Rekan penulis artikel: Mike Cheng
Google Cloud Platform sekarang memiliki gambar mesin virtual dalam portofolionya, yang dirancang khusus untuk mereka yang terlibat dalam Deep Learning. Hari ini kita akan berbicara tentang apa yang diwakili gambar-gambar ini, apa keuntungan yang diberikan pengembang dan peneliti, dan, tentu saja, cara membuat mesin virtual berdasarkan padanya.
Penyimpangan liris: pada saat penulisan, produk masih dalam Beta, masing-masing, tidak ada SLA yang berlaku untuk itu.
Binatang macam apa ini, gambar mesin virtual untuk Deep Learning dari Google?
Gambar mesin virtual untuk Deep Learning dari Google adalah gambar Debian 9 yang, langsung, memiliki semua yang dibutuhkan Deep Learning. Saat ini, ada versi gambar dengan TensorFlow, PyTorch dan gambar untuk keperluan umum. Setiap versi ada dalam edisi hanya untuk CPU dan GPU. Untuk lebih memahami gambar yang Anda butuhkan, saya membuat lembar contekan kecil:
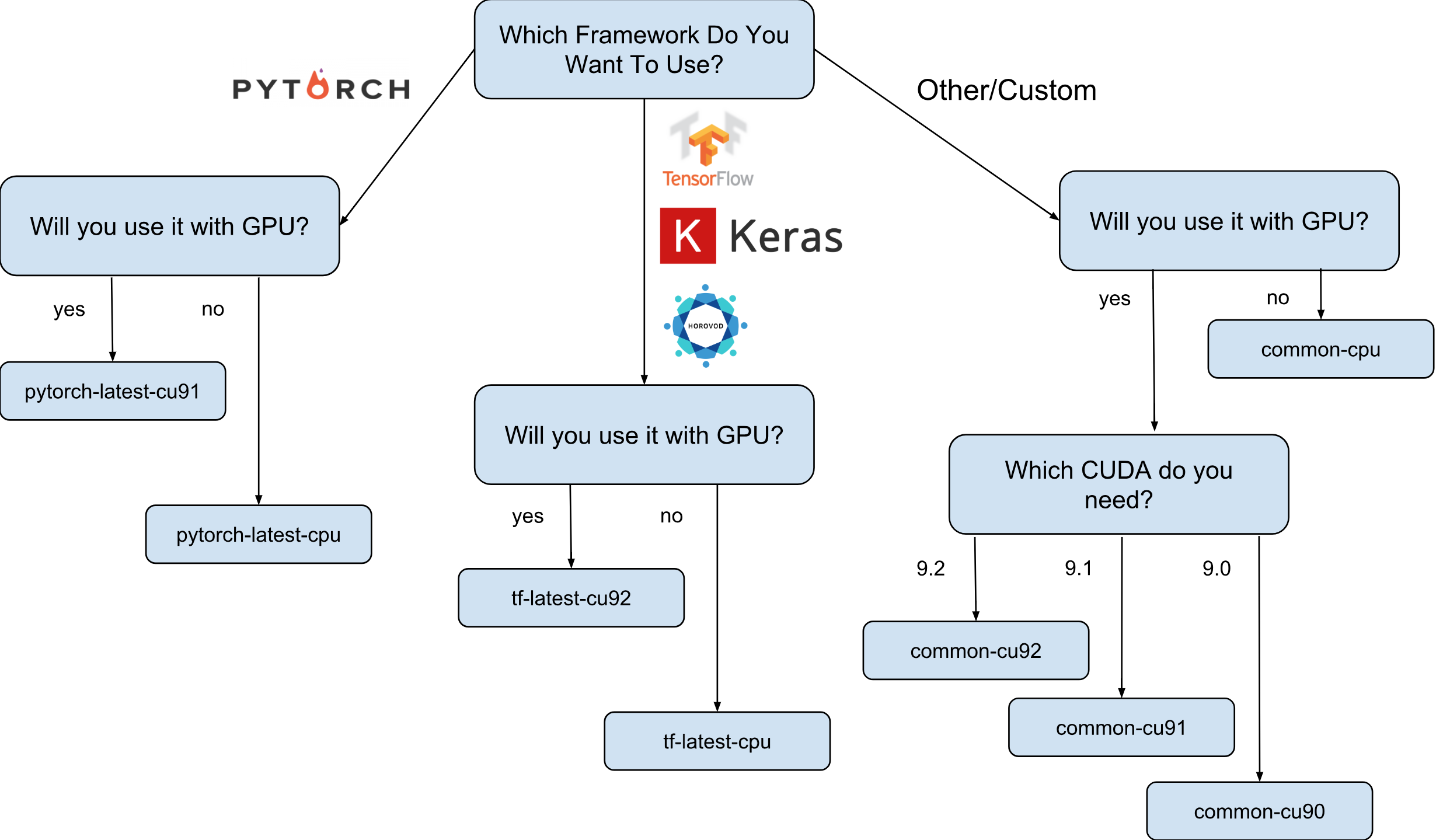
Seperti yang ditunjukkan pada lembar contekan, ada 8 kelompok gambar yang berbeda. Seperti yang telah disebutkan, semuanya didasarkan pada Debian 9.
