Hai Nama saya Denis Kiryanov, saya bekerja di Sberbank dan menangani masalah pemrosesan bahasa alami (NLP). Suatu ketika kami harus memilih parser sintaksis untuk bekerja dengan bahasa Rusia. Untuk melakukan ini, kami mempelajari belantara morfologi dan tokenisasi, menguji berbagai pilihan dan mengevaluasi penerapannya. Kami membagikan pengalaman kami di pos ini.

Persiapan untuk seleksi
Mari kita mulai dengan dasar-dasarnya: bagaimana cara kerjanya? Kami mengambil teks, melakukan tokenization dan mendapatkan beberapa pseudo-token. Tahapan analisis lebih lanjut cocok dengan piramida:
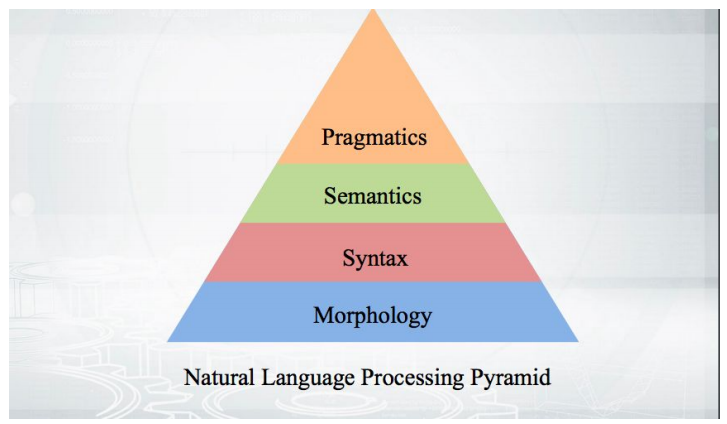
Semuanya dimulai dengan morfologi - dengan analisis bentuk kata dan kategori gramatikal (jenis kelamin, kasus, dll.). Morfologi didasarkan pada sintaksis - hubungan di luar batas satu kata, antar kata. Parser sintaksis yang akan dibahas, menganalisis teks dan memberikan struktur ketergantungan kata-kata dari satu sama lain.
Tata bahasa dependensi dan tata bahasa komponen langsung
Ada dua pendekatan utama untuk penguraian, yang dalam teori linguistik ada pada pijakan yang sama.

Di baris pertama, kalimat diuraikan sebagai bagian dari tata bahasa dependensi. Pendekatan ini diajarkan di sekolah. Setiap kata dalam sebuah kalimat entah bagaimana terhubung dengan yang lain. “Sabun” - predikat yang menjadi sandaran subjek “ibu” (di sini tata bahasa dependensi menyimpang dari sekolah, di mana predikat bergantung pada subjek). Subjek memiliki definisi tergantung dari "milikku." Predikat memiliki "bingkai" pelengkap langsung yang tergantung. Dan penambahan langsung ke "bingkai" - definisi "kotor."
Pada baris kedua, analisis sesuai dengan tata bahasa komponen itu sendiri.
Menurutnya, kalimat itu dibagi menjadi kelompok kata (frasa). Kata-kata dalam satu kelompok lebih terkait erat. Kata-kata "saya" dan "ibu" lebih terkait erat, "bingkai" dan "kotor" - juga. Dan masih ada "sabun" yang terpisah.
Pendekatan kedua untuk penguraian otomatis bahasa Rusia tidak dapat diterapkan, karena di dalamnya kata-kata yang berkaitan erat (anggota kelompok yang sama) sangat sering tidak berdiri berurutan. Kita harus menggabungkannya dengan tanda kurung yang aneh - dalam satu atau dua kata. Oleh karena itu, dalam penguraian otomatis bahasa Rusia, sudah lazim bekerja berdasarkan tata bahasa dependensi. Ini juga nyaman karena semua orang akrab dengan "kerangka kerja" di sekolah.
Pohon ketergantungan
Kita dapat menerjemahkan serangkaian dependensi ke dalam struktur pohon. Bagian atas adalah kata "sabun," beberapa kata langsung bergantung padanya, sebagian tergantung pada para pecandu. Berikut adalah
definisi pohon ketergantungan dari buku teks Martin dan Zhurafsky:
Pohon ketergantungan adalah grafik terarah yang memenuhi batasan berikut:- Ada simpul root tunggal yang ditunjuk yang tidak memiliki busur masuk.
- Dengan pengecualian dari simpul akar, setiap simpul memiliki tepat satu busur yang masuk.
- Ada jalur unik dari simpul akar ke setiap simpul di V.
Ada simpul tingkat atas - predikat. Dari sini Anda dapat mencapai kata apa pun. Setiap kata tergantung pada yang lain, tetapi hanya pada satu. Pohon ketergantungan terlihat seperti ini:

Di pohon ini, ujung-ujungnya ditandai dengan beberapa jenis hubungan sintaksis khusus. Dalam tata bahasa dependensi, tidak hanya fakta koneksi antara kata dianalisis, tetapi juga sifat koneksi ini. Misalnya, "diambil" hampir merupakan satu bentuk kata kerja, "inventaris" adalah subjek untuk "diambil". Oleh karena itu, kita memiliki tepi "adalah" di satu arah dan yang lainnya. Ini bukan koneksi yang sama, mereka memiliki sifat yang berbeda, sehingga harus dibedakan.
Selanjutnya, kami mempertimbangkan kasus-kasus sederhana di mana anggota hukuman hadir, tidak tersirat. Ada struktur dan tanda untuk menangani pass. Sesuatu muncul di pohon yang tidak memiliki ekspresi dangkal - sepatah kata pun. Tapi ini adalah subjek penelitian lain, tetapi kita masih perlu fokus pada kita sendiri.
Proyek Ketergantungan Universal
Untuk memfasilitasi pilihan parser, kami mengalihkan perhatian kami ke proyek
Ketergantungan Universal dan kompetisi
Tugas Bersama CoNLL , yang baru-baru ini terjadi dalam kerangka kerjanya.
Universal Dependencies adalah proyek untuk menyatukan markup korpus sintaksis (tribanks) dalam kerangka tata bahasa dependensi. Di Rusia, jumlah jenis tautan sintaksis terbatas - subjek, predikat, dll. Dalam bahasa Inggris sama, tetapi himpunan sudah berbeda. Misalnya, sebuah artikel muncul di sana yang juga perlu diberi label entah bagaimana. Jika kami ingin menulis parser ajaib yang dapat menangani semua bahasa, maka kami akan segera mengalami masalah membandingkan tata bahasa yang berbeda. Para pencipta heroik Dependensi Universal berhasil menyepakati di antara mereka sendiri dan menandai semua bangunan yang mereka miliki dalam satu format. Tidak terlalu penting bagaimana mereka setuju, yang terpenting adalah pada output kami mendapatkan format seragam tertentu untuk menyajikan keseluruhan cerita ini -
lebih dari 100 tribank untuk 60 bahasa .
Tugas Bersama CoNLL adalah kompetisi antara pengembang algoritma penguraian, yang diadakan sebagai bagian dari proyek Ketergantungan Universal. Panitia mengambil sejumlah tribank dan memecahnya menjadi tiga bagian - pelatihan, validasi, dan tes. Bagian pertama diberikan kepada peserta kompetisi sehingga mereka melatih model mereka di atasnya. Bagian kedua juga digunakan oleh peserta untuk mengevaluasi operasi algoritma setelah pelatihan. Peserta dapat mengulangi pelatihan dan penilaian secara iteratif. Kemudian mereka memberikan algoritma terbaik mereka kepada panitia, yang menjalankannya pada bagian uji, tertutup bagi para peserta. Hasil model pada bagian uji tribank adalah hasil kompetisi.
Metrik kualitas
Kami memiliki koneksi antara kata dan tipenya. Kami dapat mengevaluasi apakah kata atas ditemukan dengan benar - metrik UAS (Skor lampiran tidak berlabel). Atau untuk mengevaluasi apakah titik dan jenis ketergantungan ditemukan dengan benar - metrik LAS (Labeled attachment score).

Tampaknya penilaian akurasi memohon sendiri di sini - kami mempertimbangkan berapa kali kami dapatkan dari jumlah total kasus. Jika kami memiliki 5 kata dan untuk 4 kami menentukan yang benar, kami mendapat 80%.
Tetapi sebenarnya mengevaluasi parser dalam bentuk murni itu bermasalah. Pengembang yang memecahkan masalah parsing otomatis sering mengambil teks mentah sebagai input, yang, sesuai dengan analisis piramida, melewati tahap-tahap tokenization dan analisis morfologis. Kesalahan dari langkah-langkah sebelumnya ini dapat mempengaruhi kualitas pengurai. Secara khusus, ini berlaku untuk prosedur tokenization - alokasi kata. Jika kami telah mengidentifikasi kata unit yang salah, maka kami tidak akan lagi dapat mengevaluasi hubungan sintaksis di antara mereka dengan benar - bagaimanapun, dalam korps berlabel asli kami, unit-unit itu berbeda.
Oleh karena itu, rumus evaluasi dalam hal ini adalah ukuran-f, di mana akurasi adalah bagian dari hit akurat relatif terhadap jumlah prediksi, dan kelengkapan adalah share hit akurat relatif terhadap jumlah tautan dalam data mark-up.
Ketika kami memberikan taksiran di masa mendatang, kita harus ingat bahwa metrik yang digunakan tidak hanya memengaruhi sintaksis, tetapi juga kualitas tokenization.
Bahasa Rusia di Universal Dependencies
Agar parser dapat menandai kalimat yang belum dilihat secara sintaksis, ia perlu memberi makan korpus yang ditandai untuk pelatihan. Untuk bahasa Rusia, ada beberapa kasus seperti itu:

Kolom kedua menunjukkan jumlah token - kata. Semakin banyak token, semakin banyak korps pelatihan dan semakin baik algoritma final (jika ini adalah data yang baik). Jelas, semua percobaan dilakukan di SynTagRus (dikembangkan oleh IPPI RAS), di mana ada lebih dari satu juta token. Semua algoritma akan dilatih tentang hal itu, yang akan dibahas nanti.
Parser untuk bahasa Rusia dalam Tugas Bersama CoNLL
Menurut hasil
kompetisi tahun lalu, model yang dilatih pada SynTagRus yang sama mencapai indikator LAS berikut:

Hasil parser untuk Rusia mengesankan - mereka lebih baik daripada parser untuk bahasa Inggris, Prancis, dan bahasa lain yang lebih jarang. Kami sangat beruntung karena dua alasan sekaligus. Pertama, algoritma melakukan pekerjaan yang baik dengan bahasa Rusia. Kedua, kami memiliki SynTagRus - perumahan besar dan bertanda.
Ngomong-ngomong, kompetisi tahun 2018 telah berlalu, tetapi kami melakukan penelitian pada musim semi tahun ini, jadi kami mengandalkan hasil trek tahun lalu.
Ke depan, kami perhatikan bahwa
versi baru UDPipe (Future) ternyata lebih tinggi tahun ini.
Syntaxnet, parser Google, tidak ada dalam daftar. Apa yang salah dengannya? Jawabannya sederhana: Sintaksis dimulai hanya dengan tahap analisis morfologis. Dia mengambil tokenization ideal siap pakai, dan sudah membangun pemrosesan di atasnya. Oleh karena itu, tidak adil untuk mengevaluasinya setara dengan yang lainnya - sisanya melakukan pemisahan menjadi token dengan algoritma mereka sendiri, dan ini dapat memperburuk hasil pada tahap berikutnya dari sintaks. Sampel Syntaxnet 2017 memiliki hasil yang lebih baik daripada seluruh daftar di atas, tetapi perbandingan langsung tidak adil.
Tabel mendapat dua versi UDPipe, di 12 dan 15 tempat. Orang yang sama yang mengambil bagian aktif dalam proyek Ketergantungan Universal sedang mengembangkan parser ini.
