Beberapa bulan yang lalu, versi pertama Kepler.gl dirilis - alat Open Source baru untuk memvisualisasikan dan menganalisis set besar geo-data.
Pada artikel ini, saya sarankan Anda berkenalan dengan fitur-fitur utama aplikasi dan membuatnya menggunakan dua visualisasi kartografi yang memungkinkan kami menemukan beberapa fakta menarik tentang parkir berbayar di Moskow.
Tetapi pertama-tama, beberapa kata tentang siapa dan mengapa menciptakan Kepler.gl
Awalnya, Kepler.Gl diciptakan oleh tim Teknik Uber untuk analis perusahaan yang ingin lebih memahami "bagaimana kota bergerak", menggunakan data lalu lintas geo-informasi dalam jumlah besar yang dikumpulkan setiap hari oleh ribuan "uber" di berbagai kota di seluruh dunia.
Namun, pada bulan Mei tahun ini, perusahaan mengumumkan akses terbuka ke aplikasi ini dan memposting semua kode sumber Kepler.gl di GitHub
Fitur utama Kepler.gl
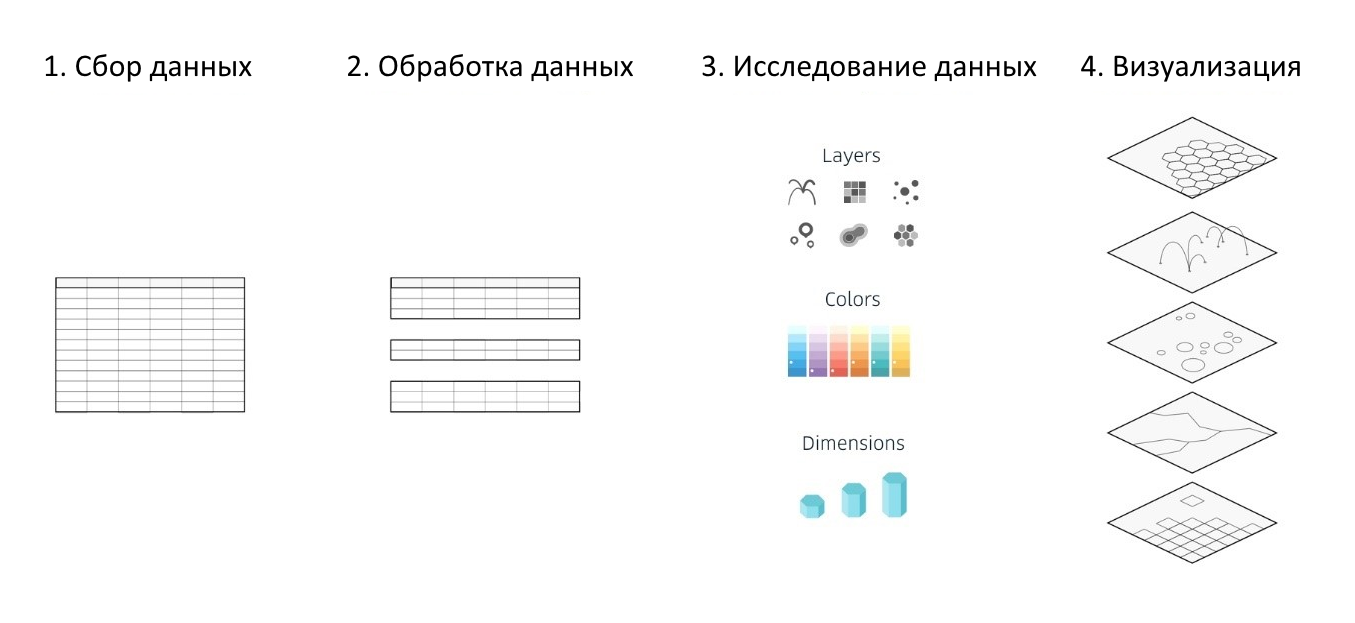
Terlepas dari alat analisis data yang dipilih, layanan peta atau kerangka kerja yang digunakan, serta perpustakaan untuk membuat berbagai visualisasi, proses mengerjakannya dikurangi menjadi 4 tahap utama:
- pengumpulan informasi
- pemrosesan data
- penelitian dan analisis data yang disiapkan (untuk mengidentifikasi dependensi, mencari anomali, dll.)
- penciptaan visualisasi
 Gambar 1. Tahapan dasar menciptakan visualisasi
Gambar 1. Tahapan dasar menciptakan visualisasiKepler.gl mengotomatisasi sebagian dan menyederhanakan 3 dari 4 langkah yang terdaftar, yang secara signifikan menyederhanakan seluruh proses analisis dan visualisasi set data besar dan membantu menciptakan peta interaktif yang informatif, dan yang paling penting, berwarna-warni berdasarkan set geo-data Anda hanya dalam waktu setengah jam.
Pada saat yang sama, pengalaman pemrograman atau desain sama sekali tidak diperlukan, karena pemfilteran dan agregasi data, memilih cara untuk menampilkan data tergantung pada berbagai parameter objek yang sedang dipelajari, overlay informasi dari berbagai sumber, beralih antara mode 2D dan 3D, dan banyak lagi yang dikonfigurasi menggunakan panel UI.
Cara menggunakan Kepler.gl untuk analisis data
Cara termudah adalah memulai kenalan Anda dengan Kepler.gl menggunakan versi online-nya, tersedia di
kepler.gl atau, jika Anda tidak mempercayai server pihak ketiga, Anda dapat menggunakan versi lokal untuk diri Anda sendiri, mengikuti instruksi di
GitHub .
Selanjutnya, saya akan menggunakan data tentang "Parkir berbayar di Moskow" yang disediakan oleh "Open Data Portal" dari pemerintah Moskow. Set ini berisi informasi tentang lebih dari 9 ribu objek yang terletak di jaringan jalan, termasuk informasi tentang biaya dan jumlah tempat parkir.
Tahap 1. Pemuatan data
Hingga saat ini, Kepler.gl mendukung 3 format data sumber: geojson, json dan csv. Setelah menyimpan data dalam salah satu format yang ditunjukkan (dalam contoh ini saya menggunakan .csv), kami cukup memuatnya ke dalam aplikasi. Ngomong-ngomong, di sini, di dialog unduhan, untuk membiasakan diri dengan aplikasi ini, Anda juga dapat menggunakan salah satu dari puluhan set data uji yang telah ditentukan.
Catatan Untuk Chrome, ukuran file unggahan maksimum tidak boleh melebihi 250Mb. Pembuat Kepler.gl menyarankan untuk menggunakan Safari jika Anda perlu mengunduh file yang lebih besar. Namun, dalam hal apa pun, Anda harus ingat bahwa kinerja aplikasi tergantung pada perangkat yang menjalankannya. Lagi pula, semua manipulasi yang terkait dengan agregasi, pemfilteran dan menampilkan data terjadi pada klien.
Tahap 2. Menampilkan data pada peta
Aplikasi ini mendukung 9 jenis lapisan visualisasi (lapisan visualisasi data), yang berbeda satu sama lain dalam satu set parameter yang dapat disesuaikan:
- lapisan titik
- lapisan busur (Arc)
- lapisan garis (Line)
- kisi (kisi)
- kotak heksagonal (Hexbin)
- lapisan poligon (Poligon)
- lapisan cluster (Claster)
- layer icon (Ikon)
- heatmap (Heatmap)
Selain itu, bahkan lapisan dari jenis yang sama, menampilkan kumpulan data yang sama, dapat berbeda secara dramatis tergantung pada konfigurasi yang dipilih.

Gambar 2. Peta dibuat di kepler.gl menggunakan berbagai jenis lapisan
Kepler.gl tidak membatasi jumlah lapisan yang digunakan saat menampilkan set data uji. Lapisan digambar di peta dalam urutan yang sama di mana mereka berada di daftar lapisan di panel samping. Urutan ini dapat dengan mudah diubah dengan hanya menyeret lapisan terkait relatif satu sama lain pada tab Layers.
Saat menggunakan banyak lapisan, perhatikan parameter "Layer Blending", yang bertanggung jawab atas bagaimana lapisan-lapisan tersebut tumpang tindih. Ini seragam di seluruh visualisasi, yang membuatnya tidak mungkin untuk menggunakan berbagai jenis pencampuran untuk lapisan yang berbeda.
Saat ini, tiga nilai untuk parameter ini tersedia:
- Normal
Dalam hal ini, lapisan bawah tidak mempengaruhi warna titik (atau elemen lain) dari lapisan atas.
- Aditif
Dengan jenis overlay ini, nilai warna dari elemen yang cocok bertambah. Lebih mudah untuk mengidentifikasi area dengan kepadatan tinggi, yang dalam hal ini akan lebih cerah. - Subtraktif
Tidak seperti aditif, ia tidak menambahkan, tetapi mengurangi arti warna di area berpotongan. Lebih mudah saat menggunakan bukan kartu gelap, tetapi kartu terang.
Jadi, untuk melihat data kami di peta, perlu untuk membuat setidaknya satu lapisan menggunakannya. Perlu dicatat bahwa setelah mengunduh file, Kepler.gl akan mencoba mengidentifikasi bidang yang berisi informasi geolokasi dan menampilkannya secara instan, secara otomatis membuat lapisan dari tipe yang sesuai (biasanya titik atau poligon).
Namun, dalam kasus kami, karena perbedaan dalam format data yang diharapkan dan digunakan, Anda harus menentukan sendiri sumber koordinat. Untuk melakukan ini, pertama-tama hapus layer poligon yang dibuat oleh Kepler.gl, dan kemudian secara manual tambahkan layer tipe Point baru. Sebagai sumber koordinat, kami menggunakan bidang Latitude_WGS84 dan Longitude_WGS84 alih-alih bidang Koordinat yang dipilih secara otomatis oleh aplikasi untuk merender data di peta.
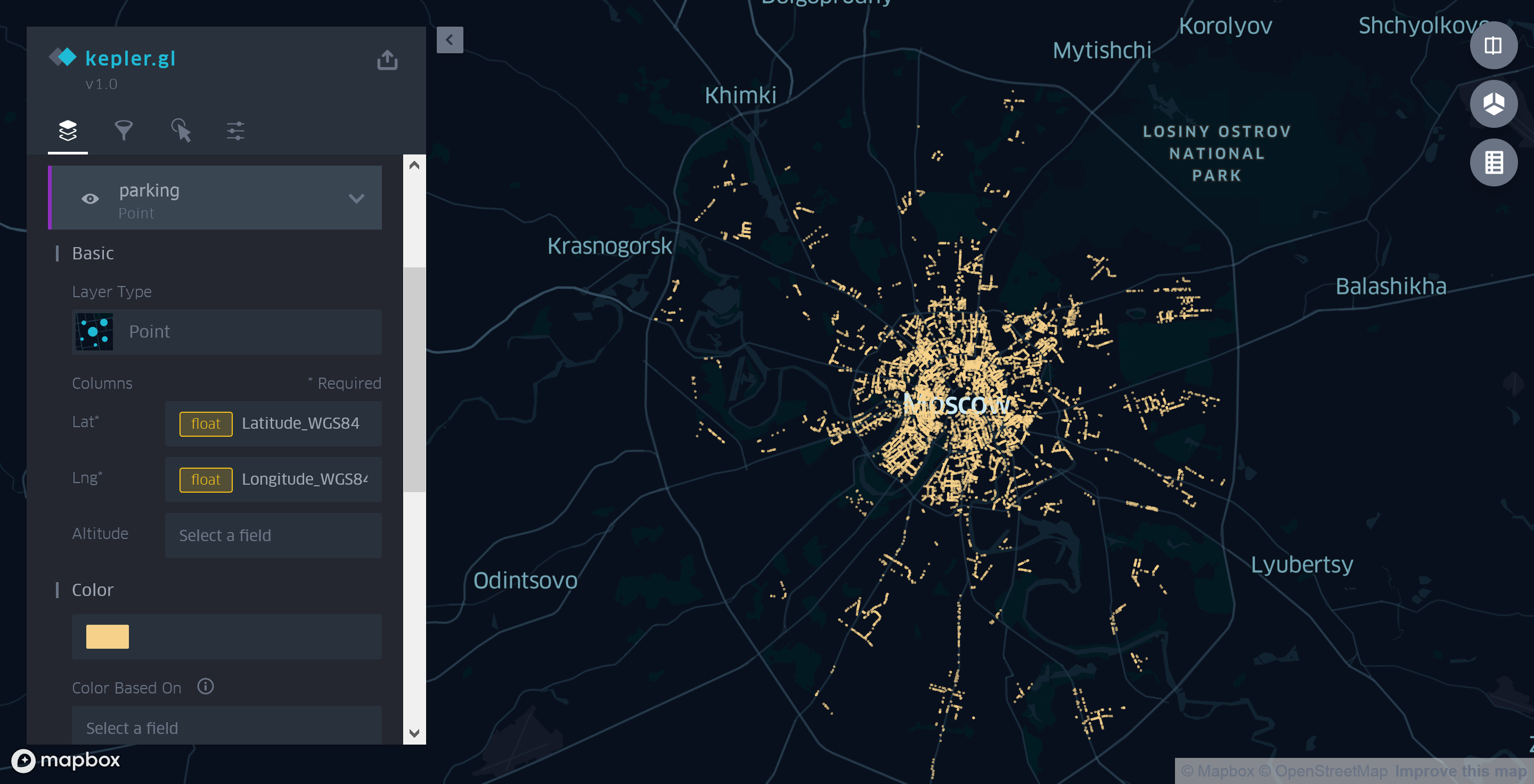
Gambar 3. Menggunakan layer spot Kepler.gl untuk menampilkan tempat parkir Moskow
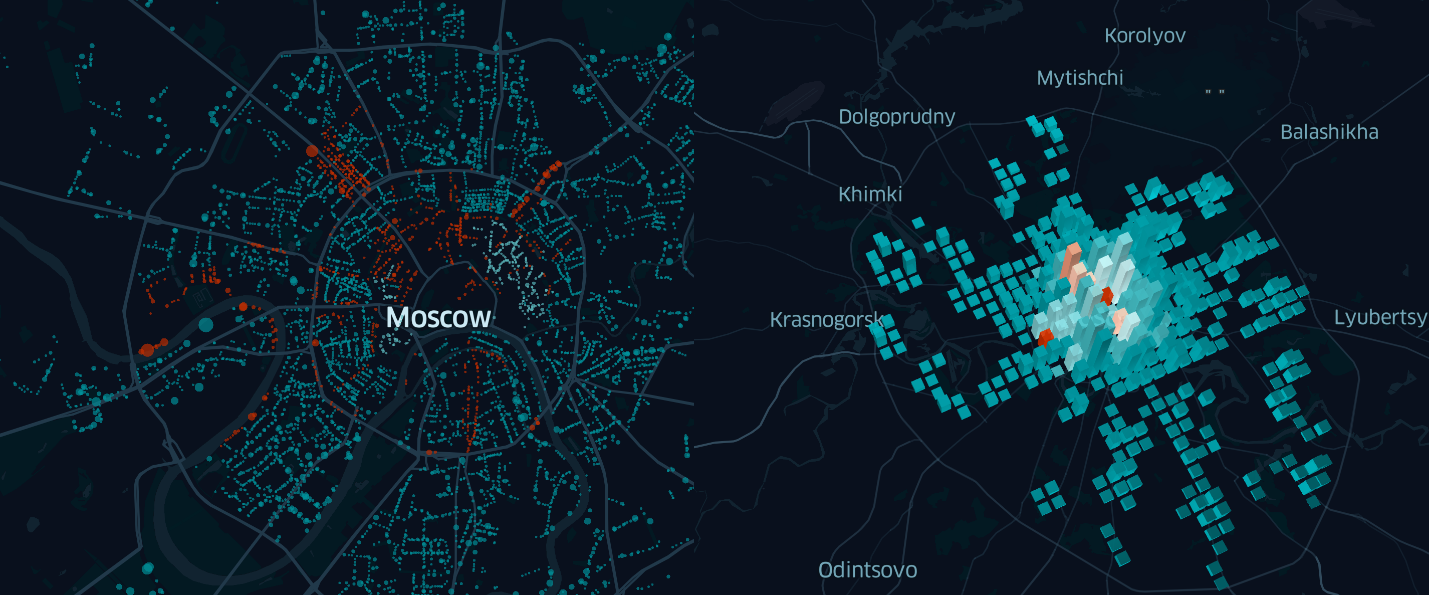
Dalam perwujudan ini, kartu tidak sangat informatif. Satu-satunya hal yang bisa dikatakan, menatapnya, adalah bahwa ada lebih banyak tempat parkir di tengah daripada di pinggiran kota.
Jadi, saatnya menggunakan informasi lain tentang objek yang diteliti untuk analisis yang lebih terperinci dan mencari fakta dan / atau pola yang menarik.
Tahap 3. Modifikasi penampilan peta berdasarkan data terkait pada objek yang ditampilkan
Set yang diunduh dari Open Data Portal berisi banyak informasi tentang masing-masing tempat parkir, namun, dua parameter bagi saya tampak paling menarik - biaya parkir satu jam dan jumlah ruang yang tersedia.
