Institut Teknologi Massachusetts. Kursus Kuliah # 6.858. "Keamanan sistem komputer." Nikolai Zeldovich, James Mickens. Tahun 2014
Keamanan Sistem Komputer adalah kursus tentang pengembangan dan implementasi sistem komputer yang aman. Ceramah mencakup model ancaman, serangan yang membahayakan keamanan, dan teknik keamanan berdasarkan pada karya ilmiah baru-baru ini. Topik meliputi keamanan sistem operasi (OS), fitur, manajemen aliran informasi, keamanan bahasa, protokol jaringan, keamanan perangkat keras, dan keamanan aplikasi web.
Kuliah 1: “Pendahuluan: model ancaman”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 2: "Kontrol serangan hacker"
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 3: “Buffer Overflows: Exploits and Protection”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 4: “Pemisahan Hak Istimewa”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 5: "Dari mana sistem keamanan berasal?"
Bagian 1 /
Bagian 2Kuliah 6: “Peluang”
Bagian 1 /
Bagian 2 /
Bagian 3Kuliah 7: “Kotak Pasir Klien Asli”
Bagian 1 /
Bagian 2 /
Bagian 3 Ada satu peringatan dalam aturan
C4 . Anda tidak dapat "melompati" akhir program. Hal terakhir yang dapat Anda lompati adalah instruksi terakhir. Jadi aturan ini menjamin bahwa ketika program dieksekusi dalam proses "mesin", tidak akan ada perbedaan.
Aturan
C5 mengatakan bahwa tidak mungkin ada instruksi yang lebih besar dari 32 byte. Kami menganggap varian aturan ini ketika kami berbicara tentang banyaknya ukuran instruksi hingga 32 byte, jika tidak, Anda dapat melompat ke tengah instruksi dan membuat masalah dengan pemanggilan sistem, yang dapat "bersembunyi" di sana.
Peraturan
C6 menyatakan bahwa semua instruksi yang tersedia dapat dibongkar dari awal. Dengan demikian, ini memastikan bahwa kita melihat setiap instruksi dan dapat memeriksa semua instruksi yang berjalan ketika program berjalan.
Aturan
C7 menyatakan bahwa semua lompatan langsung benar. Sebagai contoh, Anda melompat langsung ke bagian instruksi di mana target diindikasikan, dan meskipun bukan kelipatan 32, itu masih instruksi yang tepat yang pembongkaran diterapkan dari kiri ke kanan.
 Audiens:
Audiens: apa perbedaan antara
C5 dan
C3 ?
Profesor: Saya pikir
C5 mengatakan bahwa jika saya memiliki instruksi multi-byte, itu tidak dapat melewati batas alamat yang berdekatan. Misalkan saya memiliki aliran instruksi, dan ada alamat 32 dan alamat 64. Jadi, sebuah instruksi tidak dapat melewati batas kelipatan 32 byte, yaitu, ia tidak boleh dimulai dengan alamat kurang dari 64 dan diakhiri dengan alamat yang lebih besar dari 64.

Inilah yang dikatakan aturan
C5 . Karena jika tidak, setelah melakukan lompatan multiplisitas 32, Anda dapat masuk ke tengah instruksi lain, di mana tidak diketahui apa yang terjadi.
Dan aturan
C3 adalah analog dari larangan ini di sisi lompatan. Ini menyatakan bahwa setiap kali Anda melompat, panjang lompatan Anda harus kelipatan 32.
C5 juga mengklaim bahwa apa pun dalam kisaran alamat yang merupakan kelipatan 32 adalah instruksi yang aman.
Setelah membaca daftar aturan-aturan ini, saya merasa campur aduk, karena saya tidak bisa menilai apakah aturan-aturan ini cukup, artinya, daftar itu minimal atau lengkap.
Jadi, mari kita pikirkan tentang pekerjaan rumah yang harus Anda selesaikan. Saya pikir sebenarnya ada kesalahan dalam operasi
Klien Asli ketika menjalankan beberapa instruksi rumit di kotak pasir. Saya percaya bahwa mereka tidak memiliki pengkodean panjang yang benar, yang dapat menyebabkan sesuatu yang buruk, tetapi saya tidak ingat persis apa kesalahannya.
