 Bagi saya, itu dimulai enam setengah tahun yang lalu, ketika, dengan kehendak takdir, saya ditarik ke dalam satu proyek tertutup. Proyek siapa - jangan tanya, saya tidak akan memberi tahu. Saya hanya bisa mengatakan bahwa idenya sederhana seperti menyapu: menanamkan front-end dentang dalam IDE. Yah, seperti yang baru-baru ini dilakukan di QtCreator, di CLion (dalam arti tertentu), dll. Dentang waktu itu adalah bintang yang sedang naik daun, banyak yang berjalan lamban di sekitar kemungkinan akhirnya menggunakan parser C ++ yang lengkap hampir gratis. Dan idenya, bisa dikatakan, secara harfiah ada di udara (dan autocomplet dari kode yang dibangun ke dalam dentang API adalah seperti yang disiratkan oleh Be), Anda hanya harus mengambil dan melakukannya. Tapi, seperti yang dikatakan Boromir, "Kamu tidak bisa menerimanya, dan ...". Jadi itu terjadi dalam kasus ini. Untuk detail - Selamat datang di bawah kucing.
Bagi saya, itu dimulai enam setengah tahun yang lalu, ketika, dengan kehendak takdir, saya ditarik ke dalam satu proyek tertutup. Proyek siapa - jangan tanya, saya tidak akan memberi tahu. Saya hanya bisa mengatakan bahwa idenya sederhana seperti menyapu: menanamkan front-end dentang dalam IDE. Yah, seperti yang baru-baru ini dilakukan di QtCreator, di CLion (dalam arti tertentu), dll. Dentang waktu itu adalah bintang yang sedang naik daun, banyak yang berjalan lamban di sekitar kemungkinan akhirnya menggunakan parser C ++ yang lengkap hampir gratis. Dan idenya, bisa dikatakan, secara harfiah ada di udara (dan autocomplet dari kode yang dibangun ke dalam dentang API adalah seperti yang disiratkan oleh Be), Anda hanya harus mengambil dan melakukannya. Tapi, seperti yang dikatakan Boromir, "Kamu tidak bisa menerimanya, dan ...". Jadi itu terjadi dalam kasus ini. Untuk detail - Selamat datang di bawah kucing.
Pertama tentang yang baik
Manfaat menggunakan dentang sebagai parser bawaan di IDE C ++, tentu saja, adalah. Pada akhirnya, fungsi IDE tidak terbatas hanya untuk mengedit file. Ini adalah basis data karakter, dan tugas navigasi, dan dependensi, dan banyak lagi. Dan di sini kompiler lengkap mengarahkan setinggi-tingginya, karena untuk mengalahkan semua kekuatan preprosesor dan templat dalam parser yang ditulis sendiri yang relatif sederhana adalah tugas yang tidak sepele. Karena Anda biasanya harus membuat banyak kompromi, yang jelas mempengaruhi kualitas parsing kode. Siapa yang peduli - dapat melihat, katakan, pada parser bawaan QtCeator di sini: Qt Creator C ++ parser
Di tempat yang sama, dalam kode sumber QtCreator, Anda dapat melihat bahwa di atas tidak semua yang diperlukan oleh IDE dari parser. Selain itu, Anda membutuhkan setidaknya:
- penyorotan sintaksis (leksikal dan semantik)
- segala macam petunjuk "on the fly" dengan tampilan informasi pada simbol
- petunjuk tentang apa yang salah dengan kode dan cara memperbaikinya / menambahnya
- Penyelesaian Kode dalam berbagai konteks
- refactoring paling beragam
Oleh karena itu, pada manfaat yang tercantum sebelumnya (benar-benar serius!), Nilai plus berakhir dan rasa sakit dimulai. Untuk lebih memahami rasa sakit ini, pertama-tama Anda dapat melihat laporan oleh Anastasia Kazakova ( anastasiak2512 ) tentang apa yang sebenarnya diperlukan dari parser kode yang ada di dalam IDE:
Inti dari masalah
Tapi itu sederhana, meskipun mungkin tidak jelas pada pandangan pertama. Singkatnya, maka: dentang adalah kompiler . Dan merujuk pada kode sebagai kompiler . Dan dipertajam oleh fakta bahwa kode yang diberikan kepadanya sudah selesai, dan bukan tulisan rintisan file yang sekarang terbuka di editor IDE. Compiler tidak menyukai bit file, seperti konstruksi yang tidak lengkap, pengidentifikasi yang ditulis secara tidak benar, retrun alih-alih kembali, dan kesenangan lain yang dapat muncul di sini dan sekarang di editor. Tentu saja, sebelum dikompilasi, semua ini akan dibersihkan, diperbaiki, disatukan. Tetapi di sini dan sekarang, di dalam editor, itu adalah apa adanya. Dan dalam bentuk inilah parser yang dibangun ke dalam IDE sampai ke meja setiap 5-10 detik. Dan jika versi yang ditulis sendiri dengan sempurna "memahami" bahwa itu berurusan dengan produk setengah jadi, maka dentang - tidak. Dan sangat terkejut. Apa yang terjadi sebagai akibat kejutan seperti itu bergantung pada "pada", seperti yang mereka katakan.
Untungnya, dentang cukup toleran terhadap kesalahan kode. Namun demikian, mungkin ada kejutan - tiba-tiba menghilang lampu latar, kurva lengkapi-otomatis, diagnostik aneh. Anda harus siap untuk semua ini. Selain itu, dentang tidak omnivora. Dia berhak untuk tidak menerima apa pun di header kompiler, yang di sini dan sekarang digunakan untuk membangun proyek. Fitur intrinsik yang rumit, ekstensi non-standar, dan lainnya, um ..., semua ini dapat menyebabkan kesalahan penguraian di tempat yang paling tidak terduga. Dan, tentu saja, kinerja. Mengedit file tata bahasa di Boost.Spirit atau mengerjakan proyek berbasis llvm akan menyenangkan. Tapi, tentang semuanya lebih detail.
Kode Pracetak
Jadi, katakanlah Anda memulai proyek baru. Lingkungan Anda menghasilkan blank default untuk main.cpp, dan di dalamnya Anda menulis:
#include <iostream> int main() { foo(10) }
Kode, dari sudut pandang C ++, terus terang, tidak valid. Tidak ada definisi fungsi foo (...) dalam file, garis tidak selesai, dll. Tapi ... Anda baru saja mulai. Kode ini memiliki hak untuk jenis ini. Bagaimana kode ini memahami IDE dengan parser yang ditulis sendiri (dalam hal ini CLion)?
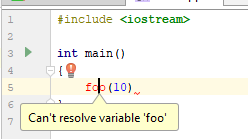
Dan jika Anda mengklik bola lampu, maka Anda dapat melihat ini:
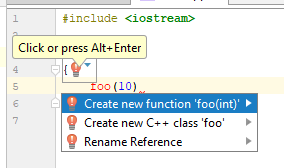
IDE semacam itu, mengetahui sesuatu, um, lebih banyak tentang apa yang terjadi, menawarkan opsi yang sangat diharapkan: untuk membuat fungsi dari konteks penggunaan. Tawaran yang bagus, saya pikir. Bagaimana IDE berbasis dentang berperilaku (dalam hal ini, Qt Creator 4.7)?
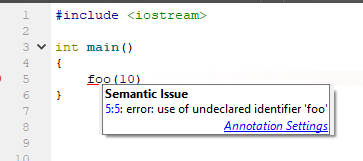
Dan apa yang diusulkan untuk memperbaiki situasi? Tapi tidak ada apa-apa! Hanya ganti nama standar!
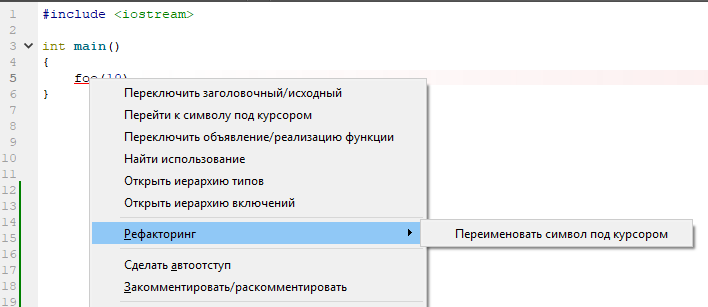
Alasan untuk perilaku ini sangat sederhana: untuk dentang, teks ini lengkap (dan tidak bisa apa pun). Dan dia membangun AST berdasarkan asumsi ini. Dan kemudian semuanya sederhana: dentang melihat pengidentifikasi yang sebelumnya tidak ditentukan. Ini adalah teks dalam C ++ (bukan dalam C). Tidak ada asumsi yang dibuat tentang sifat pengidentifikasi - tidak ditentukan, sehingga sepotong kode tidak valid. Dan di AST untuk baris ini tidak ada yang muncul. Dia tidak ada di sana. Dan apa yang tidak ada di AST tidak mungkin dianalisis. Ini memalukan, menyebalkan, oke.
