
Dalam beberapa tahun terakhir, topik kecerdasan buatan dan pembelajaran mesin telah berhenti menjadi sesuatu untuk orang-orang dari dunia fiksi dan telah dengan kuat memasuki kehidupan sehari-hari. Jejaring sosial menawarkan untuk menghadiri acara-acara yang menarik bagi kami, mobil-mobil di jalanan belajar bergerak tanpa sopir, dan seorang asisten suara di telepon memberi tahu kapan lebih baik meninggalkan rumah untuk menghindari kemacetan lalu lintas dan apakah akan membawa payung bersama Anda.
Dalam artikel ini, kami akan mempertimbangkan alat pembelajaran mesin yang ditawarkan oleh pengembang Apple, menganalisis apa yang ditunjukkan perusahaan baru di bidang ini di WWDC18, dan mencoba memahami bagaimana menerapkan semua ini ke dalam praktik.
Pembelajaran mesin
Jadi, pembelajaran mesin adalah proses di mana suatu sistem, menggunakan algoritma analisis data tertentu dan memproses sejumlah besar contoh, mengidentifikasi pola dan menggunakannya untuk memprediksi karakteristik data baru.
Pembelajaran mesin lahir dari teori bahwa komputer dapat belajar sendiri, belum diprogram untuk melakukan tindakan tertentu. Dengan kata lain, tidak seperti program konvensional dengan instruksi yang telah ditentukan untuk menyelesaikan masalah tertentu, pembelajaran mesin memungkinkan sistem untuk belajar bagaimana mengenali pola secara independen dan membuat prediksi.
BNNS dan CNN
Apple telah menggunakan teknologi pembelajaran mesin pada perangkatnya selama beberapa waktu: Mail mengidentifikasi email spam, Siri membantu Anda dengan cepat menemukan jawaban atas pertanyaan Anda, Foto mengenali wajah dalam gambar.
Di WWDC16, perusahaan memperkenalkan dua API berbasis jaringan saraf - Basic Neural Network Subroutines (BNNS) dan Convolutional Neural Networks (CNN). BNNS adalah bagian dari sistem Accelerate, yang merupakan dasar untuk melakukan perhitungan cepat pada CPU, dan CNN adalah perpustakaan Metal Performance Shaders yang menggunakan GPU. Anda dapat mempelajari lebih lanjut tentang teknologi ini, misalnya, di sini .
Core ML dan Turi Create
Tahun lalu, Apple mengumumkan kerangka kerja yang sangat memudahkan bekerja dengan teknologi pembelajaran mesin - Core ML. Ini didasarkan pada gagasan untuk mengambil model data pra-terlatih dan mengintegrasikannya ke dalam aplikasi Anda hanya dalam beberapa baris kode.
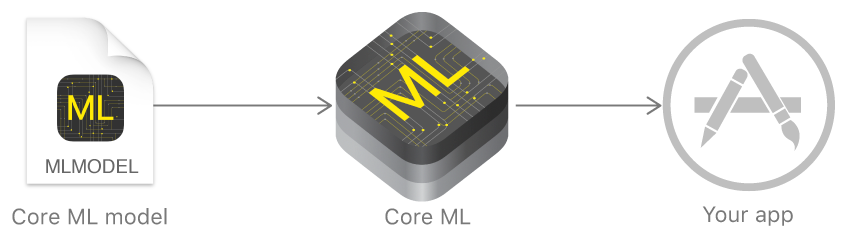
Menggunakan Core ML, Anda dapat mengimplementasikan banyak fungsi:
- definisi objek dalam foto dan video;
- input teks prediksi;
- pelacakan wajah dan pengenalan;
- analisis gerak;
- definisi barcode;
- pemahaman dan pengakuan teks;
- pengenalan gambar waktu nyata;
- stilisasi gambar;
- dan masih banyak lagi.
Core ML, pada gilirannya, menggunakan Metal tingkat rendah, Mempercepat dan BNNS, dan karenanya hasil perhitungannya sangat cepat.
Kernel mendukung jaringan saraf, model linier umum, rekayasa fitur, algoritma pengambilan keputusan berbasis pohon (ansambel pohon), mendukung metode mesin vektor, model pipa.
Tetapi Apple pada awalnya tidak menunjukkan teknologi sendiri untuk membuat dan melatih model, tetapi hanya membuat konverter untuk kerangka kerja populer lainnya: Caffe, Keras, scikit-learn, XGBoost, LIBSVM.
Menggunakan alat pihak ketiga seringkali bukan tugas yang paling mudah, model yang dilatih cukup besar, dan pelatihan itu sendiri membutuhkan banyak waktu.
Pada akhir tahun, perusahaan memperkenalkan Turi Create - sebuah kerangka kerja model pembelajaran yang ide utamanya adalah kemudahan penggunaan dan dukungan untuk sejumlah besar skenario - klasifikasi gambar, definisi objek, sistem rekomendasi, dan banyak lainnya. Tapi Turi Create, meskipun relatif mudah digunakan, hanya mendukung Python.
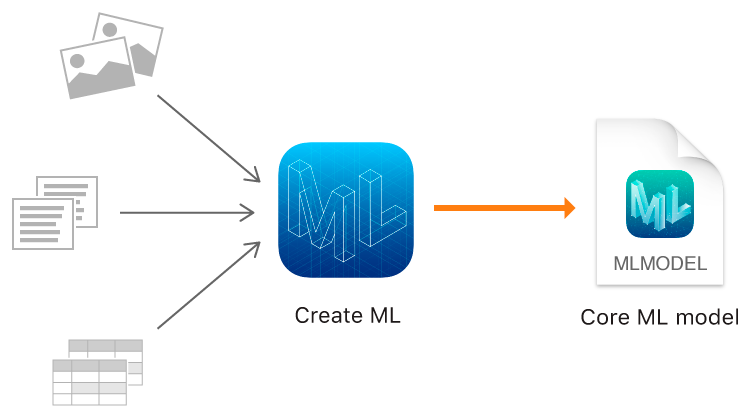
Buat ML
Dan tahun ini, Apple, selain Core ML 2, akhirnya menunjukkan alatnya sendiri untuk model pelatihan - kerangka Buat ML menggunakan teknologi asli Apple - Xcode dan Swift.
