Bagaimana saya bisa mencetak aliran pesan yang berkelanjutan dari Twitter dengan beberapa baris kode dengan menambahkan data cuaca ke tempat-tempat tinggal penulisnya? Dan bagaimana Anda dapat membatasi kecepatan permintaan ke penyedia cuaca sehingga mereka tidak memasukkan kami ke daftar hitam?
Hari ini kami akan memberi tahu Anda bagaimana melakukannya, tetapi pertama-tama kita akan mengenal teknologi Akka Streams, yang membuat bekerja dengan aliran data real-time semudah programmer bekerja dengan ekspresi LINQ tanpa memerlukan implementasi aktor individu atau antarmuka Reactive Streams. .
Artikel ini didasarkan pada transkrip dari
laporan Vagif Abilov dari konferensi Desember kami DotNext 2017 Moscow.
Nama saya Vagif, saya bekerja untuk perusahaan Norwegia, Miles. Hari ini kita akan berbicara tentang perpustakaan Akka Streams.
Akka dan Reactive Streaming adalah persimpangan dari set yang cukup sempit, dan orang mungkin mendapatkan kesan bahwa ini adalah ceruk yang Anda butuhkan untuk memiliki pengetahuan yang hebat untuk masuk, tetapi justru sebaliknya. Dan artikel ini dimaksudkan untuk menunjukkan bahwa dengan menggunakan Akka Streams, Anda dapat menghindari pemrograman tingkat rendah yang diperlukan saat menggunakan Reactive Streams dan Akka.NET. Ke depan, saya dapat langsung mengatakan: jika pada awal proyek kami, di mana kami menggunakan Akka, kami tahu tentang keberadaan Akka Streams, kami akan menulis banyak berbeda, kami akan menghemat waktu dan kode.
"Mungkin yang terburuk yang bisa kamu lakukan adalah membuat orang yang tidak kesakitan untuk minum aspirin."
Max Kreminski
“Pintu tertutup, sakit kepala, dan kebutuhan intelektual”
Sebelum kita masuk ke detail teknis, sedikit tentang apa jalan Anda menuju Akka Streams dan apa yang bisa membawa Anda ke sana. Suatu hari saya menemukan blog Max Kreminski, di mana dia mengajukan pertanyaan filosofis untuk programmer: bagaimana atau mengapa tidak mungkin bagi seorang programmer untuk menjelaskan apa itu monad. Dia menjelaskannya dengan cara ini: sangat sering orang langsung pergi ke detail teknis, menjelaskan betapa indahnya pemrograman fungsional dan seberapa banyak pengertian yang ada di monad, tanpa repot-repot bertanya-tanya mengapa programmer mungkin membutuhkannya sama sekali. Menggambar analogi, itu seperti mencoba menjual aspirin tanpa repot-repot mencari tahu apakah pasien Anda sakit.
Dengan menggunakan analogi ini, saya ingin mengajukan pertanyaan berikut: jika Akka Streams adalah aspirin, lalu apa rasa sakit yang akan menuntun Anda ke sana?
Streaming data
Pertama, mari kita bicara tentang aliran data. Alurnya bisa sangat sederhana, linier.
Di sini kami memiliki konsumen data tertentu (kelinci dalam video). Ini mengkonsumsi data pada kecepatan yang sesuai dengannya. Ini adalah interaksi ideal konsumen dengan arus: ia menetapkan bandwidth, dan data mengalir dengan tenang ke sana. Aliran data sederhana ini bisa tak terbatas, atau bisa berakhir.
Tetapi alirannya mungkin lebih kompleks. Jika Anda menanam beberapa kelinci berdampingan, kita akan memiliki paralelisasi aliran. Apa yang Reactive Streaming coba selesaikan adalah bagaimana tepatnya kita dapat berkomunikasi dengan aliran pada tingkat yang lebih konseptual, mis., Terlepas dari apakah kita hanya berbicara tentang semacam pengukuran sensor suhu, di mana pengukuran linear masuk , atau kami memiliki pengukuran terus menerus dari ribuan sensor suhu yang memasuki sistem melalui antrian RabbitMQ dan disimpan dalam log sistem. Semua hal di atas dapat dianggap sebagai satu aliran komposit. Jika Anda melangkah lebih jauh, maka manajemen produksi otomatis (misalnya, oleh beberapa toko online) juga dapat direduksi menjadi aliran data, dan alangkah baiknya jika kita dapat berbicara tentang perencanaan aliran semacam itu, tidak peduli betapa rumitnya itu.

Untuk proyek-proyek modern, dukungan utas tidak terlalu baik. Jika saya ingat dengan benar, Aaron Stannard, yang tweet-nya Anda lihat di gambar, ingin mendapatkan aliran file multi-gigabyte yang mengandung CSV, mis. teks, dan ternyata tidak ada yang bisa Anda ambil dan gunakan segera, tanpa banyak tindakan tambahan. Tapi dia tidak bisa mendapatkan aliran nilai CSV, yang membuatnya sedih. Ada beberapa solusi (dengan pengecualian beberapa area khusus), banyak hal yang diterapkan oleh metode lama, ketika kita membuka semua ini, mulai membaca, buffering, dalam kasus terburuk, kita mendapatkan sesuatu seperti notepad yang mengatakan file terlalu besar.
Pada tingkat konseptual yang tinggi, kita semua terlibat dalam pemrosesan aliran data, dan Akka Streaming akan membantu Anda jika:
- Anda terbiasa dengan Akka, tetapi ingin menyisihkan diri Anda detail yang terkait dengan penulisan kode aktor dan koordinasinya;
- Anda terbiasa dengan Aliran Reaktif dan ingin menggunakan implementasi spesifikasi mereka yang sudah jadi;
- Elemen blok Akka Streams untuk tahapan cocok untuk memodelkan proses Anda;
- Anda ingin mengambil keuntungan dari tekanan balik Akka Streams (tekanan balik) untuk mengelola dan memperbaiki secara bertahap tahapan throughput dari alur kerja Anda.
Dari aktor ke Akka Streams

Cara pertama adalah dari aktor ke Akka Streams, caraku.
Gambar menunjukkan mengapa kami mulai menggunakan model aktor. Kami lelah oleh kontrol manual arus, keadaan bersama, itu saja. Setiap orang yang telah bekerja dengan sistem besar, dengan yang multi-threaded, memahami berapa banyak ini membutuhkan waktu dan betapa mudahnya membuat kesalahan di dalamnya, yang bisa berakibat fatal bagi keseluruhan proses. Ini membawa kami ke model aktor. Kami tidak menyesali pilihan yang dibuat, tetapi, tentu saja, ketika Anda mulai bekerja dan pemrograman lebih banyak, itu bukan karena antusiasme awal memberi jalan kepada sesuatu yang lain, tetapi Anda mulai menyadari bahwa sesuatu dapat dilakukan bahkan lebih efektif.
“Secara default, penerima pesan mereka dimasukkan dalam kode aktor. Jika saya membuat aktor A yang mengirim pesan ke aktor B, dan Anda ingin mengganti penerima dengan aktor C, dalam kasus umum ini tidak akan berfungsi untuk Anda ”
Noel Welch (garis bawah.io)
Aktor dikritik karena tidak menulis. Salah satu yang pertama menulis tentang ini di blog-nya adalah Noel Welch, salah satu pengembang Underscore. Dia memperhatikan bahwa sistem aktor terlihat seperti ini:

Jika Anda tidak menggunakan hal-hal tambahan, seperti injeksi ketergantungan, alamat penerimanya dijahit ke aktor.

Ketika mereka mulai mengirim pesan satu sama lain, semua ini Anda tetapkan sebelumnya, para aktor pemrograman. Dan tanpa trik tambahan, sistem kaku seperti itu diperoleh.
Salah satu pengembang Akka, Roland Kuhn,
menjelaskan apa yang umumnya dimaksud dengan tata letak yang buruk. Metode aktor didasarkan pada metode tell, mis., Pesan searah: itu adalah tipe void, mis. Tidak mengembalikan apa pun (atau unit, tergantung pada bahasanya). Oleh karena itu, mustahil untuk membangun deskripsi proses dari rantai aktor. Jadi Anda kirim kirim, lalu apa? Berhenti Kami batal. Anda dapat membandingkannya, misalnya, dengan ekspresi LINQ, di mana setiap elemen dari ekspresi mengembalikan IQueryable, IEnumerable, dan semua ini dapat dengan mudah dikompilasi. Aktor tidak memberikan kesempatan seperti itu. Pada saat yang sama, Roland Kuhn keberatan dengan fakta bahwa mereka, kata mereka, tidak menyusun prinsip, mengatakan bahwa sebenarnya mereka disusun dengan cara lain, dalam arti yang sama di mana masyarakat manusia menyesuaikan diri dengan tata letak. Kedengarannya seperti argumen filosofis, tetapi jika Anda memikirkannya, analoginya masuk akal - ya, para aktor saling mengirim pesan satu arah, tetapi kami juga berkomunikasi satu sama lain, mengucapkan pesan satu arah, tetapi pada saat yang sama kami berinteraksi dengan cukup efektif, yaitu, kami menciptakan sistem yang kompleks. Namun demikian, kritik terhadap aktor seperti itu tetap ada.
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { } private void Idle() { Receive<Job>(job => ); } private void Working() { Receive<Cancel>(job => ); } }
Selain itu, implementasi aktor membutuhkan setidaknya menulis kelas jika Anda bekerja di C #, atau berfungsi jika Anda bekerja di F #. Dalam contoh di atas - kode boilerplate, yang harus Anda tulis dalam hal apa pun. Meskipun tidak terlalu besar, itu adalah sejumlah baris tertentu yang harus selalu Anda tulis di tingkat rendah ini. Hampir semua kode yang ada di sini adalah semacam upacara. Apa yang terjadi ketika seorang aktor langsung menerima pesan sama sekali tidak ditampilkan di sini. Dan semua ini perlu ditulis. Ini, tentu saja, tidak terlalu banyak, tetapi ini adalah bukti bahwa kami bekerja dengan para aktor di tingkat rendah, menciptakan metode yang tidak berlaku.
Bagaimana jika kita dapat pergi ke tingkat yang berbeda, lebih tinggi, bertanya pada diri sendiri pertanyaan pemodelan proses kami, yang meliputi pemrosesan data dari berbagai sumber yang dicampur, dikonversi dan ditransfer?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Sebuah analog dari pendekatan ini adalah apa yang kita semua telah terbiasa bekerja dengan LINQ selama sepuluh tahun. Kami tidak heran bagaimana gabung bekerja. Kami tahu bahwa ada penyedia LINQ yang akan melakukan semua ini untuk kami, dan kami tertarik pada tingkat yang lebih tinggi dalam memenuhi permintaan. Dan kami biasanya dapat mencampur database di sini, kami dapat mengirim permintaan distributif. Bagaimana jika Anda bisa menggambarkan prosesnya dengan cara ini?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word)
(Sumber)Atau, misalnya, transformasi fungsional. Yang disukai banyak orang tentang pemrograman fungsional adalah Anda dapat melewatkan data melalui serangkaian transformasi, dan Anda mendapatkan kode ringkas yang cukup jelas, terlepas dari bahasa apa Anda menulisnya. Cukup mudah dibaca. Kode dalam gambar secara khusus ditulis dalam F #, tetapi secara umum, mungkin, semua orang mengerti apa yang terjadi di sini.
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~>
(Sumber)Bagaimana dengan ini? Dalam contoh di atas, kami memiliki sumber data sumber, yang terdiri dari bilangan bulat dari 1 hingga 10. Ini adalah apa yang disebut DSL grafis (bahasa khusus domain). Elemen-elemen dari bahasa domain pada contoh di atas adalah simbol panah searah - ini adalah operator tambahan yang didefinisikan oleh alat bahasa yang secara grafis menunjukkan arah aliran. Kami melewati Source melalui serangkaian transformasi - untuk memudahkan demonstrasi, mereka semua hanya menambahkan sepuluh ke angka. Selanjutnya, Broadcast: kami mengalikan saluran, yaitu setiap nomor memasuki dua saluran. Lalu kami menambahkan 10 lagi, mencampur aliran data kami, mendapatkan aliran baru, menambahkan 10 juga, dan semua ini mengalir ke aliran data kami, di mana tidak ada yang terjadi. Ini adalah kode asli yang ditulis dalam Scala, bagian dari Akka Streams, diimplementasikan dalam bahasa ini. Artinya, Anda menentukan fase transformasi data Anda, menunjukkan apa yang harus dilakukan dengan mereka, menentukan sumber, stok, beberapa pos pemeriksaan, dan kemudian membentuk grafik seperti itu menggunakan DSL grafis. Ini semua kode untuk satu program. Beberapa baris kode menunjukkan apa yang terjadi dalam proses.
Mari kita lupa bagaimana menulis kode definisi untuk masing-masing aktor dan alih-alih mempelajari tata letak tingkat tinggi primitif yang akan membuat dan menghubungkan aktor yang diperlukan dalam diri mereka. Ketika kami menjalankan grafik seperti itu, sistem yang menyediakan Akka Streams akan membuat aktor yang diperlukan dengan sendirinya, mengirim semua data ini di sana, memprosesnya sebagaimana mestinya, dan akhirnya memberikannya kepada penerima akhir.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Contoh di atas menunjukkan bagaimana ini terlihat dalam C #. Cara paling sederhana: kami memiliki satu sumber data - ini adalah angka dari 1 hingga 1000 (seperti yang Anda lihat, di Akka Streams, setiap IEnumerable dapat menjadi sumber aliran data, yang sangat nyaman). Kami melakukan beberapa perhitungan sederhana, katakanlah, kami kalikan dua, dan kemudian pada aliran data semua ini ditampilkan di layar.
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); });
Apa yang ditunjukkan pada contoh di atas disebut "DSL grafis dalam C #". Sebenarnya, tidak ada grafik di sini, ini adalah port dengan Scala, tetapi di C # tidak ada cara untuk mendefinisikan operator dengan cara ini, sehingga terlihat sedikit lebih rumit, tetapi masih cukup kompak untuk memahami apa yang terjadi di sini. Jadi, kami membuat grafik tertentu (ada berbagai jenis grafik, ini dia disebut FlowShape) dari berbagai komponen, di mana ada sumber data dan ada beberapa transformasi. Kami mengirim data ke satu saluran tempat kami menghasilkan penghitungan, yaitu jumlah elemen data yang akan dikirim, dan di saluran lain kami menghasilkan jumlah dan kemudian kami mencampur semuanya. Selanjutnya kita akan melihat contoh yang lebih menarik daripada hanya memproses bilangan bulat.
Ini adalah jalur pertama yang dapat mengarahkan Anda ke Akka Streams, jika Anda memiliki pengalaman bekerja dengan model aktor dan Anda telah memikirkan apakah akan menulis masing-masing secara manual, bahkan aktor paling sederhana. Cara kedua yang dilakukan Akka Streams adalah melalui Reactive Streams.
Dari Aliran Reaktif ke Aliran Akka
Apa itu
Streaming Reaktif ? Ini adalah inisiatif bersama untuk mengembangkan standar untuk pemrosesan aliran data yang tidak sinkron. Ini mendefinisikan set minimum antarmuka, metode dan protokol yang menggambarkan operasi dan entitas yang diperlukan untuk mencapai tujuan - pemrosesan data secara asinkron secara real time dengan tekanan balik yang tidak menghalangi (tekanan balik). Ini memungkinkan berbagai implementasi menggunakan bahasa pemrograman yang berbeda.
Aliran Reaktif memungkinkan Anda untuk memproses sejumlah elemen yang berpotensi tidak terbatas dalam urutan dan mentransfer elemen secara tidak sinkron antara komponen dengan tekanan balik yang tidak menghalangi.
Daftar penggagas penciptaan Reactive Streams cukup mengesankan: di sini adalah Netflix, dan Oracle, serta Twitter.
Spesifikasi ini sangat sederhana untuk membuat implementasi dalam berbagai bahasa dan platform semudah mungkin diakses. Komponen utama API Aliran Reaktif:
- Penerbit
- Pelanggan
- Berlangganan
- Prosesor
Pada dasarnya, spesifikasi ini tidak menyiratkan bahwa Anda akan mulai mengimplementasikan antarmuka ini secara manual. Dipahami bahwa ada beberapa pengembang perpustakaan yang akan melakukan ini untuk Anda. Dan Akka Streams adalah salah satu implementasi dari spesifikasi ini.
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); }
Antarmuka, seperti yang Anda lihat dari contoh, sangat sederhana: misalnya, Penerbit hanya berisi satu metode - “berlangganan”. Pelanggan, Pelanggan, hanya berisi beberapa reaksi terhadap acara tersebut.
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { }
Akhirnya, berlangganan berisi dua metode - "mulai" dan "menolak". Prosesor tidak mendefinisikan metode baru sama sekali, melainkan menggabungkan penerbit dan pelanggan.
Apa yang membedakan Streaming Reaktif dari implementasi stream lainnya? Streaming Reaktif menggabungkan model push dan pull. Untuk dukungan, ini adalah skenario kinerja yang paling efisien. Misalkan Anda memiliki pelanggan data yang lambat. Dalam hal ini, dorongan untuknya bisa berakibat fatal: jika Anda mengiriminya sejumlah besar data, ia tidak akan dapat memprosesnya. Lebih baik menggunakan tarikan sehingga pelanggan sendiri menarik data dari penerbit. Tetapi jika penerbit lambat, ternyata pelanggan diblokir sepanjang waktu, menunggu sepanjang waktu. Solusi perantara mungkin adalah konfigurasi: kami memiliki file konfigurasi tempat kami menentukan yang mana yang lebih cepat. Dan jika kecepatan mereka berubah?
Jadi, implementasi yang paling elegan adalah di mana kita dapat secara dinamis mengubah model push dan pull.
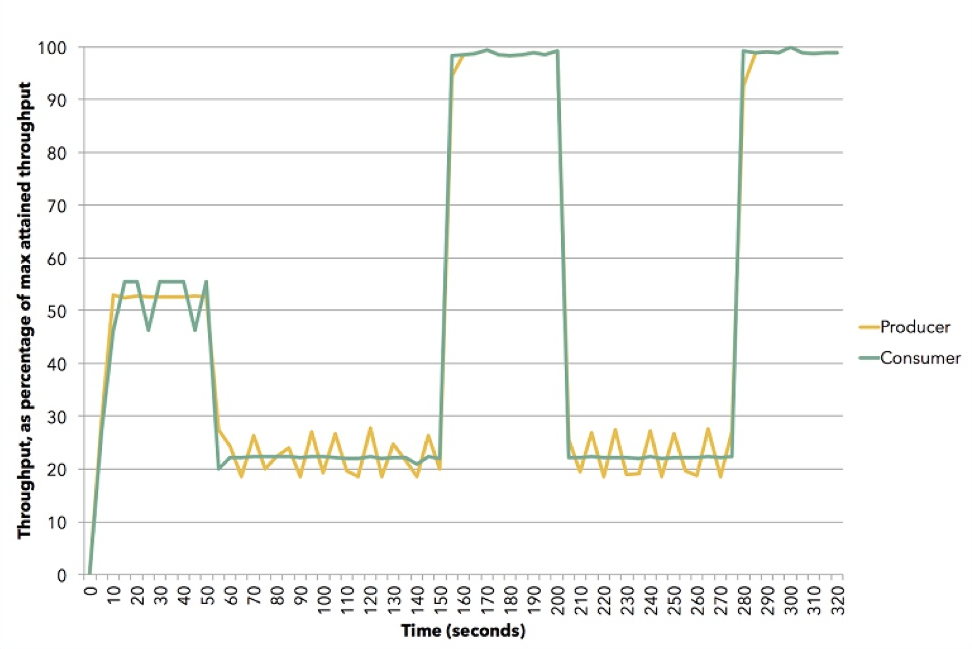 (Sumber (Apache Flink))
(Sumber (Apache Flink))Diagram menunjukkan bagaimana ini bisa terjadi. Demo ini menggunakan Apache Flink. Yellow adalah penerbit, produser data, ia ditetapkan sekitar 50% dari kemampuannya. Pelanggan mencoba untuk memilih strategi terbaik - ternyata menjadi dorongan. Kemudian kami mengatur ulang pelanggan ke kecepatan sekitar 20%, dan dia beralih untuk menarik. Lalu kita pergi 100%, kembali lagi 20%, ke model tarik, dll. Semua ini terjadi dalam dinamika, Anda tidak perlu menghentikan layanan, memasukkan sesuatu ke dalam konfigurasi. Ini adalah ilustrasi bagaimana tekanan balik bekerja di Akka Streams.
Prinsip aliran Akka
Tentu saja, Akka Streams tidak akan mendapatkan popularitas jika tidak ada blok bawaan yang sangat mudah digunakan. Ada banyak dari mereka. Mereka dibagi menjadi tiga kelompok utama:
- Sumber data (Sumber) - tahap pemrosesan dengan satu output.
- Sink adalah langkah pemrosesan entri tunggal.
- Checkpoint (Flow) - tahap pemrosesan dengan satu input dan satu output. Transformasi fungsional terjadi di sini, dan tidak harus dalam memori: itu bisa, misalnya, panggilan ke layanan web, ke beberapa elemen paralelisme, multi-threaded.
Dari ketiga jenis ini, grafik dapat dibentuk. Ini sudah merupakan tahap pemrosesan yang lebih kompleks, yang dibangun dari sumber, saluran air, dan pos pemeriksaan. Tetapi tidak semua grafik dapat dieksekusi: jika ada lubang di dalamnya, yaitu, buka input dan output, maka grafik ini tidak berjalan.
Grafik adalah Grafik Runnable, jika ditutup, yaitu ada output untuk setiap input: jika data telah dimasukkan, pasti ada di suatu tempat.

Akka Streams memiliki sumber bawaan: dalam gambar Anda melihat berapa banyak dari mereka. Nama-nama mereka adalah tentang satu-ke-satu dan mencerminkan apa yang dimiliki Scala atau JVM, dengan pengecualian beberapa sumber yang bermanfaat .NET-spesifik. Dua yang pertama (FromEnumerator dan Dari) adalah beberapa yang paling penting: penomoran apa saja, setiap ienumerable dapat diubah menjadi sumber aliran.

