Halo semuanya!
Eksperimen kami dengan langkah-langkah dalam kursus
Pengembang Java berlanjut dan, anehnya, bahkan cukup berhasil (semacam): ternyata, perencanaan leverage beberapa bulan dengan transisi berikutnya ke langkah baru pada waktu yang nyaman jauh lebih nyaman daripada jika Alokasikan hampir enam bulan untuk kursus yang sulit. Jadi ada kecurigaan bahwa justru kursus kompleks yang akan segera kita mulai transfer perlahan ke sistem seperti itu.
Tapi ini saya tentang kita, tentang otusovsky, saya minta maaf. Seperti biasa, kami terus mempelajari topik-topik menarik itu, meskipun tidak dibahas dalam program kami, tetapi yang dibahas bersama kami, jadi kami menyiapkan terjemahan artikel yang paling menarik menurut pendapat kami tentang salah satu pertanyaan yang diajukan guru kami.
Ayo pergi!

Koleksi di JDK adalah implementasi standar perpustakaan daftar dan peta. Jika Anda melihat snapshot dari aplikasi Java besar yang khas, Anda akan melihat ribuan atau bahkan jutaan instance
java.util.ArrayList ,
java.util.HashMap , dll. Koleksi sangat diperlukan untuk menyimpan dan memanipulasi data. Tetapi apakah Anda pernah berpikir tentang apakah semua koleksi dalam aplikasi Anda memanfaatkan memori secara optimal? Dengan kata lain, jika aplikasi Anda mengalami crash dengan
OutOfMemoryError memalukan atau menyebabkan jeda lama di pengumpul sampah, apakah Anda pernah memeriksa pengumpulan bekas untuk kebocoran.
Pertama, harus dicatat bahwa koleksi internal JDK bukanlah semacam sihir. Mereka ditulis dalam bahasa Jawa. Kode sumber mereka datang dengan JDK, sehingga Anda dapat membukanya di IDE Anda. Kode mereka juga dapat dengan mudah ditemukan di Internet. Dan, ternyata, sebagian besar koleksi tidak begitu elegan dalam hal mengoptimalkan jumlah memori yang dikonsumsi.
Pertimbangkan, misalnya, salah satu koleksi paling sederhana dan paling populer - kelas
java.util.ArrayList . Secara internal, setiap
ArrayList beroperasi dengan array
Object[] elementData . Di sinilah daftar item disimpan. Mari kita lihat bagaimana array ini diproses.
Ketika Anda membuat
ArrayList dengan konstruktor default, yaitu, panggil
new ArrayList() ,
elementData menunjuk ke array generik ukuran nol (
elementData juga dapat diatur ke
null , tetapi array memberikan beberapa manfaat implementasi kecil). Saat Anda menambahkan elemen pertama ke daftar, array unik yang unik dari
elementData , dan objek yang disediakan dimasukkan ke dalamnya. Untuk menghindari perubahan ukuran array setiap kali, saat menambahkan elemen baru, elemen itu dibuat dengan panjang sama dengan 10 (“kapasitas default”). Jadi ternyata: jika Anda tidak lagi menambahkan elemen ke
ArrayList ini, 9 dari 10 slot dalam array
elementData akan tetap kosong. Dan bahkan jika Anda menghapus daftar, ukuran array internal tidak akan berkurang. Berikut ini adalah diagram dari siklus hidup ini:
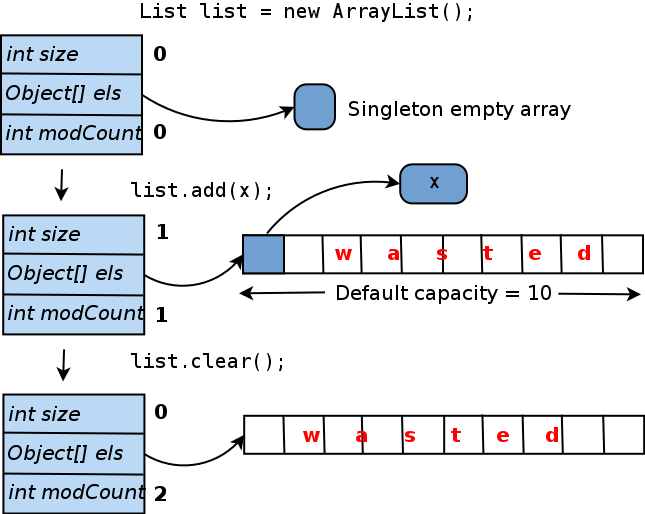
Berapa banyak memori yang terbuang di sini? Secara absolut, itu dihitung sebagai (ukuran penunjuk objek). Jika Anda menggunakan JVM HotSpot (yang datang dengan Oracle JDK), ukuran pointer akan tergantung pada ukuran heap maksimum (untuk lebih jelasnya lihat
https://blog.codecentric.de/en/2014/02/35gb-heap-less- 32gb-java-jvm-memory-oddities / ). Biasanya, jika Anda menentukan
-Xmx kurang dari 32 gigabytes, ukuran pointer akan menjadi 4 byte; untuk tumpukan besar - 8 byte. Jadi, sebuah
ArrayList , diinisialisasi oleh konstruktor default, dengan tambahan hanya satu elemen, membuang 36 atau 72 byte.
