
Baru-baru ini, phishing telah menjadi cara termudah dan paling populer bagi penjahat cyber untuk mencuri uang atau informasi. Sebagai contoh, Anda tidak perlu melangkah jauh. Tahun lalu, perusahaan-perusahaan Rusia terkemuka menghadapi serangan berskala besar yang belum pernah terjadi sebelumnya - para penyerang secara besar-besaran mendaftarkan sumber daya palsu, salinan persis dari situs pabrik pupuk dan petrokimia untuk menyimpulkan kontrak atas nama mereka. Kerusakan rata-rata dari serangan semacam itu adalah dari 1,5 juta rubel, belum lagi kerusakan reputasi yang diderita perusahaan. Dalam artikel ini, kita akan berbicara tentang cara mendeteksi situs phishing secara efektif menggunakan analisis sumber daya (CSS, gambar JS, dll.) Daripada HTML, dan bagaimana spesialis Ilmu Data dapat menyelesaikan masalah ini.
Pavel Slipenchuk, Arsitek Sistem Pembelajaran Mesin, Group-IB
Epidemi Phishing
Menurut Group-IB, lebih dari 900 klien dari berbagai bank menjadi korban phishing keuangan sendirian di Rusia setiap hari - angka ini 3 kali lipat dari jumlah harian korban malware. Kerusakan dari satu serangan phishing pada pengguna bervariasi dari 2.000 hingga 50.000 rubel. Penipu tidak hanya menyalin situs web perusahaan atau bank, logo dan warna perusahaan mereka, konten, detail kontak, mendaftarkan nama domain yang sama, mereka masih aktif mengiklankan sumber daya mereka di jejaring sosial dan mesin pencari. Misalnya, mereka mencoba untuk membawa tautan ke situs phishing mereka ke bagian atas hasil pencarian untuk permintaan "Transfer uang ke kartu". Paling sering, situs palsu dibuat tepat untuk mencuri uang saat mentransfer dari satu kartu ke kartu atau dengan pembayaran instan untuk layanan operator seluler.
Phishing (eng. Phishing, dari memancing - memancing, memancing) adalah bentuk penipuan Internet, yang tujuannya adalah untuk menipu korban agar memberikan informasi rahasia kepada penipu. Paling sering, mereka mencuri kata sandi akses rekening bank untuk mencuri uang lebih lanjut, akun media sosial (untuk memeras uang atau mengirim spam atas nama korban), mendaftar untuk layanan berbayar, milis atau menginfeksi komputer, menjadikannya tautan di botnet.
Dengan metode serangan, ada 2 jenis phishing yang ditargetkan untuk pengguna dan perusahaan:
- Situs phishing yang menyalin sumber asli korban (bank, maskapai penerbangan, toko online, perusahaan, agen pemerintah, dll.).
- Surat phising, email, sms, pesan di jejaring sosial, dll.
Individu sering diserang oleh pengguna, dan ambang batas untuk memasuki segmen bisnis kriminal ini sangat rendah sehingga "investasi" minimal dan pengetahuan dasar cukup untuk mengimplementasikannya. Penyebaran jenis penipuan ini juga difasilitasi oleh kit phishing, program pembuat situs phishing yang dapat dibeli secara bebas di Darknet di forum peretas.
Serangan terhadap perusahaan atau bank berbeda. Mereka dilakukan oleh penyerang yang secara teknis lebih cerdas. Sebagai aturan, perusahaan industri besar, toko online, maskapai penerbangan, dan paling sering bank, dipilih sebagai korban. Dalam kebanyakan kasus, phishing diturunkan untuk mengirim email dengan file yang terinfeksi terlampir. Agar serangan seperti itu berhasil, "staf" kelompok perlu memiliki spesialis dalam menulis kode berbahaya, dan programmer untuk mengotomatiskan kegiatan mereka, dan orang-orang yang dapat melakukan intelijen utama pada korban dan menemukan kelemahan dalam dirinya.
Di Rusia, menurut perkiraan kami, ada 15 kelompok kriminal yang terlibat dalam phishing yang ditujukan untuk lembaga keuangan. Jumlah kerusakan selalu kecil (sepuluh kali lebih sedikit dari Trojans perbankan), tetapi jumlah korban yang mereka pikat ke situs mereka diperkirakan mencapai ribuan setiap hari. Sekitar 10-15% pengunjung situs phishing finansial memasukkan data mereka sendiri.
Ketika halaman phishing muncul, tagihan berlaku berjam-jam, dan kadang-kadang bahkan beberapa menit, karena pengguna mengalami masalah keuangan yang serius, dan dalam kasus perusahaan, kerusakan reputasi juga. Misalnya, beberapa laman phishing yang berhasil tersedia kurang dari sehari, tetapi dapat menimbulkan kerusakan pada jumlah 1.000.000 rubel.
Pada artikel ini, kita akan membahas jenis phishing pertama: situs phishing. Sumber daya yang "dicurigai" phishing dapat dengan mudah dideteksi menggunakan berbagai cara teknis: honeypot, crawler, dll. Namun, bermasalah untuk memastikan bahwa mereka benar-benar phishing dan untuk mengidentifikasi merek yang diserang. Mari kita cari tahu cara mengatasi masalah ini.
Memancing
Jika suatu merek tidak memonitor reputasinya, itu menjadi sasaran empuk. Perlu untuk mengambil inisiatif dari penjahat segera setelah mendaftarkan situs palsu mereka. Dalam praktiknya, pencarian halaman phishing dibagi menjadi 4 tahap:
- Pembentukan banyak alamat mencurigakan (URL) untuk pemindaian phising (perayap, honeypots, dll.).
- Pembentukan banyak alamat phishing.
- Klasifikasi alamat phishing yang sudah terdeteksi berdasarkan area aktivitas dan teknologi yang diserang, misalnya, "RBS :: Sberbank Online" atau "RBS :: Alfa-Bank".
- Cari halaman donor.
Implementasi paragraf 2 dan 3 berada di pundak spesialis dalam Ilmu Data.
Setelah itu, Anda sudah dapat mengambil langkah aktif untuk memblokir halaman phishing. Khususnya:
- daftar hitamkan produk-produk Grup-IB dan produk-produk mitra kami;
- secara otomatis atau manual mengirim surat ke pemilik zona domain dengan permintaan untuk menghapus URL phishing;
- mengirim surat ke layanan keamanan merek yang diserang;
- dll.

Metode Analisis HTML
Solusi klasik untuk tugas-tugas memeriksa alamat phishing yang mencurigakan dan secara otomatis mendeteksi merek yang terpengaruh adalah berbagai cara untuk menguraikan halaman sumber HTML. Yang paling sederhana adalah menulis ekspresi reguler. Ini lucu, tetapi trik ini tetap berhasil. Dan hari ini, sebagian besar phisher pemula hanya menyalin konten dari situs asli.
Juga, sistem anti-phishing yang sangat efektif dapat dikembangkan oleh peneliti kit phishing. Tetapi dalam hal ini, Anda perlu memeriksa halaman HTML. Selain itu, solusi ini tidak universal - pengembangannya membutuhkan basis "paus" sendiri. Beberapa perangkat phishing mungkin tidak diketahui oleh peneliti. Dan, tentu saja, analisis setiap "paus" baru adalah proses yang agak melelahkan dan mahal.
Semua sistem deteksi phishing berdasarkan analisis halaman HTML berhenti bekerja setelah kebingungan HTML. Dan dalam banyak kasus cukup mengubah bingkai halaman HTML.
Menurut Group-IB, saat ini tidak ada lebih dari 10% dari situs phishing tersebut, tetapi bahkan kehilangan satu pun dapat sangat merugikan korban.
Jadi, bagi seorang nelayan untuk memotong kunci, cukup dengan cukup mengubah kerangka HTML, lebih jarang - mengaburkan halaman HTML (mengacaukan markup dan / atau memuat konten melalui JS).
Pernyataan masalah. Metode Berbasis Sumberdaya
Metode yang didasarkan pada analisis sumber daya yang digunakan jauh lebih efektif dan universal untuk mendeteksi halaman phishing. Sumber daya adalah semua file yang diunggah saat merender halaman web (semua gambar, cascading style sheets (CSS), file JS, font, dll.).
Dalam hal ini, Anda bisa membuat grafik bipartit, di mana beberapa simpul akan dicurigai phishing, sementara yang lain akan menjadi sumber daya yang terkait dengannya.
