Institut Teknologi Massachusetts. Kursus Kuliah # 6.858. "Keamanan sistem komputer." Nikolai Zeldovich, James Mickens. Tahun 2014
Keamanan Sistem Komputer adalah kursus tentang pengembangan dan implementasi sistem komputer yang aman. Ceramah mencakup model ancaman, serangan yang membahayakan keamanan, dan teknik keamanan berdasarkan pada karya ilmiah baru-baru ini. Topik meliputi keamanan sistem operasi (OS), fitur, manajemen aliran informasi, keamanan bahasa, protokol jaringan, keamanan perangkat keras, dan keamanan aplikasi web.
Kuliah 1: “Pendahuluan: model ancaman”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 2: "Kontrol serangan hacker"
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 3: “Buffer Overflows: Exploits and Protection”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 4: “Pemisahan Hak Istimewa”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 5: "Dari mana sistem keamanan berasal?"
Bagian 1 /
Bagian 2Kuliah 6: “Peluang”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 7: “Kotak Pasir Klien Asli”
Bagian 1 /
Bagian 2 /
Bagian 3 Audiens: mengapa rentang kapasitas memori rentang alamat mulai dari awal?
Profesor: karena dalam hal kinerja, lebih efisien untuk menggunakan lompatan target jika Anda tahu bahwa alamat yang valid adalah kumpulan alamat yang berkelanjutan mulai dari nol. Karena dengan begitu Anda dapat melakukannya dengan masker
AND tunggal, di mana semua bit tinggi adalah satu dan hanya sepasang bit rendah adalah nol.
Hadirin: Saya pikir topeng
AND seharusnya memberikan perataan.
Profesor: benar, topeng memberikan pelurusan, tetapi mengapa itu dimulai dari awal? Saya pikir mereka mengandalkan perangkat keras
Segmentasi Hardware . Jadi pada dasarnya, mereka bisa menggunakannya untuk memindahkan area ke atas, dalam hal ruang linear. Atau mungkin itu hanya terkait dengan bagaimana aplikasi "melihat" kisaran ini. Bahkan, Anda bisa meletakkannya di offset berbeda di ruang alamat virtual Anda. Ini akan memungkinkan Anda untuk melakukan trik tertentu dengan perangkat keras tersegmentasi untuk menjalankan beberapa modul dalam ruang alamat yang sama.
 Hadirin:
Hadirin: Mungkin ini karena mereka ingin "menangkap" titik penerima nol itu?
Profesor: ya, karena mereka ingin menangkap semua poin penerimaan. Tetapi Anda memiliki cara untuk melakukannya. Karena null pointer merujuk ke segmen yang sedang diakses. Dan jika Anda memindahkan segmen, Anda dapat menampilkan halaman nol yang tidak digunakan di awal setiap segmen. Jadi ini akan membantu membuat beberapa modul.
Saya pikir salah satu alasan untuk keputusan ini - untuk memulai rentang dari 0 - adalah karena keinginan mereka untuk port program mereka ke platform
x64 , yang memiliki desain yang sedikit berbeda. Tetapi artikel mereka tidak mengatakan ini. Dalam desain 64-bit, peralatan itu sendiri menyingkirkan beberapa perangkat keras segmentasi, yang mereka andalkan karena alasan efisiensi, sehingga mereka harus menyediakan pendekatan berorientasi perangkat lunak. Namun, untuk
x32 ini masih bukan alasan yang bagus untuk ruang untuk memulai dari awal.
Jadi, kami melanjutkan pertanyaan utama - apa yang ingin kami pastikan dari sudut pandang keamanan. Mari kita mendekati masalah ini dengan agak “naif” dan melihat bagaimana kita dapat merusak segalanya, dan kemudian mencoba memperbaikinya.
