Catatan perev. : Artikel ini diterbitkan di blog resmi Kubernetes dan ditulis oleh dua karyawan Intel yang terlibat langsung dalam pengembangan CPU Manager, fitur baru di Kubernetes yang kami tulis dalam rilis 1.8 review. Saat ini (mis., Untuk K8 1.11), fitur ini memiliki status beta, dan membaca lebih lanjut tentang tujuannya nanti di catatan.Publikasi berbicara tentang
CPU Manager , fitur beta di Kubernetes. CPU Manager memungkinkan Anda untuk mendistribusikan beban kerja dengan lebih baik di Kubelet, mis. pada agen host Kubernetes, dengan menugaskan CPU khusus untuk wadah perapian tertentu.
Kedengarannya bagus! Tetapi apakah Manajer CPU membantu saya?
Tergantung pada beban kerja. Satu-satunya simpul komputasi di kluster Kubernetes dapat menjalankan banyak perapian, dan beberapa di antaranya dapat menjalankan beban yang aktif dalam konsumsi CPU. Dalam skenario ini, perapian dapat bersaing untuk sumber daya proses yang tersedia di simpul ini. Ketika kompetisi ini meningkat, beban kerja dapat beralih ke CPU lain tergantung pada apakah itu
dibatasi di bawah dan CPU mana yang tersedia pada saat perencanaan. Selain itu, mungkin ada kasus di mana beban kerja sensitif terhadap konteks switch. Dalam semua skenario ini, kinerja beban kerja mungkin terpengaruh.
Jika beban kerja Anda sensitif terhadap skenario seperti itu, Anda dapat mengaktifkan CPU Manager untuk memberikan isolasi kinerja yang lebih baik dengan mengalokasikan CPU tertentu ke beban.
CPU Manager dapat membantu memuat dengan fitur-fitur berikut:
- Sensitif terhadap efek pelambatan CPU
- peka terhadap sakelar konteks;
- cache prosesor ketinggalan;
- Mendapatkan manfaat dari membagi sumber daya prosesor (mis., Cache data dan instruksi);
- memori yang peka-memori di antara soket prosesor (penjelasan terperinci tentang apa yang ada dalam pikiran penulis diberikan pada Unix Stack Exchange - sekitar terjemahan. ) ;
- hyperthread sensitif dari atau membutuhkan inti fisik yang sama dari CPU.
Ok! Bagaimana cara menggunakannya?
Menggunakan CPU Manager itu mudah. Pertama,
aktifkan itu menggunakan Kebijakan Statis di Kubelet yang berjalan pada compute nodes of the cluster. Kemudian konfigurasikan kelas
Jaminan Kualitas Layanan (QoS) untuk perapian. Meminta bilangan bulat dari inti CPU (mis.
1000m atau
4000m ) untuk wadah yang membutuhkan inti khusus. Buat dengan metode sebelumnya (misalnya,
kubectl create -f pod.yaml ) ... dan voila - CPU Manager akan menetapkan core prosesor khusus untuk setiap wadah perapian sesuai dengan kebutuhan CPU mereka.
apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M"
Spesifikasi perapian yang meminta 2 CPU khusus.Bagaimana cara kerja Manajer CPU?
Kami mempertimbangkan tiga jenis kontrol sumber daya CPU yang tersedia di sebagian besar distribusi Linux, yang akan relevan untuk Kubernetes dan tujuan publikasi ini. Dua yang pertama adalah bagian CFS (berapa bagian dari waktu CPU saya yang “jujur” dalam sistem) dan kuota CFS (berapa waktu CPU maksimum yang dialokasikan untuk saya selama periode tersebut). CPU Manager juga menggunakan yang ketiga, yang disebut CPU affinity (di mana CPU logis saya diizinkan untuk melakukan perhitungan).
