Pada bagian artikel ini, kami akan terus mempertimbangkan berbagai jenis pengujian dalam produksi. Mereka yang melewatkan bagian pertama dapat membacanya di
sini . Untuk yang lainnya - selamat datang di kucing.
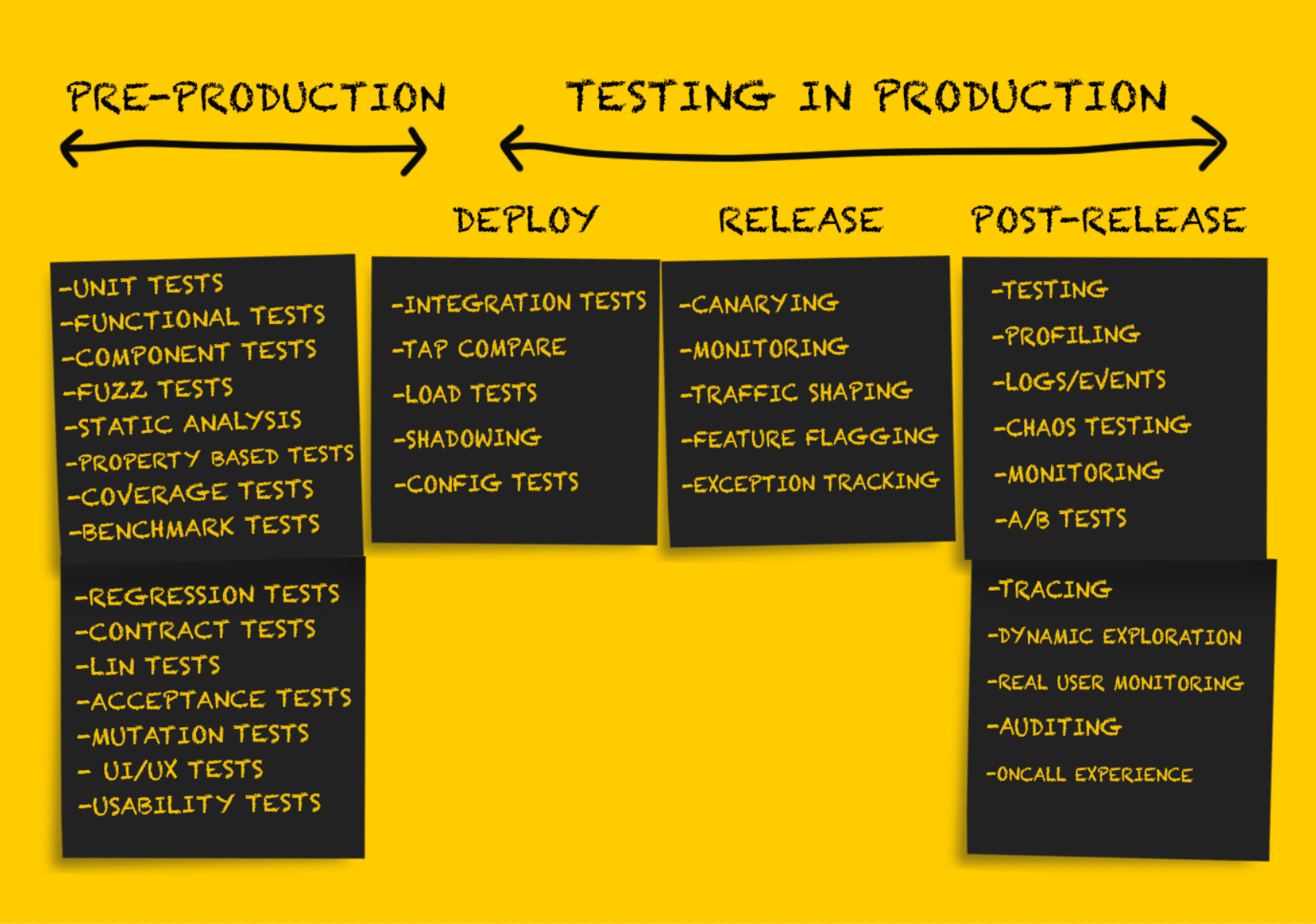
Pengujian Produksi: Rilis
Setelah menguji layanan setelah
penyebaran , harus disiapkan untuk
rilis .
Penting untuk dicatat bahwa pada tahap ini kemunduran perubahan hanya mungkin terjadi dalam situasi kegagalan
berkelanjutan , misalnya:
- perulangan kegagalan layanan;
- melebihi waktu tunggu untuk sejumlah besar koneksi di hulu, menyebabkan peningkatan kuat dalam frekuensi kesalahan;
- perubahan konfigurasi yang tidak dapat diterima, misalnya, kurangnya kunci rahasia dalam variabel lingkungan yang menyebabkan kegagalan fungsi layanan (variabel lingkungan umumnya lebih baik untuk dihindari, tetapi ini adalah topik untuk diskusi lain).
Pengujian menyeluruh pada tahap
penempatan memungkinkan saya untuk meminimalkan atau menghindari kejutan yang tidak menyenangkan pada tahap
rilis . Namun, ada sejumlah rekomendasi untuk melepaskan kode baru dengan aman.
Penempatan Canary
Penempatan kenari adalah
pelepasan sebagian
dari layanan dalam produksi. Ketika pemeriksaan kesehatan dasar berlalu, bagian kecil dari lalu lintas lingkungan produksi saat ini dikirim ke bagian yang dirilis. Hasil dari bagian-bagian layanan dipantau saat lalu lintas diproses, indikator dibandingkan dengan yang referensi (tidak terkait dengan yang kenari), dan jika mereka berada di luar nilai ambang batas yang dapat diterima, kemunduran ke keadaan sebelumnya dilakukan. Meskipun pendekatan ini biasanya digunakan ketika merilis perangkat lunak server,
pengujian kenari perangkat lunak klien juga menjadi lebih umum.
Berbagai faktor mempengaruhi lalu lintas apa yang akan digunakan untuk penyebaran kenari. Di sejumlah perusahaan, bagian layanan yang dirilis pertama hanya menerima lalu lintas pengguna internal (disebut dogfooding). Jika tidak ada kesalahan yang diamati, maka sebagian kecil dari lalu lintas lingkungan produksi ditambahkan, setelah itu penyebaran penuh dilakukan.
Disarankan agar Anda memutar kembali ke keadaan sebelumnya jika hasil penyebaran kenari tidak valid
secara otomatis , dan alat-alat seperti
Spinnaker memiliki dukungan bawaan untuk analisis otomatis dan fungsi rollback.
Ada beberapa masalah dengan pengujian kenari, dan
artikel ini memberikan gambaran yang cukup lengkap tentang mereka.
Pemantauan
Pemantauan adalah prosedur yang mutlak diperlukan pada
setiap tahap penyebaran produk dalam produksi, tetapi fungsi ini akan sangat penting pada tahap
rilis . Pemantauan sangat cocok untuk mendapatkan informasi tentang tingkat umum kinerja sistem. Tetapi memantau segala sesuatu di dunia mungkin bukan solusi terbaik. Pemantauan yang
efektif dilakukan secara searah, yang memungkinkan Anda untuk mengidentifikasi serangkaian kecil mode kegagalan berkelanjutan dari sistem atau serangkaian indikator dasar. Contoh mode kegagalan tersebut dapat:
- peningkatan tingkat kesalahan;
- penurunan kecepatan pemrosesan permintaan secara keseluruhan di seluruh layanan, pada titik akhir tertentu, atau, bahkan lebih buruk, penghentian total pekerjaan;
- peningkatan keterlambatan.
