Dalam artikel sebelumnya, kami melihat pola dan topologi yang digunakan di RabbitMQ. Pada bagian ini, kita akan beralih ke Kafka dan membandingkannya dengan RabbitMQ untuk mendapatkan beberapa ide tentang perbedaan mereka. Harus diingat bahwa arsitektur aplikasi berorientasi peristiwa akan dibandingkan daripada pipa pemrosesan data, meskipun garis antara dua konsep ini akan agak kabur dalam kasus ini. Secara umum, ini lebih merupakan spektrum daripada pemisahan yang jelas. Perbandingan kami hanya akan fokus pada bagian dari spektrum ini terkait dengan aplikasi yang digerakkan oleh peristiwa.

Perbedaan pertama yang muncul dalam pikiran adalah bahwa pesan coba lagi dan tunda mekanisme yang digunakan di RabbitMQ untuk bekerja dengan pesan yang tidak terkirim di Kafka tidak masuk akal. Di RabbitMQ, pesan bersifat sementara, mereka dikirim dan menghilang. Oleh karena itu, menambahkannya kembali adalah kasus penggunaan yang benar-benar nyata. Dan di Kafka, majalah itu menjadi pusat perhatian. Memecahkan masalah pengiriman dengan mengirim kembali pesan ke antrian tidak masuk akal dan hanya merugikan jurnal. Salah satu keuntungannya adalah distribusi pesan yang dijamin jelas di seluruh bagian jurnal, pesan yang berulang membingungkan skema yang terorganisir dengan baik. Di RabbitMQ, Anda sudah dapat mengirim pesan ke antrian tempat satu penerima bekerja, dan pada platform Kafka ada satu jurnal untuk semua penerima. Penundaan pengiriman dan masalah dengan pengiriman pesan tidak menimbulkan banyak kerugian bagi operasi jurnal, tetapi Kafka tidak mengandung mekanisme penundaan bawaan.
Bagaimana cara mengirimkan kembali pesan pada platform Kafka akan dibahas pada bagian tentang skema perpesanan.
Perbedaan besar kedua yang memengaruhi kemungkinan skema perpesanan adalah bahwa RabbitMQ menyimpan pesan jauh lebih sedikit daripada Kafka. Ketika sebuah pesan telah dikirimkan ke penerima di RabbitMQ, pesan itu dihapus tanpa meninggalkan jejak keberadaannya. Di Kafka, setiap pesan disimpan dalam log sampai dihapus. Frekuensi pembersihan tergantung pada jumlah data yang tersedia, jumlah ruang disk yang Anda rencanakan untuk dialokasikan, dan skema pengiriman pesan yang ingin Anda pastikan. Anda dapat menggunakan jendela waktu tempat kami menyimpan pesan untuk periode waktu tertentu: beberapa hari / minggu / bulan terakhir.
Dengan cara ini, Kafka memungkinkan penerima untuk melihat kembali atau menangkap kembali pesan sebelumnya. Sepertinya teknologi untuk mengirim pesan, meskipun tidak berfungsi sama seperti di RabbitMQ.
Jika RabbitMQ memindahkan pesan dan menyediakan elemen kuat untuk membuat skema perutean yang rumit, Kafka menyimpan kondisi sistem saat ini dan sebelumnya. Platform ini dapat digunakan sebagai sumber data historis yang andal karena RabbitMQ tidak bisa.
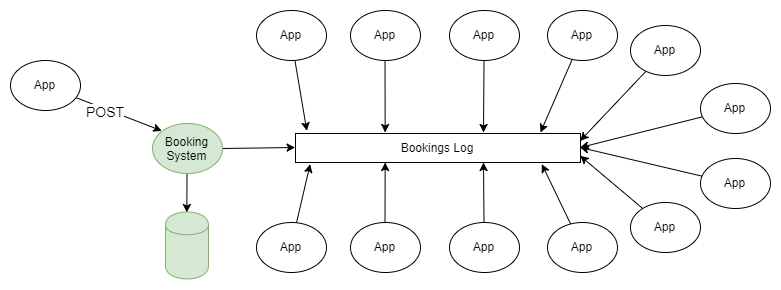
Contoh skema pengiriman pesan pada platform Kafka
Contoh paling sederhana untuk menggunakan RabbitMQ dan Kafka adalah penyebaran informasi sesuai dengan skema “penerbit-pelanggan”. Satu atau lebih penerbit menambahkan pesan ke log yang dipartisi, dan pesan-pesan ini diterima oleh pelanggan dari satu atau lebih kelompok pelanggan.

