Selama bertahun-tahun Mail.ru telah menyelenggarakan kejuaraan pembelajaran mesin, setiap kali tugasnya menarik dengan caranya sendiri dan rumit dengan caranya sendiri. Ini adalah keempat kalinya saya berpartisipasi dalam kompetisi, saya sangat menyukai platform dan organisasi, dan dengan bootcamp saya memulai pembelajaran mesin kompetitif, tetapi saya berhasil menempati posisi pertama untuk pertama kalinya. Dalam artikel ini saya akan memberi tahu Anda cara menunjukkan hasil yang stabil tanpa melatih kembali baik di papan peringkat publik atau pada sampel yang tertunda, jika bagian uji secara signifikan berbeda dari bagian pelatihan data.
Tantangan
Teks lengkap tugas tersedia di →
tautan . Singkatnya: ada 10 GB data, di mana setiap baris berisi tiga jenis json "key: counter", kategori tertentu, cap waktu dan ID pengguna tertentu. Beberapa entri dapat berkorespondensi dengan satu pengguna. Diperlukan untuk menentukan kelas mana milik pengguna, pertama atau kedua. Metrik kualitas untuk model ini adalah ROC-AUC, ia ditulis dengan baik di blog Alexander Dyakonov
[1] .
Contoh entri file
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Solusi
Gagasan pertama yang muncul dari seorang ilmuwan data yang telah berhasil mengunduh dataset adalah mengubah kolom json menjadi matriks yang jarang. Pada titik ini, banyak peserta mengalami masalah dengan kekurangan RAM. Ketika menggunakan bahkan satu kolom dalam python, konsumsi memori lebih tinggi daripada yang tersedia pada laptop rata-rata.
Beberapa statistik kering. Jumlah kunci unik di setiap kolom adalah 2053602, 20275, 1057788. Selain itu, di bagian kereta dan di bagian uji hanya ada 493866, 20268, 141931. 427994 pengguna unik di kereta dan 181024 di bagian tes. Sekitar 4% dari kelas 1 di bagian pelatihan.
Seperti yang Anda lihat, kami memiliki banyak tanda, menggunakan semuanya adalah cara yang jelas untuk mengenakan pakaian di kereta, karena, misalnya, pohon keputusan menggunakan kombinasi tanda, dan bahkan ada kombinasi yang lebih unik dari sejumlah besar tanda dan hampir semuanya hanya ada di bagian pelatihan data atau dalam tes. Namun, salah satu model dasar yang saya miliki adalah lightgbm dengan colsample ~ 0,1 dan regularisasi yang sangat ketat. Namun, meskipun terdapat parameter regularisasi yang sangat besar, ini menunjukkan hasil yang tidak stabil pada bagian publik dan swasta, yang ternyata terjadi setelah kompetisi berakhir.
Pikiran kedua dari orang yang memutuskan untuk berpartisipasi dalam kompetisi ini mungkin akan mengumpulkan kereta dan menguji, mengumpulkan informasi oleh pengidentifikasi. Misalnya jumlahnya. Atau maksimal. Dan di sini ternyata dua hal yang sangat menarik yang Mail.ru buat untuk kita. Pertama, tes dapat diklasifikasikan dengan akurasi sangat tinggi. Bahkan menurut statistik pada jumlah entri untuk cairan dan jumlah kunci unik di json, tes secara signifikan melebihi kereta. Pengklasifikasi dasar memberi 0,9+ roc-auc dalam pengenalan tes. Kedua, penghitung tidak masuk akal, hampir semua model menjadi lebih baik dari beralih dari penghitung ke tanda-tanda biner dari formulir: ada / tidak ada kunci. Bahkan pohon-pohon, yang secara teori seharusnya tidak lebih buruk dari kenyataan bahwa alih-alih sebuah unit ada jumlah tertentu, tampaknya dilatih ulang untuk penghitung.
Hasil pada leaderboard publik jauh melebihi hasil pada validasi silang. Ini tampaknya karena fakta bahwa lebih mudah bagi model untuk membangun peringkat dua catatan dalam tes daripada di kereta, karena lebih banyak tanda memberi lebih banyak istilah untuk peringkat.