Pengamatan dari salah satu mode kegagalan berkelanjutan ini adalah dasar untuk rollback langsung ke keadaan sebelumnya atau rollback versi perangkat lunak baru yang
dirilis . Penting untuk diingat bahwa pemantauan pada tahap ini tidak mungkin lengkap dan indikatif. Banyak yang percaya bahwa jumlah sinyal ideal yang dipantau selama pemantauan adalah dari 3 hingga 5, tetapi
jelas tidak lebih dari 7-10. Buku putih Facebook Kraken menawarkan solusi berikut:
"Masalahnya diselesaikan dengan bantuan komponen pemantauan yang mudah dikonfigurasi, yang melaporkan dua indikator dasar (persentil ke-99 dari waktu respons server web dan frekuensi terjadinya kesalahan HTTP fatal) yang secara objektif menggambarkan kualitas interaksi pengguna."Rangkaian indikator sistem dan aplikasi yang dipantau selama fase rilis paling baik ditentukan selama desain sistem.
Pelacakan pengecualian
Kita berbicara tentang melacak pengecualian pada tahap rilis, meskipun mungkin terlihat bahwa pada tahap
penyebaran dan setelah rilis ini tidak akan terlalu berguna. Alat pelacak pengecualian seringkali tidak menjamin ketelitian, keakuratan, dan jangkauan massa yang sama dengan beberapa alat pemantauan sistem lainnya, tetapi mereka masih bisa sangat berguna.
Alat open source (seperti
Sentry ) menampilkan informasi lanjutan tentang permintaan yang masuk dan membuat tumpukan data jejak dan variabel lokal, yang sangat menyederhanakan proses debugging, yang biasanya terdiri dari melihat log peristiwa. Pelacakan pengecualian juga berguna ketika menyortir dan memprioritaskan masalah yang tidak memerlukan rollback penuh ke keadaan sebelumnya (misalnya, kasus garis batas yang melempar pengecualian).
Pembentukan lalu lintas
Membentuk traffic (traffic redistribution) bukanlah bentuk pengujian independen sebagai alat untuk mendukung pendekatan kenari dan rilis bertahap kode baru. Bahkan, pembentukan traffic dipastikan dengan memperbarui konfigurasi load balancer, yang memungkinkan Anda untuk secara bertahap mengarahkan lebih banyak lalu lintas ke versi yang baru
dirilis .
Metode ini juga berguna untuk penyebaran bertahap perangkat lunak baru (terpisah dari penyebaran reguler). Pertimbangkan sebuah contoh. Imgix perlu menggunakan arsitektur infrastruktur baru yang fundamental pada Juni 2016. Setelah pengujian pertama infrastruktur baru dengan sejumlah lalu lintas gelap, mereka mulai mengerahkan produksi, awalnya mengarahkan sekitar 1% lalu lintas lingkungan produksi ke tumpukan baru. Kemudian, selama beberapa minggu, volume data yang tiba di tumpukan baru meningkat (menyelesaikan masalah di sepanjang jalan), hingga mulai memproses 100% dari lalu lintas.
Popularitas arsitektur mesh layanan telah memicu lonjakan baru dalam minat pada server proxy. Akibatnya, proksi lama (nginx, HAProxy) dan yang baru (Utusan, Conduit) menambahkan dukungan untuk fungsi-fungsi baru dalam upaya untuk menyalip pesaing. Tampak bagi saya bahwa masa depan, di mana redistribusi lalu lintas dari 0 hingga 100% pada tahap rilis produk dilakukan secara otomatis, sudah dekat.
Pengujian Produksi: Setelah Rilis
Pengujian pasca rilis dilakukan sebagai pemeriksaan yang dilakukan
setelah pelepasan kode yang berhasil. Pada tahap ini, Anda dapat yakin bahwa kode secara keseluruhan sudah benar, telah berhasil
dirilis dalam produksi dan memproses lalu lintas dengan benar. Kode yang digunakan secara langsung atau tidak langsung digunakan dalam kondisi nyata, melayani pelanggan nyata atau melakukan tugas yang memiliki dampak signifikan pada bisnis.
Tujuan dari setiap pengujian pada tahap ini adalah untuk memverifikasi operabilitas sistem, dengan mempertimbangkan berbagai kemungkinan beban dan pola lalu lintas. Cara terbaik untuk melakukan ini adalah mengumpulkan bukti dokumenter tentang segala sesuatu yang terjadi dalam produksi dan menggunakannya baik untuk debugging dan untuk mendapatkan gambaran lengkap dari sistem.
Penandaan Fitur, atau Peluncuran Gelap
Publikasi tertua tentang keberhasilan penggunaan flag fitur yang saya temukan diterbitkan hampir sepuluh tahun yang lalu.
Featureflags.io menyediakan panduan paling komprehensif untuk ini.
“Fitur penandaan adalah metode yang digunakan oleh pengembang untuk menandai fungsi baru menggunakan pernyataan if-then, yang memungkinkan lebih banyak kontrol atas rilisnya. Dengan menandai suatu fungsi dan mengisolasinya dengan cara ini, pengembang mendapatkan kemampuan untuk menghidupkan dan mematikan fungsi ini terlepas dari status penyebaran. Ini secara efektif memisahkan pelepasan fungsi dari penyebaran kode. "Dengan menandai kode baru, Anda dapat menguji kinerjanya dan kinerjanya dalam produksi sesuai kebutuhan. Penandaan fitur adalah salah satu jenis pengujian yang diterima secara umum dalam produksi, telah dikenal luas dan sering
dijelaskan dalam
berbagai sumber . Fakta bahwa metode ini dapat digunakan dalam proses pengujian
transfer database atau perangkat lunak untuk sistem pribadi jauh kurang dikenal.
Apa yang jarang ditulis oleh penulis artikel adalah metode terbaik untuk mengembangkan dan menggunakan flag fungsi. Penggunaan flag yang tidak terkontrol bisa menjadi masalah serius. Kurangnya disiplin dalam hal menghapus bendera yang tidak digunakan setelah jangka waktu tertentu kadang-kadang mengarah pada fakta bahwa Anda harus melakukan audit penuh dan menghapus bendera usang yang diakumulasikan selama berbulan-bulan (jika tidak lebih dari tahun) pekerjaan.
Pengujian A / B
Pengujian A / B sering dilakukan sebagai bagian dari analisis eksperimental dan tidak dianggap sebagai pengujian dalam produksi. Untuk alasan ini, tes A / B tidak hanya digunakan secara luas (kadang-kadang bahkan dengan cara yang
meragukan ), tetapi juga
dipelajari dan
dijelaskan secara aktif (termasuk artikel tentang
apa yang menentukan kartu skor yang efektif untuk eksperimen online). Jauh lebih jarang, tes A / B digunakan untuk menguji berbagai konfigurasi perangkat keras atau mesin virtual. Mereka sering disebut "tuning" (misalnya, tuning JVM), tetapi mereka tidak diklasifikasikan sebagai tes A / B khas (meskipun tuning dapat dianggap sebagai jenis tes A / B dilakukan dengan tingkat kekakuan yang sama ketika datang ke pengukuran) .
Log, acara, indikator, dan penelusuran
Anda
dapat membaca tentang apa yang disebut "tiga paus yang dapat diamati" - log, indikator, dan penelusuran yang didistribusikan di
sini .
Pembuatan profil
Dalam beberapa kasus, untuk mendiagnosis masalah kinerja, perlu menggunakan profil aplikasi dalam produksi. Bergantung pada bahasa dan runtime yang didukung, pembuatan profil dapat menjadi prosedur yang cukup sederhana, yang melibatkan penambahan hanya satu baris kode ke aplikasi (
import _ "net/http/pprof" untuk Go). Di sisi lain, mungkin memerlukan penggunaan banyak alat atau menguji proses dengan metode kotak hitam dan memeriksa hasilnya menggunakan alat-alat seperti
flamegraphs .
Tes tee
Banyak orang menganggap pengujian semacam itu seperti duplikasi bayangan data, karena dalam kedua kasus lalu lintas lingkungan produksi dikirim ke cluster atau proses non-produksi. Menurut pendapat saya, perbedaannya adalah bahwa penggunaan lalu lintas untuk tujuan
pengujian agak berbeda dari penggunaannya untuk tujuan
debugging .
Etsy menulis di blognya tentang menggunakan tes tee sebagai alat verifikasi (contoh ini benar-benar menyerupai duplikasi bayangan data).
“Di sini tee dapat dipahami sebagai perintah tee di baris perintah. Kami menulis aturan iRule berdasarkan penyeimbang beban F5 yang ada untuk mengkloning lalu lintas HTTP yang diarahkan ke salah satu kumpulan dan mengarahkannya ke kumpulan lain. Dengan demikian, kami dapat menggunakan lalu lintas lingkungan produksi yang diarahkan ke cluster API kami dan mengirimkan salinannya ke cluster HHVM eksperimental, serta ke cluster PHP yang terisolasi untuk perbandingan.
Teknik ini telah terbukti sangat efektif. Dia mengizinkan kami untuk membandingkan kinerja kedua konfigurasi menggunakan profil lalu lintas yang identik. "Namun, kadang-kadang tes tee berdasarkan lalu lintas lingkungan produksi dalam sistem otonom diperlukan untuk
debugging . Dalam kasus seperti itu, sistem otonom dapat diubah untuk mengkonfigurasi output informasi diagnostik tambahan atau prosedur kompilasi lainnya (misalnya, menggunakan alat pembersih aliran), yang sangat menyederhanakan proses pemecahan masalah. Dalam kasus seperti itu, tee-test harus dipertimbangkan, bukan,
alat debugging , daripada
verifikasi .
Sebelumnya, jenis debugging seperti itu relatif jarang di
IMGIX , tetapi mereka masih digunakan, terutama ketika datang ke masalah dengan aplikasi debugging yang sensitif terhadap penundaan.
Sebagai contoh, berikut ini adalah deskripsi analitis dari salah satu insiden yang terjadi pada tahun 2015. Kesalahan 400 terjadi sangat jarang sehingga hampir tidak terlihat ketika mencoba mereproduksi masalah. Dia muncul hanya dalam beberapa kasus dari satu miliar. Ada sangat sedikit dari mereka di siang hari. Akibatnya, ternyata tidak mungkin mereproduksi masalah dengan andal, sehingga perlu melakukan debugging menggunakan lalu lintas kerja agar memiliki kesempatan untuk melacak terjadinya kesalahan ini. Inilah yang ditulis mantan kolega saya tentang ini:
“Saya memilih perpustakaan yang seharusnya internal, tetapi pada akhirnya saya harus membuat perpustakaan sendiri berdasarkan perpustakaan yang disediakan oleh sistem. Dalam versi yang disediakan oleh sistem, terjadi kesalahan secara berkala yang tidak muncul dengan cara apa pun saat jumlah lalu lintas kecil. Namun, nama terpotong dalam judul adalah masalah sebenarnya.
Selama dua hari berikutnya, saya mempelajari secara detail masalah yang terkait dengan peningkatan frekuensi kesalahan palsu 400. Kesalahan itu terwujud dalam sejumlah kecil permintaan, dan masalah jenis ini sulit didiagnosis. Semua ini tampak seperti jarum terkenal di tumpukan jerami: masalahnya ditemukan dalam satu kasus per miliar.
Langkah pertama dalam menemukan sumber kesalahan adalah untuk mendapatkan semua data permintaan HTTP mentah yang menghasilkan respons yang salah. Untuk melakukan uji coba trafik masuk ketika terhubung ke soket, saya menambahkan titik akhir soket domain Unix ke server render. Idenya adalah untuk memungkinkan kita dengan cepat dan mudah menghidupkan dan mematikan arus lalu lintas yang gelap dan melakukan pengujian langsung di komputer pengembang. Untuk menghindari masalah dalam produksi, perlu memutuskan koneksi jika ada masalah tekanan balik. Yaitu jika duplikat tidak dapat mengatasi tugas, itu terputus. Soket ini sangat berguna dalam beberapa kasus selama pengembangan. Namun, kali ini, kami menggunakannya untuk mengumpulkan lalu lintas masuk pada server yang dipilih, berharap mendapatkan cukup permintaan untuk mengidentifikasi pola yang menyebabkan munculnya kesalahan palsu 400. Menggunakan dsh dan netcat, saya dapat relatif mudah menghasilkan lalu lintas yang masuk ke file lokal .
Sebagian besar lingkungan dihabiskan untuk mengumpulkan data ini. Segera setelah kami memiliki cukup data, saya dapat menggunakan netcat untuk memutarnya di sistem lokal, konfigurasi yang diubah untuk menampilkan sejumlah besar informasi debug. Dan semuanya berjalan dengan sempurna. Langkah selanjutnya adalah memutar data dengan kecepatan setinggi mungkin. Dalam kasus ini, loop dengan cek kondisi mengirim permintaan mentah satu per satu. Setelah sekitar dua jam, saya berhasil mencapai hasil yang diinginkan. Data dalam log menunjukkan kurangnya tajuk!
Saya menggunakan kayu merah-hitam untuk menyampaikan header. Struktur semacam itu mempertimbangkan komparabilitas sebagai identitas, yang dengan sendirinya sangat berguna ketika ada persyaratan khusus untuk kunci: dalam kasus kami, header HTTP tidak peka terhadap huruf besar-kecil. Pada awalnya kami berpikir bahwa masalahnya ada pada simpul daun dari perpustakaan yang digunakan. Urutan penambahan benar-benar memengaruhi urutan konstruksi pohon dasar, dan menyeimbangkan pohon merah-hitam adalah proses yang agak rumit. Dan meskipun situasi ini tidak mungkin, itu bukan tidak mungkin. Saya beralih ke implementasi ebony merah lainnya. Itu diperbaiki beberapa tahun yang lalu, jadi saya memutuskan untuk menanamkannya langsung di sumber untuk mendapatkan versi yang dibutuhkan. Namun demikian, majelis memilih versi yang berbeda, dan karena saya mengandalkan versi yang lebih baru, pada akhirnya saya mendapatkan perilaku yang salah.
Karena itu, sistem visualisasi menghasilkan 500 kesalahan, yang menyebabkan gangguan siklus. Inilah sebabnya mengapa kesalahan hanya terjadi seiring waktu. Setelah pemrosesan siklis dari beberapa majelis, lalu lintas dari mereka dialihkan ke rute yang berbeda, yang meningkatkan skala masalah pada server ini. Asumsi saya bahwa masalahnya ada di perpustakaan ternyata salah, dan saklar balik menyelesaikan 500 kesalahan.
Saya kembali ke 400 kesalahan: masih ada masalah dengan kesalahan, yang membutuhkan waktu sekitar dua jam untuk mendeteksi. Mengubah perpustakaan, jelas, tidak menyelesaikan masalah, tetapi saya yakin bahwa perpustakaan yang dipilih cukup andal. Tidak menyadari kekeliruan pilihan, saya tidak mengubah apa pun. Setelah mempelajari situasinya secara lebih rinci, saya menyadari bahwa nilai yang benar disimpan dalam header karakter tunggal (misalnya, "h: 12345"). Akhirnya saya sadar bahwa h adalah karakter tambahan dari header Content-Length. Melihat data lagi, saya menyadari bahwa header Panjang Konten kosong.
Akibatnya, semuanya menjadi kesalahan bias ketika membaca header. Penganalisa HTTP nginx / joyent membuat data parsial, dan setiap kali bidang header parsial satu karakter lebih pendek dari yang diperlukan, saya mengirim header tanpa nilai dan kemudian menerima bidang header satu karakter yang berisi nilai yang benar. Ini adalah kombinasi yang agak jarang, sehingga operasinya membutuhkan waktu yang lama. Jadi saya meningkatkan jumlah pengumpulan data setiap kali header satu karakter muncul, menerapkan perbaikan yang diusulkan dan berhasil menjalankan skrip selama beberapa jam.
Tentu saja, beberapa jebakan lain dengan kerusakan perpustakaan yang disebutkan bisa dideteksi, tetapi kedua kesalahan itu diperbaiki. ”
Insinyur yang terlibat dalam pengembangan aplikasi yang sensitif terhadap penundaan memerlukan kemampuan untuk debug menggunakan lalu lintas dinamis yang ditangkap, karena sering terjadi kesalahan yang tidak dapat direproduksi selama pengujian unit atau terdeteksi menggunakan alat pemantauan (terutama jika ada penundaan serius dalam logging).
Pendekatan Rekayasa Kekacauan
Chaos Engineering adalah pendekatan yang didasarkan pada eksperimen pada sistem terdistribusi untuk mengkonfirmasi kemampuannya dalam menahan kondisi kacau lingkungan produksi.Metode Chaos Engineering, pertama kali dipopulerkan oleh
Chaos Monkey dari Netflix, kini telah menjadi disiplin yang independen. Istilah Chaos Engineering muncul baru-baru ini, tetapi pengujian kesalahan adalah praktik lama.
Istilah "pengujian kacau" mengacu pada teknik berikut:
- nonaktifkan node sembarang untuk menentukan seberapa tahan sistem terhadap kegagalan;
- memperkenalkan kesalahan (misalnya, meningkatkan penundaan) untuk mengkonfirmasi bahwa sistem memprosesnya dengan benar;
- pelanggaran paksa jaringan untuk menentukan respons layanan.
Sebagian besar perusahaan menggunakan lingkungan operasi yang tidak cukup kompleks dan berjenjang untuk secara efektif melakukan pengujian kacau. Penting untuk menekankan bahwa pengenalan kesalahan dalam sistem sebaiknya dilakukan setelah menetapkan fungsi dasar toleransi kesalahan.
Buku putih GREMLIN ini memberikan deskripsi yang cukup komprehensif tentang prinsip-prinsip pengujian kacau, serta instruksi untuk mempersiapkan prosedur ini.
“Yang terpenting adalah fakta bahwa Chaos Engineering dianggap sebagai disiplin ilmu. Dalam disiplin ini, proses rekayasa presisi tinggi diterapkan.
Tugas Chaos Engineering adalah memberi tahu pengguna sesuatu yang baru tentang kerentanan sistem dengan melakukan eksperimen di atasnya. Penting untuk mengidentifikasi semua masalah tersembunyi yang dapat muncul dalam produksi, bahkan sebelum mereka menyebabkan kegagalan besar. Hanya setelah itu Anda dapat secara efektif menghilangkan semua kelemahan dalam sistem dan membuatnya benar-benar toleran terhadap kesalahan. "Kesimpulan
Tujuan pengujian dalam produksi bukan untuk sepenuhnya
menghilangkan semua kemungkinan kegagalan dalam sistem.
John Allspaw mengatakan:
“ Kami melihat bahwa sistem menjadi lebih toleran terhadap kesalahan - dan itu hebat. Tetapi kita harus mengakui: "semakin banyak" tidak sama dengan "mutlak." Dalam sistem kompleks apa pun, kegagalan dapat terjadi (dan akan terjadi) dengan cara yang paling tidak terduga. "
Pengujian dalam produksi pada pandangan pertama mungkin tampak seperti tugas yang agak rumit, jauh melampaui kompetensi sebagian besar perusahaan teknik. Dan meskipun pengujian seperti itu
bukanlah tugas yang
mudah , terkait dengan beberapa risiko, jika Anda mengikutinya dengan semua aturan, itu akan membantu untuk mencapai keandalan sistem terdistribusi kompleks yang ditemukan di mana-mana saat ini.