
Nama saya Yuri Nevinitsin, dan saya terlibat dalam sistem statistik internal di OK. Saya ingin berbicara tentang bagaimana kami mentransfer sistem analitik 50-terabyte waktu nyata, di mana miliaran peristiwa dicatat setiap hari, dari Microsoft SQL ke basis kolom yang disebut Druid. Dan pada saat yang sama Anda akan belajar beberapa resep untuk menggunakan
Druid .
Mengapa kita membutuhkan statistik?
Kami ingin mengetahui segala sesuatu tentang situs kami, jadi kami mencatat tidak hanya perilaku disk, prosesor, dll., Tetapi juga setiap tindakan pengguna, setiap interaksi antara subsistem dan semua proses internal dari hampir semua sistem kami. Sistem statistik terintegrasi erat ke dalam proses pengembangan.
Berdasarkan data dari sistem statistik, manajer kami menetapkan tujuan untuk tim, melacak pencapaian mereka dan indikator utama. Administrator dan pengembang memantau pengoperasian semua sistem, menyelidiki insiden dan anomali. Pemantauan otomatis secara konstan memonitor dan pada tahap awal mengidentifikasi masalah, membuat perkiraan melebihi batas. Juga, fitur dan eksperimen terus diluncurkan, pembaruan dan perubahan dibuat. Dan kami memantau efek dari semua tindakan ini melalui sistem statistik. Jika dia menolak, kami tidak akan dapat membuat perubahan ke situs.
Statistik kami disajikan terutama dalam bentuk grafik. Biasanya, grafik menampilkan beberapa hari sekaligus, sehingga dinamika menjadi jelas. Ini adalah contoh percobaan saya dengan Druid. Berikut ini adalah grafik pemuatan data (baris / 5 menit).
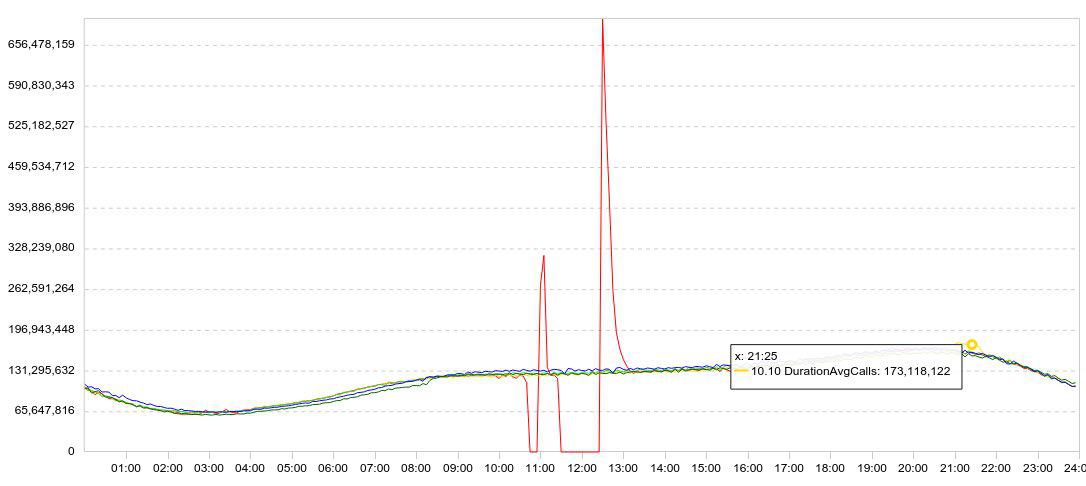
Saya memperlambat unduhan (grafik merah mogok ke nol), menunggu beberapa saat, memulai kembali unduhan, dan menyaksikan seberapa cepat Druid dapat memuat data yang terakumulasi (puncak setelah kegagalan).
Jadwal apa pun dapat diperluas dengan parameter apa pun, misalnya, oleh host, tabel, operasi, dll. Kami juga memiliki grafik jangka panjang dengan dinamika tahunan. Misalnya, di bawah ini adalah grafik peningkatan harian dalam jumlah entri di Druid.