Saya percaya bahwa rencana naif adalah mencari instruksi terlarang dengan hanya memindai yang dapat dieksekusi dari awal sampai akhir. Jadi bagaimana Anda bisa melihat instruksi ini? Anda cukup mengambil kode program dan meletakkannya di garis raksasa yang bergerak dari nol hingga 256 megabita, tergantung pada seberapa besar kode Anda, dan kemudian mulai pencarian.

Baris ini pertama-tama dapat berisi modul instruksi
NOP , kemudian modul instruksi
ADD ,
NOT ,
JUMP, dan sebagainya. Anda hanya mencari, dan jika Anda menemukan instruksi yang buruk, maka katakan bahwa itu adalah modul yang buruk dan buanglah. Dan jika Anda tidak melihat panggilan sistem ke instruksi ini, maka Anda dapat mengaktifkan peluncuran modul ini dan melakukan semuanya dalam kisaran 0-256. Apakah Anda pikir ini akan berhasil atau tidak? Apa yang mereka khawatirkan? Mengapa begitu sulit?
Hadirin: Apakah mereka khawatir tentang ukuran instruksi?
Profesor: ya, kenyataannya adalah platform
x86 memiliki instruksi panjang variabel. Ini berarti bahwa ukuran persis dari instruksi tergantung pada beberapa byte pertama dari instruksi ini. Bahkan, Anda dapat melihat byte pertama untuk mengatakan bahwa instruksi akan jauh lebih besar, dan kemudian Anda mungkin harus melihat beberapa byte lagi, dan kemudian memutuskan ukuran apa yang diperlukan. Beberapa arsitektur seperti
Spark ,
ARM ,
MIPS memiliki lebih banyak instruksi dengan panjang tetap.
ARM memiliki dua panjang instruksi - baik 2 atau 4 byte. Tetapi pada platform
x86, panjang instruksi bisa 1, 5, dan 10 byte, dan jika Anda mencoba, Anda bahkan bisa mendapatkan instruksi yang agak panjang 15 byte. Namun, ini adalah instruksi yang rumit.
Akibatnya, masalah dapat muncul. Jika Anda memindai baris kode ini secara linear, semuanya akan baik-baik saja. Tapi mungkin saat runtime Anda akan pergi ke tengah-tengah semacam instruksi, misalnya,
TIDAK .

Ada kemungkinan bahwa ini adalah instruksi multibyte, dan jika Anda menafsirkannya mulai dari byte kedua, maka itu akan terlihat sangat berbeda.
Contoh lain di mana kita akan "bermain" dengan assembler. Misalkan kita memiliki instruksi
25 CD 80 00 00 . Setelah melihat byte ke-2, Anda akan mengartikannya sebagai instruksi lima-byte, yaitu, Anda harus melihat pada 5 byte ke depan dan melihat bahwa itu diikuti oleh instruksi
AND% EAX, 0x00 00 80 CD , dimulai dengan operator
AND untuk register
EAX dengan beberapa konstanta yang didefinisikan, misalnya,
00 00 80 CD . Ini adalah salah satu instruksi aman yang seharusnya diizinkan oleh
Klien Asli dengan aturan pertama memeriksa instruksi biner. Tetapi jika, selama pelaksanaan program,
CPU memutuskan bahwa ia harus mulai mengeksekusi kode dari
CD , saya akan menandai tempat instruksi ini dengan panah, maka instruksi
% EAX, 0x00 00 80 CD , yang sebenarnya merupakan instruksi 4-byte, akan berarti eksekusi
INT $ 0x80 , yang merupakan cara untuk membuat panggilan sistem di
Linux .
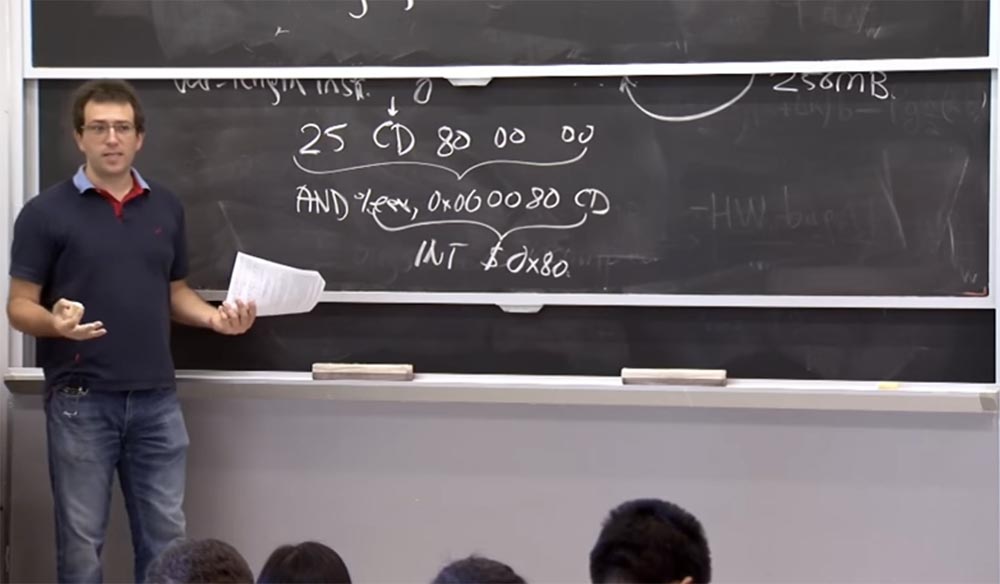
Jadi jika Anda melewatkan fakta ini, maka biarkan modul yang tidak dapat diandalkan "melompat" ke dalam kernel dan melakukan panggilan sistem, yaitu, lakukan apa yang ingin Anda cegah. Bagaimana kita bisa menghindari ini?
Mungkin kita harus mencoba melihat offset dari setiap byte. Karena x86 hanya dapat mulai menafsirkan instruksi dalam byte, bukan bit, batas. Jadi, Anda harus melihat offset masing-masing byte untuk melihat di mana instruksi dimulai. Apakah Anda pikir ini adalah rencana yang layak?
Pemirsa: Saya pikir jika seseorang benar-benar menggunakan
DAN , prosesor tidak akan melompat ke tempat ini, tetapi cukup biarkan program berjalan.
Profesor: ya, karena pada dasarnya dia tidak rentan terhadap kesalahan positif. Sekarang, jika Anda benar-benar menginginkannya, Anda dapat mengubah sedikit kode untuk menghindarinya. Jika Anda tahu persis apa yang dicari perangkat uji, Anda berpotensi mengubah instruksi ini. Mungkin dengan mengatur
DAN pertama untuk satu instruksi, dan kemudian menggunakan topeng di instruksi lainnya. Tetapi jauh lebih mudah untuk menghindari pengaturan byte yang mencurigakan ini, meskipun ini agak tidak nyaman.
Mungkin saja arsitektur menyertakan perubahan kompiler. Pada dasarnya, mereka memiliki beberapa jenis komponen yang sebenarnya perlu dikompilasi dengan benar. Anda tidak bisa hanya "melepas"
GCC dan mengkompilasi kode untuk
Native Client . Jadi pada dasarnya ini bisa dilakukan. Tetapi mungkin, mereka hanya berpikir bahwa itu menyebabkan terlalu banyak masalah, tidak akan menjadi solusi yang andal atau berkinerja tinggi, dan sebagainya. Plus, ada beberapa instruksi
x86 yang dilarang, atau harus dianggap tidak aman dan karenanya harus dilarang. Tetapi sebagian besar berukuran satu byte, jadi cukup sulit untuk menemukan atau memfilternya.
Karena itu, jika mereka tidak bisa hanya mengumpulkan dan menyortir instruksi yang tidak aman dan berharap yang terbaik, mereka perlu menggunakan rencana yang berbeda untuk membongkarnya dengan cara yang dapat diandalkan. Jadi, apa yang dilakukan
Klien Asli untuk memastikan mereka tidak "tersandung" pada pengodean panjang variabel ini?
