Sebagai kelanjutan dari “
debriefing ” dengan HighLoad ++ 2017, kami menyiapkan ulasan singkat dari lima laporan berbahasa Inggris terbaik (menurut peserta konferensi).
Nilai tertinggi diberikan untuk topik yang terkait dengan penggunaan ProxySQL (di TOP 5 ada dua laporan tentang alat ini), pengujian aplikasi di cloud publik Amazon, serta prinsip-prinsip logging pada skala saat ini menjadi masalah, dan pemantauan Apache Kafka.
Kami baru saja memposting video semua laporan HighLoad ++ 2017 untuk akses gratis. Daftar lengkap 150 laporan di saluran YouTube kami di daftar putar ini.
Selain daftar putar ini, saluran ini memiliki beberapa ratus video di basis data, arsitektur, penskalaan, antrian, pembelajaran mesin, dan kebijaksanaan beban tinggi lainnya :)
Mengukur variabillity kinerja EC2
Henrik Ingo (Arsitek Solusi MongoDB, dan sekarang Insinyur Produktivitas Pimpinan di Mongo DB).Laporan pertama, yang dicatat oleh para peserta, berpendapat bahwa cloud publik memang dapat digunakan untuk menguji produk mereka sendiri, termasuk pengujian beban. Dalam hal ini, DBMS MongoDB, yang sedang diuji menggunakan cloud Amazon, adalah "eksperimental". Secara total, sekitar 400 ribu jam dihabiskan untuk tugas ini per bulan, sekitar 5% dari waktu ini hanya berupa tes kinerja, yang tugas utamanya adalah tidak menyediakan optimasi, dan tidak membiarkan "penurunan permukaan" sebagai hasil dari beberapa perbaikan.
Pertanyaan utama dari presentasi adalah bagaimana mendapatkan hasil tes yang dapat direproduksi di cloud publik.
Laporan ini dibangun berdasarkan prinsip analisis hipotesis. Awalnya, Henrik Ingo membuat asumsi tentang faktor apa yang harus memengaruhi tingkat “kebisingan” dalam tes (konsep “kebisingan” dalam laporan memiliki definisi yang sangat spesifik). Misalnya, tim pengujian menyarankan bahwa dalam pengujian "berat" "suara" utama berasal dari hard drive, atau di cloud, saat mendistribusikan sumber daya, Anda dapat mengalami baik (sepenuhnya dialokasikan) atau buruk (dibagi dengan oleh seseorang) contoh yang mempengaruhi hasil tes.
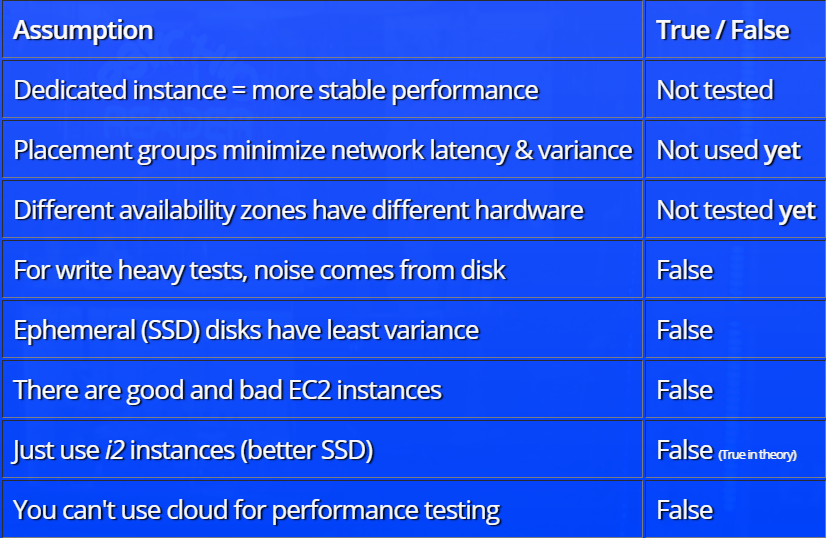
Setelah itu, hasil pengujian masing-masing teori dengan demonstrasi beberapa dependensi menarik dianalisis. Sebagai contoh, berikut adalah grafik ketergantungan tingkat “noise” (dalam terminologi laporan) pada konfigurasi instance yang dipilih:
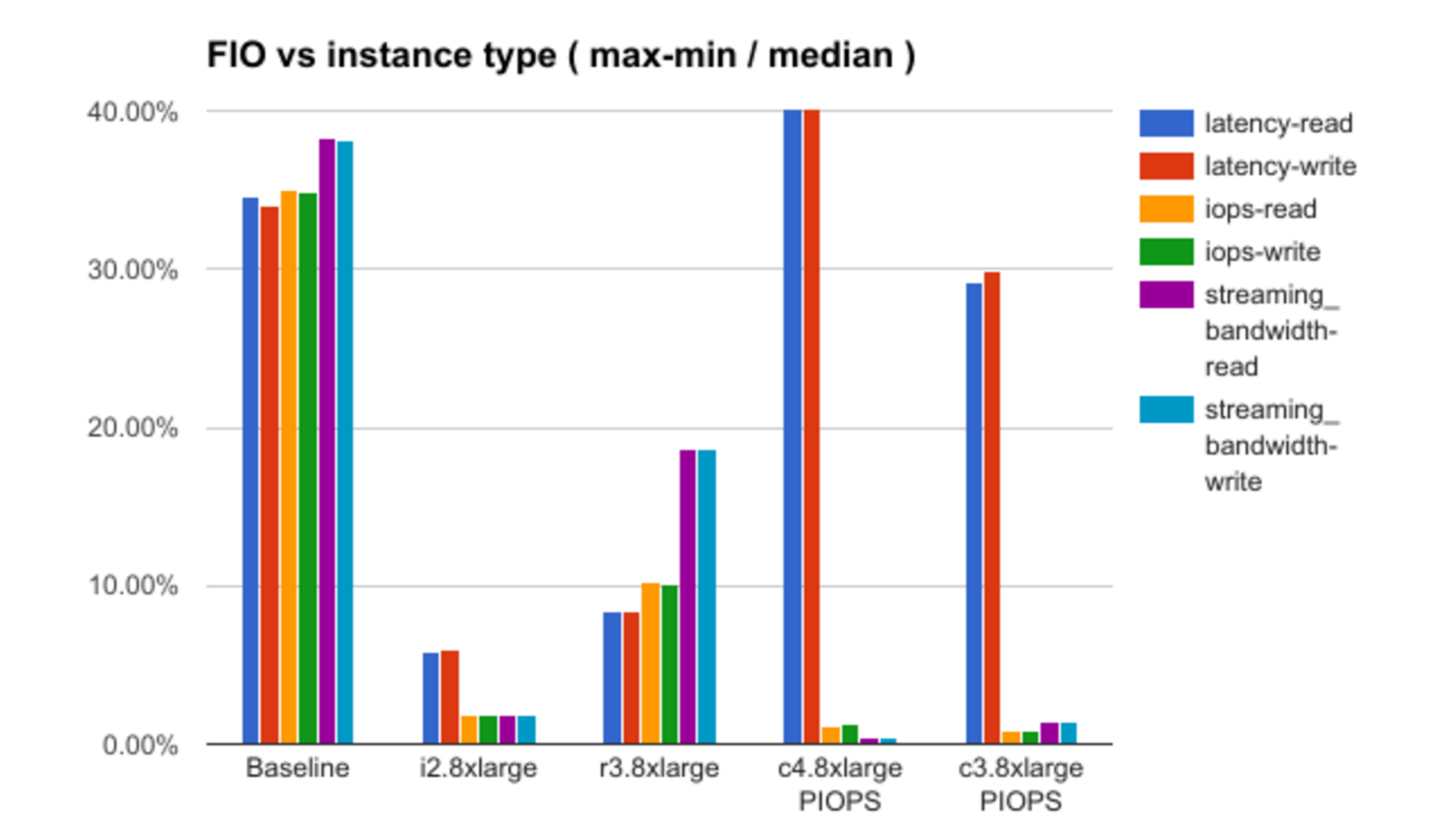
Karena kurangnya informasi tentang rincian infrastruktur Amazon, laporan itu tidak menjawab semua pertanyaan, dalam beberapa kasus hanya membuat asumsi, tetapi ada sesuatu untuk dipikirkan.
Logging dan ocehan
Vytis Valentinavičius (Lamoda, pemimpin operasi)Laporan menarik berikutnya adalah pemikiran seorang spesialis di toko online Lamoda besar tentang logging dan bagaimana seharusnya sehingga pengembang, di satu sisi, menerima data yang diperlukan secara penuh, dan di sisi lain, tidak tenggelam dalam gigabyte informasi yang masuk. Dan pembicara tahu apa yang dia bicarakan. Masalah yang mulai membangun pekerjaan dengan log di Lamoda adalah hilangnya 5% dari laporan yang dikirim oleh pengguna melalui UDP (dalam beberapa kasus bagian ini mencapai 100%). Ini dengan serius mendistorsi semua metrik yang dapat dibangun berdasarkan mereka.
Laporan tersebut mengatakan bagaimana tidak mengungkap situasi seperti itu, tetapi bagaimana mencegahnya, pada prinsipnya, mengingat bahwa banyak solusi yang jelas memiliki jebakan mereka.
Vytis Valentinavičius berfokus pada fakta bahwa log harus memiliki struktur. Tetapi pada saat yang sama tidak bisa meningkat. Harus ada tujuan untuk mengumpulkan dan menyimpan setiap bidang, karena setiap data yang dikumpulkan adalah uang. Contoh dari Lamoda adalah 25 ribu pesan log debug per detik (32 TB informasi per minggu, yang penyimpanannya saja berharga $ 12 ribu).
Selain itu, penting untuk melacak peristiwa, bukan kesalahan spesifik. Mereka perlu dikumpulkan, metrik diidentifikasi, dan berdasarkan analisis mereka untuk membangun peristiwa yang lebih kompleks untuk agregasi masa depan.
Selain pertimbangan teoritis, laporan tersebut menjelaskan beberapa trik yang digunakan Lamoda dalam produksi untuk bekerja dengan log.
Metrik Tidak Cukup: Memantau Apache Kafka
Gwen Shapira (Confluent, product manager)Laporan berikutnya adalah tentang pemantauan Apache Kafka, atau lebih tepatnya, metrik mana yang harus dipilih dari banyaknya parameter yang tersedia untuk analisis untuk memahami status pialang pesan setiap saat.
Pembicara memulai ceritanya dengan lelucon, di mana, seperti yang mereka katakan, hanya ada sebagian kecil dari lelucon itu: "Bahkan jika Anda tidak dapat mengingat isi keseluruhan laporan, ingat satu hal: jika Kafka digunakan dalam produksi, itu perlu dipantau" (bagus, API yang sesuai disediakan untuk ini )
Apakah perlu untuk memantau semuanya? Tergantung pada tugas. Dari merekalah Gwen Shapira menolak, menganalisis metrik yang direkomendasikan. Speaker menjelaskan kasus operasi standar dan merekomendasikan parameter yang harus ditambahkan ke dasbor untuk menanggapi apa yang terjadi tepat waktu, dan bagaimana tidak memperburuk situasi. Secara khusus, sekali lagi mengingatkan bahwa tidak perlu memulai kembali broker pada perubahan metrik pertama, karena dibutuhkan banyak waktu dan kadang-kadang (karena bug yang diketahui) dapat menyebabkan konsekuensi yang lebih serius. Pada akhirnya, metrik hanyalah data awal. Dan untuk membuat keputusan, seseorang harus memiliki hipotesis berdasarkan data ini.

Berkat pengalaman luas Gwen Shapira sebagai konsultan, seluruh presentasi disertai dengan contoh nyata dari kehidupan.
Skenario Penggunaan Kasus ProxySQL
Alkin Tezuysal (Percona, tim DBA Global)Dua laporan segera, yang, menurut perkiraan peserta, berada di TOP 5, berhubungan dengan ProxySQL, sarana proxy kueri SQL untuk MySQL (dan, baru-baru ini, ClickHouse).
Laporan pertama umumnya tentang skenario untuk menggunakan alat ini.
ProxySQL adalah solusi open source, sejauh ini kami belum menemukan intisari pengalaman seperti itu. Ya, banyak perusahaan mengunduh solusi ini, tetapi bahkan pabrikan itu sendiri tidak selalu mengerti siapa yang akan menggunakannya dan pada skala apa. Skenario yang dikumpulkan dalam laporan ini diidentifikasi sebagai hasil komunikasi dengan pengguna ProxySQL dan analisis kasus mereka.
Secara umum, ProxySQL memungkinkan Anda untuk menyelesaikan sejumlah besar tugas, mulai dari load balancing dan penulisan ulang kueri (yang akan dibahas dalam laporan berikutnya dari daftar kami), hingga antrian permintaan dan memanaskan cache, yang tidak ada di MySQL. Masing-masing opsi Alkin Tezuysal mem-parsing secara rinci, menyebutkan kelebihan dan kekurangan dari solusi, serta kasus-kasus khusus yang mungkin bermanfaat.
Di sini kami hanya menyebutkan dua contoh mengenai optimalisasi database.
Contoh 1 - menggunakan ProxySQL untuk mengurangi jumlah permintaan untuk membuat koneksi aplikasi ke database. Idenya secara grafis tercermin dalam grafik yang diberikan dalam laporan:
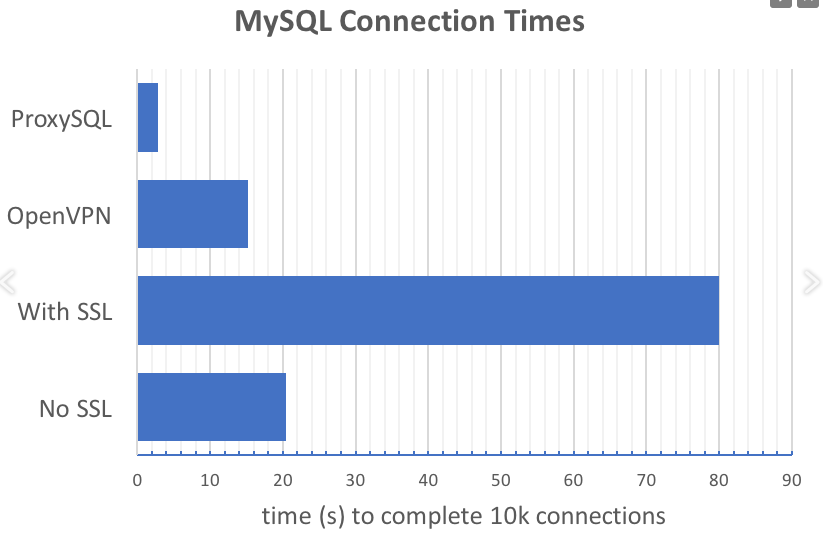
ProxySQL secara drastis mengurangi jumlah permintaan koneksi, terutama saat menggunakan SSL.
Contoh 2 - memfilter kueri yang tidak berguna (seperti SELECT 1, dimanifestasikan dalam aplikasi skala besar) yang memperlambat basis data. Di sini, hasilnya juga terbaik dievaluasi secara grafis:

Datamasking murah untuk MySQL dengan ProxySQL - Anonimisasi Data untuk Pengembang
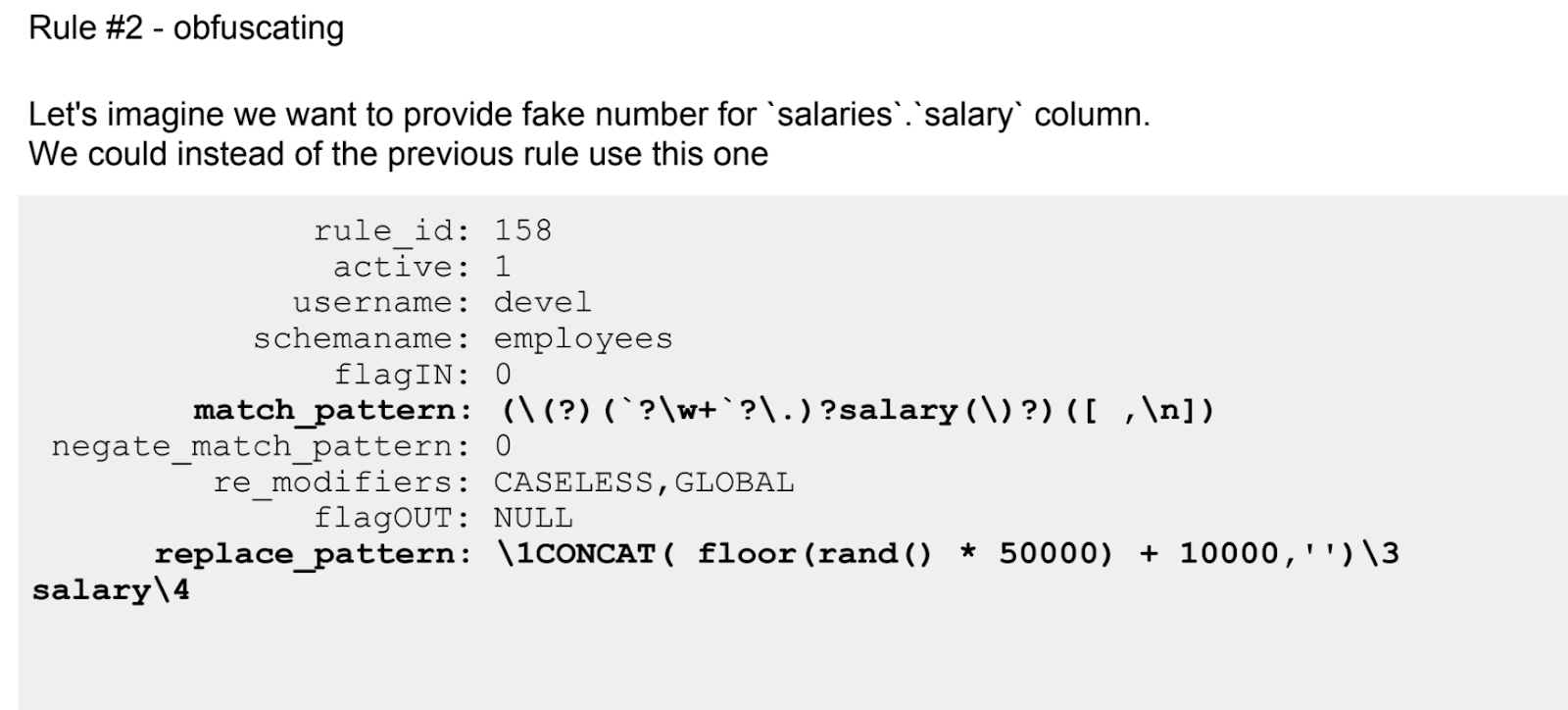
Rene Cannao (pendiri dan pemilik produk ProxySQL)Laporan bahasa Inggris kedua tentang ProxySQL, yang masuk ke TOP-5, didedikasikan untuk memecahkan masalah yang sangat spesifik - penyembunyian data.
Setelah pengantar singkat tentang ProxySQL bagi mereka yang belum melihat laporan pertama, pembicara terjun ke kemampuan alat sehubungan dengan memecahkan masalah tertentu - menyembunyikan (mengganti dengan tanda bintang) bagian nama atau mengganti jumlah pendapatan riil dengan yang palsu.
Seperti yang dicatat oleh pembicara, masalah ini dapat dipecahkan dengan menggunakan sarana Anda sendiri dari produk MySQL atau pihak ketiga yang sama. Di antara pihak ketiga ProxySQL jauh dari satu-satunya alat. Namun, sementara tidak ada solusi ideal di pasar, dan ProxySQL tidak lebih buruk dari banyak, memungkinkan pengembang untuk mendapatkan data yang valid untuk pengujian yang tidak mengandung informasi pribadi nyata. Selain itu, ia memiliki kode sumber terbuka.
Jika cerita pertama tentang ProxySQL lebih teoretis, maka inilah praktik yang berkelanjutan. Bahkan aturan yang dikonfigurasi menggunakan ekspresi reguler terdaftar.

Seperti halnya alat proxySQL memiliki keterbatasan. Ini juga akan dibahas. Secara khusus, ini bukan pendekatan terbaik untuk transformasi kompleks.
Laporan berakhir dengan bagian penuh pertanyaan dan jawaban, dari mana Anda juga dapat belajar banyak hal yang berguna dan menarik.
Tentu saja, lima berbahasa Inggris ini hanyalah puncak gunung es yang berada di HighLoad ++ 2017. Oleh karena itu, kami ingat bahwa kami baru saja memposting video dari semua laporan konferensi yang dapat ditemukan di
daftar putar ini .
HighLoad ++ 2018 akan diadakan pada 8 dan 9 November di Moskow, di Skolkovo. Pekerjaan pada program ini sudah berjalan, tetapi laporan itu dapat diserahkan sebelum 1 September.