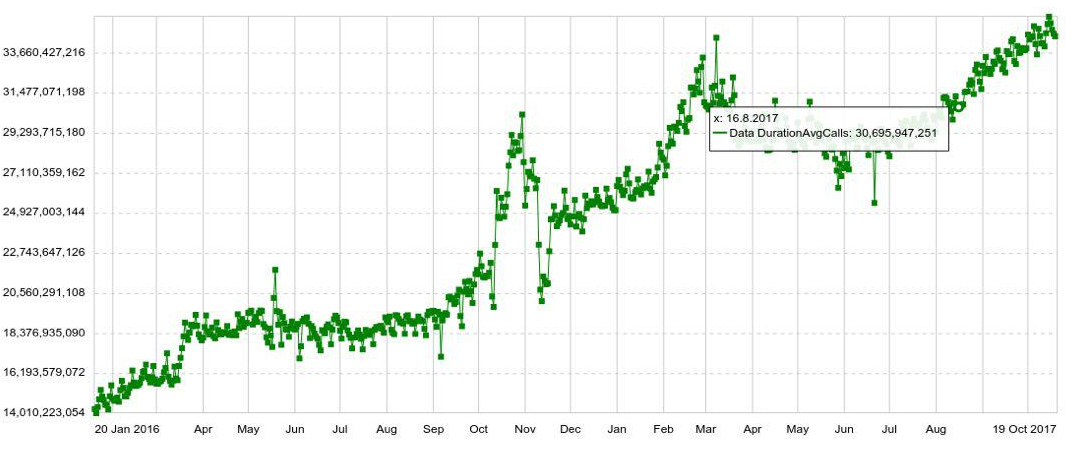
Kami juga dapat menggabungkan beberapa bagan pada panel terpisah (dasbor), yang ternyata sangat nyaman. Dan bahkan jika pengguna perlu melihat hanya beberapa ratusan grafik, ia masih membukanya tidak secara individu, tetapi di panel, yang meningkatkan beban pada sistem.
Masalah
Meskipun volume data kecil, kami berhasil mengatasi SQL dengan cukup baik. Tetapi karena volume data tumbuh, output grafik melambat. Dan pada akhirnya, statistik pada jam sibuk mulai tertinggal setengah jam, dan waktu respons rata-rata satu grafik mencapai 6 detik. Artinya, seseorang menerima jadwal dalam 2 detik, seseorang dalam 10-20, dan seseorang dalam satu menit. (Anda dapat membaca tentang pengembangan sistem dalam SQL di
sini )
Saat Anda menyelidiki anomali atau kejadian, Anda biasanya perlu membuka dan melihat selusin grafik, yang masing-masingnya mengikuti dari yang sebelumnya, mereka tidak dapat dibuka pada saat yang sama. Saya harus menunggu 10 kali selama 10-20 detik. Itu sangat menjengkelkan.
Migrasi
Anda masih bisa memeras sesuatu dari sistem, menambah server ... Tetapi pada saat yang bersamaan, Microsoft mengubah kebijakan lisensi. Jika kami terus menggunakan SQL Server, kami harus memberikan jutaan dolar. Karena itu, mereka memutuskan untuk bermigrasi.
Persyaratannya adalah sebagai berikut:
- Statistik tidak boleh ketinggalan (lebih dari 2 menit).
- Bagan harus dibuka tidak lebih dari 2 detik.
- Seluruh panel akan terbuka dalam waktu tidak lebih dari 10 detik.
- Sistem harus toleran terhadap kesalahan, mampu bertahan dari hilangnya pusat data.
- Sistem harus mudah diukur.
- Sistemnya harus mudah dimodifikasi, jadi kami ingin berada di Jawa.
Semua ini ditawarkan kepada kami hanya oleh Druid. Ini juga memiliki agregasi awal, yang memungkinkan Anda untuk menyimpan lebih banyak volume, dan pengindeksan selama penyisipan data. Druid mendukung semua jenis kueri yang diperlukan untuk statistik kami. Oleh karena itu, sepertinya kita dapat dengan mudah mengganti Druid dengan SQL Server.
Tentu saja, kami mempertimbangkan tidak hanya Druid untuk peran kandidat untuk pindah. Pikiran pertama saya adalah mengganti Microsoft SQL Server dengan PostgreSQL. Namun, ini hanya akan menyelesaikan masalah biaya keuangan, tetapi tidak akan membantu dengan aksesibilitas dan penskalaan.
Kami juga menganalisis Influx, tetapi ternyata bagian yang bertanggung jawab atas ketersediaan dan skalabilitas tinggi ditutup. Prometheus, dengan segala hormat sehubungan dengan kinerjanya, lebih sesuai untuk pemantauan dan tidak dapat membanggakan ketersediaan tinggi atau skalabilitas sederhana. OpenTSDB juga lebih cocok untuk pemantauan, tidak memiliki indeks untuk semua bidang. Kami tidak mempertimbangkan Click House, karena pada saat itu tidak ada.
Masukan Druid. Terabyte data dimigrasikan. Dan segera setelah beralih dari SQL Server ke Druid, jumlah tampilan grafik meningkat 5 kali. Kemudian mereka mulai menjalankan statistik "berat", yang mereka takut jalankan sebelumnya, karena SQL akan sulit menanganinya.
Sekarang Druid dari 12 node (40 core, 196 GB RAM) membutuhkan 500 ribu peristiwa per detik per jam sibuk, sementara ada margin keamanan yang besar (kolom MAX: hampir lima kali margin CPU).
