian adalah kegiatan penting bagi pusat data yang berusaha mempertahankan keunggulan operasional, banyak faktor lain memengaruhi keputusan organisasi tentang tingkat kepegawaian yang diperlukan.
Di antara faktor-faktor yang dapat memengaruhi tingkat kepegawaian secara keseluruhan, seseorang dapat memilih kompleksitas pusat data, pergantian staf, jumlah jam kerja dukungan teknis yang diperlukan, jumlah kontrak dengan kontraktor dan tujuan bisnis aksesibilitas. Biaya juga meresahkan, karena setiap karyawan adalah biaya langsung ke pusat data. Karena banyak faktor ini, penting untuk secara konstan meninjau tingkat pusat data staf untuk memberikan dukungan yang efektif dengan harga yang wajar.
The Uptime Institute sering mendapat pertanyaan: "Apa tingkat kepegawaian yang sesuai untuk pusat data saya?" Sayangnya, tidak ada jawaban ringkas yang universal untuk setiap pusat data. Penempatan staf yang tepat tergantung pada sejumlah variabel.
Waktu yang diperlukan untuk menyelesaikan tugas perawatan dan memastikan bahwa pergeseran dukungan teknis selesai adalah dua variabel utama. Staf untuk memenuhi persyaratan pemeliharaan adalah faktor yang relatif tetap, tetapi tergantung pada tindakan apa yang dilakukan oleh personel pusat data dan fungsi apa yang ditugaskan kepada kontraktor. Mengelola pergeseran dukungan teknis didefinisikan sebagai penempatan staf untuk memantau pusat data dan untuk menanggapi setiap insiden dan peristiwa. Penempatan staf untuk dukungan teknis dapat ditentukan dengan berbagai cara. Setiap metode penempatan staf memiliki dampak potensial pada operasi, tergantung pada proses mana yang dicakup oleh dukungan teknis.
Tren Shift
Tujuan utama dari keberadaan permanen personel yang berkualifikasi di tempat adalah untuk meminimalkan risiko kegagalan yang disebabkan oleh peristiwa abnormal dengan mencegah insiden, menghalangi atau mengisolasinya, serta mencegah penyebaran atau dampaknya pada sistem lain. Banyak pusat data terus menghadirkan kehadiran tim listrik, teknisi mesin, dan teknisi lainnya yang memenuhi syarat yang menyediakan mode pengoperasian 24x7. Namun, teknologi pemantauan jarak jauh, pengaturan khusus bangunan dalam bentuk kompleks, keinginan untuk menyeimbangkan biaya dan alasan lain dapat mendorong organisasi untuk merekrut staf dengan cara yang berbeda.
Mengelola rejim dukungan teknis tanpa personel yang berkualifikasi di tempat kapan saja dapat meningkatkan risiko karena respons yang tertunda terhadap insiden abnormal. Pada akhirnya, perusahaan harus mengambil keputusan dengan tingkat risiko yang dapat diterima.
Model dukungan teknis cakupan penuh lainnya termasuk:
- Melatih personel keamanan untuk merespons alarm dan melakukan prosedur untuk menyelesaikan masalah;
- Memantau pusat data melalui sistem pemantauan bangunan (BMS) lokal atau regional dan melibatkan teknisi panggilan;
- Ketersediaan staf di lokasi selama jam kerja normal dan panggilan di malam hari dan di akhir pekan;
- Pekerjaan beberapa pusat data dalam bentuk kompleks bangunan khusus, yang timnya memberikan dukungan untuk beberapa pusat data tanpa harus ada di setiap pusat data terpisah setiap saat.
Ini dan metode lain harus dievaluasi dalam hal efektivitas secara individual. Untuk mengevaluasi model dukungan teknis, pusat data harus menentukan potensi risiko insiden di pusat data dan potensi dampaknya terhadap bisnis.
Selama 20 tahun terakhir, Uptime Institute telah menyusun database insiden abnormal (Abnormal Incident Report, AIRs), menggunakan informasi yang diterima dari anggota Uptime Institute Network. Uptime Institute setiap tahun menganalisis data dan menyajikan hasilnya kepada anggota Jaringan. Basis data AIRs berisi informasi menarik tentang masalah personel dan model kepegawaian yang efektif untuk pusat data.
Insiden terjadi di luar jam kerja
Pada 2013, sebagian kecil insiden (dari 277 kasus) terjadi selama jam kerja. Namun, 44% insiden terjadi antara tengah malam dan jam 8:00 pagi, yang menggarisbawahi kebutuhan potensial untuk mode dukungan teknis 24x7 (lihat Gambar 1).
Gambar 1. Sekitar setengah dari insiden abnormal yang terjadi pada tahun 2013 terjadi antara jam 8 pagi dan siang hari, setengah lainnya dari tengah malam hingga jam 8 pagi.
Insiden dapat terjadi kapan saja sepanjang tahun. Memfokuskan aktivitas staf selama jangka waktu tertentu dalam prioritas di atas yang lain tidak akan produktif (misalnya, larangan liburan). Insiden didistribusikan secara merata sepanjang tahun.
Gambar 2 menunjukkan distribusi insiden pada hari dalam seminggu. Diagram menunjukkan bahwa setiap hari dalam seminggu memiliki bagian yang hampir sama, yang menunjukkan bahwa kepegawaian harus sama untuk perubahan setiap hari dalam seminggu. Ini adalah kesimpulan penting, karena beberapa pusat data telah memusatkan sumber daya tenaga kerja dari dukungan teknis mereka untuk periode dari Senin hingga Jumat dan membiarkan hari libur untuk pemantauan jarak jauh (lihat Gambar 2).
Gambar 2. Personil pusat data harus siap setiap hari dalam seminggu.Insiden menurut industri
Gambar 3 lebih lanjut menggambarkan insiden industri dan tidak menunjukkan perbedaan yang signifikan dalam tren antara industri. Bagan menunjukkan bahwa industri jasa keuangan melaporkan insiden yang jauh lebih banyak daripada industri lain, tetapi ini lebih cenderung mencerminkan komposisi sampel.
 Gambar 3. Insiden di pusat data terjadi sepanjang tahun.
Gambar 3. Insiden di pusat data terjadi sepanjang tahun.Penyebab Kegagalan dan Metode Deteksi
Mengetahui kapan insiden terjadi, sedikit yang bisa dikatakan tentang personil apa yang harus ditempatkan. Memahami insiden yang paling sering terjadi akan membantu membentuk struktur shift, serta mencari tahu bagaimana insiden yang paling sering terdeteksi. Gambar 4 menunjukkan bahwa sebagian besar insiden mempengaruhi sistem kelistrikan, diikuti oleh sistem mekanis. Sebaliknya, beban kerja TI yang kritis menyebabkan jumlah insiden yang relatif kecil.
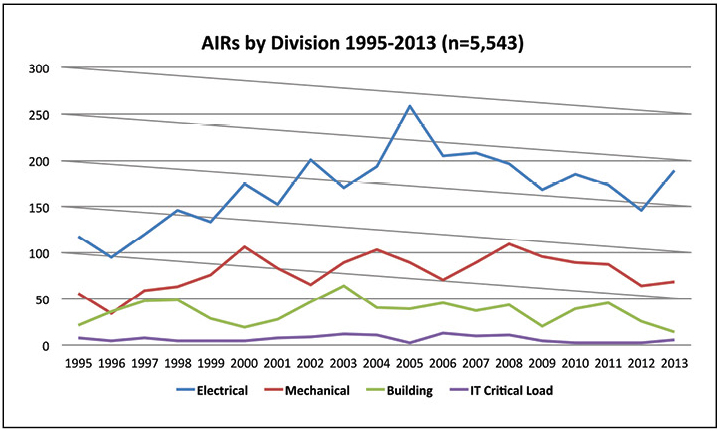 Gambar 4. Lebih dari setengah insiden abnormal yang dilaporkan pada tahun 2013 terkait dengan sistem kelistrikan.