Ini bekerja cepat, dan membuat model model dengan Create ML sangat mudah.
Di WWDC, kinerja mengesankan Buat ML dan Core ML 2 diumumkan menggunakan aplikasi Memrise sebagai contoh. Jika sebelumnya butuh 24 jam untuk melatih satu model menggunakan 20 ribu gambar, maka Buat ML mengurangi waktu ini menjadi 48 menit pada MacBook Pro dan hingga 18 menit pada iMac Pro. Ukuran model yang dilatih menurun dari 90MB menjadi 3MB.
Buat ML memungkinkan Anda menggunakan gambar, teks, dan objek terstruktur sebagai tabel, misalnya, sebagai sumber data.
Klasifikasi gambar
Pertama, mari kita lihat bagaimana klasifikasi gambar bekerja. Untuk melatih model, kita memerlukan set data awal: kita mengambil tiga kelompok foto hewan: anjing, kucing dan burung dan mendistribusikannya ke folder dengan nama yang sesuai, yang akan menjadi nama-nama kategori model. Setiap grup berisi 100 gambar dengan resolusi hingga 1920 × 1080 piksel dan ukuran hingga 1Mb. Foto harus berbeda mungkin sehingga model yang dilatih tidak bergantung pada tanda-tanda seperti warna pada gambar atau ruang di sekitarnya.
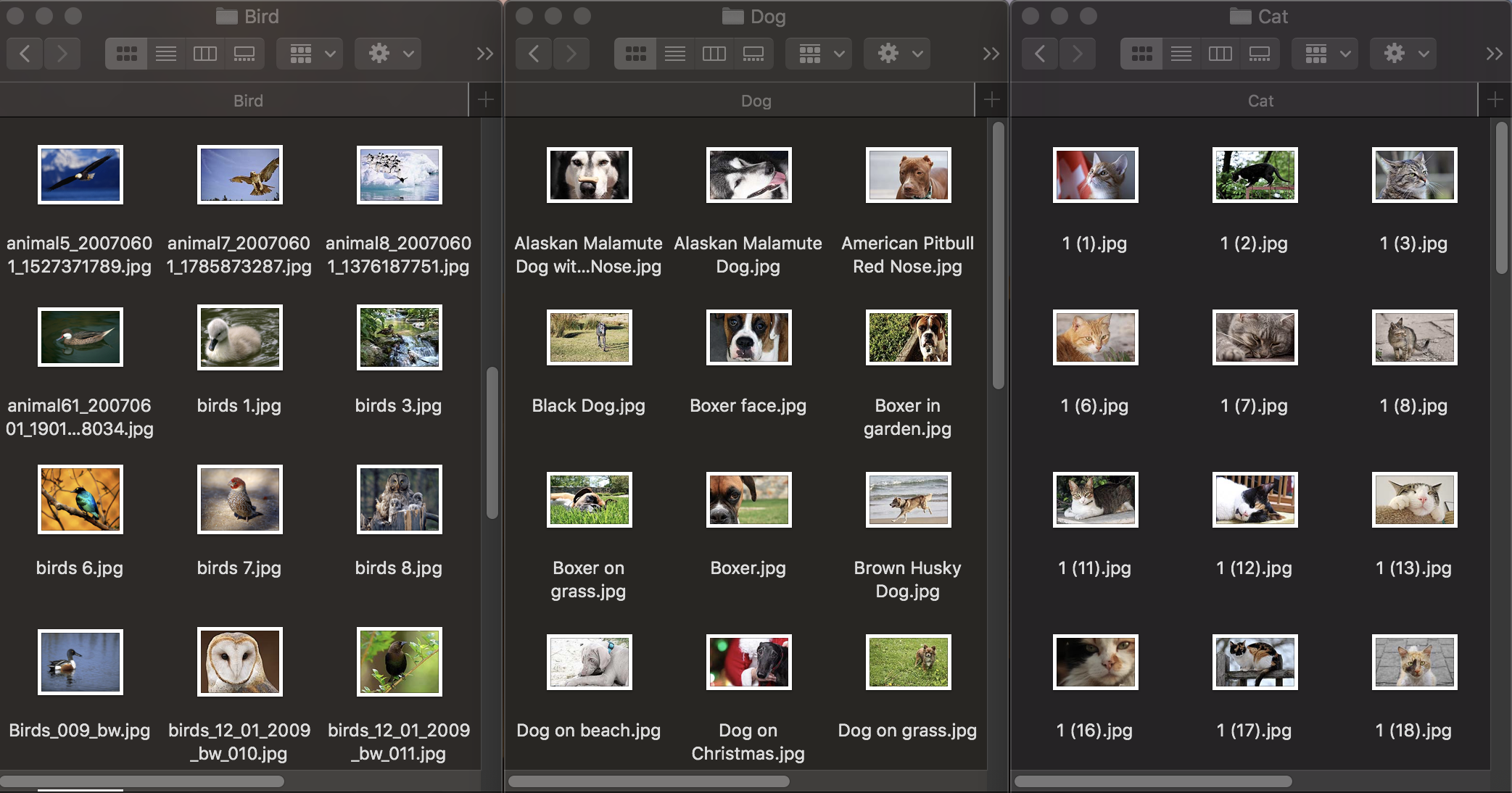
Juga, untuk memeriksa seberapa baik model terlatih menangani pengenalan objek, Anda memerlukan kumpulan data uji - gambar yang tidak ada dalam dataset asli.
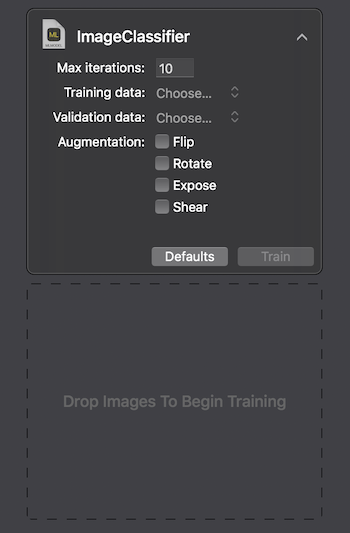
Apple menyediakan dua cara untuk berinteraksi dengan Create ML: menggunakan UI pada MacOS Playground Xcode dan secara terprogram menggunakan CreateMLUI.framework dan CreateML.framework. Dengan menggunakan metode pertama, cukup menulis beberapa baris kode, mentransfer gambar yang dipilih ke area yang ditentukan, dan menunggu sementara model belajar.

Pada Macbook Pro 2017 dalam konfigurasi maksimum, pelatihan membutuhkan 29 detik untuk 10 iterasi, dan ukuran model yang dilatih adalah 33Kb. Itu terlihat mengesankan.
Mari kita coba mencari tahu bagaimana kita berhasil mencapai indikator seperti itu dan apa yang "di bawah tenda".
Tugas mengklasifikasikan gambar adalah salah satu penggunaan paling populer dari jaringan saraf convolutional. Pertama, ada baiknya menjelaskan apa itu.
Seseorang, melihat gambar binatang, dapat dengan cepat menghubungkannya dengan kelas tertentu berdasarkan fitur apa pun yang membedakan. Jaringan saraf bertindak dengan cara yang sama dengan mencari karakteristik dasar. Mengambil array awal piksel sebagai input, ia secara berurutan meneruskan informasi melalui kelompok lapisan convolutional dan membangun abstraksi yang semakin kompleks. Pada setiap lapisan berikutnya, ia belajar untuk menyorot fitur tertentu - pertama ini adalah garis, lalu set garis, bentuk geometris, bagian tubuh, dan sebagainya. Pada lapisan terakhir kita mendapatkan kesimpulan dari kelas atau kelompok kelas yang mungkin.
Dalam kasus Buat ML, pelatihan jaringan saraf tidak dilakukan dari awal. Kerangka kerja ini menggunakan jaringan saraf yang sebelumnya dilatih pada kumpulan data besar, yang sudah mencakup sejumlah besar lapisan dan memiliki akurasi tinggi.
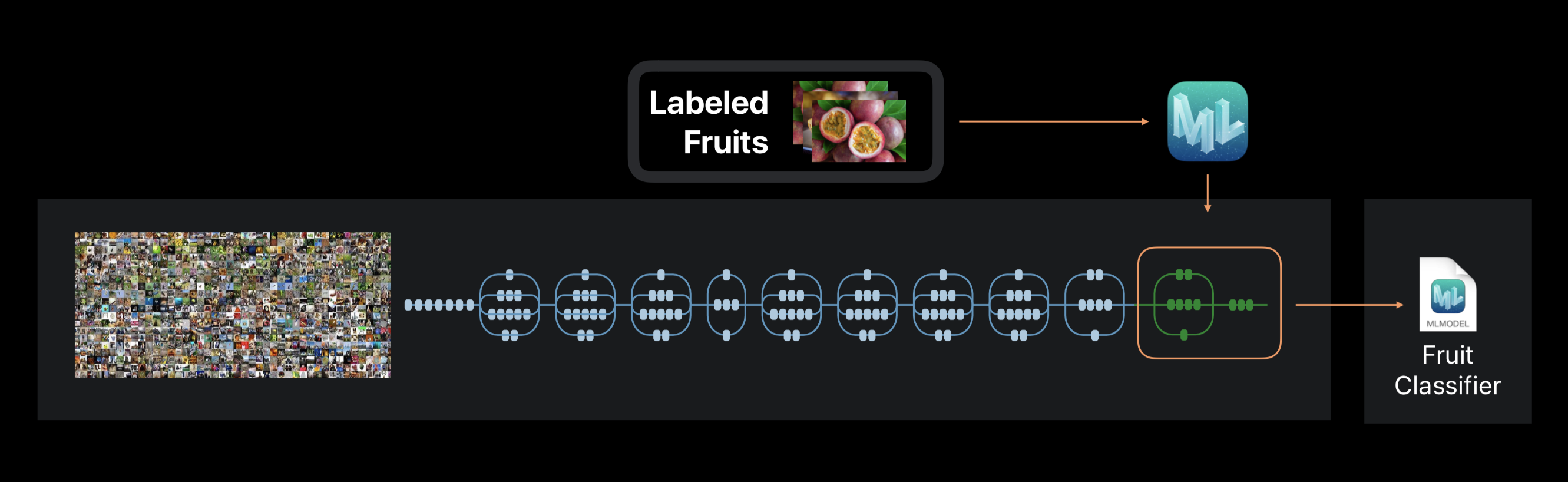
Teknologi ini disebut transfer learning. Dengannya, Anda dapat mengubah arsitektur jaringan pra-terlatih sehingga cocok untuk memecahkan masalah baru. Jaringan yang diubah kemudian dilatih tentang dataset baru.
Buat ML selama ekstrak pelatihan dari foto sekitar 1000 fitur khas. Ini bisa berupa objek, warna tekstur, lokasi mata, ukuran, dan banyak lainnya.
Perlu dicatat bahwa set data awal yang digunakan untuk melatih jaringan saraf yang digunakan, seperti milik kami, mungkin berisi foto-foto kucing, anjing, dan burung, tetapi kategori ini tidak dialokasikan secara khusus. Semua kategori membentuk hierarki. Oleh karena itu, sangat tidak mungkin untuk menerapkan jaringan ini dalam bentuk murni - perlu untuk melatihnya kembali pada data kami.
Pada akhir proses, kami melihat seberapa akurat model kami dilatih dan diuji setelah beberapa iterasi. Untuk meningkatkan hasil, kami dapat menambah jumlah gambar dalam dataset asli atau mengubah jumlah iterasi.
