Artikel ini membahas berbagai jenis pengujian dalam produksi dan kondisi di mana masing-masing paling berguna, dan juga menjelaskan cara mengatur pengujian aman berbagai layanan dalam produksi.
Perlu dicatat bahwa konten artikel ini hanya berlaku untuk
layanan tersebut , yang penyebarannya dikendalikan oleh pengembang. Selain itu, Anda harus segera memperingatkan bahwa penggunaan salah satu dari jenis pengujian yang dijelaskan di sini bukanlah tugas yang mudah, yang seringkali membutuhkan perubahan serius pada desain, pengembangan, dan pengujian sistem. Dan, terlepas dari judul artikel, saya tidak berpikir bahwa salah satu dari jenis pengujian dalam produksi benar-benar dapat diandalkan. Hanya ada pendapat bahwa pengujian semacam itu dapat secara signifikan mengurangi tingkat risiko di masa depan, dan biaya investasi akan dibenarkan.
(Catatan: karena artikel aslinya adalah Longrid, untuk kenyamanan pembaca, artikel ini dibagi menjadi dua bagian).Mengapa pengujian dalam produksi diperlukan jika dapat dilakukan dalam pementasan?
Signifikansi cluster pementasan (atau lingkungan pementasan) oleh orang yang berbeda dirasakan secara berbeda. Bagi banyak perusahaan, penyebaran dan pengujian suatu produk dalam pementasan adalah tahap integral sebelum rilis finalnya.
Banyak organisasi terkenal menganggap pementasan sebagai salinan miniatur dari lingkungan kerja. Dalam kasus seperti itu, ada kebutuhan untuk memastikan sinkronisasi maksimumnya. Dalam hal ini, biasanya diperlukan untuk memastikan pengoperasian berbagai sistem stateful yang berbeda, seperti database, dan secara berkala menyinkronkan data dari lingkungan produksi dengan pementasan. Pengecualian hanya informasi rahasia yang memungkinkan Anda untuk menetapkan identitas pengguna (ini diperlukan untuk mematuhi persyaratan
GDPR ,
PCI ,
HIPAA dan peraturan lainnya).
Masalah dengan pendekatan ini (dalam pengalaman saya) adalah bahwa perbedaannya tidak hanya dalam penggunaan contoh terpisah dari database yang berisi data lingkungan produksi aktual. Seringkali perbedaan meluas ke aspek-aspek berikut:
- Ukuran cluster pementasan (jika Anda dapat menyebutnya "cluster" - terkadang hanya satu server yang menyamar sebagai cluster);
- Fakta bahwa pementasan biasanya menggunakan kluster yang jauh lebih kecil juga berarti bahwa pengaturan konfigurasi untuk hampir setiap layanan akan bervariasi. Ini berlaku untuk konfigurasi load balancers, database, dan antrian, misalnya, jumlah deskriptor file terbuka, jumlah koneksi database terbuka, ukuran kumpulan thread, dll. Jika konfigurasi disimpan dalam database atau penyimpanan data bernilai kunci (misalnya, Zookeeper atau Konsul), sistem tambahan ini juga harus ada dalam lingkungan pementasan;
- Jumlah koneksi online yang diproses oleh layanan stateless, atau metode penggunaan kembali koneksi TCP oleh server proxy (jika prosedur ini dilakukan sama sekali);
- Kurangnya pemantauan dalam pementasan. Tetapi bahkan jika pemantauan dilakukan, beberapa sinyal mungkin berubah menjadi benar-benar tidak akurat, karena lingkungan selain yang berfungsi dimonitor. Misalnya, bahkan jika Anda memantau latensi kueri MySQL atau waktu respons, sulit untuk menentukan apakah kode baru berisi kueri yang dapat memulai pemindaian tabel penuh di MySQL, karena jauh lebih cepat (dan kadang-kadang bahkan lebih disukai) untuk melakukan pemindaian penuh dari tabel kecil yang digunakan dalam pengujian. database daripada database produksi, di mana kueri dapat memiliki profil kinerja yang sama sekali berbeda.
Meskipun adil untuk mengasumsikan bahwa semua perbedaan di atas bukanlah argumen serius terhadap penggunaan pementasan seperti itu, tidak seperti antipattern yang harus dihindari. Pada saat yang sama, keinginan untuk melakukan segala sesuatunya dengan benar seringkali membutuhkan biaya tenaga kerja insinyur yang sangat besar dalam upaya untuk memastikan lingkungan yang konsisten. Produksi terus berubah dan dipengaruhi oleh berbagai faktor, jadi berusaha mencapai kecocokan ini seperti pergi ke mana-mana.
Selain itu, bahkan jika kondisi pada pementasan akan sama mungkin dengan lingkungan kerja, ada jenis pengujian lain yang lebih baik untuk digunakan berdasarkan informasi produksi nyata. Contoh yang baik adalah pengujian rendam, di mana keandalan dan stabilitas layanan diuji selama periode waktu yang lama pada tingkat multitasking dan beban nyata. Ini digunakan untuk mendeteksi kebocoran memori, menentukan durasi jeda dalam GC, level beban prosesor dan indikator lainnya untuk periode waktu tertentu.
Tak satu pun dari yang di atas menunjukkan bahwa pementasan sama
sekali tidak berguna (ini akan menjadi jelas setelah membaca bagian tentang duplikasi bayangan data saat menguji layanan). Ini hanya menunjukkan bahwa mereka cukup sering mengandalkan pementasan ke tingkat yang lebih besar dari yang diperlukan, dan di banyak organisasi itu tetap
satu -
satunya jenis pengujian yang dilakukan sebelum rilis penuh produk.