Ada built-in drain: beberapa dari mereka menyerupai metode LINQ, misalnya, Pertama, Terakhir, FirstOrDefault. Tentu saja, semua yang Anda dapatkan, Anda dapat membuang ke file, ke stream, bukan di Akka Streams, tetapi di stream .NET. Dan lagi, jika Anda memiliki aktor dalam sistem Anda, Anda dapat menggunakannya baik pada input maupun pada output sistem, yaitu, jika Anda ingin, menanamkan ini dalam sistem Anda selesai.

Dan ada sejumlah besar pos-pos pemeriksaan built-in, yang, mungkin, bahkan lebih mengingatkan pada LINQ, karena di sini ada Select, dan SelectMany, dan GroupBy, yaitu, semua yang kita gunakan untuk bekerja dengan di LINQ.
Sebagai contoh, Select in Scala disebut SelectAsync: itu cukup kuat karena mengambil tingkat paralelisme sebagai salah satu argumen. Artinya, Anda dapat menunjukkan bahwa, misalnya, Pilih mengirim data ke beberapa layanan web secara paralel dalam sepuluh utas, lalu semuanya dikumpulkan dan diteruskan. Bahkan, Anda menentukan tingkat penskalaan dari pos pemeriksaan dengan satu baris kode.
Deklarasi aliran adalah rencana pelaksanaannya, yaitu, grafik, bahkan yang dijalankan, tidak dapat dieksekusi begitu saja - itu perlu diwujudkan. Harus ada sistem instantiated, sistem aktor, Anda harus memberikan streaming, rencana ini untuk dieksekusi, dan kemudian akan dieksekusi. Selain itu, pada saat dijalankan sangat optimal, seperti ketika Anda mengirim ekspresi LINQ ke database: penyedia dapat mengoptimalkan SQL Anda untuk output data yang lebih efisien, pada dasarnya mengganti perintah permintaan dengan yang lain. Sama dengan Akka Streams: mulai dari versi 2.0 Anda dapat menetapkan sejumlah pos pemeriksaan tertentu, dan sistem akan memahami bahwa beberapa di antaranya dapat digabungkan sehingga dijalankan oleh satu aktor (fusi operator). Pos pemeriksaan, sebagai aturan, menjaga urutan elemen pemrosesan.
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Materialisasi aliran dapat dibandingkan dengan elemen ToList terakhir dalam ekspresi LINQ dalam contoh di atas. Jika kami tidak menulis ToList, maka kami mendapatkan ekspresi LINQ tidak material yang tidak akan menyebabkan data ditransfer ke server SQL atau Oracle, karena sebagian besar penyedia LINQ mendukung apa yang disebut eksekusi permintaan tangguhan (eksekusi permintaan tertunda), t yaitu, permintaan dieksekusi hanya ketika perintah diberikan untuk memberikan hasil. Bergantung pada apa yang diminta - daftar atau hasil pertama - tim yang paling efektif akan dibentuk. Ketika kami mengatakan ToList, kami meminta penyedia LINQ untuk memberi kami hasil yang sudah selesai.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Akka Streams bekerja dengan cara yang sama. Dalam gambar adalah grafik yang diluncurkan kami, yang terdiri dari sumber pos pemeriksaan dan limpasan, dan kami sekarang ingin menjalankannya.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); }
Agar ini terjadi, kita perlu membuat sistem aktor, di dalamnya ada seorang materializer, berikan grafik kita kepadanya, dan dia akan melaksanakannya. Jika kami membuatnya kembali, itu akan mengeksekusinya lagi, dan hasil lainnya dapat diperoleh.
Selain materialisasi aliran, berbicara tentang bagian materi Akka Streams, ada baiknya menyebutkan nilai-nilai yang terwujud.
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right);
Ketika kita memiliki aliran yang mengalir dari sumber melalui pos pemeriksaan ke saluran, maka jika kita tidak meminta nilai perantara, nilai itu tidak tersedia bagi kita, karena akan dieksekusi dengan cara yang paling efisien. Ini seperti kotak hitam. Tetapi mungkin menarik bagi kita untuk menarik beberapa nilai perantara, karena pada setiap titik di sebelah kiri beberapa nilai masuk, nilai-nilai lain keluar di sebelah kanan, dan Anda dapat menentukan grafik untuk menunjukkan apa yang Anda minati. Dalam contoh di atas, grafik run-in di mana NotUsed ditunjukkan, yaitu, tidak ada nilai material yang menarik minat kami. Di bawah ini kita buat dengan indikasi bahwa di sisi kanan limpasan, yaitu, setelah semua transformasi selesai, kita perlu memberikan nilai terwujud. Kami mendapatkan Tugas grafik - tugas, setelah selesai kami mendapatkan int, yaitu, apa yang terjadi pada akhir grafik ini. Anda dapat menunjukkan dalam setiap paragraf bahwa Anda memerlukan semacam nilai terwujud, semua ini akan dikumpulkan secara bertahap.
Untuk mentransfer data ke aliran Akka Streams atau mengeluarkannya dari sana, tentu saja, beberapa jenis interaksi dengan dunia luar diperlukan. Tahap sumber tertanam berisi berbagai aliran data reaktif:
- Source.FromEnumerator dan Source.From memungkinkan Anda untuk mentransfer data dari sumber apa pun yang mengimplementasikan IEnumerable;
- Unfold dan UnfoldAsync menghasilkan hasil perhitungan fungsi asalkan mengembalikan nilai-nilai non-nol;
- FromInputStream mengubah Stream;
- FromFile mem-parsing isi file ke dalam aliran reaktif;
- ActorPublisher mengonversi pesan aktor.
Seperti yang sudah saya katakan, untuk pengembang NET. Sangat produktif untuk menggunakan Enumerator atau IEnumerable, tetapi kadang-kadang terlalu primitif, terlalu efisien untuk mengakses data. Sumber yang lebih kompleks yang berisi sejumlah besar data memerlukan konektor khusus. Konektor semacam itu ditulis. Ada proyek sumber terbuka Alpakka, yang awalnya muncul di Scala dan sekarang di .NET. Selain itu, Akka memiliki apa yang disebut aktor gigih, dan mereka memiliki aliran mereka sendiri yang dapat digunakan (misalnya, Akka Persistence Query membentuk aliran konten dari Akka Event Journal).

Jika Anda bekerja dengan Scala, maka cara termudah adalah untuk Anda: ada banyak konektor, dan Anda pasti akan menemukan sesuatu sesuai selera Anda. Sebagai informasi, Kafka adalah apa yang disebut Kafka Reaktif, bukan Aliran Kafka. Kafka Streaming, sejauh yang saya tahu, tidak mendukung tekanan balik. Kafka reaktif adalah implementasi aliran dari Kafka yang mendukung aliran reaktif.
