Saat ini, salah satu kendala utama untuk pengenalan pembelajaran mesin dalam bisnis adalah ketidakcocokan metrik ML dan indikator yang beroperasi dengan manajemen puncak. Analis memperkirakan kenaikan laba? Tetapi Anda perlu memahami dalam hal apa pembelajaran mesin akan menjadi penyebab peningkatan, dan di mana faktor-faktor lainnya. Sayangnya, cukup sering peningkatan dalam metrik ML tidak mengarah pada pertumbuhan laba. Selain itu, terkadang kompleksitas data sedemikian rupa sehingga pengembang yang berpengalaman sekalipun dapat memilih metrik yang salah yang tidak dapat diorientasikan.
Mari kita lihat apa itu metrik ML dan kapan mereka layak digunakan. Kami akan menganalisis kesalahan umum, serta berbicara tentang opsi mana untuk mengatur masalah yang mungkin cocok untuk pembelajaran mesin dan bisnis.
Metrik ML: mengapa ada begitu banyak?
Metrik pembelajaran mesin sangat spesifik dan sering menyesatkan, menunjukkan
wajah yang baik pada game yang buruk, hasil yang baik untuk model yang buruk. Untuk menguji model dan memperbaikinya, Anda harus memilih metrik yang mencerminkan kualitas model secara memadai, dan cara mengukurnya. Biasanya, set data uji terpisah digunakan untuk mengevaluasi kualitas model. Dan seperti yang Anda tahu, memilih metrik yang tepat adalah tugas yang sulit.
Tugas apa yang paling sering diselesaikan dengan bantuan pembelajaran mesin? Pertama-tama, ini adalah regresi, klasifikasi dan pengelompokan. Dua yang pertama adalah apa yang disebut pelatihan dengan guru: ada satu set data berlabel, berdasarkan beberapa pengalaman, Anda perlu memprediksi nilai yang ditetapkan. Regresi adalah prediksi beberapa nilai: misalnya, berapa banyak pelanggan akan membeli, berapa ketahanan aus material, berapa kilometer perjalanan mobil sebelum kerusakan pertama.
Clustering adalah definisi dari struktur data dengan menyoroti cluster (misalnya, kategori pelanggan), dan kami tidak memiliki asumsi tentang cluster ini. Kami tidak akan mempertimbangkan jenis masalah ini.
Algoritma pembelajaran mesin mengoptimalkan (dengan menghitung fungsi kerugian) metrik matematika - perbedaan antara prediksi model dan nilai sebenarnya. Tetapi jika metrik adalah jumlah dari penyimpangan, maka dengan jumlah penyimpangan yang sama di kedua arah, jumlah ini akan menjadi nol, dan kita tidak akan tahu jika ada kesalahan. Oleh karena itu, mereka biasanya menggunakan rata-rata absolut (jumlah nilai absolut dari penyimpangan) atau kesalahan kuadrat rata-rata (jumlah kuadrat penyimpangan dari nilai sebenarnya). Terkadang rumusnya rumit: ambil logaritma atau ekstrak akar kuadrat dari jumlah ini. Berkat metrik ini, Anda dapat mengevaluasi dinamika kualitas perhitungan model, tetapi untuk ini Anda perlu membandingkan hasilnya dengan sesuatu.
Ini tidak akan sulit jika sudah ada model yang dibangun untuk membandingkan hasilnya. Tetapi bagaimana jika pertama kali Anda membuat model? Dalam hal ini, koefisien determinasi, atau R2, sering digunakan. Koefisien determinasi dinyatakan sebagai:
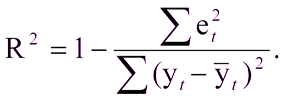
Dimana:
R ^ 2 - koefisien determinasi,
e
t ^ 2 adalah mean square error,
y
t adalah nilai yang benar,
yt dengan sampul adalah nilai rata-rata.