Di mana tempat parkir paling mahal di Moskow? Apakah ada hubungan antara ukuran tempat parkir dan jaraknya dari sen? Berapa perbedaan biaya parkir satu jam di dalam dan di luar Garden Ring? Untuk menjawab pertanyaan-pertanyaan ini, cukup bagi kami untuk sedikit mengubah pengaturan tampilan dari layer titik yang dibuat sebelumnya dan kembali melihat peta.
Pertama, ubah warna titik-titik tergantung pada biaya satu jam parkir di tempat ini. Untuk melakukan ini, dalam daftar turun bawah “Warna berdasarkan”, sebagai dasar untuk memilih warna, kami menunjukkan parameter “Harga” dari kumpulan data asli.

Gambar 4. Menggunakan warna untuk menampilkan informasi biaya jam parkir
Sudah pada tahap ini, beberapa pengamatan menarik dapat dilakukan. Misalnya, bahwa tidak seluruh pusat sama mahal untuk pengendara, tetapi di Tverskaya lebih baik menjadi pejalan kaki
Sekarang mari kita lihat kapasitas tempat parkir. Untuk ini, kita akan menggunakan bidang "CarCapacity" sebagai parameter dasar untuk menentukan jari-jari suatu titik (atribut "Radius Based On" pada lapisan titik). Tetapkan rentang radius dari 0 hingga 30px.

Gambar 5. Kustomisasi ukuran titik tergantung pada jumlah ruang parkir
Dengan demikian, hanya dalam beberapa menit, peta parkir kami menjadi lebih informatif. Sekarang bahkan dengan melihat sekilas memungkinkan tidak hanya untuk membandingkan kebijakan harga berbagai wilayah kota, tetapi juga untuk secara kasar mengevaluasi peluang Anda menemukan ruang bebas yang diberikan tidak hanya jumlah tempat parkir di sekitarnya, tetapi juga kelapangannya.
