Ini adalah kisah tentang porting JavaScript ke platform domestik Elbrus, dibuat oleh orang-orang dari UniPro. Artikel ini memberikan analisis komparatif singkat tentang platform, detail proses dan jebakan.

Artikel ini didasarkan pada laporan oleh Dmitry (
dbezheckov ) Bezhetskov dan Vladimir (
volodyabo ) Anufrienko dengan HolyJS 2018 Piter. Di bawah potongan Anda akan menemukan transkrip video dan teks dari laporan.
Bagian 1. Elbrus, berasal dari Rusia
Pertama, kita akan mengerti apa itu Elbrus. Berikut adalah beberapa fitur utama platform ini dibandingkan dengan x86.
Arsitektur VLIW
Solusi arsitektur yang sama sekali berbeda dari arsitektur superscalar, yang lebih umum di pasaran sekarang. VLIW memungkinkan Anda untuk mengekspresikan maksud kode dengan lebih baik karena kontrol eksplisit dari semua perangkat aritmatika-logika independen (ALU), yang dimiliki oleh Elbrus, 4. Namun, ini tidak mengecualikan kemungkinan downtime dari beberapa ALU, namun demikian meningkatkan kinerja teoritis dengan satu siklus clock. prosesor.
Bundling tim
Perintah prosesor siap digabungkan dalam bundel (Bundel). Satu bundel adalah satu instruksi besar yang dijalankan per jam bersyarat. Ini memiliki banyak instruksi atom yang dieksekusi secara independen dan segera dalam arsitektur Elbrus.

Pada gambar di sebelah kanan, persegi panjang abu-abu menunjukkan bundel yang diperoleh dengan memproses kode JS di sebelah kiri. Jika semuanya hampir jelas dengan instruksi ldd, fmuld, faddd, fsqrts, maka pernyataan pengembalian di awal bundel pertama mengejutkan bagi orang-orang yang tidak terbiasa dengan assembler Elbrus. Instruksi ini memuat alamat pengirim dari fungsi floatMath saat ini ke dalam register ctpr3 terlebih dahulu, sehingga prosesor dapat mengatur untuk mengunduh instruksi yang diperlukan. Kemudian, dalam bundel terakhir, kami sudah melakukan transisi ke alamat yang dimuat sebelumnya di ctpr3.
Perlu juga dicatat bahwa Elbrus memiliki lebih banyak register 192 + 32 + 32 versus 16 + 16 +8 untuk x86.
Spekulatif eksplisit versus implisit
Elbrus mendukung spekulatif eksplisit di tingkat perintah. Oleh karena itu, kita dapat memanggil dan memuat a.bar dari memori bahkan sebelum memeriksa apakah itu tidak nol, seperti yang terlihat pada kode di sebelah kanan. Jika membaca secara logis pada akhirnya ternyata tidak valid, maka nilai dalam b hanya akan ditandai sebagai perangkat keras yang salah dan tidak mungkin untuk mengaksesnya.

Dukungan Eksekusi Bersyarat
Elbrus juga mendukung eksekusi bersyarat. Pertimbangkan ini dalam contoh berikut.

Seperti yang dapat kita lihat, kode dari contoh sebelumnya tentang spekulatif juga berkurang karena penggunaan konvolusi ekspresi kondisional menjadi ketergantungan, bukan oleh kontrol, tetapi oleh data. Perangkat keras Elbrus mendukung register predikat, di mana Anda hanya dapat menyimpan dua nilai benar atau salah. Fitur utamanya adalah Anda dapat menandai instruksi dengan predikat seperti itu dan tergantung pada nilainya pada saat eksekusi, instruksi tersebut akan dieksekusi atau tidak. Dalam contoh ini, instruksi cmpeq melakukan perbandingan dan menempatkan hasil logisnya pada predikat P1, yang kemudian digunakan sebagai penanda untuk memuat nilai dari b ke dalam hasil. Dengan demikian, jika predikatnya sama dengan true, maka nilai 0 tetap di hasilnya.
Pendekatan ini memungkinkan Anda untuk mengubah grafik kontrol program yang cukup kompleks menjadi eksekusi predikat dan, karenanya, meningkatkan kepenuhan bundel. Sekarang kita dapat menghasilkan lebih banyak tim independen di bawah predikat yang berbeda dan mengisinya dengan bundel. Elbrus mendukung 32 register predikat, yang memungkinkan Anda untuk menyandikan 65 aliran kontrol (ditambah satu untuk tidak adanya predikat pada perintah).
Tiga tumpukan perangkat keras dibandingkan dengan yang ada di Intel
Dua di antaranya dilindungi dari modifikasi oleh programmer. Satu - tumpukan rantai - bertanggung jawab untuk menyimpan alamat untuk pengembalian dari fungsi, yang lain - tumpukan register - berisi parameter yang dilewati. Stack pengguna ketiga - menyimpan variabel dan data pengguna. Dalam intel, semuanya disimpan di satu tumpukan, yang menimbulkan kerentanan, karena semua alamat transisi, parameter berada di satu tempat yang tidak dilindungi oleh modifikasi oleh pengguna.
Tidak ada prediktor cabang dinamis
Alih-alih, sebuah skema dengan persiapan-konversi dan persiapan transisi digunakan sehingga pipa eksekusi tidak berhenti.
Jadi mengapa kita perlu JS di Elbrus?
- Substitusi impor.
- Pengenalan Elbrus ke pasar komputer rumahan, di mana Javascript sudah diperlukan untuk peramban yang sama.
- Elbrus sudah dibutuhkan di industri, misalnya dengan Node.js. Oleh karena itu, Anda perlu mem-port Node ke arsitektur ini.
- Perkembangan arsitektur Elbrus, serta spesialis di bidang ini.
Jika tidak ada juru bahasa, dua penyusun datang
Implementasi v8 sebelumnya dari Google diambil sebagai dasar. Ia bekerja seperti ini: pohon sintaksis abstrak dibuat dari kode sumber, kemudian tergantung pada apakah kode itu dieksekusi atau tidak, menggunakan salah satu dari dua kompiler (Crankshaft atau FullCodegen), masing-masing, kode biner yang dioptimalkan atau tidak dioptimalkan dibuat. Tidak ada penerjemah.

Bagaimana cara kerja FullCodegen?
Simpul pohon sintaksis diterjemahkan ke dalam kode biner, setelah itu semuanya "direkatkan" bersama-sama. Satu node adalah sekitar 300 baris kode dalam assembler makro. Ini, pertama, memberikan cakrawala optimalisasi, dan, kedua, tidak ada transisi bytecode, seperti dalam interpreter. Ini sederhana, tetapi pada saat yang sama ada masalah - selama porting Anda harus menulis ulang banyak kode di assembler makro.
Namun demikian, semua ini dilakukan, dan hasilnya adalah versi kompiler FullCodegen 1.0 untuk Elbrus. Semuanya dilakukan melalui runtime C ++ v8, mereka tidak mengoptimalkan apa pun, kode assembler hanya ditulis ulang dari x86 ke arsitektur Elbrus.
Codegen 1.1
Akibatnya, hasilnya tidak persis sama dengan yang diharapkan, dan diputuskan untuk merilis FullCodegen 1.1:
- Membuat runtime lebih sedikit, menulis di assembler makro;
- Menambahkan konversi if manual (pada gambar, sebagai contoh, variabel js diperiksa benar atau salah);

Perhatikan bahwa memeriksa NaN, undefined, null dilakukan sekaligus, tanpa menggunakan if, yang akan diperlukan dalam arsitektur Intel.
- Kode tersebut tidak hanya ditulis ulang dengan Intel, tetapi juga menerapkan spekulativeness di stubs dan mengimplementasikan jalur cepat juga melalui MAsm (assembler makro).
Tes dilakukan di Google Octane. Mesin uji:
- Elbrus: E2S 750 MHz, 24 GB
- Intel: core i7 3.4 GHz, 16 GB
Hasil lebih lanjut:

Pada histogram adalah rasio hasil, yaitu berapa kali Elbrus lebih buruk dari Intel. Pada dua tes, Crypto dan zlib, hasilnya terasa lebih buruk karena Elbrus belum memiliki instruksi perangkat keras untuk bekerja dengan enkripsi. Secara umum, mengingat perbedaan frekuensi, ternyata cukup baik.
Berikut ini adalah tes dibandingkan dengan juru bahasa js dari firefox, yang merupakan bagian dari distribusi Elbrus standar. Lebih banyak lebih baik.
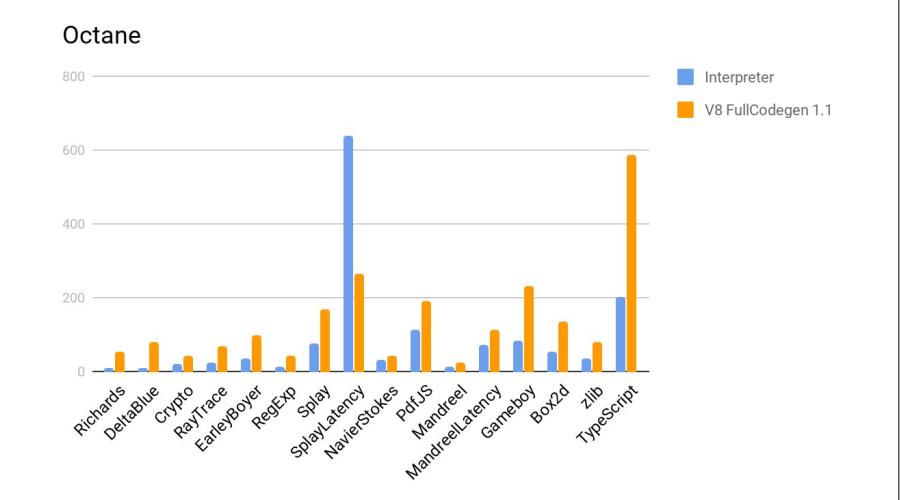
Putusan - kompiler melakukan pekerjaan dengan baik lagi.
Hasil Pengembangan
- Mesin JS baru lulus tes test262. Ini memberinya hak untuk disebut lingkungan runtime lengkap ECMAScript 262.
- Produktivitas meningkat rata-rata lima kali dibandingkan dengan mesin sebelumnya - interpreter.
- Node.js 6.10 juga porting sebagai contoh menggunakan V8, karena itu tidak sulit.
- Namun, ini masih lebih buruk daripada Core i7 di FullCodegen sebanyak tujuh kali.
Tampaknya tidak ada yang menandakan
Semuanya akan baik-baik saja, tetapi di sini Google mengumumkan bahwa itu tidak lagi mendukung FullCodegen dan Crankshaft dan mereka akan dihapus. Setelah itu tim menerima pesanan pengembangan untuk browser Firefox, dan lebih lanjut tentang itu nanti.

Bagian 2. Firefox dan monyet laba-laba
Ini tentang mesin browser Firefox - SpiderMonkey. Pada gambar, perbedaan antara mesin ini dan V8 yang lebih baru.
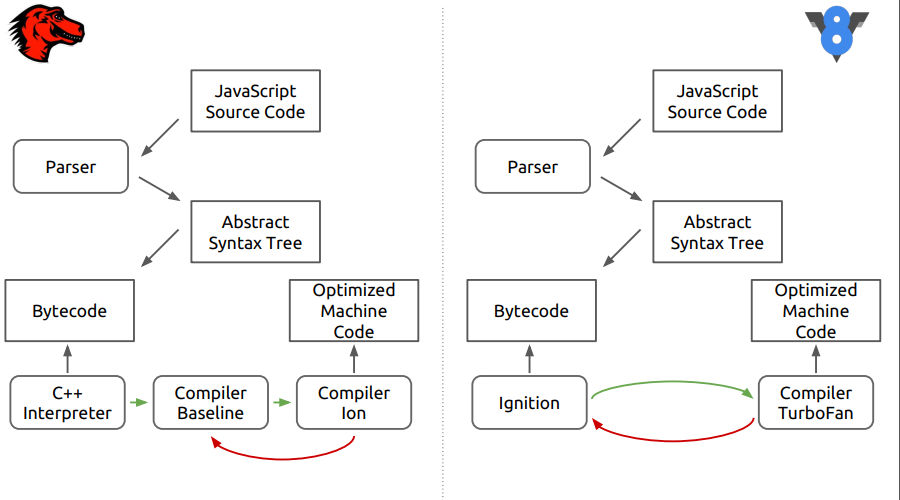
Dapat dilihat bahwa pada tahap pertama semuanya tampak seperti kode sumber diurai menjadi pohon sintaksis abstrak, kemudian ke dalam kode byte, dan kemudian perbedaan dimulai.
Dalam SpiderMonkey, bytecode ditafsirkan oleh penerjemah C ++, yang pada dasarnya menyerupai saklar besar, di dalamnya bytecode melompat. Selanjutnya, kode yang diinterpretasikan masuk ke Baseline kompilator yang melakukan neotimisasi. Kemudian, pada tahap akhir, Ion kompiler yang mengoptimalkan dimasukkan dalam kasing. Dalam mesin V8, bytecode diproses oleh juru bahasa Ingnition, dan kemudian oleh kompiler TurboFan.
Baseline, aku memilihmu!
Porting dimulai dengan kompiler Baseline. Ini pada dasarnya adalah mesin bertumpuk. Yaitu, ada tumpukan tertentu dari mana sel-sel ia mengambil variabel, mengingatnya, melakukan beberapa tindakan dengan mereka, setelah itu ia mengembalikan kedua variabel dan hasil tindakan kembali ke sel-sel tumpukan. Di bawah ini dalam beberapa gambar mekanisme ini ditunjukkan langkah demi langkah sehubungan dengan fungsi sederhana foo:
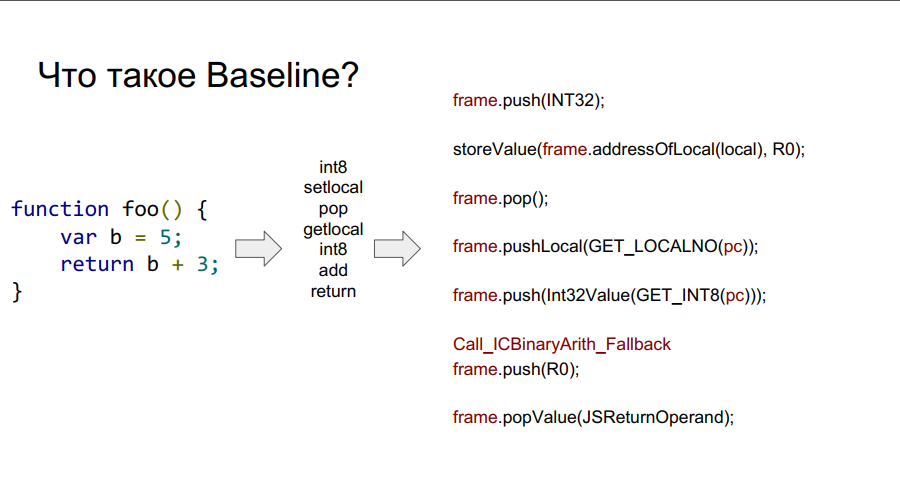


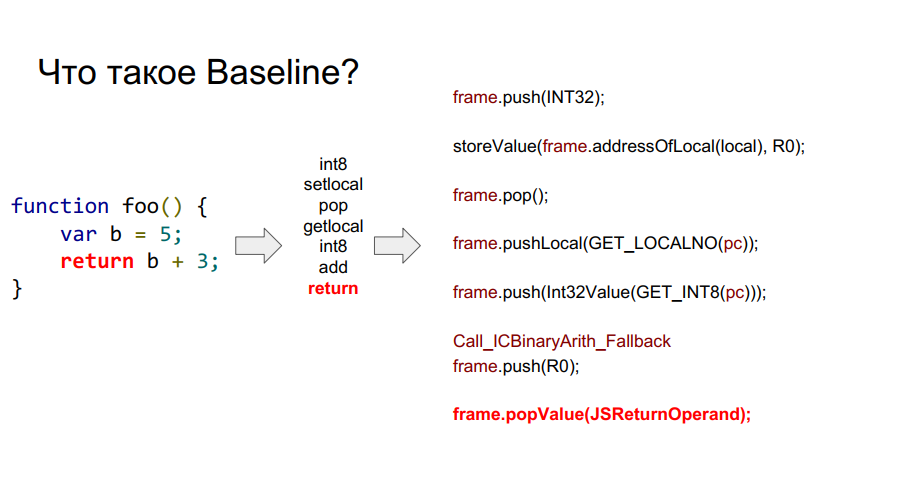
Apa itu bingkai?
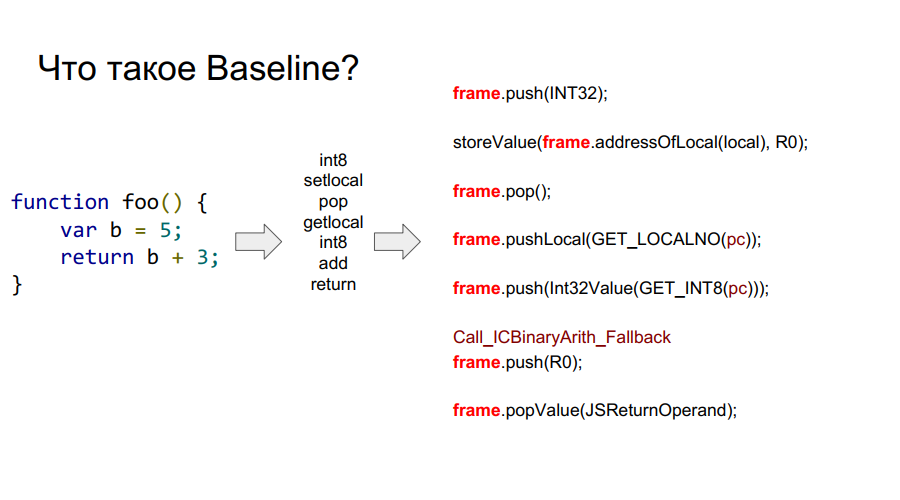
Pada gambar di atas Anda dapat melihat bingkai kata. Secara kasar, ini adalah konteks Javascript pada perangkat keras, yaitu, set data pada tumpukan yang menjelaskan salah satu fungsi Anda. Pada gambar di bawah ini, fungsinya adalah foo, dan di sebelah kanannya adalah seperti apa yang terlihat di stack: argumen, deskripsi fungsi, alamat kembali, indikasi bingkai sebelumnya, karena fungsi dipanggil dari suatu tempat dan agar dapat kembali ke tempat panggilan dengan benar, informasi ini harus disimpan dalam stack, dan kemudian variabel lokal sendiri berfungsi dan operan untuk perhitungan.

Dengan demikian,
keuntungan dari Baseline :
- Sepertinya FullCodegen, jadi pengalaman portingnya sangat berguna;
- Port assembler, dapatkan kompiler yang berfungsi;
- Lebih mudah untuk debug;
- Stub apa pun dapat ditulis ulang.
Namun ada juga
kelemahannya :
- Kode linier, sampai Anda mengeksekusi kode satu byte, Anda tidak akan dapat menjalankan yang berikut, yang tidak terlalu baik untuk arsitektur dengan komputasi paralel;
- Karena bekerja dengan bytecode, Anda tidak benar-benar mengoptimalkan.
Hanya tinggal menerapkan assembler makro dan mendapatkan kompiler yang sudah jadi. Debugging tidak menjadi pertanda baik, itu sudah cukup untuk melihat stack pada arsitektur x86, dan kemudian pada yang diperoleh saat porting untuk menemukan masalah.
Akibatnya, dalam pengujian dengan kompiler baru, produktivitas meningkat tiga kali lipat:

Namun, Octane tidak mendukung pengecualian. Dan implementasinya sangat penting.
Pekerjaan luar biasa
Pertama, mari kita lihat bagaimana pengecualian berfungsi pada x86. Ketika program sedang berjalan, alamat pengirim dari fungsi ditulis ke stack. Pada titik tertentu, pengecualian terjadi. Kami beralih ke penangan pengecualian runtime, yang menggunakan bingkai yang kita bicarakan di atas. Kami menemukan di mana tepatnya pengecualian terjadi, setelah itu kami harus memundurkan tumpukan ke kondisi yang diinginkan, dan kemudian alamat pengirim berubah ke tempat di mana pengecualian akan diproses.
Masalahnya adalah bahwa karena perangkat stack lain pada arsitektur Elbrus, ini tidak akan berfungsi. Akan perlu untuk menghitung dengan system call berapa banyak yang Anda butuhkan untuk mundur dalam Chain stack. Selanjutnya, kami membuat panggilan sistem untuk mendapatkan tumpukan panggilan. Selanjutnya, dalam alamat di tumpukan Rantai, kami membuat pengganti untuk alamat yang mengembalikannya.
Di bawah ini adalah ilustrasi urutan langkah-langkah ini.