Unit minus rasio kesalahan kuadrat rata-rata model terhadap kesalahan kuadrat rata-rata dari nilai rata-rata sampel uji.Artinya, koefisien determinasi memungkinkan kita untuk mengevaluasi peningkatan prediksi oleh model.
Kadang-kadang terjadi bahwa kesalahan dalam satu arah tidak setara dengan kesalahan di yang lain. Misalnya, jika model memprediksi pesanan barang di gudang gudang, maka sangat mungkin untuk membuat kesalahan dan memesan sedikit lagi, barang akan menunggu di gudang untuk waktu mereka. Dan jika model melakukan kesalahan dengan cara lain dan mengurangi pesanan, maka Anda dapat kehilangan pelanggan. Dalam kasus seperti itu, kesalahan kuantil digunakan: penyimpangan positif dan negatif dari nilai sebenarnya diperhitungkan dengan bobot yang berbeda.
Dalam masalah klasifikasi, model pembelajaran mesin mendistribusikan objek ke dalam dua kelas: pengguna meninggalkan situs atau tidak pergi, bagiannya rusak atau tidak, dll. Keakuratan prediksi sering diestimasi sebagai rasio dari jumlah kelas yang didefinisikan dengan benar dengan total jumlah prediksi. Namun, karakteristik ini jarang dapat dianggap sebagai parameter yang memadai.
 Fig. 1. Matriks kesalahan untuk masalah prediksi pengembalian pelangganContoh
Fig. 1. Matriks kesalahan untuk masalah prediksi pengembalian pelangganContoh : jika 7 orang dari 100 tertanggung mengajukan kompensasi, maka model yang memprediksi tidak adanya acara yang diasuransikan akan memiliki akurasi 93% tanpa daya prediksi.
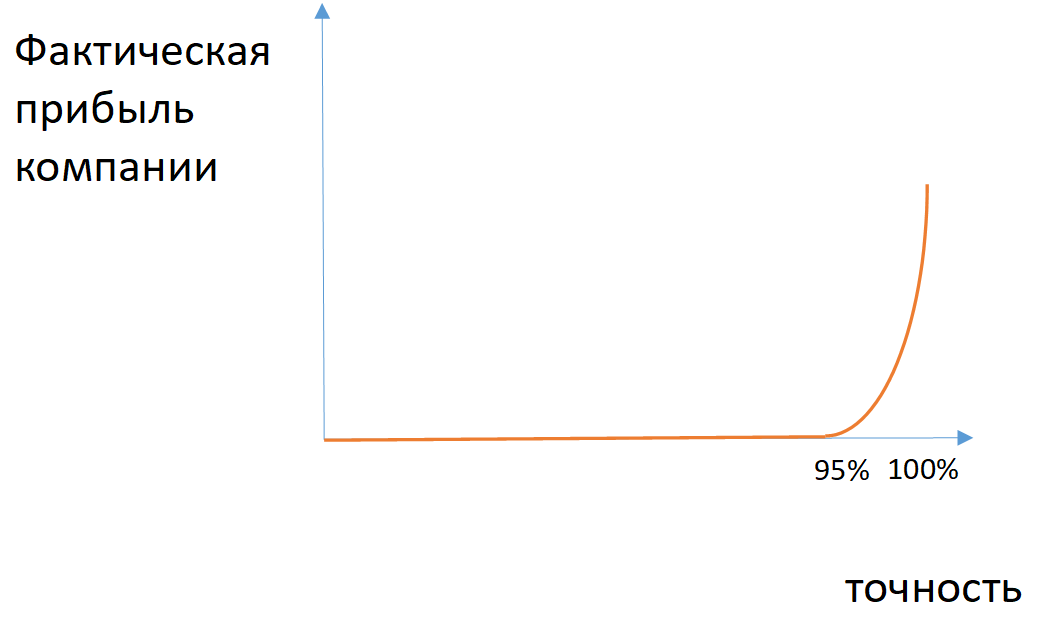 Fig. 2. Contoh ketergantungan dari laba aktual perusahaan pada keakuratan model dalam kasus kelas yang tidak seimbang
Fig. 2. Contoh ketergantungan dari laba aktual perusahaan pada keakuratan model dalam kasus kelas yang tidak seimbangUntuk beberapa tugas, Anda dapat menerapkan metrik kelengkapan (jumlah objek kelas yang didefinisikan dengan benar di antara semua objek kelas ini) dan akurasi (jumlah objek kelas yang didefinisikan dengan benar di antara semua objek yang ditetapkan oleh model untuk kelas ini). Jika perlu memperhitungkan kelengkapan dan akurasi, maka terapkan harmonik rata-rata antara nilai-nilai ini (ukuran F1).
