Halo, Habr! Baru-baru ini, kami
secara singkat berbicara tentang Antarmuka Bahasa Alami. Nah, hari ini kita belum sempat. Di bawah potongan Anda akan menemukan cerita lengkap tentang membuat NL2API untuk Web-API. Rekan-rekan kami dari Research telah mencoba pendekatan unik untuk mengumpulkan data pelatihan untuk kerangka kerja. Bergabunglah sekarang!

Anotasi
Ketika Internet berevolusi menuju arsitektur berorientasi layanan, antarmuka perangkat lunak (API) menjadi semakin penting sebagai cara untuk menyediakan akses ke data, layanan, dan perangkat. Kami sedang mengerjakan masalah membuat antarmuka bahasa alami untuk API (NL2API), dengan fokus pada layanan web. Solusi NL2API memiliki banyak manfaat potensial, misalnya, membantu menyederhanakan integrasi layanan web menjadi asisten virtual.
Kami menawarkan platform komprehensif pertama (kerangka kerja) yang memungkinkan Anda membuat NL2API untuk API web tertentu. Tugas utamanya adalah mengumpulkan data untuk pelatihan, yaitu pasangan “perintah NL - panggilan API”, memungkinkan NL2API mempelajari semantik dari kedua perintah NL yang tidak memiliki format yang ditentukan secara ketat dan panggilan API yang diformalkan. Kami menawarkan pendekatan unik kami sendiri untuk mengumpulkan data pelatihan untuk NL2API menggunakan crowdsourcing - menarik banyak pekerja jarak jauh untuk menghasilkan berbagai tim NL. Kami mengoptimalkan proses crowdsourcing itu sendiri untuk mengurangi biaya.
Secara khusus, kami menawarkan model probabilistik hierarkis yang secara fundamental baru yang akan membantu kami mendistribusikan anggaran untuk crowdsourcing, terutama di antara panggilan API yang bernilai tinggi untuk mempelajari NL2API. Kami menerapkan kerangka kerja kami pada API nyata dan menunjukkan bahwa ini memungkinkan Anda mengumpulkan data pelatihan berkualitas tinggi dengan biaya minimal, serta membuat NL2API berkinerja tinggi dari awal. Kami juga menunjukkan bahwa model crowdsourcing kami meningkatkan efisiensi proses ini, yaitu, data pelatihan yang dikumpulkan dalam kerangka kerjanya memberikan kinerja NL2API yang lebih tinggi, yang secara signifikan melebihi baseline.
Pendahuluan
Antarmuka pemrograman aplikasi (API) memainkan peran yang semakin penting baik di dunia virtual maupun fisik, berkat pengembangan teknologi seperti arsitektur berorientasi layanan (SOA), komputasi awan, dan Internet of things (IoT). Misalnya, layanan web yang dihosting di cloud (cuaca, olahraga, keuangan, dll.) Melalui API web menyediakan data dan layanan kepada pengguna akhir, dan perangkat IoT memungkinkan perangkat jaringan lain untuk menggunakan fungsionalitasnya.
 Gambar 1. Pasangan "perintah NL (kiri) dan panggilan API (kanan)" berkumpul
Gambar 1. Pasangan "perintah NL (kiri) dan panggilan API (kanan)" berkumpul
kerangka kerja kami, dan perbandingan dengan IFTTT. GET-Messages dan GET-Events adalah dua API web untuk menemukan email dan acara kalender. API dapat dipanggil dengan berbagai parameter. Kami fokus pada panggilan API dengan parameter penuh, sementara IFTTT terbatas pada API dengan parameter sederhana.Biasanya, API digunakan dalam berbagai perangkat lunak: aplikasi desktop, situs web, dan aplikasi seluler. Mereka juga melayani pengguna melalui antarmuka pengguna grafis (GUI). GUI telah memberikan kontribusi besar pada mempopulerkan komputer, tetapi seiring dengan perkembangan teknologi komputer, banyak keterbatasannya yang semakin nyata. Di satu sisi, ketika perangkat menjadi lebih kecil, lebih mobile dan lebih pintar, persyaratan untuk tampilan grafik di layar terus meningkat, misalnya, terkait perangkat portabel atau perangkat yang terhubung ke IoT.
Di sisi lain, pengguna harus beradaptasi dengan berbagai GUI khusus untuk berbagai layanan dan perangkat. Dengan meningkatnya jumlah layanan dan perangkat yang tersedia, biaya pelatihan dan adaptasi pengguna juga meningkat. Antarmuka bahasa alami (NLI), seperti Apple Siri dan asisten virtual Microsoft Cortana, juga disebut antarmuka percakapan atau percakapan (CUI), menunjukkan potensi signifikan sebagai alat tunggal yang cerdas untuk berbagai layanan dan perangkat server.
Dalam makalah ini, kami mempertimbangkan masalah membuat antarmuka bahasa alami untuk API (NL2API). Tapi, tidak seperti asisten virtual, ini bukan NLI tujuan umum,
kami sedang mengembangkan pendekatan untuk membuat NLI untuk API web tertentu, mis. API layanan web seperti layanan multisports ESPN1. NL2APIs seperti itu dapat memecahkan masalah skalabilitas NLI tujuan umum dengan memungkinkan pengembangan terdistribusi. Kegunaan asisten virtual sangat tergantung pada luasnya kemampuannya, yaitu, pada jumlah layanan yang didukungnya.
Namun, mengintegrasikan layanan web menjadi asisten virtual satu per satu adalah pekerjaan yang sangat melelahkan. Jika masing-masing penyedia layanan web memiliki cara murah untuk membuat NLI untuk API mereka, biaya integrasi akan berkurang secara signifikan. Asisten virtual tidak perlu memproses antarmuka yang berbeda untuk layanan web yang berbeda. Akan cukup baginya untuk hanya mengintegrasikan NL2API individu, yang mencapai keseragaman berkat bahasa alami. Di sisi lain, NL2API juga dapat menyederhanakan penemuan layanan web dan rekomendasi pemrograman dan sistem bantuan untuk API, menghilangkan kebutuhan untuk mengingat sejumlah besar API web yang tersedia dan sintaksisnya.
