Kami sudah menulis di
artikel pertama dari blog perusahaan kami tentang bagaimana algoritma untuk mendeteksi pinjaman yang dapat ditransfer bekerja. Hanya beberapa paragraf dalam artikel yang dikhususkan untuk topik membandingkan teks, meskipun gagasan itu layak mendapatkan deskripsi yang jauh lebih terperinci. Namun, seperti yang Anda tahu, seseorang tidak dapat langsung menceritakan tentang segalanya, meskipun ia benar-benar ingin. Dalam upaya untuk membayar upeti pada topik ini dan arsitektur jaringan yang disebut "
auto-encoder ", yang kami punya perasaan yang sangat hangat,
Oleg_Bakhteev dan saya menulis tinjauan ini.

Sumber:
Deep Learning for NLP (tanpa Magic)Seperti yang kami sebutkan di artikel itu, perbandingan teks adalah "semantik" - kami tidak membandingkan fragmen teks itu sendiri, tetapi vektor yang bersesuaian dengannya. Vektor tersebut diperoleh sebagai hasil dari pelatihan jaringan saraf, yang menampilkan fragmen teks dengan panjang sewenang-wenang menjadi vektor dari dimensi besar tetapi tetap. Cara mendapatkan pemetaan seperti itu dan cara mengajar jaringan untuk menghasilkan hasil yang diinginkan adalah masalah terpisah, yang akan dibahas di bawah ini.
Apa itu pembuat enkode otomatis?
Secara formal, jaringan saraf disebut auto-encoder (atau auto-encoder), yang melatih untuk mengembalikan objek yang diterima pada input jaringan.
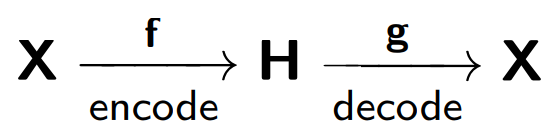
Auto-encoder terdiri dari dua bagian: sebuah encoder
f , yang mengkodekan sampel
X ke representasi internal
H , dan decoder
g , yang mengembalikan sampel asli. Dengan demikian, autocoder mencoba untuk menggabungkan versi yang dipulihkan dari setiap objek sampel dengan objek asli.
Saat melatih encoder otomatis, fungsi berikut ini diminimalkan:
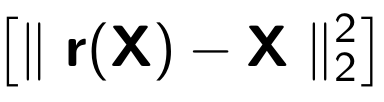
Di mana
r berarti versi objek asli yang dipulihkan:

Perhatikan contoh yang disediakan di
blog.keras.io :

Jaringan menerima objek
x sebagai input (dalam kasus kami, nomor 2).
Jaringan kami menyandikan objek ini ke keadaan tersembunyi. Kemudian, menurut keadaan laten, rekonstruksi objek
r dikembalikan, yang harus sama dengan x. Seperti yang kita lihat, gambar yang dipulihkan (di sebelah kanan) menjadi lebih buram. Ini dijelaskan oleh fakta bahwa kami mencoba untuk tetap dalam pandangan tersembunyi hanya tanda-tanda paling penting dari objek, sehingga objek dikembalikan dengan kerugian.
Model auto-encoder dilatih berdasarkan prinsip telepon yang rusak, di mana satu orang (encoder) mentransmisikan informasi
(x ) ke orang kedua (decoder
) , dan dia, pada gilirannya, memberi tahu dia kepada orang ketiga
(r (x)) .
Salah satu tujuan utama dari auto-encoders adalah untuk mengurangi dimensi ruang sumber. Ketika kita berhadapan dengan auto-encoders, prosedur pelatihan jaringan saraf itu sendiri membuat auto-encoder mengingat fitur-fitur utama dari objek yang akan lebih mudah untuk mengembalikan objek sampel asli.
Di sini kita dapat menggambar analogi dengan
metode komponen utama : ini adalah metode pengurangan dimensi, yang hasilnya adalah proyeksi sampel ke subruang di mana varians sampel ini maksimum.
Memang, auto-encoder adalah generalisasi dari metode komponen utama: dalam kasus ketika kita membatasi diri kita pada pertimbangan model linier, auto-encoder dan metode komponen utama memberikan representasi vektor yang sama. Perbedaan muncul ketika kita mempertimbangkan model yang lebih kompleks, misalnya, jaringan saraf multilayer sepenuhnya terhubung, sebagai encoder dan decoder.
Contoh perbandingan metode komponen utama dan auto-encoder disajikan dalam artikel
Mengurangi Dimensi Data dengan Jaringan Saraf Tiruan :
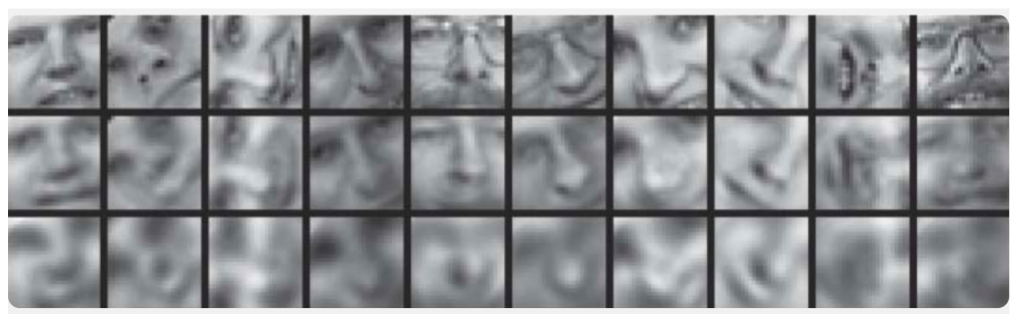
Di sini, hasil pelatihan auto-encoder dan metode komponen utama untuk pengambilan sampel gambar wajah manusia ditunjukkan. Baris pertama menunjukkan wajah orang-orang dari sampel kontrol, mis. dari bagian yang ditangguhkan khusus dari sampel yang tidak digunakan oleh algoritma dalam proses pembelajaran. Pada baris kedua dan ketiga adalah gambar yang dipulihkan dari keadaan tersembunyi auto-encoder dan metode komponen utama, masing-masing, dari dimensi yang sama. Di sini Anda dapat melihat dengan jelas seberapa baik auto-encoder bekerja.
Dalam artikel yang sama, contoh ilustratif lain: membandingkan hasil auto-encoder dan metode
LSA untuk tugas pencarian informasi. Metode LSA, seperti metode komponen utama, adalah metode pembelajaran mesin klasik dan sering digunakan dalam tugas yang berkaitan dengan pemrosesan bahasa alami.

Gambar tersebut menunjukkan proyeksi 2D dari beberapa dokumen yang diperoleh menggunakan metode auto-encoder dan LSA. Warna menunjukkan tema dokumen. Dapat dilihat bahwa proyeksi dari auto-encoder memecah dokumen berdasarkan topik dengan baik, sedangkan LSA menghasilkan hasil yang jauh lebih berisik.
Aplikasi penting lain dari auto-
encoders adalah pra-pelatihan jaringan . Pra-pelatihan jaringan digunakan ketika jaringan yang dioptimalkan cukup dalam. Dalam hal ini, melatih jaringan "dari awal" bisa sangat sulit, oleh karena itu, pertama-tama seluruh jaringan direpresentasikan sebagai rantai pembuat enkode.
Algoritma pra-pelatihan cukup sederhana: untuk setiap layer kita melatih auto-encoder kita sendiri, dan kemudian kita menetapkan bahwa output dari encoder berikutnya secara bersamaan merupakan input untuk lapisan jaringan berikutnya. Model yang dihasilkan terdiri dari rantai enkode yang dilatih untuk mempertahankan fitur objek yang paling penting, masing-masing pada lapisannya sendiri. Skema pra-pelatihan disajikan di bawah ini:
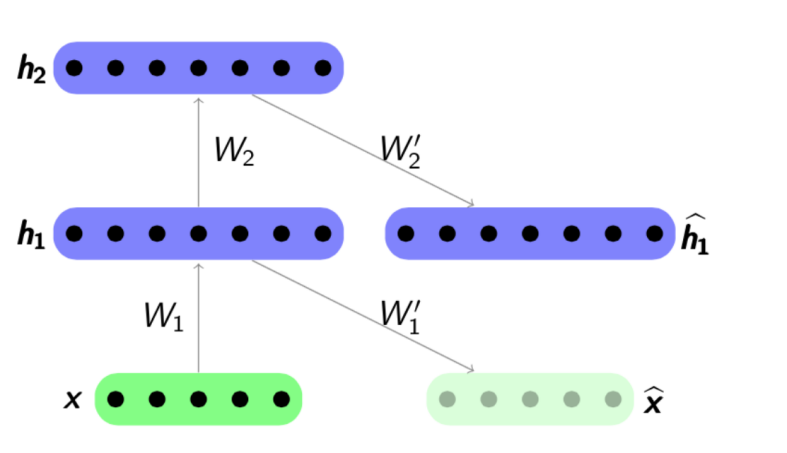
Sumber:
psyyz10.imtqy.comStruktur ini disebut Stenced Autoencoder dan sering digunakan sebagai "overclocking" untuk lebih lanjut melatih model jaringan penuh dalam. Motivasi untuk pelatihan jaringan saraf seperti itu adalah bahwa jaringan saraf yang dalam adalah fungsi non-cembung: dalam proses pelatihan jaringan, optimalisasi parameter dapat "terjebak" dalam minimum lokal. Pra-pelatihan yang serakah terhadap parameter jaringan memungkinkan Anda menemukan titik awal yang baik untuk pelatihan terakhir dan dengan demikian mencoba menghindari minimum lokal semacam itu.
Tentu saja, kami tidak mempertimbangkan semua struktur yang mungkin, karena ada
Autoencoder Jarang ,
Autoencoder Denoising ,
Autoencoder Kontraktif ,
Autoencoder Kontraktif Rekonstruksi . Mereka berbeda di antara mereka sendiri dengan menggunakan berbagai fungsi kesalahan dan ketentuan hukuman kepada mereka. Semua arsitektur ini, menurut pendapat kami, pantas mendapatkan ulasan terpisah. Dalam artikel kami, kami menunjukkan, pertama-tama, konsep umum auto-encoders dan tugas-tugas khusus dari analisis teks yang diselesaikan dengan menggunakannya.
Bagaimana cara kerjanya dalam teks?
Kami sekarang beralih ke contoh spesifik penggunaan autocoder untuk tugas analisis teks. Kami tertarik pada kedua sisi aplikasi - kedua model untuk memperoleh representasi internal, dan penggunaan representasi internal ini sebagai atribut, misalnya, dalam masalah klasifikasi lebih lanjut. Artikel-artikel tentang topik ini paling sering menyentuh tugas-tugas seperti analisis sentimen atau deteksi ulang kata-kata, tetapi ada juga karya yang menggambarkan penggunaan auto-encoders untuk membandingkan teks dalam bahasa yang berbeda atau untuk terjemahan mesin.
Dalam tugas analisis teks, objek yang paling sering adalah kalimat, mis. urutan kata yang dipesan. Jadi, auto-encoder menerima urutan kata-kata ini dengan tepat, atau lebih tepatnya, representasi vektor dari kata-kata ini yang diambil dari beberapa model yang dilatih sebelumnya. Apa representasi vektor kata, itu dianggap pada Habré dalam detail yang cukup, misalnya di
sini . Dengan demikian, auto-encoder, mengambil urutan kata-kata sebagai input, harus melatih beberapa representasi internal dari seluruh kalimat yang memenuhi karakteristik yang penting bagi kami, berdasarkan pada tugas. Dalam masalah analisis teks, kita perlu memetakan kalimat ke vektor sehingga mereka dekat dalam arti beberapa fungsi jarak, paling sering merupakan ukuran kosinus:
Sumber:
Deep Learning for NLP (tanpa Magic)Salah satu penulis pertama yang menunjukkan keberhasilan penggunaan auto-encoders dalam analisis teks adalah
Richard Socher .
Dalam artikelnya
Dynamic Pooling dan Unfolding Recursive Autoencoder untuk Paraphrase Detection, ia menjelaskan struktur autocoding baru - Unfolding Recursive Autoencoder (Unfolding RAE) (lihat gambar di bawah).

Membuka RAE
Diasumsikan bahwa struktur kalimat didefinisikan oleh
parser sintaksis . Struktur paling sederhana dianggap - struktur pohon biner. Pohon seperti itu terdiri dari dedaunan - kata-kata dari sebuah fragmen, simpul internal (simpul cabang) —fase, dan simpul terminal. Mengambil urutan kata-kata (x
1 , x
2 , x
3 ) sebagai input (tiga representasi vektor kata dalam contoh ini), auto-encoder secara berurutan mengkodekan, dalam hal ini, dari kanan ke kiri, representasi vektor dari kata-kata kalimat menjadi representasi vektor dari kolokasi, dan kemudian menjadi vektor Presentasi seluruh penawaran. Khususnya dalam contoh ini, pertama-tama kita menggabungkan vektor x
2 dan x
3 , kemudian mengalikannya dengan matriks
W yang memiliki dimensi
tersembunyi × 2 tidak terlihat , di mana
tersembunyi adalah di mana ukuran representasi internal yang tersembunyi,
terlihat adalah dimensi dari kata vektor. Jadi, kita mengurangi dimensi, lalu menambahkan non-linearitas menggunakan fungsi tanh. Pada langkah pertama, kita mendapatkan representasi vektor tersembunyi untuk frasa dua kata
x 2 dan
x 3 :
h 1 =
tanh (W e [x 2 , x 3 ] + b e ) . Pada yang kedua, kita menggabungkannya dan kata yang tersisa
h 2 =
tanh (W e [h1, x 1 ] + b e ) dan mendapatkan representasi vektor untuk seluruh kalimat -
h 2 . Seperti disebutkan di atas, dalam definisi auto-encoder, kita perlu meminimalkan kesalahan antara objek dan versi yang dipulihkan. Dalam kasus kami, ini adalah kata-kata. Oleh karena itu, setelah menerima representasi vektor akhir dari seluruh kalimat
h 2 , kami akan mendekode versinya yang dipulihkan (x
1 ', x
2 ', x
3 '). Dekoder di sini bekerja dengan prinsip yang sama dengan pembuat enkode, hanya matriks parameter dan vektor shift yang berbeda di sini:
W d dan
b d .
Dengan menggunakan struktur pohon biner, Anda dapat menyandikan kalimat dengan panjang apa pun ke dalam vektor dimensi tetap - kami selalu menggabungkan sepasang vektor dari dimensi yang sama, menggunakan matriks parameter
W yang sama . Dalam kasus pohon non-biner, Anda hanya perlu menginisialisasi matriks terlebih dahulu jika kami ingin menggabungkan lebih dari dua kata - 3, 4, ... n, dalam hal ini matriks hanya akan memiliki dimensi
tersembunyi × tidak terlihat .
Perlu dicatat bahwa dalam artikel ini, representasi vektor terlatih dari frasa digunakan tidak hanya untuk menyelesaikan masalah klasifikasi - beberapa kalimat diulang atau tidak. Data percobaan tentang pencarian tetangga terdekat juga disajikan - hanya berdasarkan vektor tawaran yang diterima, vektor terdekat dalam sampel dicari yang dekat dengan artinya:

Namun, tidak ada yang mengganggu kita untuk menggunakan arsitektur jaringan lain untuk penyandian dan pengodean kata untuk menggabungkan kata-kata menjadi kalimat.
Berikut adalah contoh dari artikel NIPS 2017 -
Pembelajaran Representasi Paragraf Dekonvolusional :

Kita melihat bahwa pengkodean sampel
X ke dalam representasi tersembunyi
h terjadi menggunakan
jaringan saraf convolutional , dan dekoder bekerja pada prinsip yang sama.
Atau di sini adalah contoh menggunakan
GRU-GRU dalam artikel
Skip-Thought Vectors .
Fitur yang menarik di sini adalah bahwa model ini bekerja dengan tiga kali lipat kalimat: (
s i-1 , s i , s i + 1 ). Kalimat
s i dikodekan menggunakan rumus GRU standar, dan dekoder, menggunakan informasi representasi internal
s i , mencoba memecahkan kode
s i-1 dan
s i +1 , juga menggunakan GRU.

Prinsip operasi dalam hal ini menyerupai model standar
terjemahan mesin jaringan saraf , yang bekerja sesuai dengan skema encoder-decoder. Namun, di sini kami tidak memiliki dua bahasa, kami mengirimkan frasa dalam satu bahasa ke input unit pengkodean kami dan mencoba mengembalikannya. Dalam proses pembelajaran, ada minimalisasi beberapa fungsional kualitas internal (ini tidak selalu kesalahan rekonstruksi), maka, jika diperlukan, vektor pra-terlatih digunakan sebagai fitur dalam masalah lain.
Makalah lain,
Autoencoder Rekursif Bilingual Correspondence untuk Terjemahan Mesin Statistik , menyajikan arsitektur yang mengambil pandangan segar pada terjemahan mesin. Pertama, untuk dua bahasa, autocoder rekursif dilatih secara terpisah (sesuai dengan prinsip yang dijelaskan di atas - di mana Unfolding RAE diperkenalkan). Kemudian, di antara mereka, sebuah auto-encoder ketiga dilatih - pemetaan antara dua bahasa. Arsitektur seperti itu memiliki keuntungan yang jelas - ketika menampilkan teks dalam berbagai bahasa ke dalam satu ruang tersembunyi yang umum, kita dapat membandingkannya tanpa menggunakan terjemahan mesin sebagai langkah perantara.
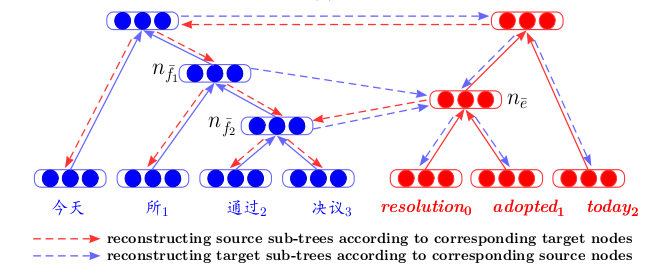
Pelatihan auto-encoders pada fragmen teks sering ditemukan dalam artikel tentang
pelatihan peringkat . Di sini, sekali lagi, fakta bahwa kita sedang melatih fungsional akhir dari kualitas peringkat adalah penting, pertama-tama kita melatih trainer-otomatis untuk menginisialisasi vektor permintaan dan tanggapan yang lebih baik yang dikirimkan ke input jaringan.

Dan, tentu saja, kita tidak bisa tidak menyebut
Varietas Autoencoder , atau
VAE , sebagai model generatif. Yang terbaik, tentu saja, hanya menonton
entri kuliah ini dari Yandex . Sudah cukup bagi kita untuk mengatakan yang berikut: jika kita ingin
menghasilkan objek dari ruang tersembunyi dari auto-encoder konvensional, maka kualitas generasi tersebut akan rendah, karena kita tidak tahu apa-apa tentang distribusi variabel tersembunyi. Tetapi Anda dapat segera melatih pembuat enkode otomatis untuk menghasilkan, memperkenalkan asumsi distribusi.
Dan kemudian, menggunakan VAE, Anda dapat menghasilkan teks dari ruang tersembunyi ini, misalnya, seperti yang dilakukan penulis artikel
Menghasilkan Kalimat dari Ruang Kontinu atau
Autoencoder Variabel Konvolusional Hibrid untuk Pembuatan Teks .
Properti generatif dari VAE juga bekerja dengan baik dalam tugas membandingkan teks dalam bahasa yang berbeda -
Pendekatan Variasi Autoencoding untuk Menginduksi Penyesuaian Kata Lintas Bahasa adalah contoh yang bagus untuk ini.
Sebagai kesimpulan, kami ingin membuat perkiraan kecil.
Representasi Pembelajaran - pelatihan dalam representasi internal yang menggunakan VAE tepat, terutama dalam hubungannya dengan
Generative Adversarial Networks , adalah salah satu pendekatan yang paling berkembang dalam beberapa tahun terakhir - ini dapat dinilai dengan setidaknya topik paling umum dari artikel di
konferensi pembelajaran mesin
ICLR 2018 terbaru. dan
ICML 2018 . Ini cukup logis - karena penggunaannya telah membantu meningkatkan kualitas dalam sejumlah tugas, dan tidak hanya terkait dengan teks. Tapi ini adalah topik ulasan yang sama sekali berbeda ...