Selanjutnya, kita dapat menguji model sendiri pada set data uji. Gambar di dalamnya harus unik, mis. Jangan masukkan set sumber.
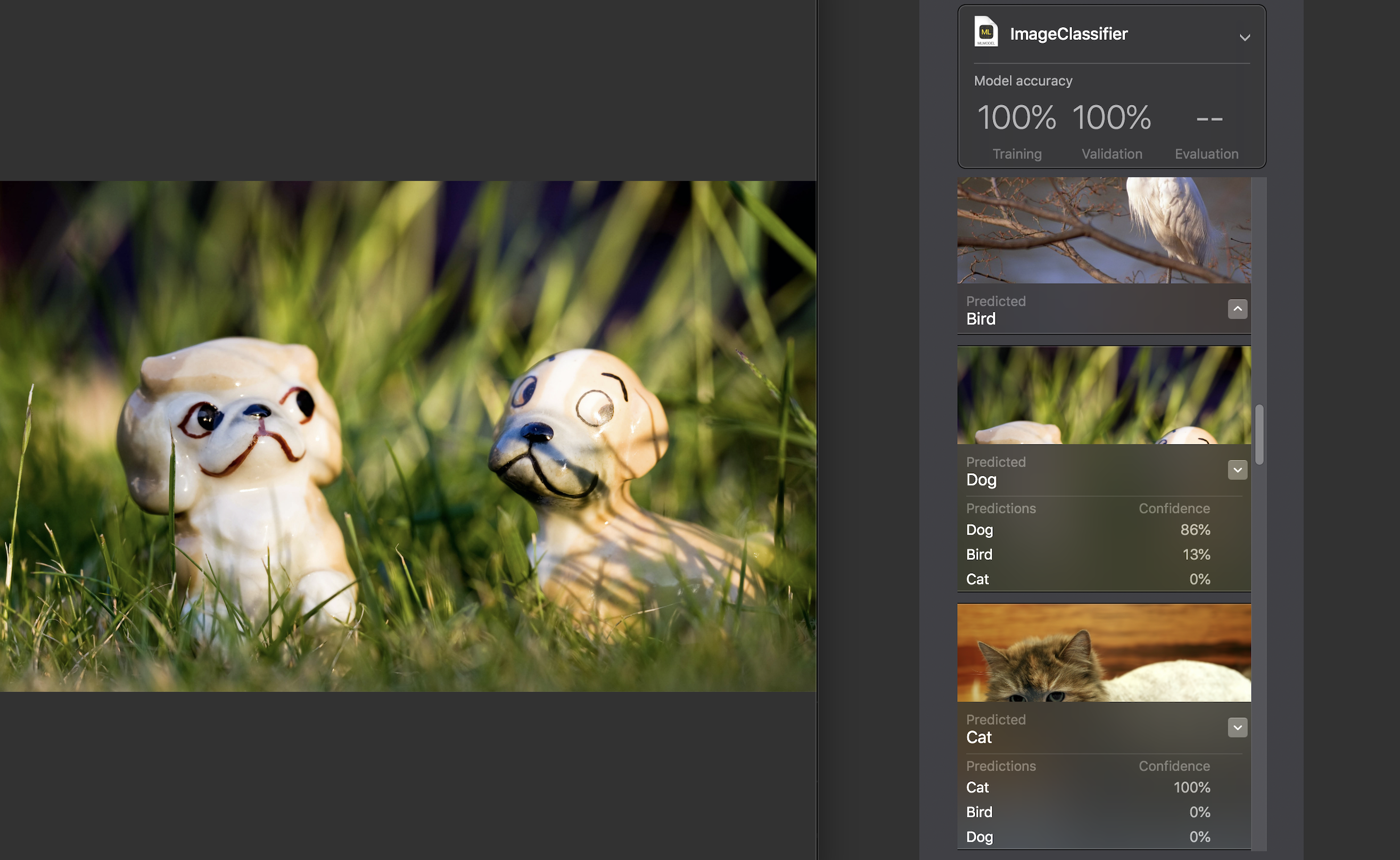
Untuk setiap gambar, indikator kepercayaan diri ditampilkan - seberapa akurat dengan bantuan model kami, kategori itu dikenali.
Untuk hampir semua foto, dengan pengecualian langka, angka ini adalah 100%. Saya secara khusus menambahkan gambar yang Anda lihat di atas ke dataset uji, dan, seperti yang Anda lihat, Buat ML yang dikenali di dalamnya 86% anjing dan 13% burung.
Pelatihan model selesai, dan yang tersisa bagi kami adalah menyimpan file * .mlmodel dan menambahkannya ke proyek Anda.