Tahap 4. Menggabungkan data dengan Kepler.gl
Menggunakan layer titik untuk menampilkan masing-masing lebih dari 9000 tempat parkir telah memungkinkan kami melakukan beberapa pengamatan menarik, tetapi peta tidak memungkinkan kami untuk dengan mudah menjawab pertanyaan seperti "Di mana tempat parkir paling luas per unit area?". Untuk menjawabnya, kita perlu menggunakan salah satu lapisan agregasi.
Saat ini, Kepler.Gl mendukung 4 jenis lapisan tersebut: kisi (Kisi), kisi heksagonal (Heksbin), peta panas (Peta Panas) dan kluster (Cluster). Dua tipe terakhir (Cluster dan Heatmap) nyaman ketika Anda perlu menggabungkan data hanya dengan satu parameter. Kisi dan kisi heksagonal memungkinkan menganalisis nilai teragregasi oleh beberapa parameter secara bersamaan.
Untuk menjawab pertanyaan yang diajukan sebelumnya, kami akan mengubah jenis lapisan titik yang sebelumnya kami buat menjadi "kisi" (Kisi), ini tidak hanya akan mengevaluasi jumlah total ruang parkir per unit area, tetapi juga menyimpan informasi tentang biaya rata-rata satu jam parkir di tempat ini.
Atur ukuran kisi ke 1km2 (minimum tersedia di Kepler.gl). Nilai parameter Cakupan berkurang dari 1 hingga 0,7 sehingga ruang kecil muncul di antara sel, yang meningkatkan keterbacaan peta akhir.
Catatan Daftar opsi yang tersedia untuk kustomisasi bervariasi tergantung pada jenis lapisan yang dipilih. Anda dapat menemukan detail lebih lanjut tentang atribut yang didukung oleh masing-masing atribut tersebut dalam dokumentasi resmi Kepler.gl.
Warna setiap sel dalam visualisasi baru, seperti sebelumnya, akan tergantung pada biaya satu jam parkir. Namun, sekarang, selain nama bidang dalam kumpulan data yang digunakan, kami juga perlu menunjukkan bagaimana Kepler.gl akan menggabungkan informasi ini. Metode agregasi tergantung pada jenis bidang yang dipilih. Dalam kasus kami, "Harga" adalah tipe numerik (int) dan aplikasi menawarkan salah satu dari 5 opsi:
- nilai tertinggi (minimum)
- nilai terkecil (maksimum)
- jumlah (jumlah)
- nilai rata-rata (rata-rata)
- median
Ketinggian setiap kolom kisi akan mencerminkan jumlah total tempat parkir di area ini. Untuk melakukan ini, buka mode 3D untuk melihat peta. Kemudian, pada tab "Layers" pada panel samping , pilih "Enable height" untuk lapisan agregasi kami, dan pilih bidang "CarCapacity" sebagai parameter dasar.
