
Saat ini, pengembangan perangkat lunak berkualitas tinggi sulit dibayangkan tanpa menggunakan
metode analisis kode statis . Analisis statis kode program dapat dibangun ke dalam lingkungan pengembangan (dengan metode standar atau menggunakan plug-in), dapat dilakukan oleh perangkat lunak khusus sebelum kode dimasukkan ke dalam operasi komersial, atau "secara manual" oleh pakar reguler atau eksternal.
Sering diperdebatkan bahwa
analisis kode dinamis atau
uji penetrasi dapat menggantikan analisis statis, karena metode verifikasi ini akan mengungkapkan masalah nyata dan tidak akan ada kesalahan positif. Namun, ini adalah poin yang diperdebatkan, karena analisis dinamis, tidak seperti analisis statis, tidak memeriksa semua kode, tetapi hanya memeriksa resistensi perangkat lunak terhadap serangkaian serangan yang meniru tindakan penyerang. Penyerang mungkin lebih inventif daripada verifier, terlepas dari siapa yang melakukan verifikasi: seseorang atau mesin.
Analisis dinamis akan lengkap hanya jika dilakukan pada cakupan uji penuh, yang, ketika diterapkan pada aplikasi nyata, adalah tugas yang sulit. Bukti kelengkapan cakupan tes merupakan masalah yang secara algoritmik tidak dapat diselesaikan.
Analisis statis wajib terhadap kode program adalah salah satu langkah yang diperlukan ketika menugaskan perangkat lunak dengan peningkatan persyaratan untuk keamanan informasi.
Saat ini, ada banyak penganalisa kode statis yang berbeda di pasaran, dan semakin banyak yang baru terus muncul. Dalam praktiknya, ada beberapa kasus ketika beberapa analisis statis digunakan bersama untuk meningkatkan kualitas verifikasi, karena analisis yang berbeda mencari cacat yang berbeda.