Bahkan,
ArrayList kosong juga membuang-buang memori karena tidak membawa beban kerja apa pun, tetapi ukuran
ArrayList itu sendiri tidak nol dan lebih besar dari yang Anda kira. Ini karena, di satu sisi, setiap objek yang dikelola oleh HotSpot JVM memiliki header 12 atau 16 byte, yang digunakan oleh JVM untuk keperluan internal. Selanjutnya, sebagian besar objek dalam koleksi berisi bidang
size , penunjuk ke array internal atau objek "media beban kerja" lainnya, bidang
modCount untuk melacak perubahan konten, dll. Dengan demikian, bahkan objek terkecil yang mungkin mewakili koleksi kosong mungkin memerlukan setidaknya 32 byte memori. Beberapa, seperti
ConcurrentHashMap , membutuhkan lebih banyak.
Pertimbangkan koleksi umum lainnya - kelas
java.util.HashMap . Siklus hidupnya mirip dengan siklus hidup
ArrayList :

Seperti yang Anda lihat,
HashMap yang hanya berisi satu pasangan nilai kunci menghabiskan 15 sel internal array, yang sesuai dengan 60 atau 120 byte. Angka-angka ini kecil, tetapi tingkat kehilangan memori penting untuk semua koleksi dalam aplikasi Anda. Dan ternyata beberapa aplikasi dapat menghabiskan cukup banyak memori dengan cara ini. Sebagai contoh, beberapa komponen Hadoop open-source populer yang penulis analisis kehilangan sekitar 20 persen dari tumpukan mereka dalam beberapa kasus! Untuk produk yang dikembangkan oleh insinyur yang kurang berpengalaman yang tidak menjalani tinjauan kinerja reguler, kehilangan memori bisa lebih tinggi. Ada cukup banyak kasus di mana, misalnya, 90% dari simpul dalam pohon besar hanya mengandung satu atau dua keturunan (atau tidak sama sekali), dan situasi lain di mana tumpukan tersumbat dengan koleksi elemen, 0, 1, atau 2 elemen.
Jika Anda menemukan koleksi yang tidak terpakai atau kurang digunakan dalam aplikasi Anda, bagaimana cara memperbaikinya? Di bawah ini adalah beberapa resep umum. Di sini, diasumsikan bahwa koleksi kami yang bermasalah adalah
ArrayList dirujuk oleh bidang data
Foo.list .
Jika sebagian besar daftar tidak pernah digunakan, coba inisialisasi dengan malas. Jadi kode yang sebelumnya tampak seperti ...
void addToList(Object x) { list.add(x); }
... harus diulang menjadi sesuatu seperti
void addToList(Object x) { getOrCreateList().add(x); } private list getOrCreateList() {
Ingatlah bahwa kadang-kadang Anda perlu mengambil tindakan tambahan untuk mengatasi potensi persaingan. Misalnya, jika Anda mendukung
ConcurrentHashMap , yang dapat diperbarui oleh beberapa utas secara bersamaan, kode yang menginisialisasi itu seharusnya tidak memungkinkan dua utas untuk membuat dua salinan peta ini secara acak:
private Map getOrCreateMap() { if (map == null) {
Jika sebagian besar contoh daftar atau peta Anda hanya berisi beberapa item, coba inisialisasi dengan kapasitas awal yang lebih cocok, misalnya.
list = new ArrayList(4);
Jika koleksi Anda kosong atau hanya mengandung satu elemen (atau pasangan nilai kunci) dalam kebanyakan kasus, Anda dapat mempertimbangkan satu bentuk optimalisasi yang ekstrem. Ini hanya berfungsi jika koleksi dikelola sepenuhnya dalam kelas saat ini, yaitu, kode lain tidak dapat mengaksesnya secara langsung. Idenya adalah bahwa Anda mengubah jenis bidang data Anda, misalnya, dari daftar ke objek yang lebih umum, sehingga sekarang dapat menunjuk ke daftar nyata atau langsung ke item daftar tunggal. Berikut ini sketsa singkatnya:
Jelas, kode dengan optimasi ini kurang jelas dan sulit untuk dipertahankan. Tapi ini bisa berguna jika Anda yakin ini akan menghemat banyak memori atau membuang jeda panjang dari pengumpul sampah.
Anda mungkin sudah bertanya-tanya: bagaimana cara mengetahui koleksi mana di aplikasi saya yang menggunakan memori dan berapa banyak?
Singkatnya: sulit untuk mengetahui tanpa alat yang tepat. Mencoba menebak jumlah memori yang digunakan atau dihabiskan oleh struktur data dalam aplikasi kompleks besar hampir tidak akan pernah mengarah pada apa pun. Dan, tidak tahu persis ke mana ingatannya pergi, Anda dapat menghabiskan banyak waktu mengejar tujuan yang salah, sementara aplikasi Anda dengan keras kepala terus
OutOfMemoryError dengan
OutOfMemoryError .
Oleh karena itu, Anda harus memeriksa banyak aplikasi menggunakan alat khusus. Dari pengalaman, cara paling optimal untuk menganalisis memori JVM (diukur sebagai jumlah informasi yang tersedia dibandingkan dengan efek alat ini pada kinerja aplikasi) adalah untuk mendapatkan heap dump dan kemudian melihatnya secara offline. Heap dump pada dasarnya adalah snapshot lengkap dari heap. Anda bisa mendapatkannya kapan saja dengan memanggil utilitas jmap, atau Anda dapat mengonfigurasi JVM untuk secara otomatis dibuang jika aplikasi crash dengan
OutOfMemoryError . Jika Anda google "JVM heap dump", Anda akan segera melihat sejumlah besar artikel yang menjelaskan secara detail cara mendapatkan dump.
Tumpukan tumpukan adalah file biner ukuran tumpukan JVM, sehingga hanya dapat dibaca dan dianalisis menggunakan alat khusus. Ada beberapa alat, baik open source maupun komersial. Alat open source paling populer adalah Eclipse MAT; ada juga VisualVM dan beberapa alat yang kurang kuat dan kurang terkenal. Alat komersial termasuk profiler Java untuk keperluan umum: JProfiler dan YourKit, serta satu alat yang dirancang khusus untuk analisis tumpukan timbunan - JXRay (penafian: terakhir dikembangkan oleh penulis).
Tidak seperti alat-alat lain, JXRay segera menganalisis tumpukan timbunan untuk sejumlah besar masalah umum, seperti garis berulang dan objek lainnya, serta struktur data yang kurang efisien. Masalah dengan koleksi yang dijelaskan di atas termasuk dalam kategori yang terakhir. Alat ini menghasilkan laporan dengan semua informasi yang dikumpulkan dalam format HTML. Keuntungan dari pendekatan ini adalah Anda dapat melihat hasil analisis di mana saja kapan saja dan dengan mudah membagikannya kepada orang lain. Anda juga dapat menjalankan alat di mesin apa pun, termasuk mesin besar dan kuat, tetapi "tanpa kepala" di pusat data.
JXRay menghitung overhead (berapa banyak memori yang akan Anda simpan jika Anda menyingkirkan masalah tertentu) dalam byte dan sebagai persentase dari tumpukan yang digunakan. Ini menggabungkan koleksi dari kelas yang sama yang memiliki masalah yang sama ...

... dan kemudian mengelompokkan koleksi bermasalah yang dapat diakses dari beberapa akar pengumpul sampah melalui rantai tautan yang sama, seperti dalam contoh di bawah ini

Mengetahui rantai tautan mana dan / atau bidang data individual (misalnya,
INodeDirectory.children atas) menunjukkan koleksi yang menghabiskan sebagian besar memori mereka memungkinkan Anda untuk dengan cepat dan akurat mengidentifikasi kode yang bertanggung jawab atas masalah tersebut, dan kemudian membuat perubahan yang diperlukan.
Dengan demikian, koleksi Java yang tidak dikonfigurasi dengan benar dapat menghabiskan banyak memori. Dalam banyak situasi, masalah ini mudah diselesaikan, tetapi kadang-kadang Anda mungkin perlu mengubah kode Anda dengan cara yang tidak sepele untuk mencapai peningkatan yang signifikan. Sangat sulit untuk menebak koleksi mana yang perlu dioptimalkan agar memiliki dampak terbesar. Agar tidak membuang waktu mengoptimalkan bagian kode yang salah, Anda perlu mendapatkan heap dump JVM dan menganalisisnya menggunakan alat yang sesuai.
AKHIR
Kami, seperti biasa, tertarik dengan pendapat dan pertanyaan Anda, yang dapat Anda tinggalkan di sini atau mampir dengan
pelajaran terbuka dan bertanya kepada
guru -
guru kami di sana.