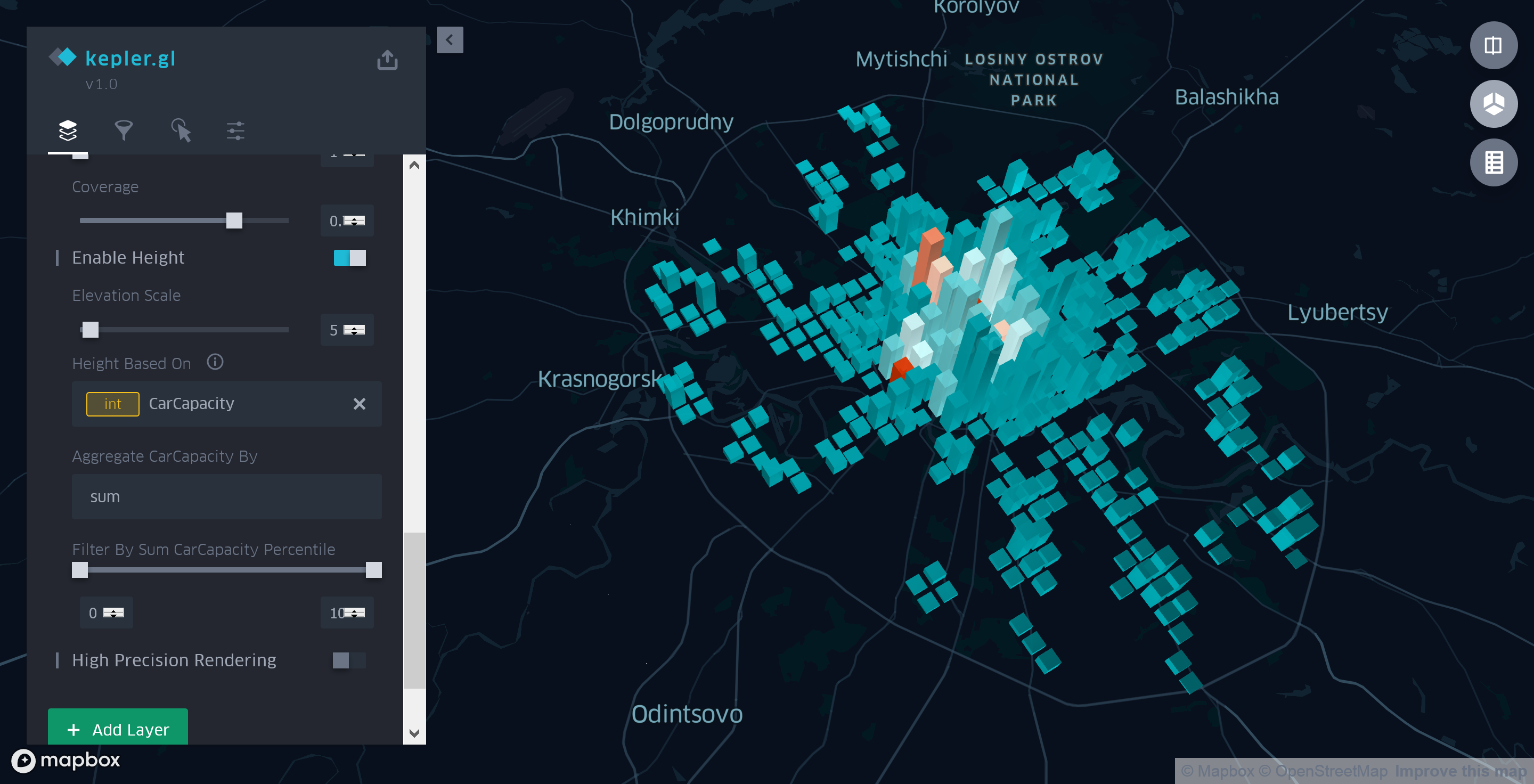
Gambar 6. Informasi umum tentang biaya dan kapasitas parkir
Dengan demikian, setelah menghabiskan beberapa menit lagi untuk menyiapkan lapisan agregasi, kita dapat dengan yakin mengatakan bahwa di dalam Garden Ring tidak hanya jumlah tempat parkir, tetapi juga jumlah ruang parkir sebenarnya jauh lebih besar daripada di luar.
Kesimpulan
Dalam artikel ini, menggunakan contoh spesifik, hanya sebagian dari kemampuan Kepler.gl yang dianggap sebagai alat modern untuk visualisasi dan analisis dasar dari berbagai data geografis. Jika Anda tertarik dengan aplikasi ini, saya sarankan Anda juga membiasakan diri dengan artikel dan tutorial di bawah ini, serta bereksperimen dengan penyaringan data sendiri, mengkonfigurasi tooltips dan gaya peta, dan fitur lain dari aplikasi ini.
Dan di artikel selanjutnya saya akan memberi tahu Anda tentang cara untuk berbagi visualisasi dan peta yang Anda buat, serta tentang penggunaan Kepler.gl sebagai komponen Bereaksi untuk aplikasi web Anda.
Tautan yang bermanfaat