Dalam kasus organisasi layanan microser dari aplikasi, pekerjaan substansial bertumpu pada mekanisme koneksi integrasi layanan microser. Selain itu, integrasi ini harus toleran terhadap kesalahan, dengan tingkat ketersediaan yang tinggi.
Dalam solusi kami, kami menggunakan integrasi dengan Kafka, gRPC, dan RabbitMQ.
Pada artikel ini, kami akan berbagi pengalaman kami tentang pengelompokan RabbitMQ, yang simpulnya di-host di Kubernetes.

Sebelum RabbitMQ versi 3.7, mengelompokkannya dalam K8S bukanlah tugas yang sangat sepele, dengan banyak peretasan dan bukan solusi yang sangat indah. Pada versi 3.6, plugin autocluster dari RabbitMQ Community digunakan. Dan di 3,7 Kubernetes Peer Discovery Backend muncul. Ini built-in oleh plug-in dalam pengiriman dasar RabbitMQ dan tidak memerlukan perakitan dan instalasi terpisah.
Kami akan menggambarkan konfigurasi final secara keseluruhan, sambil mengomentari apa yang terjadi.
Secara teori
Plugin memiliki
repositori di github , di mana ada
contoh penggunaan dasar .
Contoh ini tidak dimaksudkan untuk Produksi, yang secara jelas ditunjukkan dalam uraiannya, dan terlebih lagi, beberapa pengaturan di dalamnya diatur bertentangan dengan logika penggunaan dalam produk. Juga, dalam contoh ini, kegigihan penyimpanan tidak disebutkan sama sekali, jadi dalam situasi darurat apa pun cluster kami akan berubah menjadi nihil.
Dalam praktek
Sekarang kami akan memberi tahu Anda apa yang Anda hadapi sendiri dan cara menginstal dan mengkonfigurasi RabbitMQ.
Mari kita gambarkan konfigurasi semua bagian RabbitMQ sebagai layanan di K8s. Kami akan segera mengklarifikasi bahwa kami menginstal RabbitMQ di K8 sebagai StatefulSet. Pada setiap node dari cluster K8s, satu instance dari RabbitMQ akan selalu berfungsi (satu node dalam konfigurasi cluster klasik). Kami juga akan menginstal panel kontrol RabbitMQ di K8 dan memberikan akses ke panel ini di luar cluster.
Hak dan peran:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
Hak akses untuk RabbitMQ diambil sepenuhnya dari contoh, tidak diperlukan perubahan di dalamnya. Kami membuat ServiceAccount untuk kluster kami dan memberikannya izin baca ke Endpoints K8s.
Penyimpanan Persisten:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
Di sini kami mengambil kasus paling sederhana sebagai penyimpanan persisten - hostPath (folder reguler pada setiap simpul K8), tetapi Anda dapat menggunakan salah satu dari banyak jenis volume persisten yang didukung oleh K8.
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
Buat Klaim Volume pada volume yang dibuat pada langkah sebelumnya. Klaim ini kemudian akan digunakan di StatefulSet sebagai penyimpan data yang persisten.
Layanan:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
Kami membuat layanan tanpa kepala internal di mana plugin Peer Discovery akan berfungsi.
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
Untuk aplikasi di K8 agar berfungsi dengan kluster kami, kami membuat layanan penyeimbang.
Karena kita membutuhkan akses ke cluster RabbitMQ di luar K8s, kita menggulir melalui NodePort. RabbitMQ akan tersedia ketika mengakses node cluster K8 pada port 31673 dan 30673. Dalam pekerjaan nyata, tidak ada kebutuhan besar untuk ini. Pertanyaan tentang kenyamanan menggunakan panel admin RabbitMQ.
