Hai, Habr. Saya ingin berbicara tentang salah satu pendekatan untuk menyelesaikan masalah diarisasi pembicara dan menunjukkan bagaimana metode ini dapat diimplementasikan dalam python. Agar tidak menakut-nakuti pembaca, saya tidak akan memberikan rumus matematika yang rumit (sebagian karena saya sendiri "bukan tukang las yang nyata"), tetapi saya akan mencoba menjelaskan semuanya dalam bahasa yang sederhana dan menceritakan semuanya sedemikian rupa sehingga pengembang yang belum pernah mengalami pembelajaran mesin sebelumnya telah memahaminya.
Dalam mempersiapkan untuk menulis artikel ini, saya memilih antara dua opsi: bagi mereka yang sudah terbiasa dengan Ilmu Data dan mereka yang hanya memprogram dengan baik. Pada akhirnya, saya memilih opsi kedua, memutuskan bahwa ini akan menjadi demonstrasi yang baik dari kemampuan DS.
Pernyataan masalah
Seperti yang dikatakan Wikipedia, diarization adalah proses membagi aliran audio yang masuk ke segmen yang homogen sesuai dengan apakah aliran audio itu milik satu atau yang lain. Dengan kata lain, catatan harus dibagi menjadi beberapa bagian dan diberi nomor: satu orang berbicara di tempat-tempat ini, dan yang lain di tempat-tempat ini. Dari sudut pandang pembelajaran mesin, tugas-tugas semacam ini termasuk dalam kelas pembelajaran tanpa guru dan disebut pengelompokan. Anda dapat membaca tentang metode pengelompokan apa yang ada di
sini atau di
sini , misalnya, tetapi saya hanya akan membahas yang bermanfaat bagi kami - ini adalah Model Campuran Gaussian dan Clustering Spectral. Tetapi tentang mereka sedikit kemudian.
Mari kita mulai dari awal.
Persiapan lingkungan
SpoilerSaya tidak yakin apakah akan meninggalkan bagian ini - saya tidak ingin mengubah artikel menjadi tutorial yang sangat. Tetapi pada akhirnya saya meninggalkannya. Siapa pun yang tidak membutuhkannya akan melewatkan, dan bagi mereka yang akan melakukan semuanya dari awal, langkah ini akan memudahkan awal.
Secara umum, selain R, python adalah bahasa utama untuk menyelesaikan masalah Ilmu Data, dan jika Anda belum mencoba untuk memprogramnya, maka saya sangat merekomendasikan melakukannya karena python memungkinkan Anda melakukan banyak hal dengan elegan, secara harfiah dalam beberapa baris (omong-omong, ada bahkan meme seperti itu).
Ada dua cabang python yang berkembang secara terpisah - versi 2 dan 3. Dalam contoh saya, saya menggunakan versi 3.6, tetapi jika diinginkan, mereka dapat dengan mudah dipindahkan ke versi 2.7. Lebih mudah untuk menyebarkan cabang-cabang ini bersama-sama dengan installer
Anaconda , dengan menginstal yang Anda akan segera menerima shell interaktif untuk pengembangan - IPython.
Selain lingkungan pengembangan itu sendiri, perpustakaan tambahan akan diperlukan: librosa (untuk bekerja dengan atribut audio dan mengekstraksi), webrtcvad (untuk segmentasi) dan acar (untuk menulis model terlatih ke file). Semuanya diinstal dengan perintah sederhana di Anaconda Prompt.
pip install [library]
Ekstraksi fitur
Mari kita mulai dengan ekstraksi fitur - data yang dapat digunakan model pembelajaran mesin. Pada prinsipnya, sinyal suara itu sendiri sudah berupa data, yaitu susunan teratur dari nilai-nilai amplitudo suara, yang ditambahkan header yang berisi jumlah saluran, frekuensi pengambilan sampel, dan informasi lainnya. Tetapi kami tidak akan dapat menganalisis data ini secara langsung, karena tidak mengandung hal-hal seperti itu, melihat di mana, model kami dapat mengatakan - ya, potongan-potongan ini milik orang yang sama.
Dalam tugas pemrosesan ucapan, ada beberapa pendekatan untuk mengekstraksi fitur. Salah satunya adalah untuk mendapatkan Koefisien Frekuensi Cepstral Mel. Mereka
sudah ditulis di sini, jadi saya hanya akan sedikit mengingatkan Anda.
Sinyal asli dipotong menjadi bingkai dengan panjang 16-40 ms. Kemudian, menerapkan jendela
Hamming ke bingkai, mereka membuat transformasi Fourier cepat dan mendapatkan kepadatan spektral daya. Kemudian, dengan "sisir" khusus dari filter yang disusun secara seragam pada skala kapur, dibuat spektrogram kapur, yang menerapkan DCT (discrete cosine transform) yang diterapkan - algoritma kompresi data yang banyak digunakan. Koefisien yang diperoleh adalah semacam karakteristik terkompresi dari frame, dan karena filter yang kami gunakan berada dalam skala
kapur , koefisien membawa lebih banyak informasi dalam kisaran persepsi telinga manusia. Biasanya, 13 hingga 25 MFCC per frame digunakan. Karena selain spektrum itu sendiri, kepribadian suara dibentuk oleh kecepatan dan akselerasi, MFCC dikombinasikan dengan turunan pertama dan kedua.
Secara umum, MFCC adalah pilihan paling umum untuk bekerja dengan ucapan, tetapi selain itu, ada tanda-tanda lain - LPC (Linear Predictive Coding) dan PLP (Perceptual Linear Prediction), dan kadang-kadang Anda juga dapat menemukan LFCC, di mana alih-alih skala kapur, linier digunakan.
Mari kita lihat cara mengekstrak MFCC dengan python.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
Seperti yang Anda lihat, ini benar-benar dilakukan hanya dalam beberapa baris. Sekarang mari kita beralih ke algoritma pengelompokan pertama.
Model Campuran Gaussian
Model campuran distribusi Gaussian menunjukkan bahwa data kami adalah campuran distribusi Gaussian multidimensi dengan parameter tertentu.
Jika Anda mau, Anda dapat dengan mudah menemukan deskripsi terperinci dari model dan bagaimana
algoritma EM yang melatih model ini bekerja, tetapi saya berjanji untuk tidak mengganggu formula yang rumit dan karena itu saya akan menunjukkan contoh-contoh indah dari artikel
ini .
Kami akan menghasilkan empat kelompok dan menggambarnya.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
Kami akan membuat model, melatih data kami dan sekali lagi menggambar poin, tetapi dengan mempertimbangkan model keanggotaan cluster yang diprediksi.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
Model tersebut berhasil dengan baik dengan data buatan. Pada prinsipnya, dengan mengatur jumlah komponen campuran dan jenis matriks kovarian (jumlah derajat kebebasan Gaussians), data yang agak rumit dapat dijelaskan.

Jadi, kita tahu bagaimana melakukan parameterisasi data dan mampu melatih model campuran distribusi Gaussian. Sekarang orang dapat mencoba melakukan pengelompokan di dahi - melatih GMM tentang MFCC yang diambil dari dialog. Dan, mungkin, dalam beberapa dialog ruang-vakum ideal, di mana setiap pembicara akan cocok dengan Gaussian-nya, kita akan mendapatkan hasil yang baik. Jelas bahwa dalam kenyataan ini tidak akan pernah terjadi. Bahkan, dengan bantuan GMM, mereka tidak memodelkan dialog, tetapi masing-masing orang dalam dialog - yaitu, mereka membayangkan bahwa suara masing-masing pembicara dalam tanda-tanda yang diekstraksi dijelaskan oleh set Gaussians-nya sendiri.
Untuk meringkas, kita perlahan-lahan sampai ke topik utama.
Segmentasi
Secara tradisional, proses diarisasi terdiri dari tiga blok berturut-turut - deteksi suara (Voice Activity Detection), segmentasi dan pengelompokan (ada model di mana dua langkah terakhir digabungkan, lihat
LIA E-HMM ).
Pada langkah pertama, ucapan dipisahkan dari berbagai jenis kebisingan. Algoritma VAD menentukan apakah potongan file audio yang dikirimkan kepadanya adalah pidato, atau misalnya, terdengar sirene atau seseorang bersin. Jelas bahwa agar algoritma semacam itu berkualitas tinggi, pelatihan dengan seorang guru diperlukan. Dan ini pada gilirannya berarti bahwa Anda perlu menandai data - dengan kata lain, buat database dengan rekaman pidato dan semua jenis kebisingan. Kami akan melakukannya dengan malas - mengambil
VAD yang sudah jadi , yang tidak bekerja dengan sempurna, tetapi sebagai permulaan kami memiliki cukup.
Blok kedua memotong data pidato menjadi segmen-segmen dengan satu pembicara aktif. Pendekatan klasik dalam hal ini adalah algoritma untuk menentukan perubahan pembicara berdasarkan kriteria informasi Bayesian -
BIC . Inti dari metode ini adalah sebagai berikut - jendela geser menelusuri rekaman audio dan pada setiap titik bagian mereka menjawab pertanyaan: "Bagaimana data di tempat ini lebih baik dijelaskan - satu atau dua distribusi?" Untuk menjawab pertanyaan ini, parameter dihitung
DeltaBIC , berdasarkan tanda keputusan diambil untuk mengganti pembicara. Masalahnya adalah bahwa metode ini tidak akan bekerja dengan baik jika terjadi perubahan speaker yang sering, dan bahkan di tengah kebisingan (yang sangat khas untuk merekam percakapan telepon).
Sedikit penjelasanDalam aslinya, saya bekerja dengan rekaman telepon dari call center dengan durasi rata-rata sekitar 4 menit. Untuk alasan yang jelas, saya tidak dapat memposting catatan ini, jadi untuk demonstrasi saya mengambil wawancara dari satu stasiun radio. Dalam kasus wawancara panjang, metode ini mungkin akan memberikan hasil yang dapat diterima, tetapi tidak bekerja pada data saya.
Dalam kondisi ketika penyiar tidak saling mengganggu dan suaranya tidak tumpang tindih, VAD yang akan kita gunakan lebih atau kurang berupaya dengan tugas segmentasi, oleh karena itu dua langkah pertama akan terlihat seperti ini.
Pada kenyataannya, orang tentu akan berbicara pada saat yang sama. Selain itu, VAD di beberapa tempat telah salah karena fakta bahwa catatan itu tidak hidup, tetapi merupakan pengeleman di mana jeda dipotong. Anda dapat mencoba mengulangi pemotongan menjadi segmen-segmen, meningkatkan agresivitas VAD dari 2 menjadi 3.
GMM-UBM
Sekarang kami memiliki segmen yang terpisah, dan kami memutuskan untuk memodelkan setiap pembicara menggunakan GMM. Kami mengekstrak tanda-tanda dari segmen dan pada data ini kami melatih model. Mari kita lakukan pada setiap segmen dan bandingkan model yang dihasilkan satu sama lain. Dapat dibenarkan untuk mengharapkan bahwa model yang dilatih pada segmen yang dimiliki oleh orang yang sama akan agak mirip. Tapi di sini kita dihadapkan dengan masalah berikut, mengekstraksi tanda-tanda dari file audio berdurasi 1 detik dengan frekuensi pengambilan sampel 8000 Hz dengan ukuran jendela 10 ms, kita mendapatkan satu set 800 vektor MFCC. Model kami tidak akan dapat belajar dari data seperti itu, karena dapat diabaikan. Sekalipun tidak satu detik, tetapi sepuluh, data masih belum cukup. Dan di sini Universal Background Model (UBM) datang untuk menyelamatkan, itu juga disebut speaker-independent. Idenya adalah sebagai berikut. Kami akan melatih GMM pada sampel data yang besar (dalam kasus kami, ini adalah rekaman wawancara lengkap) dan kami akan mendapatkan model akustik dari pembicara umum (ini akan menjadi UBM kami). Dan kemudian, dengan menggunakan algoritma adaptasi khusus (tentangnya di bawah), kita akan “menyesuaikan” model ini dengan karakteristik yang diekstraksi dari setiap segmen. Pendekatan ini banyak digunakan tidak hanya untuk diarisasi, tetapi juga dalam sistem pengenalan suara. Untuk mengenali seseorang dengan suara, Anda harus terlebih dahulu melatih model dan tanpa UBM, Anda harus memiliki beberapa jam untuk merekam pembicaraan orang ini.
Dari masing-masing GMM yang diadaptasi, kami mengekstrak vektor koefisien geser
mu (ini juga median atau mat. harapan, jika Anda suka) dan, berdasarkan data pada vektor-vektor ini dari semua segmen, kami akan melakukan pengelompokan (di bawahnya akan menjadi jelas mengapa itu adalah vektor pergeseran).
Adaptasi peta
Metode yang akan digunakan untuk menyesuaikan UBM untuk setiap segmen disebut Adaptasi A-Posteriori Maksimum. Secara umum, algoritma adalah sebagai berikut. Pertama, probabilitas posterior dihitung pada data adaptasi dan
statistik yang cukup untuk berat, median dan varians masing-masing Gaussian. Kemudian statistik yang diperoleh dikombinasikan dengan parameter UBM dan parameter model yang diadaptasi diperoleh. Dalam kasus kami, kami hanya akan menyesuaikan median, tanpa memengaruhi parameter lainnya. Terlepas dari kenyataan bahwa saya berjanji untuk tidak masuk lebih jauh ke matematika, saya akan mengutip tiga rumus setelah semua, karena adaptasi MAP adalah titik kunci dalam artikel ini.
Ei= frac1ni sumNt=1Pr(i|xt)xt
hat mui= betaiEi+(1− betai) mui
b e t a i = n i / ( n i + r b e t a )
Di sini
P r ( i | x t ) - probabilitas posterior,
E i - statistik yang memadai untuk
m u ,
h a t m u i - median model yang diadaptasi,
b e t a i - koefisien adaptasi,
r b e t a - faktor kepatuhan.
Jika semua ini tampak tidak masuk akal dan menyebabkan putus asa - jangan putus asa. Bahkan, untuk memahami operasi algoritma, tidak perlu mempelajari rumus-rumus ini, operasinya dapat dengan mudah ditunjukkan dengan contoh berikut:
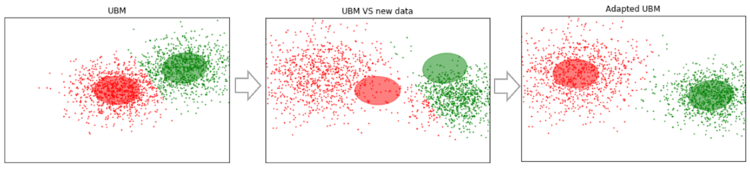
Misalkan kita memiliki beberapa data yang cukup besar, dan kita melatih UBM pada mereka (gambar kiri, UBM adalah campuran dua komponen dari distribusi Gaussian). Muncul data baru yang tidak sesuai dengan model kami (gambar di tengah). Dengan menggunakan algoritma ini, kami akan menggeser pusat-pusat Gaussians sehingga mereka terletak pada data baru (gambar di sebelah kanan). Menerapkan algoritme ini ke data eksperimental, kami akan berharap bahwa pada segmen dengan penutur yang sama, Gauss akan bergeser dalam satu arah, sehingga membentuk cluster. Itu sebabnya kami akan menggunakan data geser untuk mengelompokkan segmen
m u .
Jadi, mari kita lakukan adaptasi MAP untuk setiap segmen. (Untuk referensi: selain Adaptasi MAP, metode MLLR - Maximum Likelihood Linear Regression dan beberapa modifikasinya banyak digunakan. Mereka juga mencoba menggabungkan kedua metode ini.)
SV = []
Sekarang untuk setiap segmen kami memiliki data
m u , kami akhirnya beralih ke langkah terakhir.
Pengelompokan spektrum
Pengelompokan spektral secara singkat dijelaskan dalam artikel, tautan yang saya berikan di awal. Algoritma membangun grafik lengkap, di mana simpul adalah data kami, dan ujung-ujungnya adalah ukuran kesamaan. Dalam tugas-tugas pengenalan suara, metrik kosinus digunakan sebagai ukuran seperti itu, karena memperhitungkan sudut antara vektor, mengabaikan besarnya (tidak membawa informasi tentang speaker). Dengan membuat grafik, vektor eigen dari matriks Kirchhoff dihitung (yang pada dasarnya merupakan representasi dari grafik yang dihasilkan) dan kemudian beberapa metode pengelompokan standar digunakan, misalnya, metode k-means. Semuanya cocok dalam dua baris kode
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
Kesimpulan dan Rencana Masa Depan
Algoritma yang dijelaskan telah diuji dengan berbagai parameter:
- Nomor MFCC: 7, 13, 20
- MFCC dalam kombinasi dengan LPC
- Jenis dan jumlah campuran dalam GMM: penuh [8, 16, 32], diag [8, 16, 32, 64, 256]
- Metode adaptasi UBM: MAP (dengan covariance_type = 'full') dan MLLR (dengan covariance_type = 'diag')
Akibatnya, parameter tetap optimal secara subyektif: MFCC 13, GMM covariance_type = 'full' n_components = 16.
Sayangnya, saya tidak memiliki kesabaran (saya mulai menulis artikel ini lebih dari sebulan yang lalu) untuk menandai segmen yang diterima dan menghitung DER (Diariztion Error Rate). Secara subyektif, saya mengevaluasi operasi algoritma sebagai "pada prinsipnya, tidak buruk, tetapi jauh dari ideal." Dengan mengelompokkan pada vektor yang diperoleh dari seratus segmen pertama (dengan satu pass MAP), dan kemudian memilih yang menurut pewawancara (gadis, dia berbicara jauh lebih sedikit daripada tamu di sana), pengelompokan memberikan daftar
[ 1 , 2 , 25 , 26 , 46 , 48 , 49 , 61 , 85 , 86 ] itu 100% hit. Pada saat yang sama, segmen di mana kedua speaker hadir (misalnya, 14) putus, tetapi ini sudah dapat disalahkan pada kesalahan VAD. Selain itu, segmen-segmen tersebut mulai diperhitungkan dengan peningkatan jumlah pass MAP. Poin penting. Wawancara yang kami kerjakan kurang lebih "bersih." Jika berbagai sisipan musik, kebisingan dan hal-hal non-verbal ditambahkan, pengelompokan mulai lemas. Oleh karena itu, ada rencana untuk mencoba melatih VAD kita sendiri (karena webrtcvad, misalnya, tidak memisahkan musik dari ucapan).
Karena pada awalnya saya bekerja dengan percakapan telepon, saya tidak perlu memperkirakan jumlah pembicara. Tetapi jumlah penuturnya tidak selalu ditentukan sebelumnya, meskipun ini adalah wawancara. Misalnya, dalam wawancara
ini di tengah ada pengumuman ditumpangkan pada musik dan disuarakan oleh dua orang tambahan. Oleh karena itu, akan menarik untuk mencoba metode memperkirakan jumlah penutur yang ditentukan dalam artikel pertama di bagian daftar referensi (berdasarkan analisis nilai eigen dari matriks Laplace yang dinormalisasi).
Referensi
Selain bahan-bahan yang terdapat pada tautan dalam teks dan laptop Jupyter, sumber-sumber berikut digunakan untuk menyiapkan artikel ini:
- Speaker Diarization menggunakan GMM Supervector dan Advanced Reduction Algorithms. Nurit spingarn
- Metode Ekstraksi Fitur LPC, PLP dan MFCC Dalam Pengenalan Ucapan. Namrata dave
- Penilaian MAP untuk pengamatan campuran Gauss mulivariat rantai markov. Jean-Luc Gauvain dan Chin-Hui Lee
- Pada Analisis Clustering Spectral dan sebuah algoritma. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Pengenalan speaker menggunakan model latar belakang universal pada basis data YOHO. Alexandre Majetniak
Saya juga akan menambahkan beberapa proyek diarisasi:
- Ekstensi diarisasi sidekit dan s4d. Pustaka python untuk bekerja dengan pidato. Sayangnya, dokumentasinya buruk.
- Bob dan berbagai bagiannya seperti bob.bio , bob.learn.em - pustaka python untuk pemrosesan sinyal dan bekerja dengan data biometrik. Windows tidak didukung.
- LIUM adalah solusi turnkey yang ditulis dalam Java.
Semua kode diposting di
github . Untuk kenyamanan, saya membuat beberapa laptop Jupyter dengan demonstrasi hal-hal tertentu - MFCC, GMM, MAP Adaptasi dan Diarisasi. Yang terakhir adalah proses utama. Juga dalam repositori adalah file acar dengan beberapa model pra-terlatih dan wawancara itu sendiri.