Contoh 1. Dua contoh ditunjukkan pada Gambar 1. API dapat dipanggil dengan berbagai parameter. Dalam kasus API pencarian email, pengguna dapat memfilter email berdasarkan properti tertentu atau mencari email dengan kata kunci. Tugas utama NL2API adalah memetakan perintah NL ke panggilan API yang sesuai.
Tantangan. Pengumpulan data pelatihan adalah salah satu tugas paling penting yang terkait dengan penelitian dalam pengembangan antarmuka NLI dan aplikasi praktisnya. NLI menggunakan data pelatihan terkontrol, yang dalam kasus NL2API terdiri dari pasangan "perintah NL - panggilan API" untuk mempelajari semantik dan memetakan perintah NL secara jelas ke representasi formal yang sesuai. Bahasa alami sangat fleksibel, sehingga pengguna dapat mendeskripsikan panggilan API dengan cara yang berbeda secara sintaksis, yaitu, parafrase dilakukan.
Pertimbangkan contoh kedua pada Gambar 1. Pengguna dapat mengulangi pertanyaan ini sebagai berikut: "Di mana pertemuan berikutnya akan diadakan" atau "Temukan tempat untuk pertemuan berikutnya". Oleh karena itu, sangat penting untuk mengumpulkan data pelatihan yang memadai sehingga sistem dapat mengenali opsi-opsi tersebut lebih lanjut. NLI yang ada biasanya mematuhi prinsip "sebaik mungkin" dalam pengumpulan data. Sebagai contoh, analog terdekat dari metodologi kami untuk membandingkan perintah NL dengan panggilan API menggunakan konsep IF-This-Then-That (IFTTT) - "jika ya, maka kemudian" (Gambar 1). Data pelatihan datang langsung dari situs web IFTTT.
Namun, jika API tidak didukung atau tidak didukung sepenuhnya, tidak ada cara untuk memperbaiki situasi. Selain itu, data pelatihan yang dikumpulkan dengan cara ini tidak berlaku untuk mendukung perintah lanjutan dengan beberapa parameter. Sebagai contoh, kami menganalisis log panggilan Microsoft API anonim untuk mencari email untuk bulan itu dan menemukan bahwa sekitar 90% dari mereka menggunakan dua atau tiga parameter (kira-kira jumlah yang sama), dan parameter ini cukup beragam. Oleh karena itu, kami berusaha keras untuk memberikan dukungan penuh untuk parameterisasi API dan mengimplementasikan perintah NL lanjutan. Masalah penerapan proses yang aktif dan dapat disesuaikan untuk mengumpulkan data pelatihan untuk API tertentu saat ini masih belum terselesaikan.
Masalah menggunakan NLI dalam kombinasi dengan representasi formal lainnya, seperti database relasional, basis pengetahuan dan tabel web, telah dikerjakan dengan baik, sementara hampir tidak ada perhatian diberikan pada pengembangan NLI untuk API web. Kami menawarkan platform komprehensif pertama (kerangka kerja) yang memungkinkan Anda membuat NL2API untuk API web tertentu dari awal. Dalam implementasi untuk API web, kerangka kerja kami mencakup tiga tahap: (1) Presentasi. Format HTTP web API asli berisi banyak sekali redundan dan, karenanya, mengganggu rincian dari sudut pandang NLI.
Kami menyarankan menggunakan representasi semantik perantara untuk API web, agar tidak membebani NLI dengan informasi yang tidak perlu. (2) Satu set data pelatihan. Kami menawarkan pendekatan baru untuk mendapatkan data pelatihan terkontrol berdasarkan crowdsourcing. (3) NL2API. Kami juga menawarkan dua model NL2API: model ekstraksi berbasis bahasa dan model jaringan saraf berulang (Seq2Seq).
Salah satu hasil teknis utama dari pekerjaan ini adalah pendekatan baru yang fundamental pada pengumpulan aktif data pelatihan untuk NL2API berdasarkan crowdsourcing - kami menggunakan eksekutif jarak jauh untuk membubuhi keterangan panggilan API ketika membandingkannya dengan perintah NL. Ini memungkinkan Anda untuk mencapai tiga tujuan desain dengan menyediakan: (1) Kustomisasi. Anda harus dapat menentukan parameter mana untuk API mana yang akan digunakan dan berapa banyak data pelatihan untuk dikumpulkan. (2) Biaya rendah. Layanan pekerja crowdsourcing adalah urutan besarnya lebih murah daripada layanan spesialis khusus, itulah sebabnya mereka harus dipekerjakan. (3) Kualitas tinggi. Kualitas data pelatihan tidak boleh dikurangi.
Saat merancang pendekatan ini, dua masalah utama muncul. Pertama, panggilan API dengan parameterisasi lanjutan, seperti pada Gambar 1, tidak dapat dipahami oleh rata-rata pengguna, jadi Anda perlu memutuskan bagaimana merumuskan masalah anotasi sehingga karyawan crowdsourcing dapat dengan mudah mengatasinya. Kami mulai dengan mengembangkan representasi semantik perantara untuk API web (lihat bagian 2.2), yang memungkinkan kami untuk menghasilkan panggilan API dengan parameter yang diperlukan.
Kemudian kami memikirkan tata bahasa untuk secara otomatis mengubah setiap panggilan API menjadi perintah NL kanonik, yang bisa agak rumit, tetapi akan jelas bagi karyawan crowdsourcing rata-rata (lihat bagian 3.1). Para pemain hanya perlu mengubah kata-kata tim kanonik agar terdengar lebih alami. Pendekatan ini memungkinkan Anda untuk mencegah banyak kesalahan dalam pengumpulan data pelatihan, karena tugas pengubahan kata kata jauh lebih sederhana dan lebih mudah dipahami bagi karyawan crowdsourcing rata-rata.