Saat membuat layanan dengan tipe NodePort di K8s, layanan dengan tipe ClusterIP juga secara implisit dibuat untuk melayaninya. Oleh karena itu, aplikasi dalam K8 yang perlu bekerja dengan RabbitMQ kami akan dapat mengakses cluster di
amqp: // rabbitmq: 5672Konfigurasi:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Kami membuat file konfigurasi RabbitMQ. Keajaiban utama.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
Tambahkan plugin yang diperlukan ke yang diizinkan untuk diunduh. Sekarang kita dapat menggunakan Peer Discovery otomatis di K8S.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
Kami mengekspos plugin yang diperlukan sebagai backend untuk penemuan rekan.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
Tentukan alamat dan port yang melaluinya Anda dapat mencapai apiserver kubernetes. Di sini Anda dapat menentukan alamat-IP secara langsung, tetapi akan lebih indah untuk melakukannya.
Dalam namespace default, sebuah layanan biasanya dibuat dengan nama kubernet yang mengarah ke apiserver k8. Dalam opsi instalasi K8S yang berbeda, namespace, nama layanan, dan port mungkin berbeda. Jika ada sesuatu dalam instalasi tertentu yang berbeda, Anda harus memperbaikinya.
Sebagai contoh, kita dihadapkan dengan fakta bahwa di beberapa cluster layanan ada di port 443, dan di beberapa 6443. Akan mungkin untuk memahami bahwa ada sesuatu yang salah dalam log awal RabbitMQ, waktu koneksi ke alamat yang ditentukan di sini jelas disorot di sana.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
Secara default, contoh menentukan jenis alamat node cluster RabbitMQ berdasarkan alamat IP. Tetapi ketika Anda me-restart pod, ia mendapat IP baru setiap saat. Kejutan! Cluster sedang sekarat dalam penderitaan.
Ubah pengalamatan ke nama host. StatefulSet menjamin kita tidak berubahnya nama host dalam siklus hidup seluruh StatefulSet, yang sepenuhnya cocok untuk kita.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
Karena ketika kita kehilangan salah satu node, kita berasumsi bahwa itu akan pulih cepat atau lambat, kita menonaktifkan penghapusan-diri oleh sekelompok node yang tidak dapat diakses. Dalam hal ini, segera setelah node kembali online, ia akan memasuki cluster tanpa kehilangan status sebelumnya.
cluster_partition_handling = autoheal
Parameter ini menentukan tindakan cluster jika kehilangan kuorum. Di sini Anda hanya perlu membaca
dokumentasi tentang topik ini dan memahami sendiri apa yang lebih dekat dengan kasus penggunaan tertentu.
queue_master_locator=min-masters
Tentukan pilihan panduan untuk antrian baru. Dengan pengaturan ini, wizard akan memilih node dengan jumlah antrian paling sedikit, sehingga antrian akan didistribusikan secara merata di seluruh node cluster.
cluster_formation.k8s.service_name = rabbitmq-internal
Kami menamai layanan K8 tanpa kepala (dibuat oleh kami sebelumnya) di mana node RabbitMQ akan berkomunikasi satu sama lain.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Satu hal penting untuk pengalamatan dalam sebuah cluster adalah nama host. FQDN dari perapian K8s dibentuk sebagai nama pendek (rabbitmq-0, rabbitmq-1) + akhiran (bagian domain). Di sini kami menunjukkan sufiks ini. Di K8S, sepertinya
. <Nama layanan>. <Namespace name> .svc.cluster.localkube-dns menyelesaikan nama bentuk rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local ke alamat IP pod tertentu tanpa konfigurasi tambahan, yang memungkinkan semua keajaiban pengelompokan berdasarkan nama host menjadi mungkin.
Konfigurasi StatefulSet RabbitMQ:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Sebenarnya, StatefulSet sendiri. Kami mencatat poin-poin menarik.
serviceName: rabbitmq-internal
Kami menulis nama layanan tanpa kepala yang digunakan pod berkomunikasi di StatefulSet.
replicas: 3
Tetapkan jumlah replika di cluster. Di negara kita, itu sama dengan jumlah node yang bekerja K8.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
Ketika salah satu node K8 jatuh, statefulset berusaha untuk mempertahankan jumlah instance dalam set, oleh karena itu, ia menciptakan beberapa perapian pada node K8 yang sama. Perilaku ini benar-benar tidak diinginkan dan, pada prinsipnya, tidak ada gunanya. Oleh karena itu, kami meresepkan aturan anti-afinitas untuk set perapian dari statefulset. Kami membuat aturan sulit (Diperlukan) sehingga kube-scheduler tidak dapat melanggarnya ketika merencanakan pod.
Intinya sederhana: dilarang untuk penjadwal untuk menempatkan (dalam namespace) lebih dari satu pod dengan
aplikasi: tag rabbitmq pada setiap node. Kami membedakan
node dengan nilai label
kubernetes.io/hostname . Sekarang, jika karena alasan tertentu jumlah node K8S yang bekerja kurang dari jumlah replika yang diperlukan di StatefulSet, replika baru tidak akan dibuat sampai simpul bebas muncul lagi.
serviceAccountName: rabbitmq
Kami mendaftarkan ServiceAccount, tempat pod kami bekerja.
image: rabbitmq:3.7
Gambar RabbitMQ sepenuhnya standar dan diambil dari hub docker, tidak memerlukan pembangunan kembali dan revisi file.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
Data persisten dari RabbitMQ disimpan di / var / lib / rabbitmq / mnesia. Di sini kita memasang Klaim Volume Persisten kami di folder ini sehingga ketika memulai kembali tungku / node atau bahkan seluruh StatefulSet, data (kedua layanan, termasuk tentang kumpulan rakitan, dan data pengguna) aman dan sehat. Ada beberapa contoh di mana seluruh folder / var / lib / rabbitmq / dibuat persisten. Kami sampai pada kesimpulan bahwa ini bukan ide terbaik, karena pada saat yang sama semua informasi yang ditetapkan oleh konfigurasi Kelinci mulai diingat. Artinya, untuk mengubah sesuatu dalam file konfigurasi, Anda perlu membersihkan penyimpanan persisten, yang sangat tidak nyaman dalam pengoperasian.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
Dengan set variabel lingkungan ini, pertama-tama kami memberi tahu RabbitMQ untuk menggunakan nama FQDN sebagai pengidentifikasi untuk anggota cluster, dan kedua, kami mengatur format nama ini. Format telah dijelaskan sebelumnya ketika mem-parsing konfigurasi.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
Nama layanan tanpa kepala untuk komunikasi antara anggota cluster.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
Isi Cookie Erlang harus sama pada semua node cluster, Anda harus mendaftarkan nilai Anda sendiri. Node dengan cookie berbeda tidak bisa masuk ke cluster.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Tetapkan volume yang dipetakan dari Klaim Volume Persisten yang dibuat sebelumnya.
Di sinilah kita selesai dengan pengaturan di K8s. Hasilnya adalah cluster RabbitMQ, yang mendistribusikan antrian di antara node secara merata dan tahan terhadap masalah di lingkungan runtime.
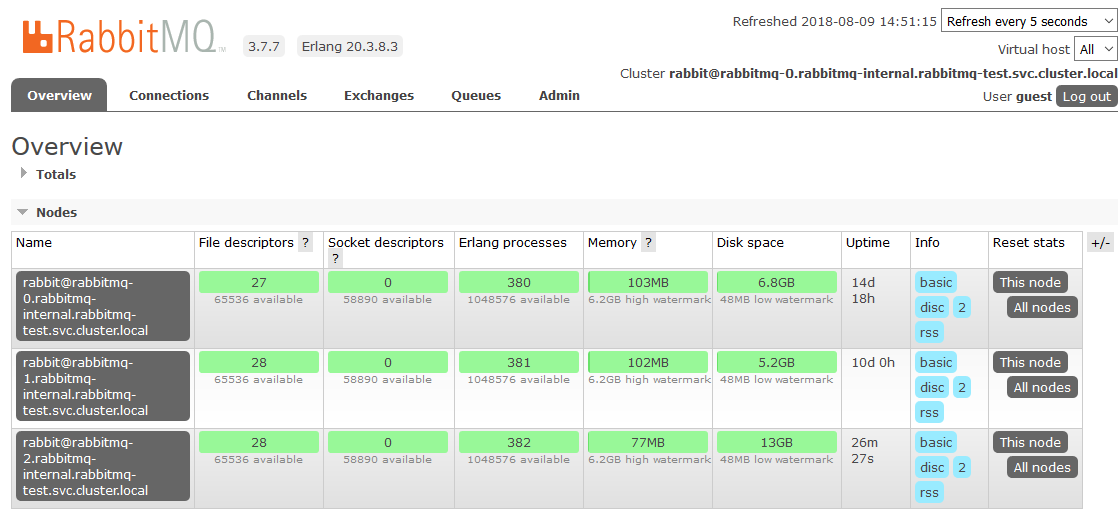
Jika salah satu node cluster tidak tersedia, antrian yang ada di dalamnya akan berhenti diakses, semuanya akan terus berfungsi. Segera setelah node kembali ke operasi, ia akan kembali ke cluster, dan antrian yang menjadi Master akan operasional kembali, menjaga semua data yang terkandung di dalamnya (jika penyimpanan persisten tidak rusak, tentu saja). Semua proses ini sepenuhnya otomatis dan tidak memerlukan intervensi.
Bonus: sesuaikan HA
Salah satu proyeknya adalah nuansa. Persyaratan terdengar mirroring lengkap dari semua data yang terkandung dalam cluster. Ini diperlukan agar dalam situasi di mana setidaknya satu node cluster operasional, semuanya terus bekerja dari sudut pandang aplikasi. Momen ini tidak ada hubungannya dengan K8, kami menggambarkannya hanya sebagai mini how-to.
Untuk mengaktifkan HA penuh, Anda perlu membuat Kebijakan di dasbor RabbitMQ pada
Admin -> tab
Kebijakan . Namanya arbitrer, Pola kosong (semua antrian), di Definisi menambahkan dua parameter:
mode-ha: semua ,
mode-ha-sinkronisasi: otomatis .
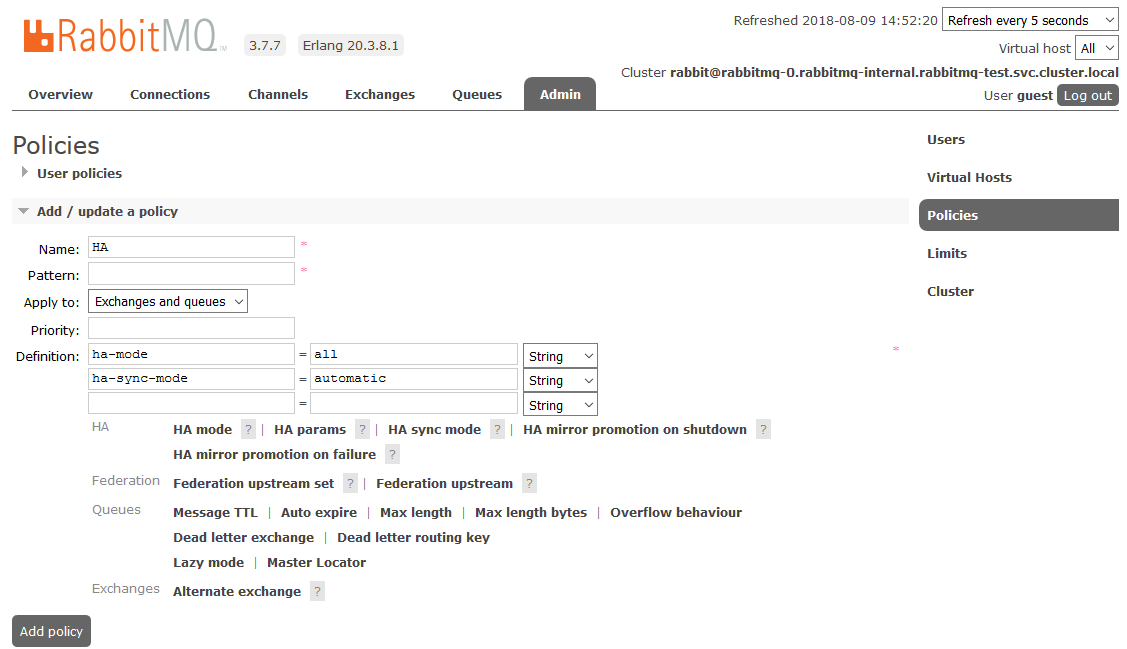
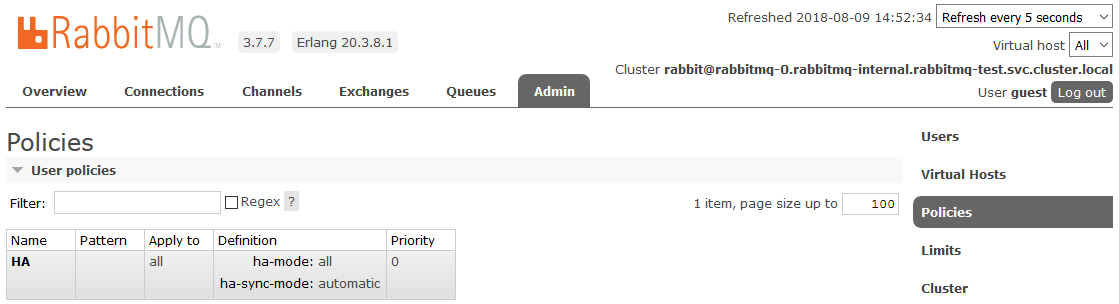
Setelah itu, semua antrian yang dibuat dalam kluster akan berada dalam mode Ketersediaan Tinggi: jika simpul Master tidak tersedia, salah satu Budak akan secara otomatis dipilih oleh wizard baru. Dan data yang masuk ke antrian akan dicerminkan ke semua node cluster. Yang sebenarnya harus diterima.
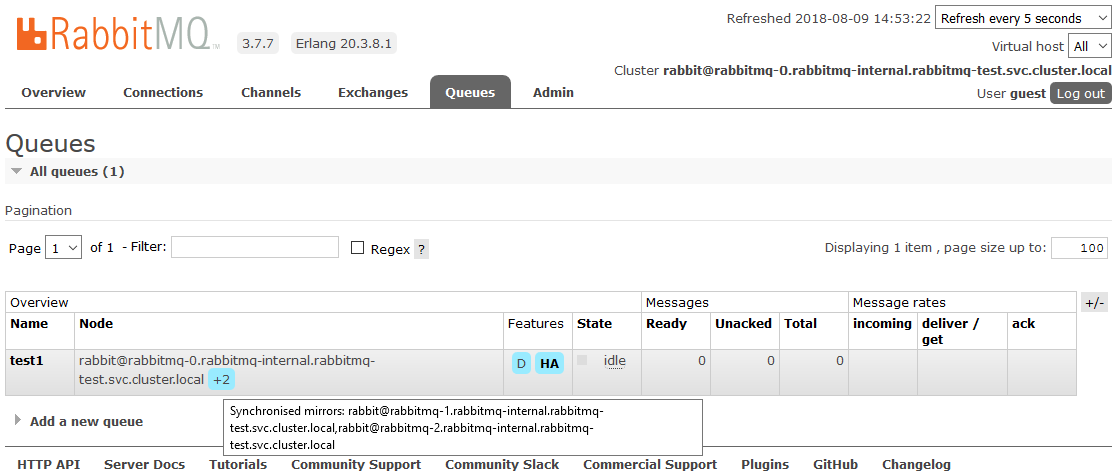
Baca lebih lanjut tentang HA di RabbitMQ di
siniLiteratur yang berguna:
Semoga beruntung