Di perusahaan, tim kami untuk melawan serangan DDoS disebut "packet droppers". Sementara semua tim lain melakukan hal-hal keren dengan lalu lintas melewati jaringan kami, kami senang menemukan cara baru untuk menghilangkannya.
 Foto: Brian Evans , CC BY-SA 2.0
Foto: Brian Evans , CC BY-SA 2.0Kemampuan untuk dengan cepat menjatuhkan paket sangat penting dalam menentang serangan DDoS.
Paket drop yang mencapai server kami dapat dilakukan di beberapa level. Setiap metode memiliki pro dan kontra. Di bawah potongan, kami melihat semua yang kami uji.
Catatan Penerjemah: dalam output beberapa perintah yang disajikan, spasi tambahan dihapus untuk menjaga keterbacaan.
Situs uji
Untuk kenyamanan dalam membandingkan metode, kami akan memberi Anda beberapa angka, namun, jangan menerimanya secara harfiah, karena kepalsuan tes. Kami akan menggunakan salah satu kartu jaringan Intel 10Gb / s kami. Karakteristik server yang tersisa tidak begitu penting, karena kami ingin fokus pada batasan sistem operasi, bukan perangkat keras.
Tes kami akan terlihat sebagai berikut:
- Kami menciptakan banyak paket kecil UDP, mencapai nilai 14 juta paket per detik;
- Semua lalu lintas ini diarahkan ke satu inti prosesor dari server yang dipilih;
- Kami mengukur jumlah paket yang diproses oleh kernel pada satu inti prosesor.
Lalu lintas buatan dihasilkan sedemikian rupa untuk menciptakan beban maksimum: alamat IP acak dan port pengirim digunakan. Ini seperti apa di tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
Pada server yang dipilih, semua paket akan menjadi dalam satu antrian RX dan, karenanya, akan diproses oleh satu inti. Kami mencapainya dengan kontrol aliran perangkat keras:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Pengujian kinerja adalah proses yang kompleks. Ketika kami menyiapkan tes, kami melihat bahwa keberadaan soket mentah aktif secara negatif mempengaruhi kinerja, jadi sebelum menjalankan tes, Anda perlu memastikan bahwa tidak ada
tcpdump yang berjalan. Ada cara mudah untuk memeriksa proses yang buruk:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Dan akhirnya, kami mematikan Intel Turbo Boost di server kami:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Terlepas dari kenyataan bahwa Turbo Boost adalah hal yang hebat dan meningkatkan throughput setidaknya 20%, itu secara signifikan merusak standar deviasi dalam pengujian kami. Dengan turbo aktif, deviasi mencapai ± 1,5%, sementara tanpa turbo hanya 0,25%.
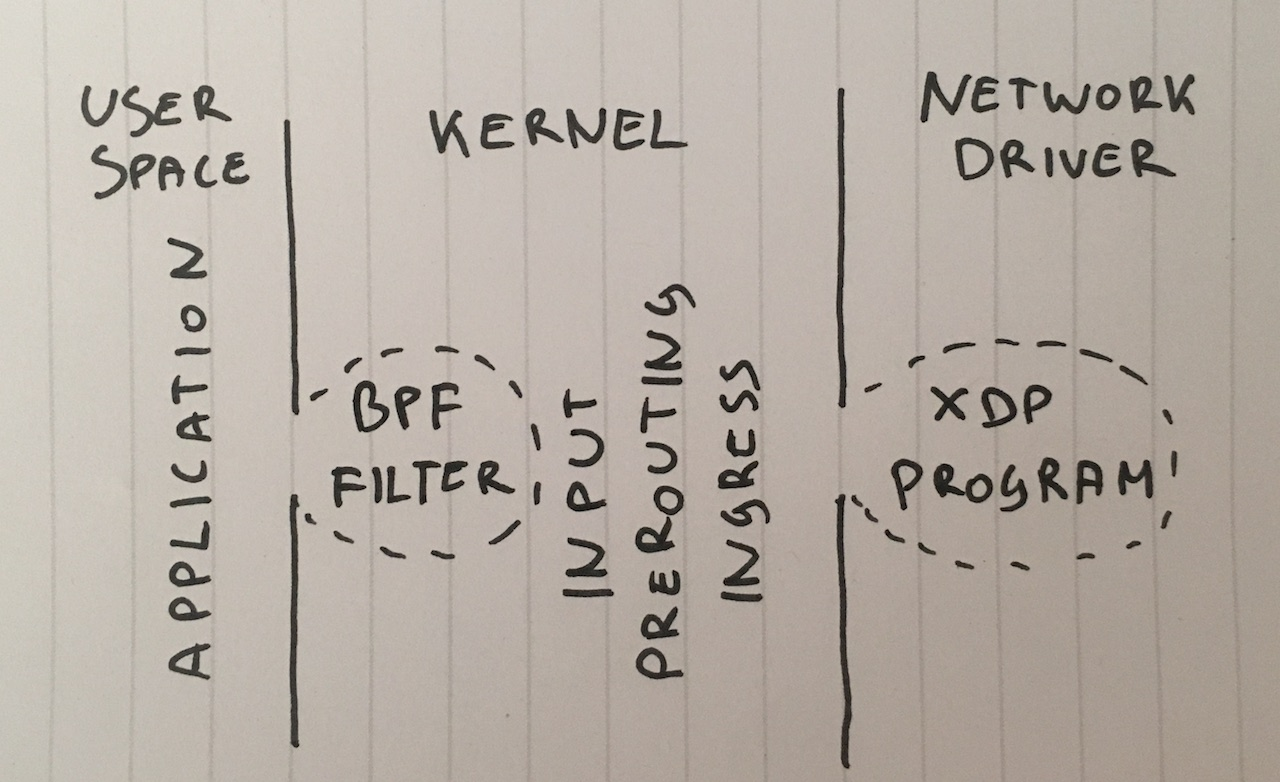
Langkah 1. Jatuhkan paket dalam aplikasi
Mari kita mulai dengan ide untuk mengirimkan semua paket ke aplikasi dan mengabaikannya di sana. Untuk kejujuran percobaan, pastikan iptables tidak memengaruhi kinerja dengan cara apa pun:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Aplikasi adalah siklus sederhana di mana data yang diterima segera dibuang:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