Kedua, Anda perlu memahami cara mendefinisikan dan membubuhi keterangan hanya panggilan API yang bernilai nyata untuk mempelajari NL2API. “Ledakan kombinatorial” yang muncul selama parameterisasi mengarah pada fakta bahwa jumlah panggilan bahkan untuk satu API bisa sangat besar. Tidak masuk akal untuk membubuhi keterangan semua panggilan. Kami menawarkan model probabilistik hierarkis yang secara fundamental baru untuk implementasi proses crowdsourcing (lihat bagian 3.2). Dengan analogi dengan pemodelan bahasa untuk tujuan memperoleh informasi, kami mengasumsikan bahwa perintah NL dihasilkan berdasarkan panggilan API yang sesuai, sehingga model bahasa harus digunakan untuk setiap panggilan API untuk mendaftarkan proses "generatif" ini.
Model kami didasarkan pada sifat komposisi panggilan API atau representasi formal dari struktur semantik secara keseluruhan. Pada tingkat intuitif, jika panggilan API terdiri dari panggilan yang lebih sederhana (misalnya, "email yang belum dibaca tentang kandidat untuk gelar sains" = "email yang belum dibaca" + "email untuk kandidat untuk gelar sains", kita dapat membangunnya model bahasa dari panggilan API sederhana bahkan tanpa anotasi, oleh karena itu, dengan menjelaskan sejumlah kecil panggilan API, kita dapat menghitung model bahasa untuk semua orang.
Tentu saja, model-model bahasa yang dihitung jauh dari ideal, jika tidak kita akan sudah memecahkan masalah menciptakan NL2API. Namun demikian, ekstrapolasi model bahasa untuk panggilan API yang tidak ditandai memberi kita pandangan menyeluruh tentang seluruh ruang panggilan API, serta interaksi bahasa alami dan panggilan API, yang memungkinkan kita untuk mengoptimalkan proses crowdsourcing. Di Bagian 3.3, kami menjelaskan algoritme untuk membubuhi keterangan secara selektif panggilan API untuk membantu menjadikan panggilan API lebih mudah dibedakan, yaitu untuk memaksimalkan perbedaan di antara model bahasa mereka.
Kami menerapkan kerangka kerja kami pada dua API yang digunakan dari paket Microsoft Graph API2. Kami menunjukkan bahwa data pelatihan berkualitas tinggi dapat dikumpulkan dengan biaya minimal jika pendekatan yang diusulkan digunakan3. Kami juga menunjukkan bahwa pendekatan kami meningkatkan crowdsourcing. Dengan biaya yang sama, kami mengumpulkan data pelatihan yang lebih baik, secara signifikan melebihi baseline. Hasilnya, solusi NL2API kami memberikan akurasi yang lebih tinggi.
Secara umum, kontribusi utama kami meliputi tiga aspek:
- Kami adalah salah satu yang pertama mempelajari masalah NL2API dan mengusulkan kerangka kerja yang komprehensif untuk membuat NL2API dari awal.
- Kami mengusulkan pendekatan unik untuk pengumpulan data pelatihan menggunakan crowdsourcing dan model probabilistik hierarkis baru untuk mengoptimalkan proses ini.
- Kami menerapkan kerangka kerja kami ke API web nyata dan menunjukkan bahwa solusi NL2API yang cukup efektif dapat dibuat dari awal.
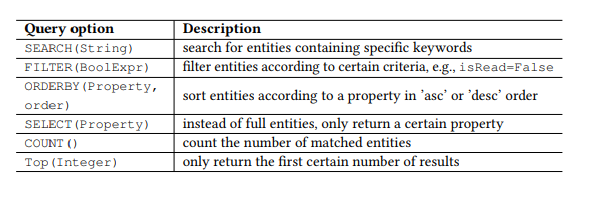 Tabel 1. Parameter kueri OData.
Tabel 1. Parameter kueri OData.Pembukaan
API tenang
Baru-baru ini, API web yang mematuhi gaya arsitektur REST, yaitu RESTful API, menjadi semakin populer karena kesederhanaannya. API tenang juga digunakan pada smartphone dan perangkat IoT. Restful API bekerja dengan sumber daya yang dialamatkan melalui URI dan menyediakan akses ke sumber daya ini untuk berbagai klien menggunakan perintah HTTP sederhana: GET, PUT, POST, dll. Kami terutama akan bekerja dengan RESTful API, tetapi metode dasar dapat digunakan dan API lainnya.
Sebagai contoh, ambil Open Data Protocol (OData) populer untuk RESTful API dan dua web API dari paket Microsoft Graph API (Gambar 1), yang, masing-masing, digunakan untuk mencari email dan acara kalender pengguna. Sumber daya di OData adalah entitas, yang masing-masing terkait dengan daftar properti. Misalnya, entitas Pesan - email - memiliki properti seperti subjek (subjek), dari (dari), isRead (baca), diterimaDateTime (tanggal dan waktu penerimaan), dll.
Selain itu, OData mendefinisikan satu set parameter kueri, memungkinkan Anda untuk melakukan manipulasi lanjutan pada sumber daya. Misalnya, parameter FILTER memungkinkan Anda mencari email dari pengirim atau surat tertentu yang diterima pada tanggal tertentu. Parameter permintaan yang akan kami gunakan disajikan pada Tabel 1. Kami memanggil setiap kombinasi perintah HTTP dan entitas (atau set entitas) sebagai API, misalnya, GET-Pesan - untuk mencari email. Setiap permintaan parameter, misalnya, FILTER (isRead = False), disebut parameter, dan panggilan API adalah API dengan daftar parameter.
