
Tugas menyimpan dan mengakses data adalah titik yang menyakitkan bagi sistem informasi apa pun. Bahkan sistem penyimpanan yang dirancang dengan baik (selanjutnya disebut SHD) selama operasi mengungkapkan masalah yang terkait dengan penurunan kinerja. Perhatian khusus harus diberikan pada serangkaian masalah penskalaan ketika jumlah sumber daya yang terlibat mendekati batas yang ditetapkan yang ditetapkan oleh pengembang penyimpanan.
Alasan mendasar untuk terjadinya masalah ini adalah arsitektur tradisional berdasarkan ikatan yang erat dengan karakteristik perangkat keras dari perangkat penyimpanan yang digunakan. Sebagian besar pelanggan masih memilih metode menyimpan dan mengakses data, dengan mempertimbangkan karakteristik antarmuka fisik (SAS / SATA / SCSI), dan bukan kebutuhan nyata dari aplikasi yang digunakan.
Selusin tahun yang lalu, ini adalah keputusan yang logis. Administrator sistem dengan cermat memilih perangkat penyimpanan informasi dengan spesifikasi yang diperlukan, misalnya, SATA / SAS, dan mengandalkan tingkat kinerja berdasarkan kemampuan perangkat keras pengontrol disk. Pertarungan itu untuk volume cache controller RAID dan untuk opsi yang mencegah kehilangan data. Sekarang pendekatan untuk menyelesaikan masalah ini tidak optimal.
Dalam lingkungan saat ini, ketika memilih sistem penyimpanan, masuk akal untuk memulai bukan dari antarmuka fisik, tetapi dari kinerja yang dinyatakan dalam IOPS (jumlah operasi I / O per detik). Menggunakan virtualisasi memungkinkan Anda untuk secara fleksibel menggunakan sumber daya perangkat keras yang ada dan menjamin tingkat kinerja yang diperlukan. Untuk bagian kami, kami siap memberikan sumber daya dengan karakteristik yang benar-benar diperlukan untuk aplikasi.
Virtualisasi penyimpanan
Dengan pengembangan sistem virtualisasi, perlu untuk menemukan solusi inovatif untuk menyimpan dan mengakses data, sambil memastikan toleransi kesalahan. Ini adalah titik awal untuk membuat SDS (Software-Defined Storage). Untuk memenuhi kebutuhan bisnis, repositori ini dirancang dengan pemisahan perangkat lunak dan perangkat keras.
Arsitektur SDS secara fundamental berbeda dari tradisional. Logika penyimpanan telah diabstraksikan di tingkat perangkat lunak. Organisasi penyimpanan menjadi lebih mudah karena penyatuan dan virtualisasi masing-masing komponen sistem tersebut.
Apa faktor utama yang menghambat implementasi SDS di mana-mana? Faktor ini paling sering adalah penilaian yang salah dari kebutuhan aplikasi yang digunakan dan penilaian risiko yang salah. Untuk bisnis, pilihan solusi tergantung pada biaya implementasi, berdasarkan sumber daya yang dikonsumsi saat ini. Sedikit orang berpikir - apa yang akan terjadi ketika jumlah informasi dan kinerja yang diperlukan melebihi kemampuan arsitektur yang dipilih. Berpikir berdasarkan prinsip metodologis "seseorang tidak boleh berlipat ganda ada tanpa keharusan", lebih dikenal sebagai "pisau Occam", menentukan pilihan yang mendukung solusi tradisional.
Hanya sedikit yang memahami bahwa kebutuhan skalabilitas dan keandalan penyimpanan data lebih penting daripada yang terlihat pada pandangan pertama. Informasi adalah sumber daya, dan oleh karena itu, risiko kerugiannya harus diasuransikan. Apa yang akan terjadi ketika sistem penyimpanan tradisional turun? Anda perlu menggunakan garansi atau membeli peralatan baru. Dan jika sistem penyimpanan dihentikan atau telah mengakhiri "masa hidup" (yang disebut EOL - End-of-Life)? Ini bisa menjadi hari yang gelap bagi organisasi mana pun yang tidak dapat terus menggunakan layanannya sendiri yang sudah dikenal.
Tidak ada sistem yang tidak memiliki satu titik kegagalan. Tetapi ada sistem yang dapat dengan mudah selamat dari kegagalan satu atau lebih komponen. Baik sistem penyimpanan virtual dan tradisional diciptakan dengan mempertimbangkan fakta bahwa cepat atau lambat kegagalan akan terjadi. Itu hanya "batas kekuatan" dari sistem penyimpanan tradisional yang diletakkan dalam perangkat keras, tetapi dalam sistem penyimpanan virtual ditentukan dalam lapisan perangkat lunak.