Namun, bukan cara tercepat, pengecualian ditangani. Namun tetap saja, pada Intel terlihat sedikit lebih sederhana:

Dengan Elbrus, akan ada lebih banyak lompatan ke pawang:

Itu sebabnya Anda tidak harus mendasarkan logika program pada pengecualian, terutama pada Elbrus.
Optimalkan!
Jadi, penanganan pengecualian diterapkan. Sekarang kami akan memberi tahu Anda bagaimana kami membuatnya sedikit lebih cepat:
- Menulis ulang cache inline;
- Membuat pengaturan penundaan secara manual (dan kemudian otomatis);
- Mereka membuat persiapan untuk transisi (lebih tinggi dalam kode): semakin awal transisi disiapkan, semakin baik;
- Pengumpul sampah tambahan yang didukung
Paragraf kedua akan membahas sedikit lebih detail. Kami telah memeriksa contoh kecil bekerja dengan bundel, dan kami akan beralih ke itu.

Operasi apa pun, misalnya, memuat, tidak dilakukan dalam satu siklus, dalam hal ini dilakukan dalam tiga siklus. Jadi, jika kita ingin mengalikan dua angka, kita memasuki operasi perkalian, tetapi operan itu sendiri belum dimuat, prosesor hanya bisa menunggu mereka memuat. Dan dia akan menunggu sejumlah langkah, kelipatan empat. Tetapi jika Anda mengatur penundaan secara manual, waktu tunggu dapat dikurangi, sehingga meningkatkan kinerja. Selanjutnya, proses mengatur penundaan otomatis.
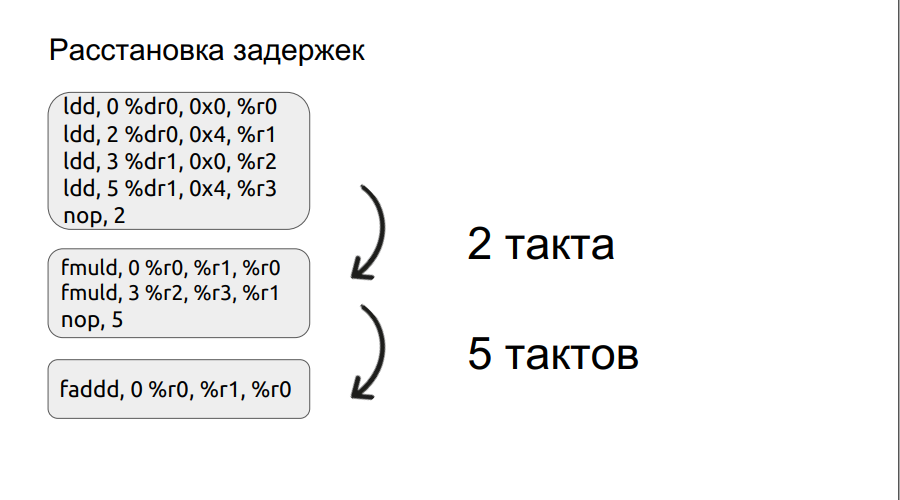
Hasil optimasi BaseLine v1.0 vs Baseline v1.1. Tentu, mesinnya menjadi lebih cepat.

Bagaimana programmer tidak bisa membuat senjata Ion?
Pada gelombang kesuksesan dari implementasi Baseline v1.1, diputuskan untuk port Ion kompiler mengoptimalkan.

Bagaimana cara kerja kompiler yang mengoptimalkan? Kode sumber ditafsirkan, kompilasi dimulai. Dalam proses mengeksekusi bytecode, Ion mengumpulkan data pada jenis yang digunakan dalam program, dan analisis "fungsi panas" - yang dilakukan lebih sering daripada yang lain. Setelah itu, keputusan dibuat untuk menyusunnya dengan lebih baik, untuk mengoptimalkan. Selanjutnya, representasi tingkat tinggi dari kompiler, grafik operasi, dibangun. Grafik dioptimalkan (opt 1, opt 2, opt ...), representasi level rendah dibuat, terdiri dari instruksi mesin, register dicadangkan, kode biner yang dioptimalkan secara langsung dihasilkan.
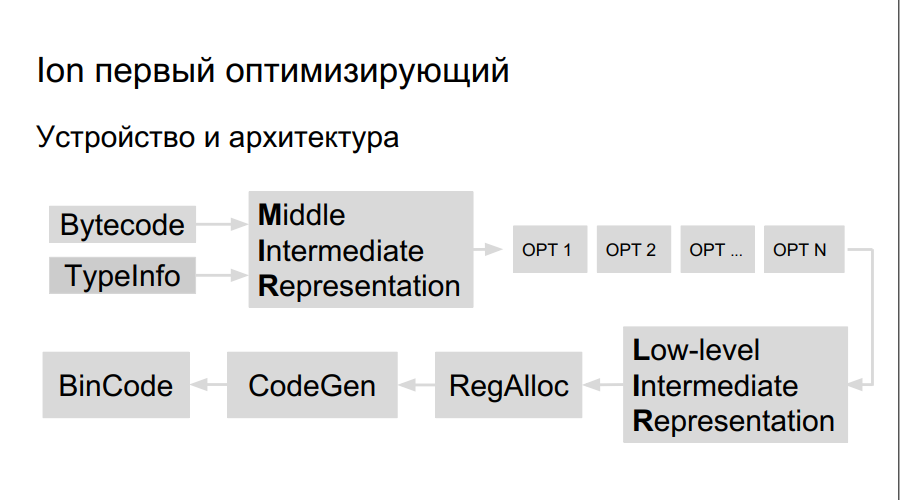
Ada lebih banyak register di Elbrus dan tim itu sendiri besar, oleh karena itu kita perlu:
- Perencana Tim
- Pengalokasi daftar sendiri;
- LIR Sendiri (Representasi Tingkat Menengah Rendah);
- Pembuat kode sendiri.
Tim sudah memiliki pengalaman porting Java ke Elbrus, mereka memutuskan untuk menggunakan perpustakaan yang sama untuk pembuatan kode untuk porting Ion. Dia disebut TANGO. Itu memiliki:
- Perencana Tim
- Pengalokasi daftar sendiri;
- Optimalisasi tingkat rendah.
Tetap memperkenalkan perwakilan tingkat tinggi di TANGO, untuk membuat pemilih. Masalahnya adalah bahwa tampilan tingkat rendah di TANGO seperti assembler, yang sulit untuk dipertahankan dan didebug. Seperti apa seharusnya kompiler di dalam? Untuk pemahaman yang lebih baik, Mozilla membuat kompiler HolyJit mereka sendiri, ada juga opsi untuk menulis bahasa mini Anda sendiri untuk menerjemahkan antara representasi level tinggi dan level rendah.
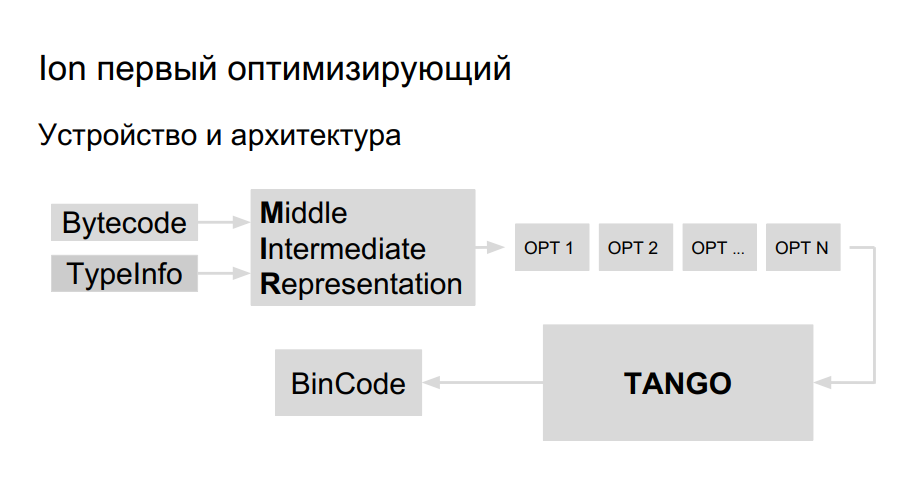
Pembangunan masih berlangsung. Nah dan selanjutnya tentang bagaimana tidak berlebihan dengan optimasi.
Bagian 3. Yang terbaik adalah musuh dari yang baik
Kompilasi seperti apa adanya
Proses optimasi di Ion, ketika kode memanas dan kemudian mengkompilasi dan mengoptimalkan, serakah, ini dapat dilihat pada contoh berikut.
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
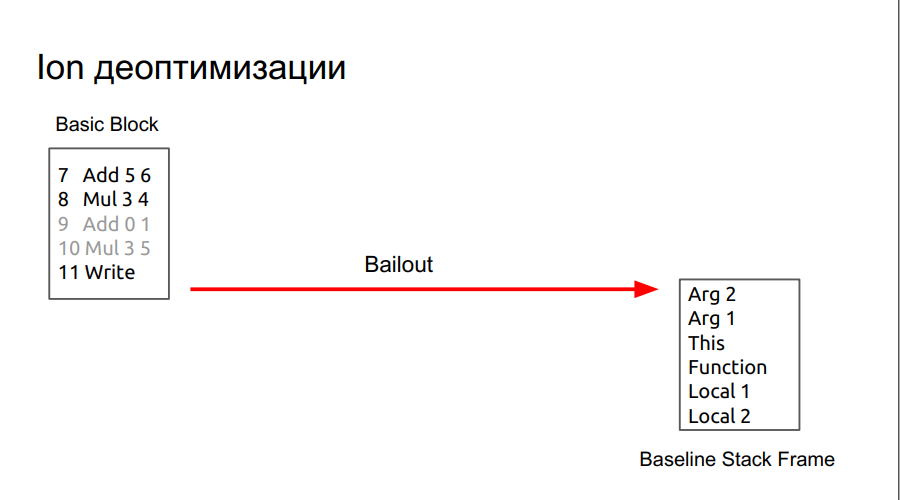
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
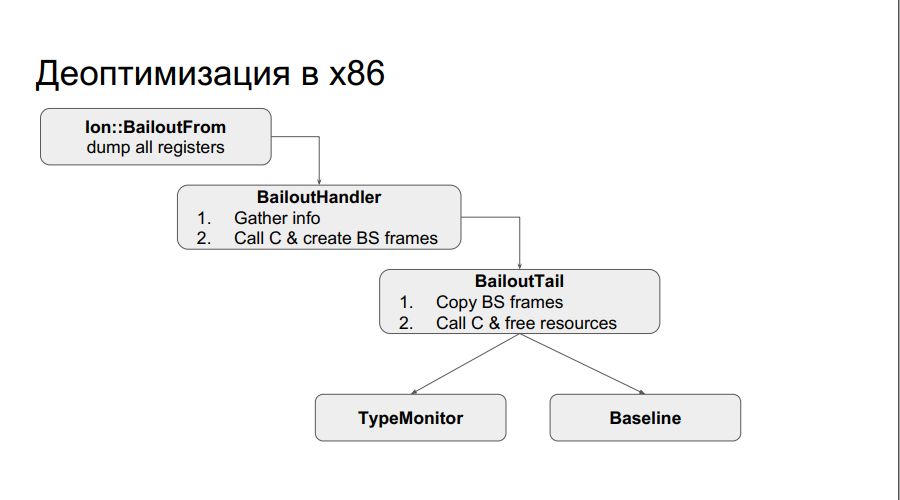
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
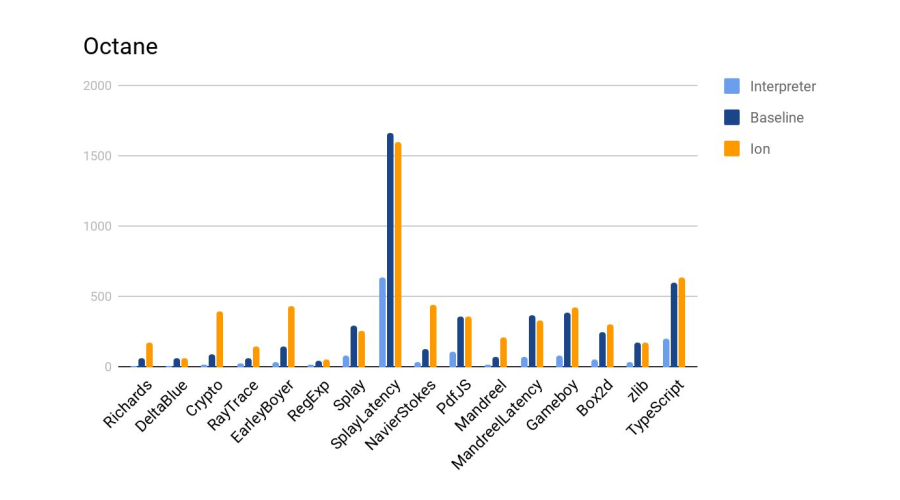
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .