Perusahaan kami SberTech (Sberbank Technologies) saat ini menggunakan HDFS 2.8.4 karena memiliki sejumlah keunggulan, seperti ekosistem Hadoop, kerja cepat dengan data dalam jumlah besar, bagus dalam analitik dan banyak lagi. Tetapi pada bulan Desember 2017, Apache Software Foundation merilis versi baru dari kerangka kerja open-source untuk mengembangkan dan mengeksekusi program terdistribusi - Hadoop 3.0.0, yang mencakup sejumlah perbaikan signifikan pada jalur rilis utama sebelumnya (hadoop-2.x). Salah satu pembaruan paling penting dan menarik bagi kami adalah dukungan kode redundansi (Erasure Coding). Oleh karena itu, tugas ditetapkan untuk membandingkan versi ini satu sama lain.
SberTech Company mengalokasikan 10 mesin virtual masing-masing 40 GB untuk pekerjaan penelitian ini. Karena kebijakan pengkodean RS (10.4) membutuhkan minimal 14 mesin, itu tidak akan berfungsi untuk mengujinya.
Di salah satu mesin, NameNode akan ditempatkan di samping DataNode. Pengujian akan dilakukan dengan kebijakan penyandian berikut:
- XOR (2.1)
- RS (3.2)
- RS (6.3)
Dan juga, menggunakan replikasi dengan faktor replikasi 3.
Ukuran blok data dipilih sama dengan 32 MB.
Penelitian
Tes Kecepatan Data
Tes untuk kecepatan transfer data dilakukan. Data ditransfer dari sistem file lokal ke sistem file terdistribusi. Ukuran file yang digunakan dalam tes ini adalah 292,2 MB.
Hasil-hasil berikut diperoleh:
Grafik nilai yang diterima yang dikelompokkan dari waktu transfer file juga dibuat:

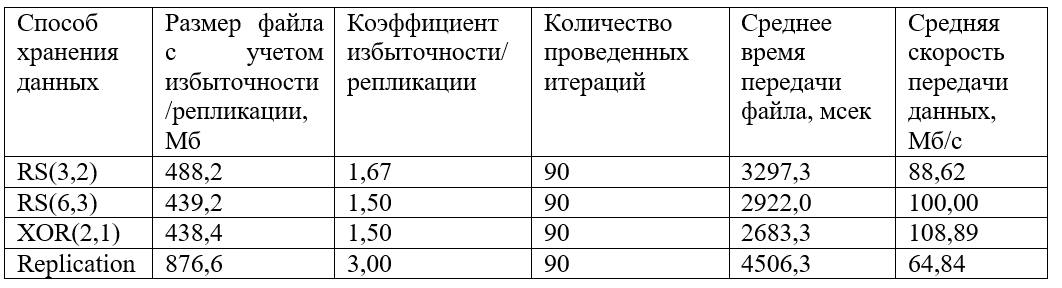
Dan juga, grafik tingkat data yang diterima yang dikelompokkan:
Seperti dapat dilihat dari grafik, data tercepat ditransmisikan dengan XOR (2,1). Pengkodean RS (6.3) dan RS (3.2) menunjukkan perilaku yang serupa, meskipun nilai kecepatan rata-rata untuk RS (6.3) sedikit lebih tinggi. Replikasi kehilangan banyak kecepatan (sekitar 1,5 kali lebih kecil dari XOR dan 1,5 kali lebih sedikit dari RS).
Adapun efisiensi penyimpanan, XOR (2.1) dan RS (6.3) adalah metode penyimpanan yang paling menguntungkan, data yang berlebihan hanya 50%. Replikasi, dengan rasio replikasi 3, kehilangan lagi, menyimpan 200% dari data yang berlebihan.
Tes kinerja
Dalam tes sebelumnya, status server dipantau menggunakan alat pemantauan Grafana.
Di bawah ini adalah grafik yang menunjukkan beban CPU selama tes transfer data:
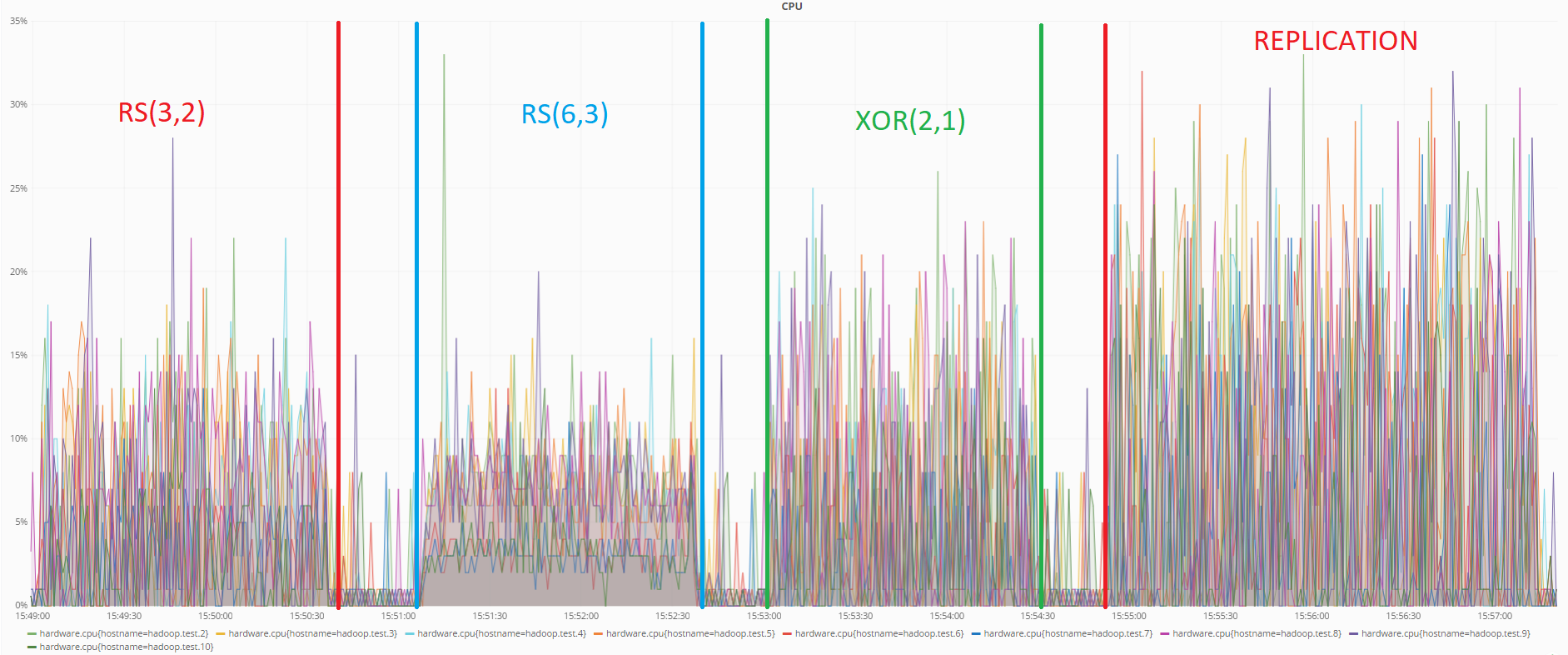
Seperti dapat dilihat dari grafik, dalam tes ini juga pengkodean RS (6.3) mengkonsumsi sumber daya paling sedikit. Replikasi menunjukkan lagi hasil terburuk.
Konsumsi Sumber Daya dalam Pemulihan Data
Untuk melakukan tes ini, sejumlah data diunggah ke sistem file terdistribusi Hadoop. Kemudian dua mesin dengan DataNode dihilangkan.
Di bawah ini adalah grafik dari keadaan mesin pada saat pemulihan data dengan pengkodean RS (6.3) dan saat menggunakan replikasi:
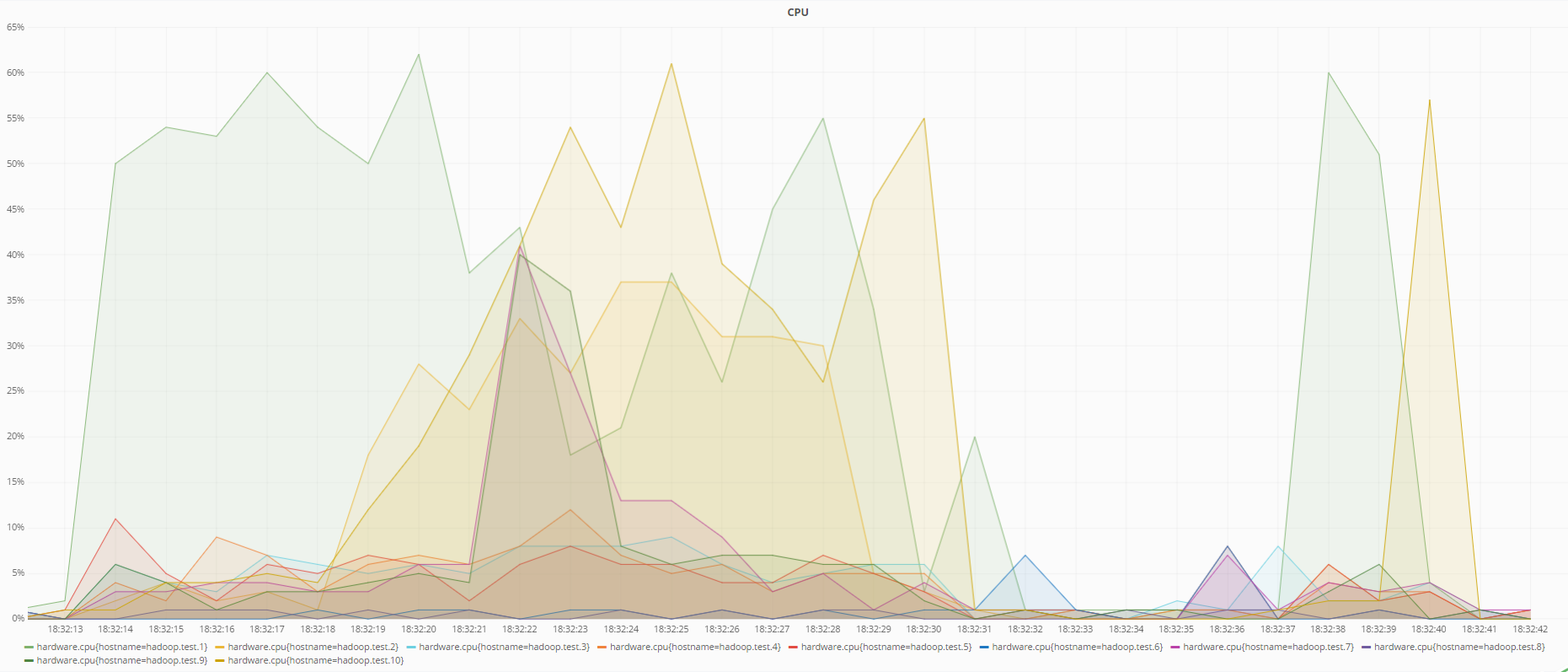
Status prosesor selama pemulihan data menggunakan pengkodean RS (6.3)

Status CPU selama pemulihan data menggunakan replikasi
Seperti dapat dilihat dari grafik, pengkodean RS (6.3) memuat prosesor lebih dari replikasi selama pemulihan data, yang logis, karena untuk memulihkan data yang hilang menggunakan kode redundan, perlu untuk menghitung matriks redundansi terbalik, yang menggunakan lebih banyak sumber daya daripada hanya menimpa. data dari DataNode lain dalam kasus replikasi.
Hasil tes:
- Untuk kecepatan transfer data, yang terbaik adalah menggunakan pengkodean XOR (2.1) atau RS (6.3)
- Saat mengirimkan data, prosesor paling sedikit memuat RS pengodean (6.3) dan RS (3.2)
- Saat mengembalikan data, prosesor paling tidak ditekankan oleh penggunaan replikasi
- Cara paling ringkas untuk menyimpan data adalah penyandian RS (6.3) dan XOR (2.1)
Metode penyimpanan yang paling dapat diandalkan adalah pengkodean RS (6.3), karena memungkinkan Anda kehilangan hingga tiga mesin tanpa kehilangan data, dan replikasi dengan koefisien replikasi 3 mendukung kegagalan hingga 2 mesin. XOR (2, 1) adalah cara paling tidak dapat diandalkan untuk menyimpan data karena memungkinkan Anda kehilangan maksimum satu mesin.
Kesimpulan
Tujuan utama menggunakan sistem file terdistribusi di SberTech adalah:
- Keandalan Tinggi
- Meminimalkan biaya pemeliharaan server untuk penyimpanan data
- Menyediakan alat analisis data
Berdasarkan hasil analisis, kesimpulan berikut dibuat:
- HDFS 3 mengungguli keandalan dibandingkan HDFS 2.
- HDFS 3 menang dengan meminimalkan biaya pemeliharaan server karena menyimpan data lebih kompak.
- HDFS 3 memiliki perangkat analisis data yang sama dengan HDFS 2.
Dalam hal ini, disimpulkan bahwa HDFS 3 adalah pengganti yang rasional untuk HDFS 2.
Sumber yang digunakan: