Dari tanggal 19 hingga 21 April, konferensi C ++ Russia 2018 diadakan di St. Petersburg. Dari tahun ke tahun, organisasi dan perilaku menjadi satu tingkat lebih tinggi, yang merupakan kabar baik. Terima kasih kepada penyelenggara tetap C ++ Russia Sergey Platonov untuk kontribusinya pada pengembangan area ini.
Pada tanggal 19 April, kelas master direncanakan, yang, sayangnya, kami tidak dapat hadir, dan pada 20-21 program utama konferensi diadakan, di mana kami berpartisipasi dengan penuh minat. Sergey
sermp melakukan pekerjaan yang baik dan menarik beberapa penutur asing yang luar biasa sebagai penutur. Hari pertama konferensi dibuka oleh Jon Kalb, penyelenggara CppCon dan penulis C ++ Today: The Beast is Back. Hari kedua dimulai dengan presentasi oleh Daveed Vandevoorde, anggota komite standardisasi, salah satu penulis C ++ Templates: The Complete Guide. Andrei Alexandrescu berada di pusat perhatian, yang, setelah laporannya tentang perkecualian, pada satu titik mengumpulkan kerumunan orang yang ingin mendapatkan tanda tangan dan mengambil foto bersama. Untuk pertama kalinya, pembicaraan Herb Sutter disiarkan di Skype tentang operator pesawat ruang angkasa untuk C ++ 20.
Meskipun konferensi berlangsung lebih dari 3 bulan yang lalu, video (
daftar putar lengkap ) telah diposting di sana sekarang, jadi sekarang saatnya untuk menyegarkan ingatan Anda dan membenamkan diri dalam fitur luar biasa dari C ++.
Pembicaraan ini mencakup mengapa insinyur yang mencari kinerja memilih C ++. Jon menyajikan perspektif historis C ++ yang berfokus pada apa yang terjadi di komunitas C ++ sekarang dan ke mana bahasa dan basis penggunanya menuju. Dengan minat baru dalam kinerja untuk pusat data dan perangkat seluler, dan keberhasilan pustaka perangkat lunak open source, C ++ kembali dan panas. Pembicaraan ini menjelaskan mengapa C ++ adalah bahasa yang digunakan kebanyakan insinyur perangkat lunak untuk kinerja. Anda akan menerima sketsa historis kasar yang menempatkan C ++ dalam perspektif dan mencakup naik turunnya popularitasnya.

Pasangan iterator ada di mana-mana di seluruh pustaka C ++. Secara umum diterima bahwa menggabungkan pasangan seperti itu ke dalam satu entitas yang biasanya disebut Range memberikan kode yang lebih ringkas dan mudah dibaca. Namun, mendefinisikan semantik yang tepat dari konsep Rentang tersebut ternyata sangat rumit. Pertimbangan teoritis bertentangan dengan yang praktis. Beberapa tujuan desain sama-sama tidak kompatibel sama sekali.
Kita semua sadar bahwa kita harus mengetahui algoritma STL. Memasukkannya ke dalam desain kami memungkinkan kami membuat kode kami lebih ekspresif dan lebih kuat. Dan terkadang, dengan cara yang spektakuler.
Tapi apakah Anda tahu algoritma STL Anda?
Dalam pembicaraan ini, penulis menyajikan 105 algoritma yang dimiliki STL saat ini, termasuk yang ditambahkan dalam C ++ 11 dan C ++ 17. Tetapi lebih dari sekadar daftar, inti pembicaraan ini adalah untuk menyajikan berbagai kelompok algoritma, pola yang mereka bentuk dalam STL, dan bagaimana algoritme tersebut saling berhubungan.
Gambaran besar semacam ini adalah cara terbaik untuk benar-benar mengingat semuanya, dan merupakan toolbox penuh dengan cara untuk membuat kode kita lebih ekspresif dan lebih kuat.
Pernah ingin memodifikasi beberapa nilai atau menjalankan beberapa pernyataan saat program C ++ Anda berjalan hanya untuk menguji sesuatu - tidak sepele atau mungkin dengan debugger? Bahasa scripting memiliki REPL (read-eval-print-loop). Hal terdekat yang dimiliki C ++ adalah kemelekatan (dikembangkan oleh para peneliti di CERN) tetapi ia dibangun di atas LLVM dan sangat rumit untuk diatur. RCRL (Read-Compile-Run-Loop) adalah proyek demo yang menampilkan pendekatan inovatif untuk melakukan kompilasi runtime C ++ dalam platform dan kompiler dengan cara agnostik yang dapat dengan mudah disematkan. Dalam presentasi ini, diperlihatkan bagaimana menggunakannya, cara kerjanya dan bagaimana hal itu dapat dimodifikasi dan diintegrasikan ke dalam aplikasi dan alur kerja apa pun.

Bukankah lebih baik jika kita memiliki tipe C ++ standar untuk mewakili string? Oh, tunggu ... kita lakukan: std :: string. Bukankah lebih baik jika kita dapat menggunakan tipe standar itu di seluruh aplikasi / proyek kita? Yah ... kita tidak bisa! Kecuali kami sedang menulis aplikasi konsol atau layanan. Tetapi, jika kita sedang menulis aplikasi dengan GUI atau berinteraksi dengan OS OS modern, kemungkinan kita harus berurusan dengan setidaknya satu jenis string C ++ yang tidak standar. Bergantung pada platform dan proyek, mungkin CString dari MFC atau ATL, Platform :: String dari WinRT, QString dari Qt, wxString dari wxWidgets, dll. Oh, jangan lupa teman lama kita const char *, lebih baik lagi const wchar_t * untuk keluarga C dari API ...
Jadi kami berakhir dengan dua tipe string dalam basis kode kami. OK, itu bisa diatur: kami tetap menggunakan std :: string untuk semua kode platform independen dan mengonversi bolak-balik ke XString lainnya saat berinteraksi dengan API sistem atau kode GUI. Kami akan membuat beberapa salinan yang tidak perlu saat melintasi jembatan ini dan kami akan berakhir dengan beberapa fungsi yang tampak lucu menyulap dua jenis string; tapi itu kode lem, toh ... kan?
Ini adalah rencana yang bagus ... sampai proyek kami berkembang dan kami mengumpulkan banyak utilitas dan algoritma string. Apakah kita membatasi barang algoritmik itu ke std :: string? Apakah kita mundur pada common denominator const char * dan kehilangan keamanan tipe / memori dari tipe C ++ kita? Apakah C ++ 17 std :: string_view jawaban untuk semua masalah string kami?
Penulis mencoba untuk mengeksplorasi opsi, bersama-sama, dengan studi kasus pada aplikasi Windows berusia 15 tahun: Advanced Installer (www.advancedinstaller.com) - proyek C ++ yang dikembangkan secara aktif, dimodernisasi menjadi C ++ 17, berkat clang-rapi dan "Dentang Alat Listrik" (
www.clangpowertools.com) ...
Menulis kode yang tahan terhadap kesalahan selalu menjadi titik penghambat dalam semua bahasa. Pengecualian adalah cara yang benar secara politis untuk menandai kesalahan dalam C ++, tetapi banyak aplikasi masih menggunakan kode kesalahan karena alasan yang terkait dengan kemudahan pemahaman, kemudahan penanganan kesalahan secara lokal, dan efisiensi kode yang dihasilkan.
Pembicaraan ini menunjukkan bagaimana beragam artefak teoretis dan praktis dapat digabungkan bersama untuk mengatasi kode kesalahan dan pengecualian dalam satu paket sederhana yang sehat. Tipe generik yang diharapkan dapat digunakan untuk perilaku lokal (kode-kesalahan-gaya) dan terpusat (gaya-pengecualian), mengambil dari kekuatan masing-masing.

Perangkat lunak dengan logika bisnis yang sangat kompleks, seperti game, sistem CAD, dan sistem perusahaan, sering kali perlu membuat dan memodifikasi objek saat runtime - misalnya untuk menambah atau mengganti metode dalam objek yang ada. Standar C ++ memiliki tipe kaku yang didefinisikan pada waktu kompilasi dan membuat ini sulit. Di sisi lain, bahasa dengan tipe dinamis seperti lua, Python, dan JavaScript membuat ini sangat mudah. Oleh karena itu, untuk menjaga agar kode tetap dapat dibaca dan dipelihara, dan memenuhi persyaratan logika bisnis yang kompleks, banyak proyek menggunakan bahasa tersebut bersama C ++. Beberapa kelemahan dari pendekatan ini termasuk kompleksitas tambahan dalam lapisan pengikatan bahasa, hilangnya kinerja karena menggunakan bahasa yang diinterpretasikan, dan duplikasi kode yang tak terelakkan untuk banyak fungsi utilitas kecil.