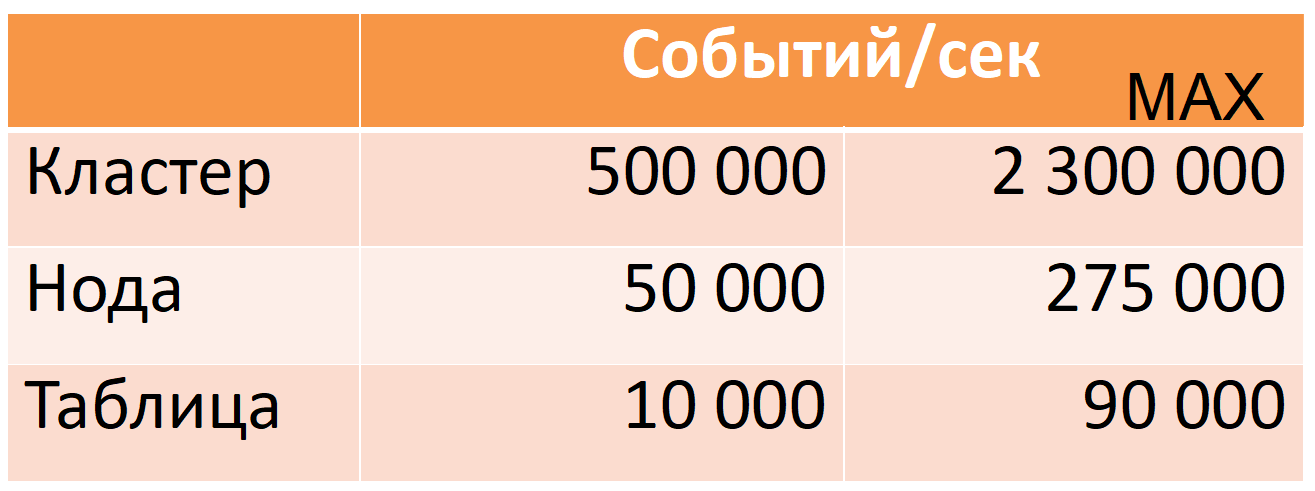
Angka-angka ini didasarkan pada data produksi. Saya akan memberi tahu Anda bagaimana kami mencapai ini, tetapi pertama-tama saya akan menjelaskan Druid secara lebih rinci.
Druid
Ini adalah sistem OLAP timeseries kolom terdistribusi. Dokumentasinya tidak mengandung konsep-konsep biasa dari dunia SQL untuk sebuah tabel (sumber data sebagai gantinya) atau string (sebagai gantinya), tetapi saya akan menggunakannya untuk kemudahan deskripsi.
Druid didasarkan pada beberapa asumsi data (batasan):
- setiap jalur data memiliki stempel waktu yang tumbuh secara monoton (dalam jendela 10 menit secara default).
- data tidak berubah, Masukkan saja (Perbarui operasi tidak).
Ini memungkinkan Anda untuk memotong data menjadi apa yang disebut segmen waktu. Segmen adalah "partisi" minimal yang tidak dapat dipisahkan dan tidak berubah dari satu tabel untuk periode waktu tertentu. Semua operasi data, semua permintaan dilakukan segmen demi segmen.
Setiap segmen swasembada: selain tabel utama, ditulis dalam bentuk kolom, juga berisi direktori dan indeks yang diperlukan untuk eksekusi kueri. Kita dapat mengatakan bahwa segmen adalah basis data read-only kolom kecil (Penjelasan lebih rinci tentang perangkat segmen akan diberikan di bawah).
Pada gilirannya, ini menghasilkan "distribusi": kemampuan untuk membagi sejumlah besar data menjadi segmen-segmen kecil untuk melakukan perhitungan secara paralel (baik pada satu mesin dan pada banyak sekaligus).
Jika Anda perlu "meningkatkan" setidaknya satu baris, Anda harus memuat ulang seluruh segmen lagi. Itu mungkin dan semuanya siap untuk ini. Setiap segmen memiliki versi, dan sebuah segmen dengan versi yang lebih baru akan secara otomatis menggantikan segmen dengan versi yang lama (namun, jika pembaruan diperlukan secara berkala, maka ada baiknya mengevaluasi kembali apakah Druid cocok untuk penggunaan ini).
