“Tim @Cloudflare baru saja membuat perubahan yang secara signifikan meningkatkan kinerja jaringan kami, terutama untuk permintaan yang paling lambat. Seberapa cepat? Kami memperkirakan bahwa kami menghemat Internet sekitar 54 tahun per hari yang seharusnya dihabiskan menunggu situs dimuat .
” -
tweet Matthew Prince, 28 Juni 2018
10 juta situs, aplikasi, dan API menggunakan Cloudflare untuk mempercepat unduhan konten untuk pengguna. Pada puncaknya, kami memproses lebih dari 10 juta permintaan per detik di 151 pusat data. Selama bertahun-tahun, kami telah membuat banyak perubahan pada versi Nginx kami untuk mengatasi pertumbuhan. Artikel ini adalah tentang salah satu dari perubahan ini.
Cara Kerja Nginx
Nginx adalah salah satu program yang menggunakan loop pemrosesan acara untuk menyelesaikan
masalah C10K . Setiap kali acara jaringan tiba (koneksi baru, permintaan atau pemberitahuan untuk mengirim data dalam jumlah lebih besar, dll.), Nginx bangun, memproses acara, dan kemudian kembali ke pekerjaan lain (ini mungkin memproses acara lain). Ketika suatu peristiwa tiba, data untuknya sudah siap, yang memungkinkan Anda untuk memproses banyak permintaan secara simultan tanpa downtime.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
Misalnya, inilah yang tampak seperti sepotong kode untuk membaca data dari deskriptor file:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
Jika fd adalah soket jaringan, maka byte yang sudah diterima akan dikembalikan. Panggilan terakhir akan mengembalikan
EWOULDBLOCK . Ini berarti bahwa buffer baca lokal telah berakhir dan Anda seharusnya tidak lagi membaca dari soket ini sampai data muncul.
Disk I / O berbeda dari jaringan
Jika fd adalah file biasa di Linux, maka
EWOULDBLOCK dan
EAGAIN tidak pernah muncul, dan operasi baca selalu menunggu untuk membaca seluruh buffer, bahkan jika file dibuka menggunakan
O_NONBLOCK . Seperti yang tertulis dalam manual
terbuka (2) :
Harap perhatikan bahwa tanda ini tidak valid untuk file biasa dan blokir perangkat.
Dengan kata lain, kode di atas pada dasarnya dikurangi menjadi ini:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
Jika pawang perlu membaca dari disk, maka ia memblokir loop acara hingga pembacaan selesai, dan penangan event berikutnya menunggu.
Ini normal untuk sebagian besar tugas, karena membaca dari disk biasanya cukup cepat dan jauh lebih mudah diprediksi daripada menunggu paket dari jaringan. Apalagi sekarang semua orang memiliki SSD, dan semua cache kami ada di SSD. Dalam SSD modern, penundaan sangat kecil, biasanya dalam puluhan mikrodetik. Selain itu, Anda bisa menjalankan Nginx dengan beberapa alur kerja sehingga pengendali acara yang lambat tidak memblokir permintaan dalam proses lain. Sebagian besar waktu Anda dapat mengandalkan Nginx untuk memproses permintaan dengan cepat dan efisien.
Kinerja SSD: tidak selalu seperti yang dijanjikan
Seperti yang bisa Anda tebak, asumsi-asumsi indah ini tidak selalu benar. Jika setiap pembacaan selalu membutuhkan 50 μs, maka membaca 0,19 MB dalam blok 4 KB (dan kita membaca dalam blok yang lebih besar) hanya akan memakan waktu 2 ms. Tetapi tes menunjukkan bahwa waktu ke byte pertama kadang-kadang jauh lebih buruk, terutama di persentil ke-99 dan ke-999. Dengan kata lain, pembacaan paling lambat dari setiap 100 (atau 1000) bacaan seringkali membutuhkan waktu lebih lama.
Solid state drive sangat cepat, tetapi dikenal dengan kompleksitasnya. Mereka memiliki komputer di dalam antrian itu dan menyusun ulang I / O, dan juga melakukan berbagai tugas latar belakang, seperti pengumpulan sampah dan defragmentasi. Dari waktu ke waktu, permintaan melambat secara nyata. Kolega saya,
Ivan Bobrov, meluncurkan beberapa tolok ukur I / O dan mencatat penundaan baca hingga 1 detik. Selain itu, beberapa SSD kami memiliki lebih banyak lonjakan kinerja seperti itu daripada yang lain. Di masa depan kita akan mempertimbangkan indikator ini saat membeli SSD, tetapi sekarang kita perlu mengembangkan solusi untuk peralatan yang ada.
Distribusi muatan yang seragam dengan SO_REUSEPORT
Sulit untuk menghindari satu respons lambat per 1000 permintaan, tetapi yang sebenarnya tidak kita inginkan adalah memblokir 1000 permintaan yang tersisa untuk satu detik penuh. Secara konseptual, Nginx dapat memproses banyak permintaan secara paralel, tetapi hanya memulai 1 pengendali event secara bersamaan. Jadi saya menambahkan metrik khusus:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
Persentil ke-99 (p99)
event_loop_blocked melebihi 50% dari TTFB kami. Dengan kata lain, separuh waktu ketika melayani permintaan adalah hasil dari memblokir siklus pemrosesan acara oleh permintaan lain.
event_loop_blocked hanya mengukur setengah kunci (karena panggilan yang ditangguhkan ke
epoll_wait() tidak diukur), sehingga rasio aktual dari waktu yang diblokir jauh lebih tinggi.
Setiap mesin kami menjalankan Nginx dengan 15 alur kerja, mis. Satu I / O lambat akan memblokir tidak lebih dari 6% dari permintaan. Tetapi acara tidak merata: pekerja utama menerima 11% dari permintaan.
SO_REUSEPORT dapat menyelesaikan masalah distribusi yang tidak merata. Marek Maikovsky menulis sebelumnya tentang
kelemahan dari pendekatan ini dalam konteks contoh Nginx lainnya, tetapi di sini Anda terutama dapat mengabaikannya: koneksi upstream dalam cache tahan lama, sehingga Anda dapat mengabaikan sedikit peningkatan keterlambatan saat membuka koneksi. Konfigurasi ini berubah sendiri dengan aktivasi
SO_REUSEPORT meningkatkan puncak p99 sebesar 33%.
Memindahkan read () ke kumpulan utas: bukan peluru perak
Solusinya adalah membuat read () non-blocking. Sebenarnya fungsi ini
diimplementasikan dalam Nginx normal ! Menggunakan konfigurasi berikut, baca () dan tulis () dijalankan di kumpulan utas dan jangan halangi loop peristiwa:
aio threads; aio_write on;
Tetapi kami menguji konfigurasi ini dan alih-alih meningkatkan waktu respons sebanyak 33 kali, kami hanya melihat sedikit perubahan pada p99, perbedaannya ada dalam margin of error. Hasilnya sangat mengecewakan, jadi kami menunda sementara opsi ini.
Ada beberapa alasan mengapa kami tidak memiliki peningkatan yang signifikan, seperti pengembang Nginx. Dalam pengujian mereka menggunakan 200 koneksi simultan untuk meminta file 4 MB ke HDD. Winchesters memiliki latensi I / O yang lebih banyak, sehingga pengoptimalan memiliki efek yang lebih besar.
Selain itu, kami terutama prihatin dengan kinerja p99 (dan p999). Mengoptimalkan penundaan rata-rata tidak serta merta memecahkan masalah emisi puncak.
Terakhir, di lingkungan kita, ukuran file tipikal jauh lebih kecil. 90% dari hit cache kami kurang dari 60KB. Semakin kecil file, semakin sedikit kasus pemblokiran (biasanya kita membaca seluruh file dalam dua kali dibaca).
Mari kita lihat disk I / O ketika menekan cache:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
32K tidak selalu dibaca. Jika tajuknya kecil, maka Anda hanya perlu membaca 4 KB (kami tidak menggunakan I / O secara langsung, sehingga kernel membulatkan ke 4 KB).
open() tampaknya tidak berbahaya, tetapi sebenarnya membutuhkan sumber daya. Minimal, kernel harus memeriksa apakah file itu ada dan apakah proses panggilan memiliki izin untuk membukanya. Dia perlu menemukan inode untuk
/cache/prefix/dir/EF/BE/CAFEBEEF , dan untuk ini dia harus mencari
CAFEBEEF di
/cache/prefix/dir/EF/BE/ . Singkatnya, dalam kasus terburuk, kernel melakukan pencarian ini:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
Ini adalah 6 bacaan terpisah yang
open() menghasilkan, dibandingkan dengan 1
read() ! Untungnya, dalam kebanyakan kasus pencarian jatuh ke
cache dentry dan tidak mencapai SSD. Tetapi jelas bahwa pemrosesan
read() dalam kumpulan thread hanya setengah dari gambar.
Final chord: non-blocking open () di kumpulan thread
Oleh karena itu, kami membuat perubahan ke Nginx sehingga
open() sebagian besar dieksekusi di dalam kumpulan thread dan tidak memblokir loop acara. Dan ini adalah hasil dari open-blocking non-blocking () dan read () pada saat yang sama:
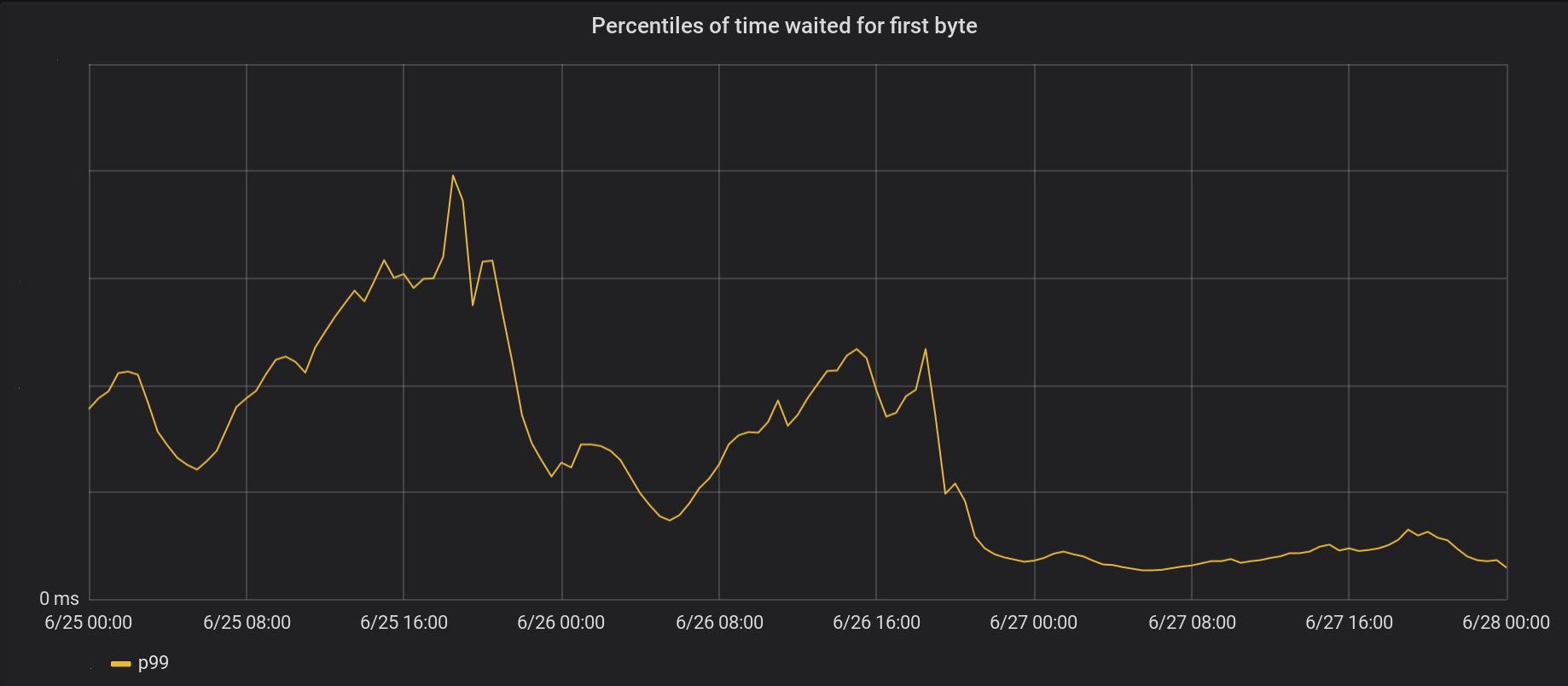
Pada tanggal 26 Juni, kami meluncurkan perubahan ke 5 pusat data tersibuk, dan hari berikutnya - ke semua 146 pusat data lainnya di seluruh dunia. Total puncak p99 TTFB menurun sebanyak 6 kali. Bahkan, jika kami merangkum sepanjang waktu dari pemrosesan 8 juta permintaan per detik, kami menghemat waktu tunggu Internet 54 tahun setiap hari.
Serangkaian acara kami belum sepenuhnya menghilangkan kunci. Secara khusus, pemblokiran masih terjadi saat file pertama kali di-cache (keduanya
open(O_CREAT) dan
rename() ) atau ketika memperbarui validasi ulang. Tetapi kasus seperti itu jarang dibandingkan dengan akses cache. Di masa depan, kami akan mempertimbangkan kemungkinan untuk memindahkan elemen-elemen ini di luar loop pemrosesan acara untuk lebih meningkatkan faktor penundaan p99.
Kesimpulan
Nginx adalah platform yang tangguh, tetapi meningkatkan beban I / O Linux sangat tinggi bisa menjadi tugas yang menakutkan. Nginx standar membongkar bacaan di utas terpisah, tetapi pada skala kami, kami sering perlu melangkah lebih jauh.