DynaMix adalah pustaka yang mencoba untuk menghapus, atau setidaknya sangat mengurangi, kebutuhan untuk bahasa skrip terpisah dengan memungkinkan pengguna untuk menyusun dan memodifikasi objek polimorfik saat runtime di C ++. Pembicaraan ini menguraikan masalah ini dan memperkenalkan perpustakaan dan fitur utamanya kepada calon pengguna atau orang-orang yang mungkin mendapat manfaat dari pendekatan dengan contoh beranotasi dan demo kecil.

Di C ++, Anda bisa menyelesaikan satu tugas dengan berbagai cara. Penulis mengambil tugas aktual dari produksi, dan menyelidiki bagaimana hal itu dapat diselesaikan dengan sejumlah alat yang disediakan C ++: wadah STL, boost.range, rentang C ++ 20, coroutine. Dia juga membandingkan kendala API dan kinerja berbagai solusi, dan bagaimana mereka dapat dengan mudah dikonversi dari satu ke yang lain jika kode terstruktur dengan baik. Selama perjalanan penulis juga mengeksplorasi aplikasi dari beberapa fitur C ++ 17 yang berguna seperti constexpr if, pernyataan pemilihan dengan initializer, std :: not_fn, dll. Perhatian khusus diberikan pada topik - algoritma standar.

Pemrograman paralel adalah topik yang sangat beragam dan mendalam. Selama beberapa dekade penelitian, sejumlah besar pendekatan, praktik, dan alat telah dikembangkan, tetapi kita hampir tidak dapat mengasumsikan bahwa bahasa C ++ mengikuti tren ini. Dimulai dengan standar C ++ 11, konsep-konsep seperti std :: thread, std :: atomic, std :: future, std :: mutex diperkenalkan, dan di masa mendatang diharapkan coroutine, model perhitungan asinkron, akan ditambahkan. Ya, ini semua hal yang menarik untuk dipelajari, tetapi laporan ini akan fokus pada ide yang sama sekali berbeda.
Software Transactional Memory (STM) - konsep model data yang bisa berubah secara transaksi - telah ada sejak lama dan memiliki sejumlah implementasi untuk semua bahasa. Dengan menggunakan STM, Anda mengekspresikan model data Anda dan memulainya untuk berubah di banyak utas, secara kompetitif, tanpa harus khawatir tentang sinkronisasi utas, keadaan data yang valid, atau terkunci. STM akan melakukan segalanya untuk Anda. Ini kedengarannya sangat bagus, tetapi tidak semua perpustakaan STM sama-sama bermanfaat. STM imperatif tradisional sangat kompleks, rentan terhadap bug multithreaded non-sepele, dan sulit digunakan. Di sisi lain, di dunia pemrograman fungsional, konsep STM kombinatorial telah lama ada, transaksi di mana batu bata komposer, dari mana Anda membangun transaksi dari tingkat yang lebih tinggi. Pendekatan kombinatorial pada STM memungkinkan Anda untuk mengekspresikan model data kompetitif secara lebih fleksibel, jelas, dan andal. Pemrograman paralel juga bisa menyenangkan!
Dalam laporan tersebut, penulis akan berbicara tentang fitur-fitur STM kombinatorial, bagaimana menggunakannya, dan bagaimana itu dapat diimplementasikan dalam C ++ 17.