Dalam arti tertentu, jika kita benar-benar memindai file yang dapat dieksekusi dari kiri ke kanan dan mencari semua kemungkinan kode yang salah, dan jika itu cara kode berjalan, maka kita dalam kondisi yang baik. Bahkan jika ada beberapa instruksi aneh dan beberapa bias, prosesor masih tidak akan "melompat" di sana, itu akan menjalankan program dalam urutan yang sama di mana instruksi dipindai, yaitu, dari kiri ke kanan.

Dengan demikian, masalah dengan pembongkaran yang andal muncul karena fakta bahwa di suatu tempat dalam aplikasi mungkin ada "melompat". Prosesor dapat gagal jika membuat "lompatan" ke beberapa instruksi kode yang tidak diperhatikan saat memindai dari kiri ke kanan. Jadi ini adalah masalah pembongkaran yang dapat diandalkan sejauh ini dalam pengembangan. Dan rencana utama adalah untuk memeriksa di mana semua "melompat" memimpin. Bahkan, ini cukup sederhana pada tingkat tertentu. Ada banyak aturan yang akan kami pertimbangkan dalam hitungan detik, tetapi rencana perkiraannya adalah jika Anda melihat instruksi "lompatan", Anda perlu memastikan bahwa tujuan "lompatan" tersebut diketahui sebelumnya. Untuk melakukan ini, sebenarnya, cukup dengan memindai dari kiri ke kanan, yaitu prosedur yang kami jelaskan dalam pendekatan naif kami terhadap masalah tersebut.
Dalam hal ini, jika Anda melihat instruksi "lompatan" dan alamat yang ditunjuk oleh instruksi ini, maka Anda harus memastikan bahwa ini adalah alamat yang sama dengan yang sudah Anda lihat selama pembongkaran dari kiri ke kanan.
Jika instruksi "lompatan" ke byte CD ini ditemukan, maka kita harus menandai lompatan ini sebagai tidak valid karena kita tidak pernah melihat instruksi dimulai pada byte CD, tetapi kita melihat instruksi lain dimulai dengan nomor 25. Tetapi jika semua instruksi lompatan diperintahkan untuk pergi ke awal instruksi, dalam hal ini ke 25, maka semuanya beres dengan kami. Apakah itu jelas?
Satu-satunya masalah adalah bahwa Anda tidak dapat memeriksa tujuan setiap lompatan dalam program, karena mungkin ada lompatan tidak langsung. Misalnya, di
x86 Anda mungkin memiliki sesuatu seperti lompatan ke nilai register
EAX ini. Ini bagus untuk mengimplementasikan fungsi pointer.

Artinya, penunjuk fungsi berada di suatu tempat di memori, Anda menahannya di beberapa register, dan kemudian pergi ke alamat apa pun di register gerakan.
Jadi, bagaimana orang-orang ini mengatasi lompatan tidak langsung? Karena, pada kenyataannya, saya tidak tahu apakah ini akan menjadi "lompatan" ke byte
CD atau ke byte 25. Apa yang mereka lakukan dalam kasus ini?
Pemirsa: menggunakan alat?
Profesor: ya, instrumentasi adalah trik utama mereka. Oleh karena itu, setiap kali mereka melihat bahwa kompiler siap untuk melakukan pembangkitan, ini adalah bukti bahwa lompatan ini tidak akan menyebabkan masalah. Untuk melakukan ini, mereka perlu memastikan bahwa semua lompatan dilakukan dengan banyak 32 byte. Bagaimana mereka melakukannya? Mereka mengubah semua instruksi lompatan menjadi apa yang mereka sebut "instruksi semu." Ini adalah instruksi yang sama, tetapi diawali, yang membersihkan 5 bit rendah dalam register
EAX . Fakta bahwa instruksi menghapus 5 bit rendah berarti bahwa itu menyebabkan nilai yang diberikan menjadi kelipatan 32, dari dua menjadi lima, dan kemudian lompatan ke nilai ini sudah dilakukan.