Misalkan validator kotak pasir salah mendapatkan panjang semacam instruksi. Apa yang buruk bisa terjadi dalam kasus ini? Bagaimana Anda menggunakan slip ini?
Pemirsa: misalnya, Anda dapat menyembunyikan panggilan sistem atau
ret pernyataan kembali.
Profesor: ya. Misalkan ada beberapa versi mewah dari pernyataan
DAN yang Anda tulis. Mungkin saja validator salah dan menganggap bahwa panjangnya 6 byte dengan panjang sebenarnya 5 byte.
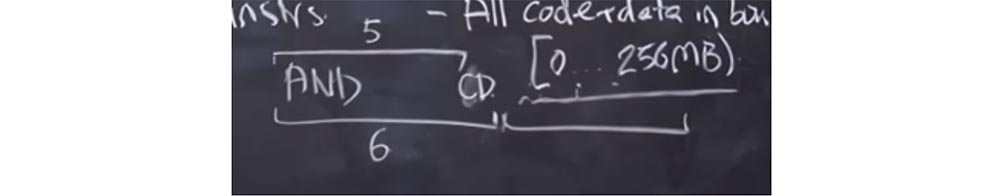
Apa yang akan terjadi Validator menganggap panjang instruksi ini menjadi 6 byte dan memiliki instruksi lain yang valid di belakangnya. Tetapi prosesor, ketika meluncurkan kode, menggunakan panjang sebenarnya dari instruksi, yaitu 5 byte. Sebagai hasilnya, kami memiliki byte gratis di akhir pernyataan
AND , tempat kami dapat memasukkan panggilan sistem dan menggunakannya untuk keuntungan kami. Dan jika kita memasukkan byte
CD di sini, itu akan seperti awal instruksi lain. Selanjutnya, kita akan meletakkan sesuatu dalam rentang 6-byte berikutnya, dan itu akan terlihat seperti instruksi yang dimulai dengan byte
CD , meskipun sebenarnya itu adalah bagian dari instruksi
AND . Setelah itu, kita dapat melakukan panggilan sistem dan "melarikan diri" dari kotak pasir.
Dengan demikian, validator
Native Client harus menyinkronkan tindakannya dengan tindakan
CPU , yaitu, “tebak” persis bagaimana prosesor akan menginterpretasikan setiap instruksi. Dan ini harus di setiap tingkat kotak pasir, yang cukup sulit untuk diterapkan.
Bahkan, ada kesalahan menarik lainnya di
Native Client . Salah satunya adalah pembersihan lingkungan prosesor yang salah saat masuk ke
Layanan Tepercaya Tepercaya . Saya pikir kita akan membicarakan ini sebentar lagi. Tetapi
Runtime Layanan Tepercaya pada dasarnya akan bekerja dengan set register
CPU yang sama yang dirancang untuk menjalankan modul yang tidak terpercaya. Jadi jika prosesor lupa untuk menghapus sesuatu atau reboot, runtime dapat diakali dengan mempertimbangkan modul yang tidak dapat diandalkan sebagai aplikasi tepercaya dan melakukan sesuatu yang seharusnya tidak dilakukan atau itu bukan maksud dari pengembang.
Jadi di mana kita sekarang? Saat ini, kami memahami cara membongkar semua instruksi dan cara mencegah pelaksanaan instruksi yang dilarang. Sekarang mari kita lihat bagaimana kita menyimpan memori dan tautan untuk kode dan data dalam modul
Native Client .
Untuk alasan kinerja, para
klien Native mulai menggunakan dukungan perangkat keras untuk memastikan bahwa penyimpanan memori dan tautan tidak benar-benar menyebabkan banyak overhead. Tetapi sebelum mempertimbangkan dukungan perangkat keras yang mereka gunakan, saya ingin mendengar saran, bagaimana saya bisa melakukan hal yang sama tanpa dukungan perangkat keras? Bisakah kita memberikan akses ke semua proses memori dalam batas yang ditentukan oleh mesin sebelumnya?
Pemirsa: Anda dapat instruksi instrumen untuk menghapus semua bit tinggi.
 Profesor:
Profesor: ya, itu benar. Faktanya, kita melihat bahwa kita memiliki instruksi
DAN ini di sini, dan setiap kali, misalnya, kita melompat ke suatu tempat, itu akan membersihkan bit-bit rendah. Tetapi jika kita ingin menyimpan semua kode yang mungkin berjalan dalam 256 MB yang rendah, kita cukup mengganti atribut
f pertama dengan
0 dan mendapatkan
$ 0x0fffffe0 alih-alih
$ 0xffffffe0 . Ini membersihkan bit-bit rendah dan menetapkan batas atas 256 MB.