Kami sudah menyiapkan
kode , jalankan:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
Solusi ini memungkinkan kernel untuk mengambil hanya 175 ribu paket dari antrian perangkat keras, seperti yang diukur oleh
ethtool dan
mmwatch kami :
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
Secara teknis, 14 juta paket per detik tiba di server, namun satu inti prosesor tidak dapat mengatasi volume seperti itu.
mpstat mengkonfirmasi ini:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Seperti yang dapat kita lihat, aplikasi ini bukan hambatan: CPU # 1 digunakan pada 27,17% + 2,17%, sementara penanganan interupsi membutuhkan 100% pada CPU # 2.
Menggunakan
recvmessagge(2) memainkan peran penting. Setelah kerentanan Spectre ditemukan, panggilan sistem menjadi lebih mahal karena
KPTI dan
retpoline yang digunakan dalam kernel
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
Langkah 2. Membunuh conntrack
Kami secara khusus membuat beban seperti itu dengan IP dan port pengirim yang berbeda untuk memuat conntrack sebanyak mungkin. Jumlah entri dalam conntrack selama tes cenderung semaksimal mungkin dan kami dapat memverifikasi ini:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
Selain itu, di
dmesg Anda juga dapat melihat jeritan conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
Jadi mari kita matikan:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Dan mulai ulang tes:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
Ini memungkinkan kami untuk mencapai tanda 333 ribu paket per detik. Hore!
PS Menggunakan SO_BUSY_POLL kita dapat mencapai sebanyak 470 ribu per detik, namun, ini adalah topik untuk pos yang terpisah.
Langkah 3. Filter Berkeley Batch
Mari kita lanjutkan. Mengapa kita perlu mengirimkan paket ke aplikasi? Meskipun ini bukan solusi umum, kita dapat mengikat filter paket Berkeley klasik ke soket dengan memanggil
setsockopt(SO_ATTACH_FILTER) dan mengkonfigurasi filter untuk menjatuhkan paket kembali ke kernel.
Siapkan
kodenya , jalankan:
$ ./bpf-drop packets=0 bytes=0
Menggunakan filter paket (filter Berkeley klasik dan lanjutan memberikan kinerja yang hampir sama), kami mendapatkan sekitar 512 ribu paket per detik. Selain itu, menjatuhkan paket selama interupsi membebaskan prosesor dari keharusan membangunkan aplikasi.
Langkah 4. iptables DROP setelah routing
Sekarang kita bisa menjatuhkan paket dengan menambahkan aturan berikut ke iptables di rantai INPUT:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Biarkan saya mengingatkan Anda bahwa kami sudah menonaktifkan conntrack dengan aturan
-j NOTRACK . Dua aturan ini memberi kita 608 ribu paket per detik.