Parser yang dibangun ke dalam IDE berasal dari beberapa asumsi lain. Dia tahu bahwa kode itu belum selesai. Bahwa programmer sekarang sedang sibuk berpikir dan jari-jari di belakangnya tidak punya waktu. Oleh karena itu, tidak semua pengidentifikasi dapat didefinisikan. Kode seperti itu, tentu saja, tidak benar dari sudut pandang standar kualitas kompiler yang tinggi, tetapi parser tahu apa yang dapat dilakukan dengan kode tersebut dan menawarkan opsi. Pilihan yang cukup masuk akal.
Setidaknya hingga versi 3.7 (inklusif), masalah serupa terjadi dalam kode ini:
#include <iostream> class Temp { public: int i; }; template<typename T> class Foo { public: int Bar(Temp tmp) { Tpl(tmp); } private: template<typename U> void Tpl(U val) { Foo<U> tmp(val); tmp. } int member; }; int main() { return 0; }
Di dalam metode kelas template, autocomplet berbasis dentang tidak berfungsi. Sejauh yang saya ketahui, alasannya ada pada parsing templat dua lintasan. Autocomplete di dentang dipicu pada pass pertama, ketika informasi tentang jenis yang sebenarnya digunakan mungkin tidak cukup. Di dentang 5.0 (dinilai oleh Catatan Rilis), ini diperbaiki.
Dengan satu atau lain cara, situasi di mana kompiler tidak dapat membangun AST yang benar (atau menarik kesimpulan yang benar dari konteks) dalam kode yang diedit mungkin. Dan dalam hal ini, IDE tidak akan "melihat" bagian teks yang sesuai dan tidak akan dapat membantu programmer dengan cara apa pun. Yang tentu saja tidak bagus. Kemampuan untuk bekerja secara efektif dengan kode yang salah adalah apa yang dibutuhkan parser dalam IDE, dan apa yang tidak dibutuhkan oleh kompiler biasa sama sekali. Oleh karena itu, parser dalam IDE dapat menggunakan banyak heuristik, yang bagi kompiler tidak hanya tidak berguna, tetapi juga berbahaya. Dan untuk mengimplementasikan dua mode operasi di dalamnya - yah, Anda masih perlu meyakinkan pengembang.
"Peran ini kasar!"
IDE programmer biasanya satu (well, two), tetapi ada banyak proyek dan toolchains. Dan, tentu saja, saya tidak ingin melakukan gerakan ekstra untuk beralih dari toolchain ke toolchain, dari proyek ke proyek. Satu atau dua klik, dan konfigurasi bangunan berubah dari Debug ke Rilis, dan kompiler dari MSVC ke MinGW. Tetapi parser kode dalam IDE tetap sama. Dan dia harus, bersama dengan sistem build, beralih dari satu konfigurasi ke konfigurasi lain, dari satu toolchain ke yang lain. Toolchain bisa menjadi semacam eksotis, atau salib. Dan tugas parser di sini adalah terus mengurai kode dengan benar. Jika memungkinkan dengan kesalahan minimal.
dentang cukup omnivora. Dapat dipaksa untuk menerima ekstensi kompiler dari Microsoft, kompiler gcc. Ini dapat melewati opsi dalam format kompiler ini, dan dentang bahkan akan memahaminya. Tetapi semua ini tidak menjamin bahwa dentang akan menerima tajuk dari jeroan ayam itik yang dikumpulkan dari tangki gcc. Setiap __builtin_intrinsic_xxx dapat menjadi penghalang baginya. Atau bahasa mengkonstruksi bahwa versi clang saat ini di IDE tidak mendukung. Kemungkinan besar, ini tidak akan mempengaruhi kualitas konstruksi AST untuk file yang saat ini diedit. Tetapi membangun basis karakter global atau menyimpan tajuk yang sudah dikompilasi dapat dihancurkan. Dan ini bisa menjadi masalah serius. Masalah yang sama mungkin berubah menjadi kode yang serupa tidak di header dari toolchains atau pihak ketiga, tetapi di header atau kode sumber proyek. Omong-omong, semua ini adalah alasan yang cukup signifikan untuk secara eksplisit memberi tahu sistem build (dan IDE) tentang file header mana untuk proyek Anda yang "asing". Itu bisa membuat hidup lebih mudah.