Pada tahap ini, menjadi sangat jelas bahwa validasi dalam kompetisi ini bukan hal yang sederhana dan baik informasi publik maupun CV dari peserta lain, yang dapat diperdayai untuk memikat dalam obrolan resmi
[2] . Mengapa itu terjadi? Tampaknya kereta dan tes dipisahkan oleh waktu, yang kemudian dikonfirmasi oleh penyelenggara.
Setiap anggota kaggle yang berpengalaman akan segera menyarankan validasi permusuhan
[3] , tetapi tidak sesederhana itu. Terlepas dari kenyataan bahwa keakuratan classifier untuk kereta dan tes dekat dengan 1 oleh metric roc-auc, tidak ada banyak entri serupa di kereta. Saya mencoba untuk meringkas sampel agregat cairan dengan target yang sama untuk meningkatkan jumlah catatan dengan sejumlah besar kunci unik di json, tetapi ini menyebabkan kelemahan dalam validasi silang dan di depan umum, dan saya takut menggunakan model seperti itu.
Ada dua cara: mencari nilai-nilai abadi dengan pembelajaran tanpa pengawasan atau mencoba untuk mengambil fitur yang lebih penting untuk ujian. Saya pergi dua arah, menggunakan TruncatedSVD untuk tanpa pengawasan dan memilih fitur berdasarkan frekuensi dalam pengujian.
Langkah pertama, bagaimanapun, saya membuat autoencoder yang dalam, tapi saya keliru, mengambil matriks yang sama dua kali, saya tidak bisa memperbaiki kesalahan dan menggunakan set penuh tanda: tensor input tidak masuk ke memori GPU pada ukuran layer yang padat. Saya menemukan kesalahan dan kemudian saya tidak mencoba fitur kode.
Saya menghasilkan SVD dengan semua cara yang imajinatif: pada dataset asli dengan cat_feature dan penjumlahan selanjutnya oleh cuid. Untuk setiap kolom secara terpisah. Oleh tf-idf di json sebagai bag-of-words
[4] (tidak membantu).
Untuk variasi yang lebih besar, saya mencoba memilih sejumlah kecil fitur di kereta, menggunakan A-NOVA untuk bagian kereta dari setiap lipatan dalam validasi silang.
Model
Model dasar utama: lightgbm, vowpal wabbit, xgboost, SGD. Selain itu, saya menggunakan beberapa arsitektur jaringan saraf. Dmitry Nikitko, yang berada di tempat pertama dari papan publik, disarankan menggunakan
HashEmbeddings , model ini setelah beberapa pemilihan parameter menunjukkan hasil yang baik dan meningkatkan ansambel.
Model jaringan saraf lain dengan pencarian interaksi (gaya mesin faktorisasi) antara 3-4-5 kolom data (tiga input kiri), statistik numerik (4 input), matriks SVD (5 input).