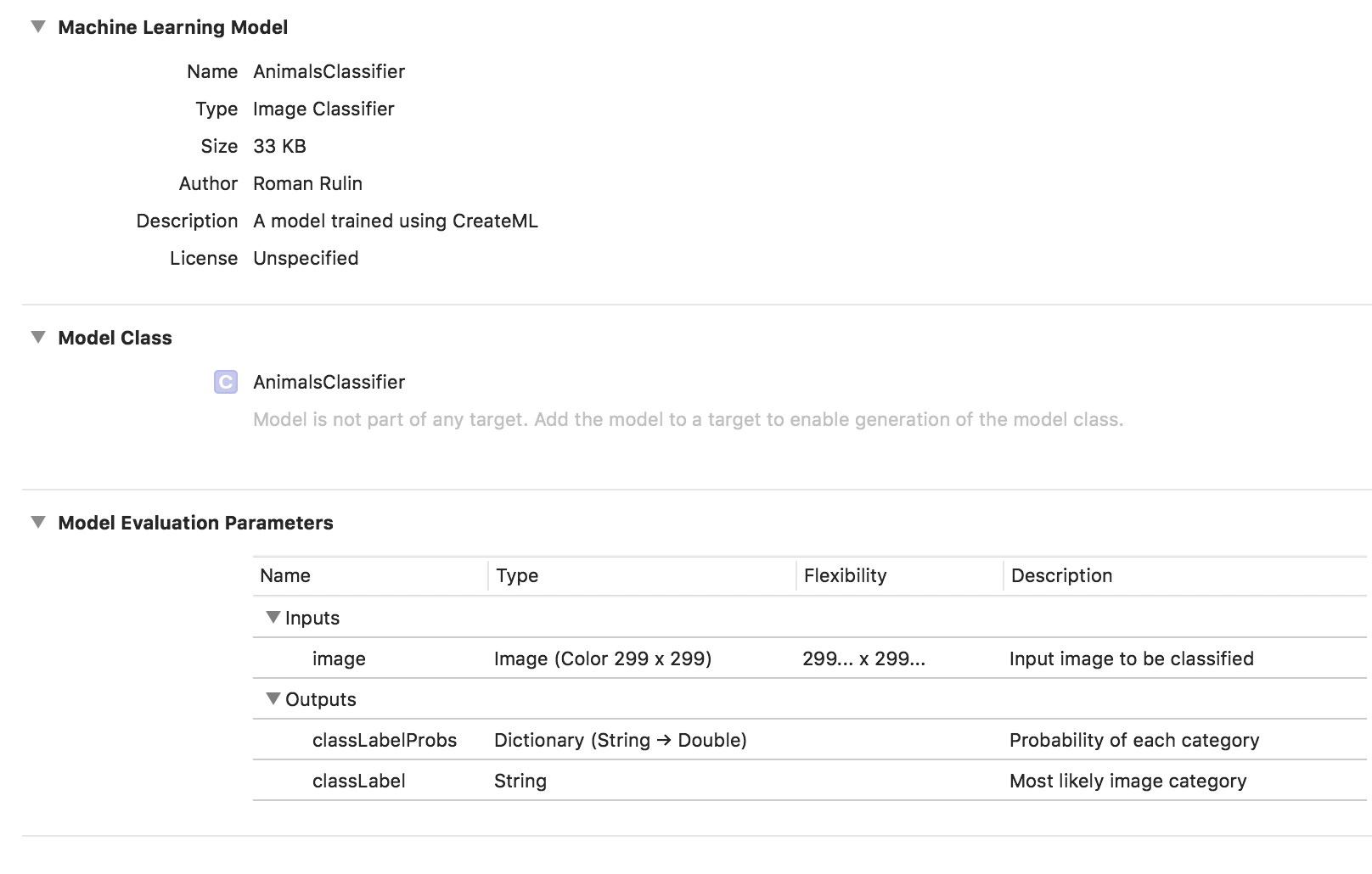
Untuk menguji model, saya menulis aplikasi sederhana menggunakan kerangka Visi. Ini memungkinkan Anda untuk bekerja dengan model Core ML dan memecahkan masalah dalam menggunakannya, seperti klasifikasi gambar atau deteksi objek.
Aplikasi kita akan mengenali gambar dari kamera perangkat dan menampilkan kategori dan persentase kepercayaan dalam klasifikasi.
Kami menginisialisasi model Core ML untuk bekerja dengan Vision dan mengonfigurasi kueri:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
Tambahkan metode yang akan memproses hasil VNCoreMLRequest. Kami hanya menampilkan mereka yang memiliki indikator kepercayaan lebih dari 70%:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
Dan yang terakhir - kita akan menambahkan metode delegasi AVCaptureVideoDataOutputSampleBufferDelegate, yang akan dipanggil dengan setiap bingkai baru dari kamera dan menjalankan permintaan:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
Mari kita periksa seberapa baik model mengatasi tugasnya:

Kategori ini ditentukan dengan akurasi yang cukup tinggi, dan ini sangat mengejutkan ketika Anda mempertimbangkan seberapa cepat pelatihan berlangsung dan seberapa kecil dataset aslinya. Secara berkala, dengan latar belakang gelap, model ini mengungkapkan burung, tapi saya pikir ini dapat dengan mudah diselesaikan dengan meningkatkan jumlah gambar dalam kumpulan data asli atau dengan meningkatkan tingkat kepercayaan minimum yang dapat diterima.
Jika kami ingin melatih ulang model untuk mengklasifikasikan kategori lain, cukup tambahkan grup gambar baru dan ulangi prosesnya - ini akan memakan waktu beberapa menit.
Sebagai percobaan, saya membuat kumpulan data lain, di mana saya mengubah semua foto kucing di foto satu kucing dari sudut yang berbeda, tetapi pada latar belakang yang sama dan di lingkungan yang sama. Dalam hal ini, model hampir selalu membuat kesalahan dan mengenali kategori di ruang kosong, tampaknya mengandalkan warna sebagai fitur utama.
Fitur menarik lainnya yang diperkenalkan di Vision hanya tahun ini adalah kemampuan untuk mengenali objek dalam gambar secara real time. Ini diwakili oleh kelas VNRecognizedObjectObservation, yang memungkinkan Anda untuk mendapatkan kategori objek dan lokasinya - boundingBox.

Sekarang Buat ML tidak memungkinkan pembuatan model untuk mengimplementasikan fungsi ini. Apple menyarankan menggunakan Turi Buat dalam kasus ini. Prosesnya tidak jauh lebih rumit daripada yang di atas: Anda perlu menyiapkan folder kategori dengan foto dan file di mana untuk setiap gambar koordinat dari persegi panjang di mana objek berada akan ditunjukkan.
Pemrosesan bahasa alami
Fungsi Buat ML berikutnya adalah untuk melatih model untuk mengklasifikasikan teks dalam bahasa alami - misalnya, untuk menentukan pewarnaan emosional dari kalimat atau mendeteksi spam.