Integrasi
Perubahan dramatis dalam infrastruktur TI selalu merupakan fenomena yang tidak diinginkan, penuh dengan downtime dan kehilangan dana. Hanya kelancaran penerapan solusi baru yang memungkinkan untuk menghindari konsekuensi negatif dan meningkatkan kinerja layanan. Itulah sebabnya Selectel merancang dan
meluncurkan cloud berbasis VMware , pemimpin yang diakui di pasar virtualisasi. Layanan yang kami buat akan memungkinkan setiap perusahaan untuk menyelesaikan seluruh jajaran tugas infrastruktur, termasuk penyimpanan data.
Kami akan memberi tahu Anda dengan tepat bagaimana kami memutuskan pilihan sistem penyimpanan, serta keuntungan apa yang diberikan pilihan ini kepada kami. Tentu saja, baik sistem penyimpanan tradisional dan SDS dipertimbangkan. Untuk memahami dengan jelas semua aspek operasi dan risiko, kami menawarkan wawasan yang lebih mendalam tentang topik tersebut.
Pada tahap desain, persyaratan berikut diberlakukan pada sistem penyimpanan:
- toleransi kesalahan;
- kinerja
- scaling
- kemampuan untuk menjamin kecepatan;
- operasi yang benar di ekosistem VMware.
Penggunaan solusi perangkat keras tradisional tidak dapat memberikan tingkat skalabilitas yang diperlukan, karena tidak mungkin untuk terus meningkatkan volume penyimpanan karena keterbatasan arsitektur. Pemesanan di tingkat seluruh pusat data juga sangat sulit. Itu sebabnya kami mengalihkan perhatian ke SDS.
Ada beberapa solusi perangkat lunak di pasar SDS yang cocok untuk kita untuk membangun cloud berdasarkan VMware vSphere. Di antara solusi ini dapat dicatat:
- Dell EMC ScaleIO;
- Datacore Hyper-konvergensi Virtual SAN;
- HPE StoreVirtual.
Solusi ini cocok untuk digunakan dengan VMware vSphere, namun, mereka tidak berintegrasi ke hypervisor dan berjalan secara terpisah. Oleh karena itu, pilihan dibuat untuk VMware vSAN. Mari kita pertimbangkan secara terperinci seperti apa arsitektur virtual dari solusi semacam itu.
Arsitektur
Gambar diambil dari dokumentasi resmiTidak seperti sistem penyimpanan tradisional, semua informasi tidak disimpan pada satu titik. Data mesin virtual tersebar secara merata di antara semua host, dan penskalaan dilakukan dengan menambahkan host atau menginstal disk drive tambahan pada mereka. Dua opsi konfigurasi didukung:
- Konfigurasi AllFlash (hanya solid state drive, baik untuk penyimpanan data dan untuk cache);
- Konfigurasi hibrid (penyimpanan magnetik dan cache keadaan padat).
Prosedur untuk menambah ruang disk tidak memerlukan pengaturan tambahan, misalnya, membuat LUN (Nomor Unit Logis, nomor disk logis) dan mengatur akses ke sana. Segera setelah host ditambahkan ke cluster, ruang disknya menjadi tersedia untuk semua mesin virtual. Pendekatan ini memiliki beberapa keunggulan signifikan:
- kurangnya ikatan dengan produsen peralatan;
- peningkatan toleransi kesalahan;
- memastikan integritas data jika terjadi kegagalan;
- pusat kendali tunggal dari konsol vSphere;
- penskalaan horizontal dan vertikal yang nyaman.
Namun, arsitektur ini menempatkan permintaan tinggi pada infrastruktur jaringan. Untuk memastikan throughput maksimum, di cloud kami jaringan dibangun di atas model Spine-Leaf.
Jaringan
Model jaringan tiga-tier tradisional (inti / agregasi / akses) memiliki sejumlah kelemahan signifikan. Contoh yang mencolok adalah keterbatasan protokol Spanning-Tree.
Model Spine-Leaf hanya menggunakan dua level, yang memberikan keuntungan sebagai berikut:
- jarak antar perangkat yang dapat diprediksi;
- lalu lintas berjalan di sepanjang rute terbaik;
- kemudahan penskalaan;
- Pengecualian pembatasan protokol L2.