Secara default, semua pod dan kontainer yang berjalan pada node cluster Kubernetes dapat berjalan di kernel sistem yang tersedia. Jumlah total saham dan kuota yang ditetapkan dibatasi oleh sumber daya CPU yang dicadangkan untuk
Kubernet dan daemon sistem . Namun, batas waktu CPU yang digunakan dapat ditentukan dengan menggunakan
batas CPU dalam spesifikasi perapian . Kubernetes menggunakan
kuota CFS untuk menegakkan batas CPU pada wadah perapian.
Saat Anda mengaktifkan Manajer CPU dengan kebijakan
statis , ia mengelola kumpulan CPU khusus. Awalnya, kumpulan ini berisi seluruh CPU dari node komputasi. Ketika Kubelet membuat sebuah wadah di perapian dengan sejumlah inti prosesor khusus, CPU yang ditugaskan untuk wadah ini dialokasikan untuknya seumur hidup dan dikeluarkan dari kumpulan bersama. Beban dari kontainer yang tersisa ditransfer dari inti khusus ini ke yang lain.
Semua wadah tanpa CPU khusus (
Burstable ,
BestEffort, dan
Dijamin dengan CPU non-integer ) berjalan di kernel yang tersisa di kumpulan bersama. Ketika sebuah wadah dengan CPU khusus berhenti bekerja, kernelnya kembali ke kumpulan bersama.
Lebih detail, silakan ...

Diagram di atas menunjukkan anatomi dari Manajer CPU. Ia menggunakan metode
UpdateContainerResources dari Container Runtime Interface (CRI) untuk mengubah CPU tempat wadah dijalankan.
Manajer secara berkala mencocokkan
cgroupfs dengan kondisi saat ini dari sumber daya CPU untuk setiap wadah yang berjalan.
Manajer CPU menggunakan
Kebijakan untuk memutuskan alokasi inti CPU. Dua kebijakan diterapkan:
Tidak Ada dan
Statis . Secara default, dimulai dengan Kubernetes versi 1.10, diaktifkan dengan kebijakan
None .
Kebijakan
statis menetapkan wadah pod yang dialokasikan CPU untuk kelas QoS yang dijamin, yang meminta jumlah inti bilangan bulat. Kebijakan
Static mencoba untuk menunjuk CPU dengan cara topologi terbaik dan dalam urutan berikut:
- Tetapkan semua CPU ke satu soket prosesor, jika tersedia dan wadah membutuhkan CPU dalam jumlah setidaknya seluruh soket CPU.
- Tetapkan semua CPU logis (hyperthreads) dari satu inti CPU fisik, jika tersedia, dan wadah memerlukan CPU setidaknya seluruh inti.
- Tetapkan CPU logis yang tersedia dengan preferensi untuk CPU dari satu soket.
Bagaimana cara Manajer CPU meningkatkan isolasi komputasi?
Dengan kebijakan
Statis diaktifkan di CPU Manager, beban kerja dapat berkinerja lebih baik karena salah satu alasan berikut:
- CPU khusus dapat ditugaskan ke wadah dengan beban kerja, tetapi tidak untuk wadah lain. Wadah ini (lainnya) tidak menggunakan sumber daya CPU yang sama. Sebagai hasilnya, kami mengharapkan kinerja yang lebih baik karena isolasi dalam kasus munculnya "agresor" (proses menuntut CPU - kira - kira Terjemahkan. ) Atau beban kerja yang berdekatan.
- Ada sedikit kompetisi untuk sumber daya yang digunakan oleh beban kerja, karena kita dapat membagi CPU dengan beban kerja itu sendiri. Sumber daya ini tidak hanya mencakup CPU, tetapi juga hierarki cache dan bandwidth memori. Ini meningkatkan kinerja beban kerja keseluruhan.
- Manajer CPU menetapkan CPU dalam urutan topologi berdasarkan pilihan terbaik yang tersedia. Jika seluruh soket gratis, ia akan menetapkan semua CPU-nya ke beban kerja. Ini meningkatkan kinerja beban kerja karena kurangnya lalu lintas di antara soket.
