Mungkin tidak ada teknologi lain saat ini di mana akan ada begitu banyak mitos, kebohongan dan ketidakmampuan. Wartawan yang berbicara tentang kebohongan teknologi, politisi yang berbicara tentang keberhasilan implementasi kebohongan, sebagian besar penjual teknologi berbohong. Setiap bulan, saya melihat konsekuensi dari bagaimana orang mencoba menerapkan pengenalan wajah dalam sistem yang tidak dapat bekerja dengannya.

Topik artikel ini sejak lama menjadi menyakitkan, tapi entah bagaimana terlalu malas untuk menulisnya. Banyak teks yang sudah saya ulangi dua puluh kali untuk orang yang berbeda. Tetapi, setelah membaca sebungkus sampah lagi, saya memutuskan bahwa sudah waktunya. Saya akan memberikan tautan ke artikel ini.
Jadi Dalam artikel ini saya akan menjawab beberapa pertanyaan sederhana:
- Apakah mungkin mengenali Anda di jalan? Dan bagaimana otomatis / dapat diandalkan?
- Sehari sebelum kemarin mereka menulis bahwa para penjahat ditahan di metro Moskow, dan kemarin mereka menulis bahwa mereka tidak bisa di London. Dan juga di Cina mereka mengenali semua orang, semua orang di jalan. Dan di sini mereka mengatakan bahwa 28 anggota Kongres AS adalah penjahat. Atau, mereka menangkap seorang pencuri.
- Siapa yang sekarang merilis solusi pengenalan wajah, apa perbedaan antara solusi, fitur teknologi?
Sebagian besar jawaban akan berbasis bukti, dengan tautan ke penelitian di mana parameter kunci dari algoritma + dengan perhitungan matematika ditampilkan. Sebagian kecil akan didasarkan pada pengalaman implementasi dan pengoperasian berbagai sistem biometrik.
Saya tidak akan merinci bagaimana pengenalan wajah diimplementasikan sekarang. Pada Habré ada banyak artikel bagus tentang hal ini:
a ,
b ,
c (ada lebih banyak dari mereka, tentu saja, ini muncul di memori). Tapi tetap saja, beberapa poin yang mempengaruhi keputusan berbeda - saya akan jelaskan. Jadi membaca setidaknya satu artikel di atas akan menyederhanakan pemahaman artikel ini. Ayo mulai!
Pendahuluan, Dasar
Biometrik adalah ilmu pasti. Tidak ada ruang untuk frasa "selalu bekerja" dan "ideal". Semuanya dipertimbangkan dengan sangat baik. Dan untuk menghitung Anda hanya perlu tahu dua jumlah:
- Kesalahan jenis pertama - situasi ketika seseorang tidak ada dalam basis data kami, tetapi kami mengidentifikasinya sebagai orang yang hadir dalam basis data (dalam FAR biometrik (tingkat akses palsu))
- Kesalahan jenis kedua - situasi ketika seseorang ada di database, tapi kami merindukannya. (Dalam biometrik FRR (false reject rate))
Kesalahan ini dapat memiliki sejumlah fitur dan kriteria aplikasi. Kami akan membicarakannya di bawah. Sementara itu, saya akan memberi tahu Anda di mana mendapatkannya.
Karakteristik
Opsi pertama . Sekali waktu, produsen sendiri menerbitkan kesalahan. Tapi ini masalahnya: Anda tidak bisa mempercayai pabrikan. Dalam kondisi apa dan bagaimana ia mengukur kesalahan ini - tidak ada yang tahu. Dan apakah diukur sama sekali, atau departemen pemasaran menarik.
Opsi kedua. Basis terbuka muncul. Produsen mulai menunjukkan kesalahan di pangkalan. Algoritme dapat dipertajam untuk database terkenal, sehingga mereka menunjukkan kualitas yang luar biasa bagi mereka. Namun dalam kenyataannya, algoritma semacam itu mungkin tidak berfungsi.
Opsi ketiga adalah kontes terbuka dengan solusi tertutup. Penyelenggara memeriksa keputusan. Pada dasarnya kaggle. Yang paling terkenal adalah
MegaFace . Tempat pertama dalam kompetisi ini pernah memberikan popularitas dan ketenaran yang luar biasa. Sebagai contoh, N-Tech dan Vocord telah banyak membuat nama untuk diri mereka sendiri di MegaFace.
Semuanya akan baik-baik saja, tetapi jujur. Anda dapat menyesuaikan solusinya di sini. Ini jauh lebih sulit, lebih lama. Tetapi Anda dapat menghitung orang, Anda dapat secara manual menandai basis, dll. Dan yang paling penting - tidak ada hubungannya dengan bagaimana sistem akan bekerja pada data nyata. Anda dapat melihat siapa pemimpin di MegaFace sekarang, dan kemudian mencari solusi dari orang-orang ini di paragraf berikutnya.
Opsi keempat . Sampai saat ini, yang paling jujur. Saya tidak tahu bagaimana cara curang di sana. Meskipun saya tidak mengecualikan mereka.
Lembaga besar dan terkenal di dunia setuju untuk menggunakan sistem pengujian solusi independen. SDK diterima dari pabrikan, yang tunduk pada pengujian tertutup, di mana pabrikan tidak berpartisipasi. Pengujian memiliki banyak parameter, yang kemudian secara resmi diterbitkan.
Sekarang
pengujian semacam
itu dilakukan oleh NIST - Institut Nasional Standar dan Teknologi Amerika. Pengujian semacam itu adalah yang paling jujur dan menarik.
Saya harus mengatakan bahwa NIST melakukan pekerjaan dengan baik. Mereka mengembangkan lima kasus, merilis pembaruan baru setiap beberapa bulan, terus meningkat dan termasuk produsen baru. Di sini Anda dapat menemukan edisi terbaru studi ini.
Tampaknya opsi ini ideal untuk analisis. Tapi tidak! Kerugian utama dari pendekatan ini adalah kita tidak tahu apa yang ada di database. Lihat grafik ini di sini:

Ini adalah data dari dua perusahaan yang melakukan pengujian. Sumbu x adalah bulan, y adalah persentase kesalahan. Saya mengikuti tes "Wajah-wajah liar" (tepat di bawah deskripsi).
Peningkatan akurasi yang tiba-tiba sebesar 10 kali di dua perusahaan independen (secara umum, semua orang lepas landas di sana). Dari mana?
Log NIST mengatakan "database terlalu rumit, kami menyederhanakannya." Dan tidak ada contoh basis lama atau baru. Menurut saya ini adalah kesalahan serius. Itu di pangkalan lama bahwa perbedaan antara algoritma vendor terlihat. Pada semua yang baru 4-8% dari pass. Dan yang lama itu 29-90%. Komunikasi saya dengan pengenalan wajah pada sistem CCTV mengatakan bahwa 30% sebelumnya - ini adalah hasil nyata dari algoritma grandmaster. Sulit dikenali dari foto-foto tersebut:

Dan tentu saja, akurasi 4% tidak bersinar pada mereka. Tetapi tanpa melihat basis NIST itu adalah 100% tidak mungkin untuk membuat pernyataan seperti itu. Tetapi NIST yang merupakan sumber data independen utama.
Dalam artikel itu, saya menggambarkan situasi yang relevan untuk Juli 2018. Pada saat yang sama, saya mengandalkan akurasi, menurut database orang yang lama untuk tes yang terkait dengan tugas "Faces in the wild".
Mungkin saja dalam setengah tahun semuanya akan berubah sepenuhnya. Atau mungkin akan stabil selama sepuluh tahun ke depan.
Jadi, kita membutuhkan tabel ini:
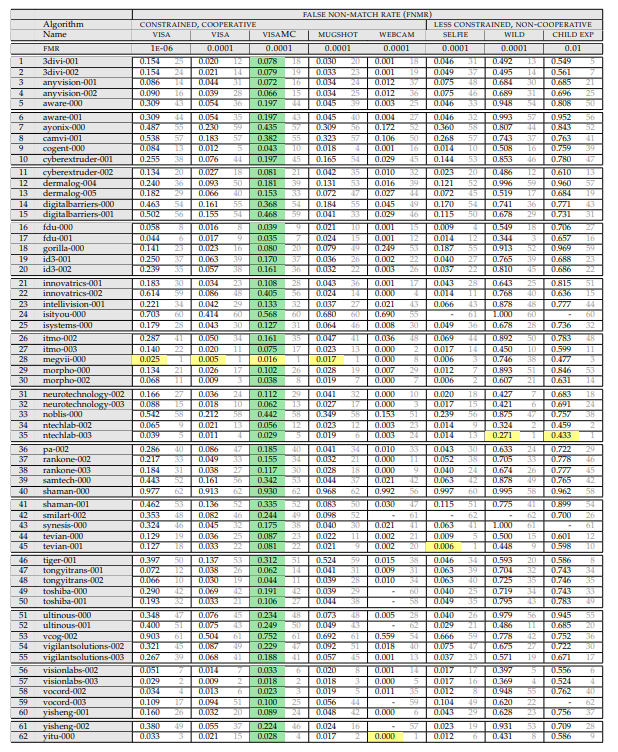
(April 2018, karena liar lebih memadai di sini)
Mari kita lihat apa yang tertulis di dalamnya dan bagaimana mengukurnya.
Di atas adalah daftar percobaan. Eksperimen terdiri dari:
Yang di mana set sedang diukur. Set adalah:
- Foto paspor (ideal, frontal). Latar belakangnya putih, sistem pemotretan yang ideal. Ini kadang-kadang dapat ditemukan di pos pemeriksaan, tetapi sangat jarang. Biasanya tugas-tugas tersebut adalah perbandingan seseorang di bandara dengan pangkalan.

- Fotografi adalah sistem yang baik, tetapi tanpa kualitas terbaik. Ada latar belakang latar belakang, seseorang mungkin tidak berdiri merata / melihat melewati kamera, dll.

- Swafoto dari kamera smartphone / komputer. Ketika pengguna bekerja sama, tetapi kondisi pemotretan buruk. Ada dua himpunan bagian, tetapi mereka hanya memiliki banyak foto di selfie.

- "Wajah di alam liar" - memotret dari hampir semua sisi / pemotretan tersembunyi. Sudut maksimum rotasi wajah ke kamera adalah 90 derajat. Di sinilah NIST sangat menyederhanakan pangkalan.

- Anak-anak Semua algoritma bekerja buruk untuk anak-anak.
Selain itu, pada tingkat kesalahan kesalahan jenis pertama apa yang diukur (parameter ini dianggap hanya untuk foto paspor):
- 10 ^ -4 - JAUH (satu false positive dari jenis pertama) untuk 10 ribu perbandingan dengan basis
- 10 ^ -6 - JAUH (satu false positive dari jenis pertama) per juta perbandingan dengan basis
Hasil percobaan adalah nilai FRR. Kemungkinan kami melewatkan orang yang ada di database.
Dan sudah di sini pembaca yang penuh perhatian dapat memperhatikan hal menarik pertama. "Apa artinya FAR 10 ^ -4?" Dan ini adalah momen paling menarik!
Pengaturan utama
Apa artinya kesalahan seperti itu dalam praktik? Ini berarti bahwa di pangkalan 10.000 orang akan ada satu kebetulan yang salah ketika memeriksa setiap orang biasa di atasnya. Artinya, jika kita memiliki basis 1000 penjahat, dan kita membandingkannya dengan 10.000 orang per hari, maka kita akan memiliki rata-rata 1000 positif palsu. Apakah ada yang benar-benar membutuhkan ini?
Pada kenyataannya, semuanya tidak terlalu buruk.
Jika Anda melihat pembuatan grafik ketergantungan kesalahan jenis pertama pada kesalahan jenis kedua, Anda mendapatkan gambar yang sangat keren (di sini langsung untuk selusin perusahaan yang berbeda, untuk opsi Wild, inilah yang akan terjadi di stasiun metro jika Anda meletakkan kamera di suatu tempat sehingga orang tidak melihatnya) :
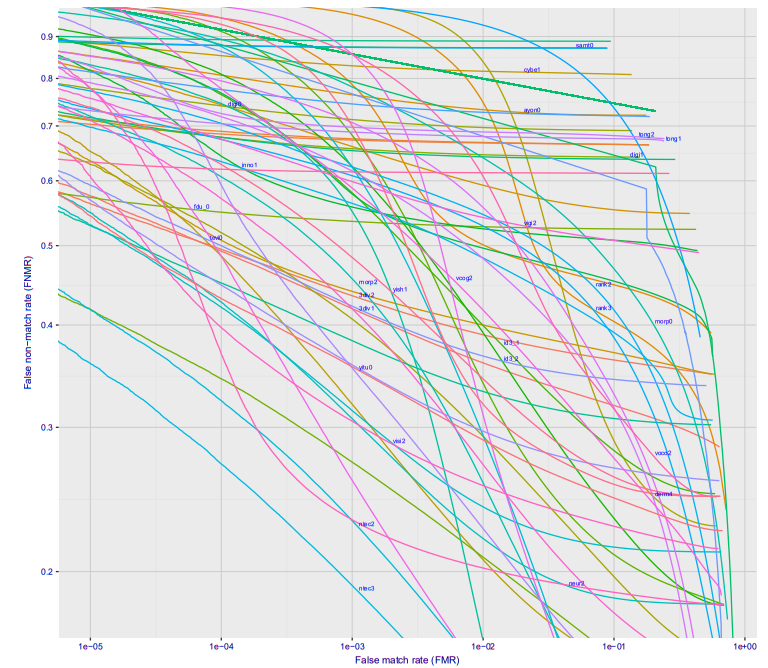
Dengan kesalahan 10 ^ -4, 27% dari orang yang tidak dikenal. 10 ^ -5 sekitar 40%. Kemungkinan besar kerugian 10 ^ -6 akan menjadi sekitar 50%
Jadi apa artinya ini dalam bilangan real?
Cara terbaik untuk pergi dari paradigma "berapa banyak kesalahan sehari dapat dilakukan." Kami memiliki banyak orang di stasiun, jika setiap 20-30 menit sistem memberikan positif palsu, maka tidak ada yang akan menganggapnya serius. Kami memperbaiki jumlah positif palsu yang diizinkan di stasiun metro 10 orang sehari (jika ada baiknya sistem tidak dimatikan karena mengganggu, Anda bahkan perlu lebih sedikit). Aliran satu stasiun Metro Moskow
20-120 ribu penumpang per hari. Rata-rata adalah 60 ribu.
Biarkan nilai tetap FAR menjadi 10 ^ -6 (Anda tidak bisa mengatakannya di bawah, kami akan kehilangan 50% penjahat jika kami optimis). Ini berarti bahwa kita dapat mengizinkan 10 alarm palsu dengan ukuran basis 160 orang.
Apakah banyak atau sedikit? Ukuran pangkalan di daftar orang yang dicari federal adalah ~
300.000 orang . Interpol 35 ribu. Adalah logis untuk berasumsi bahwa sekitar 30 ribu Moskow dibutuhkan.
Ini akan memberikan jumlah alarm palsu yang tidak realistis.
Perlu dicatat bahwa 160 orang dapat menjadi basis yang memadai jika sistem bekerja on-line. Jika Anda mencari mereka yang melakukan kejahatan di hari terakhir - ini sudah cukup berhasil. Pada saat yang sama, mengenakan kacamata hitam / topi, dll., Anda dapat menyamar. Tapi berapa banyak yang membawanya di kereta bawah tanah?
Poin penting kedua. Mudah membuat sistem di metro memberikan foto dengan kualitas lebih tinggi. Misalnya, letakkan di bingkai pintu putar kamera. Sudah tidak akan ada 50% dari kerugian sebesar 10 ^ -6, tetapi hanya 2-3%. Dan sebesar 10 ^ -7 5-10%. Di sini akurasi dari grafik di Visa, semuanya pasti akan jauh lebih buruk pada kamera nyata, tapi saya pikir pada 10 ^ -6 Anda dapat meninggalkan kerugian 10% ini:

Sekali lagi, sistem tidak akan menarik basis dari 30 ribu, tetapi semua yang terjadi secara real time akan memungkinkan deteksi.
Pertanyaan pertama
Sepertinya ini waktunya menjawab bagian pertama dari pertanyaan:
Liksutov
mengatakan bahwa 22 orang yang dicari diidentifikasi. Apakah ini benar?
Di sini pertanyaan utamanya adalah apa yang dilakukan orang-orang ini, berapa banyak orang yang tidak diinginkan diperiksa, berapa banyak pengenalan wajah membantu dalam penahanan 22 orang ini.
Kemungkinan besar, jika ini adalah orang-orang yang dicari oleh rencana "intersepsi", ini benar-benar tahanan. Dan ini hasil yang bagus. Tetapi asumsi sederhana saya memungkinkan saya untuk mengatakan bahwa untuk mencapai hasil ini, setidaknya 2-3 ribu orang diperiksa, tetapi sekitar sepuluh ribu.
Ini berdetak sangat baik dengan nomor yang dipanggil di
London . Hanya ada angka-angka ini yang diterbitkan dengan jujur, karena orang-orang
memprotes . Dan kami diam ...
Kemarin di Habré ada artikel tentang akun
wajah palsu tentang pengenalan wajah. Tapi ini adalah contoh manipulasi ke arah yang berlawanan. Amazon tidak pernah memiliki sistem pengenalan wajah yang baik. Ditambah pertanyaan tentang cara menetapkan ambang batas. Saya setidaknya bisa membuat 100% kacang dengan memutar pengaturan;)
Tentang orang Cina, yang mengenali semua orang di jalan - palsu. Meskipun, jika mereka melakukan pelacakan yang kompeten, maka di sana Anda dapat melakukan beberapa analisis yang lebih memadai. Tapi, jujur saja, saya tidak percaya sejauh ini bisa dicapai. Sebaliknya, satu set colokan.
Bagaimana dengan keselamatan saya? Di jalan, di rapat umum?
Mari kita melangkah lebih jauh. Mari kita evaluasi momen lain. Cari seseorang dengan biografi terkenal dan profil yang baik di jejaring sosial.
NIST memeriksa pengenalan tatap muka. Dua wajah dari orang yang sama / berbeda diambil dan membandingkan seberapa dekat mereka satu sama lain. Jika kedekatan lebih besar dari ambang, maka ini adalah satu orang. Jika lebih jauh - berbeda. Tetapi ada pendekatan yang berbeda.
Jika Anda membaca artikel yang saya sarankan di awal, maka Anda tahu bahwa ketika mengenali wajah, kode hash wajah dihasilkan, yang menampilkan posisinya dalam ruang dimensi-N. Biasanya ini adalah ruang 256/512 dimensi, meskipun semua sistem memiliki cara yang berbeda.
