Isi
Mnemonics adalah kata atau frasa yang membantu kita mengingat sesuatu. Mnemonik yang paling terkenal adalah "setiap pemburu ingin tahu di mana burung itu duduk." Siapa pun yang Anda tanya, semua orang mengenalnya.
Tapi di bidang profesional, semuanya sedikit lebih sedih. Tanya kawan Anda apakah mereka tahu apa itu SPDFOT atau RCRCRC. Jauh dari fakta ... Tetapi mnemonik membantu kita menjalankan tes, tidak lupa untuk memeriksa yang paling penting. Daftar periksa diciutkan dalam satu frasa!
Rekan pengujian yang berbahasa Inggris secara aktif menggunakan mnemonik. Seorang teman yang membaca blog asing, mengatakan bahwa orang Amerika datang dengan mereka untuk hampir setiap bersin.
Dan saya pikir itu hebat. Mnemonik asing mungkin tidak cocok untuk sistem Anda atau proses Anda. Dan itu, sayang, akan mengingatkan Anda "tidak menunggu untuk memeriksa ini dan itu" dan membatasi jumlah bug dalam produksi.
Hari ini saya ingin berbagi dengan Anda mnemonik BMW saya untuk studi nilai batas. Itu bisa:
- berikan junior untuk pengembangan umum dalam desain tes;
- gunakan saat wawancara - kandidat biasanya menyelesaikan tugas "menemukan perbatasan dalam jumlah", tetapi apakah ia akan menemukan perbatasan dalam barisan atau untuk mengunduh file?
BMW Mnemonics
B - besar
M - kecil
B - tepat

Mudah diingat. Hanya ingat mobil keren ini dan dekripsi langsung siap! Tetapi apa artinya dan bagaimana itu akan membantu dalam wawancara?
Tepat

Pada prinsipnya, "tepat" yang Anda uji tanpa mnemonik. Kami selalu memulai dengan pengujian positif untuk memverifikasi bahwa sistem bekerja pada prinsipnya.
Jika bidang ini berupa angka, masukkan nilai umum. Katakanlah kita memiliki toko online ritel. Dalam jumlah barang kami dapat memeriksa 1 atau 2.
Tes positif - ini "tepat". Saya menunjukkan mnemonik dalam bentuk mouse. Ini dia ukuran standar.
Besar
Kemudian kita katakan bahwa mouse harus digembungkan ke ukuran yang luar biasa, sehingga tidak pas langsung ke dalam gambar. Dan lihat bagaimana sistem akan bekerja dengannya.

Dalam hal ini, kami hanya akan "jauh di depan". SANGAT JAUH Tikus besar mewakili pencarian untuk batas teknologi di suatu tempat di luar sana, di luar yang sewenang-wenang.
Untuk memasukkan jumlah barang, ini akan menjadi "999999999999999999999999999999999999999999999999999999999999999999, ...". Bukan hanya beberapa nilai hebat (9999), tetapi SANGAT besar. Ingat mouse - itu sangat meledak sehingga bahkan tidak sesuai dengan gambar.
Perbedaannya penting, sangat penting akan membantu untuk menemukan perbatasan yang sewenang-wenang, dan yang besar akan membantu menemukan yang teknologi. Tes untuk "besar" sering dilakukan, untuk "besar" - tidak. Mnemonics ingat tepatnya tentang dia.
Kecil
Kami menembus mouse, dan diterbangkan ke ukuran mikroskopis.

Tikus kecil adalah pencarian nilai yang mendekati nol. Nilai positif terkecil.
Bagaimana dengan tes untuk "0,00000001"? Diperiksa nol, tetapi jangan lupa untuk menggali berdampingan.
Dan apa yang ada di sana?
Tampaknya mengatakan hal-hal yang jelas. Sepertinya semua orang sudah tahu ini. Cukup berikan wawancara tentang tugas bilangan, segitiga yang sama (
tugas dari Myers ), dan Anda mengerti bahwa ini tidak benar ... Sangat sedikit orang akan pergi mencari batas teknologi atau mencoba memasukkan nilai fraksional mendekati nol. Maksimal nol dan akan menawarkan untuk memeriksa.
Dan jika Anda mengusulkan untuk menguji BUKAN angka, maka ini adalah kebodohan yang lebih besar. Dengan nomor itu, oke, kami memeriksa nol dan perbatasan sesuai dengan pernyataan kerja, itu sudah tidak buruk. Dan di baris apa yang harus diuji? Dan di dalam file?
Saya ingin membicarakan hal ini di artikel. Bagaimana Anda bisa menggunakan mnemonik dalam kehidupan nyata dan pada saat yang sama menangkap bug. Mari kita mulai dengan contoh umum - yang ditemukan di setiap proyek. Dan yang bisa diberikan saat wawancara dalam bentuk tugas kecil.
Dan kemudian saya akan memberi contoh dari pekerjaan saya. Ya, mereka spesifik. Ya, itu tentang teknologi spesifik. Jadi apa Tetapi mereka menunjukkan bagaimana Anda dapat menerapkan mnemonik di tempat yang lebih kompleks.
Artinya sama: perbatasan hampir di mana-mana. Temukan saja nomor dan bereksperimenlah dengannya. Dan jangan lupa tentang BMW mnemonics, karena pada B dan M kita sering menemui bug.
Contoh umum
Contoh yang ada dalam proyek apa pun: bidang numerik, string, tanggal ... Kami akan mempertimbangkan dalam urutan ini:
Nomor
- 10
- 0,00000001
- 999999999999999999999999 ....
Ucapkan sebuah kotak dengan jumlah buku, pakaian, atau paket jus. Sebagai tes positif, kami memilih jumlah yang memadai: 3, 5, 10.
Sebagai nilai kecil, pilih sedekat mungkin dengan nol. Ingat bahwa mouse harus sangat kecil. Ini bukan hanya sebuah unit, tetapi tempat desimal ke-N. Tiba-tiba itu akan membulat ke nol dan di suatu tempat dalam formula akan crash? Apalagi pada angka "1" semuanya akan bekerja dengan baik.
Nah, maksimal dicapai dengan memasukkan 10 juta sembilan. Hasilkan string seperti itu menggunakan alat-alat seperti Perlclip, dan lanjutkan, uji SANGAT banyak!
Lihat juga:Kelas kesetaraan untuk string yang menunjukkan angka - bahkan lebih banyak ide untuk tes string numerik
Cara menghasilkan string besar, alat - asisten dalam menghasilkan nilai yang besar
Tanggal
- 26/05/2017
- 01/01/1900
- 12/21/003
Tanggal positif adalah "hari ini" jika kami mengirimkan laporan pada tanggal tertentu. Atau tanggal lahir Anda sendiri, jika kita berbicara tentang DR, atau yang lain yang sesuai dengan proses bisnis Anda.
Sebagai kencan kecil, kita mengambil tanggal ajaib "01/01/1900", di mana aplikasi sering berantakan. Dari tanggal ini, waktu dimulai di Excel. Itu juga merayap ke dalam aplikasi. Anda mengekspos angka ajaib ini - dan laporan itu berantakan, bahkan jika ada perlindungan terhadap orang bodoh terhadap nol. Jadi saya sangat merekomendasikannya untuk verifikasi.
Jika kita berbicara tentang mouse yang sangat kecil, maka Anda masih dapat memeriksa "00.00.0000". Ini akan menjadi cek nol, yang juga penting. Tetapi pengembang lebih sering terlindungi dari orang bodoh seperti itu dari pada 01/01/1900.
Jauh di depan juga bisa berbeda. Anda dapat masuk ke negatif dan memeriksa tanggal atau bulan yang benar-benar tidak ada: 05/40/2018. Atau cari perbatasan teknologi menggunakan tanggal 99.99.9999. Dan Anda dapat mengambil nilai lebih nyata, yang tidak akan segera hadir: 2400 atau 3000.
Lihat juga:Kelas kesetaraan untuk string yang menunjukkan tanggal - bahkan lebih banyak ide untuk menguji tanggal

Tali
- Vasya
- (satu spasi)
- (Ada banyak teks)
Katakanlah saat mendaftar ada bidang dengan nama. Tes positif adalah nama umum: Olga, Vasya, Peter ...
Saat mencari mouse kecil, kami mengambil baris kosong atau hack seumur hidup: satu atau dua spasi. Dalam hal ini, garis tetap kosong (tidak ada karakter di sana), tetapi tampaknya diisi.
Apa fokusnya ketika mencari mouse besar? Saat kami menguji string besar, kami perlu menguji string BESAR! Ingat bahwa mouse harus BESAR. Karena saya biasanya menjelaskan kepada siswa bagaimana semua ini bekerja, bagaimana mencari batas teknologi, dll. Dan kemudian mereka memberi saya DZ dan menulis "Saya memeriksa 1000 karakter - tidak ada batas teknologi."
Abad 21 di halaman, apa 1000 karakter? Kami mengambil alat apa pun yang memungkinkan kami menghasilkan 10 juta, dan memasukkan 10 juta. Sekarang ini akan menjadi pencarian perbatasan teknologi. Dan sudah ada bug pada ini, pada sistem ini mungkin terputus. Tapi 1000 karakter? Tidak.
Lihat juga:Cara menghasilkan string besar, alat - asisten dalam menghasilkan nilai yang besar
Tapi ok, semuanya jelas di sini juga. Dan apa yang akan terjadi jika kita menguji file?
File
Di mana saya dapat menemukan nomor dalam file?
Pertama, ukuran file:
Saat menguji file besar, mereka biasanya mencoba sesuatu seperti 30 MB, dan mereka tenang. Dan kemudian Anda memuat 1GB - dan itu saja, server membeku.
Tentu saja, jika Anda seorang pemula dan menguji beberapa situs nyata untuk pengalaman, Anda tidak boleh memuatnya tanpa sepengetahuan pemiliknya. Tetapi ketika Anda menguji di tempat kerja, pastikan untuk memeriksa mouse besar.
Kedua, file tersebut memiliki nama → dan ini adalah panjang baris yang baru saja kita diskusikan.
Tetapi file tersebut juga memiliki isinya! Ada sejumlah kolom (kolom) dan baris. Tes garis:
- 5 baris
- 1 baris
- 1.000.000.000 baris
Dan di sini kesenangan dimulai. Karena bahkan di Excel yang sama dalam versi yang berbeda ada batasan berbeda pada jumlah baris yang didukungnya:
- Excel di bawah 97 - 16 384
- Excel 97-2003 - 65 536
- Excel 2007 - 1.048.576
Namun jumlahnya masih cukup besar, tidak menarik. Tetapi exel lama tidak membuka lebih dari 256 di kolom, dan ini adalah batasan serius:
- Excel 2003 - 256
- Excel 2007 - 16.385
Abangnya yang bebas, LibreOffice, tidak dapat membuka lebih dari 1024 kolom.

Kisah hidup
Kami menulis beberapa uji coba dalam format CSV. Di pintu masuk ke meja, di output dari tabel. Buka dan edit di LibreOffice untuk melihat di mana kolom itu. Semuanya bagus, semuanya bekerja. Sementara jumlah kolom tidak keluar untuk 1024.
Di sinilah rasa sakit # kehidupan dimulai. Tes LibreOffice tidak akan terbuka lagi, dalam format CSV itu tidak nyaman, karena sulit untuk memahami di mana kolom 555 berada. Anda membuka tes di Excel, mengedit, menyimpan, menjalankan tes ... Itu jatuh di 10 tempat baru: TIN sudah buruk. Panjang, misalnya, 7710152113. Excel dengan senang hati menerjemahkannya ke dalam format 1.2E + 5.
Nomor panjang lainnya juga hilang.
Jika nilainya dalam tanda kutip, itu dibungkus dengan tanda kutip tambahan yang tidak diharapkan oleh tes.
Dan Anda sudah memperbaiki hal-hal kecil ini dalam format CSV, memarahi Excel secara mental untuk diri Anda sendiri ... Jadi ada batasan, harus diingat! Meskipun tidak muncul di sistem itu sendiri, itu hanya dapat mempersulit kehidupan penguji.
Tabel dalam Oracle (database)
Dan karena kita berbicara tentang 1024 kolom, kita akan ingat tentang Oracle (database populer). Ada batasan yang sama: dalam satu tabel bisa ada maksimum 1024 kolom.
Lebih baik mengingat ini sebelumnya! Kami memiliki meja di mana ada sekitar 1000 kolom, tetapi setengahnya disediakan untuk masa depan: "suatu hari nanti akan berguna, ini akan cukup bagi kami untuk waktu yang lama." Cukup, tapi tidak lama ...
Tempat untuk memperluas tabel - berlari ke batasan. Jadi, bagilah tabel menjadi dua, atau kemas isinya dalam BLOB: ini adalah sesuatu arsip zip dengan data ternyata menempati satu kolom, tetapi di dalamnya berisi sebanyak yang Anda suka.
Tetapi bagaimanapun juga, ini adalah migrasi data. Dan migrasi data selalu menyebalkan. Di pangkalan besar, butuh waktu lama, membawa masalah baru yang hanya bisa ditembak dalam enam bulan ... Brrr! Jika Anda dapat melakukannya tanpa migrasi, maka itu lebih baik dilakukan.
Jika Anda memiliki tabel dengan BANYAK data, pikirkan tentang masa depan. Apakah Anda selalu muat di 1024 kolom? Apakah Anda harus bermigrasi nanti? Lagi pula, semakin lama sistem hidup, semakin sulit transfernya. Dan "cukup untuk 5 tahun" berarti volume lima tahun harus dimigrasi.
Bagaimana cara mengujinya? Ya, dengan kode, evaluasi tabel data Anda, lihat di mana itu. Perhatikan mouse besar: tabel-tabel yang sudah memiliki banyak kolom. Akankah ada masalah dengan mereka di masa depan?
