
Kami mulai memperbarui pemantauan untuk PgBouncer di layanan kami dan memutuskan untuk menyisir semuanya sedikit. Agar semuanya cocok, kami menggunakan metodologi pemantauan kinerja paling terkenal: USE (Utilization, Saturation, Errors) oleh Brendan Gregg dan RED (Permintaan, Kesalahan, Durasi) dari Tom Wilkie.
Di bawah cutscene adalah cerita dengan grafik tentang bagaimana pgbouncer bekerja, konfigurasi apa yang dipegangnya dan bagaimana, menggunakan USE / RED, untuk memilih metrik yang tepat untuk memonitornya.
Pertama tentang metode itu sendiri
Meskipun metode ini cukup terkenal (tentang mereka itu sudah ada di Habré, meskipun tidak dengan sangat rinci ), bukan bahwa mereka tersebar luas dalam praktik.
GUNAKAN
Untuk setiap sumber daya, catat pembuangan, saturasi, dan kesalahan.
Brendan gregg
Di sini, sumber daya adalah komponen fisik yang terpisah - CPU, disk, bus, dll. Tetapi tidak hanya - kinerja beberapa sumber daya perangkat lunak juga dapat dipertimbangkan dengan metode ini, khususnya sumber daya virtual, seperti wadah / cgroup dengan batas, juga nyaman untuk mempertimbangkan ini.
U - Disposal : baik persentase waktu (dari interval pengamatan) ketika sumber daya sibuk dengan pekerjaan yang bermanfaat. Seperti, misalnya, memuat penggunaan CPU atau disk 90% berarti bahwa 90% dari waktu diambil oleh sesuatu yang bermanfaat) atau, untuk sumber daya seperti memori, ini adalah persentase memori yang digunakan.
Bagaimanapun, 100% daur ulang berarti bahwa sumber daya tidak dapat digunakan lebih dari sekarang. Dan salah satu pekerjaan akan macet menunggu rilis / pergi ke antrian, atau akan ada kesalahan. Dua skenario ini dicakup oleh dua metrik USE yang sesuai:
S - Saturasi , itu juga saturasi: ukuran jumlah "ditangguhkan" / bekerja antri.
E - Kesalahan : kami hanya menghitung jumlah kegagalan. Kesalahan / kegagalan memengaruhi kinerja, tetapi mungkin tidak segera terlihat karena mengambil operasi yang dibalik atau mekanisme toleransi kesalahan dengan perangkat cadangan, dll.
Merah
Tom Wilkie (sekarang bekerja di Grafana Labs) merasa frustrasi dengan metodologi USE, atau lebih tepatnya, penerapannya yang buruk dalam beberapa kasus dan tidak konsisten dengan praktik. Bagaimana, misalnya, untuk mengukur saturasi memori? Atau bagaimana mengukur kesalahan bus sistem dalam praktiknya?
Linux, ternyata, benar-benar melaporkan jumlah bug.
T. Wilkie
Singkatnya, untuk memantau kinerja dan perilaku layanan mikro, ia mengusulkan metode lain yang cocok: untuk mengukur, sekali lagi, tiga indikator:
R - Rate : Jumlah permintaan per detik.
E - Kesalahan : berapa banyak permintaan mengembalikan kesalahan.
D - Durasi : waktu yang dibutuhkan untuk memproses permintaan. Ini adalah latensi, "latensi" (© Sveta Smirnova :), waktu respons, dll.
Secara umum, USE lebih cocok untuk memantau sumber daya, dan RED untuk layanan dan beban kerja / payload mereka.
Pgbouncer
Menjadi layanan, pada saat yang sama ia memiliki segala macam batasan dan sumber daya internal. Hal yang sama dapat dikatakan tentang Postgres, yang diakses oleh klien melalui PgBouncer ini. Oleh karena itu, untuk pemantauan penuh dalam situasi ini, kedua metode diperlukan.
Untuk memahami cara menerapkan metode ini ke penjaga, Anda harus memahami detail perangkatnya. Tidak cukup untuk memantaunya sebagai kotak hitam - "apakah proses pgbouncer hidup" atau "adalah port terbuka", karena jika ada masalah, ini tidak akan memberikan pemahaman tentang apa sebenarnya dan bagaimana itu pecah dan apa yang harus dilakukan.
Apa yang secara umum terlihat seperti apa PgBouncer dari sudut pandang klien:
- klien terhubung
- [klien mengajukan permintaan - menerima tanggapan] x berapa kali ia membutuhkan
Di sini saya telah menggambar diagram status klien yang sesuai dari sudut pandang PgBoucer:

Dalam proses login, otorisasi dapat terjadi baik secara lokal (file, sertifikat, dan bahkan PAM dan hba dari versi baru), dan dari jarak jauh - yaitu: di dalam basis data itu sendiri di mana koneksi sedang dicoba. Dengan demikian, status masuk memiliki substate tambahan. Mari kita sebut Executing untuk menunjukkan bahwa auth_query sedang auth_query di database saat ini:
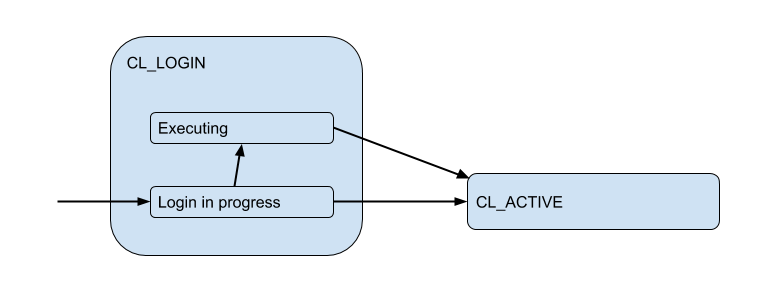
Tetapi koneksi klien ini benar-benar cocok dengan koneksi backend / hulu yang dibuka PgBouncer di dalam kumpulan dan memegang jumlah terbatas. Dan mereka memberikan koneksi seperti itu kepada klien hanya untuk waktu - selama sesi, transaksi atau permintaan, tergantung pada jenis pooling (ditentukan oleh pengaturan pool_mode ). Paling sering, pooling transaksi digunakan (kita akan membahasnya nanti) - ketika koneksi dikeluarkan ke klien untuk satu transaksi, dan sisa waktu klien sebenarnya tidak terhubung ke server. Dengan demikian, keadaan "aktif" klien memberi tahu kami sedikit, dan kami akan membaginya menjadi substrat:
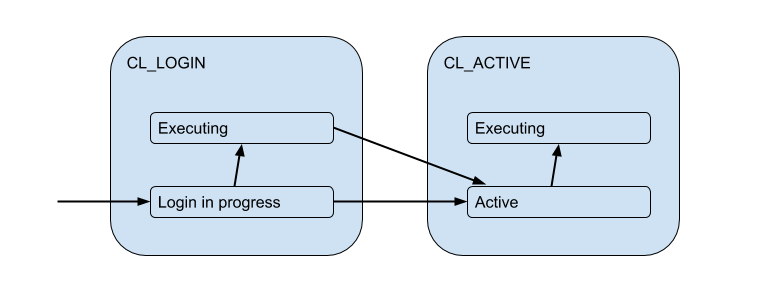
Setiap klien tersebut termasuk dalam kelompok koneksi sendiri, yang akan dikeluarkan untuk digunakan oleh koneksi nyata ke Postgres. Ini adalah tugas utama PgBouncer - untuk membatasi jumlah koneksi ke Postgres.
Karena koneksi server terbatas, suatu situasi dapat muncul ketika klien perlu memenuhi permintaan secara langsung, tetapi tidak ada koneksi gratis sekarang. Kemudian klien diantrekan dan koneksinya masuk ke status CL_WAITING . Dengan demikian, diagram keadaan harus dilengkapi:
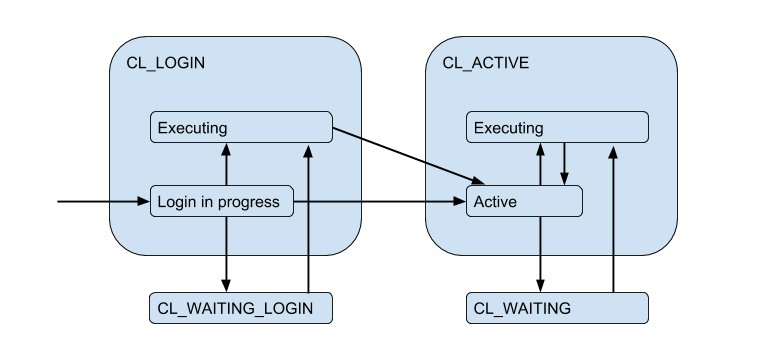
Karena ini dapat terjadi dalam kasus ketika klien hanya masuk dan dia perlu menjalankan permintaan otorisasi, negara CL_WAITING_LOGIN juga CL_WAITING_LOGIN .