NL2API
Tugas utama NLI adalah membandingkan pernyataan (perintah dalam bahasa alami) dengan representasi formal tertentu, misalnya, formulir logis atau kueri SPARQL untuk basis pengetahuan atau API web dalam kasus kami. Ketika perlu untuk fokus pada pemetaan semantik tanpa terganggu oleh detail yang tidak relevan, representasi semantik menengah biasanya digunakan agar tidak bekerja secara langsung dengan target. Misalnya, tata bahasa kategori kombinatorial banyak digunakan dalam menciptakan NLI untuk basis data dan basis pengetahuan. Pendekatan serupa dengan abstraksi juga sangat penting untuk NL2API. Banyak detail, termasuk konvensi URL, header HTTP, dan kode respons, dapat "mengalihkan" NL2API dari penyelesaian masalah utama - pemetaan semantik.
Oleh karena itu, kami membuat tampilan perantara untuk RESTful APIs (Gambar 2) dengan bingkai nama API, tampilan ini mencerminkan semantik dari frame. Bingkai API terdiri dari lima bagian. HTTP Verb (HTTP Command) dan Resource adalah elemen dasar untuk RESTful API. Return Type memungkinkan Anda untuk membuat API komposit, yaitu, menggabungkan beberapa panggilan API untuk melakukan operasi yang lebih kompleks. Parameter yang Diperlukan paling sering digunakan dalam panggilan PUT atau POST di API, misalnya, alamat, header, dan isi pesan adalah parameter yang diperlukan untuk mengirim email. Parameter opsional sering hadir dalam GET panggilan di API, mereka membantu mempersempit permintaan informasi.
Jika parameter yang diperlukan tidak ada, kami membuat serialisasi kerangka API, misalnya: GET-messages {FILTER (isRead = False), SEARCH ("aplikasi PhD"), COUNT ()}. Frame API dapat bersifat deterministik dan dikonversi menjadi panggilan API yang nyata. Selama proses konversi, data kontekstual yang diperlukan akan ditambahkan, termasuk ID pengguna, lokasi, tanggal dan waktu. Dalam contoh kedua (Gambar 1), nilai sekarang dalam parameter FILTER akan diganti dengan tanggal dan waktu pelaksanaan perintah terkait selama konversi frame API menjadi panggilan API nyata. Selanjutnya, konsep-konsep kerangka API dan panggilan API akan digunakan secara bergantian.
 Gambar 2. Frame API. Atas: tim bahasa alami. Di tengah: Frame API. Bawah: Panggilan API.
Gambar 2. Frame API. Atas: tim bahasa alami. Di tengah: Frame API. Bawah: Panggilan API.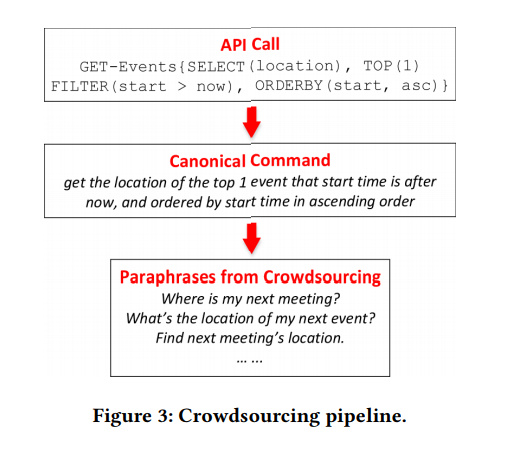 Gambar 3. Konveyor crowdsourcing.
Gambar 3. Konveyor crowdsourcing.Pengumpulan data pelatihan
Bagian ini menjelaskan pendekatan baru yang secara mendasar kami tawarkan untuk pengumpulan data pelatihan untuk solusi NL2API menggunakan crowdsourcing. Pertama, kami membuat panggilan API dan mengonversinya masing-masing menjadi tim kanonik, mengandalkan tata bahasa sederhana (bagian 3.1), dan kemudian kami menarik pekerja crowdsourcing untuk membentuk ulang tim kanonik (Gambar 3). Mengingat sifat komposisi panggilan API, kami mengusulkan model crowdsourcing probabilistik hirarkis (bagian 3.2), serta algoritma untuk optimasi crowdsourcing (bagian 3.3).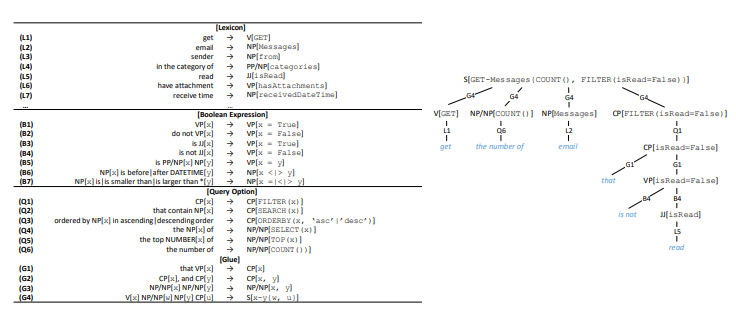 Gambar 4. Generasi perintah Canonical. Kiri: leksikon dan tata bahasa. Kanan: contoh derivasi.
Gambar 4. Generasi perintah Canonical. Kiri: leksikon dan tata bahasa. Kanan: contoh derivasi.Panggilan API dan perintah kanonik
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
Kami dapat menghasilkan sejumlah besar panggilan API menggunakan pendekatan di atas, tetapi menjelaskan semuanya menggunakan crowdsourcing tidak layak secara ekonomi. Oleh karena itu, kami mengusulkan model probabilistik hierarkis untuk crowdsourcing yang membantu Anda memutuskan panggilan API mana yang harus dianotasi. Sejauh yang kita tahu, ini adalah model probabilistik pertama menggunakan crowdsourcing untuk membuat antarmuka NLI, yang memungkinkan kita untuk menyelesaikan tugas yang unik dan menarik dari pemodelan interaksi antara representasi bahasa alami dan representasi struktur semantik yang diformalkan. Representasi formal dari struktur semantik pada umumnya dan panggilan API pada khususnya bersifat komposisional. Misalnya, z12 = GET-Pesan {COUNT (), FILTER (isRead = False)} terdiri dari z1 = GET-Pesan {FILTER (isRead = False)} dan z2 = GET-Pesan-pesan {COUNT ()} (contoh-contoh ini lebih rinci diskusikan lebih lanjut).