Apa sebenarnya yang sudah diinstal pada gambar?
Semua gambar memiliki Python 2.7 / 3.5 dengan paket pra-instal berikut:
- numpy
- sklearn
- Scipy
- panda
- nltk
- bantal
- Lingkungan Jupyter (Lab dan Notebook)
- dan masih banyak lagi.
Tumpukan yang dikonfigurasi dari Nvidia (hanya dalam gambar GPU):
- CUDA 9. *
- CuDNN 7.1
- NCCL 2. *
- driver nvidia terbaru
Daftar ini terus diperbarui, jadi tunggu saja di halaman resmi .
Dan mengapa gambar-gambar ini benar-benar dibutuhkan?
Katakanlah Anda perlu melatih model jaringan saraf menggunakan Keras (dengan TensorFlow). Kecepatan belajar penting bagi Anda dan Anda memutuskan untuk menggunakan GPU. Untuk menggunakan GPU, Anda harus menginstal dan mengkonfigurasi tumpukan Nvidia (driver Nvidia + CUDA + CuDNN + NCCL). Tidak hanya proses ini cukup rumit dalam dirinya sendiri (terutama jika Anda bukan seorang insinyur sistem, tetapi seorang peneliti), itu semua lebih rumit oleh fakta bahwa Anda perlu memperhitungkan dependensi biner dari versi Anda dari perpustakaan TensorFlow. Sebagai contoh, distribusi resmi TensorFlow 1.9 dikompilasi dengan CUDA 9.0 dan tidak akan berfungsi jika Anda memiliki tumpukan dengan CUDA 9.1 atau 9.2 yang diinstal. Menyiapkan tumpukan ini bisa menjadi proses yang "menyenangkan", saya pikir tidak ada yang bisa berdebat dengan ini (terutama mereka yang melakukannya).
Sekarang anggaplah bahwa setelah beberapa malam tanpa tidur semuanya sudah diatur dan bekerja. Pertanyaan: konfigurasi ini, yang dapat Anda konfigurasi, apakah ini yang paling optimal untuk perangkat keras Anda? Misalnya, apakah benar bahwa CUDA 9.0 yang terinstal dan paket biner resmi TensorFlow 1.9 menunjukkan kecepatan tercepat pada instance dengan prosesor SkyLake dan satu Volta V100 GPU?
Hampir tidak mungkin untuk menjawab tanpa pengujian dengan versi CUDA lainnya. Untuk menjawab dengan pasti, Anda perlu membangun kembali TensorFlow secara manual dalam berbagai konfigurasi dan menjalankan pengujian Anda. Semua ini harus dilakukan pada perangkat keras yang mahal, yang direncanakan untuk melatih model selanjutnya. Nah, dan yang terakhir, semua pengukuran ini dapat dibuang begitu versi baru TensorFlow atau tumpukan Nvidia dirilis. Dapat dengan aman dinyatakan bahwa sebagian besar peneliti tidak akan melakukan ini dan hanya akan menggunakan perakitan TensorFlow standar, karena tidak memiliki kecepatan optimal.
Di sinilah gambar Deep Learning dari Google muncul di layar. Misalnya, gambar dengan TensorFlow memiliki perakitan TensorFlow sendiri, yang dioptimalkan untuk perangkat keras yang tersedia di Google Cloud Engine. Mereka diuji dengan konfigurasi Nvidia stack yang berbeda dan didasarkan pada yang menunjukkan kinerja tertinggi (spoiler: ini tidak selalu yang terbaru). Baik dan yang paling penting - hampir semua yang Anda butuhkan untuk penelitian sudah diinstal sebelumnya!
Bagaimana saya bisa membuat instance berdasarkan pada salah satu gambar?
Ada dua opsi untuk membuat instance baru berdasarkan gambar-gambar ini:
- Menggunakan UI Web Google Cloud Marketplace
- Menggunakan gcloud
Karena saya penggemar berat terminal dan utilitas CLI, dalam artikel ini saya akan berbicara tentang opsi ini. Selain itu, jika Anda menyukai UI, ada dokumentasi yang cukup bagus yang menjelaskan cara membuat instance menggunakan UI Web .
Sebelum melanjutkan, instal (jika Anda belum menginstal) alat gcloud. Secara opsional, Anda dapat menggunakan Google Cloud Shell , namun perhatikan bahwa fungsi WebPreview di Google Cloud Shell saat ini tidak didukung dan oleh karena itu Anda tidak dapat menggunakan Jupyter Lab atau Notebook di sana.
Langkah selanjutnya adalah memilih keluarga gambar. Saya akan membiarkan diri saya sekali lagi membawa lembar contekan dengan pilihan sekumpulan gambar.
Misalnya, kami menganggap bahwa pilihan Anda jatuh pada tf-latest-cu92, dan kami akan menggunakannya nanti dalam teks.
Tunggu, tetapi bagaimana jika saya memerlukan versi spesifik TensorFlow, daripada yang "terbaru"?
Misalkan kita memiliki proyek yang membutuhkan TensorFlow 1.8, tetapi pada saat yang sama 1.9 telah dirilis dan gambar dalam keluarga terbaru-tf sudah memiliki 1.9. Untuk kasus ini, kami memiliki kumpulan gambar, yang selalu memiliki versi spesifik dari kerangka kerja (dalam kasus kami, tf-1-8-cpu dan tf-1-8-cu92). Keluarga gambar ini akan diperbarui, tetapi versi TensorFlow tidak akan berubah di dalamnya.
Karena ini hanya rilis Beta, sekarang kami hanya mendukung TensorFlow 1.8 / 1.9 dan PyTorch 0.4. Kami berencana untuk mendukung rilis di masa mendatang, tetapi kami tidak dapat pada tahap saat ini dengan jelas menjawab pertanyaan tentang berapa lama versi lama akan didukung.
Bagaimana jika saya ingin membuat cluster atau menggunakan gambar yang sama?
Memang, mungkin ada banyak kasus di mana perlu untuk menggunakan kembali gambar yang sama berulang-ulang (bukan keluarga gambar). Sebenarnya, menggunakan gambar secara langsung hampir selalu merupakan pilihan yang lebih disukai. Sebagai contoh, jika Anda menjalankan sebuah cluster dengan beberapa instance, tidak disarankan untuk menentukan keluarga gambar secara langsung dalam skrip Anda, karena jika keluarga diperbarui pada saat script sedang berjalan, kemungkinan instance cluster yang berbeda akan dibuat dari gambar yang berbeda. (dan mungkin memiliki berbagai versi perpustakaan!). Dalam kasus seperti itu, lebih baik untuk pertama-tama mendapatkan nama tertentu untuk gambar keluarga mereka, dan baru kemudian menggunakan nama tertentu.
Jika Anda tertarik dengan topik ini, Anda dapat melihat artikel saya "Cara menggunakan keluarga gambar dengan benar".
Anda dapat melihat nama gambar terakhir dalam keluarga dengan perintah sederhana:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
Misalkan nama gambar tertentu adalah tf-latest-cu92-1529452792, Anda sudah dapat menggunakannya di mana saja:
Saatnya membuat instance pertama kami!
Untuk membuat instance dari kumpulan gambar, jalankan saja satu perintah sederhana:
export IMAGE_FAMILY="tf-latest-cu92"
Jika Anda menggunakan nama gambar dan bukan keluarga gambar, Anda perlu mengganti “- image-family = $ IMAGE_FAMILY” dengan “- image = $ IMAGE-NAME”.
Jika Anda menggunakan instance dengan GPU, maka Anda perlu memperhatikan keadaan berikut:
Anda harus memilih zona yang benar . Jika Anda membuat instance dengan GPU tertentu, Anda perlu memastikan bahwa jenis GPU ini tersedia di zona di mana Anda membuat instance. Di sini Anda dapat menemukan korespondensi zona dengan tipe GPU. Seperti yang Anda lihat, us-west1-b adalah satu-satunya zona di mana terdapat 3 jenis GPU yang memungkinkan (K80 / P100 / V100).
Pastikan Anda memiliki kuota yang cukup untuk membuat instance dengan GPU . Bahkan jika Anda telah memilih wilayah yang tepat, ini tidak berarti Anda memiliki kuota untuk membuat instance dengan GPU di wilayah ini. Secara default, kuota GPU diatur ke nol di semua wilayah, sehingga semua upaya untuk membuat instance dengan GPU akan gagal. Penjelasan yang baik tentang bagaimana meningkatkan kuota dapat ditemukan di sini .
Pastikan ada cukup GPU di zona untuk memenuhi permintaan Anda . Bahkan jika Anda telah memilih wilayah yang tepat dan Anda memiliki kuota untuk GPU di wilayah ini, ini tidak berarti bahwa ada GPU yang menarik bagi Anda di zona ini. Sayangnya, saya tidak tahu bagaimana lagi Anda dapat memeriksa ketersediaan GPU, kecuali sebagai upaya untuk membuat instance dan melihat apa yang terjadi =)
Pilih jumlah GPU yang benar (tergantung pada jenis GPU) . Faktanya adalah bahwa bendera "akselerator" di tim kami bertanggung jawab untuk jenis dan jumlah GPU yang akan tersedia untuk contoh: i.e. “- akselerator = 'type = nvidia-tesla-v100, count = 8'” akan membuat instance dengan delapan GPU Nvidia Tesla V100 (Volta) yang tersedia. Setiap jenis GPU memiliki daftar nilai hitungan yang valid. Berikut adalah daftar untuk setiap jenis GPU:
- nvidia-tesla-k80, dapat memiliki jumlah: 1, 2, 4, 8
- nvidia-tesla-p100, dapat memiliki jumlah: 1, 2, 4
- nvidia-tesla-v100, dapat memiliki jumlah: 1, 8
Berikan izin Google Cloud untuk menginstal driver Nvidia atas nama Anda pada saat Anda meluncurkan mesin virtual . Pengemudi dari Nvidia adalah suatu keharusan. Untuk alasan di luar ruang lingkup artikel ini, gambar tidak memiliki driver Nvidia yang telah diinstal sebelumnya. Namun, Anda dapat memberi Google Cloud hak untuk menginstalnya atas nama Anda saat pertama kali meluncurkan mesin virtual. Ini dilakukan dengan menambahkan flag “- metadata = 'install-nvidia-driver = True'”. Jika Anda tidak menentukan flag ini, maka pertama kali Anda terhubung melalui SSH, Anda akan diminta untuk menginstal driver.
Sayangnya, proses instalasi driver membutuhkan waktu saat boot pertama, karena perlu mengunduh dan menginstal driver ini (dan ini juga memerlukan reboot contoh). Secara total, ini seharusnya tidak lebih dari 5 menit. Kami akan berbicara sedikit kemudian tentang bagaimana Anda dapat mengurangi waktu boot pertama.
Terhubung ke sebuah instance melalui SSH
Ini lebih sederhana dari lobak dan dapat dilakukan dengan satu perintah:
gcloud compute ssh $INSTANCE_NAME
gcloud akan membuat pasangan kunci dan secara otomatis mengunggahnya ke instance yang baru dibuat, serta membuat pengguna Anda di dalamnya. Jika Anda ingin menjadikan proses ini lebih sederhana, Anda dapat menggunakan fungsi yang menyederhanakan ini juga:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
Omong-omong, Anda dapat menemukan semua fungsi bash gcloud saya di sini . Nah, sebelum kita sampai pada pertanyaan seberapa cepat gambar-gambar ini, atau apa yang bisa dilakukan dengan mereka, izinkan saya mengklarifikasi masalah dengan kecepatan peluncuran contoh.
Bagaimana saya bisa mengurangi waktu mulai pertama?
Secara teknis, waktu peluncuran pertama bukanlah apa-apa. Tetapi Anda bisa:
- buat instance n1-standard-1 termurah dengan satu K80;
- tunggu hingga unduhan pertama selesai;
- verifikasi bahwa driver Nvidia diinstal (ini dapat dilakukan dengan menjalankan "nvidia-smi");
- Hentikan contohnya
- Buat gambar Anda sendiri dari contoh yang dihentikan
- Profit - Semua instance yang dibuat dari gambar Anda akan memiliki waktu peluncuran 15 detik yang legendaris.
Jadi, dari daftar ini kita sudah tahu cara membuat instance baru dan menghubungkannya, kita juga tahu cara memeriksa driver untuk operabilitas. Tetap hanya berbicara tentang cara menghentikan instance dan membuat gambar darinya.
Untuk menghentikan instance, jalankan perintah berikut:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
Dan ini adalah perintah untuk membuat gambar:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
Selamat, sekarang Anda memiliki gambar Anda sendiri dengan driver Nvidia yang diinstal.
Bagaimana dengan Jupyter Lab?
Setelah instans Anda berjalan, langkah logis berikutnya adalah memulai Jupyter Lab untuk langsung ke bisnis :) Dengan gambar baru, ini sangat sederhana. Jupyter Lab sudah berjalan sejak contoh diluncurkan. Yang perlu Anda lakukan hanyalah terhubung ke instance dan meneruskan port tempat Jupyter Lab mendengarkan. Dan ini port 8080. Ini dilakukan dengan perintah berikut:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
Semuanya sudah siap, sekarang Anda cukup membuka browser favorit Anda dan pergi ke http: // localhost: 8080
Seberapa cepat TensorFlow dari gambar?
Pertanyaan yang sangat penting, karena kecepatan pelatihan model adalah uang sungguhan. Namun, jawaban lengkap untuk pertanyaan ini akan menjadi yang terpanjang yang sudah ditulis dalam artikel ini. Jadi Anda harus menunggu artikel selanjutnya :)
Sementara itu, saya akan memanjakan Anda dengan beberapa nomor yang diperoleh dalam percobaan pribadi kecil saya. Jadi, kecepatan pelatihan di ImageNet adalah 6100 gambar per detik (jaringan ResNet-50). Anggaran pribadi saya tidak memungkinkan saya untuk menyelesaikan pelatihan model sepenuhnya, namun, pada kecepatan ini, saya berasumsi bahwa adalah mungkin untuk mencapai akurasi 75% dalam 5 jam dengan sedikit.
Di mana mencari bantuan?
Jika Anda memerlukan informasi tentang gambar baru, Anda dapat:
- ajukan pertanyaan tentang stackoverflow, dengan tag google-dl-platform;
- menulis ke Grup Google publik;
- dapat menulis kepada saya melalui surat atau di twitter .
Umpan balik Anda sangat penting, jika Anda memiliki sesuatu untuk dikatakan tentang gambar, jangan ragu untuk menghubungi saya dengan cara apa pun yang nyaman bagi Anda atau meninggalkan komentar di bawah artikel ini.