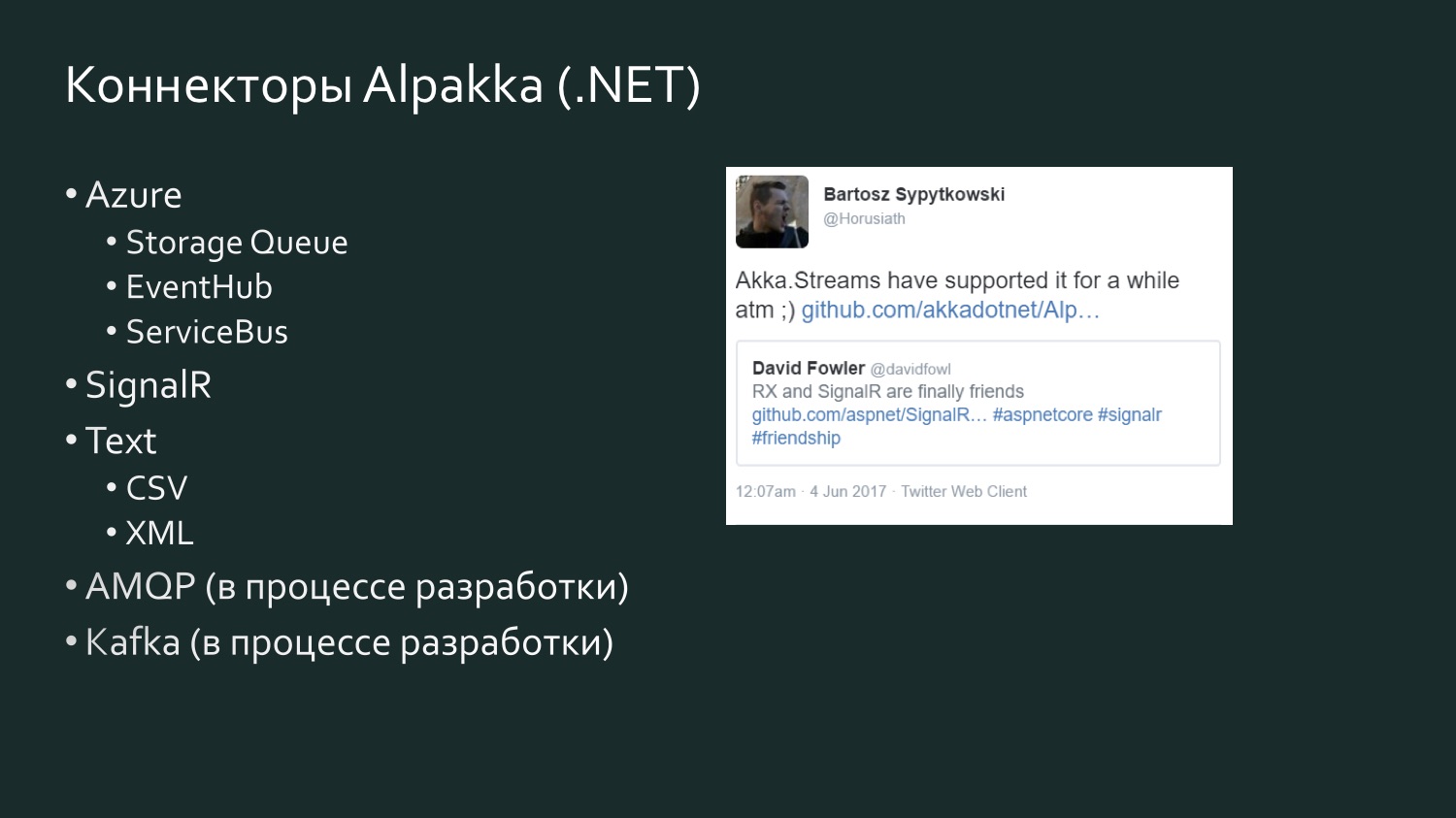
Daftar konektor .NET Alpakka lebih sederhana, tetapi diisi ulang, dan ada elemen kompetisi. Ada tweet berusia enam bulan dari David Fowler dari Microsoft, yang mengatakan bahwa SignalR sekarang dapat bertukar data dengan Reactive Extensions, dan salah satu pengembang di Akka menjawab bahwa itu sebenarnya ada di Akka Streams selama beberapa waktu. Akka mendukung berbagai layanan dari Microsoft Azure. CSV adalah hasil dari frustrasi Aaron Stannard ketika ia menemukan bahwa tidak ada aliran yang baik untuk CSV: sekarang Akka memiliki alirannya sendiri untuk CSV XML. Ada AMQP (pada kenyataannya, RabbitMQ), sedang dalam pengembangan, tetapi tersedia untuk digunakan, berfungsi. Kafka juga sedang dikembangkan. Daftar ini akan terus berkembang.
Beberapa kata tentang alternatif, karena jika Anda bekerja dengan aliran data, Akka Streams, tentu saja, bukan satu-satunya cara untuk menangani aliran ini. Kemungkinan besar, dalam proyek Anda, pilihan cara menerapkan utas akan bergantung pada banyak faktor lain yang mungkin menjadi kunci. Misalnya, jika Anda banyak bekerja dengan Microsoft Azure dan Orleans secara organik dibangun ke dalam kebutuhan proyek Anda dengan dukungan mereka untuk aktor virtual, atau, seperti yang mereka sebut, biji-bijian, maka mereka memiliki implementasi sendiri yang tidak memenuhi spesifikasi Reactive Streams - Orleans Streams, yang itu akan menjadi yang terdekat bagi Anda, dan masuk akal bagi Anda untuk memperhatikannya. Jika Anda banyak bekerja dengan TPL, ada TPL DataFlow - ini mungkin analogi terdekat dengan Akka Streams: ini juga memiliki primitif untuk menyusun aliran data, serta alat buffering dan pembatasan bandwidth (BoundedCapacity, MaxMessagePerTask). Jika ide-ide model aktor dekat dengan Anda, maka Akka Streams adalah cara untuk mengatasi ini dan menghemat banyak waktu tanpa harus menulis setiap aktor secara manual.
Contoh Implementasi: Aliran Log Kejadian
Mari kita lihat beberapa contoh implementasi.
Contoh pertama tidak secara langsung menerapkan aliran, itu adalah bagaimana menggunakan aliran. Ini adalah pengalaman pertama kami dengan Akka Streams, ketika kami menemukan bahwa sebenarnya kami dapat berlangganan beberapa aliran yang akan menyederhanakan banyak hal bagi kami.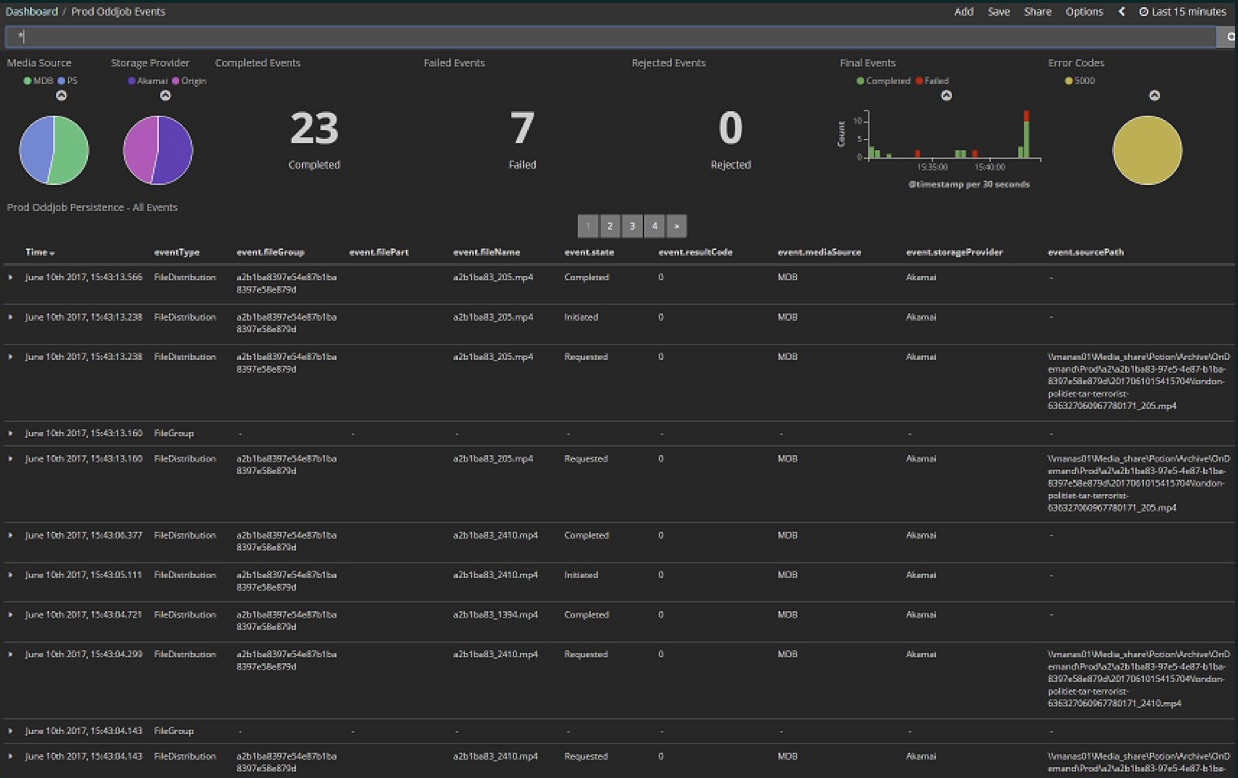 Kami mengunggah berbagai file media ke cloud. Ini adalah tahap awal proyek: di sini dalam 15 menit terakhir 23 file, di antaranya 7 kesalahan. Sekarang praktis tidak ada kesalahan dan jumlah file jauh lebih besar - ratusan melalui setiap beberapa menit. Semua ini terkandung dalam Dashboard Kibana.Kibana membaca data dari Elasticsearch, dan karena data sekunder dan bukan primer disimpan di Elasticsearch, implementasi dari pengindeks ini mengharuskan Anda untuk menghapusnya dan mengeluarkan perintah untuk mengisinya lagi. Karena proyek ini sedang dikembangkan, ini memungkinkan kami untuk mengubah format data, memperluasnya dengan nilai-nilai baru, yaitu indeks perlu terus diperbarui. Itu diisi ulang dengan isi jurnal acara Akka, yang disimpan dalam database Microsoft SQL Server. Baik peristiwa yang sebelumnya disimpan dan peristiwa waktu nyata harus ditampilkan di panel operasi saat ini.