Fitur utama dari arsitektur semacam itu adalah bahwa arsitektur ini dioptimalkan untuk lalu lintas "horisontal". Paket data hanya melewati satu hop, yang memungkinkan estimasi penundaan yang jelas.
Koneksi fisik disediakan menggunakan beberapa tautan 10GbE per server, bandwidth yang digabungkan menggunakan protokol agregasi. Dengan demikian, setiap host fisik menerima akses kecepatan tinggi ke semua objek penyimpanan.
Pertukaran data diimplementasikan menggunakan protokol kepemilikan yang dibuat oleh VMware, yang memungkinkan operasi jaringan penyimpanan yang cepat dan andal pada Ethernet-transport (mulai 10GbE dan lebih tinggi).
Transisi ke model objek penyimpanan data memungkinkan penyesuaian fleksibel penggunaan penyimpanan sesuai dengan persyaratan pelanggan. Semua data disimpan dalam bentuk objek yang didistribusikan dengan cara tertentu di antara host cluster. Kami mengklarifikasi nilai beberapa parameter yang dapat dikontrol.
Toleransi kesalahan
- FTT (Kegagalan Bertoleransi). Mengindikasikan jumlah kegagalan host yang dapat ditangani oleh cluster tanpa mengganggu operasi reguler.
- FTM (Metode Toleransi Kegagalan). Metode memastikan toleransi kesalahan pada tingkat disk.
a. Mirroring
Gambar diambil dari blog VMware.
Merupakan duplikasi lengkap dari suatu objek, dan replika selalu terletak pada host fisik yang berbeda. Analog terdekat dengan metode ini adalah RAID-1. Penggunaannya memungkinkan cluster untuk secara rutin memproses hingga tiga kegagalan komponen apa pun (disk, host, kehilangan jaringan, dll.). Parameter ini dikonfigurasi dengan mengatur opsi FTT.
Secara default, opsi ini memiliki nilai 1, dan 1 replika dibuat untuk objek (hanya 2 instance pada host yang berbeda). Saat nilainya meningkat, jumlah salinan akan menjadi N +1. Jadi, dengan nilai maksimum FTT = 3, 4 instance objek akan berada pada host yang berbeda.
Metode ini memungkinkan Anda untuk mencapai kinerja maksimum dengan mengorbankan efisiensi ruang disk. Ini dapat digunakan dalam konfigurasi hybrid dan AllFlash.
b. Erasure Coding (analog dari RAID 5/6).
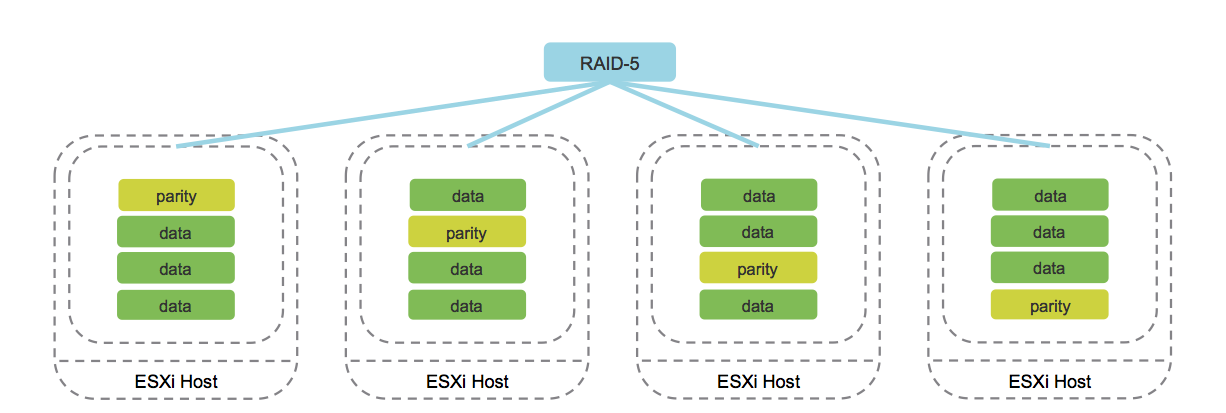
Gambar diambil dari blog cormachogan.com.
Pekerjaan metode ini didukung secara eksklusif pada konfigurasi AllFlash. Dalam proses merekam setiap objek, blok paritas yang sesuai dihitung, yang memungkinkan pemulihan data secara unik jika terjadi kegagalan. Pendekatan ini secara signifikan menghemat ruang disk dibandingkan dengan Mirroring.