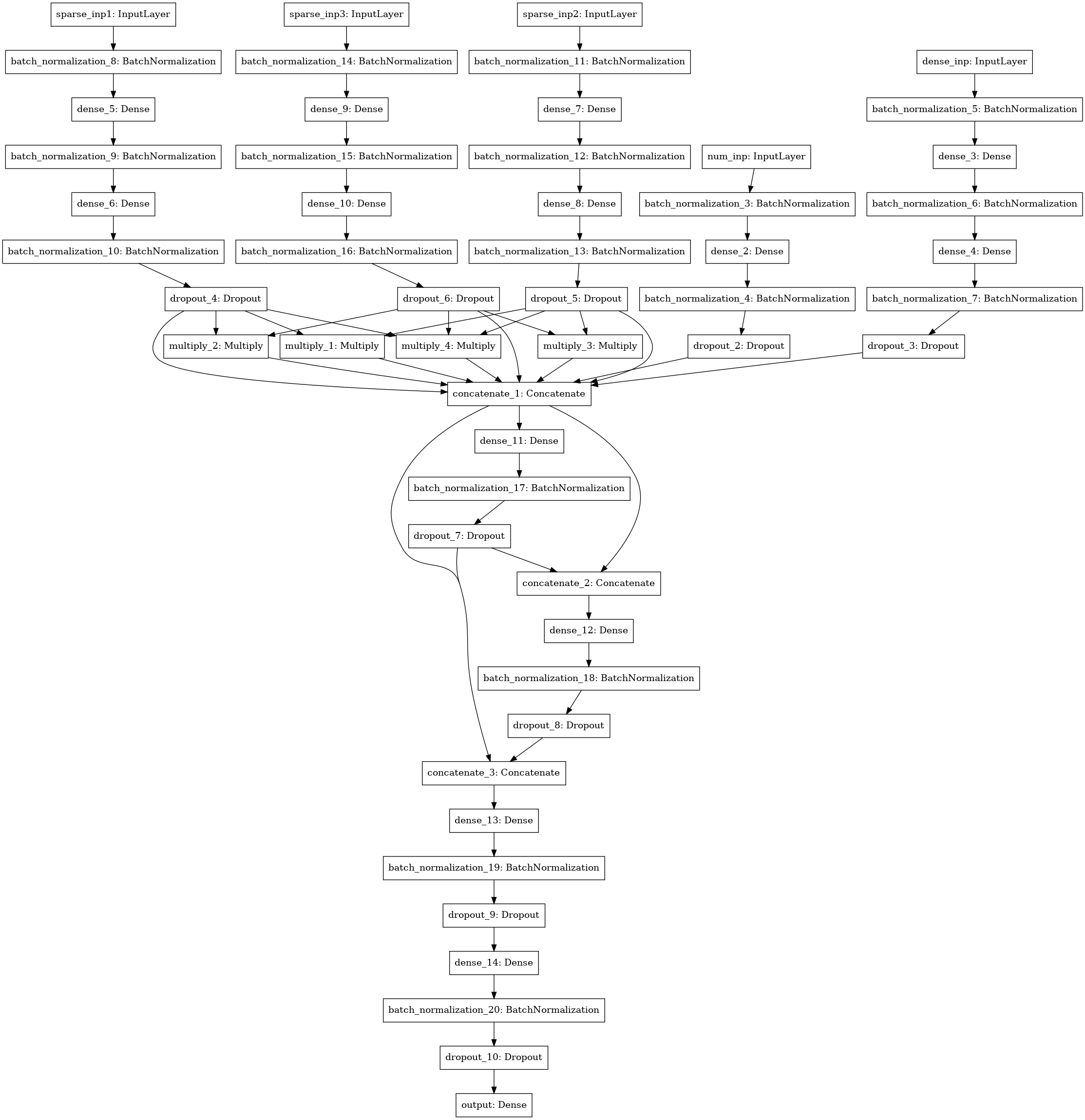
Ensemble
Saya menghitung semua model dengan lipatan, rata-rata prediksi tes dari model yang dilatih pada berbagai lipatan. Prediksi kereta api digunakan untuk menumpuk. Hasil terbaik ditunjukkan oleh tumpukan level 1 menggunakan xgboost pada prediksi model dasar dan 250 atribut dari setiap kolom json, dipilih sesuai dengan frekuensi pertemuan atribut dalam pengujian.
Saya menghabiskan ~ 30 jam waktu saya untuk solusi, mengandalkan server dengan 4 core-i7 core, 64 gigabytes RAM, dan satu GTX 1080. Akibatnya, solusi saya ternyata cukup stabil dan saya pindah dari posisi ketiga di papan peringkat publik ke yang pribadi.
Sebagian besar kode tersedia pada bitbucket dalam bentuk laptop
[5] .
Saya ingin berterima kasih kepada Mail.ru untuk kontes yang menarik dan peserta lain untuk komunikasi yang menarik dalam grup!
[1]
ROC-AUC di blog Aleksandrov Dyakonov[2]
Obrolan Resmi ML BootCamp resmi[3]
Validasi permusuhan[4]
bag-of-words[5]
kode sumber untuk sebagian besar model