- Kontainer dalam pod dengan QoS yang Dijamin tunduk pada batas kuota CFS. Beban kerja yang cenderung meledak tiba-tiba dapat direncanakan dan melebihi kuota mereka sebelum akhir periode yang ditentukan, sebagai akibatnya mereka diperlambat . CPU yang terlibat saat ini dapat memiliki pekerjaan yang signifikan dan tidak terlalu berguna. Namun, wadah tersebut tidak akan mengalami pelambatan CFS ketika kuota CPU dilengkapi dengan kebijakan alokasi CPU khusus.
Ok! Apakah Anda punya hasil?
Untuk melihat peningkatan kinerja dan isolasi yang disediakan oleh masuknya CPU Manager di Kubelet, kami melakukan percobaan pada node komputasi dengan dua soket (Intel Xeon CPU E5-2680 v3) dan diaktifkan HyperShreading. Node terdiri dari 48 CPU logis (24 core fisik, masing-masing dengan hyperthreading). Manfaat kinerja dan isolasi Manajer CPU yang ditangkap oleh tolok ukur dan beban kerja nyata dalam tiga skenario berbeda ditunjukkan di bawah ini.
Bagaimana cara mengartikan grafik?
Untuk setiap skenario, grafik ditampilkan (
diagram rentang , plot kotak) yang menggambarkan waktu eksekusi yang dinormalisasi dan variabilitasnya ketika memulai benchmark atau beban nyata dengan Manajer CPU yang hidup dan mati. Waktu berjalan dinormalisasi ke peluncuran berkinerja terbaik (1,00 pada sumbu Y mewakili waktu startup terbaik: semakin rendah nilai grafik, semakin baik). Ketinggian plot pada grafik menunjukkan variabilitas dalam kinerja. Misalnya, jika situs tersebut berupa garis, maka tidak ada variasi dalam kinerja untuk peluncuran ini. Di daerah-daerah ini sendiri, garis tengah adalah median, atas adalah persentil ke-75, dan bawah adalah persentil ke-25. Ketinggian plot (mis., Perbedaan antara persentil ke-75 dan ke-25) didefinisikan sebagai rentang interkuartil (IQR). "Moustache" menunjukkan data di luar interval ini, dan poin menunjukkan pencilan. Emisi didefinisikan sebagai data apa pun yang berbeda dari IQR sebesar 1,5 kali - kurang atau lebih dari kuartil yang sesuai. Setiap percobaan dilakukan 10 kali.
Perlindungan Agresif
Kami meluncurkan enam benchmark'ov dari
serangkaian PARSEC (beban kerja - "korban")
[lebih lanjut tentang beban kerja korban dapat dibaca, misalnya, di sini - kira - kira. perev. ] di sebelah wadah memuat CPU ("agresor" beban kerja) dengan Manajer CPU dihidupkan dan dimatikan.
Kontainer agresor diluncurkan
seperti di bawah dengan kelas QoS
Burstable yang meminta 23 CPU flag
--cpus 48 . Benchmark dijalankan
sebagai pod dengan kelas QoS yang
Dijamin , yang membutuhkan satu set CPU dari soket penuh (mis. 24 CPU pada sistem ini). Grafik di bawah ini menunjukkan waktu mulai pod yang dinormalisasi dengan patokan di sebelah aggressor pod, dengan kebijakan
Static Manager CPU dan tanpa itu. Dalam semua kasus pengujian, Anda dapat melihat peningkatan kinerja dan penurunan variabilitas kinerja dengan kebijakan diaktifkan.