Sepanjang seluruh sejarah pemrograman, pemrosesan berurutan elemen berurutan dari berbagai jenis koleksi telah dan masih merupakan salah satu tugas praktis yang paling umum. Representasi internal koleksi, serta algoritma yang digunakan untuk mengambil elemen berikutnya, dapat bervariasi dalam rentang yang sangat luas: array, daftar tertaut, pohon, tabel hash, file et al. Namun, di balik beragam idiom, fungsi perpustakaan standar, solusi ad-hoc, orang dapat mengungkapkan esensi yang tetap tidak berubah untuk seluruh kelas tugas itu. Pembicaraan ini bertujuan untuk menunjukkan transisi selangkah demi selangkah dari algoritma berdasarkan deskripsi eksplisit tindakan atas elemen individu menuju tingkat tinggi, alat pemrosesan deklaratif yang memperlakukan koleksi sebagai entitas dan mengungkapkan logika domain secara memadai.
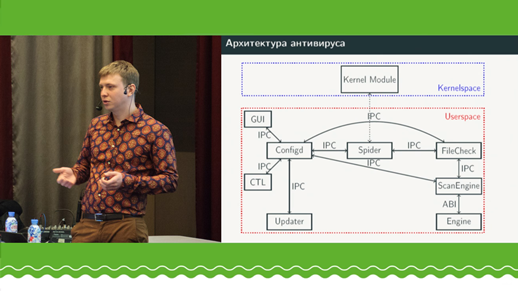
Penulis akan menceritakan tentang pengalamannya dalam mengembangkan mesin anti-virus dalam C ++ dalam bentuk shared library. Fitur unik adalah tidak adanya dependensi eksternal (runtime C ++ atau C). Sejumlah besar ini dibangun di sekitar penggunaan toolchain kustom pada GCC untuk target khusus, yang akan digunakan libc newlib untuk target yang sama, di atasnya libstdc ++ dibangun. Dengan demikian, pustaka bersama dirakit melalui toolchain kustom dengan libgcc_s kustom, libc, libcstdc ++ (perubahan hanya dalam perakitan). Semua interaksi dengan runtime adalah melalui pustaka bersama ABI. Dengan demikian, perpustakaan mempertahankan kemampuan untuk menggunakan C + + penuh modern tanpa batasan (RTTI, pengecualian, iostream, dll), yang pergi ke libstdc ++ libc (newlib) | l ibgcc-ABI. Pendekatan serupa telah diuji pada toolchains GCC / newlib / libstdc ++ untuk Linux, dan clang / newlib / libc ++ untuk MacOS. Laporan ini mungkin menarik bagi mereka yang ingin menggunakan C ++ di perpustakaan bersama, tetapi tidak mampu membelinya karena dependensi eksternal.

Selama satu setengah tahun terakhir, penulis telah memimpin penciptaan spesialisasi Coursera dalam C ++ modern. Spesialisasi akan terdiri dari lima kursus, dua di antaranya sudah berjalan, dan yang lain hampir siap.
Laporan akan memberi tahu:
- masalah apa yang bisa ditemui dalam mengerjakan kursus (misalnya, setelah 3 bulan bekerja, pengembang membuang semua materi dan mulai lagi)
- bagaimana kurikulum dibentuk dan mengapa tepatnya (misalnya, mengapa kata "penunjuk" tidak terdengar dalam dua kursus pertama bahkan sekali)
Selain itu, selama pekerjaan spesialisasi, seperangkat prinsip telah dikembangkan yang berlaku dalam pekerjaan sehari-hari:
- dalam proses mengintegrasikan karyawan baru ke dalam proyek
- selama tinjauan kode
- saat merekrut
Oleh karena itu, penulis tidak hanya ingin mengatakan bagaimana mereka melakukan spesialisasi, tetapi juga akan mencoba untuk mentransfer pengalaman yang diperoleh ke tugas sehari-hari.
Bukan rahasia lagi bahwa pengembangan dalam C / C ++ memiliki persyaratan yang lebih tinggi untuk kualitas kode daripada pengembangan di Jawa. Kemungkinan membuat kesalahan fatal jauh lebih tinggi. Pada saat yang sama, mengumpulkan informasi tentang kesalahan semacam itu adalah tugas yang tidak sepele bahkan untuk programmer yang berpengalaman.
Di bagian pertama laporan, kami akan meninjau secara singkat perkembangan yang ada: cara kerja debugger Android bawaan, solusi apa yang sudah ada. Bagian kedua dikhususkan untuk kisah tentang cara kerjanya "di bawah tenda": cara mendapatkan status prosesor pada saat kesalahan, cara melepaskan tumpukan panggilan, cara mengetahui nomor baris dalam kode sumber. Gambaran umum pustaka promosi stack seperti libcorkscrew, libunwind, libunwindstack akan diberikan.