Jadi, ini melakukan persis apa yang Anda tawarkan, memastikan bahwa setiap kali Anda melompat, Anda berada dalam 256 MB. Dan fakta bahwa kami melakukan pembongkaran juga memungkinkan untuk memverifikasi bahwa semua lompatan langsung berada dalam jangkauan.
Alasan mengapa mereka tidak melakukan ini untuk kode mereka adalah bahwa pada platform
x86 Anda dapat dengan sangat mudah mengkodekan
AND , di mana semua bit teratas adalah 1. Ini berubah menjadi keberadaan instruksi 3-byte untuk
DAN dan instruksi 2-byte untuk lompat. Jadi, kami memiliki biaya tambahan 3 byte. Tetapi jika Anda memerlukan bit tinggi non-unit, seperti ini bukan
0 f , maka Anda tiba-tiba memiliki instruksi 5-byte. Karena itu, saya pikir dalam hal ini mereka khawatir tentang overhead.
Hadirin: Apakah ada masalah dengan adanya beberapa instruksi yang meningkatkan versi yang Anda coba dapatkan? Artinya, Anda dapat mengatakan bahwa instruksi Anda mungkin memiliki bias konstan atau sesuatu seperti itu?
Profesor: Saya kira begitu. Anda mungkin akan melarang instruksi yang melompat ke beberapa formula alamat kompleks dan hanya akan mendukung instruksi yang langsung menuju ke nilai ini, dan nilai ini selalu mendapat
AND .
Pemirsa: lebih penting untuk akses ke memori daripada ...
Profesor: ya, karena itu hanya kode. Dan untuk mengakses memori pada platform
x86 , ada banyak cara aneh untuk mengakses lokasi memori tertentu. Biasanya, Anda harus terlebih dahulu menghitung lokasi memori, lalu menambahkan
DAN tambahan
, dan hanya kemudian melakukan akses. Saya pikir ini adalah alasan sebenarnya atas kekhawatiran mereka tentang penurunan kinerja karena penggunaan toolkit ini.
Pada platform
x86 , atau setidaknya pada platform 32-bit yang dijelaskan dalam artikel, mereka menggunakan dukungan perangkat keras alih-alih membatasi kode dan data alamat yang merujuk ke modul yang tidak terpercaya.
Mari kita lihat tampilannya sebelum mencari tahu bagaimana menggunakan modul
NaCl di kotak pasir. Perangkat keras ini disebut segmentasi. Itu muncul bahkan sebelum platform
x86 mendapat file swap. Pada platform
x86 , tabel perangkat keras yang didukung ada selama proses. Kami menyebutnya tabel deskriptor segmen. Ini adalah sekelompok segmen yang diberi nomor mulai dari 0 hingga akhir tabel dengan ukuran berapa pun. Ini adalah sesuatu seperti deskriptor file di
Unix , kecuali bahwa setiap entri terdiri dari 2 nilai: basis
dasar dan
panjang panjang.
Tabel ini memberi tahu kita bahwa kita memiliki sepasang segmen, dan setiap kali kita merujuk ke segmen tertentu, ini dalam arti berarti kita berbicara tentang sepotong memori yang dimulai dari alamat
basis basis dan berlanjut sepanjang
panjangnya .

Ini membantu kami menjaga batasan memori pada platform
x86 , karena setiap instruksi, yang mengakses memori, merujuk ke segmen tertentu dalam tabel ini.
Misalnya, ketika kita menjalankan
mov (% eax), (% ebx) , yaitu, kita memindahkan nilai memori dari sebuah pointer yang disimpan dalam register
EAX ke pointer lain yang disimpan dalam register
EBX , program mengetahui apa alamat awal dan apa alamat akhir itu. mengingat, dan akan menyimpan nilai di alamat kedua.
Tetapi sebenarnya, pada platform
x86 , ketika kita berbicara tentang memori, ada hal implisit yang disebut deskriptor segmen, mirip dengan deskriptor file di
Unix . Ini hanya indeks dalam tabel deskriptor, dan kecuali dinyatakan sebaliknya, maka setiap kode operasi berisi segmen default.