Kami mengunggah berbagai file media ke cloud. Ini adalah tahap awal proyek: di sini dalam 15 menit terakhir 23 file, di antaranya 7 kesalahan. Sekarang praktis tidak ada kesalahan dan jumlah file jauh lebih besar - ratusan melalui setiap beberapa menit. Semua ini terkandung dalam Dashboard Kibana.Kibana membaca data dari Elasticsearch, dan karena data sekunder dan bukan primer disimpan di Elasticsearch, implementasi dari pengindeks ini mengharuskan Anda untuk menghapusnya dan mengeluarkan perintah untuk mengisinya lagi. Karena proyek ini sedang dikembangkan, ini memungkinkan kami untuk mengubah format data, memperluasnya dengan nilai-nilai baru, yaitu indeks perlu terus diperbarui. Itu diisi ulang dengan isi jurnal acara Akka, yang disimpan dalam database Microsoft SQL Server. Baik peristiwa yang sebelumnya disimpan dan peristiwa waktu nyata harus ditampilkan di panel operasi saat ini. CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) )
Untuk mencapai ini, kita perlu, di satu sisi, untuk menulis ulang data yang diambil dari SQL Server, yang berisi beberapa eventstore aktor persisten Akka, eventJournal. Gambar menunjukkan toko acara yang khas.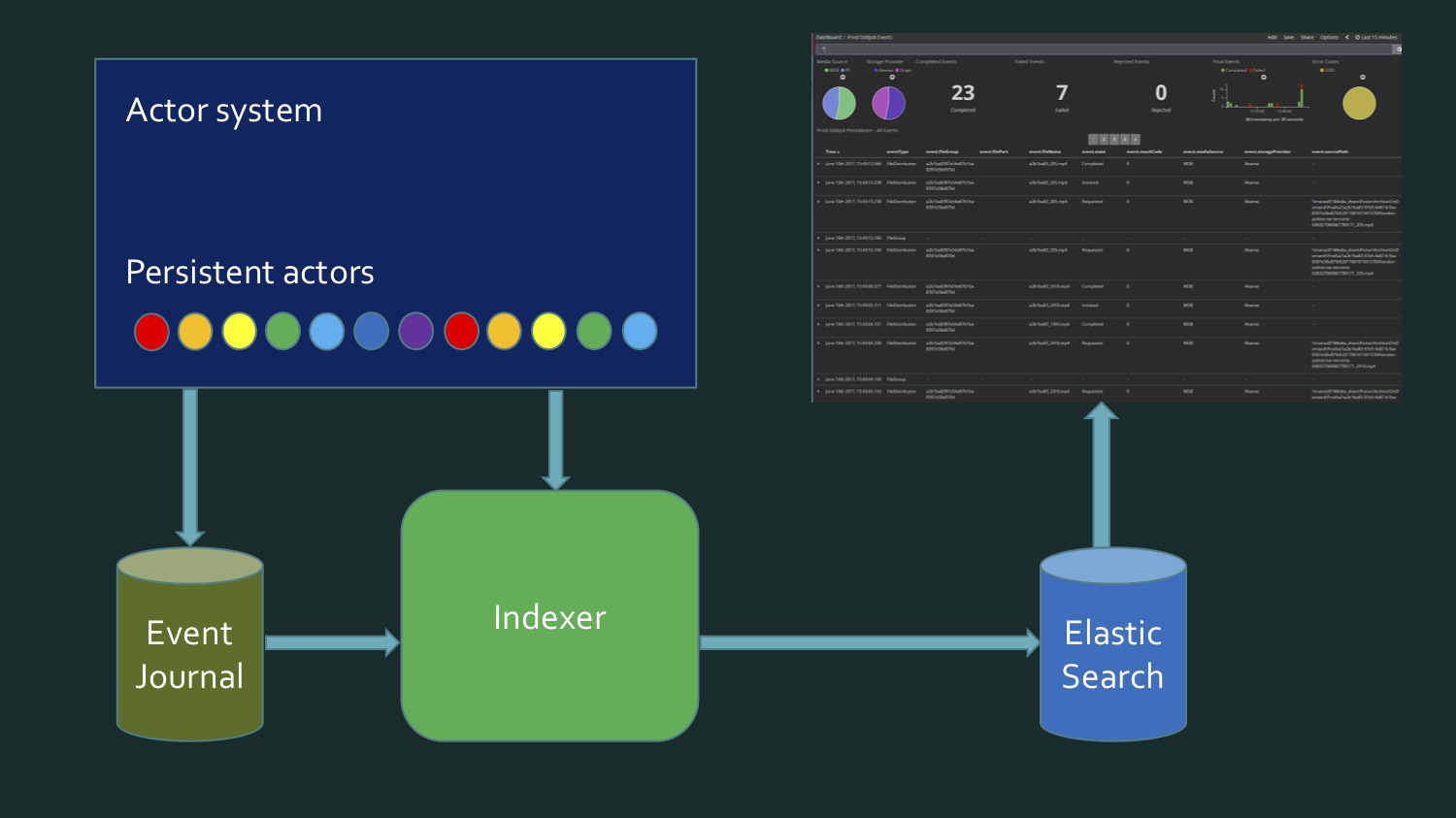 Dan di sisi lain, data datang secara real time. Dan ternyata untuk menulis indeks, kita perlu membaca data dari database, ditambah data real-time tiba, dan pada titik tertentu kita perlu memahami: di sini data dari sini berakhir, ini baru. Momen batas ini memerlukan verifikasi tambahan agar tidak kehilangan apa pun dan tidak merekam apa pun dua kali. Artinya, ternyata agak rumit. Kolega saya dan saya tidak senang dengan apa yang sedang terjadi. Bukan itu kode yang sangat kompleks, hanya agak suram. Sampai kami ingat bahwa aktor gigih di Akka mendukung permintaan kegigihan.
Dan di sisi lain, data datang secara real time. Dan ternyata untuk menulis indeks, kita perlu membaca data dari database, ditambah data real-time tiba, dan pada titik tertentu kita perlu memahami: di sini data dari sini berakhir, ini baru. Momen batas ini memerlukan verifikasi tambahan agar tidak kehilangan apa pun dan tidak merekam apa pun dua kali. Artinya, ternyata agak rumit. Kolega saya dan saya tidak senang dengan apa yang sedang terjadi. Bukan itu kode yang sangat kompleks, hanya agak suram. Sampai kami ingat bahwa aktor gigih di Akka mendukung permintaan kegigihan.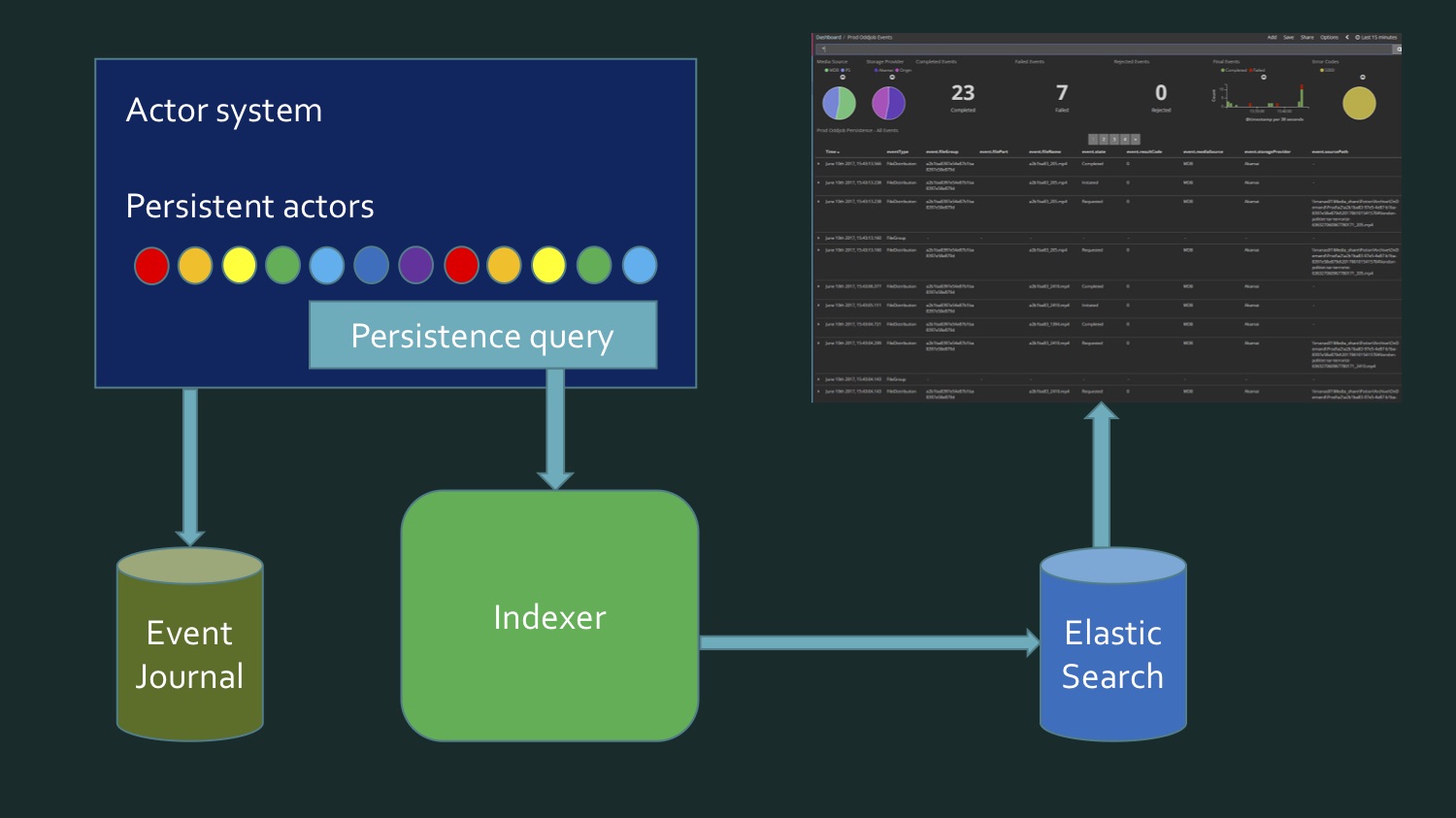 Ini hanya kesempatan untuk mendapatkannya dalam bentuk aliran data yang disarikan di atas sumbernya, mereka berasal dari basis data atau diperoleh secara waktu nyata.Kueri bawaan (kueri persistensi):
Ini hanya kesempatan untuk mendapatkannya dalam bentuk aliran data yang disarikan di atas sumbernya, mereka berasal dari basis data atau diperoleh secara waktu nyata.Kueri bawaan (kueri persistensi):- Allpersistencelds
- EldPersistenseldelds
- EventByPersistenceldeld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
Dan ada sejumlah metode yang dapat kita gunakan, misalnya, ada metode saat ini - ini adalah snapshot, data historis hingga titik waktu tertentu. Dan tanpa awalan ini, pertama dan termasuk yang asli. Kami membutuhkan EventsByTag. let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid
Dan ternyata kami punya cukup kode. Itu ditulis dalam F #, tetapi dalam C # itu tentang kompak yang sama. Kami mendapatkan EventsByTag, menggunakan blok bawaan Akka Streams, dan dari semua ini kami mendapatkan data yang kami helm di Elasticsearch. Artinya, kami mengambil keuntungan dari implementasi aliran data orang lain, dan ini memungkinkan kami untuk melupakan dari mana data kami, dari mana asalnya - dari database atau itu terjadi secara real time. Implementasi ini memberi kami semua ini dengan satu permintaan.Namun di sini kami adalah konsumen data ini. Dalam kasus ketika kita ingin menghasilkan data seperti itu sendiri, contohnya menjadi lebih menarik, dan kita melihatnya pada data nyata, karena Twitter adalah salah satu penggagas spesifikasi ini, dan tweet adalah sesuatu yang dapat diakses oleh semua orang, yang kita semua mengerti . Ini adalah contoh standar tentang cara Akka Streams bekerja.Contoh Implementasi: Jet Tweets
Ada contoh untuk Akka untuk Scala, untuk Akka.NET, tetapi saya menemukan contoh-contoh ini tidak cukup, karena mereka menunjukkan satu contoh spesifik tentang bagaimana data ditarik keluar dan apa yang dilakukan dengan itu, tetapi saya ingin melihat komplikasi bertahap, yaitu, mulai dengan aliran sederhana dan terus menambahkan beberapa desain baru ke dalamnya. Untuk melakukan ini, kita akan menggunakan pustaka Tweetinvi - ini adalah pustaka sumber terbuka yang menyediakan data dari Twitter, itu hanya mendukung keluaran data dalam bentuk aliran. Aliran ini tidak memenuhi spesifikasi Aliran Reaktif, yaitu, kami tidak dapat langsung mengambilnya, tetapi itu bahkan bagus, karena itu akan memungkinkan kami untuk menunjukkan bagaimana kami dapat, menggunakan Akka yang umumnya primitif, menulis aliran kami sendiri berdasarkan ini, yang akan memenuhi spesifikasi ini.
