Beberapa waktu lalu, sebuah tautan muncul di umpan Facebook saya ke buku Andrew Ng Machine Learning Yearning, yang dapat diterjemahkan sebagai Machine Learning Passion atau Machine Learning Thirst.

Orang yang tertarik dengan pembelajaran mesin atau bekerja di bidang ini tidak perlu memperkenalkan Andrew. Bagi yang belum tahu, cukup untuk mengatakan bahwa ia adalah bintang kelas dunia di bidang kecerdasan buatan. Ilmuwan, insinyur, pengusaha, salah satu pendiri Coursera . Dia adalah penulis pengantar yang sangat baik untuk pembelajaran mesin dan kursus yang membentuk spesialisasi Deep Learning .
Saya sangat menghormati Andrew, saya mengambil kursusnya, jadi saya segera memutuskan untuk membaca buku yang diterbitkan. Ternyata buku itu belum ditulis dan diterbitkan sebagian, seperti yang ditulis oleh penulis. Secara umum, ini bahkan bukan buku, tetapi konsep buku masa depan (apakah akan diterbitkan dalam bentuk kertas tidak diketahui). Kemudian muncul ide untuk menerjemahkan bab-bab yang sedang diterbitkan. Saat ini diterjemahkan 14 bab (ini adalah kutipan pertama dari buku ini). Saya berencana untuk melanjutkan pekerjaan ini dan menerjemahkan seluruh buku. Saya akan menerbitkan bab-bab terjemahan di blog saya di Habré.
Pada saat menulis baris-baris ini, penulis telah menerbitkan 52 bab dari 56 konsep (pemberitahuan kesiapan 52 bab datang ke email saya pada 4 Juli). Semua bab yang tersedia saat ini dapat diunduh di sini atau ditemukan di Internet sendiri.
Sebelum menerbitkan terjemahan saya, saya mencari terjemahan lain, saya menemukan terjemahan ini, juga diterbitkan di Habré. Benar, hanya 7 bab pertama yang telah diterjemahkan. Saya tidak bisa menilai terjemahan siapa yang lebih baik. Baik saya maupun IliaSafonov (seperti yang saya rasakan dari membaca) adalah penerjemah profesional. Saya suka beberapa bagian lagi, beberapa Ilya. Di pengantar Ilya, Anda dapat membaca detail menarik tentang buku, yang saya hilangkan.
Saya menerbitkan terjemahan saya tanpa proofreading, "from the oven", saya berencana untuk kembali ke beberapa tempat dan memperbaikinya (ini terutama berlaku untuk kebingungan dengan set data train / dev / test). Saya akan berterima kasih jika komentar akan diberikan komentar pada gaya, kesalahan, dll, serta informatif mengenai teks penulis.
Semua gambar asli (dari Andrew Eun), tanpa mereka buku itu akan lebih membosankan.
Jadi, untuk buku:
Bab 1. Mengapa kita membutuhkan strategi pembelajaran mesin?
Pembelajaran mesin adalah jantung dari aplikasi penting yang tak terhitung jumlahnya, termasuk pencarian web, antispam email, pengenalan ucapan, rekomendasi produk, dan lainnya. Saya berasumsi bahwa Anda atau tim Anda sedang mengerjakan aplikasi pembelajaran mesin. Dan Anda ingin mempercepat kemajuan Anda dalam pekerjaan ini. Buku ini akan membantu Anda melakukan ini.
Contoh: Membuat startup pengenalan gambar kucing
Misalkan Anda bekerja di startup yang memproses aliran foto kucing tanpa akhir untuk pecinta kucing.

Anda menggunakan jaringan saraf untuk membangun sistem visi komputer untuk mengenali kucing dalam foto.
Namun sayangnya, kualitas algoritme pembelajaran Anda masih belum cukup baik dan tekanan luar biasa pada Anda adalah untuk meningkatkan detektor kucing Anda.
Apa yang harus dilakukan
Tim Anda memiliki banyak ide, seperti:
- Dapatkan lebih banyak data: kumpulkan lebih banyak foto kucing.
- Kumpulkan dataset yang lebih heterogen. Misalnya, foto-foto kucing dalam posisi yang tidak biasa; foto kucing dengan pewarnaan yang tidak biasa; gambar dengan berbagai pengaturan kamera; ...
- Latih algoritma lebih lama dengan meningkatkan jumlah iterasi gradient descent
- Cobalah untuk meningkatkan jaringan saraf, dengan banyak lapisan / neuron / parameter tersembunyi.
- Cobalah untuk mengurangi jaringan saraf.
- Coba tambahkan regularisasi (seperti regularisasi L2)
- Ubah arsitektur jaringan saraf (fungsi aktivasi, jumlah neuron tersembunyi, dll.)
- ...
Jika Anda berhasil memilih di antara arahan yang mungkin ini, Anda akan membangun platform pemrosesan gambar kucing terkemuka dan membawa perusahaan Anda menuju sukses. Jika pilihan Anda tidak berhasil, Anda bisa kehilangan pekerjaan berbulan-bulan dengan sia-sia.
Apa yang harus dilakukan
Buku ini akan memberi tahu Anda caranya.