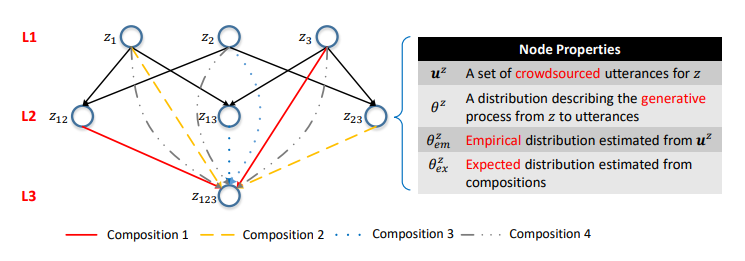 Gambar 5. Jaringan semantik. Lapisan ke-i terdiri dari panggilan API dengan parameter i. Iga adalah komposisi. Distribusi probabilitas pada simpul mencirikan model bahasa yang sesuai.
Gambar 5. Jaringan semantik. Lapisan ke-i terdiri dari panggilan API dengan parameter i. Iga adalah komposisi. Distribusi probabilitas pada simpul mencirikan model bahasa yang sesuai.Salah satu hasil utama dari penelitian kami adalah konfirmasi bahwa komposisi tersebut dapat digunakan untuk memodelkan proses crowdsourcing.
Pertama, kami mendefinisikan komposisi berdasarkan pada set parameter panggilan API.
Definisi 3.1 (komposisi). Ambil API dan satu set panggilan API
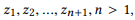
jika kita mendefinisikan r (z) sebagai seperangkat parameter untuk z, maka
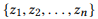
adalah komposisi
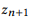
jika dan hanya jika
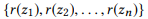
adalah bagian
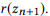
Berdasarkan pada hubungan komposisi panggilan API, Anda dapat mengatur semua panggilan API ke dalam struktur hierarki tunggal. Panggilan API dengan jumlah parameter yang sama direpresentasikan sebagai simpul dari satu layer, dan komposisi diwakili sebagai
rusuk diarahkan antara lapisan. Kami menyebut struktur ini sebagai jaringan sematic (atau SeMesh).
Dengan analogi dengan pendekatan yang didasarkan pada pemodelan bahasa dalam pencarian informasi, kami mengasumsikan bahwa pernyataan yang berkaitan dengan satu panggilan API z dihasilkan menggunakan proses stokastik yang ditandai dengan model bahasa
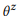
. Untuk mempermudah, kami fokus pada kemungkinan kata-kata

dimana
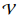
menunjukkan kamus.
Untuk alasan yang akan menjadi jelas beberapa saat kemudian, alih-alih model unigram bahasa standar, kami sarankan menggunakan satu set distribusi Bernoulli (Bag of Bernoulli, BoB). Setiap distribusi Bernoulli sesuai dengan variabel acak W, menentukan apakah kata w muncul dalam kalimat yang dihasilkan berdasarkan z, dan distribusi BoB adalah seperangkat distribusi Bernoulli untuk semua kata

. Kami akan gunakan
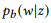
sebagai notasi singkat untuk
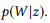
.
Misalkan kita telah membentuk seperangkat pernyataan (multi)

untuk z,
estimasi kemungkinan maksimum (MLE) untuk distribusi BoB memungkinkan Anda memilih pernyataan yang mengandung w:
 Contoh 2.
Contoh 2. Mengenai panggilan API di atas z1, misalkan kita mendapat dua pernyataan u1 = "temukan email yang belum dibaca" dan u2 = "email yang tidak dibaca", lalu u = {u1, u2}. pb ("email" | z) = 1.0, karena "email" ada di kedua pernyataan. Demikian pula, pb ("belum dibaca" | z) = 0,5 dan pb ("pertemuan" | z) = 0,0.
Di jaringan semantik, ada tiga operasi dasar di tingkat verteks:
Anotasi, tata letak, dan interpolasi.
ANNOTATE (to annotate) artinya mengumpulkan pernyataan
untuk memparafrasekan perintah kanonik dari simpul z menggunakan crowdsourcing dan mengevaluasi distribusi empiris
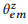
metode kemungkinan maksimum.
KOMPOS (susun) mencoba menurunkan model bahasa berdasarkan komposisi untuk menghitung distribusi yang diharapkan
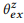
. Seperti yang kami tunjukkan secara eksperimental,
Merupakan komposisi untuk z. Jika kita melanjutkan dari asumsi bahwa pernyataan yang sesuai dicirikan oleh koneksi komposisi yang sama, maka
harus diletakkan di atas

:

di mana f adalah fungsi komposisi. Untuk distribusi BoB, fungsi komposisi akan terlihat seperti ini:
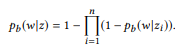
Dengan kata lain, jika ui adalah pernyataan zi, u adalah pernyataan
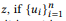
secara komposisi membentuk u, maka kata w bukan milik u. Jika dan hanya jika itu bukan milik ui. Ketika z memiliki banyak komposisi, θe x dihitung secara terpisah dan kemudian dirata-ratakan. Model unigram bahasa standar tidak mengarah pada fungsi komposisi alami. Dalam proses normalisasi probabilitas kata, panjang kalimat terlibat, yang, pada gilirannya, memperhitungkan kompleksitas panggilan API, melanggar dekomposisi dalam persamaan (2). Itu sebabnya kami menawarkan distribusi BoB.
Contoh 3. Misalkan kita menyiapkan anotasi untuk panggilan API yang disebutkan sebelumnya z1 dan z2, masing-masing memiliki dua pernyataan:
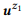
= {"Temukan email yang belum dibaca", "email yang belum dibaca"} dan
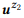
= {"Berapa banyak email yang saya miliki", "temukan jumlah email"}. Kami memberi peringkat model bahasa
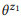
dan
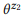
. Operasi komposisi sedang mencoba untuk mengevaluasi
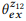
tanpa bertanya
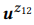
. Misalnya, untuk kata "email", pb ("email" | z1) = 1.0 dan pb ("email" | z2) = 1.0, jadi berikut dari persamaan (3) bahwa pb ("email" | z12) = 1.0, yaitu, kami percaya bahwa kata ini akan dimasukkan dalam pernyataan apa pun dari z12. Demikian pula, pb ("find" | z1) = 0,5 dan pb ("find" | z2) = 0,5, jadi pb ("find" | z12) = 0,75. Sebuah kata memiliki peluang bagus dihasilkan dari z1 atau z2, jadi probabilitasnya untuk z12 harus lebih tinggi.
Tentu saja, pernyataan tidak selalu digabungkan secara komposisi. Sebagai contoh, beberapa elemen dalam representasi formal dari struktur semantik dapat disampaikan dalam satu kata atau frase dalam bahasa alami, fenomena ini disebut komposisionalitas sublexic. Salah satu contoh tersebut ditunjukkan pada Gambar 3, di mana tiga parameter - TOP (1), FILTER (mulai> sekarang), dan ORDERBY (mulai, naik) —direpresentasikan oleh satu kata "berikutnya". Namun, tidak mungkin untuk mendapatkan informasi tersebut tanpa membuat anotasi panggilan API, sehingga masalahnya sendiri mirip dengan masalah ayam dan telur. Dengan tidak adanya informasi tersebut, masuk akal untuk mematuhi asumsi default bahwa pernyataan dikarakteristikkan dengan hubungan komposisi yang sama dengan panggilan API.
Ini adalah asumsi yang masuk akal. Perlu dicatat bahwa asumsi ini hanya digunakan untuk memodelkan proses crowdsourcing dengan tujuan mengumpulkan data. Pada tahap pengujian, pernyataan pengguna nyata mungkin tidak sesuai dengan asumsi ini. Antarmuka bahasa alami akan dapat mengatasi situasi non-komposisi tersebut jika dicakup oleh data pelatihan yang dikumpulkan.
INTERPOLATE (interpolasi) menggabungkan semua informasi yang tersedia tentang z, yaitu, ucapan beranotasi z dan informasi yang diperoleh dari komposisi, dan mendapatkan perkiraan yang lebih akurat
dengan interpolasi
dan
.
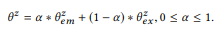
Parameter keseimbangan α mengontrol pertukaran antara anotasi
puncak saat ini yang akurat tetapi memadai, dan informasi yang diperoleh dari komposisi berdasarkan asumsi komposisi mungkin tidak seakurat, tetapi memberikan cakupan yang lebih luas. Dalam arti tertentu,
melayani tujuan yang sama dengan anti-aliasing dalam pemodelan bahasa, yang memungkinkan perkiraan distribusi probabilitas yang lebih baik dengan data yang tidak memadai (anotasi). Lebih dari
semakin berat di
. Untuk simpul akar yang tidak memiliki komposisi,
=
. Untuk bagian atas yang tidak ditandai
=
.
Selanjutnya, kami menggambarkan algoritma pembaruan jaringan semantik, mis., Perhitungan
untuk semua z (algoritme 1), bahkan jika hanya sebagian kecil dari simpul diberi penjelasan. Kami menganggap itu nilainya
Sudah diperbarui untuk semua situs beranotasi. Turun dari atas ke bawah, kami menghitung secara berurutan
dan
untuk setiap simpul z. Pertama, Anda perlu memperbarui lapisan atas sehingga Anda dapat menghitung distribusi simpul yang diharapkan dari tingkat yang lebih rendah. Kami menjelaskan semua simpul akar, sehingga kami dapat menghitung
untuk semua simpul.
Algoritma 1. Memperbarui Distribusi Node dari Semantic Mesh
3.3 Optimalisasi Crowdsourcing
Jaringan semantik membentuk pandangan holistik dari seluruh ruang panggilan API, serta interaksi pernyataan dan panggilan. Berdasarkan tampilan ini, kami hanya dapat membubuhi keterangan selektif panggilan API bernilai tinggi. Di bagian ini, kami menjelaskan strategi distribusi diferensial kami untuk mengoptimalkan crowdsourcing.
Pertimbangkan jaringan semantik dengan banyak simpul Z. Tugas kita adalah menentukan subset simpul dalam proses berulang
untuk dijelaskan oleh pekerja crowdsourcing. Verteks yang dianotasi sebelumnya akan disebut state state,
maka kita perlu menemukan kebijakan kebijakan

untuk mengevaluasi setiap simpul yang tidak ditandai berdasarkan kondisi saat ini.
Sebelum membahas diskusi tentang pendekatan untuk menghitung kebijakan yang efektif, anggaplah kita sudah memiliki satu dan memberikan deskripsi tingkat tinggi dari algoritma crowdsourcing kami (Algoritma 2) untuk menggambarkan metode yang menyertainya. Lebih khusus lagi, pertama-tama kita membubuhi keterangan semua simpul akar untuk mengevaluasi distribusi untuk semua simpul di Z (baris 3). Pada setiap iterasi, kami memperbarui distribusi titik (baris 5), menghitung
kebijakan yang didasarkan pada keadaan saat ini dari jaringan semantik (baris 6), pilih titik yang tidak ditandai dengan peringkat maksimum (baris 7), dan beri catatan pada titik dan hasil dalam keadaan baru (baris 8). Secara praktis, Anda dapat membuat anotasi beberapa simpul sebagai bagian dari iterasi untuk meningkatkan efisiensi.
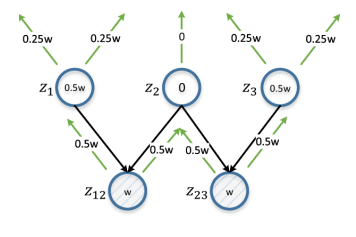 Gambar 6. Distribusi diferensial. z12 dan z23 mewakili pasangan simpul yang diteliti. w adalah estimasi yang dihitung berdasarkan d (z12, z23), dan secara iteratif merambat dari bawah ke atas, dua kali lipat dalam setiap iterasi. Estimasi untuk vertex akan menjadi perbedaan absolut dari estimasi dari z12 dan z23 (oleh karena itu diferensial). z2 mendapat skor 0 karena itu adalah entitas induk yang umum untuk z12 dan z23; penjelasan dalam hal ini akan sedikit berguna dalam hal memastikan dibedakannya z12 dan z23.
Gambar 6. Distribusi diferensial. z12 dan z23 mewakili pasangan simpul yang diteliti. w adalah estimasi yang dihitung berdasarkan d (z12, z23), dan secara iteratif merambat dari bawah ke atas, dua kali lipat dalam setiap iterasi. Estimasi untuk vertex akan menjadi perbedaan absolut dari estimasi dari z12 dan z23 (oleh karena itu diferensial). z2 mendapat skor 0 karena itu adalah entitas induk yang umum untuk z12 dan z23; penjelasan dalam hal ini akan sedikit berguna dalam hal memastikan dibedakannya z12 dan z23.Dalam arti luas, tugas-tugas yang kita selesaikan dapat dikaitkan dengan masalah pembelajaran aktif, kita menetapkan diri kita tujuan mengidentifikasi subset contoh untuk penjelasan untuk mendapatkan satu set pelatihan yang dapat meningkatkan hasil belajar. Namun, beberapa perbedaan utama tidak memungkinkan aplikasi langsung dari metode pengajaran aktif klasik, seperti "ketidakpastian sampling". Biasanya, dalam proses pembelajaran aktif, siswa, yang dalam kasus kami akan menjadi antarmuka NLI, mencoba mempelajari pemetaan f: X → Y, di mana X adalah sampel ruang input, yang terdiri dari set kecil sampel bertanda dan sejumlah besar sampel yang tidak ditandai, dan Y biasanya satu set spidol kelas.
Siswa mengevaluasi nilai informatif dari contoh yang tidak berlabel dan memilih yang paling informatif untuk mendapatkan nilai Y dari pekerja crowdsourcing. Namun dalam kerangka masalah yang kami selesaikan, masalah anotasi diajukan secara berbeda. Kita perlu memilih contoh dari Y, ruang panggilan API yang besar, dan meminta pekerja crowdsourcing untuk memberi label dengan menentukan pola dalam X, ruang kalimat. Selain itu, kami tidak terikat dengan peserta pelatihan tertentu. Jadi, kami mengusulkan solusi baru untuk masalah yang dihadapi. Kami mengambil inspirasi dari berbagai sumber tentang pembelajaran aktif.
Pertama, kita akan menentukan tujuan, di mana konten informasi dari node akan dievaluasi. Jelas, kami ingin panggilan API yang berbeda dapat dibedakan. Dalam jaringan semantik, ini berarti distribusi
puncak yang berbeda memiliki perbedaan yang jelas. Untuk mulai dengan, kami menyajikan setiap distribusi
seperti vektor n-dimensi

dimana n = |
| - ukuran kamus. Dengan metrik tertentu dari jarak vektor d (dalam percobaan kami, kami menggunakan jarak antara vektor pL1) yang kami maksud

, yaitu, jarak antara dua simpul sama dengan jarak antara distribusinya.
Tujuan yang jelas adalah untuk memaksimalkan jarak total antara semua pasangan simpul. Namun, optimasi semua jarak berpasangan mungkin terlalu rumit untuk perhitungan, dan bahkan ini tidak perlu. Sepasang puncak yang jauh sudah memiliki perbedaan yang cukup, sehingga peningkatan jarak lebih jauh tidak masuk akal. Sebagai gantinya, kita bisa fokus pada pasangan simpul yang paling membingungkan, yaitu jarak di antara mereka adalah yang terkecil.
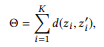
dimana
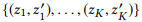
menunjuk ke K pasang simpul pertama jika kita memberi peringkat semua pasangan node berdasarkan jarak dalam urutan menaik.
Algoritma 2. Beranotasi dengan Semantic Mesh dengan Kebijakan Algoritma 3. Hitung Kebijakan berdasarkan Diferensial Propagasi
Algoritma 3. Hitung Kebijakan berdasarkan Diferensial Propagasi Algoritma 4. Menyebarkan Skor dari Node Sumber ke Semua Node Induknya secara Rekursif
Algoritma 4. Menyebarkan Skor dari Node Sumber ke Semua Node Induknya secara Rekursif
Simpul dengan konten informasi yang lebih tinggi setelah anotasi berpotensi meningkatkan nilai Θ. Untuk kuantifikasi dalam kasus ini, kami mengusulkan menggunakan strategi distribusi diferensial. Jika jarak antara sepasang simpul kecil, kami memeriksa semua simpul induknya: jika simpul induk adalah umum untuk sepasang simpul, itu harus mendapatkan peringkat rendah, karena anotasi akan menyebabkan perubahan yang serupa untuk kedua simpul.
Jika tidak, simpul harus diberi peringkat tinggi, dan semakin dekat pasangan simpul, semakin tinggi peringkatnya. Misalnya, jika jarak antara simpul "email yang belum dibaca tentang aplikasi PhD" dan "berapa banyak email tentang aplikasi PhD" kecil, maka anotasi simpul orang tua mereka "email tentang aplikasi PhD" tidak masuk akal dari sudut pandang membedakan simpul ini. Lebih disarankan untuk membuat anotasi node induk yang tidak akan umum bagi mereka: "email yang belum dibaca" dan "berapa banyak email".
Contoh dari situasi seperti itu ditunjukkan pada Gambar 6, dan algoritmanya adalah algoritma 3. Sebagai perkiraan, kami mengambil kebalikan dari jarak simpul yang dibatasi oleh konstanta (garis 6), sehingga pasangan simpul terdekat memiliki dampak terbesar. Ketika bekerja dengan sepasang simpul, kami secara bersamaan menetapkan penilaian setiap simpul untuk semua simpul induknya (baris 9, 10 dan algoritma 4). Perkiraan dari simpul yang tidak dinotasikan adalah perbedaan mutlak dalam perkiraan pasangan simpul yang sesuai dengan penjumlahan atas semua pasangan simpul (baris 12).
Antarmuka Bahasa Alami
Untuk mengevaluasi kerangka yang diusulkan, perlu untuk melatih model NL2API menggunakan data yang dikumpulkan. Saat ini, model NL2API yang sudah jadi tidak tersedia, tetapi kami mengadaptasi dua model NLI yang diuji dari area lain untuk menerapkannya ke API.
Model Ekstraksi Model Bahasa
Berdasarkan perkembangan terakhir di bidang NLI untuk basis pengetahuan, kita dapat mempertimbangkan pembuatan NL2API dalam konteks masalah ekstraksi informasi untuk menyesuaikan model ekstraksi berdasarkan model bahasa (LM) dengan kondisi kami.
Untuk mengatakan Anda, Anda perlu menemukan panggilan z API di jaringan semantik dengan kecocokan terbaik untuk Anda. Pertama kami mengubah distribusi BoB

setiap panggilan API z ke model unigram bahasa:
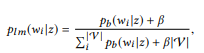
di mana kita menggunakan smoothing aditif, dan 0 ≤ β ≤ 1 adalah parameter smoothing. Nilai lebih tinggi
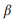
, semakin besar bobot kata yang belum dianalisis. Panggilan API dapat diberi peringkat berdasarkan probabilitas logaritmiknya:
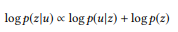
(dikenakan seragam distribusi probabilitas apriori)
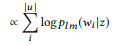
Panggilan API berperingkat tertinggi digunakan sebagai hasil simulasi.
Modul susun ulang Seq2Seq
Jaringan saraf menjadi lebih luas sebagai model untuk NLI, sedangkan model Seq2Seq lebih baik daripada yang lain untuk tujuan ini, karena memungkinkan Anda untuk secara alami memproses input dan output urutan panjang variabel. Kami mengadaptasi model ini untuk NL2API.
Untuk urutan input e

, model memperkirakan distribusi probabilitas bersyarat p (y | x) untuk semua urutan output yang mungkin
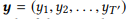
. Panjang T dan T ′ dapat bervariasi dan mengambil nilai apa pun. Dalam NL2API, x adalah pernyataan keluaran. y dapat berupa panggilan API serial atau perintah kanoniknya. Kami akan menggunakan perintah kanonik sebagai urutan output target, yang sebenarnya mengubah masalah kami menjadi masalah pengulangan kata.
Encoder diimplementasikan sebagai jaringan saraf berulang (RNN) dengan unit perulangan terkontrol (GRU) pertama kali mewakili x sebagai vektor ukuran tetap,

di mana RN N adalah representasi singkat untuk menerapkan GRU ke seluruh urutan input, penanda demi penanda, diikuti oleh output dari status tersembunyi terakhir.
Dekoder, yang juga merupakan RNN dengan GRU, mengambil h0 sebagai keadaan awal dan memproses urutan keluaran y, penanda demi penanda, untuk menghasilkan urutan keadaan,

Lapisan output mengambil setiap status dekoder sebagai nilai input dan menghasilkan distribusi kamus
sebagai nilai output. Kami hanya menggunakan transformasi affine diikuti oleh softmax fungsi logistik multi-variabel:
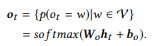
Probabilitas kondisional akhir, yang memungkinkan kita untuk mengevaluasi seberapa baik perintah kanonik y mengulangi pernyataan input x, adalah

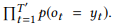
. Panggilan API kemudian diberi peringkat berdasarkan probabilitas kondisional dari perintah kanonik mereka. Kami menyarankan Anda membiasakan diri dengan sumbernya, di mana proses pembelajaran model dijelaskan secara lebih rinci.
Eksperimen
Secara eksperimental, kami mempelajari subjek penelitian berikut: [PI1]: Bisakah kita menggunakan kerangka kerja yang diusulkan untuk mengumpulkan data pelatihan berkualitas tinggi dengan harga yang wajar? [PI2]: Apakah jaringan semantik memberikan penilaian model bahasa yang lebih akurat daripada penilaian kemungkinan maksimum? [PI3]: Apakah strategi distribusi diferensial meningkatkan efisiensi crowdsourcing?
Crowdsourcing
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
 2. API.
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
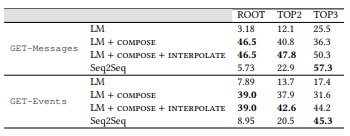
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
dan
, , ROOT,
dan
. , , . MLE. , , [2] .
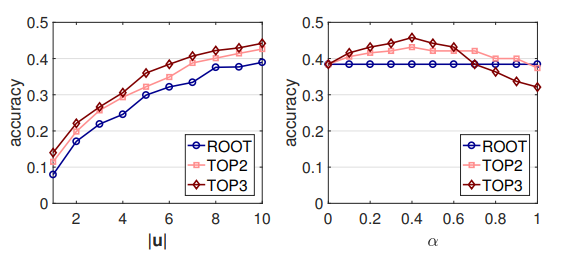
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
7. .
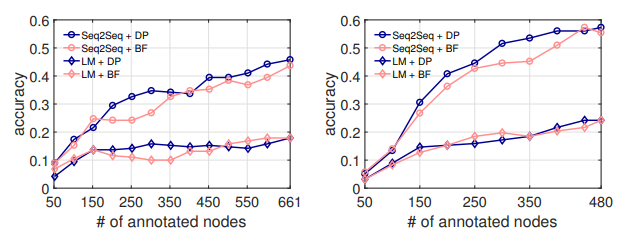
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?