Sekali lagi, IDE awalnya dirancang untuk digunakan dengan berbagai kompiler, pengaturan, toolchains, dan banyak lagi. Dirancang untuk berurusan dengan kode, beberapa elemen yang tidak didukung. Siklus rilis IDE (tidak semua :)) lebih pendek dari pada kompiler, oleh karena itu, ada potensi untuk lebih cepat menarik fitur baru dan menanggapi masalah yang ditemukan. Dalam dunia kompiler, semuanya sedikit berbeda: siklus rilis setidaknya satu tahun, masalah kompatibilitas lintas-kompiler diselesaikan dengan kompilasi bersyarat dan diteruskan ke pundak pengembang. Kompiler tidak harus bersifat universal dan omnivora - kompleksitasnya sudah tinggi. dentang tidak terkecuali.
Perjuangan untuk kecepatan
Bagian dari waktu yang dihabiskan di IDE, ketika programmer tidak duduk di debugger, dia mengedit teks. Dan keinginan alaminya di sini adalah untuk membuatnya nyaman (jika tidak mengapa sebuah IDE? Dapatkah saya bertahan dengan notepad!) Kenyamanan, khususnya, melibatkan kecepatan reaksi editor yang tinggi terhadap perubahan teks dan menekan tombol cepat. Seperti yang dicatat Anastasia dengan benar dalam laporannya, jika lima detik setelah menekan Ctrl + Spasi lingkungan tidak merespons dengan tampilan menu atau daftar pelengkapan otomatis, ini mengerikan (serius, coba sendiri). Dalam angka, ini berarti bahwa parser yang tertanam dalam IDE memiliki sekitar satu detik untuk mengevaluasi perubahan dalam file dan membangun kembali AST, dan satu setengah atau dua untuk menawarkan pengembang pilihan yang peka konteks. Kedua Yah, mungkin dua. Selain itu, perilaku yang diharapkan adalah jika pengembang mengubah nama panggilan .h, dan kemudian beralih ke .cpp-shnik, maka perubahan yang dilakukan akan "terlihat". File-file ini, di sini, dibuka di jendela tetangga. Dan sekarang perhitungannya sederhana. Jika dentang, diluncurkan dari baris perintah, dapat mengatasi kode sumber dalam waktu sekitar sepuluh hingga dua puluh detik, lalu di mana alasan untuk percaya bahwa ketika diluncurkan dari IDE, kode itu akan mengatasi kode sumber lebih cepat dan masuk ke dalam satu atau dua detik? Artinya, itu akan bekerja urutan besarnya lebih cepat? Secara umum, ini bisa selesai, tetapi saya tidak akan.
Sekitar sepuluh hingga dua puluh detik ke sumbernya, tentu saja, saya melebih-lebihkan. Meskipun, jika beberapa API berat dimasukkan di sana atau, katakanlah, boost.spirit dengan Hana di ready, dan kemudian semua ini secara aktif digunakan dalam teks, maka 10-20 detik masih merupakan nilai yang baik. Tetapi bahkan jika AST siap beberapa detik setelah tiga atau empat setelah peluncuran parser built-in - itu sudah lama. Asalkan peluncuran tersebut harus seperti biasa (untuk mempertahankan model kode dan indeks dalam keadaan yang konsisten, sorot, cepat, dll.), Serta sesuai permintaan - penyelesaian kode juga merupakan peluncuran kompiler. Apakah mungkin untuk mengurangi waktu ini? Sayangnya, dalam hal menggunakan dentang sebagai pengurai, tidak ada banyak kemungkinan. Alasan: ini adalah alat pihak ketiga di mana ( idealnya ) perubahan tidak dapat dilakukan. Yaitu, menggali kode dentang dengan perftool, mengoptimalkan, menyederhanakan beberapa cabang - fitur ini tidak tersedia dan Anda harus melakukan dengan apa yang disediakan API eksternal (dalam kasus menggunakan libclang, itu juga cukup sempit).