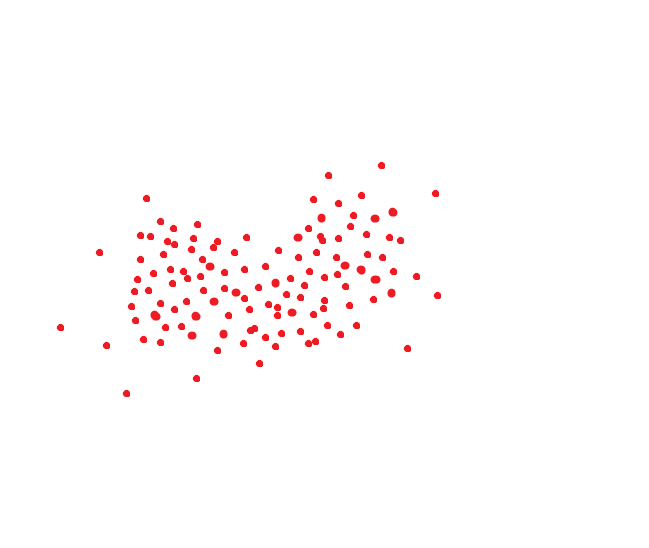
Sistem pengenalan wajah yang ideal menerjemahkan wajah yang sama ke dalam kode yang sama. Tetapi tidak ada sistem yang ideal. Satu dan orang yang sama biasanya menempati beberapa area ruang. Misalnya, jika kodenya dua dimensi, maka bisa jadi seperti ini:
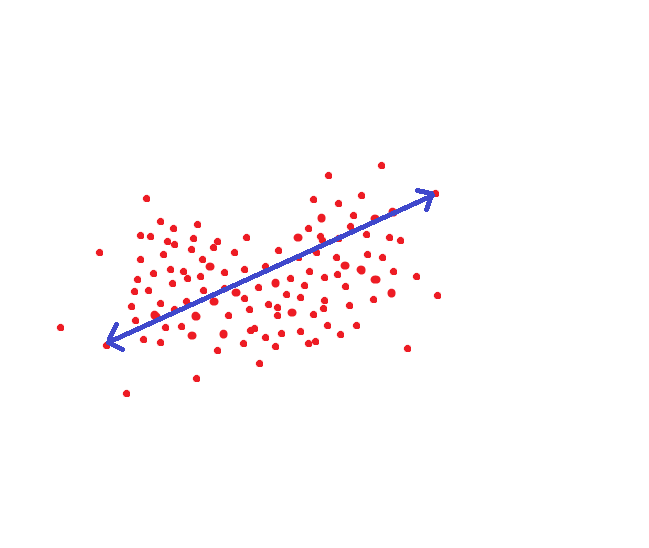
Jika kita dibimbing oleh metode yang diadopsi oleh NIST, maka jarak ini akan menjadi ambang batas target sehingga kita dapat mengenali seseorang sebagai satu dan individu yang sama dengan probabilitas 95%:
Tetapi Anda bisa melakukan sebaliknya. Untuk setiap orang, konfigurasikan area hyperspace tempat nilai yang valid untuknya disimpan:

Kemudian jarak ambang batas, sambil mempertahankan akurasi, akan berkurang beberapa kali.
Hanya kami yang membutuhkan banyak foto untuk setiap orang.
Jika seseorang memiliki profil di jejaring sosial / dasar gambarnya dari berbagai usia, maka akurasi pengenalannya dapat meningkat sangat banyak. Saya tidak tahu penilaian pasti tentang bagaimana FAR | FRR tumbuh. Dan sudah salah untuk mengevaluasi jumlah tersebut. Seseorang dalam database ini memiliki 2 foto, seseorang memiliki 100. Banyak logika pembungkus. Menurut saya peringkat maksimumnya adalah satu / satu setengah pesanan. Itu memungkinkan Anda untuk menambahkan 10 ^ -7 ke kesalahan dengan kemungkinan tidak mengenali 20-30%. Tapi ini spekulatif dan optimis.
Secara umum, tentu saja, ada banyak masalah dengan pengelolaan ruang ini (chip usia, chip editor gambar, chip noise, chip ketajaman), tetapi seperti yang saya pahami, kebanyakan dari mereka telah berhasil diselesaikan oleh perusahaan besar yang membutuhkan solusi.