Seni pengujian dalam produksi
Itu terjadi secara historis bahwa konsep "pengujian dalam produksi" dikaitkan dengan stereotip tertentu dan konotasi negatif ("pemrograman gerilya", kurangnya atau tidak adanya pengujian unit dan integrasi, kelalaian atau ketidakpedulian terhadap persepsi produk oleh pengguna akhir).
Pengujian dalam produksi tentu akan pantas mendapatkan reputasi seperti itu jika dilakukan dengan sembarangan dan buruk. Itu
tidak dengan cara apa pun
menggantikan pengujian pada tahap pra-produksi dan dalam keadaan apa pun itu bukan
tugas yang mudah . Selain itu, saya berpendapat bahwa pengujian yang
berhasil dan
aman dalam produksi memerlukan tingkat otomatisasi yang signifikan, pemahaman yang baik tentang praktik yang telah mapan, dan desain sistem dengan orientasi awal untuk jenis pengujian ini.
Untuk mengatur proses komprehensif dan aman dari pengujian layanan yang efektif dalam produksi, penting untuk tidak menganggapnya sebagai istilah generalisasi yang menunjukkan seperangkat alat dan teknik yang berbeda. Sayangnya, kesalahan ini juga saya buat -
dalam artikel saya sebelumnya tidak disajikan klasifikasi ilmiah tentang metode pengujian, dan di bagian "Pengujian dalam produksi" berbagai metodologi dan alat dikelompokkan.
Dari catatan Testing Microservices, cara yang waras ("Pendekatan cerdas untuk menguji microservices")Sejak penerbitan catatan pada akhir Desember 2017, saya telah membahas isinya dan umumnya topik pengujian dalam produksi dengan beberapa orang.
Dalam perjalanan diskusi ini, dan juga setelah serangkaian percakapan terpisah, menjadi jelas bagi saya bahwa topik pengujian dalam produksi tidak dapat direduksi menjadi beberapa poin yang tercantum di atas.
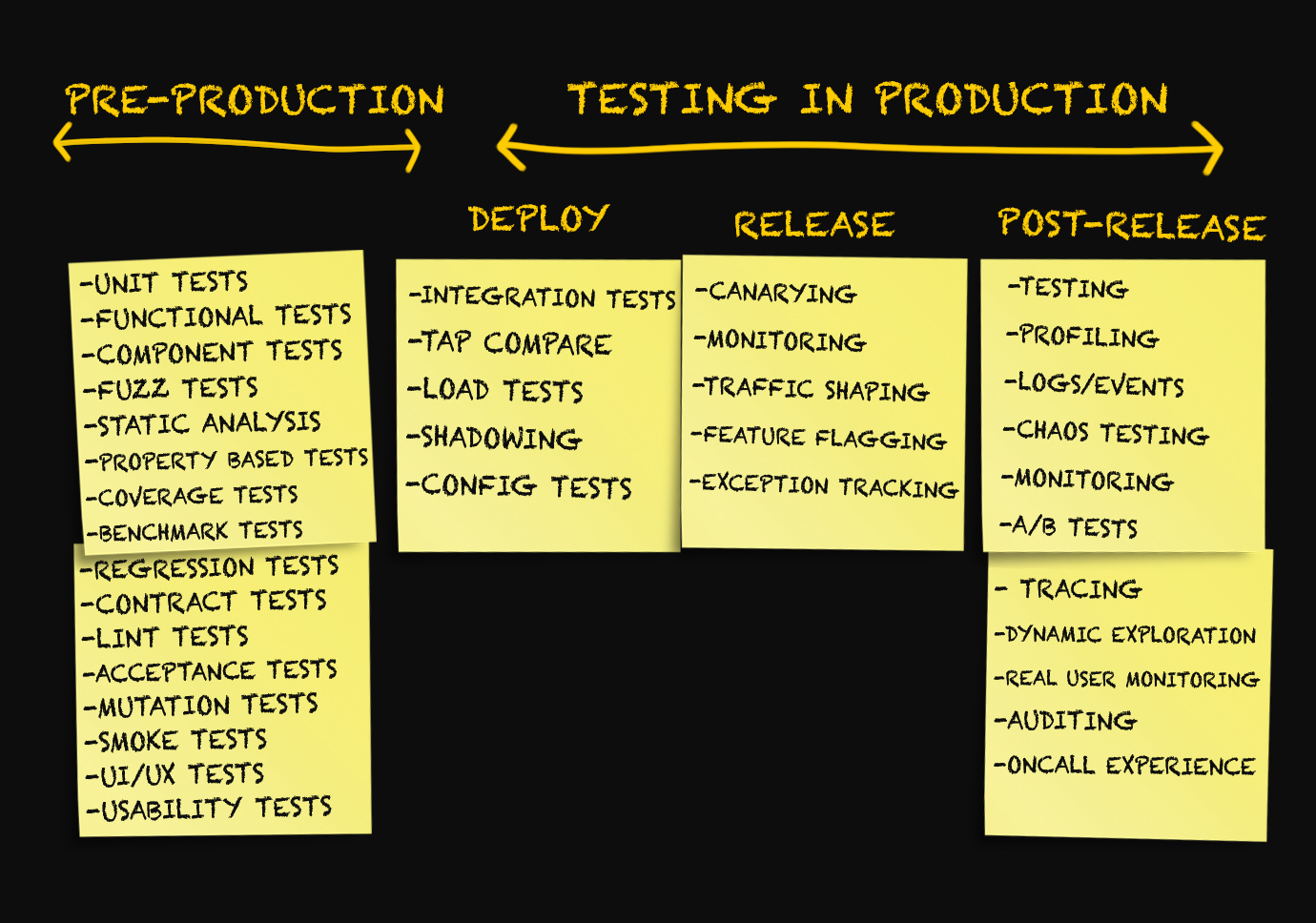
Konsep "pengujian dalam produksi" mencakup berbagai teknik yang diterapkan
pada tiga tahap yang berbeda . Yang mana - mari kita mengerti.