Gambar 4. Lebih dari setengah insiden abnormal yang dilaporkan pada tahun 2013 terkait dengan sistem kelistrikan.Sebagai hasilnya, masuk akal bagi tim dari semua shift untuk memiliki pengalaman yang cukup untuk menanggapi insiden paling umum dalam sistem kelistrikan. Tim pendukung juga harus menanggapi jenis insiden lainnya. Pelatihan lintas insinyur listrik pada sistem mekanik dan bangunan dapat memberikan cakupan yang memadai, dan petugas panggilan dapat mencakup insiden TI yang relatif jarang terjadi.
Basis data AIRs juga menjelaskan bagaimana insiden terdeteksi. Gambar 5 menunjukkan bahwa lebih dari setengah informasi utama tentang semua insiden yang terdeteksi pada tahun 2013 diperoleh dari sistem alarm, lebih dari 40% insiden terdeteksi oleh spesialis teknis di tempat, yang totalnya adalah sekitar 95% dari kasus. Perubahan terbesar selama bertahun-tahun yang ditunjukkan dalam diagram adalah pertumbuhan lambat dari insiden yang terdeteksi oleh alarm.
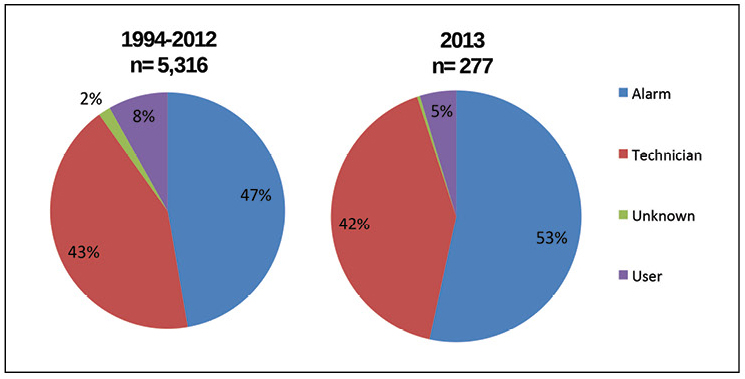 Gambar 5. Alarm sekarang merupakan cara untuk mendeteksi sebagian besar insiden; Namun, masalah aksesibilitas lebih sering ditemukan oleh para ahli teknis.
Gambar 5. Alarm sekarang merupakan cara untuk mendeteksi sebagian besar insiden; Namun, masalah aksesibilitas lebih sering ditemukan oleh para ahli teknis.Namun, alarm tidak dapat merespons insiden atau mengurangi konsekuensi. Uptime Institute telah menyaksikan sejumlah metode yang memungkinkan pusat data untuk menghindari kerusakan dan mengurangi dampaknya. Metode-metode ini membutuhkan personel untuk merespons insiden tersebut, menciptakan redundansi dalam sistem kritis, dan program pemeliharaan prediktif yang efektif untuk memprediksi potensi kegagalan sebelum terjadi. Gambar 6 menunjukkan seberapa sering masing-masing metode ini "menyelamatkan" pusat data.
 Gambar 6. Redundansi peralatan pada tahun 2013 berkontribusi pada lebih banyak “penyelamatan” dibandingkan tahun-tahun sebelumnya.
Gambar 6. Redundansi peralatan pada tahun 2013 berkontribusi pada lebih banyak “penyelamatan” dibandingkan tahun-tahun sebelumnya.Diagram juga menunjukkan bahwa dalam beberapa tahun terakhir redundansi peralatan dan pemeliharaan preventif menjadi lebih efisien dan menghemat lebih banyak uang pusat data. Ada beberapa penjelasan yang mungkin untuk ini, termasuk meningkatkan keandalan sistem, penggunaan layanan proaktif yang lebih luas dan pemotongan anggaran, yang mengarah pada pengurangan jumlah personel atau relokasi mereka di luar pusat data.
Kegagalan dalam konteks akar permasalahan
Data menunjukkan bahwa semua masalah aksesibilitas pada tahun 2013 disebabkan oleh insiden dengan sistem kelistrikan. Sebagian besar kegagalan terjadi karena prosedur perawatan tidak dilakukan dengan benar. Temuan ini menggarisbawahi pentingnya memiliki prosedur yang memadai dan staf yang terlatih.