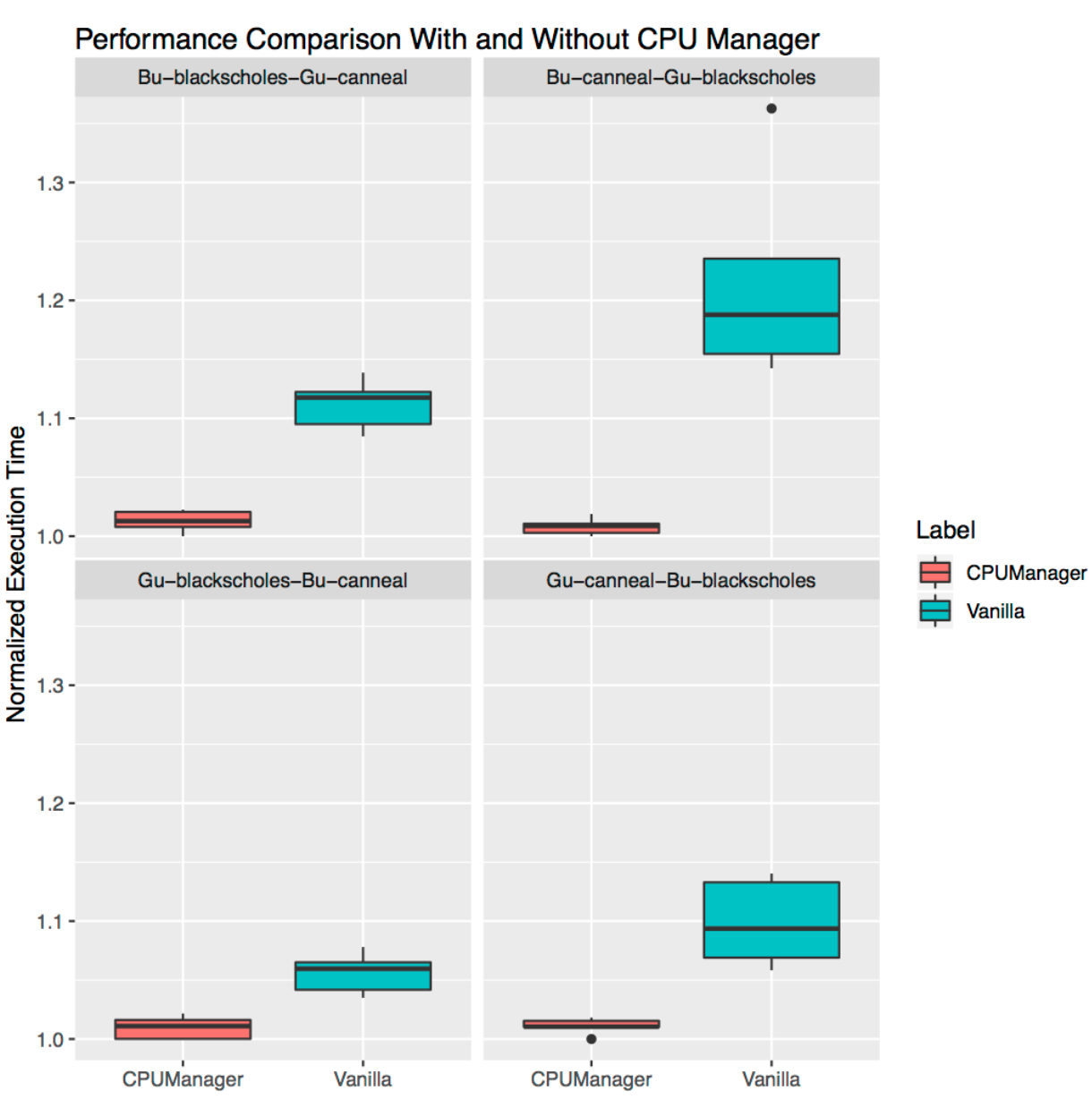
Isolasi untuk beban yang berdekatan
Ini menunjukkan betapa bermanfaatnya CPU Manager untuk banyak beban kerja bersama. Diagram rentang di bawah ini menunjukkan kinerja dua tolok ukur dari set
PARSEC (
Blackscholes dan
Canneal ) yang diluncurkan untuk kelas QoS
Guaranteed (Gu) dan
Burstable (Bu) yang berdekatan satu sama lain, dengan kebijakan
Statis dihidupkan dan dimatikan.