Laporkan dalam sistem
Tetapi mengapa kita mengunggah file ke sistem atau memompa data dari Oracle? Kemungkinan besar untuk membangun semacam laporan. Dan di sini Anda juga dapat menerapkan mnemonik ini.
Data dapat berupa input (banyak, sedikit, tepat), dan pada output! Dan ini juga penting, karena ini adalah kelas kesetaraan yang berbeda.
Sebagai hasilnya, kami menguji kuantitas:
- kolom laporan
- garis
- memasukkan data;
- data keluaran (dalam laporan itu sendiri).
Struktur (kolom dan baris)Bisakah kita memengaruhi jumlah baris atau kolom? Terkadang ya, kita bisa. Pada karya kedua, saya menguji perancang laporan: di sebelah kiri Anda memiliki kubus dengan nama-nama parameter yang dapat Anda lemparkan secara horizontal atau vertikal ke dalam laporan itu sendiri. Artinya, Anda memutuskan berapa baris, dan berapa kolom.
Terapkan mnemonik. Setelah laporan standar (tes positif, mouse "benar") kami mencoba melakukan sedikit:
- 1 kolom, 0 baris;
- 0 kolom, 1 baris;
- 1 kolom, 1 baris.
Maka banyak:
- kolom maksimum, 1 baris (semua kubus dilemparkan ke dalam kolom);
- baris maksimum, 1 kolom;
- jika kubus dapat diduplikasi, maka di sana dan di sana secara maksimal, tetapi ini diragukan;
- maksimum level bersarang (ini adalah ketika dua lainnya berada di dalam satu kolom agregator).
Selanjutnya, kami menguji input dan output data. Kami dapat memengaruhi mereka dalam laporan apa pun, bahkan jika tidak ada konstruktor dan jumlah baris dan kolom selalu sama.
Masukkan dataKami mencari tahu bagaimana laporan itu dibentuk. Misalkan setiap hari beberapa data diisi, katakanlah, jumlah gaun yang terjual, gaun malam, kaos. Dan dalam laporan itu kita melihat pengelompokan data berdasarkan kategori, warna, ukuran. Berapa dijual per hari / bulan / jam.
Kami membuat laporan, dan kami sendiri memengaruhi data input:
- Angka yang biasa (5 gaun per hari, meskipun di tempat-tempat besar jumlah ini bisa 2000 atau lebih, Anda perlu mengklarifikasi apa yang akan lebih positif untuk sistem Anda).
- Kosong, tidak menjual / menjual 1 item per bulan.
- Volumenya sangat besar, dengan maksimum setiap produk, setiap warna, setiap ukuran. Kami menetapkan maksimum "terletak di gudang" dan menjual semuanya: dalam satu bulan atau bahkan satu hari. Apa yang akan dilaporkan oleh pelaporan?
Output dataSecara teori, data output berkorelasi dengan input data. Di pintu masuk sedikit → di pintu keluar akan ada sedikit. Di pintu masuk ada banyak - di pintu keluar ada banyak.
Tetapi ini tidak selalu berhasil. Terkadang data input dapat dihilangkan, atau, sebaliknya, dikalikan. Dan kemudian kita entah bagaimana bisa bermain dengannya.
Misalnya, sistem
Dadat . Anda mengunggah file dengan satu kolom nama lengkap, pada output Anda mendapatkan beberapa sekaligus:
- Nama asli, apa yang ada di file;
- Nama dibongkar (jika Anda bisa melihat);
- Batang kasus;
- Dat kasus;
- Creat. kasus;
- Nama keluarga
- Nama depan;
- Nama tengah;
- Status parse - pengakuan percaya diri dengan mekanisme atau diverifikasi oleh seseorang;

Kami mendapat 9. Dari satu sel dan ini hanya berdasarkan nama, dan sistem juga dapat mengurai alamat. Di sana, hampir 50 diperoleh dari satu sel: selain komponen granular, ada semua jenis kode KLADR, FIAS, OKATO ...
Dan ini dia yang menarik. Ternyata kita mungkin memiliki sedikit data di input, tetapi banyak di output. Dan jika kita memeriksa maksimum dalam kolom, maka kita memiliki dua opsi:
- 500 kolom pada output (yaitu sekitar 10 alamat di input);
- 500 kolom di pintu masuk (dan sejumlah di pintu keluar).
Prinsipnya juga bekerja berlawanan arah. Bagaimana jika inputnya adalah sejumlah besar data dan outputnya nihil? Jika alih-alih nama lengkap ada semacam omong kosong seperti "op34e8n8pe"? Kemudian ternyata semua kolom tambahan kosong, hanya status parsing "Anda mengirimi saya sampah." Jadi kita mendapatkan minimum pada output (mouse kecil), yang juga patut diperiksa.
Dan jika speaker dapat dikecualikan! Dimungkinkan untuk memeriksa kelas ekivalen “nol” ketika nol pada output, file sumber tidak kosong. Anda dapat memeriksa setidaknya ketika mereka meninggalkan 1 kolom dari seratus.
Hal utama di sini adalah untuk mengingat bahwa selain input data, kami memiliki data output. Dan kadang-kadang di dalamnya Anda dapat memeriksa batas-batas, yang tidak akan bergantung pada input data. Dan kemudian ini harus dilakukan.
Aplikasi seluler
Komunikasi
Ada beberapa opsi komunikasi:
- Normal
- Sangat ara (tikus kecil);
- Super cepat (besar).
Selain itu, komunikasi yang buruk dapat sebagian: jika Anda berada di area dengan Wi-Fi normal dan jaringan seluler yang buruk. Internet berfungsi dengan baik, tetapi SMSnya buruk.
Jumlah memori
Penting juga seberapa besar memori yang dimiliki aplikasi:
- Jumlah normal;
- Sangat sedikit;
- Banyak.
Dan jika dalam kasus ini tes pertama dan ketiga dalam kasus ini dapat digabungkan, maka mouse kecil sangat menarik. Dan ada beberapa pilihan:
- Jalankan aplikasi di telepon, yang sudah memiliki sedikit memori;
- Jalankan ketika memori normal, runtuh, gunakan sesuatu yang besar, coba kembali ke aplikasi pertama.
Sekarang, jika aplikasi tidak tahu bagaimana cara normal menyimpan memori, maka dalam kasus kedua itu hanya akan crash, maka memori sudah ditekan.
Perangkat diagonal
- Standar (kami mempelajari pasar, melihat apa yang lebih populer di kalangan pengguna kami).
- Minimum (telepon).
- Maksimum (tablet besar).
Resolusi layar
- Standar;
- Terkecil;
- Terbesar;
Jangan bingung antara resolusi dan diagonal, ini adalah dua hal yang berbeda. Anda mungkin memiliki perangkat lama dengan layar besar, tetapi saya memiliki smartphone trendi baru, di mana resolusinya 5 kali lebih baik. Dan apa yang akan terjadi dalam 20 tahun ini menakutkan untuk dibayangkan.