Mengapa tidak ada penganalisa statis universal yang akan sepenuhnya memeriksa kode apa pun dan menemukan semua cacat di dalamnya tanpa kesalahan positif dan pada saat yang sama bekerja dengan cepat dan tidak memerlukan banyak sumber daya (waktu dan memori CPU)?
Sedikit tentang arsitektur analisa statis
Jawaban atas pertanyaan ini terletak pada arsitektur alat analisis statis. Hampir semua analisa statis dibangun berdasarkan prinsip kompiler, yaitu, dalam pekerjaan mereka terdapat tahapan konversi kode sumber - sama seperti yang dilakukan oleh kompiler.
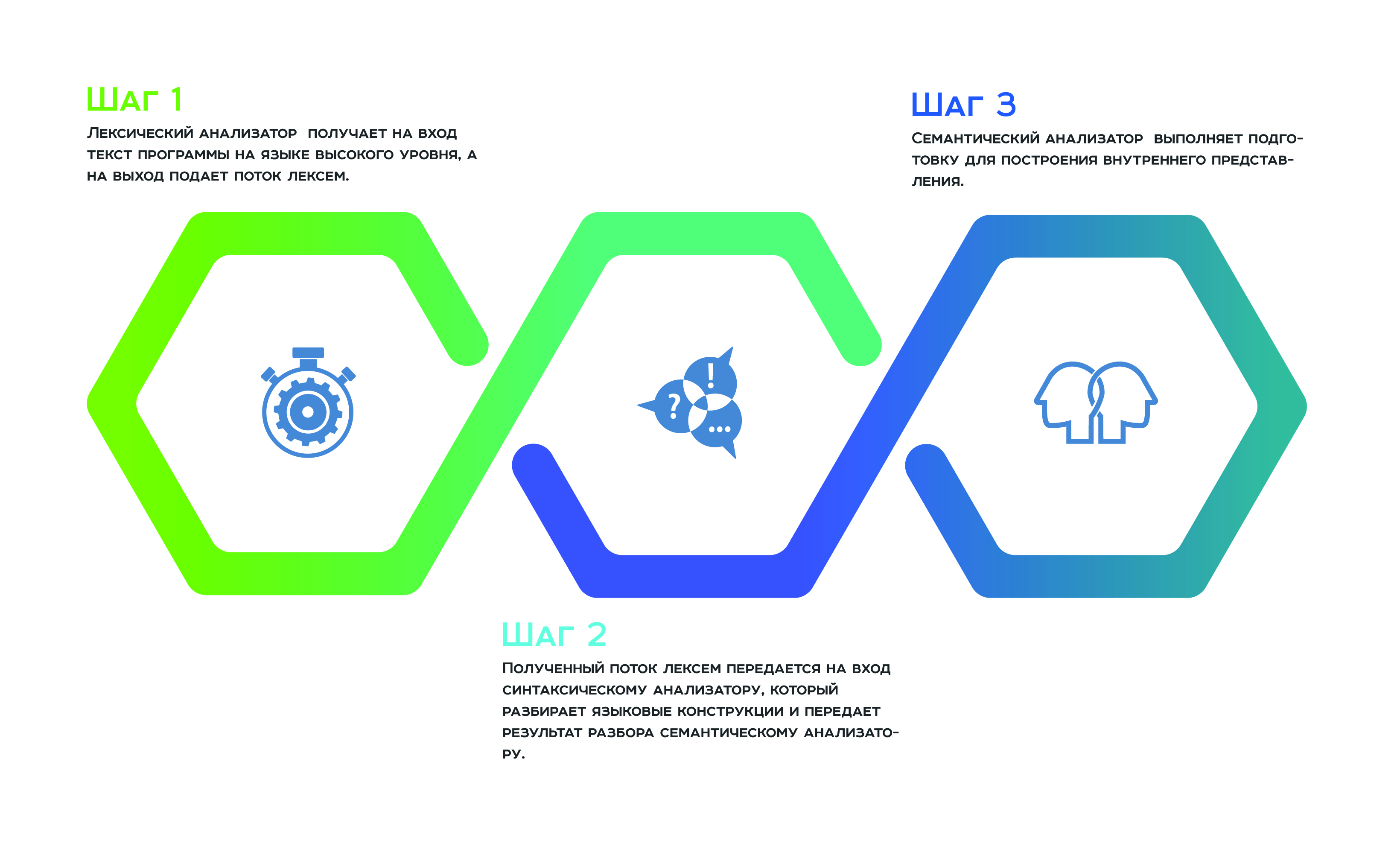
Semuanya dimulai dengan
analisis leksikal , yang menerima teks program dalam bahasa tingkat tinggi sebagai input, dan aliran token ke output. Selanjutnya, aliran token yang diterima ditransmisikan ke input
ke parser , yang mem-parsing konstruksi bahasa dan meneruskan hasil penguraian ke
penganalisis semantik , yang, sebagai akibat dari pekerjaannya, bersiap untuk membangun representasi internal. Representasi internal ini adalah fitur dari setiap analisa statis. Efisiensi penganalisis tergantung pada seberapa sukses itu.
Banyak produsen penganalisa statis mengklaim menggunakan representasi internal universal untuk semua bahasa pemrograman yang didukung oleh penganalisa. Dengan demikian, mereka dapat menganalisis kode program yang dikembangkan dalam beberapa bahasa secara keseluruhan, dan bukan sebagai komponen yang terpisah. Suatu "pendekatan holistik" untuk analisis memungkinkan menghindari penghilangan cacat yang muncul pada antarmuka antara komponen individu dari produk perangkat lunak.
Secara teori, ini benar, tetapi dalam praktiknya, representasi internal universal untuk semua bahasa pemrograman sulit dan tidak efisien. Setiap bahasa pemrograman adalah khusus. Tampilan internal biasanya pohon yang simpulnya menyimpan atribut. Dengan melintasi pohon seperti itu, penganalisa mengumpulkan dan mengubah informasi. Oleh karena itu, setiap simpul pohon harus berisi sekumpulan atribut yang seragam. Karena setiap bahasa adalah unik, keseragaman atribut hanya dapat didukung oleh redundansi komponen. Bahasa pemrograman yang lebih heterogen, komponen yang lebih heterogen dalam karakteristik setiap titik, dan oleh karena itu, representasi internal tidak efisien dari memori. Sejumlah besar karakteristik heterogen juga mempengaruhi kerumitan pejalan kaki pohon, yang berarti bahwa hal itu mengarah pada inefisiensi dalam kinerja.
Konversi Optimasi untuk Analisis Statis
Agar penganalisa statis dapat bekerja secara efisien dalam memori dan waktu, Anda harus memiliki representasi internal universal yang ringkas, dan ini dapat dicapai dengan fakta bahwa representasi internal dibagi menjadi beberapa pohon, yang masing-masing dirancang untuk bahasa pemrograman terkait.
Pekerjaan optimisasi tidak terbatas pada pembagian representasi internal ke dalam bahasa pemrograman terkait. Lebih jauh, pabrikan menggunakan berbagai transformasi optimisasi - sama seperti pada teknologi kompiler, khususnya,
transformasi optimisasi siklus . Faktanya adalah bahwa tujuan analisis statis idealnya adalah untuk melakukan promosi data dalam program untuk mengevaluasi transformasi mereka selama pelaksanaan program. Oleh karena itu, data harus "maju" melalui setiap putaran siklus. Jadi, jika Anda menghemat belokan ini dan membuatnya lebih kecil, maka kami akan mendapatkan manfaat yang signifikan baik dalam memori maupun dalam kinerja. Untuk maksud inilah transformasi semacam itu digunakan secara aktif sehingga, dengan beberapa kemungkinan, melakukan ekstrapolasi transformasi data ke semua putaran siklus dengan jumlah lintasan minimum.
Anda juga dapat menghemat cabang dengan menghitung kemungkinan bahwa program akan berjalan di satu atau cabang lain. Jika probabilitas melewati sepanjang cabang lebih rendah dari ini, maka cabang program ini tidak dipertimbangkan.
Jelas, setiap transformasi ini "kehilangan" cacat yang harus dideteksi oleh penganalisa, tetapi ini adalah "biaya" untuk efisiensi dan kinerja memori.
Apa yang dicari oleh penganalisa kode statis?
Secara kondisional, cacat yang entah bagaimana tertarik pada penyusup, dan karenanya, auditor, dapat dibagi ke dalam kelompok berikut:
- kesalahan validasi
- kesalahan kebocoran informasi,
- kesalahan otentikasi.
Kesalahan validasi terjadi karena fakta bahwa data input tidak cukup diperiksa untuk kebenarannya. Seorang penyerang dapat menyelinap sebagai input apa yang bukan yang diharapkan oleh program, dan dengan demikian memperoleh akses tidak sah ke kontrol. Kesalahan validasi data yang paling umum adalah suntikan dan
XSS . Alih-alih data yang valid, penyerang mengajukan ke input program yang secara khusus menyiapkan data yang membawa program kecil. Program ini, yang sedang diproses, dijalankan. Hasil dari implementasinya mungkin transfer kontrol ke program lain, korupsi data dan banyak lagi. Selain itu, sebagai akibat dari kesalahan validasi, situs tempat pengguna bekerja dapat diganti. Kesalahan validasi dapat dideteksi secara kualitatif dengan metode analisis kode statis.
Kesalahan
kebocoran informasi adalah kesalahan yang terkait dengan fakta bahwa informasi sensitif dari pengguna sebagai hasil pemrosesan dicegat dan dikirim ke penyerang. Bisa juga sebaliknya: informasi sensitif yang disimpan dalam sistem dicegat dan dikirim ke penyerang ketika bergerak ke pengguna.
Kerentanan semacam itu sama sulitnya dideteksi dengan kesalahan validasi. Deteksi kesalahan semacam ini membutuhkan pelacakan dalam statistik kemajuan dan konversi data di seluruh kode program. Ini membutuhkan implementasi metode seperti
analisis noda dan
analisis data antar -
prosedur . Keakuratan analisis sangat tergantung pada seberapa baik metode ini dikembangkan, yaitu, meminimalkan kesalahan positif dan kesalahan yang terlewatkan.
Perpustakaan aturan untuk mendeteksi cacat, khususnya, format untuk menggambarkan aturan-aturan ini, juga memainkan peran penting dalam akurasi penganalisa statis. Semua ini merupakan keunggulan kompetitif dari masing-masing penganalisa dan dijaga ketat dari pesaing.
Kesalahan otentikasi adalah
kesalahan yang paling menarik bagi penyerang, karena mereka sulit dideteksi karena mereka muncul di persimpangan komponen dan sulit untuk diformalkan. Penyerang mengeksploitasi kesalahan semacam ini untuk meningkatkan hak akses. Kesalahan otentikasi tidak secara otomatis terdeteksi, karena tidak jelas apa yang harus dicari - ini adalah kesalahan dalam logika membangun program.
Kesalahan Memori
Mereka sulit dideteksi karena identifikasi yang akurat membutuhkan penyelesaian sistem persamaan yang rumit, yang mahal dalam memori dan kinerja. Oleh karena itu, sistem persamaan berkurang, yang berarti keakuratannya hilang.
Kesalahan memori yang umum termasuk
penggunaan-setelah-bebas ,
bebas- ganda ,
null-pointer-dereference dan
variasinya , misalnya,
out-of-bounds-Read dan
out-of-bounds-Write .
Ketika penganalisa berikutnya gagal mendeteksi kebocoran memori, Anda dapat mendengar bahwa kerusakan seperti itu sulit untuk dieksploitasi. Seorang penyerang harus sangat berkualitas dan menerapkan banyak keterampilan untuk, pertama, mencari tahu tentang adanya kerusakan seperti itu dalam kode, dan, kedua, untuk melakukan eksploitasi. Nah, dan selanjutnya argumennya adalah: "Apakah Anda yakin bahwa produk perangkat lunak Anda menarik bagi seorang guru tingkat ini?" ... Namun, sejarah mengetahui kasus ketika kesalahan memori berhasil dieksploitasi dan menyebabkan kerusakan yang cukup besar. Sebagai contoh, Anda dapat mengutip situasi terkenal seperti:
- CVE-2014-0160 - kesalahan di perpustakaan openssl - potensi kompromi kunci pribadi diperlukan penerbitan ulang semua sertifikat dan regenerasi kata sandi.
- CVE-2015-2712 - bug dalam implementasi js di mozilla firefox - cek batas.
- CVE-2010-1117 - digunakan setelah gratis di internet explorer - dapat dieksploitasi dari jarak jauh.
- CVE-2018-4913 - digunakan setelah bebas di Acrobat Reader - eksekusi kode.
Selain itu, penyerang suka mengeksploitasi cacat yang terkait dengan sinkronisasi utas atau proses yang tidak benar. Cacat seperti itu sulit diidentifikasi dalam statika, karena mensimulasikan keadaan mesin tanpa konsep "waktu" bukanlah tugas yang mudah. Ini merujuk pada kesalahan seperti
kondisi ras . Dan hari ini, concurrency digunakan di mana-mana, bahkan dalam aplikasi yang sangat kecil.
Ringkasnya, perlu dicatat bahwa penganalisa statis berguna dalam proses pengembangan, jika digunakan dengan benar. Selama operasi, perlu untuk memahami apa yang diharapkan dari itu dan apa yang harus dilakukan dengan cacat-kerusakan yang pada prinsipnya tidak dapat diidentifikasi oleh analisa statis. Jika mereka mengatakan bahwa analisa statis tidak diperlukan selama proses pengembangan, itu berarti bahwa mereka tidak dapat mengoperasikannya.
Cara mengoperasikan penganalisa statis dengan benar, untuk bekerja dengan benar dan efisien dengan informasi yang diberikannya, baca di blog kami.