Sebagian besar tugas pembelajaran mesin memiliki petunjuk yang dapat memberi tahu Anda apa yang akan berguna untuk dicoba dan apa yang tidak berguna untuk dicoba. Jika Anda belajar membaca tips ini, Anda bisa menghemat berbulan-bulan dan bertahun-tahun pembangunan.
2. Cara menggunakan buku ini untuk membantu kerja tim Anda
Setelah Anda selesai membaca buku ini, Anda akan memiliki pemahaman yang mendalam tentang bagaimana memilih arahan teknis untuk proyek pembelajaran mesin.
Tetapi mungkin tidak jelas bagi rekan tim Anda mengapa Anda merekomendasikan arah tertentu. Mungkin Anda ingin tim Anda menggunakan metrik satu-parameter dalam menilai kualitas algoritme, tetapi kolega tidak yakin bahwa ini adalah ide yang bagus. Bagaimana Anda meyakinkan mereka?
Itulah sebabnya saya membuat bab-bab singkat: Agar Anda dapat mencetaknya dan memberikan satu atau dua halaman rekan Anda berisi materi yang Anda butuhkan untuk membiasakan tim.
Perubahan kecil dalam penentuan prioritas dapat memiliki dampak besar pada produktivitas tim Anda. Membantu dengan perubahan kecil ini, saya harap Anda bisa menjadi superhero tim Anda!

3. Latar belakang dan komentar
Jika Anda telah menyelesaikan kursus pembelajaran mesin, seperti kursus belajar mesin MOOC saya di Coursera, atau jika Anda memiliki pengalaman mengajar algoritma dengan seorang guru, tidak akan sulit bagi Anda untuk memahami teks ini.
Saya berasumsi bahwa Anda terbiasa dengan "pelatihan guru": mempelajari fungsi yang menghubungkan x ke y menggunakan contoh pelatihan berlabel (x, y). Algoritma pembelajaran dengan seorang guru meliputi regresi linier, regresi logistik, jaringan saraf, dan lainnya. Saat ini, ada banyak bentuk dan pendekatan untuk pembelajaran mesin, tetapi sebagian besar pendekatan kepentingan praktis berasal dari algoritma kelas "belajar dengan seorang guru."
Saya akan sering merujuk pada jaringan saraf ("pembelajaran mendalam"). Anda hanya perlu ide-ide dasar tentang apa itu untuk memahami teks ini.
Jika Anda tidak terbiasa dengan konsep yang disebutkan di sini, tonton video tiga minggu pertama kursus Pembelajaran Mesin di Coursera http://ml-class.org/
4. Bilah kemajuan dalam pembelajaran mesin
Banyak ide untuk pembelajaran mendalam (jaringan saraf) telah ada selama beberapa dekade. Mengapa ide-ide ini melambung hanya hari ini?
Dua pendorong terbesar dari kemajuan terakhir adalah:
- Ketersediaan Data Saat ini, orang menghabiskan banyak waktu dengan perangkat komputer (laptop, perangkat seluler). Aktivitas digital mereka menghasilkan data dalam jumlah besar yang dapat kami berikan ke algoritma pembelajaran kami.
- Komputasi daya Hanya beberapa tahun yang lalu menjadi mungkin untuk melatih jaringan saraf dari ukuran yang cukup besar, memungkinkan Anda untuk mendapatkan manfaat dari menggunakan kumpulan data besar yang kami miliki.
Saya akan mengklarifikasi, bahkan jika Anda mengumpulkan banyak data, biasanya kurva pertumbuhan keakuratan algoritma pembelajaran lama, seperti regresi logistik adalah "datar". Ini menyiratkan bahwa kurva belajar "rata" dan kualitas prediksi algoritma berhenti tumbuh meskipun Anda memberi lebih banyak data untuk pelatihan.
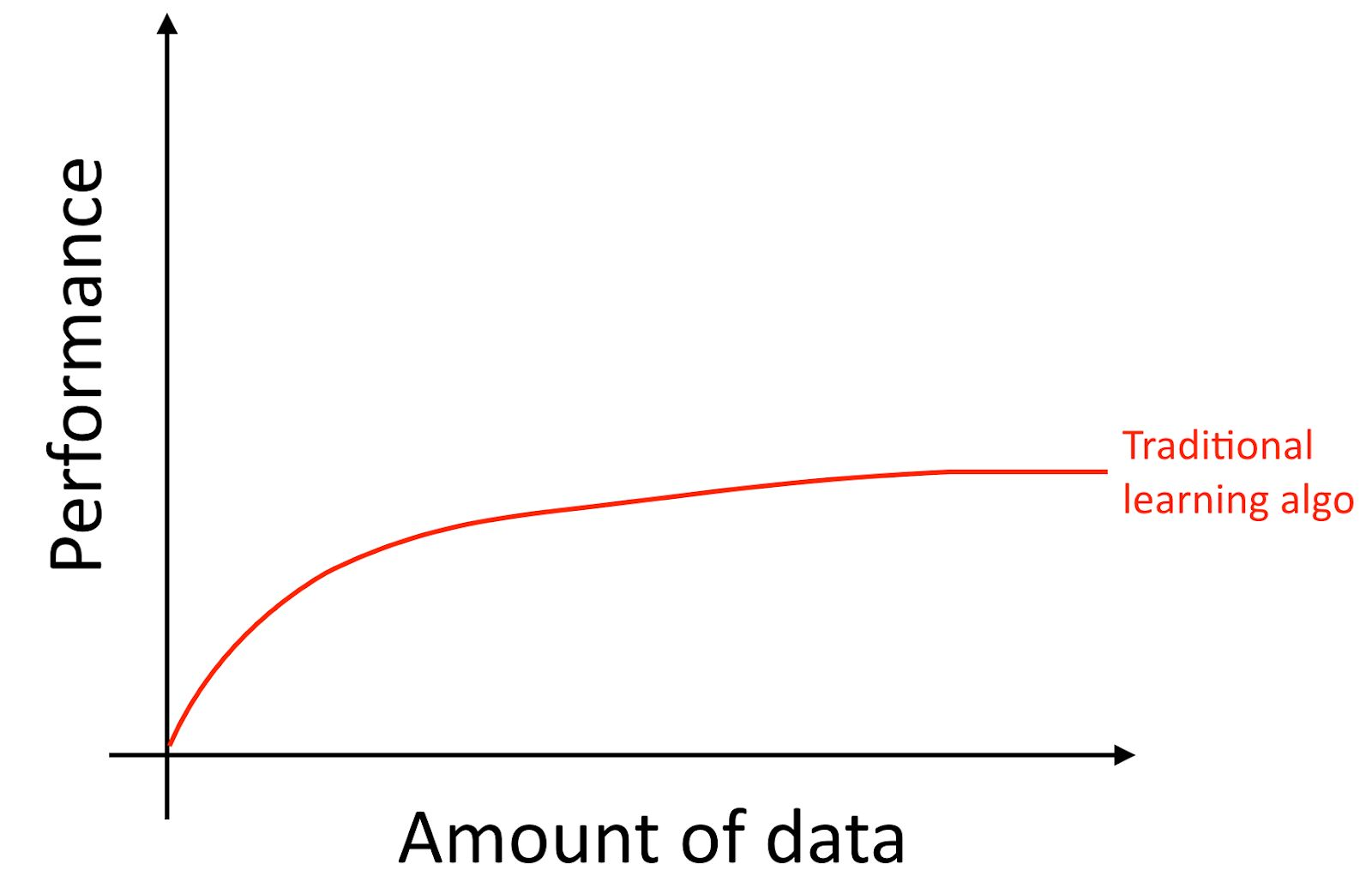
Sepertinya algoritma lama tidak tahu apa yang harus dilakukan dengan semua data ini yang sekarang tersedia untuk kita.
Jika Anda melatih jaringan saraf kecil (NN) untuk tugas "belajar dengan guru" yang sama, Anda mungkin mendapatkan hasil yang sedikit lebih baik daripada "algoritma lama".
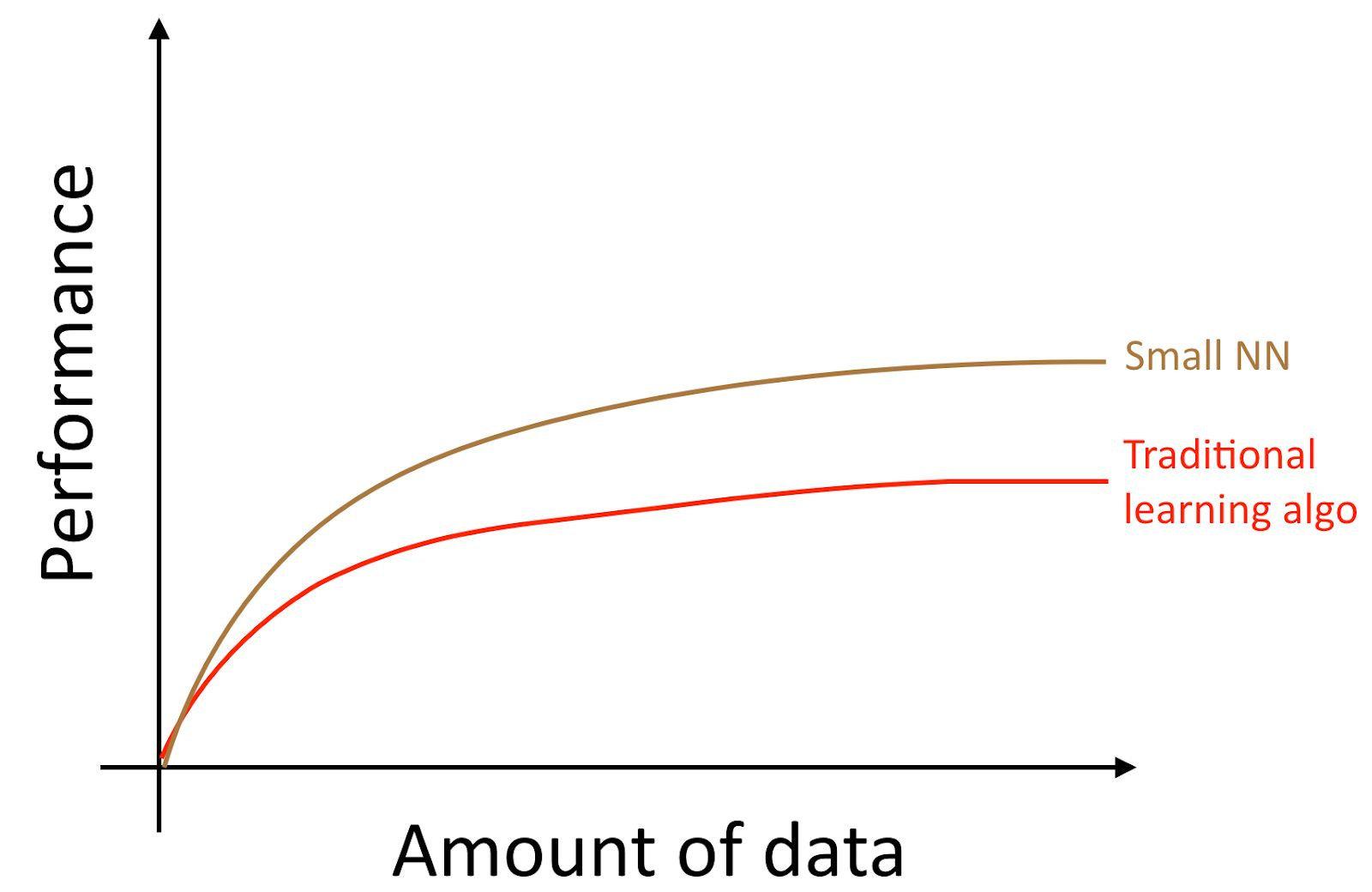
Di sini, dengan "NN Kecil" yang kami maksud adalah jaringan saraf dengan sejumlah kecil neuron / lapisan / parameter tersembunyi. Akhirnya, jika Anda mulai melatih jaringan saraf yang semakin besar dan semakin besar, Anda bisa mendapatkan kualitas yang semakin tinggi.
Catatan penulis : Diagram ini menunjukkan bahwa jaringan saraf berkinerja lebih baik dalam mode dataset kecil. Efek ini kurang stabil dibandingkan efek jaringan saraf yang bekerja dengan baik dalam mode dataset besar. Dalam mode data kecil, tergantung pada bagaimana fitur diproses (tergantung pada kualitas rekayasa fitur), algoritma tradisional dapat bekerja lebih baik dan lebih buruk daripada jaringan saraf. Misalnya, jika Anda memiliki 20 contoh untuk pelatihan, itu tidak masalah jika Anda menggunakan regresi logistik atau jaringan saraf; persiapan fitur memiliki efek yang lebih besar daripada pilihan algoritma. Namun, jika Anda memiliki 1 juta contoh pelatihan, saya lebih suka jaringan saraf.

Dengan demikian, Anda mendapatkan kualitas terbaik dari algoritma ketika Anda (i) melatih jaringan saraf yang sangat besar, dalam hal ini Anda berada pada kurva hijau pada gambar di atas; (ii) Anda memiliki sejumlah besar data yang Anda inginkan.
Banyak detail lain, seperti arsitektur jaringan saraf juga penting, dan banyak solusi inovatif telah dibuat di bidang ini. Tetapi cara yang paling dapat diandalkan untuk meningkatkan kualitas algoritma saat ini adalah masih (i) meningkatkan ukuran jaringan saraf yang terlatih (ii) memperoleh lebih banyak data untuk pelatihan.
Proses memenuhi kondisi bersama (i) dan (ii) dalam praktiknya ternyata sangat kompleks. Buku ini akan membahas secara detail detailnya. Kami mulai dengan strategi umum yang sama-sama berguna untuk algoritma tradisional dan jaringan saraf, dan kemudian mempelajari strategi paling modern yang digunakan dalam desain dan pengembangan sistem pembelajaran yang mendalam.
5. Membuat sampel untuk pelatihan dan pengujian algoritma
Mari kita kembali ke contoh foto kucing kami di atas: Anda meluncurkan aplikasi seluler dan pengguna mengunggah sejumlah besar foto yang berbeda ke aplikasi Anda. Anda ingin mencari foto kucing secara otomatis.
Tim Anda menerima pelatihan besar dengan mengunduh foto kucing (contoh positif) dan foto yang tidak ada kucing (contoh negatif) dari berbagai situs web. Mereka memotong dataset yang dibagi menjadi pelatihan dan menguji rasio 70% hingga 30%. Menggunakan data ini, mereka membangun algoritma yang menemukan kucing yang bekerja dengan baik pada data pelatihan dan tes.
Namun, ketika Anda memperkenalkan pengelompokan ini ke dalam aplikasi seluler, Anda menemukan bahwa kualitasnya sangat buruk!

Apa yang terjadi
Anda tiba-tiba mengetahui bahwa foto yang diunggah pengguna ke aplikasi seluler Anda memiliki tampilan yang sama sekali berbeda dengan foto dari situs web yang menyusun dataset pelatihan Anda: pengguna mengunggah foto yang diambil dengan kamera ponsel, yang biasanya memiliki resolusi lebih rendah, kurang tajam dan dibuat dalam cahaya rendah. Setelah pelatihan tentang sampel pelatihan / uji Anda yang dikumpulkan dari foto dari situs web, algoritme Anda tidak dapat menggeneralisasi hasil secara kualitatif ke distribusi data aktual yang relevan dengan aplikasi Anda (foto yang diambil dengan kamera ponsel).
Sebelum munculnya data besar era modern, aturan umum pembelajaran mesin adalah membagi data menjadi data pendidikan dan uji dalam rasio 70% hingga 30%. Terlepas dari kenyataan bahwa pendekatan ini masih bekerja, itu akan menjadi ide yang buruk untuk menggunakannya dalam aplikasi yang semakin banyak di mana distribusi sampel pelatihan (foto dari situs web dalam contoh yang dibahas di atas) berbeda dari distribusi data yang akan digunakan dalam pertempuran mode aplikasi Anda (foto dari kamera ponsel).
Definisi berikut umum digunakan:
- Kumpulan pelatihan - contoh data yang digunakan untuk melatih algoritma
- Sampling validasi (set Dev (pengembangan)) - pengambilan sampel data yang digunakan untuk memilih parameter, memilih fitur, dan membuat keputusan lain terkait pelatihan algoritma. Kadang-kadang juga disebut sebagai set validasi silang hold-out.
- Sampel uji - sampel yang digunakan untuk menilai kualitas algoritma, sementara itu tidak digunakan untuk mengajar algoritma atau parameter yang digunakan dalam pelatihan ini.
Komentar penerjemah: Andrew Eun menggunakan konsep set pengembangan atau set dev, dalam bahasa Rusia dan dalam terminologi pembelajaran mesin Rusia, istilah seperti itu tidak muncul. "Sampel Desain" atau "Sampel Desain" (terjemahan langsung dari kata-kata bahasa Inggris) terdengar rumit. Oleh karena itu, saya akan terus menggunakan frasa "seleksi validasi" sebagai terjemahan dari set dev.
Komentar penerjemah 2: DArtN menyarankan untuk menerjemahkan dev yang ditetapkan sebagai "debugging sampling"; Saya pikir ini adalah ide yang sangat bagus, tetapi saya telah menggunakan istilah "validasi sampling" pada volume teks yang besar dan sekarang sulit untuk menggantinya. Dalam keadilan, saya perhatikan bahwa istilah "sampel validasi" memiliki satu keunggulan - sampel ini digunakan untuk mengevaluasi kualitas algoritma (untuk menilai kualitas algoritma yang dilatih dalam sampel pelatihan), oleh karena itu, dalam arti tertentu, ini adalah "uji", istilah "validasi" dalam termasuk aspek ini. Kata sifat "debugging" berfokus pada parameter tuning. Tapi secara keseluruhan, ini adalah istilah yang sangat bagus (terutama dari sudut pandang bahasa Rusia) dan jika itu terlintas di pikiran saya sebelumnya, saya akan menggunakannya sebagai ganti istilah "sampel validasi".
Pilih validasi dan uji sampel sehingga (kecuali untuk pemilihan (penyesuaian) parameter) mencerminkan data yang Anda harapkan akan diterima di masa depan dan ingin algoritma Anda bekerja dengan baik pada mereka.
Dengan kata lain, sampel pengujian Anda seharusnya tidak hanya 30% dari data yang tersedia, terutama jika Anda berharap bahwa data yang akan datang (foto dari ponsel) akan berbeda sifatnya dari set pelatihan Anda (foto yang diambil dari web situs).
Jika Anda belum meluncurkan aplikasi seluler Anda, Anda mungkin tidak memiliki pengguna, dan sebagai hasilnya, mungkin tidak ada data yang tersedia yang mencerminkan data pertempuran yang harus ditangani oleh algoritma Anda. Tetapi Anda dapat mencoba memperkirakannya. Misalnya, minta teman Anda untuk mengambil foto kucing menggunakan ponsel dan mengirimkannya kepada Anda. Setelah meluncurkan aplikasi Anda, Anda akan dapat memperbarui validasi dan menguji sampel menggunakan data pengguna saat ini.
Jika Anda tidak dapat memperoleh data yang mendekati data yang akan diunggah pengguna, Anda mungkin dapat mencoba untuk mulai menggunakan foto dari situs web. Tetapi Anda harus menyadari bahwa ini membawa risiko bahwa sistem tidak akan bekerja dengan baik dengan data tempur (kemampuan generalisasi tidak akan cukup untuk mereka).
Pengembangan validasi dan sampel uji membutuhkan pendekatan yang serius dan pemikiran menyeluruh. Jangan dalil pada awalnya bahwa distribusi set pelatihan Anda harus sama persis dengan distribusi set tes. Cobalah untuk memilih kasus uji sedemikian rupa sehingga mereka mencerminkan distribusi data yang Anda inginkan algoritma Anda bekerja dengan baik pada akhirnya, dan bukan data yang siap membantu Anda saat membuat sampel pelatihan.
6. Validasi dan sampel uji harus memiliki distribusi yang sama

Misalkan data aplikasi foto kucing Anda tersegmentasi ke dalam empat wilayah yang sesuai dengan pasar terbesar Anda: (i) AS, (ii) Cina, (iii) India, (iv) Lainnya.
Misalkan kita membentuk sampel validasi dari data yang diperoleh dari pasar Amerika dan India, dan uji satu berdasarkan data China dan lainnya. Dengan kata lain, kita dapat menetapkan dua segmen secara acak untuk mendapatkan sampel validasi dan dua lainnya untuk mendapatkan sampel uji. Benar?
Setelah Anda menentukan validasi dan sampel uji, tim Anda akan fokus pada peningkatan operasi algoritma pada sampel validasi. Dengan demikian, sampel validasi harus mencerminkan tugas-tugas yang paling penting untuk diselesaikan - algoritma harus bekerja dengan baik pada keempat segmen geografis, dan bukan hanya dua.
Masalah kedua yang timbul dari distribusi yang berbeda dari validasi dan sampel uji adalah kemungkinan tim Anda akan mengembangkan sesuatu yang akan bekerja dengan baik pada sampel validasi hanya untuk mengetahui bahwa itu menghasilkan kualitas yang buruk dalam sampel uji. Saya telah melihat banyak kekecewaan dan usaha sia-sia karena ini. Hindari ini terjadi pada Anda.
Misalnya, anggap tim Anda telah mengembangkan sistem yang bekerja dengan baik pada sampel yang divalidasi, tetapi tidak berfungsi pada pengujian. Jika validasi dan sampel uji Anda diperoleh dari distribusi yang sama, Anda [mendapatkan diagnosis yang sangat jelas tentang itu] dapat dengan mudah mendiagnosis apa yang salah: algoritme Anda dilatih ulang pada sampel validasi. .
, .
- , . , .
- , , . . .
. , — . , , , .
, , , ( ). , , , . — , . , , , , . .
7. ?
, . , 90.0% 90.1%, , , 100 , 0.1%.
: . ( ), .
— , , -, , , 0.01% , . , 10000, , .
? . 30% . , , 100 10000 . , , , , , . / , , .
8.
: ( ), , , . , 97% , 90%, .
(precision) (recall), . . . :
, .
: (precision) () , , . (recall) () , , . , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 Saat Anda perlu mengubah sampel dan metrik validasi dan uji (dev / tes)
Ketika proyek baru dimulai, saya mencoba untuk dengan cepat memilih validasi dan menguji sampel yang akan menetapkan tujuan yang jelas untuk tim.
Saya biasanya meminta tim saya untuk mendapatkan validasi awal dan menguji sampel dan metrik awal lebih cepat dari satu minggu sejak awal proyek, jarang lebih lama. Lebih baik mengambil sesuatu yang tidak sempurna dan bergerak maju dengan cepat daripada memikirkan solusi terbaik untuk waktu yang lama. Namun, periode satu minggu ini tidak cocok untuk aplikasi yang sudah matang. Misalnya, filter anti-spam adalah aplikasi pembelajaran mendalam yang matang. Saya mengamati tim yang bekerja pada sistem yang sudah matang dan menghabiskan waktu berbulan-bulan untuk mendapatkan sampel yang lebih baik untuk pengujian dan pengembangan.
Jika Anda kemudian memutuskan bahwa pilihan dev / test awal Anda atau metrik asli tidak dipilih dengan benar, lakukan semua upaya untuk mengubahnya dengan cepat. Misalnya, jika sampel pengembangan Anda + peringkat metrik Classifier A lebih tinggi dari Classifier B, dan Anda dan tim Anda berpikir bahwa Classifier B secara objektif lebih baik untuk produk Anda, maka ini mungkin merupakan tanda bahwa Anda perlu mengubah dev / test kumpulan data atau dalam mengubah metrik untuk penilaian kualitas.
Ada tiga alasan utama yang memungkinkan karena sampel validasi atau metrik penilaian kualitas salah menempatkan Klasifikasi A di atas Klasifikasi B:
1. Distribusi aktual yang akan ditingkatkan berbeda dari sampel dev / test
Bayangkan bahwa set data dev / test asli Anda berisi sebagian besar gambar kucing dewasa. Anda mulai mendistribusikan aplikasi kucing dan mendapati bahwa pengguna mengunggah lebih banyak gambar anak kucing secara signifikan daripada yang Anda harapkan. Dengan demikian, distribusi dev / test tidak representatif, itu tidak mencerminkan distribusi aktual objek yang kualitas pengakuannya perlu Anda tingkatkan. Dalam hal ini, perbarui pilihan dev / test Anda untuk membuatnya lebih representatif.

2. Anda berlatih kembali pada pemilihan validasi (dev set)
Proses beberapa evolusi ide, pada set validasi (dev set) membuat algoritma Anda secara bertahap melatihnya. Ketika Anda telah menyelesaikan pengembangan, Anda mengevaluasi kualitas sistem Anda pada sampel uji. Jika Anda menemukan bahwa kualitas algoritme Anda pada set validasi (set dev) jauh lebih baik daripada pada set tes (set tes), maka ini menunjukkan bahwa Anda dilatih ulang pada sampel validasi. Dalam hal ini, Anda perlu mendapatkan sampel validasi baru.
Jika Anda perlu melacak kemajuan tim Anda, Anda juga dapat secara teratur mengevaluasi kualitas sistem Anda, misalnya, mingguan atau bulanan, menggunakan evaluasi kualitas algoritma pada sampel uji. Namun, jangan gunakan set tes untuk membuat keputusan mengenai algoritma, termasuk apakah akan kembali ke versi sebelumnya dari sistem yang diuji minggu lalu. Jika Anda mulai menggunakan sampel uji untuk mengubah algoritme, Anda akan mulai melatih kembali sampel uji dan tidak lagi dapat mengandalkannya untuk mendapatkan penilaian objektif tentang kualitas algoritme Anda (yang Anda perlukan jika Anda menerbitkan artikel penelitian, atau mungkin menggunakan metrik ini untuk membuat keputusan bisnis yang penting).
3. Metrik mengevaluasi sesuatu yang berbeda dari apa yang perlu dioptimalkan untuk tujuan proyek
Misalkan untuk aplikasi kucing Anda, metrik Anda adalah akurasi klasifikasi. Metrik ini saat ini peringkat Classifier A sebagai Classifier superior B. Tapi anggaplah Anda mencoba kedua algoritma dan menemukan bahwa gambar porno acak lolos dari Classifier A. Meskipun Classifier A lebih akurat, kesan buruk yang ditinggalkan oleh gambar porno acak membuat kualitasnya tidak memuaskan. Apa yang kamu lakukan salah?
Dalam hal ini, metrik yang mengevaluasi kualitas algoritma tidak dapat menentukan bahwa algoritma B sebenarnya lebih baik daripada algoritma A untuk produk Anda. Dengan demikian, Anda tidak dapat lagi mempercayai metrik untuk memilih algoritma terbaik. Waktunya telah tiba untuk mengubah metrik penilaian kualitas. Misalnya, Anda dapat mengubah metrik dengan memberikan penalti berat pada algoritme untuk melewatkan gambar porno. Saya sangat merekomendasikan memilih metrik baru dan menggunakan metrik baru ini untuk secara eksplisit menetapkan tujuan baru bagi tim, daripada terus bekerja terlalu lama dengan metrik yang tidak tepercaya, mengembalikan setiap waktu ke pemilihan manual antara pengklasifikasi.
Ini adalah pendekatan yang cukup umum untuk mengubah sampel dev / test atau mengubah metrik penilaian kualitas saat mengerjakan proyek. Memiliki sampel dev / test asli dan metrik memungkinkan Anda untuk segera mulai mengulangi proyek Anda. Jika Anda bahkan menemukan bahwa dev atau tes pilihan yang dipilih atau metrik tidak lagi mengarahkan tim Anda ke arah yang benar, itu tidak masalah! Ubah saja dan pastikan tim Anda tahu tentang arah baru.
12 Rekomendasi: Kami menyiapkan validasi (pengembangan) dan sampel uji
- Pilih dev dan uji sampel dari distribusi yang mencerminkan data yang Anda harapkan akan diterima di masa depan dan di mana Anda ingin algoritma Anda bekerja dengan baik. Sampel-sampel ini mungkin tidak sesuai dengan distribusi dataset pelatihan Anda.
- Pilih perangkat uji dev dari distribusi yang sama, jika memungkinkan
- Pilih metrik satu-parameter untuk mengevaluasi kualitas algoritma untuk optimasi untuk tim Anda. Jika Anda memiliki beberapa tujuan yang harus Anda capai pada saat yang bersamaan, pertimbangkan untuk menggabungkannya ke dalam satu rumus (seperti metrik kesalahan multiparameter rata-rata) atau tentukan metrik restriktif dan optimisasi.
- Pembelajaran mesin adalah proses yang sangat berulang: Anda dapat mencoba banyak ide sebelum menemukan yang memuaskan Anda.
- Keberadaan sampel uji / dev dan metrik penilaian kualitas satu-parameter akan membantu Anda dengan cepat mengevaluasi algoritma, dan karenanya, beralih lebih cepat.
- Ketika pengembangan aplikasi baru dimulai, cobalah untuk cepat menginstal sampel dev / test dan metrik penilaian kualitas, katakanlah, menghabiskan tidak lebih dari seminggu untuk ini. Untuk aplikasi yang matang, adalah normal jika proses ini memakan waktu lebih lama.
- Heuristik lama yang baik membagi pelatihan dan sampel uji 70% hingga 30% tidak berlaku untuk masalah di mana ada sejumlah besar data; sampel dev / tes dapat secara signifikan kurang dari 30% dari semua data yang tersedia.
- Jika sampel pengembangan dan metrik Anda tidak lagi memberi tahu tim Anda arah yang benar, cepat ubah itu: (i) jika algoritma Anda dilatih ulang pada set validasi (set dev), tambahkan lebih banyak data ke dalamnya (dalam set dev Anda). (ii) Jika distribusi data nyata, kualitas algoritma yang perlu Anda tingkatkan, berbeda dengan distribusi data dalam validasi dan (atau) sampel uji (dev / set tes), buat sampel baru untuk pengujian dan pengembangan (dev / set tes), menggunakan data lain. (iii) Jika metrik penilaian kualitas Anda tidak lagi mengukur apa yang paling penting untuk proyek Anda, ubah metrik itu.
13 Bangun sistem pertama Anda dengan cepat lalu tingkatkan secara iteratif
Anda ingin membangun untuk membangun sistem anti-spam baru untuk email. Tim Anda memiliki beberapa ide:
- Kumpulkan sampel pelatihan besar yang terdiri dari email spam. Misalnya, siapkan umpan: sengaja mengirim alamat email palsu ke pengirim spam yang dikenal, sehingga Anda dapat secara otomatis mengumpulkan email spam yang akan mereka kirim ke alamat-alamat ini.
- Kembangkan tanda-tanda untuk memahami konten teks surat itu
- Untuk mengembangkan tanda-tanda untuk memahami kulit surat / pos, tanda-tanda yang menunjukkan melalui server Internet mana surat itu dilewati
- dan sebagainya
Meskipun saya bekerja keras pada aplikasi anti-spam, masih akan sulit bagi saya untuk memilih salah satu dari area ini. Akan lebih sulit lagi jika Anda bukan ahli dalam bidang yang sedang dikembangkan aplikasi tersebut.
Karena itu, jangan mencoba membangun sistem yang ideal sejak awal. Alih-alih, bangun dan latih sistem yang sederhana secepat mungkin, mungkin dalam beberapa hari.
Catatan Penulis: Tip ini ditujukan untuk pembaca yang ingin mengembangkan aplikasi AI, bukan untuk mereka yang tujuannya adalah untuk mempublikasikan artikel akademik. Nanti, saya akan kembali ke topik penelitian.
Sekalipun sistem yang sederhana jauh dari sistem "ideal" yang dapat Anda bangun, akan berguna untuk mempelajari cara kerja sistem sederhana ini: Anda akan dengan cepat menemukan tip yang menunjukkan kepada Anda area yang paling menjanjikan di mana Anda harus menginvestasikan waktu Anda. Beberapa bab berikut akan menunjukkan cara membaca tips ini.
14 Analisis kesalahan: Lihat contoh yang diberikan dev untuk ide.

Ketika Anda bermain dengan aplikasi kucing Anda, Anda memperhatikan beberapa contoh di mana aplikasi mengira anjing untuk kucing. Beberapa anjing terlihat seperti kucing!
Salah satu anggota tim menyarankan untuk memperkenalkan perangkat lunak pihak ketiga yang akan meningkatkan kinerja sistem dalam foto-foto anjing. Implementasi perubahan akan memakan waktu satu bulan, anggota tim yang mengajukannya antusias. Keputusan apa yang harus Anda ambil?
Sebelum berinvestasi sebulan untuk menyelesaikan masalah ini, saya sarankan Anda terlebih dahulu mengevaluasi bagaimana solusinya akan meningkatkan kualitas sistem. Maka Anda dapat lebih rasional memutuskan apakah perlu perbaikan sebulan pembangunan atau apakah akan lebih baik menggunakan waktu ini untuk memecahkan masalah lain.
Secara khusus, apa yang dapat dilakukan dalam kasus ini:
- Kumpulkan sampel 100 contoh dari set dev yang diklasifikasikan oleh sistem Anda dengan salah. Yaitu, contoh di mana sistem Anda membuat kesalahan.
- Pelajari contoh-contoh ini dan hitung berapa banyak gambar anjing itu.
Proses mempelajari contoh-contoh yang membuat kesalahan pengklasifikasi disebut "analisis kesalahan". Dalam contoh ini, misalkan Anda menemukan bahwa hanya 5% dari gambar yang salah klasifikasi adalah anjing, maka tidak masalah seberapa besar Anda meningkatkan kinerja algoritma Anda pada gambar anjing, Anda tidak akan bisa mendapatkan kualitas yang lebih baik daripada 5% dari tingkat kesalahan Anda . Dengan kata lain, 5% adalah "plafon" (menyiratkan jumlah setinggi mungkin) sejauh perbaikan yang diharapkan dapat membantu. Dengan demikian, jika keseluruhan sistem Anda saat ini memiliki keakuratan 90% (10% kesalahan), peningkatan ini dimungkinkan, paling baik akan meningkatkan hasilnya menjadi akurasi 90,5% (atau tingkat kesalahan akan menjadi 9,5%, yaitu 5% lebih sedikit dari aslinya 10% kesalahan)
Sebaliknya, jika Anda menemukan bahwa 50% kesalahan adalah anjing, maka Anda dapat lebih yakin bahwa proyek yang diusulkan untuk meningkatkan sistem akan memiliki efek besar. Ini dapat meningkatkan akurasi dari 90% menjadi 95% (pengurangan kesalahan relatif 50% dari 10% menjadi 5%)
Prosedur evaluasi sederhana untuk analisis kesalahan ini memungkinkan Anda untuk dengan cepat mengevaluasi manfaat yang mungkin dari penerapan perangkat lunak klasifikasi gambar anjing pihak ketiga. Ini memberikan penilaian kuantitatif untuk memutuskan kelayakan waktu investasi dalam implementasinya.
Analisis kesalahan sering dapat membantu untuk memahami betapa menjanjikan berbagai arah untuk pekerjaan di masa depan. Saya telah mengamati bahwa banyak insinyur enggan menganalisis kesalahan. Seringkali tampak lebih menarik untuk sekadar terburu-buru memasuki sebuah gagasan daripada mencari tahu apakah gagasan itu sepadan dengan waktu yang dibutuhkan. Ini adalah kesalahan umum: Hal ini dapat mengarah pada fakta bahwa tim Anda akan menghabiskan waktu sebulan hanya untuk memahami setelah fakta bahwa hasilnya adalah peningkatan yang dapat diabaikan.
Verifikasi manual 100 contoh dari sampel, tidak lama. Bahkan jika Anda menghabiskan satu menit pada gambar, seluruh pemeriksaan akan memakan waktu kurang dari 2 jam. Dua jam ini dapat menghemat satu bulan upaya sia-sia.
kelanjutan