Jalur GPX
Jalur GPX adalah file XML dengan koordinat berurutan. Mereka dapat diunduh ke emulator seluler sehingga ponsel berpikir bahwa ia bergerak di ruang angkasa dengan kecepatan tertentu.
Berguna jika aplikasi membaca koordinat GPS untuk beberapa tujuannya. Jadi itu sendiri menentukan apakah Anda pergi, berlari atau berkuda. Dan Anda tidak bisa lari, cukup beri makan koordinat aplikasi, atur koefisien bagiannya dan uji sambil duduk di kantor.
Peluang apa yang pantas untuk dicoba? Semua menurut mnemonik:
- 1 - koefisien normal, menggantikan berjalan sederhana;
- 0,01 - seolah-olah Anda menyeretkuuuuuuuuuuuuuuuuu;
- 200 - bahkan tidak berlari, tetapi terbang!
Mengapa semua ini harus diperiksa? Bug apa yang bisa ditemukan?
Sebagai contoh, aplikasi mungkin jatuh di pesawat - itu diluncurkan, tetapi segera runtuh. Karena membaca koordinat dan mencoba menentukan kecepatan Anda. Tetapi siapa yang tahu bahwa kecepatan akan di atas 130?
Dengan kecepatan lambat, aplikasi mungkin macet. Dia akan menetapkan sendiri sejuta poin perantara dan tidak akan bisa menyimpannya dalam ingatannya. Dan itu dia!
Lihat juga:Apa jalur GPX dan mengapa mereka membutuhkan tester? - Lebih lanjut tentang jalur gpx dan contoh file tersebut
Ringkasan Contoh Umum
Saya ingin menunjukkan di sini bahwa sepertinya "besar, kecil" adalah bidang angka dan hanya itu!
Tetapi nyatanya, mnemonik dapat digunakan di mana-mana, apakah itu file, mainan, laporan ... Dan itu benar-benar membantu kita menemukan bug. Berikut adalah beberapa contoh dari praktik saya:Tikus kecil (batas bawah)- Tanggal 01/01/1900Ketika saya bekerja pada freelance, tanggal ini menghancurkan semua laporan untuk saya. Karena bahkan jika pengembang mengatur perlindungan dari si bodoh, ia menetapkan perlindungan dari 0000. Tetapi ia tidak menetapkan perlindungan dari tahun 1900.- Karakter kesepian di akhir baris.Tes ini disarankan kepada saya oleh seorang rekan yang lebih berpengalaman ketika kami membahas contoh penggunaan mnemonik. Jika sistem memeriksa kekosongan file, perlu untuk memeriksa tidak sepenuhnya kosong.Saya merekomendasikan tes ini: tambahkan terminator garis ke file. Bahkan bukan ruang, tetapi karakter khusus. Dan lihat bagaimana sistem merespons. Dan dia tidak selalu merespon dengan baik =)Tikus besar (batas atas)Jika kita berbicara tentang tikus besar, maka pada umumnya ada jumlah serangga yang tak terbatas:- Perang dan perdamaian;- Banyak data;- 2 GB.Anda dapat mengunggah perang dan perdamaian ke bidang teks, mengunggah file besar ke sistem, mendapatkan banyak data pada input atau output. Ini semua adalah kesalahan umum yang saya temui dalam latihan saya. Dan bukan hanya saya, batas atas sering diperiksa hanya karena mereka tahu bahwa mungkin ada bug. Sebaliknya, mereka melupakan tikus kecil.Contoh lain dari tikus besar adalah pengujian stres. Oh!
Saya punya contoh seperti itu, jadi kami beralih ke hardcore.Jika Anda tahu konteksnya, jika Anda tahu bagaimana aplikasi Anda bekerja di dalamnya, bahasa pemrograman apa yang digunakan, basis data yang digunakannya, Anda juga dapat menggunakan mnemonik ini. Dan saya ingin menunjukkan ini dengan contoh nyata.Contoh latihan saya
Tikus besar
Linux, Lucene, Mmap
Dalam sistem operasi Linux, ada pengaturan untuk jumlah maksimum deskriptor file terbuka:- redhat-6 - /etc/security/limits.conf
- redhat-7 - / etc / systemd / system / [nama layanan] .service.d / Limit.conf (untuk setiap layanannya sendiri)
Deskriptor file dibuka untuk tindakan apa pun dengan file:- membuat koneksi basis data;
- baca file;
- menulis ke file.
- ...
Jika sistem Anda secara aktif bekerja dengan file dan melakukan banyak operasi, pengaturan perlu ditingkatkan. Kalau tidak, beban sekecil apa pun akan menempatkan Anda.Sistem kami menggunakan indeks pencarian Lucene. Inilah saatnya kita mengambil beberapa data dari basis data dan mengunggahnya ke disk, sehingga nantinya kita bisa mencarinya dengan lebih cepat. Dan jika kita membangun indeks menggunakan teknologi mmap, maka itu membangun banyak file untuk ditulis selama konstruksi indeks.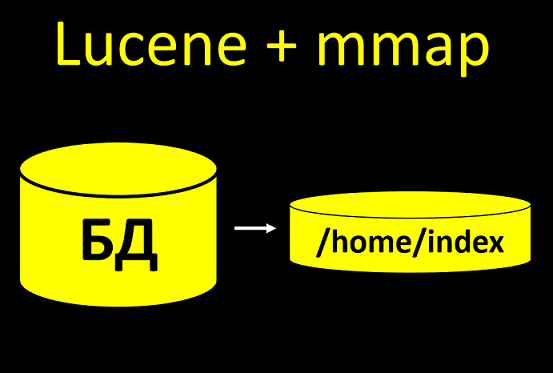 Basis tes biasanya memiliki 100 klien, well, 1000. Tidak begitu banyak. Membangun kembali berjalan tanpa masalah, bahkan jika Anda tidak mengkonfigurasi deskriptor.Dan dalam sistem nyata akan ada 10+ juta pelanggan. Dan jika Anda tidak mengonfigurasi jumlah deskriptor file di sana, maka ketika Anda mulai membuat indeks, semuanya akan macet.Anda perlu tahu tentang ini dan segera menulis instruksi: konfigurasikan sistem operasi pada server, jika tidak akan ada konsekuensi ini dan itu. Dan di sampingnya, penting untuk melakukan tidak hanya tes fungsional, tetapi juga tes stres, pada sejumlah data nyata.