Jika sekarang kita melihat dari sisi belakang - dari sisi koneksi server, maka, mereka berada dalam kondisi seperti itu: ketika otorisasi terjadi segera setelah koneksi - SV_LOGIN , dikeluarkan dan (mungkin) digunakan oleh klien - SV_ACTIVE , atau bebas - SV_IDLE .
GUNAKAN untuk PgBouncer
Jadi kita sampai pada (versi naif) Pemanfaatan kumpulan spesifik:
Pool utiliz = /
PgBouncer memiliki database utilitas pgbouncer khusus di mana ada SHOW POOLS yang menampilkan status saat ini dari koneksi setiap kumpulan:

Ada 4 koneksi klien terbuka dan semuanya cl_active . Dari 5 koneksi server - 4 sv_active dan satu di status baru sv_used .
Apa yang benar-benar digunakan tentang pengaturan berbeda pgbouncer yang tidak terkait dengan pemantauanJadi sv_used tidak berarti "koneksi sedang digunakan", seperti yang mungkin Anda pikirkan, tetapi "koneksi pernah digunakan dan tidak pernah digunakan untuk waktu yang lama". Faktanya adalah bahwa PgBouncer menggunakan koneksi server dalam mode LIFO secara default - mis. Pertama, koneksi yang baru dirilis digunakan, kemudian yang baru digunakan, dll. secara bertahap pindah ke senyawa yang sudah lama digunakan. Dengan demikian, koneksi server dari dasar tumpukan seperti itu dapat "memburuk". Dan mereka harus diperiksa untuk keaktifan sebelum digunakan, yang dilakukan menggunakan server_check_query , ketika mereka sedang diperiksa, keadaan akan sv_tested .
Dokumentasi mengatakan bahwa LIFO diaktifkan secara default, sebagai kemudian "sejumlah kecil koneksi mendapat beban kerja paling banyak. Dan ini memberikan kinerja terbaik ketika ada satu server yang melayani database di belakang pgbouncer", yaitu. seolah-olah dalam kasus yang paling khas. Saya percaya bahwa peningkatan kinerja potensial adalah karena penghematan dalam beralih kinerja antara beberapa proses backend. Tapi itu tidak berhasil, karena Detail implementasi ini telah ada selama> 12 tahun dan melampaui sejarah komit di github dan kedalaman minat saya =)
Jadi, sepertinya aneh dan server_check_delay dengan kenyataan saat ini bahwa nilai default dari pengaturan server_check_delay , yang menentukan bahwa server tidak digunakan terlalu lama dan harus diperiksa sebelum memberikannya kepada klien, adalah 30 detik. Ini terlepas dari kenyataan bahwa secara default tcp_keepalive diaktifkan secara bersamaan dengan pengaturan default - mulailah memeriksa koneksi tetap hidup dengan sampel 2 jam setelah idle'ing.
Ternyata dalam situasi ledakan / lonjakan koneksi klien yang ingin melakukan sesuatu di server, penundaan tambahan diperkenalkan pada server_check_query , yang, meskipun " SELECT 1; mungkin masih membutuhkan ~ 100 mikrodetik, dan jika server_check_query = ';' maka Anda dapat menyimpan ~ 30 microseconds =)
Tetapi asumsi bahwa melakukan pekerjaan hanya dalam beberapa koneksi = pada beberapa proses postgres back-end "utama" akan lebih efisien, tampaknya meragukan bagi saya. Informasi proses post cache pekerja cache (meta) tentang setiap tabel yang diakses dalam koneksi ini. Jika Anda memiliki sejumlah besar tabel, maka relcache ini dapat tumbuh sangat banyak dan membutuhkan banyak memori, hingga pertukaran halaman dari proses 0_o. Untuk mengatasinya, gunakan pengaturan server_lifetime (default adalah 1 jam), di mana koneksi server akan ditutup untuk rotasi. Tetapi di sisi lain, ada pengaturan server_round_robin yang akan mengalihkan mode menggunakan koneksi dari LIFO ke FIFO, menyebarkan permintaan klien pada koneksi server lebih merata.
SHOW POOLS mengambil metrik dari SHOW POOLS (oleh beberapa eksportir prometheus) kita dapat merencanakan negara-negara ini:
Tetapi untuk sampai pada pembuangan Anda perlu menjawab beberapa pertanyaan:
- Berapa ukuran kolam?
- Bagaimana cara menghitung berapa banyak senyawa yang digunakan? Dalam lelucon atau dalam waktu, rata-rata atau di puncak?
Ukuran kolam
Semuanya rumit di sini, seperti dalam kehidupan. Secara total, sudah ada lima batas pengaturan di pbbouncer!
pool_size dapat diatur untuk setiap basis data. Kumpulan terpisah dibuat untuk setiap pasangan pengguna / DB, yaitu dari pengguna tambahan apa pun, Anda dapat membuat pool_size lain / pekerja Postgres. Karena jika pool_size tidak disetel, jatuh pada default_pool_size , yang defaultnya adalah 20, maka ternyata setiap pengguna yang memiliki hak untuk terhubung ke database (dan bekerja melalui pgbouncer) berpotensi dapat membuat 20 proses Postgres, yang tampaknya tidak banyak. Tetapi jika Anda memiliki banyak pengguna berbeda dari basis data atau basis data itu sendiri, dan kumpulan tidak terdaftar dengan pengguna tetap, mis. akan dibuat dengan cepat (dan kemudian dihapus oleh autodb_idle_timeout ), maka ini bisa berbahaya =)
Mungkin layak membiarkan default_pool_size kecil, hanya untuk setiap pemadam kebakaran.
max_db_connections - hanya perlu membatasi jumlah koneksi ke satu basis data, karena jika tidak, perilaku klien yang buruk dapat membuat banyak proses backend / postgres. Dan secara default di sini - tidak terbatas ¯_ (ツ) _ / ¯
Mungkin Anda harus mengubah max_db_connections default, misalnya, Anda dapat fokus pada max_connections Postgres Anda (secara default 100). Tetapi jika Anda memiliki banyak PgBouncer ...
reserve_pool_size - sebenarnya, jika pool_size digunakan, maka PgBouncer dapat membuka beberapa koneksi lagi ke basis. Seperti yang saya pahami, ini dilakukan untuk mengatasi lonjakan beban. Kami akan kembali ke sini.max_user_connections - Ini, sebaliknya, adalah batas koneksi dari satu pengguna ke semua database, mis. relevan jika Anda memiliki beberapa database dan mereka menggunakan pengguna yang sama.max_client_conn - berapa banyak koneksi klien yang akan diterima PgBouncer secara total. Default, seperti biasa, memiliki arti yang sangat aneh - 100. Artinya, diasumsikan bahwa jika lebih dari 100 klien tiba-tiba macet, maka mereka hanya perlu reset diam-diam di tingkat TCP dan reset (baik, dalam log, saya harus mengakui, ini akan menjadi "tidak ada lagi koneksi yang diizinkan (max_client_conn)").
Mungkin bernilai membuat max_client_conn >> SUM ( pool_size' ) , misalnya, 10 kali lebih banyak.
Selain SHOW POOLS pgbouncer pseudo-base layanan juga menyediakan perintah SHOW DATABASES , yang menunjukkan batas yang sebenarnya diterapkan pada kumpulan tertentu:

Koneksi server
Sekali lagi - bagaimana mengukur berapa banyak senyawa yang digunakan?
Dalam lelucon rata-rata / dalam puncak / waktu?
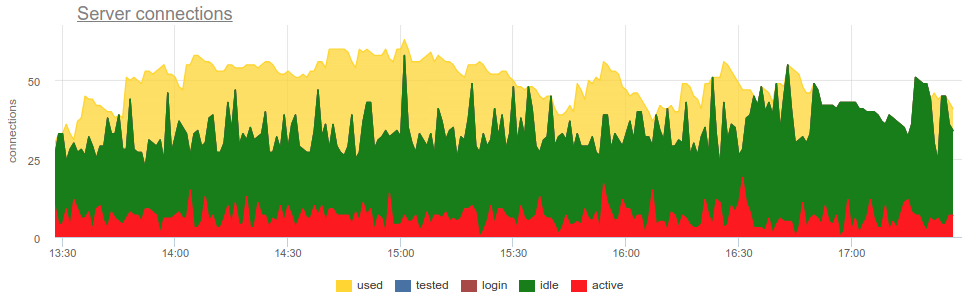
Dalam praktiknya, cukup bermasalah untuk memantau penggunaan kolam oleh penjaga dengan alat yang tersebar luas pgbouncer sendiri hanya memberikan gambaran sesaat, dan karena sering tidak melakukan survei, masih ada kemungkinan gambar yang salah karena pengambilan sampel. Berikut adalah contoh nyata kapan, tergantung pada saat eksportir bekerja - pada awal menit atau pada akhir - gambar senyawa terbuka dan bekas berubah secara mendasar:
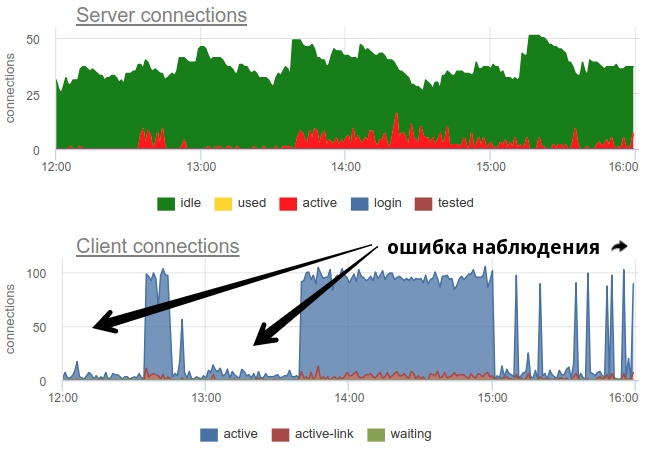
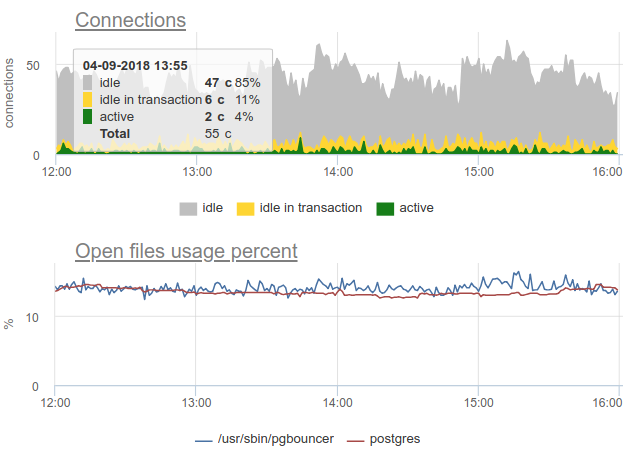
Di sini semua perubahan beban / penggunaan koneksi hanyalah sebuah fiksi, sebuah artefak dari restart kolektor statistik. Di sini Anda dapat melihat grafik koneksi di Postgres selama waktu ini dan deskriptor file bouncer dan PG - tidak ada perubahan:
Kembali ke masalah pembuangan. Kami memutuskan untuk menggunakan pendekatan gabungan dalam layanan kami - kami mencicipi SHOW POOLS sekali dalam satu detik, dan sekali dalam satu menit kami membuat rata-rata dan jumlah koneksi maksimum di setiap kelas:
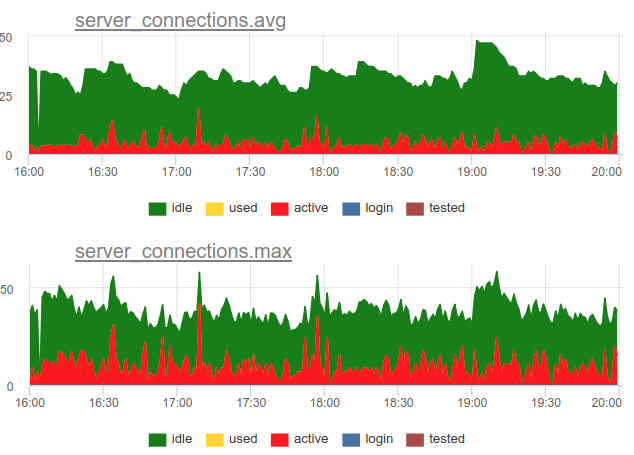
Dan jika kita membagi jumlah koneksi status aktif ini dengan ukuran pool, kita mendapatkan rata-rata dan puncak utilisasi pool ini dan dapat mengingatkan jika mendekati 100%.
Selain itu, PgBouncer memiliki perintah SHOW STATS yang akan menampilkan statistik penggunaan untuk setiap basis data yang diproksi:

Kami paling tertarik pada kolom total_query_time - waktu yang dihabiskan oleh semua koneksi dalam proses mengeksekusi query di postgres. Dan dari versi 1.8 ada juga total_xact_time metrik - waktu yang dihabiskan dalam transaksi. Berdasarkan metrik ini, kita dapat membangun pemanfaatan waktu koneksi server, indikator ini tidak tunduk, berbeda dengan yang dihitung dari status koneksi, untuk masalah pengambilan sampel, karena penghitung total_..._time ini bersifat kumulatif dan tidak lulus apa pun:

Bandingkan
Dapat dilihat bahwa sampling tidak menunjukkan semua momen pemanfaatan tinggi ~ 100%, dan query_time menunjukkan.
Kejenuhan dan PgBuncer
Mengapa Anda perlu memantau Saturasi, karena pemanfaatan yang tinggi sudah jelas bahwa semuanya buruk?