Pembaruan UDPipe secara berkala muncul (agak kurang sering, omong-omong, tata letak casing juga diperbarui). Jadi, setelah kompetisi tahun lalu, UDPipe diperbarui (ini adalah komitmen untuk versi 2.0 belum dirilis; di masa depan, untuk kesederhanaan, kita akan secara kasar merujuk pada komitmen UDPipe 2.0 yang kami ambil, meskipun sebenarnya tidak demikian); Tentu saja, tidak ada pembaruan seperti itu di tabel kompetisi. Hasil dari komit “kami” berada di peringkat ketujuh.
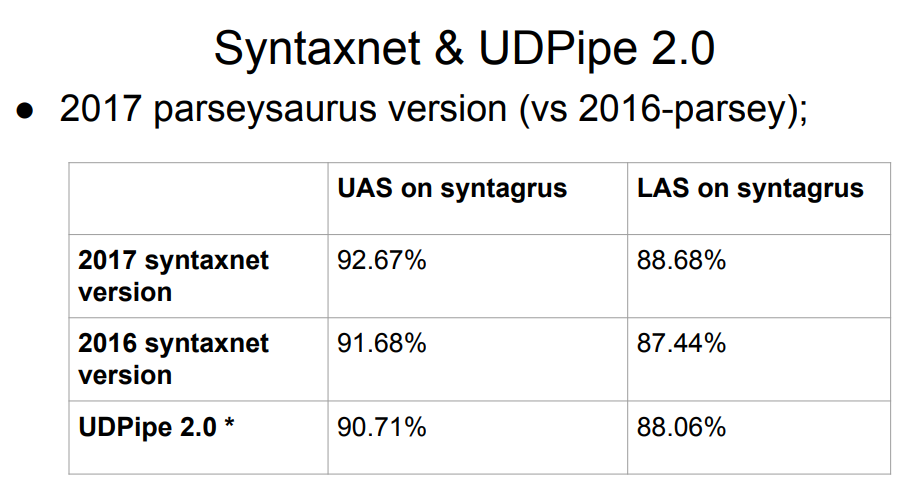
Jadi, kita perlu memilih parser untuk bahasa Rusia. Sebagai data awal, kami memiliki pelat di atas dengan Syntaxnet terkemuka dan dengan UDPipe 2.0 di suatu tempat di tempat ke-7.
Pilih model
Kami membuatnya sederhana: kami mulai dengan parser dengan harga tertinggi. Jika ada sesuatu yang salah dengannya, pergi ke bawah. Sesuatu mungkin tidak benar sesuai dengan kriteria berikut - mungkin mereka tidak sempurna, tetapi mereka mendatangi kita:
- Kecepatan kerja Parser kami harus bekerja cukup cepat. Sintaksnya, tentu saja, jauh dari satu-satunya modul "di bawah tenda" dari sistem waktu-nyata, jadi Anda tidak boleh menghabiskan lebih dari selusin milidetik untuk itu.
- Kualitas pekerjaan . Minimal, parser itu sendiri didasarkan pada data bahasa Rusia. Persyaratannya jelas. Untuk bahasa Rusia, kami memiliki analisa morfologi yang cukup baik yang dapat diintegrasikan ke dalam piramida kami. Jika kita dapat memastikan bahwa parser itu berfungsi dengan baik tanpa morfologi, maka ini cocok untuk kita - kita akan menyelipkan morfologi nanti.
- Ketersediaan kode pelatihan dan lebih disukai model dalam domain publik . Jika kami memiliki kode pelatihan, kami akan dapat mengulangi hasil dari penulis model. Untuk melakukan ini, mereka harus terbuka. Dan, di samping itu, kita perlu memantau dengan cermat kondisi distribusi kasus dan model - apakah kita harus membeli lisensi untuk menggunakannya, jika kita menggunakannya sebagai bagian dari algoritme kita?
- Luncurkan tanpa usaha ekstra . Item ini sangat subjektif, tetapi penting. Apa artinya ini? Ini berarti bahwa jika kita duduk selama tiga hari dan memulai sesuatu, tetapi itu tidak dimulai, maka kita tidak akan dapat memilih parser ini, bahkan jika itu akan memiliki kualitas yang sempurna.
Segala sesuatu yang lebih tinggi dari UDPipe 2.0 pada parser chart tidak cocok untuk kita. Kami memiliki proyek Python, dan beberapa parser dari daftar tidak ditulis dalam Python. Untuk mengimplementasikannya dalam proyek Python, perlu untuk menerapkan upaya yang sangat super. Dalam kasus lain, kami dihadapkan dengan kode sumber tertutup, pengembangan akademis, industri - secara umum, Anda tidak akan sampai ke dasar.
Star Syntaxnet layak mendapat cerita terpisah tentang kualitas pekerjaan. Di sini dia tidak cocok dengan kita untuk kecepatan kerja. Waktu tanggapannya terhadap beberapa frasa sederhana yang umum dalam obrolan adalah dari 100 milidetik. Jika kita menghabiskan begitu banyak pada sintaksis, kita tidak punya cukup waktu untuk hal lain. Pada saat yang sama, UDPipe 2.0 melakukan parsing selama ~ 3ms. Akibatnya, pilihan jatuh pada UDPipe 2.0.
UDPipe 2.0
UDPipe adalah saluran pipa yang mempelajari tokenization, lemmatization, tagging morfologis, dan penguraian tata bahasa dependensi. Kita dapat mengajarinya semua ini atau sesuatu secara terpisah. Misalnya, buatlah penganalisa morfologis lain untuk bahasa Rusia. Atau latih dan gunakan UDPipe sebagai tokenizer.
UDPipe 2.0 didokumentasikan secara rinci. Ada
deskripsi arsitektur ,
repositori dengan kode pelatihan ,
manual . Yang paling menarik adalah
model yang sudah jadi , termasuk untuk bahasa Rusia. Unduh dan jalankan. Juga pada sumber daya ini parameter pelatihan yang dipilih untuk setiap corpus bahasa telah dirilis. Untuk setiap model seperti itu, dibutuhkan sekitar 60 parameter pelatihan, dan dengan bantuan mereka Anda dapat secara mandiri mencapai indikator kualitas yang sama seperti pada tabel. Mereka mungkin tidak optimal, tetapi setidaknya kita dapat yakin bahwa pipa akan bekerja dengan benar. Selain itu, keberadaan referensi semacam itu memungkinkan kami untuk bereksperimen dengan tenang dengan model kami sendiri.
Cara Kerja UDPipe 2.0
Pertama, teks dibagi menjadi kalimat, dan kalimat menjadi kata-kata. UDPipe melakukan semua ini sekaligus dengan bantuan modul bersama - jaringan saraf (GRU dua sisi satu-lapisan), yang untuk setiap karakter memprediksi apakah itu yang terakhir dalam kalimat atau kata.
Kemudian tagger mulai bekerja - sesuatu yang memprediksi sifat morfologis token: dalam hal ini kata itu, dalam jumlah apa. Berdasarkan empat karakter terakhir dari setiap kata, tagger menghasilkan hipotesis tentang bagian dari kata-kata dan tag morfologis kata itu, dan kemudian dengan bantuan perceptron memilih opsi terbaik.
UDPipe juga memiliki lemmatizer yang memilih bentuk awal untuk kata-kata. Dia belajar tentang prinsip yang sama dengan mana seorang penutur asing dapat mencoba untuk menentukan lemma dari kata yang tidak dikenal. Kami memotong awalan dan akhir kata, menambahkan beberapa "t", yang ada dalam bentuk awal kata kerja, dll. Jadi kandidat dihasilkan, dari mana perceptron terbaik memilih.
Skema penandaan morfologis (menentukan jumlah, kasus, dan segala sesuatu yang lain) dan prediksi lemma sangat mirip. Mereka dapat diprediksi bersama, tetapi lebih baik secara terpisah - morfologi bahasa Rusia terlalu kaya. Anda juga dapat menghubungkan daftar lemma Anda.
Mari kita beralih ke bagian yang paling menarik - pengurai. Ada beberapa arsitektur parser ketergantungan. UDPipe adalah arsitektur berbasis transisi: ia bekerja dengan cepat, melewati semua token sekali dalam waktu linier.
Parsing sintaksis dalam arsitektur seperti itu dimulai dengan stack (di mana pada awalnya hanya ada root) dan konfigurasi kosong. Ada tiga cara standar untuk mengubahnya:
- LeftArc - berlaku jika elemen kedua dari stack tidak di-root. Itu membuat hubungan antara token di bagian atas tumpukan dan token kedua, dan juga mengeluarkan yang kedua dari tumpukan.
- RightArc adalah sama, tetapi ketergantungan dibangun dengan cara lain, dan ujungnya dibuang.
- Shift - mentransfer kata berikutnya dari buffer ke tumpukan.
Di bawah ini adalah contoh parser (
sumber ). Kami memiliki frasa "pesan penerbangan pagi" dan kami terhubung kembali ke sana:

Inilah hasilnya:

Parser berbasis transisi klasik memiliki tiga operasi yang tercantum di atas: panah satu arah, panah satu arah, dan shift. Ada juga operasi Swap, dalam arsitektur parser berbasis transisi dasar itu tidak digunakan, tetapi termasuk dalam UDPipe. Swap mengembalikan elemen kedua stack ke buffer untuk mengambil yang berikutnya dari buffer (jika ada spasi). Ini membantu melompati beberapa kata dan memulihkan koneksi yang benar.
Ada artikel bagus dari
tautan orang yang membuat operasi swap. Kami akan memilih satu poin: terlepas dari kenyataan bahwa kami berulang kali melewati buffer token awal (mis., Waktu kami tidak lagi linier), operasi ini dapat dioptimalkan sehingga waktu dikembalikan sangat dekat dengan linier. Artinya, sebelum kita bukan hanya operasi yang bermakna dari sudut pandang bahasa, tetapi juga alat yang tidak terlalu memperlambat kerja parser.
Dengan menggunakan contoh di atas, kami menunjukkan operasi, sebagai hasilnya kami mendapatkan beberapa konfigurasi - buffer token dan koneksi di antara mereka. Kami memberikan konfigurasi ini pada langkah saat ini ke parser berbasis transisi, dan dengan itu, ia harus memprediksi konfigurasi di langkah berikutnya. Membandingkan vektor input dan konfigurasi di setiap langkah, model dilatih.
Jadi, kami memilih parser yang sesuai dengan semua kriteria kami, dan bahkan memahami cara kerjanya. Kami melanjutkan ke percobaan.
Masalah UDPipe
Mari kita tanyakan sebuah kalimat kecil: "Transfer seratus rubel ke ibu". Hasilnya membuat Anda memegang kepala Anda.
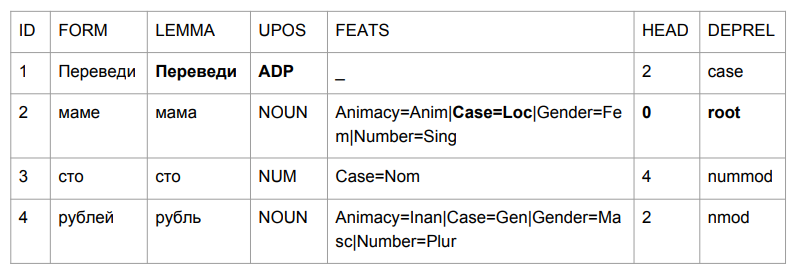
"Terjemahkan" ternyata menjadi alasan, tapi ini cukup logis. Kami menentukan tata bahasa bentuk kata oleh empat karakter terakhir. "Timbal" adalah sesuatu seperti "di tengah", jadi pilihannya relatif logis. Itu lebih menarik dengan "ibu": "ibu" ada dalam kasus preposisional dan menjadi puncak dari kalimat ini.
Jika kita mencoba menafsirkan semuanya berdasarkan hasil parsing, maka kita akan mendapatkan sesuatu seperti "di tengah-tengah seorang ibu (ibu siapa? Siapa ibu ini?) Ratusan rubel." Tidak seperti di awal. Kita harus entah bagaimana berurusan dengan ini. Dan kami datang dengan caranya.