Tiga tahap produksi
Biasanya diskusi tentang produksi dilakukan hanya dalam konteks penerapan kode dalam produksi, pemantauan, atau dalam situasi darurat ketika terjadi kesalahan.
Saya sendiri sejauh ini menggunakan istilah-istilah seperti "penyebaran", "rilis", "pengiriman", dll., Sebagai sinonim, dengan sedikit pemikiran tentang artinya. Beberapa bulan yang lalu, semua upaya untuk membedakan istilah-istilah ini akan ditolak oleh saya sebagai sesuatu yang tidak penting.
Setelah memikirkan hal ini, saya sampai pada ide bahwa
ada kebutuhan nyata untuk membedakan berbagai tahapan produksi.
Tahap 1. Penerapan
Ketika pengujian (bahkan dalam produksi) adalah pemeriksaan pencapaian
indikator terbaik , keakuratan pengujian (dan memang dari setiap cek) dipastikan hanya dengan syarat bahwa metode melakukan pengujian sedekat mungkin dengan cara layanan sebenarnya digunakan dalam produksi.
Dengan kata lain, tes harus dijalankan di lingkungan yang
paling baik mensimulasikan lingkungan kerja .
Dan
tiruan terbaik dari lingkungan kerja adalah ... lingkungan kerja itu sendiri. Untuk melakukan jumlah tes maksimum yang dimungkinkan dalam lingkungan produksi, perlu bahwa hasil dari salah satu dari mereka tidak mempengaruhi pengguna akhir.
Ini, pada gilirannya, hanya mungkin jika,
ketika menggunakan layanan dalam lingkungan produksi, pengguna tidak mendapatkan akses langsung ke layanan ini .
Dalam artikel ini, saya memutuskan untuk menggunakan terminologi dari
Deploy! = Rilis artikel yang ditulis oleh
Turbine Labs . Ini mendefinisikan istilah "penyebaran" sebagai berikut:
“Deployment adalah instalasi oleh kelompok kerja dari versi baru dari kode program layanan dalam infrastruktur produksi. Ketika kami mengatakan bahwa versi baru dari perangkat lunak telah
digunakan , kami bermaksud bahwa itu berjalan di suatu tempat dalam kerangka kerja infrastruktur. Ini bisa menjadi contoh EC2 baru di AWS atau wadah Docker yang berjalan di perapian cluster Kubernetes. Layanan mulai berhasil, lulus pemeriksaan kesehatan dan siap (Anda harap!) Untuk memproses data lingkungan produksi, tetapi mungkin tidak benar-benar menerima data. Ini adalah poin penting, saya tekankan lagi:
untuk penyebaran tidak perlu bagi pengguna untuk mendapatkan akses ke versi baru layanan Anda . Dengan definisi ini, penyebaran bisa disebut proses dengan risiko hampir nol. ”
Kata-kata "proses tanpa risiko" hanyalah balsem bagi jiwa banyak orang yang telah menderita karena penyebaran yang tidak berhasil. Kemampuan untuk menginstal perangkat lunak
dalam lingkungan nyata tanpa mengizinkan pengguna untuk itu memiliki sejumlah keunggulan ketika datang ke pengujian.
Pertama, kebutuhan untuk mempertahankan lingkungan yang terpisah untuk pengembangan, pengujian dan pementasan, yang pasti harus disinkronkan dengan produksi, diminimalkan (dan bahkan mungkin hilang sama sekali).
Selain itu, pada tahap mendesain layanan, menjadi perlu untuk mengisolasi mereka satu sama lain sehingga kegagalan untuk menguji contoh spesifik dari layanan dalam produksi
tidak mengarah ke kaskade atau mempengaruhi pengguna dari kegagalan layanan lainnya. Salah satu solusi untuk ini dapat desain model data dan skema database di mana permintaan non-idempoten (terutama
operasi tulis ) dapat:
- Untuk dilakukan dalam kaitannya dengan basis data lingkungan produksi selama setiap uji peluncuran layanan dalam produksi (Saya lebih suka pendekatan ini);
- Ditolak dengan aman di tingkat aplikasi hingga mencapai tingkat penulisan atau penyimpanan;
- Dialokasikan atau diisolasi pada catatan atau tingkat penyimpanan dengan cara tertentu (misalnya, dengan menyimpan metadata tambahan).
Tahap 2. Rilis
Note
Deploy! = Rilis mendefinisikan istilah rilis sebagai berikut:
“Ketika kami mengatakan bahwa
rilis versi layanan telah terjadi, kami bermaksud bahwa itu menyediakan pemrosesan data di lingkungan produksi. Dengan kata lain,
rilis adalah proses yang mengarahkan data lingkungan produksi ke versi perangkat lunak baru. Dengan definisi ini dalam pikiran, semua risiko yang kami asosiasikan dengan mengirim aliran data baru (gangguan, ketidakpuasan pelanggan, catatan beracun dalam
The Register ) berhubungan dengan
rilis perangkat lunak baru, dan bukan penyebarannya (di beberapa perusahaan tahap ini juga disebut
rilis . Dalam artikel ini kami akan menggunakan istilah
rilis ). "
Dalam buku Google tentang SRE, istilah "rilis" digunakan dalam
bab tentang mengatur rilis perangkat lunak untuk menggambarkannya .
“Suatu
masalah adalah elemen logis dari pekerjaan yang terdiri dari satu atau lebih tugas terpisah. Tujuan kami adalah untuk mengoordinasikan proses penyebaran dengan profil risiko dari layanan ini .
Dalam lingkungan pengembangan atau pra-produksi, kami dapat membangun setiap jam dan secara otomatis mendistribusikan rilis setelah melewati semua pengujian. Untuk layanan berorientasi pengguna yang besar, kami dapat memulai rilis dengan satu cluster, dan kemudian meningkatkan skalanya hingga kami memperbarui semua cluster.
Untuk elemen infrastruktur penting, kami dapat memperpanjang periode implementasi hingga beberapa hari dan menjalankannya secara bergantian di wilayah geografis yang berbeda. ”Dalam terminologi ini, kata-kata "rilis" dan "rilis" berarti apa yang disebut kosa kata umum sebagai "penyebaran", dan istilah yang sering digunakan untuk menggambarkan berbagai strategi
penempatan (misalnya, penyebaran biru-hijau atau penyebaran kenari) mengacu pada
rilis yang baru perangkat lunak.
Selain itu,
pelepasan aplikasi yang tidak berhasil dapat menyebabkan gangguan parsial atau signifikan dalam pekerjaan. Pada tahap ini,
kembalikan atau
perbaikan terbaru juga dilakukan jika ternyata versi layanan yang baru
dirilis tidak stabil.
Proses
rilis bekerja paling baik ketika itu otomatis dan berjalan
secara bertahap . Demikian juga,
kembalikan atau
perbaikan terbaru layanan lebih berguna ketika tingkat kesalahan dan frekuensi permintaan secara otomatis berkorelasi dengan baseline.
Tahap 3. Setelah rilis
Jika rilis
berjalan dengan lancar dan versi baru dari layanan memproses data lingkungan produksi tanpa masalah yang jelas, kami dapat menganggapnya berhasil. Rilis yang sukses diikuti oleh tahap yang bisa disebut "setelah rilis".
Setiap sistem yang cukup kompleks akan
selalu berada dalam kondisi kehilangan kinerja secara bertahap. Ini tidak berarti bahwa
kembalikan atau
perbaikan terbaru diperlukan . Sebagai gantinya, perlu untuk memantau penurunan tersebut (untuk berbagai keperluan operasional dan operasional) dan debug jika perlu. Untuk alasan ini, pengujian setelah rilis tidak lagi seperti rutinitas, tetapi
debugging atau pengumpulan data analitik.
Secara umum, saya percaya bahwa setiap komponen sistem harus dibuat dengan mempertimbangkan fakta bahwa tidak satu pun sistem besar bekerja dengan sempurna 100% dan bahwa kerusakan harus diakui dan diperhitungkan pada tahap desain, pengembangan, pengujian, penyebaran, dan pemantauan perangkat lunak. menyediakan.
Sekarang kami telah mengidentifikasi tiga tahap produksi, mari kita lihat berbagai mekanisme pengujian yang tersedia pada masing-masing dari mereka. Tidak semua orang memiliki kesempatan untuk mengerjakan proyek baru atau menulis ulang kode dari awal. Dalam artikel ini, saya mencoba mengidentifikasi dengan jelas metode yang akan bekerja paling baik ketika mengembangkan proyek baru, serta berbicara tentang apa lagi yang bisa kita lakukan untuk mengambil keuntungan dari metode yang diusulkan tanpa membuat perubahan signifikan pada proyek yang bekerja.
Pengujian Penempatan
Kami memisahkan tahap penyebaran dan rilis dari satu sama lain, dan sekarang kami akan mempertimbangkan beberapa jenis pengujian yang dapat diterapkan setelah menerapkan kode di lingkungan produksi.
Pengujian integrasi
Biasanya, pengujian integrasi dilakukan oleh server integrasi berkelanjutan dalam lingkungan pengujian terisolasi untuk setiap cabang Git. Salinan
seluruh topologi layanan (termasuk basis data, antrian, proksi, dll.) Digunakan untuk ruang uji
semua layanan yang akan bekerja sama.
Saya percaya ini tidak terlalu efektif karena beberapa alasan. Pertama-tama, lingkungan pengujian, seperti lingkungan pementasan, tidak dapat digunakan sedemikian rupa sehingga
identik dengan lingkungan produksi nyata,
bahkan jika pengujian dijalankan dalam wadah Docker yang sama yang akan digunakan dalam produksi. Ini terutama benar ketika
satu -
satunya hal yang berjalan di lingkungan pengujian adalah tes itu sendiri.
Terlepas dari apakah tes dijalankan sebagai wadah Docker atau proses POSIX, kemungkinan besar membuat
satu atau lebih koneksi ke layanan, database, atau cache yang lebih unggul, yang jarang terjadi jika layanan berada dalam lingkungan produksi di mana ia dapat secara bersamaan proses beberapa koneksi konkuren, sering menggunakan kembali koneksi TCP yang tidak aktif (ini disebut reusing koneksi HTTP).
Juga, masalah ini disebabkan oleh kenyataan bahwa sebagian besar tes di setiap mulai membuat tabel database baru atau ruang cache kunci pada
node yang sama di mana tes ini dilakukan (dengan cara ini tes diisolasi dari kegagalan jaringan). Jenis pengujian terbaik ini dapat menunjukkan bahwa sistem bekerja dengan benar dengan permintaan yang sangat spesifik. Ini jarang efektif dalam mensimulasikan jenis kegagalan serius yang terdistribusi dengan baik, belum lagi berbagai jenis kegagalan parsial.
Ada studi komprehensif yang mengkonfirmasi bahwa sistem terdistribusi sering menunjukkan
perilaku tak terduga yang tidak dapat diramalkan dengan analisis yang dilakukan secara berbeda dari seluruh sistem.
Tetapi ini tidak berarti bahwa pengujian integrasi
pada prinsipnya tidak berguna. Kami hanya dapat mengatakan bahwa implementasi tes integrasi dalam lingkungan
buatan yang sepenuhnya terisolasi , sebagai suatu peraturan, tidak masuk akal. Pengujian integrasi masih harus dilakukan untuk memverifikasi bahwa versi layanan yang baru:
- Tidak mengganggu interaksi dengan layanan hulu atau hilir;
- Tidak memengaruhi tujuan dan sasaran layanan yang lebih tinggi atau lebih rendah.
Yang pertama dapat diberikan sampai batas tertentu melalui pengujian kontrak.
Karena kenyataan bahwa
antarmuka antara layanan bekerja dengan benar,
pengujian kontrak merupakan metode yang efektif untuk mengembangkan dan menguji layanan individual pada
tahap pra-produksi , yang tidak memerlukan penyebaran seluruh topologi layanan.
Platform pengujian kontrak yang berorientasi klien, seperti
Pact , saat ini hanya mendukung interoperabilitas antar layanan melalui RESTful JSON RPC, meskipun kemungkinan
sedang dilakukan pekerjaan untuk mendukung interaksi asinkron melalui soket web, aplikasi non-server, dan antrian pesan . Dukungan untuk protokol gRPC dan GraphQL kemungkinan akan ditambahkan di masa depan, tetapi sekarang belum tersedia.
Namun, sebelum
rilis versi baru, mungkin perlu memeriksa tidak hanya operasi
antarmuka yang benar . , , , RPC- . , , , .
,
, — ,
, ( , ).
:
?
. – , : - - ( C) MySQL ( D) memcache ( B).
, ( ), stateful- stateless- .
,
.
service discovery
( ),
.
.
,
C .
,
, , . , , . ,
, .
Google
Just Say No to More End-to-End Tests (« »), :
«
( ) . , ? , .
, , , »., :
. , A .
,
C MySQL, .
( , , «» ,
).
MySQL , , .
— -. , . -, .
, -
, /:
, (, ).
, ,
. IP- , , , , , , , , .
, , , , . . Facebook,
Kraken , :
«
— , . - , . , . - , , , »., , , , , .
- . service mesh . -. -, , , :
Jika kami menguji layanan B, server proxy keluarnya dapat dikonfigurasi untuk menambahkan header
X-ServiceB-Test untuk setiap permintaan pengujian. Dalam hal ini, server proxy yang masuk dari layanan superior C akan dapat:
- Deteksi tajuk ini dan kirim respons standar ke layanan B;
- Beri tahu Layanan C bahwa permintaan itu adalah ujian .
Pengujian integrasi interaksi versi layanan B yang dikerahkan dengan versi layanan C yang dirilis, di mana operasi penulisan tidak pernah mencapai basis dataMelakukan pengujian integrasi dengan cara ini juga memungkinkan pengujian interaksi layanan B dengan layanan yang lebih tinggi
ketika mereka memproses data lingkungan produksi normal - ini mungkin merupakan tiruan yang lebih dekat tentang bagaimana layanan B akan berperilaku ketika
dilepaskan ke dalam produksi.
Akan lebih baik jika setiap layanan dalam arsitektur ini mendukung panggilan API nyata dalam mode uji atau tiruan, memungkinkan Anda menguji pelaksanaan kontrak layanan dengan layanan hilir tanpa mengubah data nyata. Ini sama dengan pengujian kontrak, tetapi pada tingkat jaringan.
Duplikasi data bayangan (menguji aliran data gelap atau mirroring)
Duplikasi bayangan (dalam artikel di blog Google itu disebut
peluncuran gelap , dan istilah
mirroring digunakan dalam
Istio ) dalam banyak kasus memiliki kelebihan lebih dari pengujian integrasi.
Prinsip -
prinsip Rekayasa Kekacauan menyatakan sebagai berikut:
“
Sistem berperilaku berbeda tergantung pada lingkungan dan skema transfer data. Karena mode penggunaan dapat berubah kapan saja ,
pengambilan sampel data nyata adalah satu-satunya cara yang dapat diandalkan untuk memperbaiki jalur permintaan. "Duplikasi data bayangan adalah metode di mana aliran data lingkungan produksi yang memasuki layanan yang diberikan ditangkap dan direproduksi dalam versi layanan yang baru
digunakan . Proses ini dapat dilakukan baik secara waktu nyata, ketika aliran data yang masuk dipisah dan dikirim ke versi layanan yang
dirilis dan
disebarkan , atau secara asinkron, ketika salinan data yang sebelumnya diambil diputar kembali di layanan yang
digunakan .
Ketika saya bekerja di
imgix (startup dengan staf 7 insinyur, yang hanya empat adalah insinyur sistem), aliran data gelap secara aktif digunakan untuk menguji perubahan dalam infrastruktur visualisasi gambar kami. Kami mendaftarkan persentase tertentu dari semua permintaan masuk dan mengirimkannya ke kluster Kafka - kami melewati log akses HAProxy ke pipa
heka , yang kemudian meneruskan aliran permintaan yang dianalisis ke kluster Kafka. Sebelum tahap
rilis, versi baru aplikasi pemrosesan gambar kami diuji pada aliran data gelap yang ditangkap - ini memungkinkan untuk memverifikasi bahwa permintaan diproses dengan benar. Namun, sistem visualisasi gambar kami pada umumnya adalah layanan tanpa kewarganegaraan yang sangat cocok untuk jenis pengujian ini.
Beberapa perusahaan lebih suka menangkap bukan bagian dari aliran data, tetapi mengirimkan
salinan lengkap aliran ini ke versi aplikasi yang baru.
McRouter Facebook (proksi memcached) mendukung jenis duplikasi bayangan aliran data memcache.
“
Saat menguji instalasi baru untuk cache, kami merasa sangat nyaman untuk dapat mengalihkan salinan lengkap dari aliran data dari klien. McRouter mendukung pengaturan duplikasi bayangan yang fleksibel. Dimungkinkan untuk melakukan duplikasi bayangan dari kumpulan berbagai ukuran (dengan melakukan caching ulang ruang kunci), menyalin hanya bagian dari ruang kunci, atau secara dinamis mengubah parameter selama operasi . "
Aspek negatif dari duplikasi bayangan dari seluruh aliran data untuk layanan yang
digunakan dalam lingkungan produksi adalah bahwa jika dijalankan pada saat intensitas transfer data maksimum, maka mungkin memerlukan daya dua kali lebih banyak.
Proxy seperti Utusan mendukung duplikasi bayangan aliran data ke cluster lain dalam mode api-dan-lupa.
Dokumentasinya mengatakan:
“
Router dapat melakukan duplikasi bayangan aliran data dari satu cluster ke yang lain. Saat ini, mode api-dan-lupa diimplementasikan, di mana server proxy Utusan tidak menunggu respons dari cluster bayangan sebelum mengembalikan respons dari cluster utama. Untuk kelompok bayangan, semua statistik biasa dikumpulkan, yang berguna untuk tujuan pengujian. Dengan duplikasi bayangan, opsi -shadow ditambahkan ke -shadow host / otoritas. Ini berguna untuk masuk. Sebagai contoh, cluster1 berubah menjadi cluster1-shadow . "
Namun, seringkali tidak praktis atau tidak mungkin untuk membuat replika kluster yang disinkronkan dengan produksi untuk pengujian (untuk alasan yang sama bahwa itu bermasalah untuk mengatur klaster pementasan yang disinkronkan). Jika duplikasi bayangan digunakan untuk menguji layanan yang
digunakan baru yang memiliki banyak dependensi, itu dapat memulai perubahan tak terduga dalam keadaan layanan tingkat yang lebih tinggi sehubungan dengan yang diuji. Duplikasi bayangan dari volume harian pendaftaran pengguna dalam versi layanan yang digunakan dengan rekaman dalam basis data produksi dapat menyebabkan peningkatan tingkat kesalahan hingga 100% karena fakta bahwa aliran data bayangan akan dianggap sebagai upaya pendaftaran berulang dan ditolak.
Pengalaman pribadi saya menunjukkan bahwa duplikasi bayangan paling cocok untuk menguji permintaan non-idempoten atau layanan stateless dengan bertopik sisi server. Dalam hal ini, duplikasi bayangan data lebih sering digunakan untuk menguji beban, stabilitas, dan konfigurasi. Pada saat yang sama, dengan bantuan pengujian atau pementasan integrasi, Anda dapat menguji bagaimana layanan berinteraksi dengan server stateful saat bekerja dengan permintaan non-idempoten.
Perbandingan TAP
Satu-satunya penyebutan istilah ini adalah dalam
artikel dari blog Twitter yang ditujukan untuk peluncuran layanan dengan kualitas layanan tingkat tinggi.
“Untuk memverifikasi kebenaran implementasi baru dari sistem yang ada, kami menggunakan metode yang disebut perbandingan-tap . Alat perbandingan keran kami mereproduksi data produksi sampel dalam sistem baru dan membandingkan jawaban yang diterima dengan hasil yang lama. Hasil yang diperoleh membantu kami menemukan dan memperbaiki kesalahan dalam sistem bahkan sebelum pengguna akhir menemukannya. "Posting blog Twitter
lain mendefinisikan perbandingan keran sebagai berikut:
"Mengirim permintaan ke layanan contoh dalam produksi dan dalam lingkungan pementasan dengan memeriksa hasil dan mengevaluasi karakteristik kinerja."Perbedaan antara perbandingan keran dan duplikasi bayangan adalah bahwa dalam kasus pertama, respons yang dikembalikan oleh versi yang
dirilis dibandingkan dengan respons yang dikembalikan oleh versi yang
digunakan , dan pada yang kedua, permintaan tersebut digandakan ke versi yang
digunakan dalam mode offline seperti api-dan-lupa.
Alat lain untuk bekerja di area ini adalah perpustakaan
ilmuwan , tersedia di GitHub. Alat ini dikembangkan untuk menguji kode Ruby, tetapi kemudian dipindahkan ke
beberapa bahasa lain . Ini berguna untuk beberapa jenis pengujian, tetapi memiliki sejumlah masalah yang belum terpecahkan. Inilah yang ditulis pengembang GitHub dalam satu komunitas Slack profesional:
“Alat ini hanya menjalankan dua cabang kode dan membandingkan hasilnya. Anda harus berhati-hati dengan kode cabang-cabang ini. Penting untuk memastikan bahwa permintaan basis data tidak digandakan jika ini menyebabkan masalah. Saya pikir ini berlaku tidak hanya untuk seorang ilmuwan, tetapi juga untuk setiap situasi di mana Anda melakukan sesuatu dua kali, dan kemudian membandingkan hasilnya. Alat ilmuwan diciptakan untuk memverifikasi bahwa sistem izin yang baru berfungsi sama dengan yang lama, dan pada waktu tertentu digunakan untuk membandingkan data yang khas untuk hampir setiap permintaan Rails. Saya pikir prosesnya akan memakan waktu lebih lama, karena pemrosesan dilakukan berurutan, tetapi ini adalah masalah Ruby di mana utas tidak digunakan.