Oleh karena itu, ketika Anda menjalankan
mov (% eax) , ini merujuk ke
% ds , atau ke register segmen data, yang merupakan register khusus di prosesor Anda. Jika saya ingat dengan benar, itu adalah bilangan bulat 16-bit yang menunjuk ke tabel deskriptor ini.
Dan hal yang sama berlaku untuk
(% ebx) - mengacu pada pemilih segmen
% ds yang sama. Faktanya, di
x86 kami memiliki sekelompok 6 penyeleksi kode:
CS, DS, ES, FS, GS dan
SS .
Pemilih panggilan CS secara implisit digunakan untuk menerima instruksi. Jadi, jika penunjuk instruksi Anda menunjuk ke sesuatu, maka itu merujuk ke yang memilih pemilih segmen
CS .
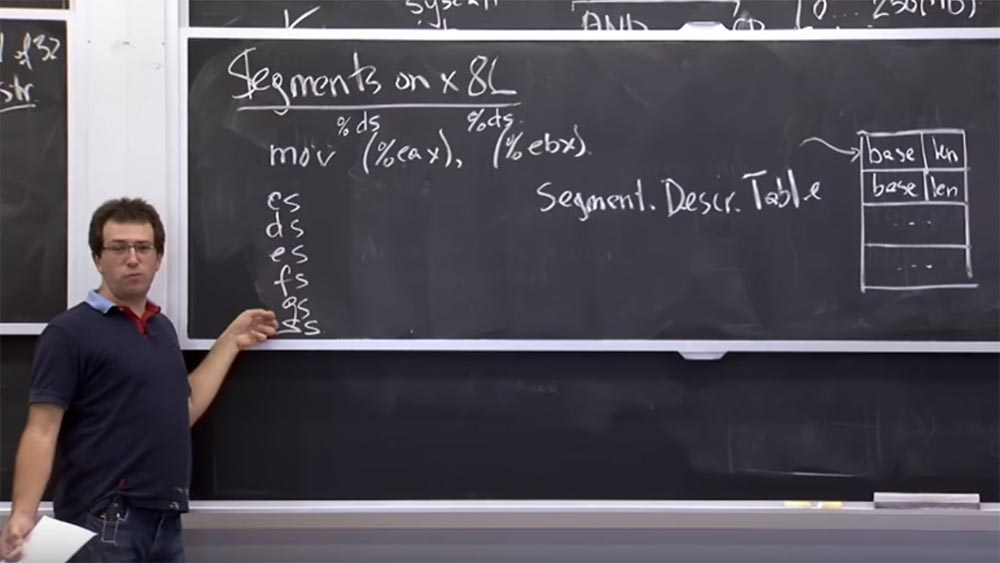
Sebagian besar referensi data secara implisit menggunakan
DS atau
ES ,
FS dan
GS menunjukkan beberapa hal khusus, dan
SS selalu digunakan untuk operasi tumpukan. Dan jika Anda melakukan
push & pop , maka mereka secara implisit berasal dari pemilih segmen ini. Ini adalah mekanika yang agak kuno, tetapi ternyata sangat berguna dalam kasus khusus ini.
Jika Anda mendapatkan akses ke beberapa alamat, misalnya, di pemilih
% ds: addr , perangkat keras akan mengarahkannya ke operasi dengan tabel
adrr + T [% ds] .base . Ini berarti bahwa ia akan mengambil alamat panjang modul dari tabel yang sama. Jadi, setiap kali Anda mengakses memori, ia memiliki database pemilih segmen dalam bentuk entri tabel deskriptor, dan dibutuhkan alamat yang Anda tentukan dan cocokkan dengan panjang segmen yang sesuai.
Pemirsa: jadi mengapa tidak digunakan, misalnya, untuk melindungi buffer?
Profesor: ya, itu pertanyaan yang bagus! Bisakah kita menggunakan ini untuk melindungi dari buffer overflows? Misalnya, untuk setiap buffer yang kita miliki, Anda dapat meletakkan basis buffer di sini, dan di sana ukuran buffer.
Hadirin: bagaimana jika Anda tidak perlu menaruhnya di meja sebelum Anda ingin menulisnya? Anda tidak perlu berada di sana terus-menerus.
