Semua organisasi yang setidaknya ada hubungannya dengan data cepat atau lambat menghadapi masalah menyimpan database relasional dan tidak terstruktur. Tidak mudah untuk menemukan pendekatan yang nyaman, efektif dan murah untuk masalah ini secara bersamaan. Dan untuk memastikan bahwa para ilmuwan data dapat berhasil bekerja dengan model pembelajaran mesin. Kami berhasil - dan meskipun saya harus mengotak-atiknya, keuntungan akhir bahkan lebih dari yang diharapkan. Kami akan membahas semua detail di bawah ini.

Seiring waktu, jumlah data perusahaan yang luar biasa menumpuk di bank mana pun. Jumlah yang sebanding hanya disimpan di perusahaan internet dan telekomunikasi. Itu terjadi karena persyaratan peraturan yang tinggi. Data-data ini tidak berbohong - kepala lembaga keuangan telah lama menemukan cara untuk mendapatkan keuntungan dari ini.
Kita semua mulai dengan manajemen dan pelaporan keuangan. Berdasarkan data ini, kami belajar cara membuat keputusan bisnis. Seringkali ada kebutuhan untuk mendapatkan data dari beberapa sistem informasi bank, di mana kami membuat basis data dan sistem pelaporan konsolidasi. Dari ini secara bertahap terbentuk apa yang sekarang disebut data warehouse. Segera, berdasarkan penyimpanan ini, sistem kami yang lain mulai bekerja:
- CRM analitik, memungkinkan untuk menawarkan produk yang lebih nyaman kepada klien;
- konveyor pinjaman yang membantu Anda dengan cepat dan akurat membuat keputusan tentang pinjaman;
- sistem loyalitas menghitung cashback atau poin bonus sesuai dengan mekanisme dengan kompleksitas yang berbeda-beda.
Semua tugas ini diselesaikan oleh aplikasi analitis yang menggunakan model pembelajaran mesin. Semakin banyak model informasi yang dapat diambil dari repositori, semakin akurat model itu akan bekerja. Kebutuhan mereka akan data tumbuh secara eksponensial.
Tentang situasi ini kami datang ke dua atau tiga tahun yang lalu. Pada saat itu, kami memiliki penyimpanan berdasarkan MPP Teradata DBMS menggunakan alat SAS Data Integration Studio ELT. Kami membangun gudang ini sejak 2011 bersama dengan Glowbyte Consulting. Lebih dari 15 sistem perbankan besar diintegrasikan ke dalamnya, dan pada saat yang sama, data yang cukup dikumpulkan untuk implementasi dan pengembangan aplikasi analitis. Ngomong-ngomong, tepat pada waktu itu, volume data di lapisan utama toko, karena banyak tugas yang berbeda, mulai tumbuh secara non-linear, dan analitik klien tingkat lanjut menjadi salah satu arahan utama pengembangan bank. Ya, dan data kami Para ilmuwan sangat ingin mendukungnya. Secara umum, untuk membangun Platform Penelitian Data, bintang-bintang terbentuk sebagaimana mestinya.
Merencanakan solusi
Di sini perlu dijelaskan: perangkat lunak industri dan server adalah kesenangan yang mahal bahkan untuk bank besar. Tidak setiap organisasi mampu untuk menyimpan sejumlah besar data dalam MPMS DBMS teratas. Anda selalu harus membuat pilihan antara harga dan kecepatan, keandalan dan volume.
Untuk memanfaatkan peluang yang ada, kami memutuskan untuk melakukan ini:
- Beban ELT dan bagian yang paling diminta dari data historis CD harus dibiarkan pada DBMS Teradata;
- kirimkan cerita lengkap ke Hadoop, yang memungkinkan Anda menyimpan informasi jauh lebih murah.
Sekitar waktu itu, ekosistem Hadoop menjadi tidak hanya modis, tetapi juga cukup andal, nyaman untuk digunakan perusahaan. Itu perlu untuk memilih kit distribusi. Anda bisa membuat sendiri atau menggunakan Apache Hadoop yang terbuka. Tetapi di antara solusi perusahaan berdasarkan Hadoop, distribusi yang sudah jadi dari vendor lain - Cloudera dan Hortonworks - telah membuktikan diri mereka lebih banyak. Karena itu, kami juga memutuskan untuk menggunakan distribusi yang sudah jadi.
Karena tugas utama kami masih menyimpan data besar terstruktur, di tumpukan Hadoop kami tertarik pada solusi yang sedekat mungkin dengan DBMS SQL klasik. Para pemimpin di sini adalah Impala dan Sarang. Cloudera mengembangkan dan mengintegrasikan Impala, Hortonworks - solusi Hive.
Untuk studi mendalam, kami mengorganisir pengujian beban untuk kedua DBMS, dengan mempertimbangkan beban profil untuk kami. Saya harus mengatakan bahwa mesin pengolah data di Impala dan Hive sangat berbeda - Hive umumnya menyajikan beberapa opsi berbeda. Namun, pilihan jatuh pada Impala - dan, karenanya, distribusi dari Cloudera.
Apa yang saya sukai tentang Impala
- Eksekusi analitik kecepatan tinggi karena pendekatan alternatif dalam kaitannya dengan MapReduce. Hasil perhitungan menengah tidak terlipat dalam HDFS, yang secara signifikan mempercepat pemrosesan data.
- Pekerjaan yang efisien dengan penyimpanan data parket di Parket . Untuk tugas analitis, tabel lebar yang disebut dengan banyak kolom sering digunakan. Semua kolom jarang digunakan - kemampuan untuk meningkatkan dari HDFS hanya yang dibutuhkan untuk bekerja menghemat RAM dan secara signifikan mempercepat permintaan.
- Solusi elegan dengan filter runtime yang mencakup pemfilteran bloom. Baik Hive dan Impala sangat terbatas dalam penggunaan indeks umum untuk DBMS klasik karena sifat sistem penyimpanan file HDFS. Oleh karena itu, untuk mengoptimalkan pelaksanaan query SQL, mesin DBMS harus secara efektif menggunakan partisi yang tersedia bahkan ketika tidak ditentukan secara eksplisit dalam kondisi permintaan. Selain itu, ia perlu mencoba memprediksi jumlah data minimum dari HDFS yang perlu dinaikkan untuk pemrosesan yang dijamin dari semua baris. Di Impala, ini bekerja dengan sangat baik.
- Impala menggunakan LLVM , kompiler mesin virtual dengan instruksi seperti RISC, untuk menghasilkan kode eksekusi query SQL yang optimal.
- Antarmuka ODBC dan JDBC didukung. Ini memungkinkan Anda untuk mengintegrasikan data Impala dengan alat dan aplikasi analitik hampir di luar kotak.
- Dimungkinkan untuk menggunakan Kudu untuk menghindari beberapa keterbatasan HDFS, dan, khususnya, menulis konstruksi UPDATE dan DELETE dalam query SQL.
Sqoop dan sisanya dari arsitektur
Alat terpenting berikutnya pada tumpukan Hadoop adalah Sqoop bagi kami. Ini memungkinkan Anda untuk mentransfer data antara DBMS relasional (kami tentu saja tertarik pada Teradata) dan HDFS dalam cluster Hadoop dalam berbagai format, termasuk Parket. Dalam pengujian, Sqoop menunjukkan fleksibilitas dan kinerja yang tinggi, jadi kami memutuskan untuk menggunakannya - alih-alih mengembangkan alat kami sendiri untuk mengambil data melalui ODBC / JDBC dan menyimpan ke HDFS.
Untuk model pelatihan dan tugas terkait dari Ilmu Data, yang lebih nyaman untuk dieksekusi langsung pada cluster Hadoop, kami menggunakan Apache
Spark . Di bidangnya, ini telah menjadi solusi standar - dan ada alasan:
- Perpustakaan Belajar Mesin Spark ML
- dukungan untuk empat bahasa pemrograman (Scala, Java, Python, R);
- integrasi dengan alat analitis;
- pemrosesan data dalam memori memberikan kinerja yang sangat baik.
Server Oracle Big Data Appliance dibeli sebagai platform perangkat keras. Kami mulai dengan enam node dalam sirkuit produktif dengan CPU 2x24-core dan masing-masing 256 GB memori. Konfigurasi saat ini berisi 18 node yang sama dengan memori yang diperluas hingga 512 GB.
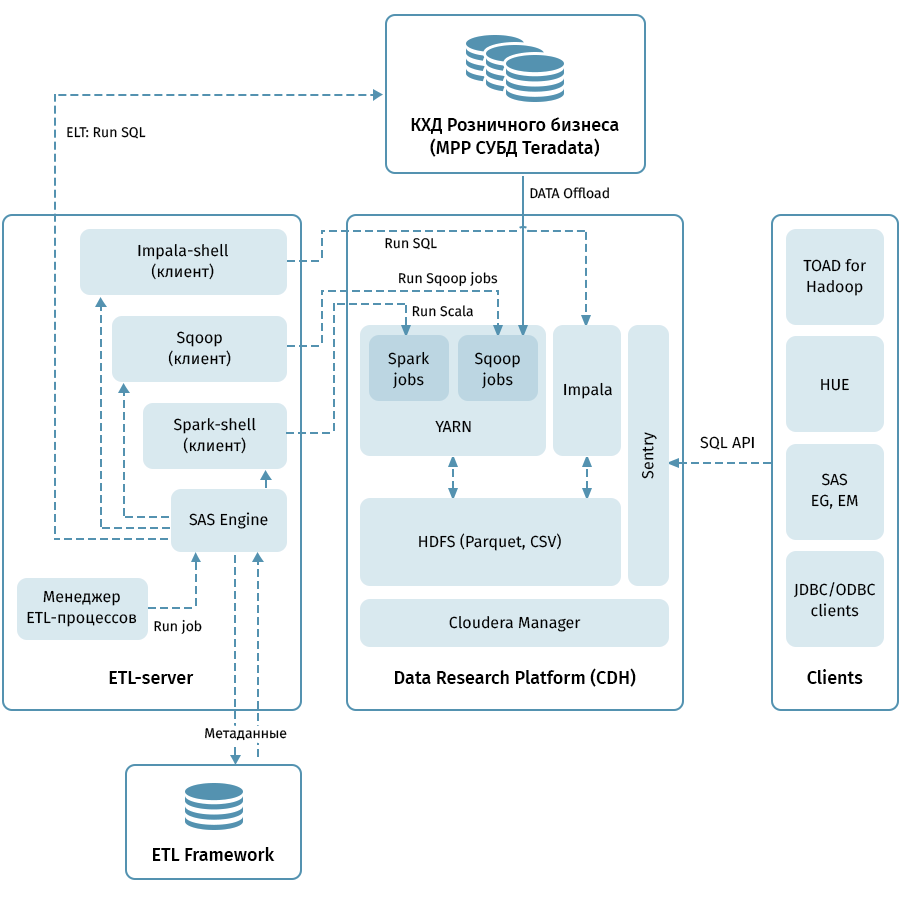
Diagram menunjukkan arsitektur tingkat atas dari Platform Penelitian Data dan sistem terkait. Tautan pusat adalah cluster Hadoop berdasarkan distribusi Cloudera (CDH). Ini digunakan baik untuk menerima dengan Sqoop dan menyimpan data QCD dalam HDFS - dalam format parket, memungkinkan penggunaan codec untuk kompresi, misalnya, Snappy. Cluster juga memproses data: Impala digunakan untuk transformasi seperti ELT, Spark - untuk tugas-tugas Ilmu Data. Sentry digunakan untuk berbagi akses data.
Impala memiliki antarmuka untuk hampir semua alat analisis perusahaan modern. Selain itu, alat sewenang-wenang yang mendukung antarmuka ODBC / JDBC dapat dihubungkan sebagai klien. Untuk bekerja dengan SQL, kami mempertimbangkan Hue dan TOAD untuk Hadoop sebagai klien utama.
Subsistem ETL yang terdiri dari alat SAS (Metadata Server, Data Integration Studio) dan kerangka kerja ETL yang ditulis berdasarkan SAS dan skrip shell menggunakan database untuk menyimpan metadata proses ETL digunakan untuk mengelola semua aliran yang ditunjukkan oleh panah pada diagram. . Dipandu oleh aturan yang ditentukan dalam metadata, subsistem ETL meluncurkan proses pemrosesan data baik pada QCD maupun pada Platform Penelitian Data. Sebagai hasilnya, kami memiliki sistem ujung ke ujung untuk memantau dan mengelola aliran data terlepas dari lingkungan yang digunakan (Teradata, Impala, Spark, dll., Jika perlu).
Melalui menyapu ke bintang-bintang
Membongkar QCD tampaknya sederhana. Pada input dan output, DBMS relasional, ambil dan limpahkan data melalui Sqoop. Menilai dari uraian di atas, semuanya berjalan sangat lancar dengan kami, tetapi, tentu saja, itu bukan tanpa petualangan, dan ini mungkin bagian yang paling menarik dari keseluruhan proyek.

Dengan volume kami, kami tidak bisa berharap untuk mentransfer semua data sepenuhnya setiap hari. Oleh karena itu, dari setiap fasilitas penyimpanan, perlu dipelajari cara membedakan kenaikan yang dapat diandalkan, yang tidak selalu mudah ketika data untuk tanggal bisnis yang bersejarah dapat berubah dalam tabel. Untuk mengatasi masalah ini, kami mensistematisasikan objek tergantung pada metode pemuatan dan pemeliharaan riwayat. Kemudian, untuk setiap jenis, predikat yang benar untuk Sqoop dan metode pemuatan ke penerima ditentukan. Dan akhirnya, mereka menulis instruksi untuk pengembang objek baru.
Sqoop adalah alat yang sangat berkualitas tinggi, tetapi tidak dalam semua kasus dan kombinasi sistem ini bekerja sangat andal. Pada volume kami, konektor ke Teradata tidak berfungsi secara optimal. Kami mengambil keuntungan dari kode sumber terbuka Sqoop dan membuat perubahan pada pustaka konektor. Stabilitas koneksi saat memindahkan data telah meningkat.
Untuk beberapa alasan, ketika Sqoop memanggil Teradata, predikat tidak sepenuhnya benar dikonversi ke kondisi WHERE. Karena itu, Sqoop terkadang mencoba mengeluarkan meja besar dan memfilternya nanti. Kami gagal menambal konektor di sini, tetapi kami menemukan cara lain: secara paksa membuat tabel sementara dengan predikat yang dikenakan untuk setiap objek yang dibongkar dan meminta Sqoop untuk melimpahi itu.
Semua MPP, dan Teradata khususnya, memiliki fitur terkait penyimpanan data paralel dan eksekusi instruksi. Jika fitur ini tidak diperhitungkan, maka mungkin ternyata semua pekerjaan akan diambil alih oleh satu node logis dari cluster, yang akan membuat eksekusi query lebih lambat, sekali dalam 100-200. Tentu saja, kami tidak dapat membiarkan ini, oleh karena itu, kami menulis mesin khusus yang menggunakan metadata ETL dari tabel QCD dan memilih tingkat paralelisasi tugas Sqoop yang optimal.
Historisitas dalam penyimpanan adalah masalah yang rumit, terutama jika Anda menggunakan
SCD2 , sementara Impala tidak mendukung UPDATE dan DELETE. Tentu saja, kami ingin tabel historis dalam Platform Penelitian Data terlihat persis sama dengan di Teradata. Ini dapat dicapai dengan menggabungkan kenaikan penerimaan melalui Sqoop, menyoroti kunci bisnis yang diperbarui dan menghapus partisi di Impala. Agar logika yang rumit ini tidak harus ditulis oleh masing-masing pengembang, kami mengemasnya ke perpustakaan khusus (di "slang" loader ETL kami).
Akhirnya - pertanyaan dengan tipe data. Impala cukup bebas mengetik konversi, jadi kami menemui beberapa kesulitan hanya pada tipe TIMESTAMP dan CHAR / VARCHAR. Untuk tanggal-waktu, kami memutuskan untuk menyimpan data dalam Impala dalam format teks (STRING) YYYY-MM-DD HH: MM: SS. Pendekatan ini, ternyata, memungkinkan untuk menggunakan fungsi mengubah tanggal dan waktu. Untuk data string dengan panjang tertentu, ternyata penyimpanan dalam format STRING di Impala tidak kalah dengan mereka, oleh karena itu kami juga menggunakannya.
Biasanya, untuk mengatur Danau Data, mereka menyalin data sumber dalam format semi-terstruktur ke area tahap khusus di Hadoop, setelah itu Hive atau Impala mengatur skema deserialisasi untuk data ini untuk digunakan dalam kueri SQL. Kami pergi dengan cara yang sama. Penting untuk dicatat bahwa tidak semuanya dan tidak selalu masuk akal untuk menarik data warehouse, karena pengembangan proses penyalinan file dan pemasangan skema jauh lebih murah daripada memuat atribut bisnis ke dalam model QCD menggunakan proses ETL menggunakan proses ETL. Ketika masih belum jelas berapa, untuk berapa lama dan dengan frekuensi berapa data sumber dibutuhkan, Data Lake dalam pendekatan yang dijelaskan adalah solusi sederhana dan murah. Sekarang kami secara teratur mengunggah ke Danau Data terutama sumber yang menghasilkan peristiwa pengguna: data analisis aplikasi, log dan skenario transisi untuk Avaya auto dialer dan mesin penjawab, transaksi kartu.
Perangkat Analis
Kami tidak melupakan tujuan lain dari keseluruhan proyek - untuk memungkinkan analis untuk menggunakan semua kekayaan ini. Berikut adalah prinsip-prinsip dasar yang membimbing kami di sini:
- Kenyamanan alat dalam penggunaan dan dukungan
- Penerapan dalam Tugas Ilmu Data
- Kemungkinan maksimum menggunakan sumber daya komputasi cluster Hadoop, daripada server aplikasi atau komputer peneliti
Dan inilah yang kami singgahi:
- Python + Anaconda. Lingkungan yang digunakan adalah iPython / Jupyter
- R + Shiny. Peneliti bekerja di desktop atau versi web R Studio, Shiny digunakan untuk mengembangkan aplikasi web yang dipertajam oleh penggunaan algoritma yang dikembangkan dalam R.
- Spark Untuk bekerja dengan data, antarmuka untuk Python (pyspark) dan R digunakan, yang dikonfigurasi dalam lingkungan pengembangan yang ditentukan dalam paragraf sebelumnya. Kedua antarmuka memungkinkan Anda untuk menggunakan perpustakaan Spark ML, yang memungkinkan untuk melatih model ML pada kluster Hadoop / Spark.
- Data Impala dapat diakses melalui Hue, Spark dan dari lingkungan pengembangan menggunakan antarmuka ODBC standar dan perpustakaan khusus seperti implyr
Saat ini, Data Lake berisi sekitar 100 TB data dari penyimpanan ritel, ditambah sekitar 50 TB dari sejumlah sumber OLTP. Danau diperbarui setiap hari secara bertahap. Di masa mendatang, kami akan meningkatkan kenyamanan pengguna, memperkenalkan beban ELT di Impala, menambah jumlah sumber yang diunggah ke Data Lake, dan memperluas peluang untuk analitik lanjutan.
Sebagai kesimpulan, saya ingin memberikan beberapa saran umum kepada rekan-rekan yang baru memulai perjalanan mereka dalam menciptakan repositori besar:
- Gunakan praktik terbaik. Jika kami tidak memiliki subsistem ETL, metadata, penyimpanan berversi dan arsitektur yang dapat dimengerti, kami tidak akan menguasai tugas ini. Praktik terbaik membayar sendiri, meskipun tidak segera.
- Ingat jumlah data. Data besar dapat membuat kesulitan teknis di tempat yang sangat tidak terduga.
- Tetap disini untuk teknologi baru. Solusi baru sering muncul, tidak semuanya berguna, tetapi terkadang permata asli ditemukan.
- Eksperimen lebih banyak. Jangan hanya mempercayai deskripsi pemasaran dari solusi - cobalah sendiri.
Omong-omong, Anda dapat membaca tentang bagaimana analis kami menggunakan pembelajaran mesin dan data bank untuk bekerja dengan risiko kredit di pos terpisah.