Yang pertama, jelas, dan, pada kenyataannya, satu-satunya solusi adalah menggunakan header yang dikompilasi yang dihasilkan secara dinamis. Dengan implementasi yang memadai, solusinya adalah pembunuh. Meningkatkan kecepatan kompilasi setidaknya kali. Esensinya sederhana: lingkungan mengumpulkan semua header pihak ketiga (atau header di luar root proyek) ke dalam file .h tunggal, membuat pch dari file ini, dan kemudian secara implisit menyertakan pch ini di setiap sumber. Tentu saja, efek samping yang jelas muncul: dalam kode sumber ( pada tahap pengeditan ), simbol dapat dilihat yang tidak termasuk di dalamnya. Tapi ini adalah biaya untuk kecepatan. Saya harus memilih. Dan semuanya akan baik-baik saja, jika bukan karena satu masalah kecil: dentang masih kompiler. Dan, sebagai kompiler, dia tidak suka kesalahan dalam kode. Dan jika tiba-tiba (tiba-tiba! - lihat bagian sebelumnya) ada kesalahan dalam header, maka file .pch tidak dibuat. Setidaknya sampai versi 3.7. Apakah ada yang berubah dalam hal ini sejak itu? Saya tidak tahu, ada kecurigaan bahwa tidak. Sayangnya, tidak ada lagi kesempatan untuk memeriksa.
Pilihan alternatif, sayangnya, tidak tersedia untuk alasan yang sama: dentang adalah kompiler dan "dalam dirinya sendiri". Campur tangan aktif dalam proses pembuatan AST, entah bagaimana membuatnya menggabungkan AST dari bagian yang berbeda, mempertahankan basis simbol eksternal dan te dan te - sayangnya, semua fitur ini tidak tersedia. Hanya API eksternal, hanya hardcore dan pengaturan yang tersedia melalui opsi kompilasi. Dan kemudian analisis AST yang dihasilkan. Jika Anda menggunakan versi C ++ - API, maka lebih banyak peluang tersedia. Misalnya, Anda dapat bermain-main dengan FrontendActions kustom, membuat pengaturan yang lebih baik untuk opsi kompilasi, dll. Tetapi dalam kasus ini, poin utama tidak akan berubah - teks yang diedit (atau diindeks) akan dikompilasi secara independen dari yang lain dan sepenuhnya. Itu saja. Intinya.
Mungkin (mungkin!) Suatu hari akan ada garpu dentang hulu yang dirancang khusus untuk digunakan sebagai bagian dari IDE. Mungkin Tetapi untuk sekarang, semuanya seperti apa adanya. Katakanlah integrasi tim Qt Creator (ke tahap "terakhir") dengan libclang memakan waktu tujuh tahun. Saya mencoba QtC 4.7 dengan mesin berbasis libclang - Saya akui, saya pribadi suka versi lama (pada versi yang ditulis sendiri) lebih sederhana karena berfungsi lebih baik pada case saya: ia meminta dan menyoroti, dan yang lainnya. Saya tidak akan melakukan estimasi berapa jam manusia yang mereka habiskan untuk integrasi ini, tetapi saya berani menyarankan bahwa selama waktu ini akan mungkin untuk menyelesaikan parser saya sendiri. Sejauh yang saya tahu (dengan indikasi tidak langsung), tim yang bekerja pada CLion terlihat hati-hati menuju integrasi dengan libclang / clang ++. Tetapi ini semua murni asumsi pribadi. Integrasi pada tingkat Protokol Server Bahasa adalah pilihan yang menarik, tetapi khusus untuk kasus C ++, saya cenderung menganggap ini lebih sebagai paliatif karena alasan yang tercantum di atas. Ini hanya mentransfer masalah dari satu tingkat abstraksi ke tingkat lain. Tapi mungkin saya salah untuk LSP - masa depan. Ayo lihat. Tapi bagaimanapun, kehidupan pengembang IDE modern untuk C ++ penuh dengan petualangan - dengan dentang sebagai backend, atau tanpa itu.