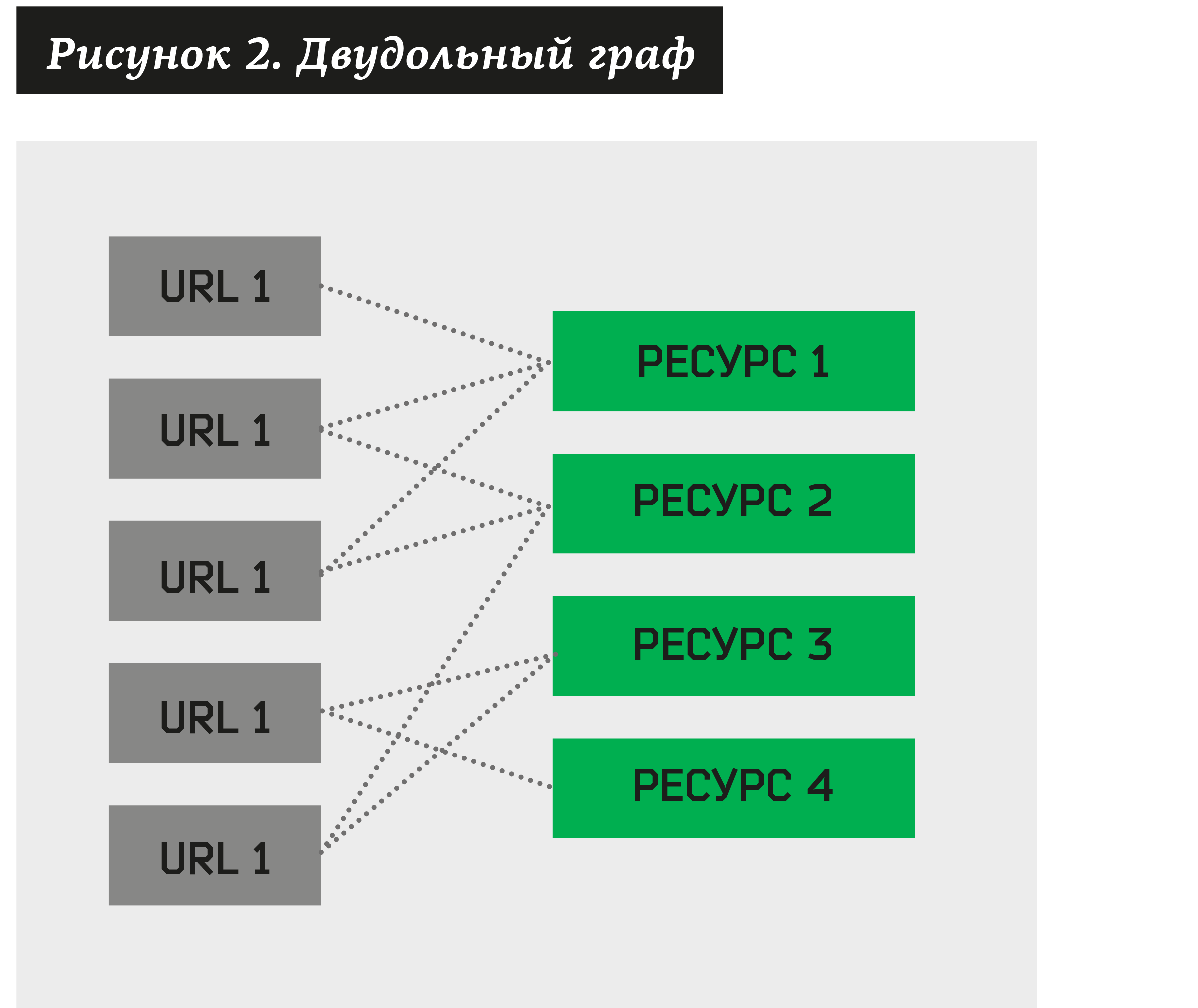
Tugas pengelompokan muncul - untuk menemukan kumpulan sumber daya yang memiliki sejumlah besar URL yang berbeda. Dengan membuat algoritma seperti itu, kita dapat menguraikan grafik bipartit menjadi kelompok.
Hipotesisnya adalah bahwa, berdasarkan data nyata, dengan tingkat probabilitas yang cukup tinggi dapat dikatakan bahwa cluster berisi kumpulan URL yang milik merek yang sama dan dihasilkan oleh satu kit phishing. Kemudian, untuk menguji hipotesis ini, setiap gugus tersebut dapat dikirim untuk verifikasi manual ke CERT (Pusat Respons Insiden Keamanan Informasi). Analis, pada gilirannya, akan memberikan status kluster: +1 ("disetujui") atau –1 (ditolak). Seorang analis juga akan menetapkan merek yang diserang untuk semua kelompok yang disetujui. "Pekerjaan manual" ini berakhir - sisa prosesnya adalah otomatis. Rata-rata, satu akun grup yang disetujui untuk 152 alamat phising (data per Juni 2018), dan kadang-kadang cluster 500-1000 alamat bahkan muncul! Analis menghabiskan sekitar 1 menit untuk menyetujui atau menyangkal cluster.
Kemudian, semua cluster yang ditolak dihapus dari sistem, dan setelah beberapa saat semua alamat dan sumber daya mereka dimasukkan lagi ke input algoritma pengelompokan. Hasilnya, kami mendapat kelompok baru. Dan lagi kami mengirim mereka untuk verifikasi, dll.
Dengan demikian, untuk setiap alamat yang baru diterima, sistem harus melakukan hal berikut:
- Ekstrak banyak sumber daya untuk situs ini.
- Periksa setidaknya satu kluster yang sebelumnya disetujui.
- Jika URL milik cluster mana pun, ekstrak secara otomatis nama merek dan lakukan tindakan untuknya (beri tahu pelanggan, hapus sumber daya, dll.).
- Jika tidak ada cluster yang dapat ditugaskan ke sumber daya, tambahkan alamat dan sumber daya ke grafik bipartit. Di masa mendatang, URL dan sumber daya ini akan berpartisipasi dalam pembentukan cluster baru.
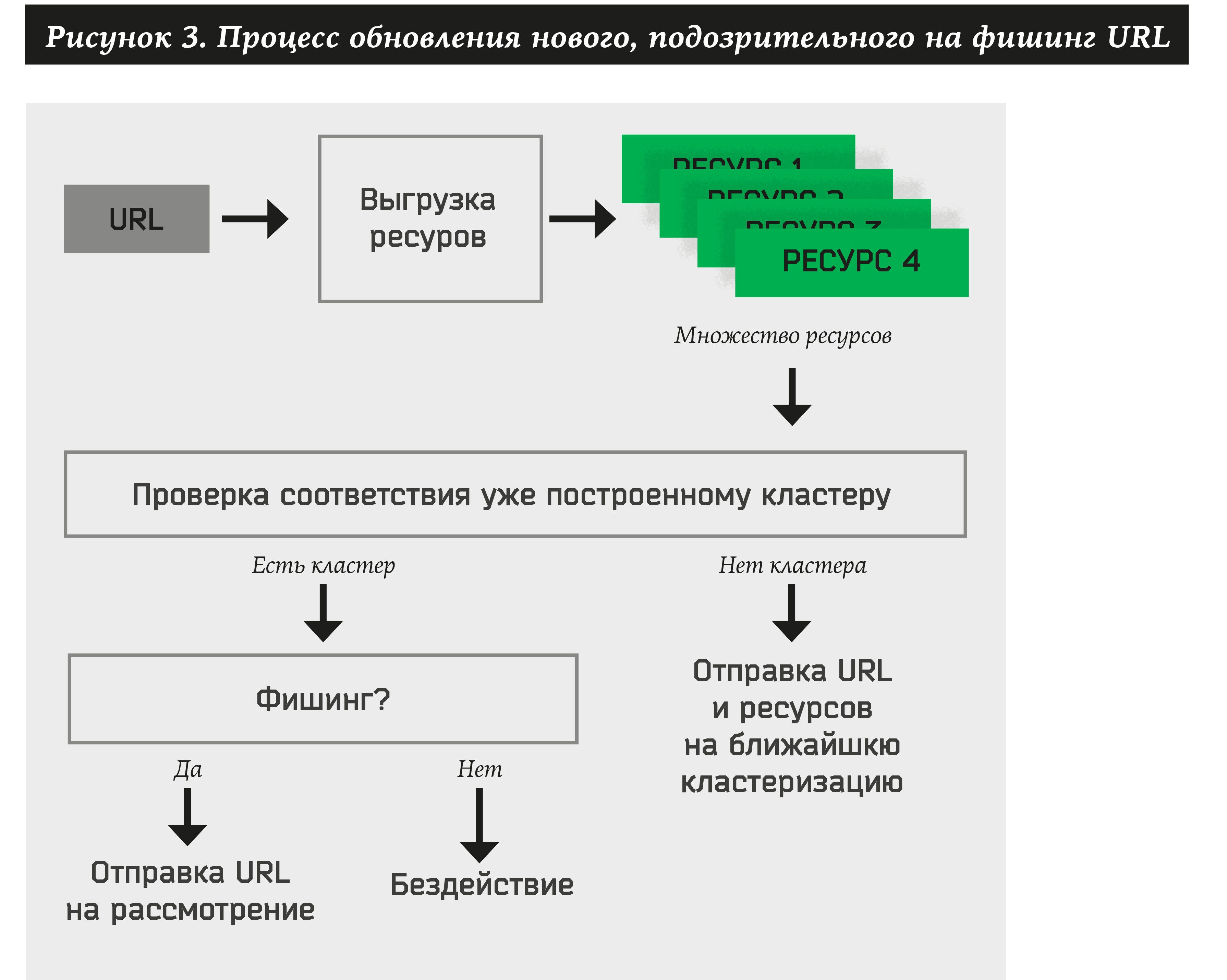
Algoritma Clustering Sumber Daya Sederhana
Salah satu nuansa paling penting yang harus diperhitungkan oleh spesialis Ilmu Data dalam keamanan informasi adalah kenyataan bahwa seseorang adalah lawannya. Karena alasan ini, kondisi dan data untuk analisis berubah sangat cepat! Solusi yang sangat memperbaiki masalah sekarang, setelah 2-3 bulan, mungkin berhenti bekerja secara prinsip. Karena itu, penting untuk membuat mekanisme universal (kikuk), jika mungkin, atau sistem yang paling fleksibel yang dapat dikembangkan dengan cepat. Spesialis Ilmu Data dalam Keamanan Informasi tidak dapat menyelesaikan masalah sekali dan untuk semua.
Metode pengelompokan standar tidak berfungsi karena banyaknya fitur. Setiap sumber daya dapat direpresentasikan sebagai atribut Boolean. Namun, dalam praktiknya, kami mendapatkan dari 5.000 alamat situs web setiap hari, dan masing-masing berisi rata-rata 17,2 sumber daya (data untuk Juni 2018). Kutukan dimensi bahkan tidak memungkinkan memuat data ke memori, apalagi membangun algoritma pengelompokan apa pun.
Gagasan lain adalah mencoba mengelompokkan ke dalam kluster menggunakan berbagai algoritma penyaringan kolaboratif. Dalam hal ini, perlu untuk membuat fitur lain - milik merek tertentu. Tugas akan dikurangi menjadi fakta bahwa sistem harus memprediksi ada atau tidak adanya tanda ini untuk URL yang tersisa. Metode ini memberikan hasil positif, tetapi memiliki dua kelemahan:
- untuk setiap merek perlu menciptakan karakteristiknya sendiri untuk penyaringan kolaboratif;
- membutuhkan sampel pelatihan.
Baru-baru ini, semakin banyak perusahaan ingin melindungi merek mereka di Internet dan meminta untuk mengotomatiskan deteksi situs phishing. Setiap merek baru yang dilindungi akan menambah atribut baru. Dan untuk membuat sampel pelatihan untuk setiap merek baru adalah pekerjaan manual tambahan dan waktu.
Kami mulai mencari solusi untuk masalah ini. Dan mereka menemukan cara yang sangat sederhana dan efektif.
Untuk memulai, kami akan membangun pasangan sumber daya menggunakan algoritma berikut:
- Ambil semua jenis sumber daya (kami tunjukkan sebagai a) yang setidaknya memiliki alamat N1, kami menyatakan hubungan ini sebagai # (a) ≥ N1.
- Kami membangun semua jenis pasangan sumber daya (a1, a2) dan memilih hanya mereka yang setidaknya akan memiliki alamat N2, yaitu # (a1, a2) ≥ N2.
Kemudian kami juga mempertimbangkan pasangan yang terdiri dari pasangan yang diperoleh pada paragraf sebelumnya. Hasilnya, kita mendapatkan posisi merangkak: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). Selain itu, jika setidaknya satu elemen hadir dalam salah satu pasangan, bukannya merangkak kita mendapatkan tiga kali lipat: (a1, a2) + (a2, a3) → (a1, a2, a3). Dari set yang dihasilkan, kami hanya meninggalkan merangkak dan tiga kali lipat yang sesuai dengan setidaknya N3 alamat. Dan seterusnya ...
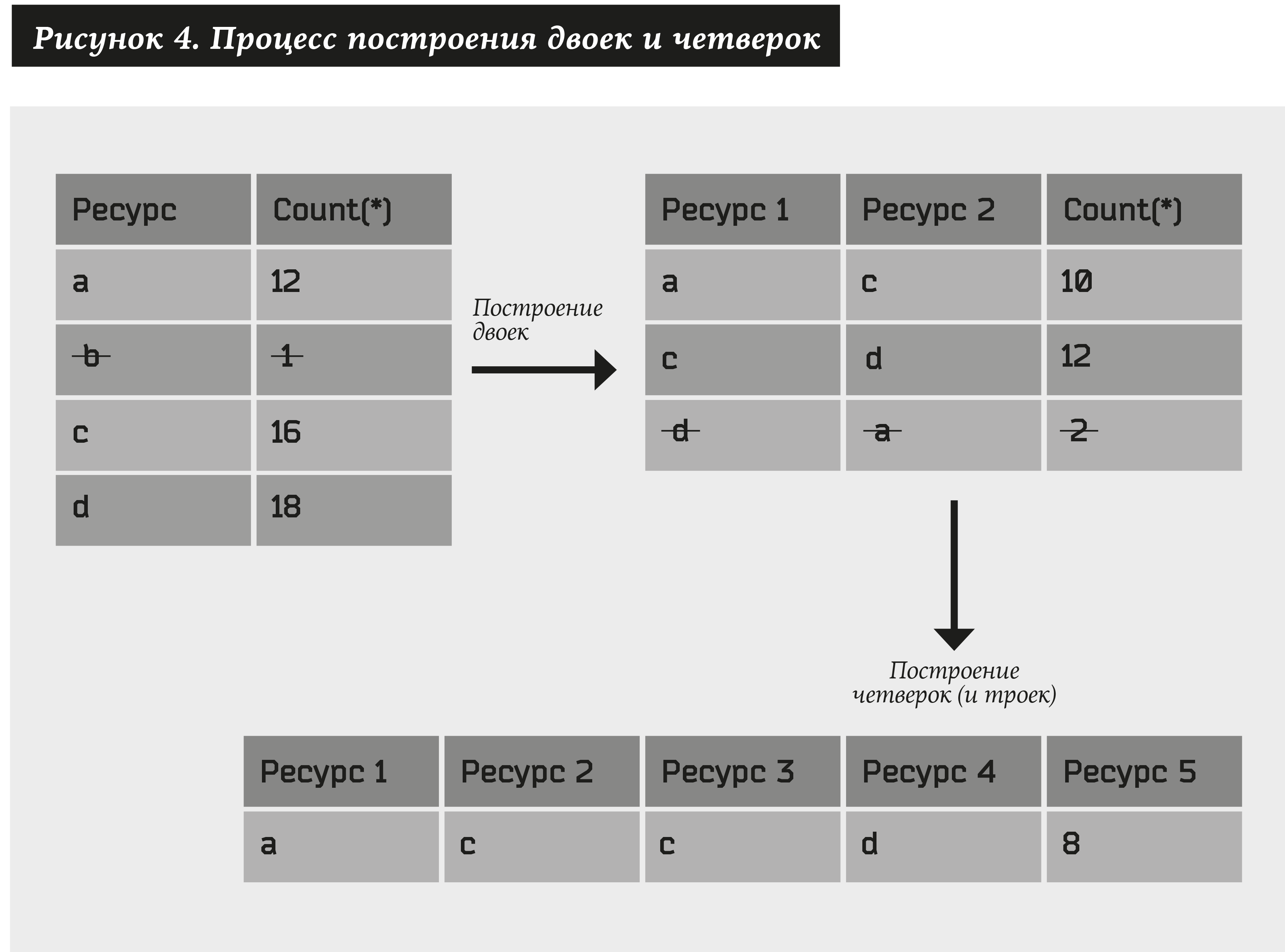
Anda bisa mendapatkan banyak sumber dengan panjang sewenang-wenang. Batasi jumlah langkah ke U. Kemudian N1, N2 ... NU adalah parameter sistem.
Nilai-nilai N1, N2 ... NU adalah parameter dari algoritma, mereka ditetapkan secara manual. Dalam kasus umum, kami memiliki pasangan CL2 yang berbeda, di mana L adalah jumlah sumber daya, mis. kesulitan untuk membangun pasangan adalah O (L2). Kemudian quad dibuat dari masing-masing pasangan. Dan secara teori, kita mungkin mendapatkan O (L4). Namun, dalam praktiknya, pasangan semacam itu jauh lebih kecil, dan dengan sejumlah besar alamat, ketergantungan O (L2log L) diperoleh secara empiris. Terlebih lagi, langkah-langkah selanjutnya (mengubah pasangan menjadi merangkak, empat kali lipat menjadi delapan, dll.) Dapat diabaikan.