Basis tes biasanya memiliki 100 klien, well, 1000. Tidak begitu banyak. Membangun kembali berjalan tanpa masalah, bahkan jika Anda tidak mengkonfigurasi deskriptor.Dan dalam sistem nyata akan ada 10+ juta pelanggan. Dan jika Anda tidak mengonfigurasi jumlah deskriptor file di sana, maka ketika Anda mulai membuat indeks, semuanya akan macet.Anda perlu tahu tentang ini dan segera menulis instruksi: konfigurasikan sistem operasi pada server, jika tidak akan ada konsekuensi ini dan itu. Dan di sampingnya, penting untuk melakukan tidak hanya tes fungsional, tetapi juga tes stres, pada sejumlah data nyata.Redhat 6 ≠ Redhat 7
Saat menguji mouse besar (memuat), jangan lupa bahwa dalam konfigurasi yang berbeda aplikasi akan bekerja secara berbeda. Jika Anda mengambil instruksi dari paragraf terakhir, maka itu tidak hanya harus ditulis, tetapi juga diperiksa. Dan periksa di lingkungan pelanggan.Karena sistem operasi yang berbeda bekerja secara berbeda. Dan kami memiliki situasi sedemikian rupa sehingga semuanya tampak terkonfigurasi, tetapi sistem macet dan berkata, "Saya tidak memiliki cukup deskriptor file terbuka." Kami mengatakan:- Periksa parameter.- Dia sudah dikonfigurasi, semuanya sesuai dengan instruksi Anda!Bagaimana bisa begitu?
Ternyata kami memiliki instruksi untuk Redhat 6, dan mereka memiliki Redhat 7, di mana pengaturannya berada di tempat yang sama sekali berbeda! Akibatnya, mereka melakukannya sesuai dengan instruksi yang tidak bekerja dan seolah-olah mereka tidak melakukannya sama sekali.Jadi jika Anda bekerja dengan berbagai versi distribusi linux, Anda perlu memeriksa semuanya. Dan tidak hanya menyebarkan layanan pada mesin, tetapi juga melakukan pengujian beban setidaknya sekali: pastikan semuanya bekerja. Lagi pula, lebih baik menangkap bug di lingkungan pengujian daripada memahami produksi nanti.Jawa dan pengumpulan sampah
Kami menggunakan bahasa java, yang memiliki pengumpul sampah bawaan ... Kadang-kadang tampaknya jika aplikasi menggunakan banyak memori dan berada di ambang OOM (Kehabisan Memori) untuk beberapa operasi yang kompleks, maka Anda dapat menyelesaikan masalah ini dengan mudah dengan hanya menambah jumlah memori yang tersedia ! Kenapa harus tes?Tidak juga. Berikan banyak Xmx - aplikasi akan menggantung di pengumpul sampah ... Dan itu muncul dengan sendirinya bagi pengguna. Di sini pada malam hari mereka mengajukan beban besar, mengunduh banyak data - terutama setelah jam kerja, agar tidak mengganggu siapa pun. Di pagi hari pengguna tiba, sementara dia adalah satu-satunya yang bekerja dengan sistem, hampir tidak ada beban, dan semuanya tergantung padanya. Dan dia bahkan tidak mengerti mengapa.Tetapi pada kenyataannya, beban telah berlalu, beban telah pergi, dan pengumpul sampah telah keluar untuk membersihkan semuanya, karena dekorasi ini. Dan meskipun sekarang tidak ada beban dan pengguna yang kesepian bekerja, dia sedih.Oleh karena itu, hanya mengalokasikan banyak memori ke aplikasi "dan Anda tidak dapat mengujinya" - ini tidak berhasil. Pemeriksaan yang lebih baik.
Dan itu muncul dengan sendirinya bagi pengguna. Di sini pada malam hari mereka mengajukan beban besar, mengunduh banyak data - terutama setelah jam kerja, agar tidak mengganggu siapa pun. Di pagi hari pengguna tiba, sementara dia adalah satu-satunya yang bekerja dengan sistem, hampir tidak ada beban, dan semuanya tergantung padanya. Dan dia bahkan tidak mengerti mengapa.Tetapi pada kenyataannya, beban telah berlalu, beban telah pergi, dan pengumpul sampah telah keluar untuk membersihkan semuanya, karena dekorasi ini. Dan meskipun sekarang tidak ada beban dan pengguna yang kesepian bekerja, dia sedih.Oleh karena itu, hanya mengalokasikan banyak memori ke aplikasi "dan Anda tidak dapat mengujinya" - ini tidak berhasil. Pemeriksaan yang lebih baik.Wildfly
Server aplikasi WildFly java tidak akan mengizinkan pengunduhan file besar jika tidak dikonfigurasi dengan benar. Kami menggunakan server aplikasi Jboss, alias Wildfly. Dan ternyata secara default Anda tidak dapat mengunggah file besar ke sana. Dan kita ingat bahwa mouse itu harus BESAR. Jika kami menguji 5mb atau 50, semuanya berfungsi, semuanya baik-baik saja.Tetapi jika Anda mencoba mengunduh 2GB, sistem memberikan kesalahan 404, dan Anda tidak dapat memahami apa pun dari log: log aplikasi kosong. Karena aplikasi ini tidak dapat mengunduh file, Wildfly sendiri memotongnya.Jika Anda tidak melakukan pengujian di pihak Anda, pelanggan mungkin menghadapi ini. Dan itu akan sangat tidak menyenangkan, dia akan datang dengan pertanyaan "Mengapa tidak dimuat?", Dan tanpa pengembang Anda tidak bisa mengatakan apa-apa. Oleh karena itu, lebih baik jangan lupa untuk menguji batas-batas, termasuk file besar yang akan didorong ke dalam sistem. Setidaknya Anda akan mengetahui hasil dari tindakan tersebut.Dan di sini kita memperbaikinya dengan meningkatkan parameter max-post-size, atau kami memberikan informasi tentang pembatasan dan meresepkannya dalam laporan kerja.