Profesor: ya. Oleh karena itu, saya berpikir bahwa alasan bahwa pendekatan ini tidak sering digunakan untuk melindungi terhadap buffer overflow adalah karena jumlah catatan dalam tabel ini tidak dapat melebihi 2 pada kekuatan 16, karena deskriptor panjangnya 16 bit, tetapi sebenarnya pada kenyataannya, beberapa bit lagi digunakan untuk hal-hal lain. Jadi sebenarnya Anda hanya bisa menempatkan 2 di kekuatan catatan ke-13 dalam tabel ini. Oleh karena itu, jika Anda memiliki array data yang berukuran lebih dari
13 dalam kode Anda, tabel ini mungkin meluap.
Selain itu, akan aneh bagi kompiler untuk secara langsung mengelola tabel ini, karena biasanya ia dimanipulasi menggunakan panggilan sistem. Anda tidak dapat langsung menulis ke tabel ini, pertama-tama Anda perlu membuat panggilan sistem ke sistem operasi, setelah itu sistem operasi akan menempatkan catatan dalam tabel ini. Oleh karena itu, saya pikir sebagian besar kompiler tidak akan mau berurusan dengan sistem manajemen buffer memori yang kompleks.

Omong-omong,
Multex menggunakan pendekatan ini: ia memiliki 2
18 catatan untuk berbagai segmen dan 2
18 catatan untuk kemungkinan offset. Dan setiap fragmen perpustakaan umum atau fragmen memori adalah segmen yang terpisah. Mereka semua diperiksa untuk jangkauan dan karenanya tidak dapat digunakan pada tingkat variabel.
Hadirin: Agaknya, kebutuhan konstan untuk menggunakan kernel akan memperlambat proses.
Profesor: ya, itu benar. Jadi kita akan memiliki overhead karena fakta bahwa ketika buffer baru tiba-tiba dibuat di stack, kita perlu membuat system call untuk menambahkannya.
Jadi berapa banyak elemen ini yang benar-benar menggunakan mekanisme segmentasi? Anda bisa menebak cara kerjanya. Saya pikir, secara default, semua segmen di
x86 ini memiliki basis yang sama dengan 0, dan panjangnya adalah 2 hingga 32. Dengan demikian, Anda dapat mengakses seluruh rentang memori yang Anda inginkan. Oleh karena itu, untuk
NaCl, mereka menyandikan basis 0 dan mengatur panjangnya menjadi 256 megabita. Kemudian mereka menunjuk ke semua register dari 6 penyeleksi segmen dalam catatan ini untuk area 256 MB. Jadi, setiap kali peralatan mengakses memori, ia memodifikasinya dengan offset 256 MB. Jadi kemampuan untuk mengubah modul akan dibatasi hingga 256 MB.
Saya pikir Anda sekarang mengerti bagaimana perangkat keras ini didukung dan cara kerjanya, sehingga Anda bisa menggunakan pemilih segmen ini.
Jadi apa yang salah jika kita menerapkan rencana ini? Bisakah kita melompat keluar dari pemilih segmen dalam modul yang tidak dipercaya? Saya pikir satu hal yang perlu diperhatikan adalah register ini seperti register biasa, dan Anda dapat memindahkan nilai ke dalam dan ke luarnya. Oleh karena itu, Anda harus memastikan bahwa modul yang tidak dipercaya tidak mendistorsi register pemilih segmen ini. Karena di suatu tempat di tabel deskriptor mungkin ada catatan, yang juga merupakan deskriptor segmen sumber untuk proses yang memiliki basis 0 dan panjang hingga 2
32 .

Jadi, jika modul yang tidak dapat diandalkan mampu mengubah
CS , atau
DS , atau
ES , atau penyeleksi mana pun sehingga mereka mulai menunjuk ke sistem operasi asli ini, yang mencakup semua ruang alamat Anda, maka Anda dapat membuat tautan memori ke segmen ini dan " melompat keluar dari kotak pasir.
Dengan demikian,
Klien Asli harus menambahkan beberapa instruksi lagi ke daftar terlarang ini. Saya pikir mereka melarang semua instruksi seperti
mov% ds, es, dan sebagainya. Karenanya, sekali di kotak pasir, Anda tidak dapat mengubah segmen yang dirujuk oleh beberapa hal. Pada platform
x86, instruksi untuk mengubah tabel deskriptor segmen adalah hak istimewa, tetapi mengubah
ds, es sendiri
, dll. Tabel ini benar-benar tidak terjangkau.
Pemirsa: dapatkah Anda menginisialisasi tabel sehingga panjang nol ditempatkan di semua slot yang tidak digunakan?
Profesor: ya. Anda dapat mengatur panjang tabel untuk sesuatu di mana tidak ada slot yang tidak digunakan. Ternyata Anda benar-benar membutuhkan slot tambahan ini yang berisi 0 dan 2
32 , karena lingkungan
runtime tepercaya harus dimulai di segmen ini dan mendapatkan akses ke seluruh rentang memori. Jadi entri ini diperlukan agar lingkungan
runtime tepercaya berfungsi.
Hadirin: apa yang dibutuhkan untuk mengubah panjang output dari tabel?
Profesor: Anda harus memiliki hak akses root.
Linux sebenarnya memiliki sistem yang dinamakan
mod_ldt () untuk tabel deskriptor lokal, yang memungkinkan setiap proses untuk memodifikasi tabelnya sendiri, yaitu, sebenarnya ada satu tabel untuk setiap proses. Tetapi pada platform
x86 ini lebih rumit, ada tabel global dan lokal. Tabel lokal untuk proses tertentu dapat diubah.
Sekarang mari kita coba mencari tahu bagaimana kita melompat dan melompat dari proses eksekusi
Native Client atau melompat keluar dari kotak pasir. Apa artinya melompat keluar dari kita?

Jadi, kita perlu menjalankan kode tepercaya ini, dan kode tepercaya ini "hidup" di suatu tempat di atas batas 256 MB. Untuk melompat ke sana, kita harus membatalkan semua perlindungan yang
telah diinstal oleh
Klien Asli . Pada dasarnya mereka turun untuk mengubah enam penyeleksi ini. Saya pikir validator kami tidak akan menerapkan aturan yang sama untuk hal-hal yang berada di atas batas 256 MB, jadi ini cukup sederhana.
Tapi kemudian kita perlu entah bagaimana melompat ke
runtime runtime tepercaya dan menginstal ulang pemilih segmen ke nilai yang benar untuk segmen raksasa ini, mencakup ruang alamat seluruh proses - kisaran ini adalah dari 0 hingga 2
32 . Mereka menyebut mekanisme semacam itu yang ada di trampolin
Native Client "trampoline" dan "springboards". Mereka tinggal di modul 64k rendah. Yang paling keren adalah "trampolin" dan "lompatan" ini adalah potongan-potongan kode yang terletak di bawah 64k ruang proses. Ini berarti bahwa modul yang tidak dapat diandalkan ini dapat melompat ke sana, karena ini adalah alamat kode yang valid yang berada dalam batas 32 bit dan dalam 256 MB. Jadi Anda bisa melompat ke trampolin ini.
Native Client «» - . ,
Native Client «», trampoline
trusted runtime . ,
DS, CS , .
, , -
malo , «», «» 32- .
, 4096 + 32 , . , ,
mov %ds, 7 ,
ds , 7 0 2
32 .
CS trusted service runtime , 256 .

, , ,
trusted service runtime , . , . DS , , , , - .
, ? , «»? , ?
: 64.
: , , . malo, 64, 32 . , , , .
, 32- , . , , 32 , 32- , . «»
trusted runtime 32 .

. , ,
DS, CS . , 256- ,
trusted runtime , . .
«»,
trusted runtime 256
Native Client . «»
DS , ,
mov %ds, 7 , ,
trusted runtime . . , «», - .
halt 32- «». «», .
trusted service runtime , 1 .
 trusted service runtime
trusted service runtime , , .
: «» ?
: «» 0 256 . 64- , , «», - -.
Native Client .
: ?
: , ? , «»? ?
: , ?
: , -
%eax ,
trusted runtime : «, »!
EAX ,
mov , «»
EAX ,
trusted runtime . , «»?
: , , . …
: , , — , , 0 2
32 . . «», 256 .
, «», . , «» , . , «» .
: «» 256 ?
: , . ,
CS - . «»,
halt , mov,
CS , , 256 .
, , «». ,
DS , ,
CS - .
, ,
x86 ,
Native Client .
, -.
.
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 ? 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?