Perlu dicatat bahwa L adalah jumlah URL yang tidak berkerumun. Semua URL yang sudah dapat dikaitkan dengan cluster yang disetujui sebelumnya tidak termasuk dalam pemilihan untuk clustering.
Pada output, Anda dapat membuat banyak cluster yang terdiri dari set sumber daya terbesar yang mungkin. Sebagai contoh, jika ada (a1, a2, a3, a4, a5) memenuhi batas Ni, seseorang harus menghapus dari kumpulan cluster (a1, a2, a3) dan (a4, a5).
Kemudian setiap cluster yang diterima dikirim untuk verifikasi manual, di mana analis CERT menetapkannya status: +1 ("disetujui") atau –1 ("ditolak"), dan juga menunjukkan apakah URL yang masuk ke dalam cluster adalah situs phishing atau sah.
Saat Anda menambahkan sumber daya baru, jumlah URL dapat berkurang, tetap sama, tetapi tidak pernah meningkat. Oleh karena itu, untuk sumber daya apa pun ... ... dan hubungannya benar:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Oleh karena itu, bijaksana untuk mengatur parameter:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
Di bagian keluaran, kami memberikan semua jenis grup untuk verifikasi. Dalam gbr. 1 di awal artikel ini menyajikan kelompok nyata yang semua sumbernya berupa gambar.
Menggunakan algoritma dalam praktik
Perhatikan bahwa sekarang Anda tidak perlu lagi menjelajahi kit phishing! Sistem secara otomatis mengelompokkan dan menemukan halaman phishing yang diperlukan.
Setiap hari, sistem menerima dari 5.000 halaman phishing dan membangun total 3 hingga 25 kluster baru per hari. Untuk setiap cluster, daftar sumber daya diunggah, banyak tangkapan layar dibuat. Cluster ini dikirim ke analytics CERT untuk konfirmasi atau penolakan.
Saat startup, akurasi algoritme rendah - hanya 5%. Namun, setelah 3 bulan, sistem menjaga akurasi dari 50 hingga 85%. Faktanya, akurasi tidak masalah! Yang utama adalah para analis punya waktu untuk melihat kluster. Karena itu, jika sistem, misalnya, menghasilkan sekitar 10.000 cluster per hari dan Anda hanya memiliki satu analis, Anda harus mengubah parameter sistem. Jika tidak lebih dari 200 per hari, ini adalah tugas yang layak untuk satu orang. Sebagai latihan menunjukkan, analisis visual rata-rata membutuhkan waktu sekitar 1 menit.
Kelengkapan sistem sekitar 82%. 18% sisanya merupakan kasus unik phishing (oleh karena itu, mereka tidak dapat dikelompokkan), atau phishing, yang memiliki sejumlah kecil sumber daya (tidak ada yang dikelompokkan berdasarkan), atau laman phishing yang melampaui batas parameter N1, N2 ... NU.
Poin penting: seberapa sering memulai pengelompokan baru pada URL baru yang tidak terkirim? Kami melakukan ini setiap 15 menit. Selain itu, tergantung pada jumlah data, waktu pengelompokan itu sendiri memakan waktu 10-15 menit. Ini berarti bahwa setelah kemunculan URL phising ada jeda waktu 30 menit.
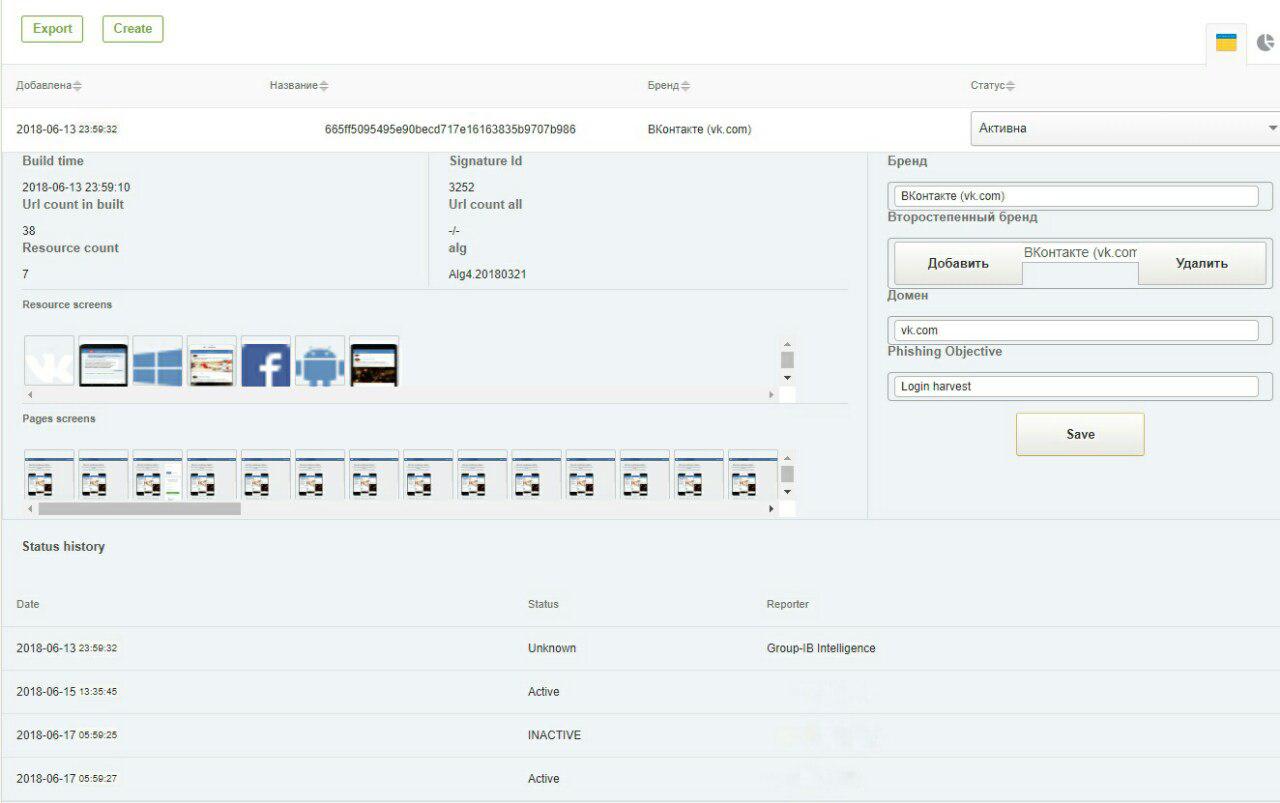
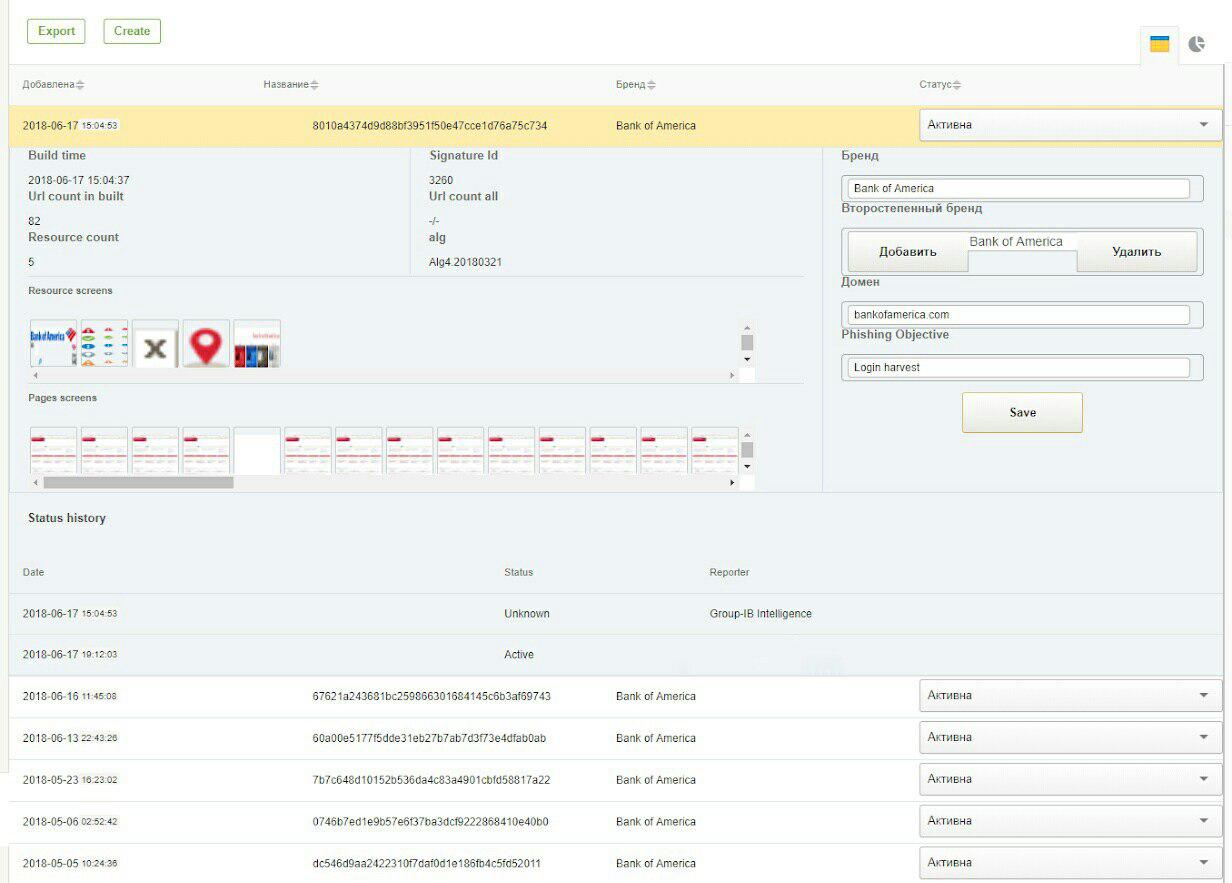
Berikut adalah 2 tangkapan layar dari sistem GUI: tanda tangan untuk mendeteksi phishing di jejaring sosial VKontakte dan Bank Of America.
Saat algoritma tidak bekerja
Seperti disebutkan di atas, algoritma tidak bekerja pada prinsipnya jika batas yang ditentukan oleh parameter N1, N2, N3 ... NU tidak tercapai, atau jika jumlah sumber daya terlalu kecil untuk membentuk cluster yang diperlukan.
Phisher dapat mem-bypass algoritme dengan membuat sumber daya unik untuk setiap situs phishing. Misalnya, di setiap gambar Anda dapat mengubah satu piksel, dan untuk pustaka JS dan CSS yang dimuat, gunakan pengaburan. Dalam hal ini, perlu untuk mengembangkan algoritma hash yang sebanding (hash perseptual) untuk setiap jenis dokumen yang dimuat. Namun, masalah ini berada di luar cakupan artikel ini.
Menyatukan semuanya
Kami menghubungkan modul kami dengan pelanggan HTML klasik, data yang diperoleh dari Threat Intelligence (sistem intelijen cyber), dan kami mendapatkan kepenuhan 99,4%. Tentu saja, ini adalah kelengkapan data yang sebelumnya telah diklasifikasikan oleh Threat Intelligence sebagai phising yang mencurigakan.
Tidak ada yang tahu kelengkapan semua data yang mungkin, karena pada prinsipnya tidak mungkin untuk mencakup seluruh Darknet, menurut laporan Gartner, IDC dan Forrester, Group-IB adalah salah satu penyedia solusi Threat Intelligence internasional terkemuka dalam kemampuannya.
Bagaimana dengan halaman phishing yang tidak rahasia? Sekitar 25-50 dari mereka sehari. Mereka dapat diperiksa secara manual. Secara keseluruhan, selalu ada tenaga manual dalam tugas apa pun yang cukup sulit bagi Data Sciense di bidang keamanan informasi, dan setiap dugaan otomatisasi 100 persen adalah fiksi pemasaran. Tugas spesialis Data Sciense adalah mengurangi tenaga kerja manual sebanyak 2-3 kali lipat, membuat analis bekerja seefisien mungkin.
Artikel dipublikasikan di
JETINFO