Halo, Habr! Saya mempersembahkan kepada Anda terjemahan artikel "
Mendeteksi Sarkasme dengan Jaringan Neural Konvolusional Dalam " oleh Elvis Saravia.
Salah satu masalah utama dalam pemrosesan bahasa alami adalah deteksi sarkasme. Mendeteksi sarkasme penting di bidang lain, seperti komputasi emosional dan analisis suasana hati, karena hal ini mungkin mencerminkan polaritas kalimat.
Artikel ini menunjukkan cara mendeteksi sarkasme dan juga menyediakan tautan ke
detektor sarkasme jaringan saraf .
Sarkasme dapat dilihat sebagai ekspresi ejekan yang menyengat, atau ironi. Contoh sarkasme: "Saya bekerja 40 jam seminggu untuk tetap miskin," atau "Jika pasien benar-benar ingin hidup, dokter tidak berdaya."
Untuk memahami dan mendeteksi sarkasme, penting untuk memahami fakta yang terkait dengan peristiwa tersebut. Ini mengungkapkan kontradiksi antara polaritas objektif (biasanya negatif) dan karakteristik sarkastik yang disampaikan oleh penulis (biasanya positif).
Perhatikan contohnya: "Saya suka rasa sakit berpisah."
Sulit untuk memahami artinya jika ada sarkasme dalam pernyataan ini. Dalam contoh ini, "I like pain" memberi pengetahuan tentang perasaan yang diungkapkan oleh penulis (dalam hal ini, positif), dan "perpisahan" menggambarkan perasaan yang bertentangan (negatif).
Masalah lain yang ada dalam memahami pernyataan sarkastik adalah referensi ke beberapa peristiwa dan kebutuhan untuk mengekstraksi sejumlah besar fakta, akal sehat dan penalaran logis.
Model
"Pergeseran suasana hati" sering hadir dalam komunikasi di mana ada sarkasme; dengan demikian, diusulkan untuk terlebih dahulu menyiapkan model suasana hati (berdasarkan CNN) untuk mengekstrak tanda-tanda suasana hati. Model memilih fitur lokal di lapisan pertama, yang kemudian diubah menjadi fitur global di tingkat yang lebih tinggi. Ekspresi sarkastik adalah spesifik pengguna - beberapa pengguna menggunakan lebih banyak sarkasme daripada yang lain.
Dalam model yang diusulkan untuk deteksi sarkasme digunakan, ciri-ciri kepribadian, tanda-tanda suasana hati dan tanda-tanda berdasarkan emosi. Satu set detektor adalah kerangka kerja yang dirancang untuk mendeteksi sarkasme. Setiap set atribut dipelajari oleh model pra-terlatih yang terpisah.
Kerangka CNN
CNN efektif dalam memodelkan hierarki fitur lokal untuk menyoroti fitur global, yang diperlukan untuk memeriksa konteksnya. Input data disajikan sebagai vektor kata. Untuk pemrosesan awal input data, word2vec dari Google digunakan. Parameter vektor diperoleh pada tahap pelatihan. Serikat maksimum kemudian diterapkan ke peta fungsi untuk membuat fungsi. Setelah lapisan sepenuhnya terikat, ada lapisan softmax untuk mendapatkan prediksi akhir.
Arsitekturnya ditunjukkan pada gambar di bawah ini.
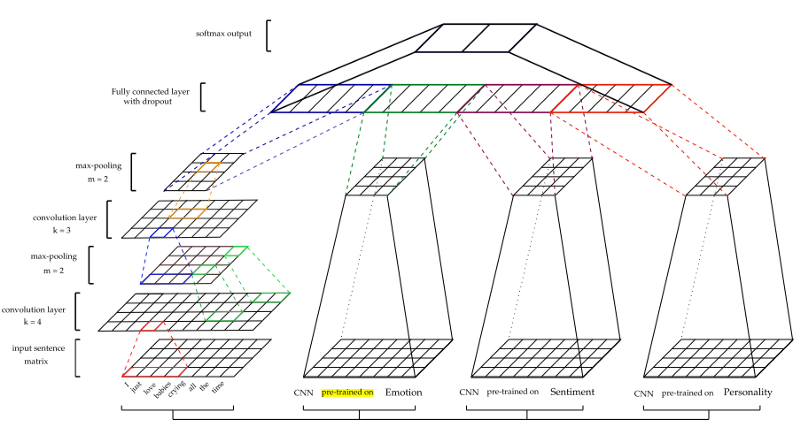
Untuk mendapatkan fitur-fitur lain - mood (S), emosi (E), dan kepribadian (P) - model CNN menjalani pelatihan pendahuluan dan digunakan untuk mengekstraksi ciri-ciri dari set data sarkasme. Untuk pelatihan setiap model, set data pelatihan yang berbeda digunakan. (Untuk lebih jelasnya lihat dokumen)
Dua pengklasifikasi diuji - CNN-classifier (CNN) murni dan karakteristik CNN-extracted diteruskan ke classifier SVM (CNN-SVM).
Klasifikasi dasar terpisah (B) juga dilatih, hanya terdiri dari model CNN tanpa dimasukkannya model lain (misalnya, emosi dan suasana hati).
Eksperimennya
Data Set data seimbang dan tidak seimbang diperoleh dari (Ptacek et al., 2014) dan
detektor sarkasme . Nama pengguna, URL, dan tag hash dihapus, kemudian tokenizer NLTK Twitter diterapkan.
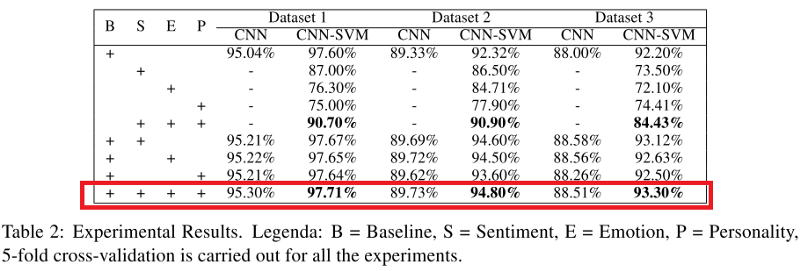
Metrik dari CNN dan CNN-SVM classifier yang diterapkan untuk semua set data ditunjukkan pada tabel di bawah ini. Anda mungkin memperhatikan bahwa ketika suatu model (khususnya, CNN-SVM) menggabungkan tanda-tanda sarkasme, tanda-tanda emosi, perasaan dan sifat-sifat karakter, itu melampaui semua model lain, dengan pengecualian model dasar (B).
Kemungkinan generalisasi model diuji, dan kesimpulan utama adalah bahwa jika set data berbeda di alam, ini secara signifikan mempengaruhi hasil, yang ditunjukkan pada gambar di bawah ini. Misalnya, pelatihan dilakukan pada dataset 1 dan diuji pada dataset 2; Skor F1 model adalah 33,05%.