Dengan menggunakan metrik ini, Anda dapat mengevaluasi klasifikasi yang dilakukan. Namun, banyak model memprediksi kemungkinan hubungan model dengan kelas tertentu. Dari sudut pandang ini, dimungkinkan untuk mengubah ambang probabilitas sehubungan dengan unsur-unsur yang akan ditugaskan ke satu atau kelas lain (misalnya, jika klien pergi dengan probabilitas 60%, maka itu dapat dianggap masih tersisa). Jika ambang tertentu tidak ditetapkan, maka untuk mengevaluasi keefektifan model, dimungkinkan untuk membuat grafik ketergantungan dari metrik pada nilai ambang yang berbeda (
kurva ROC atau kurva PR ), dengan mengambil sebagai metrik area di bawah kurva yang dipilih.
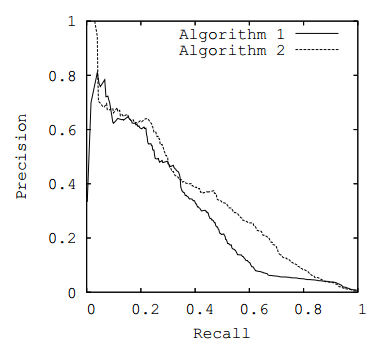 Fig. 3. Kurva PR
Fig. 3. Kurva PRMetrik bisnis
Secara kiasan, metrik bisnis adalah gajah: mereka tidak dapat diabaikan, dan dalam satu "gajah" seperti itu, sejumlah besar "burung beo" yang bisa belajar mesin bisa cocok. Jawaban untuk pertanyaan mana metrik ML akan meningkatkan laba tergantung pada peningkatan. Bahkan, metrik bisnis entah bagaimana terkait dengan peningkatan laba, tetapi kami hampir tidak pernah berhasil mengaitkan laba secara langsung dengan mereka. Metrik perantara biasanya digunakan, misalnya:
- durasi barang dalam persediaan dan jumlah permintaan barang saat barang tidak tersedia;
- jumlah uang yang akan ditinggalkan pelanggan;
- jumlah bahan yang disimpan dalam proses pembuatan.
Ketika datang untuk mengoptimalkan bisnis menggunakan pembelajaran mesin, penciptaan dua model selalu tersirat: prediksi dan optimasi.
Yang pertama lebih rumit, yang kedua menggunakan hasilnya. Kesalahan dalam model prediksi memaksa kami untuk memberikan margin yang lebih besar dalam model optimisasi, sehingga jumlah yang dioptimalkan berkurang.
Contoh : semakin rendah keakuratan memprediksi perilaku pelanggan atau kemungkinan cacat industri, semakin sedikit pelanggan yang dapat mempertahankan dan semakin sedikit jumlah bahan yang disimpan.
Metrik keberhasilan bisnis (EBITDA, dll.) Yang diterima secara umum jarang diperoleh saat menetapkan tugas ML. Biasanya Anda harus mempelajari secara mendalam spesifik dan menerapkan metrik yang diterima di bidang di mana kami memperkenalkan pembelajaran mesin (rata-rata cek, kehadiran, dll.).
Kesulitan terjemahan
Ironisnya, paling nyaman untuk mengoptimalkan model menggunakan metrik yang sulit dipahami oleh perwakilan bisnis. Bagaimana area di bawah kurva ROC dalam model nada komentar berhubungan dengan ukuran pendapatan tertentu? Dari sudut pandang ini, bisnis menghadapi dua tugas: bagaimana mengukur dan bagaimana memaksimalkan efek dari memperkenalkan pembelajaran mesin?
Tugas pertama lebih mudah diselesaikan jika Anda memiliki data retrospektif dan pada saat yang sama faktor-faktor lain dapat diratakan atau diukur. Maka tidak ada yang mencegah Anda membandingkan nilai yang diperoleh dengan data retrospektif serupa. Tetapi ada satu komplikasi: sampel harus representatif dan pada saat yang sama sama dengan yang kita uji model.
Contoh : Anda perlu mencari pelanggan yang paling mirip untuk mengetahui apakah rata-rata cek mereka meningkat. Tetapi pada saat yang sama, sampel pelanggan harus cukup besar untuk menghindari lonjakan karena perilaku yang tidak biasa. Masalah ini dapat diatasi dengan terlebih dahulu membuat pilihan yang sama dari pelanggan yang sama dan menggunakannya untuk memeriksa hasil dari upaya mereka.
Namun, Anda mungkin bertanya: bagaimana menerjemahkan metrik yang dipilih menjadi fungsi kehilangan (yang diminimalkan model) untuk pembelajaran mesin. Tugas ini tidak dapat diselesaikan dengan segera: pengembang model harus mempelajari proses bisnis secara mendalam. Tetapi jika Anda menggunakan metrik yang tergantung pada bisnis saat melatih model, kualitas model segera tumbuh. Katakanlah, jika model memprediksi pelanggan mana yang akan pergi, maka dalam peran metrik bisnis, Anda dapat menggunakan grafik di mana jumlah klien yang pergi, sesuai dengan model, diplot pada satu sumbu, dan jumlah total dana untuk pelanggan ini diplot pada sumbu lainnya. Dengan bantuan jadwal seperti itu, pelanggan bisnis dapat memilih titik yang nyaman untuk dirinya sendiri dan bekerja dengannya. Jika, menggunakan transformasi linier, kami mengurangi grafik menjadi kurva PR (akurasi pada satu sumbu, kelengkapan kedua), maka kami dapat mengoptimalkan area di bawah kurva ini secara bersamaan dengan metrik bisnis.
 Fig. 4. Kurva efek uang
Fig. 4. Kurva efek uangKesimpulan
Sebelum menetapkan tugas untuk pembelajaran mesin dan membuat model, Anda harus memilih metrik yang masuk akal. Jika Anda akan mengoptimalkan model, maka Anda dapat menggunakan salah satu metrik standar sebagai fungsi kesalahan. Pastikan untuk berkoordinasi dengan pelanggan metrik yang dipilih, bobotnya dan parameter lainnya, mengonversi metrik bisnis menjadi model ML. Dalam hal durasi, ini dapat dibandingkan dengan pengembangan model itu sendiri, tetapi tanpa ini tidak masuk akal untuk mulai bekerja. Jika Anda melibatkan ahli matematika dalam mempelajari proses bisnis, Anda dapat sangat mengurangi kemungkinan kesalahan dalam metrik. Optimalisasi model yang efektif tidak mungkin dilakukan tanpa memahami bidang subjek dan pernyataan bersama tentang masalah di tingkat bisnis dan statistik. Dan setelah semua perhitungan, Anda akan dapat mengevaluasi laba (atau tabungan), tergantung pada setiap peningkatan model.
Nikolay Knyazev ( iRumata ), Kepala Kelompok Pembelajaran Mesin, Jet Infosystems