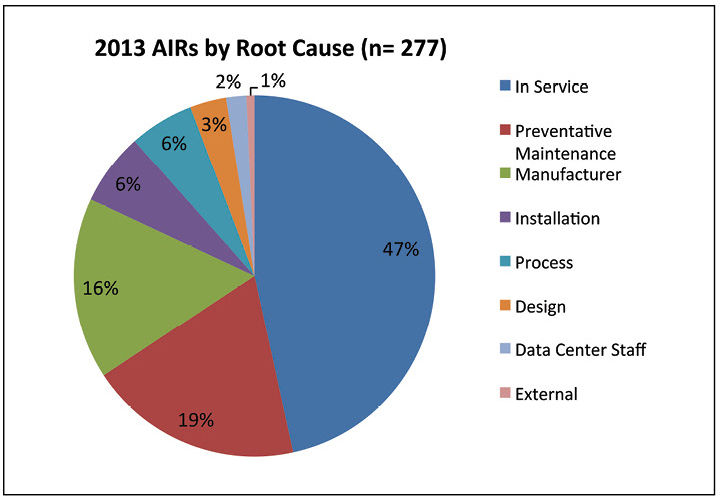 Gambar 7. Hampir setengah dari kegagalan yang dilaporkan pada tahun 2013 disebabkan oleh masalah pemeliharaan.
Gambar 7. Hampir setengah dari kegagalan yang dilaporkan pada tahun 2013 disebabkan oleh masalah pemeliharaan.Dalam gbr. 7 lebih lanjut membahas penyebab insiden pada tahun 2013. Sekitar setengah dari insiden digambarkan sebagai "Dalam Layanan," yang didefinisikan sebagai perawatan yang tidak memadai, pengaturan peralatan yang tidak tepat, kegagalan untuk bekerja, atau kurangnya akar penyebab spesifik. Kasus “pemeliharaan preventif” sebenarnya merujuk pada pemeliharaan preventif yang telah dilakukan dengan tidak tepat. Personil pusat data hanya menyebabkan 2% dari insiden, menunjukkan bahwa interaksi personel dan peralatan bukanlah penyebab utama insiden dan kegagalan.
Kesimpulan
Meningkatnya kompleksitas pengelolaan infrastruktur pusat data (DCIM), sistem manajemen gedung (BMS), dan sistem otomasi gedung (BAS) membuat sulit untuk menemukan jawaban atas pertanyaan apakah mungkin untuk mengurangi jumlah personil di pusat data. Kemajuan dalam meningkatkan sistem ini sangat penting. Mereka dapat meningkatkan kinerja pusat data Anda; namun, data menunjukkan bahwa pencegahan insiden sering kali membutuhkan personel di lokasi. Itu sebabnya terus memiliki staf yang setara penuh waktu (FTE) adalah arahan untuk pusat data bersertifikat Tier III dan Tier IV.
Tujuan utamanya adalah untuk menyediakan waktu respons yang cepat untuk mengurangi konsekuensi dari setiap insiden dan peristiwa. Data menunjukkan bahwa ketika insiden terjadi, tidak ada pola sementara yang diamati. Penampilan mereka didistribusikan dengan cukup baik di semua 24 jam dan semua 7 hari dalam seminggu.
Tujuan utamanya adalah pencegahan risiko. Pusat data terus berkembang, memungkinkan manajemen melalui akses jarak jauh dan meningkatkan redundansi perangkat keras. Setiap pusat data unik dan memiliki risiko sendiri yang melekat. Mode dukungan teknis hanyalah salah satu faktor, tetapi cukup penting. Keputusan tentang seberapa banyak staf yang akan terlibat dalam setiap shift dan dengan kualifikasi apa yang dapat memiliki dampak besar pada pencegahan risiko dan ketersediaan pusat data. Buat pilihan cerdas.
Artikel blog Cloud4Y lainnya:→
Berapa biaya sebenarnya dari downtime infrastruktur TI untuk perusahaan kecil dan menengah? (tautan eksternal)→
Masa kejayaan komputasi awan dalam otomatisasi perusahaan industri (tautan eksternal)→
Apa yang terjadi dengan harga komputasi awan dalam beberapa tahun terakhir (Habr)→
Bagaimana cara membuat sampel untuk sistem biometrik terpadu dan mengapa itu bisa berbahaya (Habr)