Pengenalan emosi adalah topik hangat di bidang kecerdasan buatan. Bidang aplikasi teknologi yang paling menarik meliputi: pengenalan pengemudi, riset pemasaran, sistem analisis video untuk kota pintar, interaksi manusia-mesin, pemantauan siswa yang mengambil kursus online, perangkat yang dapat dipakai, dll.
Tahun ini, MDG mendedikasikan sekolah pembelajaran mesin musim panasnya untuk topik ini. Dalam artikel ini saya akan mencoba memberikan perjalanan singkat ke masalah mengenali keadaan emosional seseorang dan menceritakan tentang pendekatan untuk solusinya.
Apa itu emosi?
Emosi adalah jenis proses mental khusus yang mengungkapkan pengalaman seseorang tentang hubungannya dengan dunia dan dirinya sendiri. Menurut salah satu teori, penulisnya adalah ahli fisiologi Rusia P.K. Anokhin, kemampuan untuk mengalami emosi dikembangkan dalam proses evolusi sebagai cara adaptasi makhluk hidup yang lebih sukses dengan kondisi keberadaan. Emosi bermanfaat untuk bertahan hidup dan memungkinkan makhluk hidup dengan cepat dan paling ekonomis merespons pengaruh eksternal.
Emosi memainkan peran besar dalam kehidupan manusia dan komunikasi antarpribadi. Mereka dapat diekspresikan dengan berbagai cara: ekspresi wajah, postur, reaksi motorik, suara dan reaksi otonom (denyut jantung, tekanan darah, laju pernapasan). Namun, wajah orang tersebut paling ekspresif.
Setiap orang mengekspresikan emosi dengan beberapa cara berbeda. Psikolog Amerika terkenal Paul Ekman , yang mempelajari perilaku non-verbal dari suku-suku terasing di Papua Nugini pada tahun 70-an abad terakhir, menemukan bahwa sejumlah emosi, yaitu: kemarahan, ketakutan, kesedihan, jijik, jijik, kejutan, dan kegembiraan adalah universal dan dapat universal untuk dipahami oleh manusia, terlepas dari budayanya.
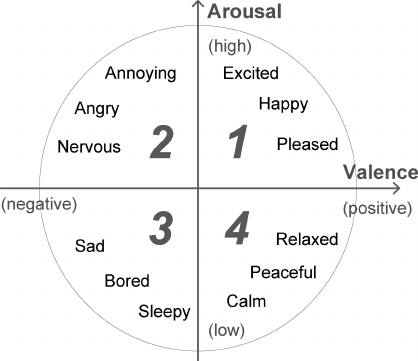
Orang dapat mengekspresikan berbagai macam emosi. Dipercayai bahwa keduanya dapat digambarkan sebagai kombinasi emosi-emosi dasar (misalnya, nostalgia adalah sesuatu antara kesedihan dan sukacita). Tetapi pendekatan kategoris semacam itu tidak selalu nyaman, karena tidak memungkinkan untuk mengukur kekuatan emosi. Oleh karena itu, bersama dengan model emosi yang terpisah, sejumlah yang terus menerus dikembangkan. Model J. Russell memiliki basis dua dimensi di mana setiap emosi ditandai oleh tanda (valensi) dan intensitas (gairah). Karena kesederhanaannya, model Russell baru-baru ini menjadi semakin populer dalam konteks tugas mengklasifikasikan ekspresi wajah secara otomatis.
Jadi, kami mengetahui bahwa jika Anda tidak berusaha menyembunyikan rangsangan emosional, maka keadaan Anda saat ini dapat diperkirakan dengan ekspresi wajah. Selain itu, dengan menggunakan prestasi modern di bidang pembelajaran yang mendalam, bahkan dimungkinkan untuk membangun pendeteksi kebohongan berdasarkan seri “Lie to me”, dasar ilmiah yang secara langsung disediakan oleh Paul Ekman. Namun, tugas ini jauh dari sederhana. Seperti yang ditunjukkan oleh penelitian oleh ahli saraf, Lisa Feldman Barrett, ketika mengenali emosi, seseorang secara aktif menggunakan informasi kontekstual: suara, tindakan, situasi. Lihatlah foto-foto di bawah ini, sungguh. Hanya menggunakan area wajah, tidak mungkin membuat prediksi yang benar. Dalam hal ini, untuk mengatasi masalah ini, perlu menggunakan modalitas tambahan dan informasi tentang perubahan sinyal dari waktu ke waktu.

Di sini kita akan mempertimbangkan pendekatan untuk analisis hanya dua modalitas: audio dan video, karena sinyal-sinyal ini dapat diperoleh dengan cara non-kontak. Untuk mendekati tugas, Anda harus terlebih dahulu mendapatkan data. Berikut adalah daftar database emosi terbesar yang tersedia untuk umum yang saya tahu. Gambar dan video dalam database ini ditandai secara manual, beberapa menggunakan Amazon Mechanical Turk.
Pendekatan klasik untuk klasifikasi emosi
Cara termudah untuk menentukan emosi dari gambar wajah didasarkan pada klasifikasi titik-titik kunci (landmark wajah), koordinat yang dapat diperoleh dengan menggunakan berbagai algoritma PDM , CML , AAM , DPM atau CNN . Biasanya menandai dari 5 hingga 68 poin, mengikatnya ke posisi alis, mata, bibir, hidung, rahang, yang memungkinkan Anda untuk menangkap sebagian ekspresi wajah. Koordinat titik yang dinormalisasi dapat langsung diserahkan ke pengklasifikasi (misalnya, SVM atau Hutan Acak) dan mendapatkan solusi dasar. Secara alami, posisi orang harus disejajarkan.
Penggunaan sederhana koordinat tanpa komponen visual menyebabkan hilangnya informasi bermanfaat yang signifikan, oleh karena itu, berbagai deskriptor dihitung pada titik-titik ini untuk meningkatkan sistem: LBP , HOG , SIFT , LATCH , dll. Setelah deskriptor digabungkan dan dimensi dikurangi menggunakan PCK, vektor fitur yang dihasilkan dapat digunakan untuk klasifikasi emosi.
tautan ke artikel
Namun, pendekatan ini sudah dianggap usang, karena diketahui bahwa jaringan konvolusi yang dalam adalah pilihan terbaik untuk analisis data visual.
Klasifikasi emosi menggunakan pembelajaran yang mendalam
Untuk membangun pengklasifikasi jaringan saraf, cukup untuk mengambil beberapa jaringan dengan arsitektur dasar, yang sebelumnya dilatih di ImageNet, dan melatih kembali beberapa lapisan terakhir. Jadi Anda bisa mendapatkan solusi dasar yang baik untuk mengklasifikasikan berbagai data, tetapi dengan mempertimbangkan spesifikasi tugas, jaringan saraf yang digunakan untuk tugas pengenalan wajah skala besar akan lebih cocok.
Jadi, cukup mudah untuk membangun penggolong emosi untuk gambar individual, tetapi seperti yang kami ketahui, foto tidak cukup akurat mencerminkan emosi sebenarnya yang dialami seseorang dalam situasi tertentu. Oleh karena itu, untuk meningkatkan akurasi sistem, perlu menganalisis urutan frame. Ada dua cara untuk melakukan ini. Cara pertama adalah memberi makan fitur tingkat tinggi yang diterima dari CNN yang mengklasifikasikan setiap frame individu ke dalam jaringan berulang (mis., LSTM) untuk menangkap komponen waktu.
tautan ke artikel
Cara kedua adalah secara langsung mengumpankan urutan frame yang diambil dari video dalam beberapa langkah ke input 3D-CNN. CNN serupa menggunakan konvolusi dengan tiga derajat kebebasan yang mengubah input empat dimensi menjadi peta fitur tiga dimensi.
tautan ke artikel
Bahkan, dalam kasus umum, dua pendekatan ini dapat dikombinasikan dengan membangun monster seperti itu.
tautan ke artikel
Klasifikasi emosi ujaran
Berdasarkan data visual, tanda emosi dapat diprediksi dengan akurasi tinggi, tetapi lebih baik menggunakan sinyal ucapan saat menentukan intensitas. Menganalisis audio sedikit lebih sulit karena variabilitas durasi bicara dan suara speaker yang tinggi. Biasanya, mereka tidak menggunakan gelombang suara asli, tetapi berbagai set atribut , misalnya: F0, MFCC, LPC, i-vektor, dll. Dalam masalah mengenali emosi melalui ucapan, perpustakaan terbuka OpenSMILE memiliki reputasi yang baik . Ini berisi serangkaian algoritma yang kaya untuk menganalisis pidato dan musikal sinyal. Setelah ekstraksi, atribut dapat diserahkan ke SVM atau LSTM untuk klasifikasi.
Baru-baru ini, bagaimanapun, jaringan saraf convolutional juga telah mulai menembus bidang analisis suara, menggeser pendekatan yang ditetapkan. Untuk menerapkannya, suara direpresentasikan dalam bentuk spektogram dalam skala linier atau mel, setelah itu dioperasikan dengan spektogram yang diperoleh seperti halnya gambar dua dimensi biasa. Dalam hal ini, masalah ukuran spektogram yang berubah-ubah sepanjang sumbu waktu diselesaikan secara elegan menggunakan pengumpulan statistik atau dengan memasukkan jaringan berulang dalam arsitektur.
tautan ke artikel
Pengenalan emosi secara audiovisual
Jadi, kami memeriksa sejumlah pendekatan untuk analisis modalitas audio dan video, tahap terakhir tetap - kombinasi pengklasifikasi untuk menghasilkan solusi akhir. Cara paling sederhana adalah menggabungkan peringkat mereka secara langsung. Dalam hal ini, cukup untuk mengambil maksimum atau rata-rata. Opsi yang lebih sulit adalah menggabungkan pada tingkat penanaman untuk setiap modalitas. SVM sering digunakan untuk ini, tetapi ini tidak selalu benar, karena embeddings dapat memiliki tingkat yang berbeda. Dalam hal ini, algoritma yang lebih maju dikembangkan, misalnya: Multiple Kernel Learning dan ModDrop .
Dan tentu saja, ada baiknya menyebutkan kelas solusi end-to-end yang dapat dilatih langsung pada data mentah dari beberapa sensor tanpa pemrosesan awal.
Secara umum, tugas pengenalan emosi secara otomatis masih jauh dari diselesaikan. Menilai dari hasil Pengakuan Emosi tahun lalu di kontes Wild, solusi terbaik mencapai akurasi sekitar 60%. Saya berharap bahwa informasi yang disajikan dalam artikel ini akan cukup untuk mencoba membangun sistem kita sendiri untuk mengenali emosi.