Dalam kebanyakan kasus yang saya kenal, alat ilmuwan digunakan untuk bekerja dengan operasi baca daripada menulis, misalnya, untuk mengetahui apakah kueri baru yang ditingkatkan dan skema izin menerima jawaban yang sama seperti yang lama. Kedua opsi dijalankan dalam lingkungan produksi (pada replika). Jika sumber daya yang diuji memiliki efek samping, saya pikir pengujian harus dilakukan pada tingkat aplikasi. "Diffy adalah alat open source tertulis Scala yang diperkenalkan oleh Twitter pada tahun 2015.
Artikel dari blog Twitter berjudul
Pengujian tanpa Menulis Tes mungkin merupakan sumber terbaik untuk memahami bagaimana perbandingan kerja tap dalam praktik.
“Diffy mendeteksi kesalahan potensial dalam layanan dengan meluncurkan kode yang baru dan lama secara bersamaan. Alat ini berfungsi sebagai server proxy dan mengirimkan semua permintaan yang diterima ke setiap instance yang berjalan. Dia kemudian membandingkan respons dari instance dan melaporkan semua penyimpangan yang ditemukan selama perbandingan. Diffy didasarkan pada gagasan berikut: jika dua implementasi suatu layanan mengembalikan jawaban yang sama dengan sejumlah permintaan yang cukup besar dan beragam, maka kedua implementasi ini dapat dianggap setara, dan yang lebih baru dari keduanya tanpa penurunan kinerja. Teknik pengurangan noise inovatif Diffy membedakannya dari alat analisis regresi komparatif lainnya. "Perbandingan keran sangat bagus ketika Anda perlu memeriksa apakah dua versi memberikan hasil yang sama. Menurut Mark McBride,
“Alat Diffy sering digunakan dalam mendesain ulang sistem. Dalam kasus kami, kami membagi basis kode sumber Rails menjadi beberapa layanan yang dibuat menggunakan Scala, dan sejumlah besar klien API menggunakan fungsi secara berbeda dari yang kami harapkan. Fungsi seperti format tanggal sangat berbahaya. "Perbandingan-tap bukanlah opsi terbaik untuk menguji aktivitas pengguna atau identitas perilaku dua versi layanan pada beban maksimum. Seperti dengan duplikasi bayangan, efek samping tetap menjadi masalah yang belum terselesaikan, terutama ketika versi yang digunakan dan versi produksi menulis data ke database yang sama. Seperti halnya pengujian integrasi, satu cara untuk mengatasi masalah ini adalah menggunakan tes perbandingan keran dengan hanya satu set akun yang terbatas.
Uji beban
Bagi mereka yang tidak terbiasa dengan stress testing,
artikel ini dapat berfungsi sebagai titik awal yang baik. Tidak ada kekurangan alat dan platform untuk pengujian beban sumber terbuka. Yang paling populer di antaranya adalah
Apache Bench ,
Gatling ,
wrk2 ,
Tsung , ditulis dalam bahasa Erlang,
Siege ,
Iago dari Twitter, ditulis dalam Scala (yang mereproduksi log dari server HTTP, server proxy atau penganalisa paket jaringan dalam contoh uji). Beberapa ahli percaya bahwa alat terbaik untuk menghasilkan beban adalah
mzbench , yang mendukung berbagai protokol, termasuk MySQL, Postgres, Cassandra, MongoDB, TCP, dll. Netflix's
NDBench adalah alat open source lain untuk memuat data gudang pengujian. , yang mendukung sebagian besar protokol yang dikenal.
Blog Twitter resmi
Iago menjelaskan secara lebih rinci fitur-fitur yang harus dimiliki generator beban yang baik:
“Permintaan non-pemblokiran dihasilkan pada frekuensi tertentu berdasarkan pada distribusi statistik khusus internal ( proses Poisson dimodelkan secara default). Frekuensi permintaan dapat diubah sesuai kebutuhan, misalnya, untuk menyiapkan cache sebelum bekerja dengan beban penuh.
Secara umum, perhatian utama diberikan pada frekuensi permintaan sesuai dengan hukum Little , dan bukan pada jumlah pengguna bersamaan, yang dapat bervariasi tergantung pada jumlah keterlambatan yang melekat dalam layanan ini. Karena ini, peluang baru muncul untuk membandingkan hasil beberapa pengujian dan mencegah penurunan layanan, memperlambat pengoperasian generator beban.
Dengan kata lain, alat Iago berupaya mensimulasikan sistem di mana permintaan diterima terlepas dari kemampuan layanan Anda untuk memprosesnya. Dalam hal ini, ini berbeda dari generator beban yang mensimulasikan sistem tertutup di mana pengguna akan dengan sabar bekerja dengan penundaan yang ada. Perbedaan ini memungkinkan kami untuk memodelkan mode kegagalan yang dapat ditemui dalam produksi dengan cukup akurat. "Tipe lain dari pengujian beban adalah pengujian tegangan dengan mendistribusikan kembali aliran data. Esensinya adalah sebagai berikut: seluruh aliran data dari lingkungan produksi diarahkan ke kluster yang lebih kecil daripada yang disiapkan untuk layanan; jika ada masalah, aliran data ditransfer kembali ke kelompok yang lebih besar. Teknik ini digunakan oleh Facebook, seperti yang dijelaskan dalam salah satu
artikel di blog resminya :
“Kami secara khusus mengarahkan aliran data yang lebih besar ke masing-masing cluster atau node, mengukur konsumsi sumber daya pada node-node ini dan menentukan batas-batas stabilitas layanan. Jenis pengujian ini, khususnya, berguna untuk menentukan sumber daya CPU yang diperlukan untuk mendukung jumlah maksimum siaran simultan Facebook Live. "Inilah yang ditulis oleh mantan insinyur LinkedIn di komunitas Slack profesional:
"LinkedIn juga menggunakan tes redline dalam produksi - server dihapus dari penyeimbang beban sampai beban mencapai nilai ambang batas atau kesalahan mulai terjadi."Memang, pencarian Google menyediakan tautan ke
kertas putih penuh dan
artikel blog LinkedIn tentang topik ini:
“Solusi Redliner untuk pengukuran menggunakan aliran data nyata dari lingkungan produksi, yang menghindari kesalahan yang mencegah pengukuran kinerja yang akurat di laboratorium.
Redliner mengalihkan sebagian aliran data ke layanan yang diuji dan real-time menganalisis kinerjanya. Solusi ini telah diterapkan di ratusan layanan LinkedIn internal dan digunakan setiap hari untuk berbagai jenis analisis kinerja.
Redliner mendukung pelaksanaan uji paralel untuk mesin virtual kenari dan produksi. Ini memungkinkan para insinyur untuk mentransfer jumlah data yang sama ke dua contoh layanan yang berbeda: 1) contoh layanan yang berisi inovasi, seperti konfigurasi baru, properti, atau kode baru; 2) contoh layanan dari versi kerja saat ini."Hasil pengujian beban diperhitungkan saat membuat keputusan dan membantu mencegah penyebaran kode, yang dapat menyebabkan kinerja yang buruk."Facebook mengambil pengujian beban menggunakan aliran data nyata ke tingkat yang sama sekali baru berkat sistem Kraken, dan
deskripsinya juga layak dibaca.
Pengujian dilaksanakan dengan mendistribusikan kembali aliran data ketika mengubah nilai bobot (baca dari toko konfigurasi terdistribusi) untuk perangkat perbatasan dan kluster dalam konfigurasi
Proxygen (penyeimbang beban Facebook). Nilai-nilai ini menentukan volume data nyata yang dikirim, masing-masing, ke setiap cluster dan wilayah pada titik kehadiran tertentu.
Data dari kertas putih KrakenSistem pemantauan (
Gorilla ) menampilkan indikator berbagai layanan (seperti yang ditunjukkan pada tabel di atas). Berdasarkan data pemantauan dan ambang batas, keputusan dibuat apakah akan mengirim data lebih lanjut sesuai dengan nilai bobot, atau apakah perlu untuk mengurangi atau bahkan sepenuhnya menghentikan transfer data ke cluster tertentu.
Tes konfigurasi
Gelombang baru alat infrastruktur sumber terbuka telah membuat menangkap semua perubahan infrastruktur dalam bentuk kode tidak hanya mungkin, tetapi juga relatif
mudah . Juga dimungkinkan untuk berbagai derajat untuk
menguji perubahan-perubahan ini, meskipun sebagian besar
tes infrastruktur-sebagai-a-kode pada tahap pra-produksi hanya dapat mengkonfirmasi spesifikasi dan sintaksis yang benar.
Selain itu, penolakan untuk menguji konfigurasi baru sebelum
rilis kode menjadi penyebab
sejumlah besar gangguan .
Untuk pengujian menyeluruh terhadap perubahan konfigurasi, penting untuk membedakan antara berbagai jenis konfigurasi. Fred Hebert pernah menyarankan menggunakan kuadran berikut:
Opsi ini, tentu saja, tidak universal, tetapi perbedaan ini memungkinkan Anda untuk memutuskan cara terbaik untuk menguji masing-masing konfigurasi dan pada tahap apa untuk melakukannya. Konfigurasi waktu pembuatan masuk akal jika Anda dapat memastikan pengulangan rakitan yang sebenarnya. Tidak semua konfigurasi statis, tetapi pada platform modern perubahan konfigurasi dinamis tidak dapat dihindari (bahkan jika kita berurusan dengan "infrastruktur permanen").
, , blue-green , . (
Jamie Wilkinson ), Google ,
:
« , , , - . . - , — , , . ., . , , — ».Facebook :
« . — , . . , .
. Facebook , . , .
(, JSON). , . .
(, Facebook Thrift) . , .
, , - . . — A/B-, 1 % . A/B-, . A/B- . , , , , . , A/B- . , A/B-. Facebook .
, A/B- 1% , 1% , ( « »). , . , .
Facebook . , . , , . , , .- Pembatalan perubahan yang sederhana dan nyaman
Dalam beberapa kasus, terlepas dari semua tindakan pencegahan, penerapan konfigurasi yang tidak aktif dilakukan. Menemukan dan mengembalikan perubahan dengan cepat sangat penting untuk mengatasi masalah seperti itu. "Alat kontrol versi tersedia di sistem konfigurasi kami yang membuatnya lebih mudah untuk membatalkan perubahan."
Untuk dilanjutkan!UPD: berlanjut di sini .