Laporan ini akan menarik bagi kedua pengembang Android, yang aplikasinya menggunakan NDK, dan semua orang untuk memperluas wawasan mereka.
int * ptr = int baru;
* ptr = 42;
hapus ptr;
Apa yang sebenarnya terjadi ketika 3 baris kode ini dieksekusi? Kami akan melihat ke dalam pengalokasi memori, sistem operasi dan perangkat keras modern untuk memberikan jawaban lengkap untuk pertanyaan ini.
Pada 2017, masalah memilih pengalokasi di C ++ tidak kehilangan relevansi. Mereka menambahkan cara baru ke standar untuk memilih pengalokasi lokal untuk kontainer (std :: pmr), global tcmalloc dan jemalloc terus berkembang, serta antarmuka kernel tempat mereka bergantung. Laporan ini dikhususkan untuk "lantai bawah" dari desain ini: fitur-fitur mmap dan madvise di kernel Linux dan dampak dari fitur-fitur ini pada kinerja pengalokasi.

Pesawat ruang angkasa baru-baru ini diadopsi sebagai fitur bahasa untuk C ++ 20. Dalam ceramah ini, perancang dan penulis proposal pesawat ruang angkasa memberikan gambaran umum tentang fitur tersebut, membahas motivasi dan desainnya, dan membahas contoh-contoh cara menggunakannya. Dia memberikan penekanan khusus pada bagaimana fitur membuat kode C ++ lebih bersih untuk menulis dan membaca, lebih cepat dengan menghindari pekerjaan yang berlebihan, dan lebih kuat dengan menghindari beberapa jebakan penting namun halus dalam kode yang lebih rapuh yang sebelumnya kita harus tulis dengan tangan tanpa fitur ini.

Saat Anda melihat templat, refleksi, pembuatan kode pada tahap kompilasi, metaclasses, Anda merasa bahwa C ++ telah menetapkan sendiri tugas "menyembunyikan" kode final dari pengembang sebanyak mungkin. Penggunaan preprocessor yang tidak sepele (dan banyak cabang) dapat membuat urutan program menjadi sangat tidak jelas. Tentu saja, pendekatan ini menyelamatkan pengembang dari copy-paste yang tak ada habisnya dan pengulangan bagian-bagian yang serupa dari basis kode, tetapi membutuhkan dukungan lebih maju dalam alat pengembangan.
Apakah mungkin untuk men-debug kode tanpa me-restart-nya terus menerus, tanpa debugger, dan bahkan tanpa kompilasi sederhana dari seluruh basis kode? Apakah mungkin menemukan kesalahan dalam kode yang tidak dapat dirakit atau dijalankan di mesin lokal? Ada! Lingkungan Pengembangan Terpadu (IDE) memiliki pengetahuan dan pemahaman yang luas tentang kode khusus, dan merekalah yang dapat menyediakan alat yang sesuai.
Laporan ini akan menunjukkan bagaimana seseorang dapat "men-debug" pergantian makro yang disarangkan oleh typedef, memahami jenis variabel (yang dalam C ++ modern sering "tersembunyi"), men-debug cabang yang berbeda dari preprosesor atau kelebihan operator, dan lebih banyak lagi dengan bantuan yang benar-benar pintar IDE Beberapa fitur sudah tersedia di CLion dan ReSharper C ++, dan beberapa hanya ide yang menarik untuk masa depan, yang akan menarik untuk didiskusikan dengan audiens.

Perakitan proyek C ++ dapat dipindahkan di dalam wadah buruh pelabuhan, sementara alih-alih memasang pustaka dan dependensi yang diperlukan dalam sistem host, mereka dapat dipasang langsung pada gambar buruh pelabuhan (misalnya, Cuda), atau dipasang menggunakan pengelola perpustakaan C ++ Conan (misalnya, Boost). Ini menghasilkan lingkungan yang terkendali (dan setiap kali sama) terisolasi untuk perakitan, di mana Anda dapat menghubungkan cache Conan, sehingga proyek yang berbeda menggunakan pustaka yang sama akan menggunakan rakitan yang sama. Juga, build tidak lagi tergantung pada distribusi Linux di mana proyek sedang dibangun, yang utama adalah Anda dapat menjalankan Docker pada distribusi ini.

Dalam perjalanan laporan, kami akan menulis perpustakaan kecil karya dengan std :: tuple. Menggunakan perpustakaan ini, kami mengkompilasi waktu kompilasi ke tabel hash heterogen. Lebih lanjut - atas dasar kita akan menulis kerangka kerja RPC kecil, menggunakan fakta bahwa kita tidak memiliki penghapusan tipe.
Akan ada banyak perhitungan constexpr, templat, dan fitur-fitur baru di C ++ 17 (khususnya, jika constexpr).
Refleksi sering diperlukan untuk menggeneralisasi algoritma serialisasi. Implementasi berbagai protokol, bekerja dengan basis data. Untuk mengatasi masalah tersebut, kami menulis kompiler IDL homebrew untuk menghasilkan struktur C ++ dan perpustakaan untuk berinteraksi dengan hasilnya. Protobuf dengan pedal dan apakah itu sepadan.
Beberapa waktu yang lalu, komite standardisasi C ++ membuat subkelompok "SG-7" untuk mengeksplorasi cara menambahkan kemampuan refleksi ke bahasa. Baru-baru ini, kelompok itu telah menambahkan "metaprogramming" ke piringnya dan membuat beberapa keputusan penting mengenai bentuk solusi akhirnya. Dalam ceramah ini penulis melihat masa lalu yang membawa kami ke sini dan memeriksa kemungkinan jalur untuk dukungan kelas satu C ++ untuk "pemrograman metafektif reflektif".
Dengan konsep-konsep yang ditambahkan ke revisi C ++ selanjutnya diharapkan konsep-konsep baru dapat didefinisikan. Setiap konsep mendefinisikan satu set operasi yang digunakan oleh kode generik. Salah satu penggunaan tersebut bisa menjadi tes generik yang memverifikasi bahwa semua bagian dari konsep didefinisikan dan memeriksa interaksi generik antara operasi konsep. Idealnya, tes semacam itu bahkan bekerja dengan kelas yang hanya memodelkan sebagian konsep untuk memandu pelaksanaan kelas.
Presentasi ini tidak menggunakan ekstensi konsep yang sebenarnya tetapi menunjukkan bagaimana tes generik dapat dibuat menggunakan fitur C ++ 17. Untuk tes generik, idiom deteksi dan constexpr jika digunakan untuk menentukan ketersediaan operasi yang diperlukan dan dengan anggun berurusan dengan abseence operasi. Tes generik harus dapat mencakup dasar-dasar pemodelan kelas konsep. Jelas, perilaku spesifik untuk kelas masih akan memerlukan tes yang sesuai.

Pemrograman paralel dapat digunakan untuk mengambil keuntungan dari arsitektur multi-core dan heterogen dan secara signifikan dapat meningkatkan kinerja perangkat lunak. C ++ modern telah lama membuat pemrograman paralel lebih mudah dan lebih mudah diakses; menyediakan abstraksi level tinggi dan level rendah. C ++ 17 mengambil ini lebih jauh dengan menyediakan algoritma paralel tingkat tinggi, dan banyak lagi yang diharapkan dalam C ++ 20. Pembicaraan ini memberikan gambaran umum tentang utilitas paralelisme saat ini yang tersedia, dan melihat ke masa depan tentang bagaimana GPU dan sistem heterogen dapat didukung melalui fitur perpustakaan standar baru dan standar lain seperti SYCL.
Bahasa C ++ dan infrastruktur di sekitarnya terus berkembang, yang menjadikan bahasa ini salah satu alat paling efektif saat ini. Saya ingin menyoroti tiga faktor yang membuat bahasa C ++ sekarang sangat menarik.
- Pertama: inovasi dalam standar bahasa, memungkinkan Anda untuk menulis kode yang efisien.
- Kedua: kematangan alat pengembangan dan peningkatan kecepatan perakitan proyek.
- Ketiga: alat pendukung yang matang yang memungkinkan Anda untuk mengontrol kualitas kode dan aspek-aspek lain dari siklus hidup proyek.