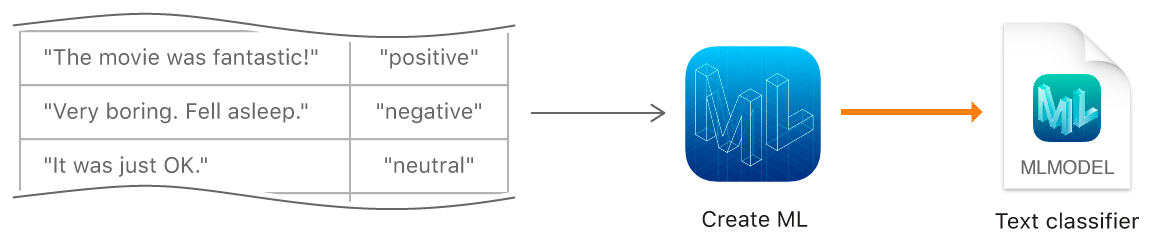
Untuk membuat model, kita harus mengumpulkan tabel dengan kumpulan data asli - kalimat atau seluruh teks yang ditetapkan untuk kategori tertentu, dan melatih model menggunakannya dengan menggunakan objek MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
Dalam hal ini, model yang dilatih adalah tipe Text Classifier:
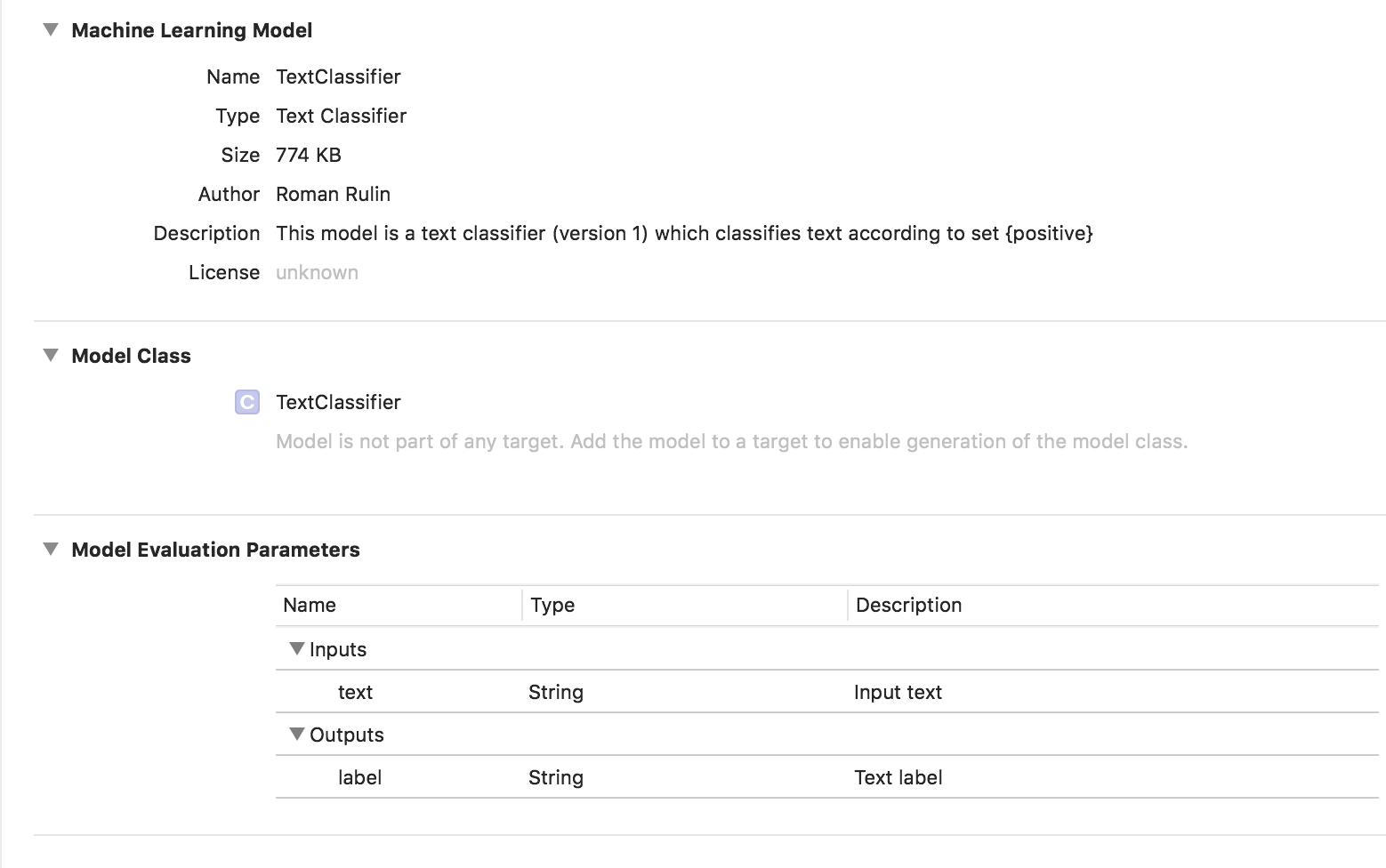
Data tabel
Mari kita lihat lebih dekat fitur lain dari Buat ML - latih model menggunakan data terstruktur (tabel).
Kami akan menulis aplikasi uji yang memprediksi harga apartemen berdasarkan lokasinya di peta dan parameter tertentu lainnya.
Jadi, kami memiliki tabel dengan data abstrak tentang apartemen di Moskow dalam bentuk file csv: luas setiap apartemen, lantai, jumlah kamar dan koordinat (lintang dan bujur) diketahui. Selain itu, biaya setiap apartemen diketahui. Semakin dekat ke pusat atau semakin besar area, semakin tinggi harganya.
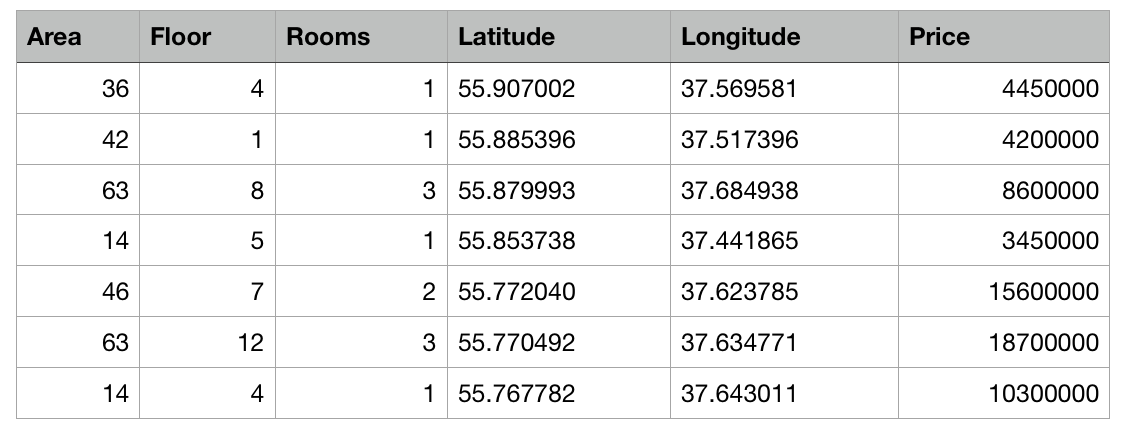
Tugas Buat ML adalah membangun model yang mampu memprediksi harga apartemen berdasarkan karakteristik ini. Tugas seperti itu dalam pembelajaran mesin disebut tugas regresi dan merupakan contoh klasik pembelajaran dengan seorang guru.
Buat ML mendukung banyak model - Regresi Linier, Regresi Pohon Keputusan, Klasifikasi Pohon, Regresi Logistik, Klasifikasi Hutan Acak, Regresi Pohon Didorong, dll.
Kami akan menggunakan objek MLRegressor, yang akan memilih opsi terbaik berdasarkan data input.
Pertama, inisialisasi objek MLDataTable dengan konten file csv kami:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
Kami membagi set data awal menjadi data untuk pelatihan model dan pengujian dalam persentase 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
Kami membuat model MLRegressor, yang menunjukkan data untuk pelatihan dan nama kolom yang nilainya ingin kami prediksi. Jenis tugas khusus dari regresi (linier, pohon keputusan, pohon yang ditingkatkan atau hutan acak) akan secara otomatis dipilih berdasarkan studi dari data input. Kami juga dapat menentukan kolom fitur - kolom parameter khusus untuk analisis, tetapi dalam contoh ini ini tidak diperlukan, kami akan menggunakan semua parameter. Pada akhirnya, simpan model yang terlatih dan tambahkan ke proyek:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
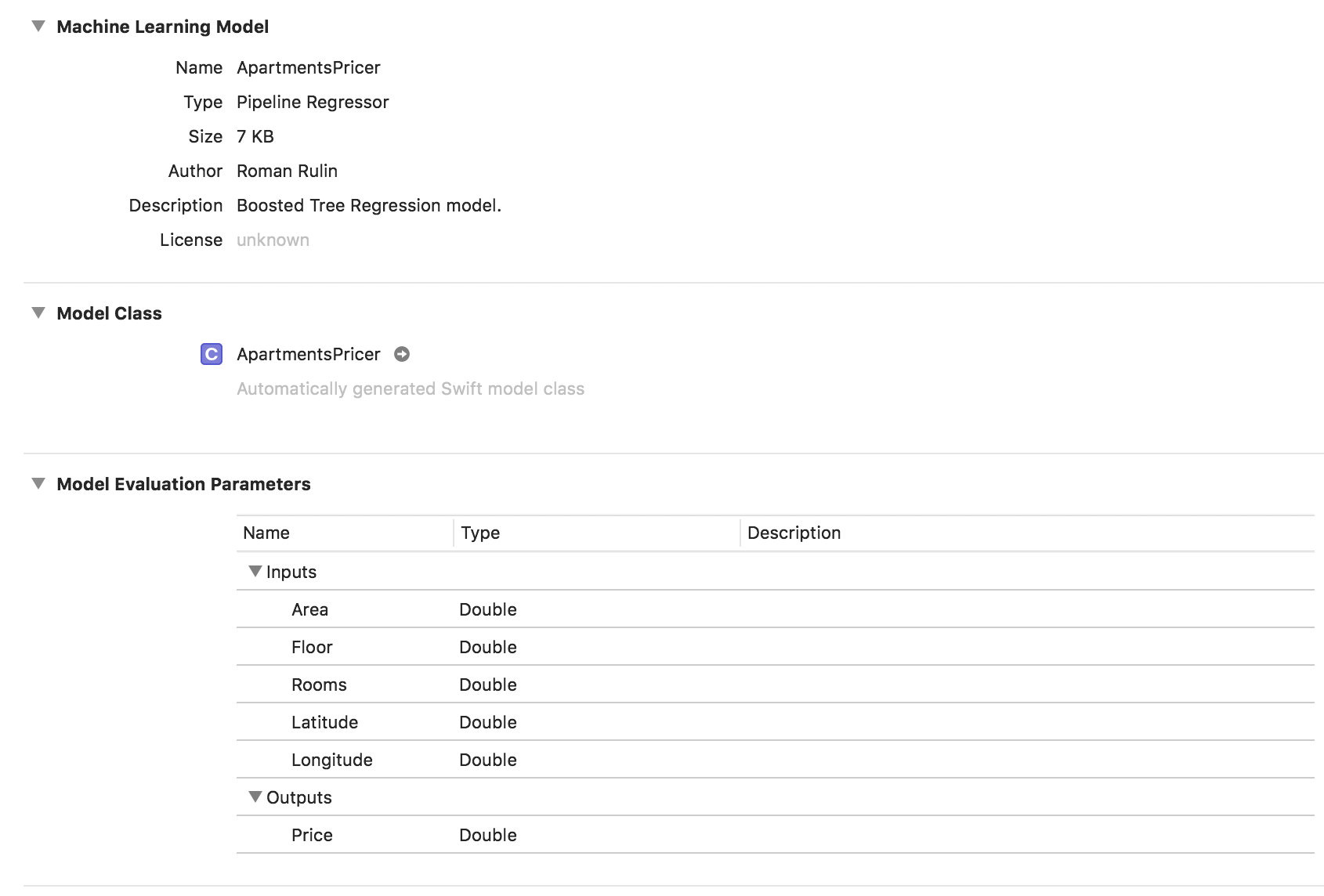
Dalam contoh ini, kita melihat bahwa jenis model sudah Regulator Pipa, dan bidang Deskripsi berisi tipe regresi yang dipilih secara otomatis - Model Regresi Pohon yang Ditingkatkan. Parameter Input dan Output sesuai dengan kolom tabel, tetapi tipe datanya telah menjadi Double.