Kenapa saya melakukan ini. Selain itu, penggunaan profil memungkinkan beberapa kali untuk meningkatkan akurasi algoritma pengenalan. Tapi itu jauh dari absolut. Profil membutuhkan banyak pekerjaan manual. Ada banyak orang yang serupa. Tetapi jika Anda mulai menetapkan batasan pada usia, lokasi, dll., Maka metode ini memungkinkan Anda untuk mendapatkan solusi yang baik. Sebagai contoh bagaimana mereka menemukan seseorang berdasarkan prinsip "cari profil dengan foto" -> "gunakan profil untuk mencari seseorang" Saya memberi
tautan di awal.
Tapi, menurut saya, ini adalah proses yang sangat scalable. Dan, sekali lagi, orang-orang dengan sejumlah besar gambar di profil, Tuhan melarang 40-50% di negara kita. Ya, dan banyak dari mereka adalah anak-anak yang semuanya bekerja dengan buruk.
Tapi, sekali lagi - ini adalah penilaian.
Jadi disini. Tentang keamanan Anda. Semakin sedikit foto profil yang Anda miliki, semakin baik. Semakin besar reli di mana Anda pergi, semakin baik. Tidak ada yang akan mem-parsing 20 ribu foto secara manual. Bagi mereka yang peduli dengan keamanan dan privasi mereka - saya akan menyarankan Anda untuk tidak membuat profil dengan gambar Anda.
Pada rapat umum di kota dengan populasi 100 ribu, mereka akan dengan mudah menemukan Anda dengan melihat 1-2 pertandingan. Di Moskow, mereka agak macet.
Sekitar setengah tahun yang lalu,
Vasyutka , dengan siapa kami bekerja bersama, berbicara tentang topik ini:
By the way, tentang jejaring sosial
Lalu aku membiarkan diriku melakukan perjalanan kecil ke samping. Kualitas pelatihan untuk algoritma pengenalan wajah tergantung pada tiga faktor:
- Kualitas wajah.
- Metrik kedekatan orang yang digunakan selama pelatihan Kehilangan Triplet, Kehilangan Center, kehilangan bola, dll.
- Ukuran dasar
Menurut klaim 2, sepertinya batas sekarang telah tercapai. Pada prinsipnya, matematika berkembang pada hal-hal seperti itu dengan sangat cepat. Dan bahkan setelah triplet loss, sisa fungsi loss tidak menghasilkan peningkatan dramatis, hanya peningkatan yang halus dan penurunan ukuran pangkalan.
Ekstraksi wajah sulit jika Anda perlu menemukan wajah dari semua sudut, setelah kehilangan sebagian kecil dari persen. Tetapi menciptakan algoritma seperti itu adalah proses yang cukup dapat diprediksi dan dikelola dengan baik. Semakin biru semuanya, semakin baik, sudut besar diproses dengan benar:

Dan enam bulan lalu seperti ini:

Dapat dilihat bahwa semakin banyak perusahaan yang perlahan-lahan bergerak dengan cara ini, algoritma mulai mengenali wajah semakin banyak.
Tetapi dengan ukuran dasar - semuanya lebih menarik. Basis terbuka kecil. Pangkalan yang bagus untuk maksimal beberapa puluh ribu orang. Mereka yang besar anehnya terstruktur / buruk (
megaface ,
MS-Celeb-1M ).
Menurut Anda dari mana pembuat algoritma mendapatkan basis data ini?
Sedikit petunjuk. Produk NTech pertama yang sedang mereka
buat adalah Find Face, pencarian orang-ke-orang. Saya pikir tidak ada penjelasan yang diperlukan. Tentu saja, kontak bertarung dengan bot yang mengempiskan semua profil terbuka. Tapi, sejauh yang saya dengar, orang masih bergetar. Dan teman sekelas. Dan instagram.