Tentu saja, pengoperasian metode ini meningkatkan overhead, yang dinyatakan dalam penurunan produktivitas. Namun demikian, mengingat kinerja konfigurasi AllFlash, kelemahan ini diratakan, menjadikan penggunaan Erasure Coding sebagai opsi yang dapat diterima untuk sebagian besar tugas.
Selain itu, VMware vSAN memperkenalkan konsep "domain kegagalan", yang merupakan pengelompokan logis dari rak server atau keranjang disk. Segera setelah elemen yang diperlukan dikelompokkan, ini mengarah ke distribusi data di antara node yang berbeda dengan mempertimbangkan domain kegagalan. Ini memungkinkan kluster untuk bertahan dari kehilangan seluruh domain, karena semua replika objek yang sesuai akan ditempatkan pada host lain di domain kegagalan yang berbeda.
Domain kegagalan terkecil adalah grup disk, yang merupakan disk drive yang terhubung secara logis. Setiap grup disk berisi dua jenis media - cache dan kapasitas. Sebagai media cache, sistem memungkinkan hanya menggunakan disk solid-state, dan baik disk magnetik maupun solid-state dapat bertindak sebagai pembawa kapasitas. Media cache membantu mempercepat disk magnetik dan mengurangi latensi saat mengakses data.
Implementasi
Mari kita bicara tentang batasan apa yang ada dalam arsitektur VMware vSAN dan mengapa mereka diperlukan. Terlepas dari platform perangkat keras yang digunakan, arsitektur menyediakan batasan berikut:
- tidak lebih dari 5 grup disk per host;
- tidak lebih dari 7 pembawa kapasitas dalam grup disk;
- tidak lebih dari 1 cache-carrier dalam grup disk;
- tidak lebih dari 35 operator kapasitas per host;
- tidak lebih dari 9000 komponen per host (termasuk komponen saksi);
- tidak lebih dari 64 host di sebuah cluster;
- tidak lebih dari 1 vSAN-datastore per cluster.
Mengapa ini dibutuhkan? Sampai batas yang ditentukan terlampaui, sistem akan beroperasi dengan kapasitas yang dinyatakan, menjaga keseimbangan antara kinerja dan kapasitas penyimpanan. Ini memungkinkan Anda untuk menjamin operasi yang benar dari seluruh sistem penyimpanan virtual secara keseluruhan.
Selain keterbatasan ini, satu fitur penting harus diingat. Tidak disarankan untuk mengisi lebih dari 70% dari total volume penyimpanan. Faktanya adalah ketika 80% tercapai, mekanisme penyeimbangan dimulai secara otomatis, dan sistem penyimpanan mulai mendistribusikan kembali data di semua host cluster. Prosedur ini sangat intensif sumber daya dan dapat secara serius mempengaruhi kinerja subsistem disk.
Untuk memenuhi kebutuhan berbagai pelanggan, kami telah menerapkan tiga kumpulan penyimpanan untuk kemudahan penggunaan dalam berbagai skenario. Mari kita lihat masing-masing secara berurutan.
Kolam disk cepat
Prioritas untuk membuat kumpulan ini adalah untuk mendapatkan penyimpanan yang akan memberikan kinerja maksimum untuk hosting sistem yang sangat dimuat. Server dari kumpulan ini menggunakan sepasang Intel P4600 sebagai cache dan 10 Intel P3520 untuk penyimpanan data. Cache di kumpulan ini digunakan agar data dibaca langsung dari media, dan operasi penulisan terjadi melalui cache.
Untuk meningkatkan kapasitas yang berguna dan memastikan toleransi kesalahan, model penyimpanan data yang disebut Erasure Coding digunakan. Model ini mirip dengan array RAID 5/6 biasa, tetapi pada tingkat penyimpanan objek. Untuk menghilangkan kemungkinan korupsi data, vSAN menggunakan mekanisme perhitungan checksum untuk setiap blok data 4K.
Validasi dilakukan di latar belakang selama operasi baca / tulis, serta untuk data "dingin", akses yang tidak diminta selama tahun itu. Ketika checksum mismatch terdeteksi, dan karenanya korupsi data terdeteksi, vSAN akan secara otomatis memulihkan file dengan menimpa.