Jika Anda melihat ini selama verifikasi, pastikan bahwa "pasangan" instruksional ini akan "melompat" hanya dengan banyaknya 32 byte. Dan kemudian, untuk memastikan tidak ada kemungkinan "melompat" ke beberapa instruksi aneh, Anda menerapkan aturan tambahan. Terdiri dari fakta bahwa selama pembongkaran, ketika Anda melihat instruksi Anda dari kiri ke kanan, Anda memastikan bahwa awal setiap instruksi yang valid juga akan menjadi kelipatan 32 byte.
Dengan demikian, selain toolkit ini, Anda memverifikasi bahwa setiap kode yang merupakan kelipatan dari 32 adalah instruksi yang benar. Dengan instruksi yang valid dan valid, yang saya maksud adalah instruksi yang dibongkar dari kiri ke kanan.
Hadirin: Mengapa nomor 32 dipilih?
Profesor: ya, mengapa mereka memilih 32 bukannya 1000 atau 5? Mengapa 5 buruk?
Hadirin: karena angka itu haruslah kekuatan 2.
Profesor: ya, itu sebabnya. Karena sebaliknya, memastikan penggunaan sesuatu yang merupakan kelipatan 5 akan memerlukan instruksi tambahan yang mengarah ke overhead. Bagaimana dengan delapan? Apakah delapan angka yang cukup baik?
Hadirin: Anda mungkin memiliki instruksi lebih dari delapan bit.
Profesor: ya, ini mungkin untuk instruksi terpanjang yang diizinkan pada platform x86. Jika kami memiliki instruksi 10 byte, dan semuanya harus merupakan kelipatan 8, maka kami tidak dapat menyisipkannya di mana saja. Jadi panjangnya harus cukup untuk semua kasus, karena instruksi terbesar yang saya lihat adalah 15 byte. Jadi 32 byte sudah cukup.
Jika Anda ingin menyesuaikan instruksi untuk masuk atau keluar dari lingkungan layanan proses, Anda mungkin memerlukan sejumlah kode nontrivial dalam satu slot 32-byte. Misalnya, 31 byte, karena 1 byte berisi instruksi. Haruskah itu jauh lebih besar? Haruskah kita membuat ini sama dengan, katakanlah, 1024 byte? Jika Anda memiliki banyak fungsi pointer atau banyak lompatan tidak langsung, maka setiap kali Anda ingin membuat tempat di mana Anda akan melompat, Anda harus melanjutkannya ke perbatasan berikutnya, berapapun nilainya. Jadi dengan 32 bit itu ukuran yang cukup normal. Dalam skenario terburuk, Anda hanya akan kehilangan 31 byte jika Anda perlu dengan cepat mencapai perbatasan berikutnya. Tetapi jika Anda memiliki ukuran yang kelipatan 1024 byte, maka sangat mungkin untuk membuang seluruh kilobyte memori secara sia-sia untuk lompatan tidak langsung. Jika Anda memiliki fungsi pendek atau banyak fungsi pointer, ukuran besar dari banyaknya panjang "lompatan" akan menyebabkan pemborosan memori yang signifikan.
Saya tidak berpikir bahwa angka 32 adalah batu sandungan bagi
Klien Asli . Beberapa blok bisa bekerja dengan multiplisitas 16 bit, 64 atau 128 bit, itu tidak masalah. Bagi mereka, hanya 32 bit yang merupakan nilai optimal yang paling dapat diterima.
Jadi, mari kita buat rencana untuk pembongkaran yang andal. Akibatnya, kompilator harus sedikit berhati-hati ketika mengkompilasi
kode C atau
C ++ ke dalam biner
Native Client dan mematuhi aturan berikut.

Karena itu, setiap kali dia melompat, seperti yang ditunjukkan di baris atas, dia harus menambahkan instruksi tambahan yang diberikan di 2 baris terbawah. Dan terlepas dari kenyataan bahwa ia menciptakan fungsi yang akan ia "lompati", instruksi kami akan melompat sebagai tambahan
DAN $ 0xffffffe0,% eax menunjukkan. Dan itu tidak bisa hanya melengkapinya dengan nol, karena semua ini harus memiliki kode yang benar. Dengan demikian, penambahan diperlukan untuk memastikan bahwa setiap instruksi yang mungkin berlaku. Dan, untungnya, pada platform
x86 , tidak ada fungsi
noop tunggal dijelaskan oleh satu byte, atau setidaknya tidak ada ukuran
no 1 byte tunggal. Dengan demikian, Anda selalu dapat menambahkan sesuatu ke nilai konstanta.
Jadi apa yang ini menjamin kita? Mari kita pastikan bahwa kita selalu melihat apa yang terjadi dalam terminologi instruksi yang akan diikuti. Inilah yang diberikan aturan ini kepada kami - jaminan bahwa panggilan sistem tidak akan dilakukan secara tidak sengaja. Ini berlaku untuk lompatan, tetapi bagaimana dengan pengembalian? Bagaimana mereka menangani pengembalian? Bisakah kita
kembali ke fungsi di
Native Client ? Apa yang terjadi jika Anda menjalankan kode red-hot?
Pemirsa: Itu bisa meluap stack.
Profesor: memang benar muncul secara tidak terduga di tumpukan. Tetapi kenyataannya adalah bahwa tumpukan yang digunakan oleh modul
Native Client sebenarnya berisi beberapa data di dalamnya. Dengan demikian, ketika berhadapan dengan
Native Client, Anda tidak perlu khawatir tentang stack overflow.
Hadirin: tunggu, tetapi Anda dapat meletakkan apa pun di tumpukan. Dan ketika Anda melakukan lompatan tidak langsung.
Profesor: itu benar. Pengembalian terlihat hampir seperti lompatan tidak langsung dari suatu tempat di memori, yang terletak di bagian atas tumpukan. Oleh karena itu, saya berpikir bahwa satu hal yang bisa mereka lakukan untuk fungsi
pengembalian adalah dengan mengatur awalan dengan cara yang sama seperti pada pemeriksaan sebelumnya. Dan awalan ini memeriksa apa yang muncul di bagian atas tumpukan. Anda memeriksa apakah ini valid, dan ketika Anda menulis atau menggunakan operator
DAN , Anda memeriksa apa yang ada di bagian atas tumpukan. Ini tampaknya agak tidak dapat diandalkan karena perubahan data yang konstan. Karena, misalnya, jika Anda melihat bagian atas tumpukan dan memastikan semuanya baik-baik saja di sana, dan kemudian menulis sesuatu, aliran data dalam modul yang sama dapat memodifikasi sesuatu di bagian atas tumpukan, setelah itu Anda akan merujuk ke yang salah alamat
Hadirin: Apakah ini tidak berlaku untuk melompat ke tingkat yang sama?
Profesor: ya, jadi apa yang terjadi di sana dengan lompatan? Dapatkah kondisi balapan kita entah bagaimana membatalkan tes ini?
Hadirin: Tetapi apakah kodenya tidak dapat ditulis?
Profesor: ya, kode tidak dapat ditulis, ini benar. Karenanya, Anda tidak dapat memodifikasi AND. Tapi tidak bisakah aliran lain mengubah tujuan lompatan antara dua instruksi ini?
Pemirsa: ini ada dalam register, jadi ...