Sepertinya dengan Facebook - semuanya lebih rumit di sana. Tetapi saya hampir yakin bahwa sesuatu juga ditemukan.
Jadi ya, jika profil Anda terbuka - Anda bisa bangga, itu digunakan untuk mempelajari algoritma;)
Tentang solusi dan tentang perusahaan
Di sini Anda bisa bangga. Dari 5 perusahaan terkemuka di dunia, dua di antaranya adalah perusahaan Rusia. Ini adalah N-Tech dan VisionLabs. Setengah tahun yang lalu, NTech dan Vocord adalah pemimpin, yang pertama bekerja jauh lebih baik pada wajah yang dirotasi, yang terakhir di bagian depan.
Sekarang sisa pemimpin - 1-2 perusahaan Cina dan 1 Amerika, Vocord melewati sesuatu di peringkat.
Masih Rusia di peringkat itmo, 3divi, intellivision. Synesis adalah perusahaan Belarusia, meskipun beberapa pernah di Moskow, sekitar 3 tahun yang lalu mereka memiliki blog di Habré. Saya juga tahu beberapa solusi milik perusahaan asing, tetapi kantor pengembangannya juga ada di Rusia. Masih ada beberapa perusahaan Rusia yang tidak berada dalam persaingan, tetapi yang tampaknya memiliki solusi yang bagus. Sebagai contoh, MDGs miliki. Jelas, Odnoklassniki dan Vkontakte juga memiliki yang bagus, tetapi mereka untuk penggunaan internal.
Singkatnya, ya, kita dan orang Cina sebagian besar bergeser pada wajah kita.
NTech umumnya yang pertama di dunia yang menunjukkan kinerja yang baik di tingkat yang baru. Suatu tempat di
akhir 2015 . VisionLabs hanya tertangkap dengan NTech. Pada 2015, mereka adalah pemimpin pasar. Tetapi solusi mereka adalah dari generasi terakhir, dan mereka mulai mencoba mengejar ketinggalan dengan NTech hanya pada akhir 2016.
Sejujurnya, saya tidak suka kedua perusahaan ini. Pemasaran yang sangat agresif. Saya melihat orang-orang yang memiliki solusi yang jelas tidak pantas yang tidak menyelesaikan masalah mereka.
Di sisi ini, saya lebih menyukai Vocord. Entah bagaimana, dia menasehati orang-orang yang dengan jujur dikatakan Vokord, "proyekmu tidak akan bekerja dengan kamera dan titik pemasangan seperti itu." NTech dan VisionLabs dengan senang mencoba menjual. Tetapi sesuatu Vokord baru-baru ini menghilang.
Kesimpulan
Dalam kesimpulan saya ingin mengatakan yang berikut.
Pengenalan wajah adalah alat yang sangat bagus dan kuat. Ini sangat memungkinkan Anda menemukan penjahat hari ini. Tetapi implementasinya membutuhkan analisis yang sangat akurat dari semua parameter. Ada aplikasi di mana solusi OpenSource cukup. Ada aplikasi (pengakuan di stadion di tengah keramaian) di mana Anda hanya perlu menginstal VisionLabs | Ntech, dan juga menyimpan layanan, analisis, dan tim pembuat keputusan. Dan OpenSource tidak akan membantu Anda di sini.Hari ini, orang tidak bisa mempercayai semua kisah yang bisa Anda tangkap semua penjahat, atau menonton semua orang di kota. Tetapi penting untuk diingat bahwa hal-hal seperti itu dapat membantu menangkap penjahat. Misalnya, untuk berhenti di kereta bawah tanah tidak semua orang, tetapi hanya mereka yang sistemnya anggap serupa. Posisikan kamera agar wajah lebih dikenali dan buat infrastruktur yang sesuai untuk ini. Meskipun, misalnya, saya menentang ini. Untuk harga kesalahan jika Anda dikenali sebagai orang lain mungkin terlalu tinggi.