Kami menggunakan server aplikasi Jboss, alias Wildfly. Dan ternyata secara default Anda tidak dapat mengunggah file besar ke sana. Dan kita ingat bahwa mouse itu harus BESAR. Jika kami menguji 5mb atau 50, semuanya berfungsi, semuanya baik-baik saja.Tetapi jika Anda mencoba mengunduh 2GB, sistem memberikan kesalahan 404, dan Anda tidak dapat memahami apa pun dari log: log aplikasi kosong. Karena aplikasi ini tidak dapat mengunduh file, Wildfly sendiri memotongnya.Jika Anda tidak melakukan pengujian di pihak Anda, pelanggan mungkin menghadapi ini. Dan itu akan sangat tidak menyenangkan, dia akan datang dengan pertanyaan "Mengapa tidak dimuat?", Dan tanpa pengembang Anda tidak bisa mengatakan apa-apa. Oleh karena itu, lebih baik jangan lupa untuk menguji batas-batas, termasuk file besar yang akan didorong ke dalam sistem. Setidaknya Anda akan mengetahui hasil dari tindakan tersebut.Dan di sini kita memperbaikinya dengan meningkatkan parameter max-post-size, atau kami memberikan informasi tentang pembatasan dan meresepkannya dalam laporan kerja.Penebangan
Contoh lain untuk menguji mouse "besar". Ya, dia ingat entah bagaimana lebih banyak contoh ... Lebih sering daripada tidak, dia menangkap bug!Katakanlah kita memeriksa kesalahan logging. Bahwa kesalahan ditulis ke jejak tumpukan di log. Jadi kami memeriksa, kami hebat: ya, semuanya keren, semuanya direkam! Dan saya mengerti semuanya dari tumpukan pada teks kesalahan. Jika pelanggan jatuh, saya akan segera mengerti mengapa. Dan apa yang akan terjadi jika kita tidak satu kesalahan, tetapi beberapa? Semuanya baik-baik saja, semuanya dicatat, semuanya baik-baik saja! Tetapi kita ingat bahwa mouse harus BESAR:
Dan apa yang akan terjadi jika kita tidak satu kesalahan, tetapi beberapa? Semuanya baik-baik saja, semuanya dicatat, semuanya baik-baik saja! Tetapi kita ingat bahwa mouse harus BESAR: Apa yang akan terjadi jika kita memiliki banyak BANYAK kesalahan? Kami baru saja mengalami situasi ini. Sistem sumber mengunggah data ke tabel buffer dalam database. Sistem kami mengambil data ini dari sana dan entah bagaimana kemudian bekerja dengannya.Sistem sumber macet dan mengunggah kenaikan yang salah, di mana semua data salah. Sistem kami mengambil kenaikan, dan ada 13.600 kesalahan. Dan ketika Java mencoba untuk menghasilkan jejak stack untuk kesalahan 13k, dia memakan semua memori yang dialokasikan untuk itu, dan kemudian berkata "Oh, java heap space".Bagaimana cara memperbaikinya? Kami menambahkan parameter maxStoredErrors (default 100) ke tugas pemuatan - jumlah maksimum kesalahan yang disimpan dalam memori untuk satu aliran. Setelah mencapai jumlah ini, kesalahan dicatat dan daftar dihapus.Kami juga menghapus duplikasi pesan kesalahan tentang pelaksanaan tugas oleh Tugas kami dan Quarz RunShell, meningkatkan tingkat logging yang terakhir untuk memperingatkan (pesan ditampilkan dalam info). Karena duplikasi, tumpukan itu berlipat ganda ...Dan apa kesimpulan dari cerita ini? Tidak cukup untuk memeriksa "tepat". Ini adalah ujian yang penting dan bermanfaat, ya, tidak ada yang membantah. Kami melihat apakah kesalahan tersebut dicatat pada prinsipnya, dalam pengujian mana, dll. Tetapi kemudian sangat penting untuk memeriksa mouse BESAR. Apa yang terjadi jika ada banyak kesalahan?Dan Anda perlu memahami bahwa "banyak" - ini sangat berarti. Jika Anda memuat selisih 10 kesalahan dan mengatakan "10 kesalahan juga normal, sistem menampilkan semua jejak tumpukan", maka sepertinya mereka melakukan pengujian, tetapi mereka tidak mengungkapkan masalahnya. Jika kita melihat bahwa sistem menampilkan semua pesan, kita perlu berpikir terlebih dahulu: apa yang akan terjadi jika ada BANYAK dari mereka? Dan lihat.
Apa yang akan terjadi jika kita memiliki banyak BANYAK kesalahan? Kami baru saja mengalami situasi ini. Sistem sumber mengunggah data ke tabel buffer dalam database. Sistem kami mengambil data ini dari sana dan entah bagaimana kemudian bekerja dengannya.Sistem sumber macet dan mengunggah kenaikan yang salah, di mana semua data salah. Sistem kami mengambil kenaikan, dan ada 13.600 kesalahan. Dan ketika Java mencoba untuk menghasilkan jejak stack untuk kesalahan 13k, dia memakan semua memori yang dialokasikan untuk itu, dan kemudian berkata "Oh, java heap space".Bagaimana cara memperbaikinya? Kami menambahkan parameter maxStoredErrors (default 100) ke tugas pemuatan - jumlah maksimum kesalahan yang disimpan dalam memori untuk satu aliran. Setelah mencapai jumlah ini, kesalahan dicatat dan daftar dihapus.Kami juga menghapus duplikasi pesan kesalahan tentang pelaksanaan tugas oleh Tugas kami dan Quarz RunShell, meningkatkan tingkat logging yang terakhir untuk memperingatkan (pesan ditampilkan dalam info). Karena duplikasi, tumpukan itu berlipat ganda ...Dan apa kesimpulan dari cerita ini? Tidak cukup untuk memeriksa "tepat". Ini adalah ujian yang penting dan bermanfaat, ya, tidak ada yang membantah. Kami melihat apakah kesalahan tersebut dicatat pada prinsipnya, dalam pengujian mana, dll. Tetapi kemudian sangat penting untuk memeriksa mouse BESAR. Apa yang terjadi jika ada banyak kesalahan?Dan Anda perlu memahami bahwa "banyak" - ini sangat berarti. Jika Anda memuat selisih 10 kesalahan dan mengatakan "10 kesalahan juga normal, sistem menampilkan semua jejak tumpukan", maka sepertinya mereka melakukan pengujian, tetapi mereka tidak mengungkapkan masalahnya. Jika kita melihat bahwa sistem menampilkan semua pesan, kita perlu berpikir terlebih dahulu: apa yang akan terjadi jika ada BANYAK dari mereka? Dan lihat.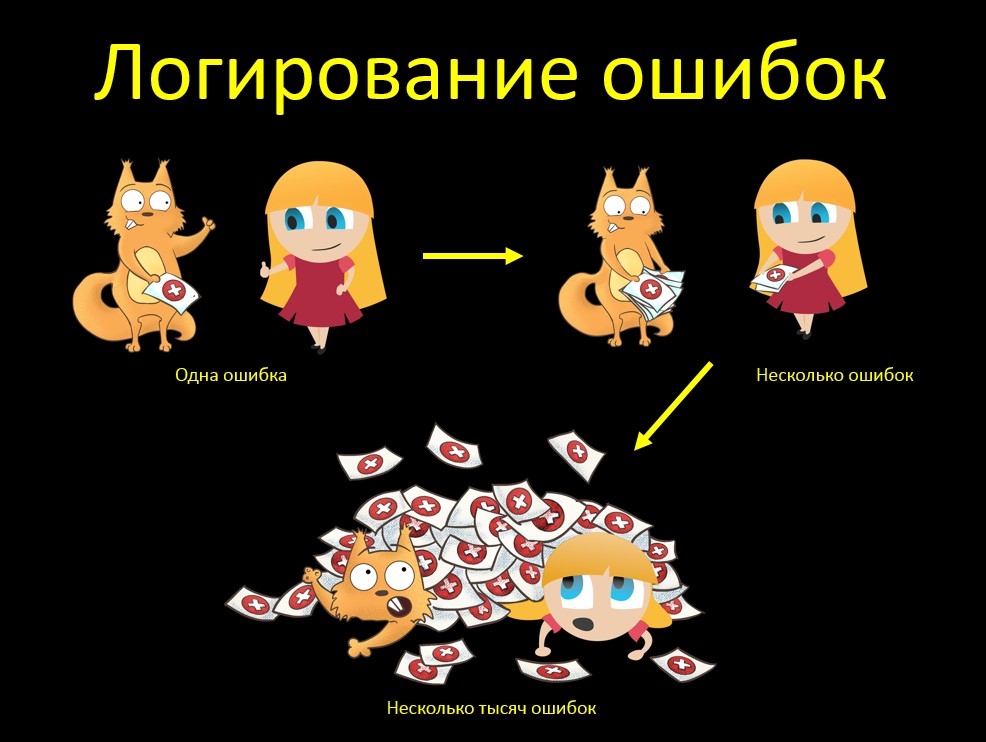
Transliterasi
- , , ? , , ?
=
=?

, ? , , . :
, «»

Oracle RAC
Oracle adalah basis data yang populer. Oracle RAC adalah ketika Anda memiliki banyak instance database. Penting untuk memastikan kelancaran sistem bisnis penting: bahkan jika satu instance rusak, sisanya terus bekerja, pengguna bahkan tidak akan mengetahuinya.
Jika Anda menggunakan Oracle RAC - WAJIB untuk melakukan pengujian beban. Jika Anda tidak memilikinya, maka Anda perlu meminta pelanggan dengan siapa ia berdiri untuk melakukan beban di sisinya.
Di sini muncul pertanyaan - mengapa Anda tidak memilikinya? Sederhana, perangkat keras untuk pengujian biasanya selalu lebih buruk. Dan jika sistem hanya berfokus pada Oracle dan RAC menggunakan satu dari dua puluh klien, maka membelinya untuk pengujian tidak akan menguntungkan, karena RAC sangat mahal. Lebih mudah untuk bernegosiasi dengan klien dan membantunya melakukan tes.
Apa yang terjadi jika pengujian beban tidak dilakukan? Ini adalah contoh dari kehidupan.
Dalam database ada peluang untuk membuat kolom dan mengatakan bahwa itu adalah bidang kenaikan-otomatis. Ini berarti bahwa Anda tidak mengisi bidang sama sekali, basis data menghasilkannya. Ada jalur baru? Saya mencatat nilai "1". Baris baru lainnya? Dia akan memiliki nilai "2". Dan setiap nilai baru akan semakin banyak.
Jadi, misalnya, sangat mudah untuk menghasilkan pengidentifikasi. Anda selalu tahu bahwa id Anda unik. Dan untuk setiap baris baru lebih dari untuk yang sebelumnya. Secara teori ...
Kami memiliki dua pengidentifikasi entitas dalam sistem kami:
- id - pengidentifikasi versi tertentu, bidang penambahan otomatis;
- hid adalah pengenal historis, karena satu entitas selalu konstan dan tidak berubah.
Sebagai hasilnya, Anda dapat memilih menurut versi tertentu, atau Anda dapat memilih dengan menyembunyikan suatu entitas dan melihat seluruh sejarahnya.
Ketika suatu entitas dibuat, id = sembunyikan. Dan kemudian id tumbuh, selalu lebih besar untuk versi baru daripada hid. Oleh karena itu, rumus untuk menentukan versi:
versi = (id - hid) +1Tidak boleh negatif, karena id dibuat oleh database itu sendiri.
Tapi di sini mereka datang kepada kami dengan pertanyaan pada intinya dan menunjukkan catatan dari database. Saya tidak ingat apa pertanyaan itu, dan itu tidak masalah. Saya melihat catatan dan saya tidak bisa mempercayai mata saya: ada versi yang memiliki nilai negatif. Bagaimana bisa ?? Ini tidak mungkin. Ternyata itu mungkin.
Dalam RAC, setiap node memiliki cache sendiri. Dan mungkin saja node tidak punya waktu untuk saling memberi tahu, dan Anda memiliki nomor yang sama dua kali di tablet:
- Membuat entitas. Noda terlihat di cache, berapa nilai terakhir dari bidang kenaikan-otomatis? Ya, 10. Jadi saya akan memberikan pengenal 11.
- Segera, entitas baru tiba di simpul kedua (permintaan datang secara bersamaan dan penyeimbang melemparkan satu di simpul 1, dan yang kedua di simpul 2).
- Node kedua terlihat di cache-nya, berapa nilai terakhir dari field? Ya, 10 (simpul pertama belum berhasil menginformasikan yang kedua bahwa nomor ini diambil). Jadi saya akan memberikan pengenal 11.
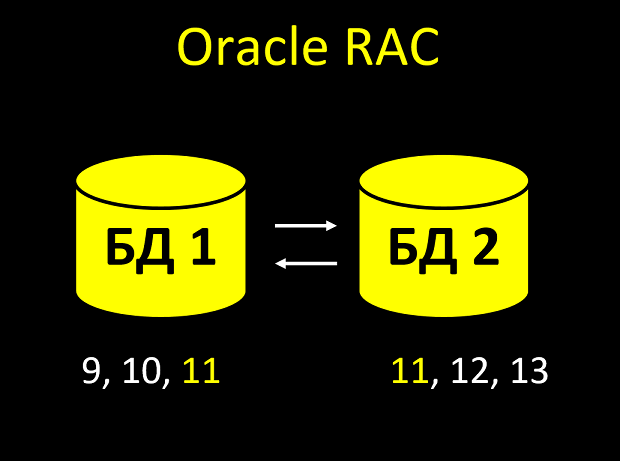
Total yang kami terima bukan nilai unik dari bidang unik. Lagi pula, dengan banyak persimpangan pengidentifikasi seperti itu, tidak akan ada satu atau bahkan dua ... Jika Anda memiliki semua logika bisnis terkait dengan fakta bahwa id selalu unik dan selalu meningkat, itu akan menjadi OH.
Dalam kasus kami, tidak ada bencana yang terjadi, dan pengujian beban di bangku uji pelanggan membantu. Kami menemukan masalah lebih awal, ternyata, versi negatif dari sistem tidak mengganggu kehidupan. Tapi kami menambahkan urutan sekuensing ke skrip pembuatan database, hanya untuk kasus seperti itu.
Moral dari dongeng ini adalah ini - SANGAT penting untuk melakukan pengujian beban pada perangkat keras yang sama yang akan ada di PROD. Semuanya dapat mempengaruhi hasilnya: pengaturan OS itu sendiri, pengaturan database, ya apa saja. Apa yang Anda bahkan tidak curiga.
Tes terlebih dahulu. Dan ingat bahwa tidak semua masalah dapat ditemukan dengan tes fungsional. Dalam contoh ini, tes sederhana tidak akan menemukan bug. Memang, jika Anda membuat entitas secara manual, yaitu, perlahan, semua node basis data akan punya waktu untuk memberi tahu node tetangga, jadi kami tidak akan mendapatkan inkonsistensi.
Tikus kecil
Json kosong
Jika Anda menggunakan pustaka Axis terbuka, coba kirim JSON kosong ke aplikasi. Dia mungkin benar-benar menggantungnya sepenuhnya.
Dan yang paling penting - Anda tidak bisa berbuat apa-apa di pihak Anda! Ini adalah bug di perpustakaan pihak ketiga. Jadi di sini menunggu koreksi resmi, atau mengganti perpustakaan, yang bisa sangat sulit.
Bahkan, bug ini sudah diperbaiki di versi baru Axis. Tampaknya hanya meningkatkan, dan hanya itu! Tapi ... Sistem jarang menggunakan satu perpustakaan pihak ketiga. Biasanya ada beberapa dari mereka, mereka diikat satu di atas yang lain. Untuk memperbaruinya, Anda perlu memperbarui semuanya sekaligus. Perlu untuk melakukan refactoring, karena mereka sekarang bekerja secara berbeda. Sumber daya pengembang harus dialokasikan.
Secara umum, hanya memperbarui versi perpustakaan kadang-kadang membutuhkan rilis lengkap dari pengembang yang keren. Jadi, misalnya, ketika kami pindah ke versi baru Lucene, kami menghabiskan 56 jam untuk tugas itu, ini adalah 7 hari kerja, satu minggu pengembang penuh waktu dan pengujian plus. Tugas itu sendiri terlihat seperti ini, kata arsitek:
Lucene Beralihlah menggunakan PointValues alih-alih Long / IntegerField
Lucene Migration 5 -> 6 dock memiliki klausa tentang menjatuhkan Long (Integer / Double) Field yang mendukung PointValues.
Ketika beralih ke Lucene 6.3.1, saya meninggalkan bidang lama (semua kelas diganti nama dengan penambahan awalan Legacy), karena terjemahan menarik ke tugas yang terpisah.
Anda harus meninggalkan bidang lama dan menggunakan kelas-kelas Long (Integer / Double) Point, yang lebih cepat dan lebih ringan dalam indeks dengan tes. Harus menulis ulang banyak kode.
Tentu! Transisi harus kompatibel ke belakang sehingga pencarian (setidaknya fungsi tombol) tidak terputus dengan peningkatan versi. Ini harus bekerja pada indeks lama (sebelum membangun kembali), dan setelah membangun kembali (pada waktu yang tepat bagi pelanggan), bidang baru harus diambil.
Dan ini hanya pembaruan perpustakaan! Dan untuk meninggalkan satu perpustakaan karena bug di dalamnya umumnya menakutkan untuk membayangkan berapa lama ...
Jadi sangat mungkin bahwa untuk beberapa waktu Anda hanya akan hidup dengan bug. Ketahui tentang dia, tetapi jangan ubah apa pun. Pada akhirnya, "tidak ada yang mengirim permintaan konyol."
Tetapi bagaimanapun juga, Anda setidaknya harus tahu tentang keberadaan bug. Karena jika pengguna mendatangi Anda dan berkata, "Semuanya telah menutup telepon Anda," Anda harus memahami alasannya. Mengingat bahwa log kosong. Karena ini bukan aplikasi Anda macet, semuanya hang pada tahap konversi JSON.
Tampaknya - permintaan kosong! Dan di sini dapat mengarah ke ... Yaitu, bahkan jika Anda tidak tahu bahwa Axis memiliki bug seperti itu, Anda dapat memeriksa JSON kosong, permintaan SOAP kosong. Pada akhirnya, ini adalah contoh yang bagus dari tes nol dalam konteks permintaan JSON.
Ingatlah untuk menguji nol. Dan nilai yang paling kecil adalah tikus kecil, karena ia juga membawa bug, terkadang sangat menakutkan.
Lihat juga:Kelas kesetaraan "Nol-bukan nol" - lebih lanjut tentang pengujian nol
"Moskow" di bidang alamat
Layanan Dadat dapat menstandardisasi alamat - meletakkan alamat dalam satu baris pada komponen granular + menentukan area apartemen, jika ada dalam direktori.
Selama pengujian, bug lucu ditemukan - jika Anda memasukkan kata "Moskow" ke dalam alamat, sistem menentukan area apartemen. Meskipun, sepertinya, di mana apartemen di "alamat" ini?

Saya pikir ini adalah contoh yang bagus dari "tikus kecil." Karena apa yang biasanya diperiksa? Alamat yang biasa, alamat ke jalan, ke rumah ... Bidang kosong. Setiap karakter tunggal - ini dianggap sebagai unit test.
Tetapi jika Anda memasukkan satu huruf, sistem akan menentukan input sebagai sampah lengkap dan menghapus alamat. Itu berperilaku benar, tetapi ini adalah kasus negatif per unit. Ini adalah pemeriksaan panjang bidang eksklusif.
Dan di sini perlu dipikirkan lebih lanjut - apakah ada unit positif? Ada. Satu kata, sistem seperti itu akan menentukan. Dan di sini juga, ada kelas-kelas kesetaraan yang berbeda: bisa berupa kata dari awal alamat (kota), atau bisa dari tengah (jalan). Layak untuk dicoba keduanya. Tetapi jika Anda membatasi diri hanya untuk "unit di bidang teks = satu karakter", Anda tidak akan pernah menemukan bug ini.
Total
Mnemonik ada banyak sekali. Dan menggunakannya bisa membantu Anda. Karena Anda sudah melihat aplikasi Anda untuk yang ke-10, ke-100 ... Anda sudah kehilangan mata, Anda bisa melewatkan kesalahan yang jelas. Dan jika Anda mengambil mnemonik yang ada, maka lihat aplikasi dengan cara baru. Apa yang akan membantu mendeteksi bug baru.
Dan bahkan mnemonik sederhana seperti BMW banyak membantu. Tapi, sepertinya ... Besar, kecil, pikirkan! Nilai batas sederhana. Tetapi mereka harus selalu diingat dan selalu diperiksa! Itu membawa buah-buahan dan berbagai bug.
Dengan menggunakan contoh saya, saya ingin menunjukkan bahwa Anda dapat mencari batas tidak hanya dalam bidang teks atau angka. Mnemonics bekerja di mana-mana: di Oracle RAC, Java, Wildfly, di mana saja! Belajarlah untuk melihat batas-batas di luar pemahaman yang biasa tentang "memasukkan Perang dan Kedamaian ke dalam kotak teks."
Tentu saja, penekanan utama adalah pada "mouse besar", ia membawa bug terbanyak. Justru kasus-kasus seperti itu yang diingat ketika Anda berpikir Anda telah bertemu di proyek Anda.
Tetapi Anda jangan lupa tentang "tikus kecil". Ya, saya dapat mengingat hanya beberapa contoh yang spesifik untuk pekerjaan saya. Tetapi ini tidak berarti bahwa saya tidak menemukan bug pada mouse kecil. Aku menemukannya! Yang ada di bagian contoh umum: 01.01.1900 tanggal, file 1 kb, laporan kosong saat data diisi ...
Perbatasan itu sangat penting. Ingatlah untuk mengujinya. Saya harap contoh saya menginspirasi Anda, dan BMW mnemonics akan selalu muncul di kepala saya ketika menyoroti kelas kesetaraan.
Atau mungkin Anda akan membuat mnemonik sendiri. Yang akan untuk Anda, untuk tim Anda, untuk fitur Anda, untuk proses Anda. Dan itu juga luar biasa, juga sukses. Yang utama itu membantu!
PS adalah kutipan dari
buku saya untuk penguji pemula. Saya juga berbicara tentang mnemonik dalam laporan SQA Days,
video di sini .