Dalam piramida analisis, sintaks dibangun di atas morfologi, berdasarkan tag morfologi. Berikut adalah contoh buku teks dari ahli bahasa L.V. Shcherby dalam hal ini:
"Gloky cuzdra shteko budlanula bokra dan bocah kecil berambut keriting."Analisis proposal ini tidak menimbulkan masalah. Mengapa Karena kita, sebagai pemberi tag UDPipe, melihat bagian akhir kata dan memahami bagian bicara yang dimaksud dan bentuknya. Cerita dengan "menerjemahkan" sebagai alasan benar-benar bertentangan dengan intuisi kita, tetapi ternyata menjadi logis pada saat kita mencoba melakukan hal yang sama dengan kata-kata yang tidak dikenal. Seseorang mungkin berpikir dengan cara yang sama.
Kami akan mengevaluasi tagger UDPipe secara terpisah. Jika tidak sesuai dengan kami, kami akan mengambil tagger lain - kemudian membuat penguraian di atas markup morfologis lainnya.
Memberi tag dari teks biasa (Skor CoNLL17 F1)- bentuk emas: 301639 ,
- upostag: 98,15% ,
- xpostag: 99,89% ,
- prestasi: 93,97% ,
- alltags: 93,44% ,
- lemmas: 96.68%
Kualitas morfologi UDPipe 2.0 tidak buruk. Tetapi untuk bahasa Rusia lebih baik dicapai. Alat analisis Mystem (
pengembangan Yandex ) mencapai hasil yang lebih baik dalam menentukan bagian pidato daripada UDPipe. Selain itu, penganalisa lain lebih sulit diimplementasikan dalam proyek python, dan mereka bekerja lebih lambat pada kualitas yang sebanding dengan Mystem. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
Dalam kasus seperti itu, Mystem jujur memberikan seluruh rantai:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
Tetapi kami tidak dapat mengirim seluruh rantai pipa ke UDPipe, tetapi kami harus menetapkan beberapa tag yang lebih baik. Bagaimana cara memilihnya? Jika Anda tidak menyentuh apa pun, saya ingin mengambil yang pertama, mungkin itu akan berhasil. Tetapi tag diurutkan secara alfabetis sesuai dengan nama bahasa Inggris, sehingga pilihan kami akan hampir acak, dan beberapa pengurai hampir kehilangan kesempatan untuk menjadi yang pertama.
Ada penganalisa yang dapat memberikan opsi terbaik - Pymorphy2. Tetapi dengan analisis morfologi, ia lebih buruk. Selain itu, ia memberikan kata terbaik di luar konteks. Pymorphy2 hanya akan memberikan satu analisis untuk "no director", "see director" dan "director". Ini tidak akan acak, tetapi benar-benar yang terbaik dalam probabilitas, yang dalam pymorphy2 dianggap pada badan teks yang terpisah. Tetapi persentase tertentu dari analisis yang salah dari teks pertempuran akan dijamin, hanya karena mereka mungkin mengandung frasa dengan bentuk nyata yang berbeda: "Aku melihat direktur" dan "direktur datang ke pertemuan" dan "tidak ada direktur". Probabilitas penguraian tanpa konteks tidak cocok untuk kita.
Bagaimana cara mendapatkan set tag terbaik secara kontekstual? Menggunakan penganalisis
RNNMorph . Hanya sedikit orang yang mendengar tentang dia, tetapi tahun lalu dia memenangkan persaingan di antara para penganalisa morfologis, yang diadakan sebagai bagian dari konferensi Dialog.
RNNMorph memiliki masalah sendiri: tidak memiliki tokenization. Jika Mystem dapat menandai teks mentah, maka RNNMorph membutuhkan daftar token pada input. Untuk sampai ke sintaks, pertama-tama Anda harus menggunakan beberapa tokenizer eksternal, kemudian memberikan hasilnya ke RNNMorph dan baru kemudian memberi makan morfologi yang dihasilkan ke parser sintaks.
Berikut adalah opsi yang kami miliki. Kami tidak akan menolak analisis pymorphy2 tanpa konteks untuk saat ini atas kasus yang dapat diperdebatkan di Mystem - tiba-tiba itu tidak akan tertinggal jauh di belakang RNNMorph. Meskipun jika kita membandingkannya murni pada tingkat kualitas
marka morfologis (data dari
MorphoRuEval-2017 ), maka kerugiannya signifikan - sekitar 15%, jika kita mengambil akurasi sesuai dengan kata-kata.
Selanjutnya, kita perlu mengkonversi output Mystem ke format yang dimengerti oleh UDPipe - conllu. Dan lagi ini adalah masalah, bahkan sebanyak dua. Murni teknis - garis tidak cocok. Dan konseptual - tidak selalu sepenuhnya jelas bagaimana membandingkannya. Dihadapkan dengan dua markup data bahasa yang berbeda, Anda hampir pasti akan mengalami masalah pencocokan tag, lihat contoh di bawah ini. Jawaban untuk pertanyaan "tag mana yang ada di sini" mungkin berbeda, dan mungkin jawaban yang benar tergantung pada tugasnya. Karena ketidakkonsistenan ini, sistem markup yang cocok bukanlah tugas yang mudah.
Bagaimana cara mengubahnya? Ada
paket _
Russian_tagsets - paket untuk Python yang dapat mengonversi berbagai format. Tidak ada terjemahan dari format penerbitan Mystem ke Conllu, yang diterima di Universal Dependencies, tetapi ada terjemahan ke conllu, misalnya, dari format markup dari corpus nasional bahasa Rusia (dan sebaliknya). Penulis paket (ngomong-ngomong, dia adalah penulis pymorphy2) menulis hal yang luar biasa langsung dalam dokumentasi: "Jika Anda tidak dapat menggunakan paket ini, jangan menggunakannya." Dia melakukan ini bukan karena programmer krivorukov (dia adalah programmer yang hebat!), Tetapi karena jika Anda perlu mengonversi satu sama lain, maka Anda berisiko mendapat masalah karena ketidakkonsistenan linguistik dari konvensi markup.
Berikut ini sebuah contoh. Sekolah itu diajarkan "kategori kondisi" (dingin, perlu). Beberapa mengatakan itu kata keterangan, yang lain mengatakan kata sifat. Anda perlu mengonversi ini, dan Anda menambahkan beberapa aturan, tetapi tetap tidak mencapai korespondensi yang jelas antara satu format dengan yang lainnya.
Contoh lain: janji (seseorang melakukan sesuatu atau melakukan sesuatu dengan seseorang). "Petya membunuh seseorang" atau "Petya terbunuh." “Vasya mengambil gambar” - “Vasya mengambil gambar” (yaitu, sebenarnya, “Vasya difoto”). Ada juga jaminan medial di SynTagRus - kami bahkan tidak akan menyelidiki apa itu dan mengapa. Tetapi dalam Mystem tidak. Jika Anda perlu membawa satu format ke format lain, ini jalan buntu.
Kami kurang lebih jujur menerima saran dari penulis paket russian_tagsets - tidak menggunakan pengembangannya, karena kami tidak menemukan pasangan yang diperlukan dalam daftar format korespondensi. Sebagai hasilnya, kami menulis konverter kustom kami dari Mystem ke Conllu dan melanjutkan.
Kami menghubungkan tagger pihak ketiga dan pengurai UDPipe
Setelah semua petualangan, kami mengambil tiga algoritma, yang dijelaskan di atas:
- UDPipe dasar
- Mym dengan tag disambiguasi dari pymorphy2
- RNNMorph
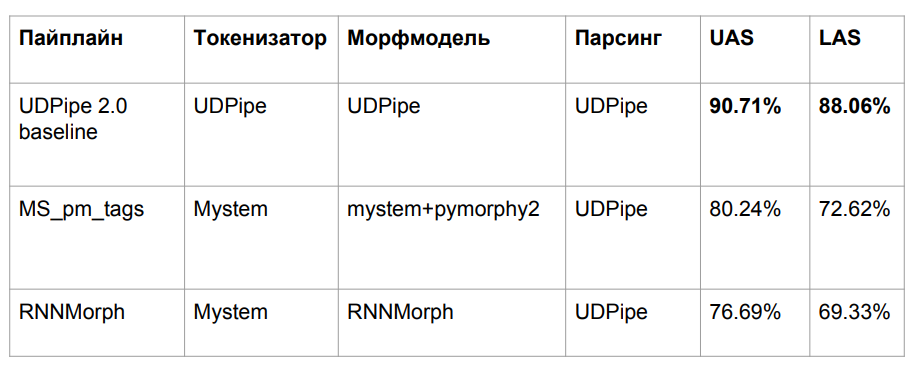
Kami kehilangan kualitas karena alasan yang cukup jelas. Kami mengambil model UDPipe yang dilatih pada satu morfologi, tetapi menyelipkan morfologi lain pada input. Masalah klasik ketidakcocokan data antara kereta api dan tes adalah hasil dari penurunan kualitas.
Kami mencoba menyelaraskan alat penandaan morfologis otomatis kami dengan marka SynTagRus, yang ditandai secara manual. Kami tidak berhasil, oleh karena itu, dalam kasus pelatihan SynTagRus, kami akan mengganti semua tanda morfologi manual dengan yang diperoleh dari Mystem dan pymorphy2 dalam satu kasus dan dari RNNMorph dalam kasus lain. Dalam kasus tervalidasi yang ditandai dengan tangan, kita dipaksa untuk mengubah tanda manual menjadi otomatis, karena "dalam pertempuran" kita tidak akan pernah mendapatkan tanda manual.
Sebagai hasilnya, kami melatih parser UDPipe (hanya parser) dengan hyperparameter yang sama dengan baseline. Apa yang bertanggung jawab atas sintaksis - ID vertex, yang bergantung pada jenis koneksi - kami pergi, kami mengubah segalanya.
Hasil
Selanjutnya saya akan membandingkan kami dengan Syntaxnet dan algoritma lainnya. Penyelenggara Tugas Bersama CoNLL telah meluncurkan partisi SynTagRus (train / dev / test 80/10/10). Kami awalnya mengambil yang lain (kereta / tes 70/30), sehingga data tidak selalu bertepatan dengan kami, meskipun mereka diterima pada kasus yang sama. Selain itu, kami mengambil rilis terbaru (per Februari-Maret) dari repositori SynTagRus - versi ini sedikit berbeda dari yang ada di kompetisi. Data untuk apa yang tidak lepas landas diberikan dalam artikel di mana pemisahannya sama dengan di kompetisi - algoritme tersebut ditandai dengan tanda bintang di tabel.
Inilah hasil akhirnya:
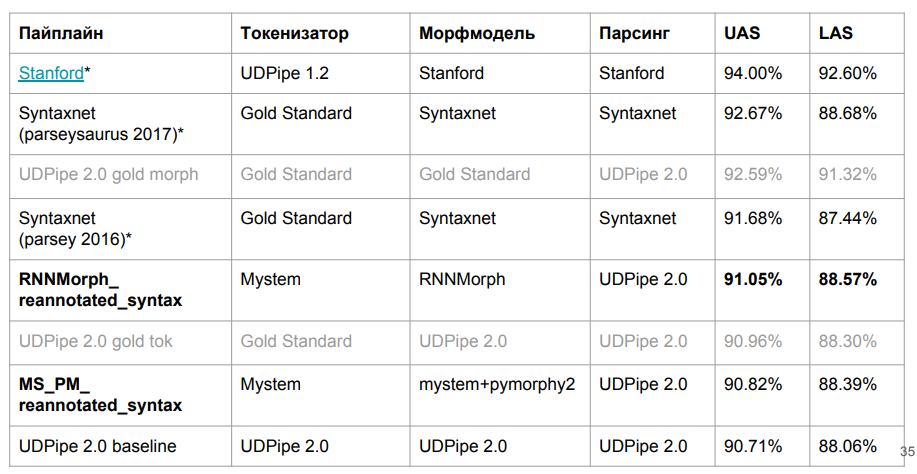
RNNMorph benar-benar menjadi lebih baik - bukan dalam arti absolut, tetapi dalam peran alat bantu untuk mendapatkan metrik umum sesuai dengan hasil parsing (dibandingkan dengan Mystem + pymorphy2). Artinya, semakin baik morfologi, semakin baik sintaksisnya, tetapi pemisahan "sintaksis" jauh lebih sedikit daripada yang morfologis. Perhatikan juga bahwa kami tidak jauh dari model dasar, yang berarti bahwa dalam morfologi benar-benar tidak sebanyak yang kami harapkan.
Saya bertanya-tanya berapa banyak terletak pada morfologi sama sekali? Apakah mungkin untuk mencapai peningkatan mendasar dalam parser sintaksis karena morfologi yang ideal? Untuk menjawab pertanyaan ini, kami mengendarai UDPipe 2.0 menggunakan tokenization dan morfologi yang dikalibrasi sempurna (menggunakan standar markup manual standar). Kami mendapat margin tertentu (lihat baris tentang Gold Morph di tabel; ternyata + 1,54% dari RNNMorph_reannotated_syntax) dari apa yang kami miliki, termasuk dari sudut pandang penentuan jenis koneksi dengan benar. Jika seseorang pernah menulis analisa morfologis yang benar-benar sempurna dari bahasa Rusia, kemungkinan hasil yang kita peroleh dengan menggunakan pengurai sintaksis abstrak juga akan bertambah. Dan kami kira-kira memahami langit-langit (setidaknya langit-langit untuk arsitektur itu dan untuk kombinasi parameter yang kami gunakan untuk UDPipe - ditunjukkan pada baris ketiga dari tabel di atas).
Menariknya, kami hampir mencapai versi Syntaxnet di metrik LAS. Jelas bahwa kami memiliki data yang sedikit berbeda, tetapi pada prinsipnya masih sebanding. Token sintaksis adalah "emas", dan bagi kami - dari Mystem. Kami menulis pembungkus yang disebutkan di atas untuk Mystem, tetapi penguraian masih terjadi secara otomatis; mungkin Mystem juga salah di suatu tempat. Dari garis tabel “UDPipe 2.0 gold tok”, dapat dilihat bahwa jika Anda mengambil tokenization UDPipe dan emas default, maka itu masih sedikit kehilangan Syntaxnet-2017. Tetapi itu bekerja lebih cepat.
Apa yang belum dicapai oleh siapa pun adalah
pengurai Stanford . Ini dirancang dengan cara yang sama seperti Syntaxnet, jadi ini berfungsi untuk waktu yang lama. Di UDPipe, kita tinggal menyusuri tumpukan. Arsitektur parser Stanford dan Syntaxnet memiliki konsep yang berbeda: pertama mereka menghasilkan grafik berorientasi lengkap, dan kemudian algoritma bekerja untuk meninggalkan kerangka (pohon spanning minimal) yang kemungkinan besar akan terjadi. Untuk melakukan ini, ia melakukan kombinasi, dan pencarian ini tidak lagi linier, karena Anda akan beralih ke satu kata lebih dari sekali. Terlepas dari kenyataan bahwa untuk waktu yang lama, dari sudut pandang sains murni, setidaknya untuk bahasa Rusia, itu adalah arsitektur yang lebih efisien. Kami mencoba meningkatkan pengembangan akademik ini selama dua hari - sayangnya, itu tidak berhasil. Tetapi berdasarkan arsitekturnya, jelas bahwa itu tidak bekerja cepat.
Adapun pendekatan kami - meskipun secara formal kami hampir tidak naik dengan metrik, sekarang semuanya baik-baik saja dengan "ibu".
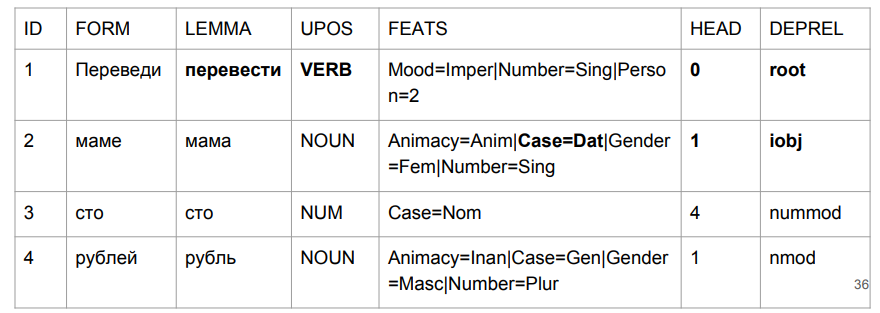
Dalam frasa "menerjemahkan seratus rubel ke ibu", "menerjemahkan" benar-benar kata kerja dalam suasana hati yang penting. "Mom" mendapatkan kopernya. Dan yang paling penting bagi kami adalah label kami (iobj), sebuah objek tidak langsung (tujuan). Meskipun pertumbuhan dalam jumlah dapat diabaikan, kami berhasil mengatasi masalah dengan mana tugas dimulai.
Track bonus: tanda baca
Jika kita kembali ke data sebenarnya, ternyata sintaks tergantung pada tanda baca. Ambillah ungkapan "Anda tidak bisa melakukan belas kasihan." Apa yang sebenarnya tidak bisa dilakukan - untuk "mengeksekusi" atau "berbelas kasihan" - tergantung di mana koma berada. Bahkan jika kita menempatkan ahli bahasa untuk menandai data, dia akan membutuhkan tanda baca sebagai semacam alat bantu. Dia tidak bisa melakukannya tanpa dia.
Mari kita ambil frasa "Peter halo" dan "Peter halo" dan lihat analisis mereka dengan model baseline-UDPipe. Kami mengabaikan masalah itu, menurut model ini, kemudian:
1) "Petya" adalah kata benda feminin;
2) "Petya" adalah (dilihat dari himpunan tag) bentuk awal, tetapi pada saat yang sama, lemanya seharusnya bukan "Petya".
Ini adalah bagaimana hasil berubah karena koma, dengan bantuannya kita mendapatkan sesuatu yang mirip dengan kebenaran.