Sekarang periksa hasilnya.
Inisialisasi objek model:
let model = ApartmentsPricer()
Kami memanggil metode prediksi, meneruskan parameter yang ditentukan untuk itu:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
Kami menampilkan nilai perkiraan biaya:
let price = prediction?.price priceLabel.text = formattedPrice(price)
Mengubah titik pada peta atau nilai parameter, kami mendapatkan harga apartemen cukup dekat dengan data pengujian kami:
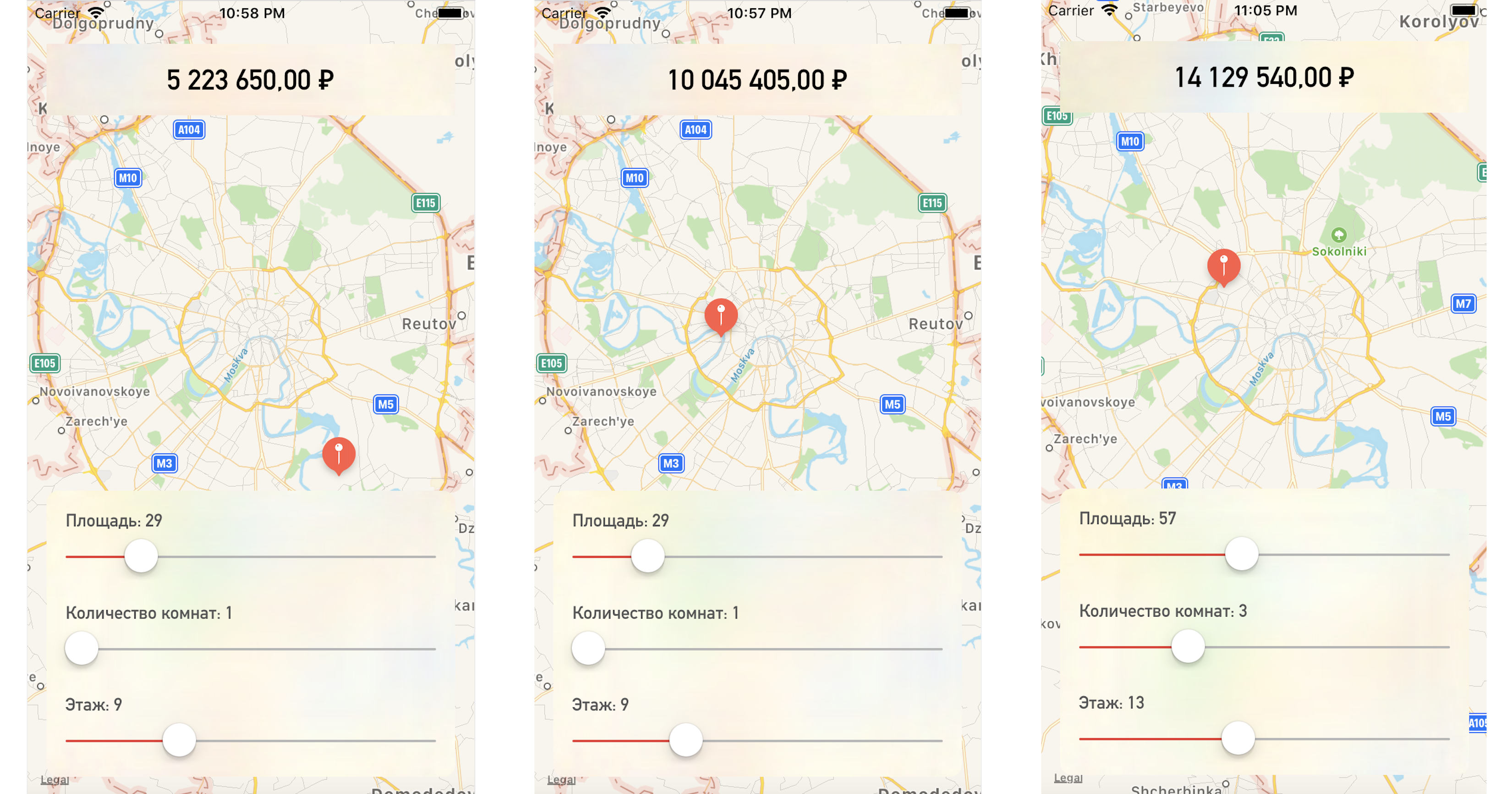
Kesimpulan
Kerangka kerja ML Buat sekarang adalah salah satu cara termudah untuk bekerja dengan teknologi pembelajaran mesin. Itu belum memungkinkan pembuatan model untuk memecahkan beberapa masalah: pengenalan objek dalam gambar, stilisasi foto, penentuan gambar yang serupa, pengakuan tindakan fisik berdasarkan data dari accelerometer atau giroskop, yang Turi Buat, misalnya, menangani.
Tetapi perlu dicatat bahwa Apple telah membuat kemajuan yang cukup serius di bidang ini selama setahun terakhir, dan, yang pasti, kita akan segera melihat perkembangan teknologi yang dijelaskan.