Profesor: Ya, ini adalah hal yang keren. Karena jika aliran memodifikasi sesuatu dalam memori atau dalam apa yang dimuat dari
EAX (tentu saja, Anda melakukannya sebelum mengunduh), dalam hal ini
EAX ini akan dalam keadaan buruk, tetapi kemudian akan menghapus bit yang buruk. Atau dia dapat mengubah memori setelah, ketika pointer sudah di
EAX , jadi tidak masalah bahwa itu mengubah lokasi memori dari mana register
EAX dimuat.
Bahkan, utas tidak berbagi set register. Oleh karena itu, jika utas lain mengubah register
EAX , ini tidak akan mempengaruhi register
EAX utas ini. Oleh karena itu, utas lain tidak dapat membatalkan urutan instruksi ini.
Ada pertanyaan menarik lainnya. Bisakah kita mengatasi ini
DAN ? Saya bisa melompat ke mana saja saya mau ke mana saja di ruang alamat ini. ,
AND .

, , , , ,
AND . .
jmp , .

, , - , 1237. , 32.
Native Client , , , . , , 1237 ?
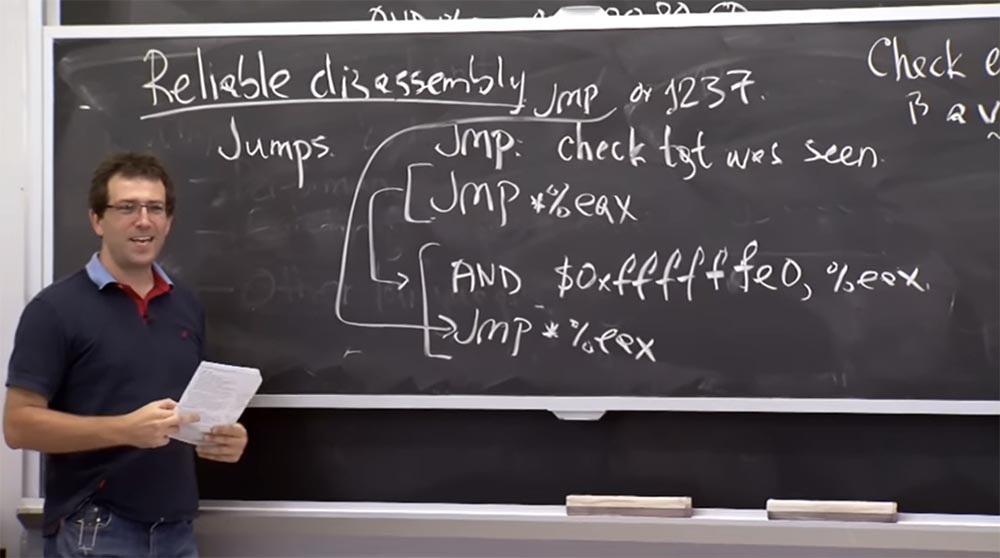
-
EAX , , , , . , ? ?
: NaCl , .
: , .
x86 , ,
NaCl , 2 . , , : «, , !»,
25 CD 80 00 00 . . ,
x86 .
,
Native Client . , , , ,
NaCl . , .
: , , . , . , , , , .
 :
: , . , . , , ,
EAX . , - .
EAX ,
EBX . , .
EAX EBX AND . , ,
EAX , . , -
64 .
Jmp *% eax AND .

, , , , .
Intel , , , , . , , .
AND ,
EAX , «» .
, , . , . , , , . , , , .
, ,
C1 C7 .
C1 , , . , «» . , , . , , - . , .
2 , 0
64 . , , . , , .
3 , , , . , , .
4 ,
hlt .
halt ? ,
C4 . , , - , .
, , ? , , - .
, , , , . , , , , . .

55:20
:
Kursus MIT "Keamanan Sistem Komputer". 7: « Native Client», 3.
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
3 Dell R630 —
2 Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 41TB HDD 2240GB SSD / 1Gbps 10 TB — $99,33 , ,
di sini .Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?