Laporan ini adalah ode ke bahasa pemrograman C ++!
Di bidang pengembangan aplikasi multithreaded atau terdistribusi sangat, seseorang dapat semakin mendengar percakapan tentang kode asinkron, termasuk spekulasi tentang perlunya (kurangnya kebutuhan) untuk memperhitungkan asinkron dalam kode, tentang kelengkapan (tidak dapat dipahami) dari kode asinkron, dan efisiensinya (inefisiensi). Dalam laporan ini, kami akan mencoba menyelam lebih dalam ke area subjek: kami akan menganalisis apa yang tidak sinkron; ketika itu muncul; bagaimana hal itu memengaruhi kode yang kita tulis dan bahasa pemrograman yang kita gunakan. Kami akan mencoba mencari tahu apa hubungan masa depan & janji dengan itu, mari kita bicara sedikit tentang coroutine dan aktor. Kami akan memengaruhi JavaScript dan sistem operasi. Tujuan dari laporan ini adalah untuk membuat kompromi yang muncul dengan satu atau beberapa pendekatan lain untuk pengembangan perangkat lunak multithreaded atau terdistribusi lebih eksplisit.

Laporan ini akan membahas keadaan WebAssembly saat ini terkait dengan produk nyata. Kami akan berbicara tentang pengalaman kami dalam porting aplikasi, tentang masalah apa yang muncul dan bagaimana kami menyelesaikannya.
Topik yang dibahas meliputi:
- Dukungan untuk standar pada berbagai platform dan browser.
- Performa dan ukuran bangun dibandingkan asm.js.
- Interaksi dengan browser.
- Bangun macet dari pengguna.
- Fitur VM.
Sistem CMake build secara bertahap menjadi standar de facto untuk pemrograman C ++ lintas-platform. Namun, sering dikritik secara adil, termasuk untuk bahasa scripting yang tidak nyaman, dokumentasi yang ketinggalan zaman, dan fakta bahwa tugas yang sama di dalamnya dapat dilakukan dengan cara yang berbeda, dan bisa sangat sulit untuk memahami mana yang lebih tepat dalam situasi tertentu . Penulis akan memberi tahu:- sering anti-pola populer dan mengapa mereka buruk,
- pada tingkat abstraksi apa CMake bekerja, dan kapan mereka “bocor”,
- apa itu "Modern CMake" dan apa kelebihannya,
- cara melokalkan dan men-debug masalah dalam skrip CMake (termasuk beberapa yang agak eksotis).
Arsitektur proyek yang bersih, abstraksi sederhana pada setiap layer adalah impian setiap tim. Untuk mewujudkan mimpi ini, banyak teknik berorientasi objek telah ditemukan. Dibawa oleh OOP, pengembang lupa untuk memantau kebersihan kode di persimpangan C dan C ++. Di sinilah gaya prosedural akan membantu memulihkan ketertiban, membangun abstraksi yang nyaman dan aman yang mudah masuk ke dalam kode berorientasi objek proyek. Kami akan mencari tahu:- mengapa Anda perlu mengisolasi API C (seperti winapi, POSIX, SQLite, OpenGL, OpenSSL)
- mengapa OOP bekerja dengan buruk dalam bisnis ini
- cara menulis lapisan abstraksi di atas API gaya-C
- bagaimana menangani callback, penanganan kesalahan dan manajemen sumber daya untuk membuat kode yang rumit dan membingungkan tradisional dapat dimengerti bahkan untuk junior
Minat profesionalnya adalah semantik bahasa pemrograman, desain dan implementasi kompiler YaP, dan alat berorientasi bahasa lainnya. Di antara pencapaian yang paling signifikan adalah partisipasi dalam proyek-proyek seperti pembuatan kompiler standar bahasa C ++ lengkap (Interstron, Moscow, 2000), implementasi kompiler bahasa Zonnon untuk .NET (ETH Zurich, 2005), dan implementasi kompiler Swift prototipe untuk platform Tizen ( Samsung Research Institute, Moskow, 2015).C ++ selalu memiliki sub-bahasa meta-pemrograman yang kuat yang memungkinkan pengembang perpustakaan untuk