Untuk menjelaskan segmen perangkat, kami mempertimbangkan contoh sederhana dalam bentuk tabel biasa:
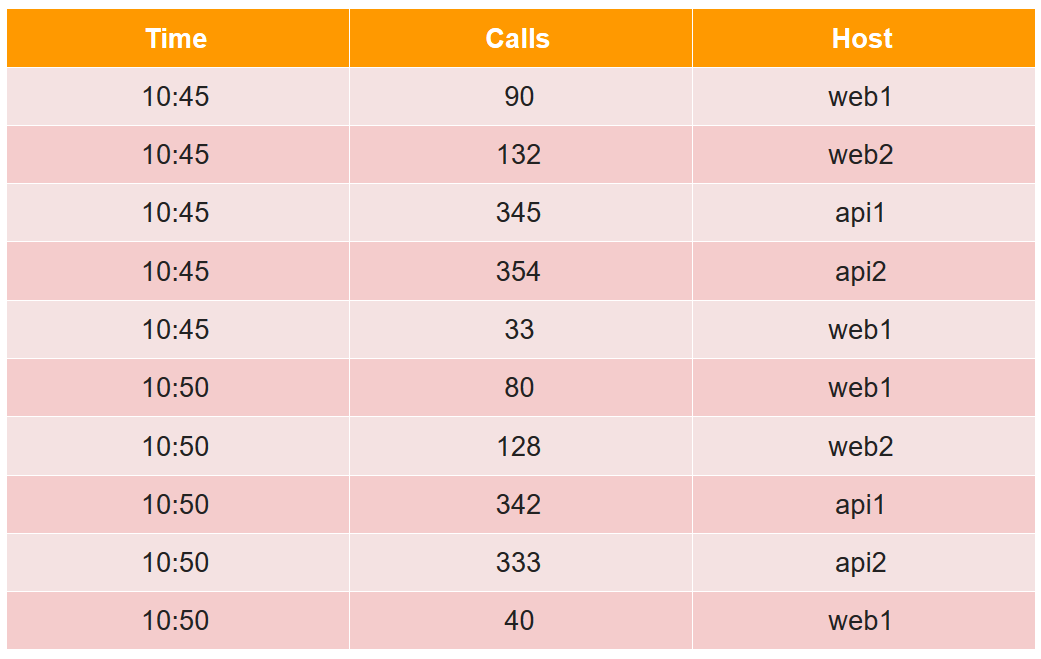
Dalam tabel ini, jumlah panggilan dalam dua lima menit dari empat host (perhatikan bahwa untuk host web1 ada dua baris dalam setiap periode lima menit).
Semua sel data dari sudut pandang druid dibagi menjadi tiga jenis:
- timestamp - timestamp UTC dalam ms (dalam contoh ini adalah Waktu).
- metrik adalah apa yang perlu Anda hitung (jumlah, min, maks, hitung, ...), dan Anda harus mengetahuinya terlebih dahulu untuk setiap tabel (dalam contoh, ini Panggilan, dan kami akan menghitung jumlahnya).
- Dimensi - inilah yang dapat Anda kelompokkan dan filter (Anda tidak perlu mengetahuinya terlebih dahulu dan dapat diubah dengan cepat) (dalam contoh, ini adalah Host).
Saat memasukkan, semua baris dikelompokkan berdasarkan set penuh dimensi + cap waktu, dan jika mereka cocok dengan masing-masing metrik, fungsi agregasi "nya" diterapkan (sebagai hasilnya, tidak ada baris dengan set dimensi + cap waktu yang sama). Jadi, contoh kita setelah dimasukkan ke dalam druid akan terlihat seperti ini:

Stempel waktu dan semua metrik (dalam kasus kami, ini adalah Waktu dan Panggilan) akan ditulis sebagai array dari jumlah tipe yang panjang (float dan double juga didukung). Untuk setiap dimensi (dalam kasus kami ini adalah Host), kamus akan dibuat - serangkaian string yang diurutkan (dengan nama host). Kolom host sendiri akan ditulis sebagai array int, menunjukkan angka-angka dalam kamus.
Harap dicatat bahwa setelah memasukkan ke dalam Druid, pasang garis untuk host web1 dengan stempel waktu yang sama digabungkan, dan jumlah total dicatat dalam panggilan (tidak mungkin untuk mengekstrak data awal dari Druid).
Diperlukan indeks untuk memfilter data cepat, karena mungkin ada jutaan baris dan ribuan host. Indeks adalah bitmap, satu untuk setiap baris dalam kamus.

Unit menunjukkan nomor baris tempat host ini berpartisipasi. Untuk memfilter dua host, Anda perlu mengambil dua bitmap, menggabungkannya melalui OR, dan memilih nomor baris dalam unit bitmap yang dihasilkan.
Druid terdiri dari banyak komponen.
Pertama, ia memiliki beberapa dependensi eksternal.

- Penyimpanan Di sana, Druid hanya menyimpan segmen dalam bentuk terkompresi. Itu bisa berupa direktori lokal, HDFS, Amazon S3. Hanya ruang yang digunakan di sini, tidak ada perhitungan yang dilakukan.