, , . . Broadcast-. , , . : , , , , .
GitHub-,
AkkaStreamsDemo . (
).
Mari kita mulai dengan yang sederhana. Twitter: Program.cs
var useCachedTweets = false
Jika saya diblokir dari Twitter, saya telah men-cache tweet, mereka lebih cepat. Untuk memulai, kami membuat beberapa RunnableGraph. public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); }
( Sumber )Kami memiliki sumber tweet di sini, yang berasal dari aktor. Saya akan menunjukkan kepada Anda bagaimana kami menarik tweet ini di sana, memformatnya (format tweet hanya memberikan tweet kepada penulis) dan kemudian menulisnya di layar.StartTweetStream - di sini kita akan menggunakan perpustakaan Tweetinvi. public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); }
( Sumber )Melalui CreateSampleStream kami mendapatkan tweet sampel, mereka dikeluarkan dengan kecepatan yang tidak terlalu tinggi. Dari semua ini, kami memilih apa yang kami butuhkan dan membuat aktor yang mengatakan: "Terima tweet ini." Selanjutnya kita perlu mendapatkan IEnumerable, sehingga pada akhirnya kita mendapatkan sumbernya.Dan TweetEnumerator terlihat sangat sederhana: kami memiliki koleksi tweet, dan kami perlu menerapkan Current, MoveNext, Reset, dan Buang menjadi warga negara yang baik. Jika kita menjalankan ini, kita akan melihat contoh real-time. Ada banyak non-cetak, karena ini berasal dari negara-negara non-Latin yang berbeda. Ini adalah versi termudah dari program kami.Sekarang kita mengubah nilai useCachedTweets menjadi true, dan di sini komplikasinya dimulai. CashedTweets adalah hal yang sama, hanya saja saya punya file 50.000 tweet yang sudah saya pilih, simpan, kita akan menggunakannya. Saya mencoba memilih tweet yang berisi data pada koordinat geografis penulisnya, yang kami perlukan. Langkah selanjutnya adalah kita ingin memparalelkan tweet. Setelah eksekusi, pertama kita akan memiliki pemilik tweet dalam daftar, dan kemudian koordinatnya.TweetsWithBroadcast: var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
( Sumber )Jika itu adalah Scala, itu akan benar-benar terlihat seperti DSL grafis. Di sini kita membuat Siaran dengan dua saluran - keluar (0), keluar (1) - dan dalam satu kasus kita mencetak CreatedBy, yang lain kita mencetak koordinat, lalu kita campur semuanya dan mengirimkannya ke stok. Cukup sederhana untuk saat ini.Langkah selanjutnya dalam demo kami adalah sedikit menyulitkan. Mari kita mulai mengubah bandwidth. var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });}
( Sumber )10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
( Sumber )Di sini kita memiliki saluran kedua, memiliki SelectAsync, di mana kita mendapatkan cuaca. Kami tidak hanya mengirim ini ke layanan pengiriman cuaca, kami juga mengatakan bahwa kode ini dijalankan dengan level paralelisasi 5: ini berarti bahwa 5 thread paralel akan dibuat jika layanan ini cukup lambat di mana layanan ini akan meminta cuaca. Layanan itu sendiri diterapkan di sini, juga masuk akal untuk menunjukkan betapa sederhananya kode ini. public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); }
(
)
. -, , - , HttpClient , XML, , .
,
, , . 10 10 , , .
Cukup mengesankan betapa mudahnya menggambarkan proses semacam itu, termasuk menunjukkan tingkat paralelisme. Ini hanya beberapa blok yang dapat digunakan di Akka Streams, saya sudah mengatakan bahwa ada banyak dari mereka. Kemungkinan Anda dapat memanfaatkan banyak dari mereka cukup tinggi.Jika saya menggunakan model aktor, mungkin setahun yang lalu, ketika saya tidak terbiasa dengan Akka Streams, saya akan menulis secara terpisah setiap aktor untuk ini. Seperti yang Anda lihat, Anda tidak perlu menulis kode untuk setiap pos pemeriksaan, semua ini dapat dilakukan dengan alat Akka Streams, jadi secara total dalam C # diperlukan beberapa puluh baris kode, yang memungkinkan kami untuk memfokuskan kontrol kami, perhatian kami pada tingkat yang lebih tinggi dari organisasi proses, dan bukan pada detail mikro, bagian dalam aliran data.Pertimbangan terakhir
 Gagasan apa tentang Akka Streams yang ingin saya buat sendiri setelah membaca artikel ini? Di DotNext 2017 Moscow saya menghadiri presentasi oleh Alex ThyssenTentang Fungsi Azure. Dalam arti tertentu, ini adalah perubahan dalam gagasan tentang bagaimana menulis kode untuk ditempatkan, bahwa alih-alih berfokus pada konfigurasi mesin, kami menginstal program-program semacam itu pada mesin ini yang berbicara dengan layanan ini dan menerima data ini) , kami fokus langsung pada bagian fungsional dan helm fungsional ini masuk ke cloud. Kami tidak memikirkan dengan tepat node mesin mana yang akan mengeksekusi kode ini, kami berpikir tentang bagaimana fungsi kami harus bekerja sama satu sama lain. Analogi serupa dapat ditarik antara sistem yang ditulis menggunakan model aktor, tetapi secara manual dan Akka Streams, yaitu. kita lupa bagaimana menulis aktor secara manual dan alih-alih fokus pada keseluruhan deskripsi proses.Dalam sebagian besar skenario, kami berhasil tetap berada pada level yang cukup tinggi sambil mempertahankan skalabilitas dan kinerja sistem.
Gagasan apa tentang Akka Streams yang ingin saya buat sendiri setelah membaca artikel ini? Di DotNext 2017 Moscow saya menghadiri presentasi oleh Alex ThyssenTentang Fungsi Azure. Dalam arti tertentu, ini adalah perubahan dalam gagasan tentang bagaimana menulis kode untuk ditempatkan, bahwa alih-alih berfokus pada konfigurasi mesin, kami menginstal program-program semacam itu pada mesin ini yang berbicara dengan layanan ini dan menerima data ini) , kami fokus langsung pada bagian fungsional dan helm fungsional ini masuk ke cloud. Kami tidak memikirkan dengan tepat node mesin mana yang akan mengeksekusi kode ini, kami berpikir tentang bagaimana fungsi kami harus bekerja sama satu sama lain. Analogi serupa dapat ditarik antara sistem yang ditulis menggunakan model aktor, tetapi secara manual dan Akka Streams, yaitu. kita lupa bagaimana menulis aktor secara manual dan alih-alih fokus pada keseluruhan deskripsi proses.Dalam sebagian besar skenario, kami berhasil tetap berada pada level yang cukup tinggi sambil mempertahankan skalabilitas dan kinerja sistem.Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap».
, .
This is the Akka Stream.
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
Ini adalah Wastafel yang diisi dari Bidiflow yang mengembalikan Throttle yang mempercepat TakeWhile yang menarik dari Drop yang menghapus dari Zip yang menggabungkan dari Saldo yang membagi FilterNot yang memilih dari Gabung yang mengumpulkan dari Siaran yang bercabang MapAsync yang memetakan dari Sumber yang memberi makan Akka Stream.
Menit periklanan. Jika Anda menyukai laporan dan menginginkan hal lain seperti itu, DotNext 2018 Moskow berikutnya akan diadakan di Moskow pada 22-23 November , dan mungkin tidak kalah menariknya bagi Anda di sana. Bergegas untuk mendapatkan tiket dengan harga Juli (mulai 1 Agustus, biaya tiket akan meningkat).