melakukan hal-hal ajaib seperti introspeksi statis untuk mencapai eksekusi polimorfik tanpa warisan. Masalahnya adalah bahwa sintaksinya canggung dan tidak perlu yang membuat pembelajaran meta-pemrograman tugas yang menakutkan.Dengan perbaikan standar baru-baru ini, dan dengan fitur yang direncanakan untuk C ++ 20, meta-pemrograman menjadi lebih mudah, dan meta-program menjadi lebih mudah untuk dipahami dan dipikirkan.Dalam ceramah ini, penulis menyajikan beberapa teknik pemrograman meta modern, dengan fokus utama pada fungsi meta void_t magis.Penulis laporan ini bertanggung jawab atas pengembangan kerangka Openb Source SObjectizer selama 16 tahun. Ini adalah salah satu dari beberapa kerangka kerja aktor lintas-platform yang hidup dan berkembang untuk C ++. Pengembangan SObjectizer dimulai pada tahun 2002, ketika C ++ adalah salah satu bahasa pemrograman yang paling populer dan umum. Selama masa lalu, C ++ telah banyak berubah, dan sikap terhadap C ++ telah berubah bahkan lebih. Laporan ini akan membahas bagaimana perubahan ini memengaruhi pengembangan alat dengan riwayat 16 tahun dan betapa mudah dan nyamannya membuat alat semacam itu untuk bahasa C ++. Dan apakah itu perlu untuk membuat alat seperti itu untuk C ++ secara umum.Dengan standarisasi C ++ 11, kami mendapatkan C ++ perpustakaan multithreading dan model memori. Perpustakaan memiliki blok penyusun dasar seperti atomik, utas, tugas, kunci, dan variabel kondisi. Model memori memberikan jaminan untuk penggunaan blok bangunan dasar yang aman ini.Tujuh tahun kemudian, kami memiliki banyak praktik terbaik untuk menerapkan multithreading dan model memori dengan cara yang aman. Pembicaraan penulis adalah tepatnya tentang praktik terbaik ini untuk aturan umum konkurensi, aturan khusus untuk perpustakaan multithreading, dan aturan khusus untuk model memori. Fokus praktik terbaik ini jauh melampaui C ++.Pembicaraan akan tentang alat-alat bahasa C ++ dan Boost dan perpustakaan STL, serta tentang pendekatan arsitektur untuk membangun aplikasi GUI yang kami gunakan untuk mengembangkan alat untuk membuat pelajaran video.- Berlatih menggunakan pola Model-View-Presenter
- Manajemen Siklus Hidup Dokumen
- Penyimpanan File Pointer Cerdas
Berita tentang kerentanan berikutnya ditemukan secara teratur muncul di sana-sini. Kerugian agunan $, sebagai suatu peraturan, sangat besar. Karena itu, alih-alih memperbaiki kerentanan, mereka seharusnya tidak diizinkan untuk muncul.
Salah satu cara untuk mengatasi kesalahan dalam kode adalah dengan menggunakan analisis statis. Tetapi seberapa cocokkah itu untuk mencari kerentanan? Dan apakah memang ada perbedaan besar antara bug sederhana dan kerentanan kode?
Kami akan membahas masalah ini selama laporan, dan pada saat yang sama kami akan berbicara tentang cara menggunakan analisis statis untuk mendapatkan hasil maksimal dari itu.
PSSaya sendiri, saya ingin menarik perhatian Anda pada intrik mini di sekitar
std :: string yang terkait dengan laporan rekan saya Andrei Karpov. Jadi, untuk:
- Sebuah fragmen dari laporan Andrei (C ++ Rusia 2016) "Kisah pribadi dari pengembang penganalisa kode" dari 30:05 - tautan .
- Mudah trolling orang-orang seperti kami oleh Anton Polukhin (C ++ Rusia 2017) dalam laporan "Bagaimana tidak melakukannya: C ++ membangun sepeda untuk para profesional" mulai pukul 2:00 - tautan .
- Kisah Andrey di konferensi C ++ Russia 2018 bahwa kita bukan dinosaurus dan sedang mempelajari hal baru: "C ++ Efektif" dari 12:21 - tautan .
Itu saja! Nikmati laporan Anda.