Gambar 1. Beberapa penerbit mengirim pesan ke log yang dipartisi, dan beberapa kelompok penerima menerimanya.
Jika Anda tidak merinci tentang bagaimana penerbit mengirim pesan ke bagian jurnal yang diperlukan, dan bagaimana kelompok penerima dikoordinasikan di antara mereka, skema ini tidak berbeda dari topologi fanout (pertukaran bercabang) yang digunakan dalam RabbitMQ.
Dalam artikel sebelumnya, semua skema dan topologi pesan RabbitMQ dibahas. Mungkin pada titik tertentu Anda berpikir "Saya tidak membutuhkan semua kesulitan ini, saya hanya ingin mengirim dan menerima pesan dalam antrian", dan fakta bahwa Anda dapat memundurkan majalah ke posisi sebelumnya berbicara tentang keuntungan nyata Kafka.
Bagi orang-orang yang terbiasa dengan fitur tradisional sistem antrian, fakta kemungkinan mengembalikan jam dan memutar balik log peristiwa ke masa lalu sungguh menakjubkan. Properti ini (tersedia dengan menggunakan log, bukan antrian) sangat berguna untuk memulihkan dari kegagalan. Saya (penulis artikel bahasa Inggris) mulai bekerja untuk klien saya saat ini 4 tahun yang lalu sebagai manajer teknis dari kelompok dukungan sistem server. Kami memiliki lebih dari 50 aplikasi yang menerima informasi real-time tentang peristiwa bisnis melalui MSMQ, dan hal yang biasa adalah ketika terjadi kesalahan dalam aplikasi, sistem hanya mendeteksi keesokan harinya. Sayangnya, sering kali pesan menghilang sebagai hasilnya, tetapi biasanya kami bisa mendapatkan data awal dari sistem pihak ketiga dan meneruskan pesan hanya ke "pelanggan" yang memiliki masalah. Ini mengharuskan kami untuk membuat infrastruktur pengiriman pesan untuk penerima. Dan jika kita memiliki platform Kafka, itu tidak akan lebih sulit untuk melakukan pekerjaan seperti itu daripada mengubah tautan ke lokasi pesan yang terakhir diterima untuk aplikasi di mana kesalahan terjadi.
Integrasi Data dalam Aplikasi dan Sistem yang Berorientasi Acara
Skema ini dalam banyak hal merupakan sarana untuk menghasilkan acara, meskipun tidak terkait dengan satu aplikasi. Ada dua tingkat generasi acara: perangkat lunak dan sistem. Skema saat ini dikaitkan dengan yang terakhir.
Pembuatan acara tingkat program
Aplikasi mengelola kondisinya sendiri melalui urutan perubahan peristiwa yang disimpan di toko peristiwa. Untuk mendapatkan status aplikasi saat ini, Anda harus memutar atau menggabungkan acara dalam urutan yang benar. Biasanya dalam model seperti itu, model CQRS Kafka dapat digunakan sebagai sistem ini.
Interaksi antar aplikasi pada level sistem.
Aplikasi atau layanan dapat mengelola keadaan mereka dengan cara apa pun yang ingin dikelola oleh pengembang mereka, misalnya, dalam basis data relasional biasa.
Tetapi aplikasi sering membutuhkan data tentang satu sama lain, ini mengarah pada arsitektur suboptimal, misalnya, database umum, mengaburkan batas entitas, atau REST API yang tidak nyaman.
Saya (penulis artikel bahasa Inggris) mendengarkan podcast " Rekayasa Perangkat Lunak Harian ", yang menggambarkan skenario berorientasi peristiwa untuk profil layanan di jejaring sosial. Ada sejumlah layanan terkait dalam sistem, seperti pencarian, sistem grafik sosial, mesin rekomendasi, dll. Semuanya perlu tahu tentang perubahan status profil pengguna. Ketika saya (penulis artikel bahasa Inggris) bekerja sebagai arsitek arsitektur untuk sistem yang berkaitan dengan transportasi udara, kami memiliki dua sistem perangkat lunak besar dengan berbagai layanan kecil terkait. Layanan dukungan diperlukan pesanan dan data penerbangan. Setiap kali pesanan dibuat atau diubah, ketika penerbangan ditunda atau dibatalkan, layanan ini harus diaktifkan.
Untuk itu diperlukan teknik untuk menghasilkan acara. Tetapi pertama-tama, mari kita lihat beberapa masalah umum yang muncul dalam sistem perangkat lunak besar, dan lihat bagaimana generasi peristiwa dapat menyelesaikannya.
Sistem perusahaan terpadu yang besar biasanya berkembang secara organik; migrasi ke teknologi baru dan arsitektur baru dilakukan, yang mungkin tidak mempengaruhi 100% dari sistem. Data didistribusikan ke berbagai bagian institusi, aplikasi mengungkapkan basis data untuk penggunaan publik sehingga integrasi terjadi secepat mungkin, dan tidak ada yang dapat memprediksi dengan pasti bagaimana semua elemen sistem akan berinteraksi.
Distribusi data acak
Data didistribusikan di tempat yang berbeda dan dikelola di tempat yang berbeda, sehingga sulit untuk dipahami:
- bagaimana data bergerak dalam proses bisnis;
- bagaimana perubahan dalam satu bagian sistem dapat memengaruhi bagian lain;
- apa yang harus dilakukan dengan konflik data yang muncul karena fakta bahwa ada banyak salinan data yang menyebar dengan lambat.
Jika tidak ada batasan yang jelas dari entitas domain, perubahannya akan mahal dan berisiko, karena mereka memengaruhi banyak sistem sekaligus.
Database terdistribusi terpusat
Database terbuka untuk umum dapat menyebabkan beberapa masalah:
- Ini tidak cukup dioptimalkan untuk setiap aplikasi secara terpisah. Kemungkinan besar, database ini berisi kumpulan data yang terlalu lengkap untuk aplikasi, apalagi, itu dinormalisasi sedemikian rupa sehingga aplikasi harus menjalankan query yang sangat kompleks untuk menerimanya.
- Menggunakan database umum, aplikasi dapat saling mempengaruhi pekerjaan masing-masing.
- Perubahan dalam struktur logis dari basis data memerlukan koordinasi skala besar dan pengerjaan migrasi data, dan pengembangan layanan individual akan dihentikan selama durasi keseluruhan proses ini.
- Tidak ada yang mau mengubah struktur penyimpanan. Perubahan yang ditunggu semua orang terlalu menyakitkan.
Menggunakan REST API yang tidak nyaman
Mendapatkan data dari sistem lain melalui REST API di satu sisi menambah kenyamanan dan isolasi, tetapi tetap tidak selalu berhasil. Setiap antarmuka seperti itu dapat memiliki gaya khusus dan konvensi sendiri. Mendapatkan data yang diperlukan dapat membutuhkan banyak permintaan HTTP dan cukup rumit.
Kami bergerak semakin ke arah sentrisitas API, dan arsitektur semacam itu memberikan banyak keuntungan, terutama ketika layanan itu sendiri berada di luar kendali kami. Ada begitu banyak cara mudah untuk membuat API saat ini sehingga kami tidak perlu menulis kode sebanyak yang kami butuhkan sebelumnya. Namun demikian, ini bukan satu-satunya alat yang tersedia, dan ada alternatif untuk arsitektur internal sistem.
Kafka sebagai repositori acara
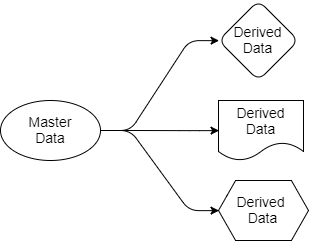
Kami memberi contoh. Ada sistem yang mengelola reservasi dalam database relasional. Sistem ini menggunakan semua jaminan atomicity, konsistensi, isolasi, dan daya tahan yang ditawarkan oleh database untuk mengelola karakteristik mereka secara efektif dan semua orang senang. Pembagian tanggung jawab ke dalam tim dan permintaan, pembuatan acara, layanan mikro tidak ada, secara umum monolit yang dibangun secara tradisional. Tetapi ada banyak sekali layanan dukungan (mungkin layanan mikro) yang terkait dengan reservasi: pemberitahuan push, distribusi email, sistem anti-penipuan, program loyalitas, penagihan, sistem pembatalan, dll. Daftar ini terus berlanjut. Semua layanan ini membutuhkan perincian reservasi, dan ada banyak cara untuk mendapatkannya. Layanan ini sendiri menghasilkan data yang mungkin berguna untuk aplikasi lain.

Gambar 2. Berbagai jenis integrasi data.
Arsitektur alternatif berdasarkan Kafka. Setiap kali Anda melakukan reservasi baru atau mengubah reservasi sebelumnya, sistem akan mengirimkan data lengkap tentang keadaan reservasi saat ini ke Kafka. Dengan mengkonsolidasikan jurnal, Anda dapat mempersingkat pesan sehingga hanya informasi tentang status pemesanan terakhir yang tersisa di dalamnya. Dalam hal ini, ukuran jurnal akan terkendali.
Gambar 3. Integrasi data berbasis Kafka sebagai dasar untuk pembuatan acara
Untuk semua aplikasi yang diperlukan, informasi ini adalah sumber kebenaran dan satu-satunya sumber data. Tiba-tiba, kami bergerak dari jaringan dependensi dan teknologi yang terintegrasi ke mengirim dan menerima data ke / dari topik Kafka.
Kafka sebagai tempat penyimpanan acara:
- Jika tidak ada masalah dengan ruang disk, Kafka dapat menyimpan seluruh riwayat peristiwa, yaitu, aplikasi baru dapat digunakan dan mengunduh semua informasi yang diperlukan dari jurnal. Rekaman peristiwa yang sepenuhnya mencerminkan karakteristik objek dapat dikompresi dengan menyusun log, yang akan membuat pendekatan ini lebih dibenarkan untuk banyak skenario.
- Bagaimana jika acara perlu dimainkan dalam urutan yang benar? Selama rekaman acara didistribusikan dengan benar, Anda dapat mengatur urutan pemutarannya dan menerapkan filter, alat konversi, dll., Sehingga pemutaran data selalu berakhir pada informasi yang diperlukan. Bergantung pada kemungkinan distribusi data, dimungkinkan untuk memastikan pemrosesan mereka yang sangat paralel dalam urutan yang benar.
- Mungkin diperlukan perubahan model data. Saat membuat fungsi filter / transformasi baru, mungkin perlu memutar ulang rekaman semua peristiwa atau peristiwa selama seminggu terakhir.
Pesan dapat datang ke Kafka tidak hanya dari aplikasi organisasi Anda yang mengirim pesan tentang semua perubahan dalam karakteristik mereka (atau hasil dari perubahan ini) tetapi juga dari layanan pihak ketiga yang terintegrasi dengan sistem Anda. Ini terjadi dengan cara berikut:
- Ekspor berkala, transfer, impor data yang diterima dari layanan pihak ketiga, dan unduhan mereka ke Kafka.
- Mengunduh data dari layanan pihak ketiga di Kafka.
- Data dari CSV dan format lain yang diunggah dari layanan pihak ketiga diunggah ke Kafka.
Mari kita kembali ke pertanyaan yang sudah kita bahas tadi. Arsitektur berbasis Kafka menyederhanakan distribusi data. Kami tahu di mana sumber kebenarannya, kami tahu di mana sumber datanya berada, dan semua aplikasi target bekerja dengan salinan yang berasal dari data ini. Data berpindah dari pengirim ke penerima. Sumber data hanya milik pengirim, tetapi yang lain bebas untuk bekerja dengan proyeksi mereka. Mereka dapat memfilter, mengubah, melengkapi mereka dengan data dari sumber lain, menyimpannya di database mereka sendiri.
Gambar 4. Sumber dan output data
Setiap aplikasi yang membutuhkan reservasi dan data penerbangan akan menerimanya untuk dirinya sendiri, karena itu "berlangganan" ke bagian-bagian Kafka yang berisi data ini. Untuk aplikasi ini, mereka dapat menggunakan SQL, Cypher, JSON, atau bahasa permintaan lainnya. Suatu aplikasi kemudian dapat menyimpan data dalam sistemnya sesuai keinginan. Skema distribusi data dapat diubah tanpa mempengaruhi pengoperasian aplikasi lain.
Mungkin timbul pertanyaan: mengapa semua ini tidak bisa dilakukan menggunakan RabbitMQ? Jawabannya adalah bahwa RabbitMQ dapat digunakan untuk memproses acara secara langsung, tetapi tidak sebagai dasar untuk menghasilkan acara. RabbitMQ adalah solusi lengkap hanya untuk menanggapi peristiwa yang sedang terjadi sekarang. Ketika aplikasi baru ditambahkan yang membutuhkan bagiannya sendiri dari data reservasi yang disajikan dalam format yang dioptimalkan untuk tugas-tugas aplikasi ini, RabbitMQ tidak akan dapat membantu. Dengan RabbitMQ, kami kembali ke database bersama atau API REST.
Kedua, urutan proses acara penting. Jika Anda bekerja dengan RabbitMQ, saat Anda menambahkan penerima kedua ke antrian, jaminan kepatuhan dengan pesanan hilang. Dengan demikian, urutan pengiriman pesan yang benar hanya diamati untuk satu penerima, tetapi ini, tentu saja, tidak cukup.
Kafka, sebaliknya, dapat memberikan semua data yang dibutuhkan aplikasi ini untuk membuat salinan datanya sendiri dan menjaga agar data tetap terbaru, sementara Kafka mengikuti urutan pengiriman pesan.
Sekarang kembali ke arsitektur API-centric. Apakah antarmuka ini selalu menjadi pilihan terbaik? Ketika Anda ingin membuka akses data read-only, saya lebih suka arsitektur memancarkan peristiwa. Ini akan mencegah kegagalan cascading dan memperpendek masa hidup yang terkait dengan peningkatan jumlah ketergantungan pada layanan lain. Akan ada lebih banyak peluang untuk pengorganisasian data yang kreatif dan efisien dalam sistem. Tetapi kadang-kadang Anda perlu secara bersamaan mengubah data di sistem Anda dan sistem lain, dan dalam situasi seperti itu, sistem API-sentris akan berguna. Banyak yang lebih suka metode asinkron lainnya. Saya pikir ini masalah selera.
Lalu lintas tinggi dan pemrosesan aplikasi sensitif.
Belum lama berselang, muncul masalah dengan salah satu penerima RabbitMQ, yang menerima file antrian dari layanan pihak ketiga. Ukuran file total besar, dan aplikasi dikonfigurasikan secara khusus untuk menerima volume data seperti itu. Masalahnya adalah bahwa data datang secara tidak konsisten, ini menciptakan banyak masalah.
Selain itu, kadang-kadang ada masalah dalam kenyataan bahwa kadang-kadang dua file dimaksudkan untuk tujuan yang sama, dan waktu kedatangan mereka berbeda beberapa detik. Mereka berdua menjalani pemrosesan dan harus diunggah ke satu server. Dan setelah pesan kedua direkam di server, pesan pertama yang mengikutinya menimpa pesan kedua. Dengan demikian, semuanya berakhir dengan menyimpan data yang tidak valid. RabbitMQ memenuhi perannya dan mengirim pesan dalam urutan yang benar, tetapi semua sama, semuanya berakhir dengan urutan yang salah dalam aplikasi itu sendiri.
Masalah ini diselesaikan dengan membaca stempel waktu dari catatan yang ada dan kurangnya respons jika pesan sudah tua. Selain itu, hashing yang konsisten diterapkan selama pertukaran data, dan antrian dibagi, seperti halnya partisi yang sama pada platform Kafka.
Sebagai bagian dari partisi, Kafka menyimpan pesan sesuai urutan pengirimannya. Urutan pesan hanya ada di dalam partisi. Pada contoh di atas, menggunakan Kafka, kami harus menerapkan fungsi hash ke id tujuan untuk memilih partisi yang diinginkan. Kami harus membuat satu set partisi, harus ada lebih banyak daripada yang dibutuhkan klien. Urutan pemrosesan pesan seharusnya tercapai karena setiap partisi hanya ditujukan untuk satu penerima. Sederhana dan efektif.
Kafka, dibandingkan dengan RabbitMQ, memiliki beberapa kelebihan terkait dengan pemisahan pesan menggunakan hashing. Tidak ada pada platform RabbitMQ yang akan mencegah konflik penerima dalam antrian yang sama yang dihasilkan sebagai bagian dari pertukaran data menggunakan hashing yang konsisten. RabbitMQ tidak membantu mengoordinasikan penerima sehingga hanya satu penerima dari seluruh antrian yang menggunakan pesan. Kafka menyediakan semua ini melalui penggunaan grup penerima dan simpul koordinator. Ini memungkinkan Anda untuk memastikan bahwa hanya satu penerima di bagian dijamin untuk menggunakan pesan, dan bahwa urutan pemrosesan data dijamin.
Lokasi data
Menggunakan fungsi hash untuk mendistribusikan data di seluruh partisi, Kafka menyediakan lokalitas data. Misalnya, pesan dari pengguna dengan id 1001 harus selalu pergi ke penerima 3. Karena peristiwa pengguna 1001 selalu pergi ke penerima 3, penerima 3 dapat secara efektif melakukan beberapa operasi yang akan jauh lebih sulit jika akses reguler ke database eksternal atau sistem lain diperlukan untuk menerima data. Kita dapat membaca data, melakukan agregasi, dll. langsung dengan informasi dalam memori penerima. Ini adalah tempat di mana aplikasi berorientasi peristiwa dan streaming data mulai bergabung.
Bagaimana Kafka memberikan lokalitas data? Untuk mulai dengan, penting untuk dicatat bahwa Kafka tidak memungkinkan peningkatan elastis dan penurunan jumlah partisi. Pertama-tama, Anda tidak dapat mengurangi jumlah partisi sama sekali: jika ada 10, Anda tidak dapat mengurangi jumlahnya menjadi 9. Tetapi, di sisi lain, ini tidak diperlukan. Setiap penerima dapat menggunakan 1 atau beberapa partisi, oleh karena itu, hampir tidak perlu untuk mengurangi jumlahnya. Pembuatan partisi tambahan pada Kafka menyebabkan penundaan pada saat penyeimbangan kembali, jadi kami mencoba untuk skala jumlah partisi dengan mempertimbangkan beban puncak.
Tetapi jika kita masih perlu meningkatkan jumlah partisi dan penerima untuk skala, kita hanya perlu satu kali biaya tidak langsung jika penyeimbangan diperlukan. Perlu dicatat bahwa ketika menskala data lama tetap di partisi yang sama di mana itu. Tetapi pesan masuk yang baru sudah akan dialihkan secara berbeda, dan partisi baru akan mulai menerima pesan baru. Pesan dari pengguna 1001 sekarang dapat pergi ke penerima 4 (karena data tentang pengguna 1001 sekarang dalam dua bagian).
Selanjutnya kami akan membandingkan dan membandingkan semantik pengiriman pesan pengiriman di kedua sistem. Topik penyeimbangan dan pemartisian layak mendapatkan artikel terpisah, yang akan kita bahas di bagian selanjutnya.