- Meta: database untuk informasi Meta. Basis data ini menyimpan peta data lengkap: segmen mana yang relevan, yang kedaluwarsa, jalur mana yang disimpan.
- Menggunakan ZooKeeper, sistem melakukan penemuan dan mengumumkan di mana node druid segmen mana yang tersedia untuk kueri.
- Tembolok dari permintaan yang dieksekusi, bisa memcached atau cache lokal di java heap.
Kedua, Druid sendiri terdiri dari beberapa jenis komponen.
- Node realtime memuat aliran data segar dalam urutan yang diterima dan melayani permintaan untuk itu.
- Simpul historis berisi seluruh massa data dan melayani permintaan untuknya. Ketika kami mengatakan bahwa kami memiliki 300 TB cluster, yang kami maksud adalah node historis.
- Broker bertanggung jawab untuk mendistribusikan perhitungan antara node historis dan realtime.
- Koordinator bertanggung jawab untuk mengalokasikan segmen lintas node historis dan untuk replikasi.
- Layanan pengindeksan, yang memungkinkan Anda untuk (kembali) memuat data dalam batch, misalnya, untuk "memutakhirkan" bagian dari data.
Aliran data
 Panah tebal menunjukkan aliran data, panah tipis menunjukkan aliran metadata.
Panah tebal menunjukkan aliran data, panah tipis menunjukkan aliran metadata.Node Realtime mengambil data, indeks, dan memotong segmen menurut waktu, misalnya hari.
Setiap segmen baru dari node realtime menulis ke penyimpanan dan meninggalkan salinan untuk melayani permintaan untuk itu. Kemudian ia mencatat metadata bahwa segmen baru telah muncul di repositori di sepanjang jalur ini dan itu.
Informasi ini diterima oleh koordinator, secara berkala membaca ulang basis metadata. Ketika dia menemukan segmen baru, (melalui ZooKeeper) memesan beberapa node historis untuk mengunduh segmen ini. Mereka mengunduh dan (melalui ZooKeeper) mengumumkan bahwa mereka memiliki segmen baru. Ketika node realtime menerima pesan ini (melalui ZooKeeper), itu menghapus salinannya untuk memberikan ruang bagi data baru.
Meminta pemrosesan

Tiga jenis node berpartisipasi dalam pemrosesan permintaan: broker, realtime, dan historis. Permintaan datang ke broker, siapa yang tahu di node mana segmen berada. Ini mendistribusikan permintaan oleh node historis (dan realtime) yang menyimpan segmen yang diinginkan. Simpul historis juga memparalelkan perhitungan sebanyak mungkin, mengirim hasilnya ke broker, dan dia memberikannya kepada klien. Dengan menggabungkan skema ini dengan penyimpanan data kolom, Druid dapat memproses informasi dalam jumlah besar dengan sangat cepat.
Ketersediaan tinggi
Seingat Anda, Druid dalam daftar dependensi memiliki basis untuk metadata, yang bisa berupa MySQL atau PostgreSQL. Apache Derby juga disebutkan, tetapi produk ini tidak dapat digunakan untuk produksi, hanya untuk pengembangan (seperti yang saya mengerti, derby digunakan dalam bentuk tertanam, agar tidak meningkatkan mysql / pgsql di lingkungan perdananya).
Apa yang akan terjadi jika pangkalan ini gagal (dan / atau penyimpanan dan / atau koordinator)? Node realtime tidak dapat menulis metadata (dan / atau segmen). Maka koordinator tidak akan dapat membacanya kembali dan tidak akan menemukan segmen baru. Node historis tidak akan mengunduhnya, dan simpul waktu nyata tidak akan menghapus salinannya, tetapi akan terus mengunduh data terbaru. Akibatnya, data akan mulai menumpuk di node realtime. Ini tidak dapat berlangsung tanpa batas. Namun demikian, diketahui sumber daya apa yang tersedia pada node realtime, dan jenis aliran data apa yang kita miliki. Oleh karena itu, kami memiliki jumlah waktu yang dapat diprediksi yang dapat digunakan untuk memperbaiki basis yang gagal (dan / atau penyimpanan dan / atau koordinator).
Karena mysql / pgsql yang didukung tidak menjamin ketersediaan tinggi di luar kotak, kami memutuskan untuk memainkannya dengan aman dan menggunakan solusi kami sendiri (siap pakai) berdasarkan Cassandra, karena di luar kotak memberikan ketersediaan tinggi (Anda dapat membaca lebih lanjut tentang hal itu di
sini ).
Selain itu, kami menyelesaikan node realtime sedemikian rupa sehingga dengan akumulasi berlebihan, data terlama dihapus, membebaskan ruang untuk yang baru. Ini sangat penting bagi kami, karena situasi ketika kami tidak dapat menaikkan basis yang gagal (dan / atau penyimpanan dan / atau koordinator) untuk waktu yang lama dan banyak data yang terakumulasi kemungkinan besar merupakan konsekuensi dari kecelakaan besar. Dan pada saat ini, data terbaru adalah yang paling penting.
Druid dan ZooKeeper
Dengan ZooKeeper, semuanya lebih baik dan lebih buruk. Lebih baik karena ZooKeeper sendiri toleran terhadap kesalahan, ia memiliki replikasi di luar kotak. Tampaknya itu bisa terjadi?
Secara umum, bab ini tidak lagi relevan. Dan ini bukan kisah sukses, ini adalah rasa sakit yang (baik kami dan Druid segar) memutuskan untuk secara radikal menghapus hampir semua data dari ZooKeeper, dan sekarang node Druid meminta mereka langsung dari satu sama lain melalui HTTP.
ZooKeeper memiliki dua jenis batas waktu. Batas waktu koneksi adalah batas waktu jaringan yang sederhana, setelah itu klien menghubungkan kembali ke ZooKeeper dan mencoba memulihkan sesi. Dan batas waktu sesi, setelah sesi dihapus dan semua data
sesaat yang dibuat dalam sesi ini juga dihapus (oleh ZooKeeper sendiri), yang diberitahukan kepada semua klien ZooKeeper lainnya.
Berdasarkan ini, penemuan dalam karya druid: pada saat startup, setiap node membuat sesi baru di ZooKeeper dan mencatat data
fana tentang dirinya: host: port, jenis node (broker / realtime / historical / ...), timestamp koneksi, dll. ... Simpul druid lain menerima pemberitahuan dari ZooKeeper dan membaca data ini, sehingga mereka mengetahui bahwa simpul druid baru telah naik dan seperti apa simpul itu. Jika ada node druid yang jatuh setelah batas waktu sesi, data tentang itu akan dihapus oleh ZooKeeper, dan node druid lainnya akan mengetahuinya. Agar mereka mempelajarinya lebih cepat, kami lebih memilih untuk menempatkan waktu tunggu sesi kecil.
Ketika simpul waktu nyata atau historis naik, simpul itu, selain data tentang dirinya sendiri, juga menulis kepada ZooKeeper daftar segmen yang dimilikinya (ini juga data
sementara ). Lebih jauh di sepanjang jalan, segmen pada node realtime dan historis dibuat baru dan lama akan dihapus, dan setiap node mencerminkan ini dalam daftar di ZooKeeper. Daftar ini bisa besar, sehingga dipecah menjadi beberapa bagian sehingga tidak seluruh daftar ditimpa, tetapi hanya bagian yang dimodifikasi.
Broker, pada gilirannya, ketika dia melihat simpul waktu nyata atau historis, juga mengurangi daftar segmen dari ZooKeeper untuk mendistribusikan permintaan ke simpul ini. Node realtime membaca daftar ini untuk menghapus salinan segmen yang muncul pada simpul historis. Karena daftar ini dibagi menjadi beberapa bagian dan ditimpa dalam beberapa bagian, ZooKeeper akan memberi tahu Anda bagian mana yang telah diubah, hanya itu yang akan dibaca kembali.
Seperti yang saya katakan, daftar ini bisa panjang. Ketika ada banyak data di ZooKeeper, maka ternyata tidak lagi stabil. Dalam kasus kami, masalah yang jelas dimulai ketika jumlah segmen mencapai sekitar 7 juta, snapshot ZooKeeper kemudian menempati 6GB.
Apa yang terjadi jika simpul Druid kehilangan kontak dengan ZooKeeper?
Druid bekerja dengan ZooKeeper sedemikian rupa sehingga dalam hal timeout sesi, setiap node membuat sesi baru dan menulis semua datanya di sana dan membaca kembali data dari node lain. Karena ada banyak data, lalu lintas macet di ZooKeeper. Hal ini dapat menyebabkan batas waktu pada node lain dari Druid, maka mereka juga mulai menulis ulang dan membaca kembali. Dengan demikian, lalu lintas tumbuh seperti longsoran salju sampai-sampai ZooKeeper kehilangan sinkronisasi antara instansenya dan mulai mendorong snapshot bolak-balik.
Apa yang dilihat pengguna saat ini?
Ketika seorang pialang kehilangan kontak dengan ZooKeeper (dan batas waktu sesi terjadi), pialang tidak lagi tahu segmen mana yang merupakan titik sejarah. Dan memberikan jawaban kosong. Artinya, jika ZooKeeper down, maka Druid tidak berfungsi. Sangat tidak mungkin untuk "menyembuhkan" itu, tetapi mungkin untuk menyebarkan sedotan di beberapa tempat.
Pertama, Anda dapat menghapus data dari ZooKeeper. Tidak apa-apa jika mereka tersesat: Druid hanya akan menimpa mereka. Jika masalah dengan ZooKeeper sudah dimulai, maka untuk solusi tercepat, disarankan untuk menonaktifkan ZooKeeper, hapus data, dan angkat itu kosong, dan jangan tunggu sampai diselesaikan sendiri.
Sekarang kami meningkatkan batas waktu sesi. Apa yang terjadi dalam kasus ini?
Katakanlah node historis tidak memulai kembali dengan benar dan tidak menghapus sesi lama dari ZooKeeper, sambil membuat yang baru dan menulis banyak data di sana. Sementara sesi lama masih hidup dan batas waktu belum berlalu, dua salinan data disimpan di ZooKeeper. Jika ada banyak node yang segera dimulai kembali, maka banyak data akan diduplikasi. Karena itu, Anda perlu menyimpan persediaan memori untuk ZooKeeper agar tidak habis dan ZooKeeper tidak berhenti bekerja. Mengapa tidak bisa menghapus data dari sesi lama?
Untuk alasan yang sama, perlu menyelesaikan operasi node historis dengan benar, karena pada saat itu mereka menghapus data mereka dari ZooKeeper, dan dapat melakukan ini untuk waktu yang lama. Penyelesaian node historis membutuhkan waktu sekitar setengah jam.
Simpul historis memiliki satu fitur lagi. Ketika mereka mulai, mereka melihat segmen apa yang disimpan di dalamnya, dan kemudian informasi tentang ini ditulis ke ZooKeeper. Dan karena data tersebar kurang lebih secara merata di seluruh node historis, jika Anda menjalankannya secara bersamaan, maka mereka akan mulai menulis di ZooKeeper pada waktu yang hampir bersamaan. Ini lagi meningkatkan kemungkinan pertumbuhan lalu lintas seperti gelombang dan timeout. Oleh karena itu, Anda perlu menjalankan node historis secara berurutan untuk menyebarkan sesi rekaman di ZooKeeper pada waktunya.
Kami juga membuat dua optimasi lagi:
- Kami memprogram ulang bekerja dengan ZooKeeper sedikit sehingga hanya simpul yang membutuhkannya yang dibaca dari Druid. realtime, , . , . , .
- , ZooKeeper, , . ZooKeeper 6 2 ( ).
8 ; .
Druid
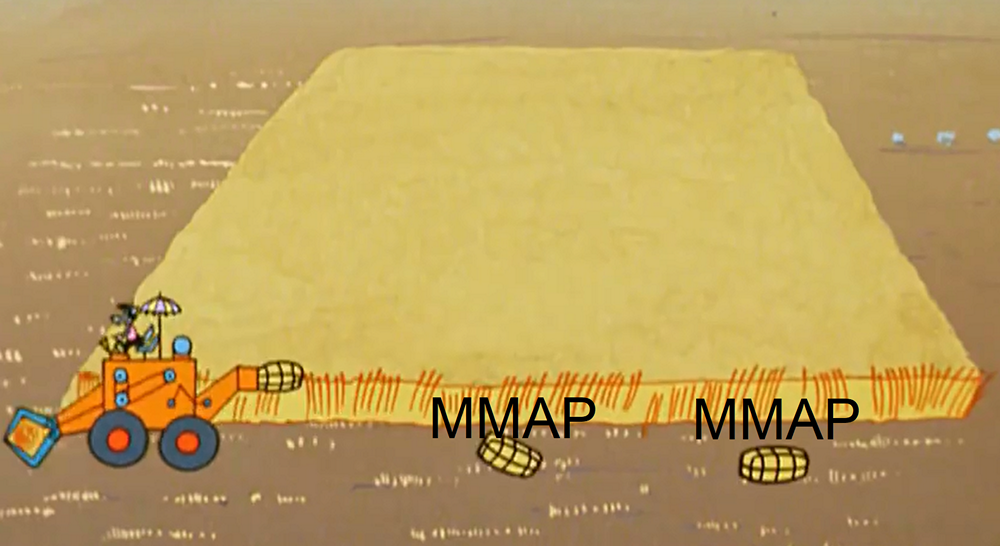
realtime , . - ( , , ). , MMAP ( ). . .
-, realtime- , JVM , .

. : 1) 2) . , . , , . , , , . ( , , ).
, realtime- , , .. , , , ( ).
, . , , .
, Druid . , , , .
, . , (web%, api%).
- Druid — . .
- , .
- Druid , , : , , , .
- Druid , , calls.
, 5 % , 95 % — .
, , realtime- .
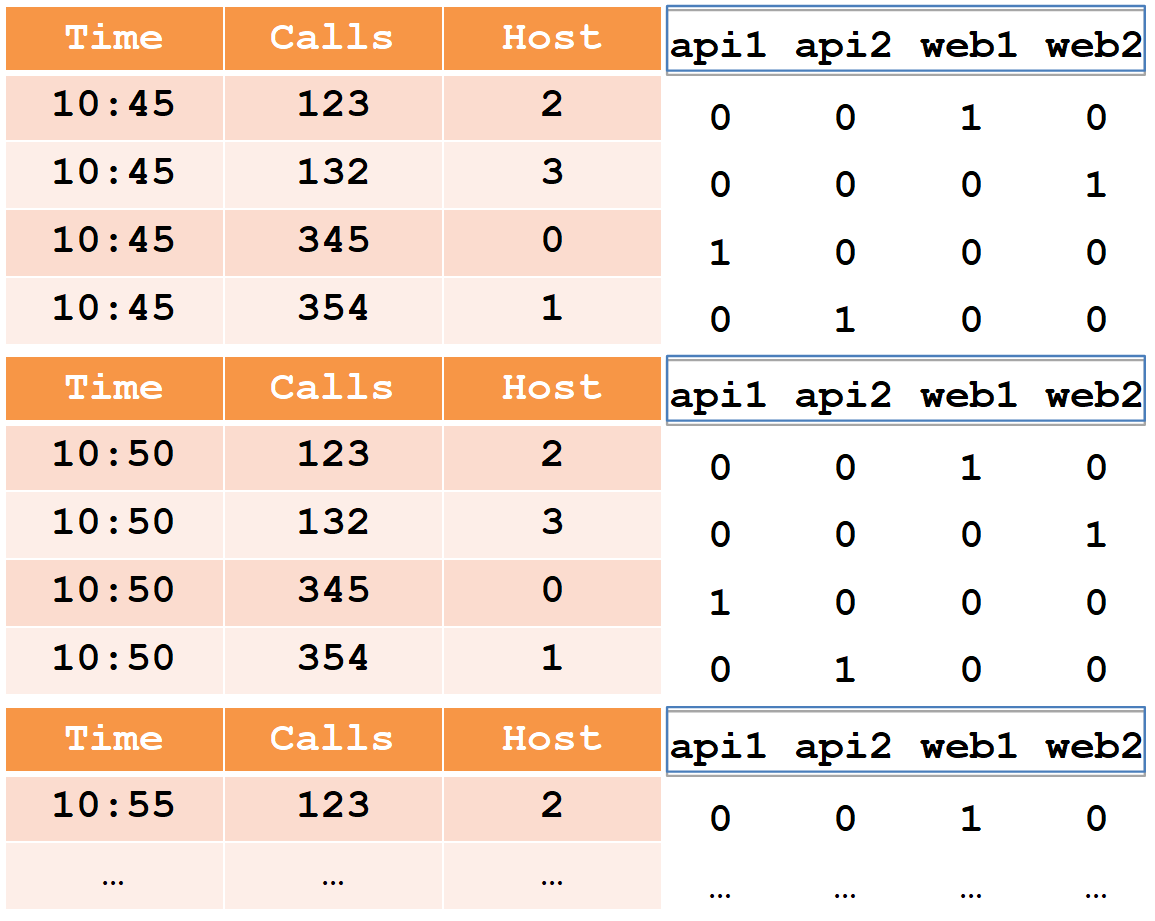
, ( 10:45) . - , -. , ( 10:50) , -. Dan sebagainya. , , «calls», «time» «host» .
-. , «» . , , . ( 95% ) , : , . 100 , 1000.
? , . , realtime , . (.. historical realtime-), .
, : . , , . 100 . , . .
. 80% , , , . . . , selector, . , .
, , , . , . , 8 . Druid. , , Druid, . , . :

, , . . , , . . 27 . , 27 , 27 .
, . 27 , 9, 9 , .
.

— : , , . — : , , . — : , , . — , . , . , 27. 9, . ( 95% ) 9 . 27 .
Pada kenyataannya, kami memiliki 14 ribu kombinasi. Dengan demikian, dalam kamus kami ada 14 ribu nilai dan 14 ribu bitmap. Akibatnya, ketika kami memotong bidang ini menjadi bagian-bagian kecil sesuai dengan kata-kata, kecepatan statistik rekaman meningkat 10 kali, dan ukuran data dibelah dua. Sekarang semuanya bekerja dengan cepat.Meminta Prioritas
, 2 . 11 , 74 . , . 74 ? , .
Druid . , , , . , , . , , . , , .
, Druid . , ( ) , . 5 : , . . ( java), . Druid , .
Ringkasan
, , SQL Server, Microsoft.
, / .
, , .
20 , , 18 .
one-cloud (
https://habr.com/company/odnoklassniki/blog/346868/ ), .