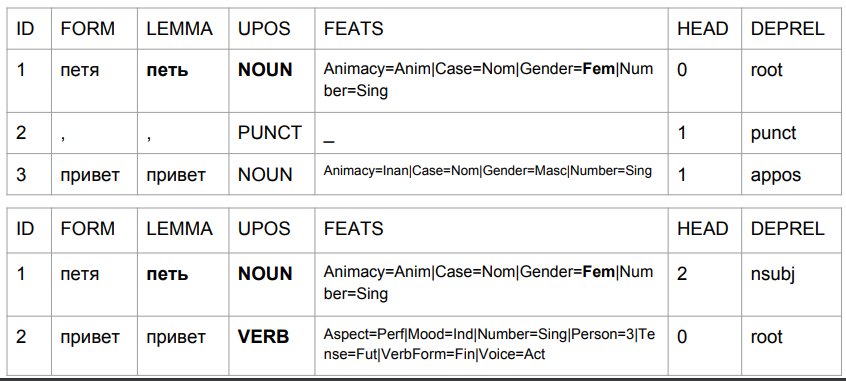
Dalam kasus kedua, "Petya" adalah subjek, dan "halo" adalah kata kerja. Kembali ke prediksi bentuk kata berdasarkan empat karakter terakhir. Dalam interpretasi algoritma, ini bukan "salam Petya", tetapi "salam Petya". Ketik "Petya bernyanyi" atau "Petya akan datang." Analisisnya cukup bisa dimengerti: dalam bahasa Rusia, tidak mungkin ada koma antara subjek dan predikat. Karena itu, jika koma adalah, ini adalah kata "halo", dan jika tidak ada koma, itu mungkin sesuatu seperti "Petya Privet."
Kami akan menjumpai ini dalam produksi cukup sering, karena pemeriksa ejaan akan memperbaiki ejaan, tetapi tidak tanda baca. Untuk memperburuk keadaan, pengguna dapat menetapkan koma secara salah, dan algoritma kami akan memperhitungkannya dalam memahami bahasa alami. Apa solusi yang mungkin ada di sini? Kami melihat dua opsi.
Opsi pertama adalah melakukan apa yang terkadang mereka lakukan ketika menerjemahkan ucapan ke dalam teks. Awalnya, tidak ada tanda baca dalam teks seperti itu, sehingga dipulihkan melalui model. Outputnya adalah materi yang relatif kompeten dalam hal aturan bahasa Rusia, yang membantu parser sintaksis untuk bekerja dengan benar.
Gagasan kedua agak berani dan bertentangan dengan pelajaran sekolah dari bahasa Rusia. Ini melibatkan bekerja tanpa tanda baca: jika tiba-tiba input tanda baca, kami akan menghapusnya dari sana. Kami juga akan menghapus sama sekali semua tanda baca dari korps pelatihan. Kami berasumsi bahwa bahasa Rusia ada tanpa tanda baca. Hanya poin untuk dibagi menjadi kalimat.
Secara teknis, ini sangat sederhana, karena kami tidak mengubah node akhir di pohon sintaksis. Kami tidak dapat memiliki tanda baca di atas. Ini selalu merupakan beberapa simpul akhir, kecuali untuk tanda%, yang karena beberapa alasan di SynTagRus adalah simpul untuk angka sebelumnya (50% di SynTagRus ditandai sebagai% - simpul, dan 50 - tergantung).
Mari kita uji menggunakan model Mystem (+ pymorphy 2).

Sangat penting bagi kita untuk tidak memberikan model teks tanda baca tanpa tanda baca. Tetapi jika kita selalu memberikan teks tanpa tanda baca, maka kita akan berada di baris teratas dan mendapatkan setidaknya hasil yang dapat diterima. Jika teks tanpa tanda baca dan model berfungsi non-tanda baca, maka sehubungan dengan tanda baca yang ideal dan model tanda baca, penurunan hanya sekitar 3%.
Apa yang harus dilakukan? Kita dapat memikirkan angka-angka ini - diperoleh dengan menggunakan model bebas tanda baca dan pemurnian tanda baca. Atau buat semacam classifier untuk mengembalikan tanda baca. Kami tidak akan mencapai angka ideal (angka dengan tanda baca pada model tanda baca), karena algoritme pemulihan tanda baca bekerja dengan beberapa kesalahan, dan angka "ideal" dihitung pada SynTagRus yang benar-benar murni. Tetapi jika kita akan menulis model yang mengembalikan tanda baca, akankah kemajuan membayar biaya kita? Jawabannya belum jelas.
Kita dapat berpikir lama tentang arsitektur parser, tetapi kita harus ingat bahwa sebenarnya belum ada kumpulan besar teks web yang ditandai secara sintaksis. Keberadaannya akan membantu memecahkan masalah nyata dengan lebih baik. Sejauh ini, kami sedang belajar pada korps teks yang benar-benar terpelajar, yang diedit - dan kami kehilangan kualitas dengan mendapatkan teks-teks khusus dalam pertempuran, yang sering ditulis buta huruf.
Kesimpulan
Kami memeriksa penggunaan berbagai algoritma parsing sintaksis berdasarkan tata bahasa dependensi, sebagaimana diterapkan pada bahasa Rusia. Ternyata dalam hal kecepatan, kemudahan dan kualitas pekerjaan, UDPipe ternyata menjadi alat terbaik. Model dasarnya dapat ditingkatkan jika tahap-tahap tokenisasi dan analisis morfologis ditugaskan untuk analisis pihak ketiga lainnya: trik ini memungkinkan untuk memperbaiki perilaku tagger yang salah dan, sebagai hasilnya, parser dalam kasus-kasus penting untuk analisis.
Kami juga menganalisis masalah hubungan antara tanda baca dan parsing dan sampai pada kesimpulan bahwa dalam kasus kami, tanda baca sebelum parsing sintaksis lebih baik untuk dihapus.
Kami berharap poin aplikasi yang dibahas dalam artikel kami akan membantu Anda menggunakan parsing sintaksis untuk menyelesaikan masalah Anda seefisien mungkin.
Penulis berterima kasih kepada Nikita Kuznetsova dan Natalya Filippova atas bantuannya dalam mempersiapkan artikel; untuk bantuan dalam penelitian ini - Anton Alekseev, Nikita Kuznetsov, Andrei Kutuzov, Boris Orekhov dan Mikhail Popov.