Mari kita lihat angka-angka di iptables:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Yah, tidak buruk, tapi kita bisa berbuat lebih baik.
Langkah 5. iptab DROP dalam PREROUTING
Teknik yang lebih cepat adalah dengan menjatuhkan paket sebelum routing menggunakan aturan ini:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Ini memungkinkan kita untuk menjatuhkan paket besar 1,688 juta per detik.
Sebenarnya, ini adalah lompatan yang sedikit mengejutkan dalam kinerja. Saya masih tidak mengerti alasannya, mungkin rute kami rumit, atau mungkin hanya bug dalam konfigurasi server.
Bagaimanapun, iptables mentah jauh lebih cepat.
Langkah 6. DROP nftables
Utilitas iptables sekarang agak lama. Dia digantikan oleh nftables. Lihat
penjelasan video ini tentang mengapa nftables di atas. Nftables menjanjikan lebih cepat dari iptables yang mulai memutih karena berbagai alasan, termasuk rumor bahwa retpoline banyak memperlambat iptables.
Tetapi artikel kami masih bukan tentang membandingkan iptables dan nftables, jadi mari kita coba yang tercepat yang bisa saya lakukan:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Penghitung dapat dilihat seperti ini:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
Pengait input nftables menunjukkan nilai sekitar 1,53 juta paket. Ini sedikit kurang dari rantai PREROUTING di iptables. Tetapi ada sebuah misteri dalam hal ini: secara teoritis, kait nftables berjalan lebih awal dari iptables PREROUTING dan, karenanya, harus diproses lebih cepat.
Dalam pengujian kami, nftables sedikit lebih lambat dari iptables, tetapi nftables lebih dingin. : P
Langkah 7. tc DROP
Agak tak terduga, kait tc (traffic control) terjadi lebih awal dari iptables PREROUTING. tc memungkinkan kita untuk memilih paket sesuai dengan kriteria sederhana dan, tentu saja, menjatuhkannya. Sintaksnya agak tidak biasa, jadi sebaiknya gunakan
skrip ini untuk konfigurasi. Dan kita membutuhkan aturan yang agak rumit yang terlihat seperti ini:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Dan kita dapat memeriksanya dalam aksi:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
Hook tc memungkinkan kami untuk menjatuhkan hingga 1,8 juta paket per detik pada satu inti. Ini bagus!
Tapi kita bisa melakukannya lebih cepat ...
Langkah 8. XDP_DROP
Dan akhirnya, senjata terkuat kami: XDP -
eXpress Data Path . Menggunakan XDP, kita dapat menjalankan kode Berkley Packet Filter (eBPF) yang diperluas secara langsung dalam konteks driver jaringan dan, yang paling penting, bahkan sebelum mengalokasikan memori untuk
skbuff , yang menjanjikan kita peningkatan kecepatan.
Biasanya, proyek XDP terdiri dari dua bagian:
- kode eBPF yang dapat diunduh
- bootloader yang menempatkan kode di antarmuka jaringan yang benar
Menulis bootloader Anda adalah tugas yang sulit, jadi gunakan saja
chip iproute2 baru dan muat kode dengan perintah sederhana:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Dam Ta!
Kode sumber untuk
program eBPF yang dapat diunduh tersedia di sini . Program melihat karakteristik paket IP seperti protokol UDP, subnet pengirim, dan port tujuan:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
Program XDP harus dibangun menggunakan dentang modern, yang dapat menghasilkan bytecode BPF. Setelah itu, kami dapat mengunduh dan menguji fungsionalitas program BFP:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
Dan kemudian lihat statistik di
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
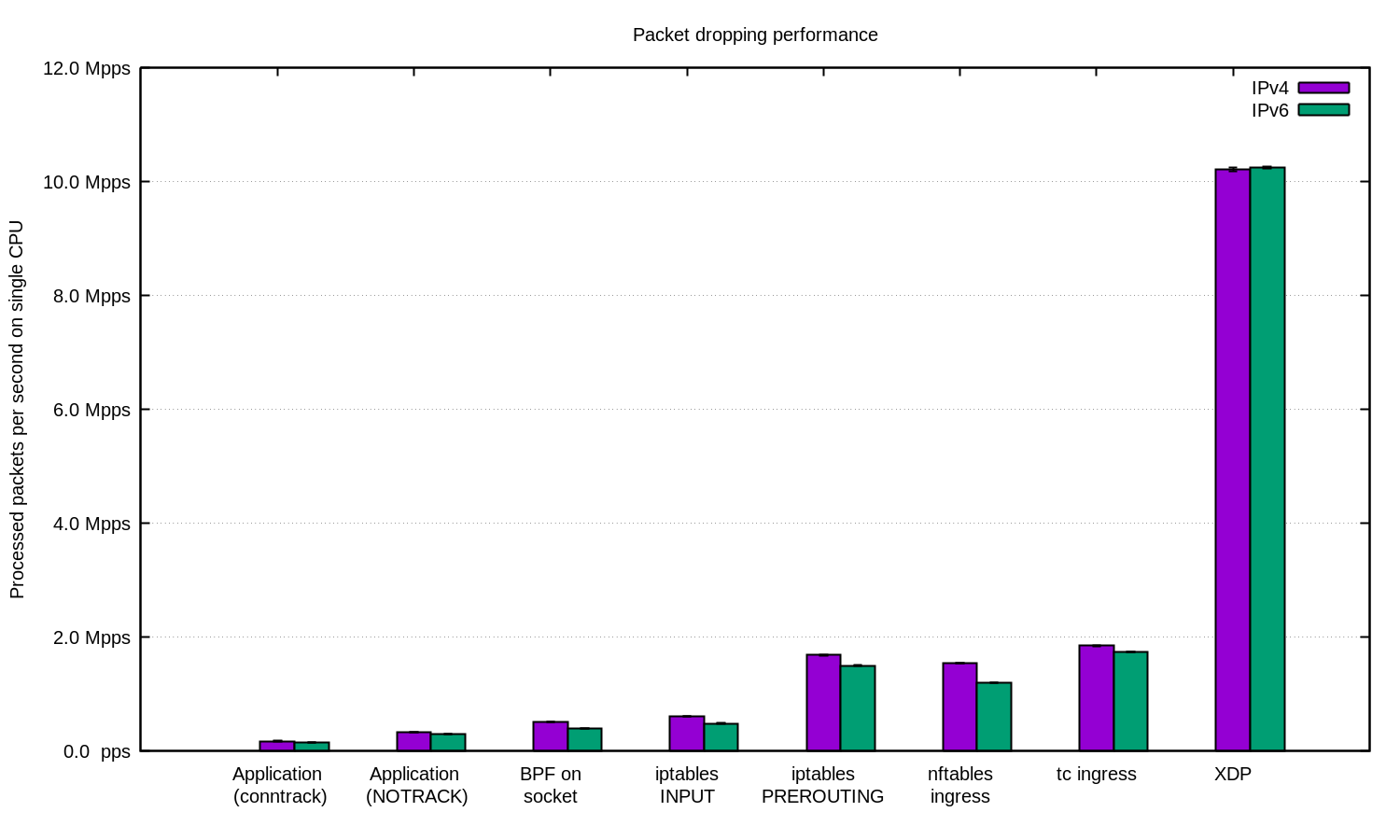
Yoo hoo! Dengan XDP, kita dapat menjatuhkan hingga 10 juta paket per detik!
 Foto: Andrew Filer , CC BY-SA 2.0
Foto: Andrew Filer , CC BY-SA 2.0Kesimpulan
Kami mengulangi percobaan untuk IPv4 dan IPv6 dan menyiapkan diagram ini:
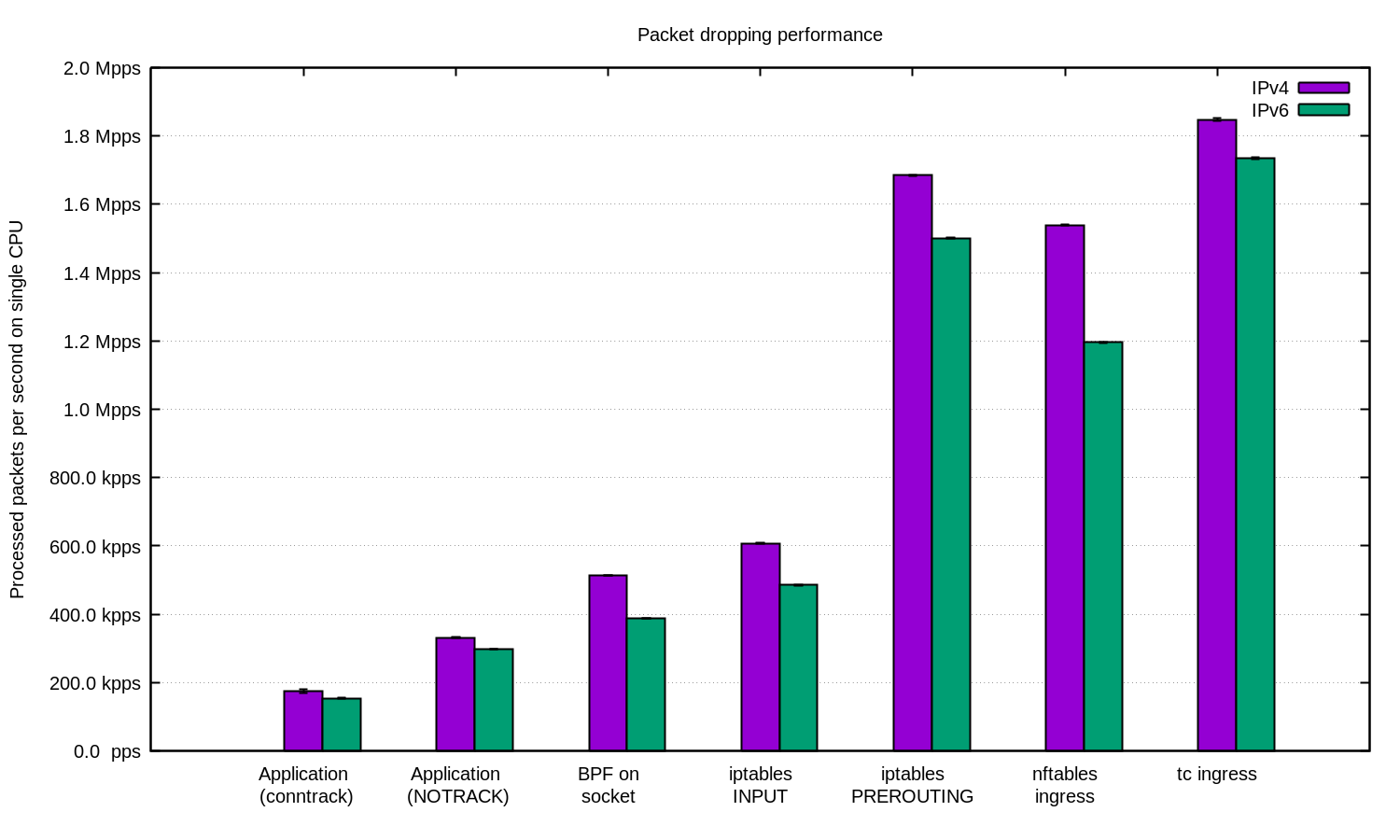
Secara umum, dapat dikatakan bahwa pengaturan kami untuk IPv6 sedikit lebih lambat. Tetapi karena paket IPv6 agak lebih besar, perbedaan dalam kecepatan diharapkan.
Linux memiliki banyak cara untuk memfilter paket, masing-masing dengan kecepatan dan kompleksitasnya sendiri.
Untuk melindungi dari DDoS, cukup masuk akal untuk memberikan paket ke aplikasi dan memprosesnya di sana. Aplikasi yang disesuaikan dengan baik dapat menunjukkan hasil yang baik.
Untuk serangan DDoS dengan IP acak atau spoof mungkin berguna untuk menonaktifkan conntrack untuk mendapatkan peningkatan kecil dalam kecepatan, tetapi berhati-hatilah: ada serangan terhadap yang conntrack sangat berguna.
Dalam kasus lain, masuk akal untuk menambahkan firewall Linux sebagai salah satu cara untuk mengurangi serangan DDoS. Dalam beberapa kasus, lebih baik menggunakan tabel "-t raw PREROUTING", karena jauh lebih cepat daripada tabel filter.
Untuk kasus yang paling canggih, kami selalu menggunakan XDP. Dan ya, ini adalah hal yang sangat kuat. Berikut ini adalah grafik seperti di atas, hanya dengan XDP:
Jika Anda ingin mengulang percobaan, ini adalah
README, tempat kami mendokumentasikan semuanya .
Kami di CloudFlare menggunakan ... hampir semua teknik ini. Beberapa trik dalam ruang pengguna terintegrasi ke dalam aplikasi kami. Teknik iptables ditemukan di
Gatebot kami. Akhirnya, kami mengganti solusi inti kami sendiri dengan XDP.
Terima kasih banyak kepada
Jesper Dangaard Brouer atas bantuan mereka.