Mengikuti searah jarum jam dari grafik kiri atas, kita melihat kinerja
Blackscholes untuk Bu QoS (kiri atas),
Canneal untuk Bu QoS (kanan atas),
Canneal untuk Gu QoS (kanan bawah) dan
Blackscholes untuk Gu QoS (kiri bawah). Pada setiap grafik, mereka berada (searah jarum jam lagi) bersama dengan
Canneal untuk Gu QoS (kiri atas),
Blackscholes untuk Gu QoS (kanan atas),
Blackscholes untuk Bu QoS (kanan bawah) dan
Canneal untuk Bu QoS (kiri bawah) sesuai. Misalnya,
grafik Bu-blackscholes-Gu-canneal (kiri atas) menunjukkan kinerja untuk
Blackscholes yang berjalan dengan Bu QoS dan terletak di sebelah
Canneal dengan kelas Gu QoS. Dalam setiap kasus, di bawah dengan kelas Gu QoS membutuhkan inti soket penuh (mis. 24 CPU), dan di bawah dengan kelas Bu QoS - 23 CPU.
Ada kinerja yang lebih baik dan lebih sedikit variasi dalam kinerja untuk kedua beban kerja yang berdekatan di semua tes. Misalnya, lihat
Bu-blackscholes-Gu-canneal (kiri atas) dan
Gu-canneal-Bu-blackscholes (kanan bawah). Mereka menunjukkan kinerja menjalankan
Blackscholes dan
Canneal dengan CPU Manager hidup dan mati. Dalam hal ini,
Canneal menerima lebih banyak core berdedikasi dari CPU Manager, karena itu milik kelas Gu QoS dan meminta nomor integer CPU core. Namun,
Blackscholes juga mendapatkan serangkaian CPU khusus, karena ini adalah satu-satunya beban kerja di kumpulan bersama. Akibatnya, baik