Drive pool hybrid
Dalam hal kumpulan ini, tugas utamanya adalah menyediakan sejumlah besar data, sambil memastikan tingkat toleransi kesalahan yang baik. Untuk banyak tugas, kecepatan akses data bukanlah prioritas, volume dan biaya penyimpanan jauh lebih penting. Menggunakan solid-state drive karena penyimpanan seperti itu akan sangat mahal.
Faktor ini adalah alasan untuk penciptaan kumpulan, yang merupakan hibrida dari caching solid-state drive (seperti di kumpulan lain itu adalah Intel P4600) dan hard drive tingkat perusahaan yang dikembangkan oleh HGST. Alur kerja hybrid mempercepat akses ke data yang sering diminta dengan caching operasi baca dan tulis.
Pada tingkat logis, data dicerminkan untuk menghilangkan kerugian jika terjadi kegagalan perangkat keras. Setiap objek dibagi menjadi komponen yang identik dan sistem mendistribusikannya ke host yang berbeda.
Pool with Disaster Recovery

Tugas utama dari pool adalah untuk mencapai tingkat toleransi kesalahan dan kinerja maksimum. Penggunaan teknologi
Stretched vSAN memungkinkan kami untuk
mendistribusikan penyimpanan antara pusat data Tsvetochnaya-2 di St. Petersburg dan Dubrovka-3 di Wilayah Leningrad. Setiap server di kumpulan ini dilengkapi dengan sepasang drive Intel P4600 yang luas dan berkecepatan tinggi untuk operasi cache dan 6 drive Intel P3520 untuk penyimpanan data. Pada level logis, ini adalah 2 grup disk per host.
Konfigurasi AllFlash tidak memiliki kelemahan serius - penurunan tajam pada IOPS dan peningkatan antrian permintaan disk dengan peningkatan volume akses acak ke data. Sama seperti di kumpulan dengan disk cepat, operasi tulis melalui cache, dan membaca dilakukan secara langsung.
Sekarang tentang perbedaan utama dari sisa kolam. Data dari setiap mesin virtual dicerminkan di dalam satu pusat data dan pada saat yang sama secara bersamaan direplikasi ke pusat data lain milik kami. Dengan demikian, bahkan kecelakaan serius, seperti gangguan konektivitas penuh antara pusat data, tidak akan menjadi masalah. Bahkan hilangnya pusat data sama sekali tidak akan memengaruhi data.
Kecelakaan dengan kegagalan total situs - situasinya cukup langka, tetapi vSAN dapat bertahan dengan kehormatan tanpa kehilangan data. Para tamu di acara
SelectelTechDay 2018 kami dapat melihat sendiri bagaimana cluster Stretched vSAN mengalami kegagalan situs total. Mesin virtual tersedia hanya satu menit setelah semua server di salah satu situs dimatikan dengan listrik. Semua mekanisme bekerja persis seperti yang direncanakan, tetapi data tetap tidak tersentuh.
Pengabaian arsitektur penyimpanan yang sudah dikenal membutuhkan banyak perubahan. Salah satu perubahan ini adalah munculnya "entitas" virtual baru, yang mencakup alat saksi. Arti dari solusi ini adalah untuk melacak proses merekam replika data dan menentukan mana yang relevan. Pada saat yang sama, data itu sendiri tidak disimpan pada komponen saksi, hanya metadata tentang proses perekaman.
Mekanisme ini berlaku jika terjadi kecelakaan ketika terjadi kegagalan selama proses replikasi, yang mengakibatkan replika tidak sinkron.
Untuk menentukan mana yang berisi informasi yang relevan, digunakan mekanisme penentuan kuorum. Setiap komponen memiliki "hak suara" dan diberikan sejumlah suara (1 atau lebih). "Hak suara" yang sama memiliki komponen saksi yang memainkan peran arbiter jika terjadi situasi kontroversial.
Kuorum tercapai hanya ketika replika lengkap tersedia untuk suatu objek dan jumlah "suara" saat ini lebih dari 50%.
Kesimpulan
Pilihan VMware vSAN sebagai sistem penyimpanan telah menjadi keputusan penting bagi kami. Opsi ini lulus pengujian stres dan pengujian toleransi kesalahan sebelum dimasukkan dalam proyek cloud berbasis VMware kami.
Menurut hasil pengujian, menjadi jelas bahwa fungsionalitas yang dideklarasikan berfungsi seperti yang diharapkan dan memenuhi semua persyaratan infrastruktur cloud kami.
Punya sesuatu untuk diceritakan berdasarkan pengalaman Anda sendiri dengan vSAN? Selamat datang di komentar.