Masalahnya adalah tidak peduli bagaimana Anda mengukur pemanfaatan, bahkan penghitung yang terakumulasi tidak dapat menunjukkan pemanfaatan sumber daya 100% lokal jika itu terjadi hanya pada interval yang sangat singkat. Misalnya, Anda memiliki mahkota atau proses sinkron lainnya yang secara bersamaan dapat mulai membuat kueri ke database pada perintah. Jika permintaan ini pendek, maka pemanfaatannya, diukur pada skala menit dan bahkan detik, mungkin rendah, tetapi pada saat yang sama, pada beberapa titik, permintaan ini terpaksa menunggu dalam antrean untuk dieksekusi. Ini mirip dengan situasi penggunaan CPU yang tidak 100% dan waktu prosesor yang mirip rata-rata yang tinggi masih ada, tetapi banyak proses yang menunggu untuk dieksekusi.
Bagaimana situasi ini dapat dipantau - yah, sekali lagi, kita bisa menghitung jumlah klien dalam status cl_waiting sesuai dengan SHOW POOLS . Dalam situasi normal, ada nol, dan lebih dari nol berarti melimpah kumpulan ini:
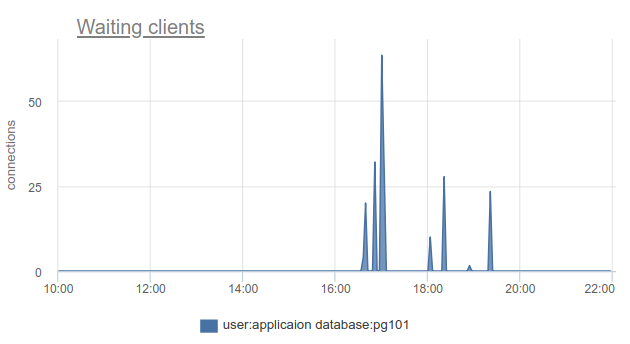
Masih ada masalah bahwa SHOW POOLS hanya dapat disampel, dan dalam situasi dengan mahkota sinkron atau sesuatu seperti itu, kita dapat dengan mudah melewati dan tidak melihat klien yang menunggu.
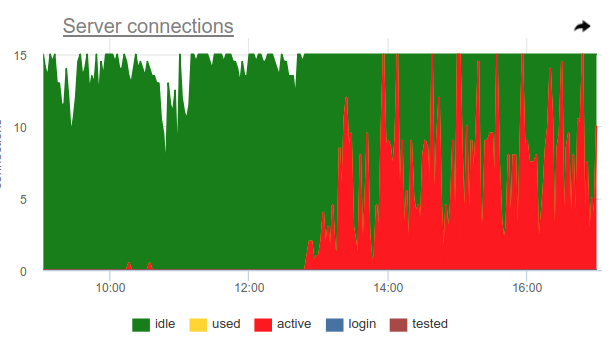
Anda dapat menggunakan trik ini, pgbouncer sendiri dapat mendeteksi 100% penggunaan pool dan membuka pool cadangan. Dua pengaturan bertanggung jawab untuk ini: reserve_pool_size - untuk ukurannya, seperti yang saya katakan, dan reserve_pool_timeout - berapa detik beberapa klien harus waiting sebelum menggunakan kumpulan cadangan. Jadi, jika kita melihat pada grafik koneksi server bahwa jumlah koneksi yang terbuka ke Postgres lebih besar dari pool_size, maka ada saturasi dari pool, seperti ini:

Jelas, sesuatu seperti mahkota sekali dalam satu jam membuat banyak permintaan dan benar-benar menempati kolam. Dan meskipun kita tidak melihat saat ketika koneksi active melebihi batas pool_size , masih pgbouncer terpaksa membuka koneksi tambahan.
Juga pada grafik ini, pengaturan server_idle_timeout bekerja terlihat jelas - setelah berapa banyak berhenti memegang dan menutup koneksi yang tidak digunakan. Secara default, ini adalah 10 menit, yang kita lihat di grafik - setelah puncak active tepat jam 5:00, jam 6:00, dll. (sesuai dengan cron 0 * * * * ), koneksi hang + used 10 menit dan ditutup.
Jika Anda hidup di garis depan kemajuan dan telah memperbarui PgBouncer selama 9 bulan terakhir, Anda dapat menemukan di kolom SHOW STATS total_wait_time , yang menunjukkan kejenuhan terbaik, karena secara kumulatif mempertimbangkan waktu yang dihabiskan oleh pelanggan dalam keadaan waiting . Misalnya, di sini - waiting muncul pukul 16:30:
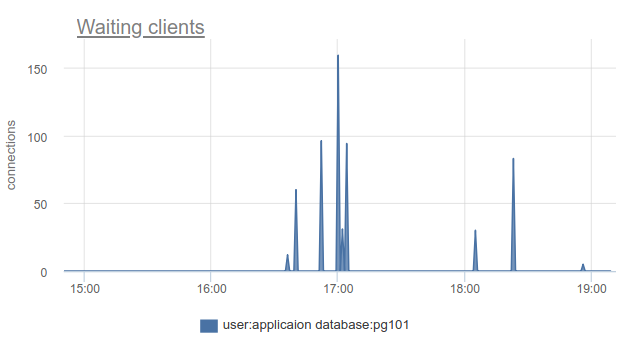
Dan wait_time , yang sebanding dan jelas mempengaruhi average query time , dapat dilihat dari 15:15 hingga hampir 19:

Meskipun demikian, pemantauan status koneksi klien masih sangat bermanfaat, karena ini memungkinkan Anda untuk mengetahui tidak hanya fakta bahwa semua koneksi ke database seperti itu telah dihabiskan dan klien harus menunggu, tetapi juga karena SHOW POOLS dibagi menjadi kumpulan yang terpisah oleh pengguna, dan SHOW STATS tidak, itu memungkinkan Anda untuk mengetahui klien mana yang menggunakan semua koneksi. ke basis yang ditentukan - sesuai dengan kolom sv_active dari kumpulan yang sesuai. Atau dengan metrik
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
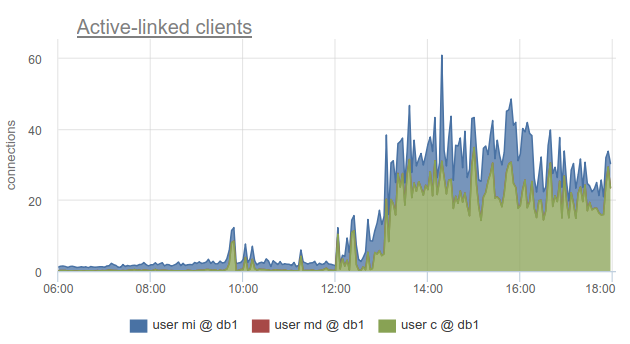
Kami di okmeter melangkah lebih jauh dan menambahkan rincian koneksi yang digunakan oleh alamat IP klien yang membuka dan menggunakannya. Ini memungkinkan Anda untuk memahami secara tepat instance aplikasi mana yang berperilaku berbeda:

Di sini kita melihat IP kubernet perapian tertentu yang perlu kita tangani.
Kesalahan
Tidak ada yang rumit di sini: pgbouncer menulis log yang melaporkan kesalahan jika batas koneksi klien tercapai, batas waktu untuk terhubung ke server, dll. Kami belum mencapai log pgbouncer sendiri :(
MERAH untuk PgBouncer
Sementara USE lebih fokus pada kinerja, dalam arti kemacetan, RED, menurut pendapat saya, lebih tentang karakteristik lalu lintas masuk dan keluar secara umum, dan bukan tentang kemacetan. Yaitu, RED menjawab pertanyaan - apakah semuanya berfungsi dengan baik, dan jika tidak, maka USE akan membantu untuk memahami apa masalahnya.
Persyaratan
Tampaknya semuanya cukup sederhana untuk database SQL dan untuk penarik proksi / koneksi dalam database seperti itu - klien menjalankan pernyataan SQL, yang merupakan Permintaan. Dari SHOW STATS kami mengambil total_requests dan merencanakan turunan waktunya
rate(metric(name="pgbouncer.total_requests", database: "*"))

Tetapi pada kenyataannya ada berbagai cara menarik, dan yang paling umum adalah transaksi. Unit kerja untuk mode ini adalah transaksi, bukan permintaan. Dengan demikian, mulai dari versi 1.8, Pgbouner sudah menyediakan dua statistik lain - total_query_count , bukan total_requests , dan total_xact_count - jumlah transaksi yang diselesaikan.
Sekarang beban kerja dapat dikarakterisasi tidak hanya dalam hal jumlah permintaan / transaksi yang diselesaikan, tetapi, misalnya, Anda dapat melihat jumlah rata-rata permintaan per transaksi dalam basis data yang berbeda, membagi satu menjadi yang lain
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

Di sini kita melihat perubahan nyata pada profil pemuatan, yang mungkin menjadi alasan untuk perubahan kinerja. Dan jika Anda hanya melihat pada tingkat transaksi atau permintaan, Anda mungkin tidak melihat ini.
Kesalahan MERAH
Jelas bahwa RED dan USE berpotongan pada pemantauan kesalahan, tetapi bagi saya tampaknya kesalahan dalam USE terutama tentang kesalahan pemrosesan permintaan karena pemanfaatan 100%, yaitu. ketika layanan menolak untuk menerima lebih banyak pekerjaan. Dan kesalahan untuk RED akan lebih baik untuk mengukur kesalahan secara tepat dari sudut pandang klien, permintaan klien. Yaitu, tidak hanya dalam situasi di mana kumpulan di PgBouncer penuh atau batas lain telah berfungsi, tetapi juga ketika meminta batas waktu permintaan seperti "membatalkan pernyataan karena batas waktu pernyataan", membatalkan dan mengembalikan transaksi oleh klien sendiri telah bekerja, dll. e. tingkat yang lebih tinggi, lebih dekat ke jenis kesalahan logika bisnis.
Durasi
Di sini lagi SHOW STATS dengan penghitung kumulatif total_xact_time , total_query_time dan total_wait_time akan membantu kami, membaginya dengan jumlah permintaan dan transaksi, masing-masing, kami mendapatkan waktu permintaan rata-rata, waktu transaksi rata-rata, waktu tunggu rata-rata per transaksi. Saya sudah menunjukkan grafik tentang yang pertama dan ketiga:
Apa lagi yang bisa Anda lakukan agar keren? Antipattern terkenal dalam bekerja dengan database dan Postgres, khususnya, ketika aplikasi membuka transaksi, membuat permintaan, kemudian mulai (untuk waktu yang lama) untuk memproses hasilnya, atau bahkan lebih buruk - pergi ke beberapa layanan / database lain dan membuat permintaan di sana. Selama ini, transaksi "hang" di postgres terbuka, layanan kemudian kembali dan membuat beberapa permintaan lagi, pembaruan dalam database, dan baru kemudian menutup transaksi. Untuk postgres, ini sangat tidak menyenangkan, karena pekerja pg itu mahal. Jadi kita dapat memonitor ketika aplikasi seperti itu idle in transaction di postgres itu sendiri - sesuai dengan kolom state di pg_stat_activity , tetapi masih ada masalah yang dijelaskan dengan sampling, karena pg_stat_activity hanya memberikan gambar saat ini. Di PgBouncer, kita dapat mengurangi waktu yang dihabiskan oleh klien dalam total_query_time permintaan dari waktu yang dihabiskan dalam transaksi total_xact_time - ini akan menjadi waktu pemalasan seperti itu. Jika hasilnya masih dibagi dengan total_xact_time , maka itu akan dinormalisasi: nilai 1 sesuai dengan situasi di mana klien idle in transaction 100% dari waktu. Dan dengan normalisasi seperti itu, membuatnya mudah untuk memahami seberapa buruk semuanya:
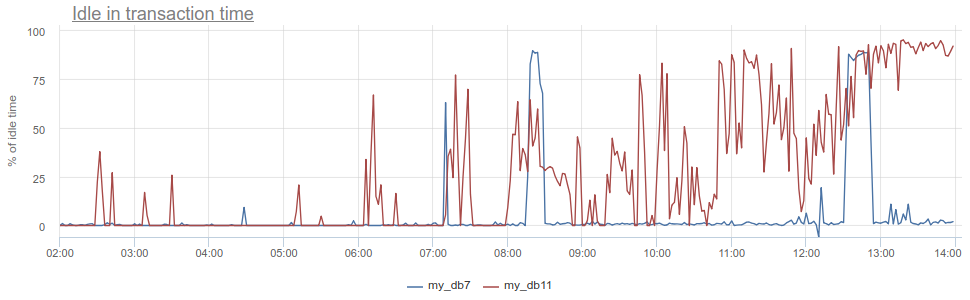
Selain itu, kembali ke Durasi, metrik total_xact_time - total_query_time dapat dibagi dengan jumlah transaksi untuk melihat berapa rata-rata aplikasi idle per transaksi.
Menurut pendapat saya, metode USE / RED paling berguna untuk menyusun metrik yang Anda potret dan alasannya. Karena kami terlibat dalam pemantauan penuh waktu dan kami harus melakukan pemantauan untuk berbagai komponen infrastruktur, metode ini membantu kami untuk mengambil metrik yang benar, membuat jadwal dan pemicu yang tepat untuk klien kami.
Pemantauan yang baik tidak dapat dilakukan segera, ini merupakan proses berulang. Di okmeter.io, kami baru saja memonitor secara terus-menerus (ada banyak hal, tapi besok akan lebih baik dan lebih rinci :)