Blackscholes dan
Canneal memanfaatkan isolasi beban saat menggunakan CPU Manager.
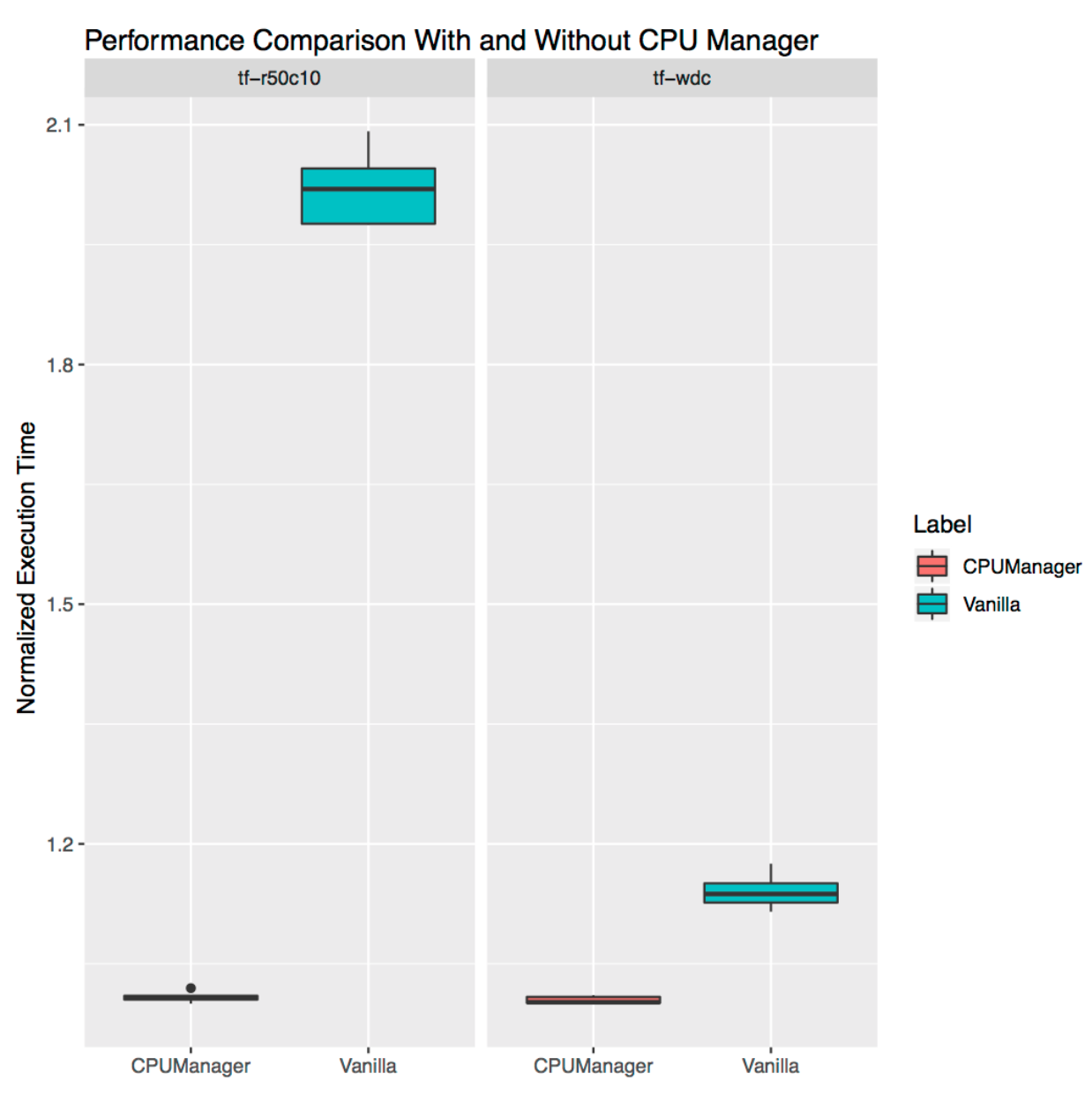
Isolasi untuk beban bebas
Ini menunjukkan betapa bermanfaatnya CPU Manager untuk beban kerja mandiri dari kehidupan nyata. Kami mengambil dua beban dari model
resmi TensorFlow :
lebar dan dalam dan
ResNet . Set data khas digunakan untuk mereka (sensus dan CIFAR10, masing-masing). Dalam kedua kasus,
perapian (
lebar dan dalam ,
ResNet ) membutuhkan 24 CPU, yang sesuai dengan soket penuh. Seperti yang ditunjukkan dalam grafik, dalam kedua kasus CPU Manager menyediakan isolasi yang lebih baik.
Keterbatasan
Pengguna mungkin ingin mendapatkan CPU yang dialokasikan pada soket yang dekat dengan bus yang terhubung ke perangkat eksternal seperti akselerator atau kartu jaringan berkinerja tinggi untuk menghindari lalu lintas antar soket. Jenis konfigurasi ini belum didukung di CPU Manager. Karena Manajer CPU memberikan alokasi CPU terbaik yang mungkin dimiliki soket atau inti fisik, maka CPU ini sensitif terhadap kasus-kasus ekstrem dan dapat menyebabkan fragmentasi. CPU Manager tidak memperhitungkan parameter boot kernel Linux
isolcpus , meskipun ia digunakan sebagai praktik yang populer untuk beberapa kasus
(untuk detail lebih lanjut tentang parameter ini, lihat, misalnya, di sini - kira - kira Terjemahkan. ) .
PS dari penerjemah
Baca juga di blog kami: