Saat ini, serat optik telah menjadi bagian integral dari bidang kehidupan manusia yang paling beragam: dari internet di rumah hingga endoskopi. Penggunaan serat optik disebabkan oleh sejumlah keunggulan: kecepatan transmisi, kekuatan fisik, bandwidth, keamanan informasi, dll.
Untuk meningkatkan throughput, serat optik multimode (MMF) dibuat ketika informasi ditransmisikan melalui beberapa saluran paralel. Terlepas dari semua kelebihannya, MMF juga memiliki sejumlah kelemahan, salah satunya peneliti memutuskan untuk menghilangkannya untuk meningkatkan proses transfer gambar. Intinya adalah ini: ketika sampel diproyeksikan ke sisi proksimal MMF, gambar yang kita dapatkan di sisi distal adalah speckle, karena data yang masuk didistribusikan melalui banyak mode dengan berbagai tingkat propagasi sepanjang serat. Para ilmuwan mengusulkan menggunakan kombinasi serat multimode dan pembelajaran mendalam untuk jaringan saraf tiruan untuk mendapatkan gambar yang akurat, termasuk saat menggunakan endoskopi. Mari kita menggali laporan para peneliti dan mencoba memahami cara kerjanya dan apa yang memberikan hasil. Ayo pergi.
Dasar studiTeknik untuk menggunakan jaringan saraf tiruan untuk mendekripsi gambar yang dikirim melalui MMF telah dikembangkan sejak lama. Jadi pada karya-karya awal, jaringan dua lapis dideskripsikan, mampu mengenali sekitar 10 gambar yang melewati 10 meter serat yang dijahit.
Dalam studi ini, sistemnya jauh lebih kompleks, tetapi, menurut para ilmuwan, jauh lebih efisien. Langkah awal adalah mengumpulkan sejumlah besar sampel spekel yang diperoleh dengan melewatkan gambar melalui MMF. Mereka telah menjadi basis pengetahuan untuk pelatihan DNN (jaringan saraf tiruan berdasarkan
pembelajaran mendalam * ).
 Contoh gambar belu
Contoh gambar beluPembelajaran mendalam * - kombinasi metode pembelajaran mesin berdasarkan presentasi, bukan algoritma khusus untuk tugas tertentu.
Arsitektur DNN sangat kompleks dan memiliki sekitar 14
lapisan tersembunyi * .
Lapisan tersembunyi * - jaringan saraf tiruan terdiri dari unit komputasi (neuron), yang dibagi menjadi 3 kategori: input, tersembunyi dan output. Input menerima informasi, yang tersembunyi melakukan berbagai perhitungan, dan akhir pekan mengirimkan informasi lebih lanjut.
Untuk melakukan percobaan pada DNN, database 20.000 nomor yang ditulis secara manual dibuat. Selanjutnya, pangkalan dibagi secara acak menjadi beberapa kelompok:
- 16.000 digit - pelatihan;
- 2.000 digit - verifikasi;
- 2.000 digit - tes.
Mempersiapkan percobaanGambar di bawah ini menunjukkan diagram sistem optik yang digunakan untuk mengumpulkan data.
 Gambar No. 1: diagram instalasi:
Gambar No. 1: diagram instalasi:
Sumber laser - sumber radiasi laser (sinar);
HWP - piring setengah gelombang;
M1 adalah cermin;
SLM - modulator cahaya spasial;
P adalah polarizer linier;
L adalah lensa;
BS - beam splitter;
OBJ - tujuan mikroskop;
OF - serat optik;
CCD - kamera CCD.Dan sekarang dalam rangka. Sinar laser dengan panjang gelombang 560 nm mengarahkan cahaya melalui
serat optik gradien * dengan diameter inti 62,5 μm dan
bukaan numerik * 0,275.
MMF Gradien * adalah serat optik dengan profil bias yang tidak seragam, ketika indeks bias secara bertahap menurun dari tepi ke sumbu serat.
 Perbandingan jenis serat: langkah multimode, multimode gradien, dan mode tunggal (atas ke bawah).
Perbandingan jenis serat: langkah multimode, multimode gradien, dan mode tunggal (atas ke bawah).
Bukaan numerik * adalah sinus sudut maksimum antara balok dan sumbu. Dalam hal ini, ada refleksi internal total dalam distribusi radiasi di atas serat.
Pada panjang gelombang tertentu, serat mampu mendukung sekitar 4.500 mode spasial. Sampel input (gambar) ditampilkan pada modulator cahaya spasial, setelah itu mereka dialihkan menggunakan sistem 4f ke wajah proksimal (dekat dengan pusat) MMF. Di ujung serat, sistem 4f lainnya memvisualisasikan spekel yang berasal dari permukaan serat (jauh dari tengah) distal ke kamera CCD.
CCD * adalah perangkat charge-coupled yang mengimplementasikan teknologi transfer biaya terkontrol dalam volume semikonduktor.
Untuk memeriksa model fase dan amplitudo sebagai sinyal input untuk gradien MMF, pelat setengah gelombang dipasang sebelum SLM, dan polarizer linier setelah SLM.
Seperti disebutkan sebelumnya, angka yang ditulis secara manual bertindak sebagai sampel. Mereka diambil dari
database MNIST .
Sebelum diproses oleh DNN, masing-masing gambar yang direkam pada CCD1 atau CCD2 dipangkas menjadi 1024 × 1024 piksel. Selanjutnya, gambar spekel yang diperoleh dikurangi menjadi 32 × 32 piksel dan digunakan sebagai input untuk DNN.
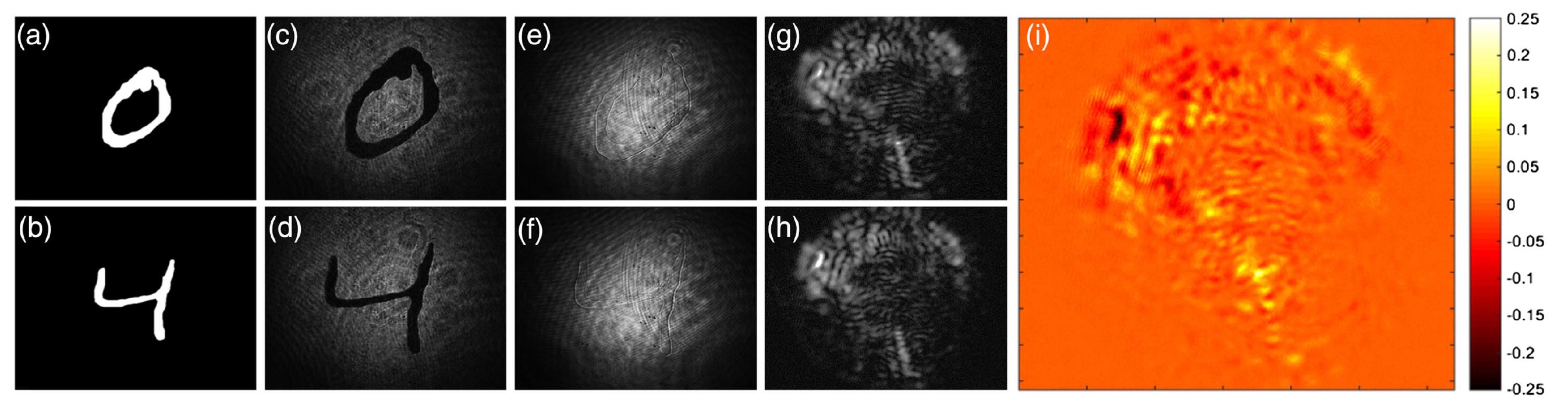
Gambar No. 2Dalam gambar
2a dan
2b kita melihat pola angka (0 dan 4).
2c dan
2d adalah angka yang sama, tetapi setelah modulasi amplitudo, ketika amplitudo dari sinyal yang ditransmisikan dapat berubah.
2e dan
2f adalah digit sampel setelah modulasi fase, ketika fase osilasi pembawa berubah dalam proporsi langsung ke sinyal. Kami juga melihat bintik-bintik itu sendiri, yang terpaku pada permukaan distal serat setelah melewati jarak 2 cm.
Cukup sulit untuk membedakan speckles (
2g dan
2h ). Namun, jika kita membandingkan gambar
2d dan
2h (misalnya, perhatikan sampel "4"), maka kita dapat mengisolasi perbedaan yang dapat ditentukan oleh DNN (
2i ). Dengan demikian, fitur-fitur khusus ini akan memungkinkan sistem untuk membedakan "0" dari "4", "2" dari "9", dll.
Pemrosesan dataJaringan neural konvolusional * tipe Visual Geometry Group (VGG) (3a) menjadi dasar sistem untuk menentukan spekel dan merekonstruksi gambar input.
Convolutional neural network * - Arsitektur JST, ditandai dengan operasi konvolusi, ketika setiap fragmen gambar dikalikan dengan matriks konvolusi dengan elemen, setelah itu hasilnya dijumlahkan dan dituliskan ke posisi yang sama dalam gambar output.

Contoh arsitektur jaringan saraf convolutional.
Pengenalan sistem seperti itu memungkinkan untuk mendekripsi gambar dengan akurasi yang lebih besar. Untuk rekonstruksi gambar, "U-net" jenis jaringan saraf convolutional dengan 14 lapisan tersembunyi digunakan (
3b ).
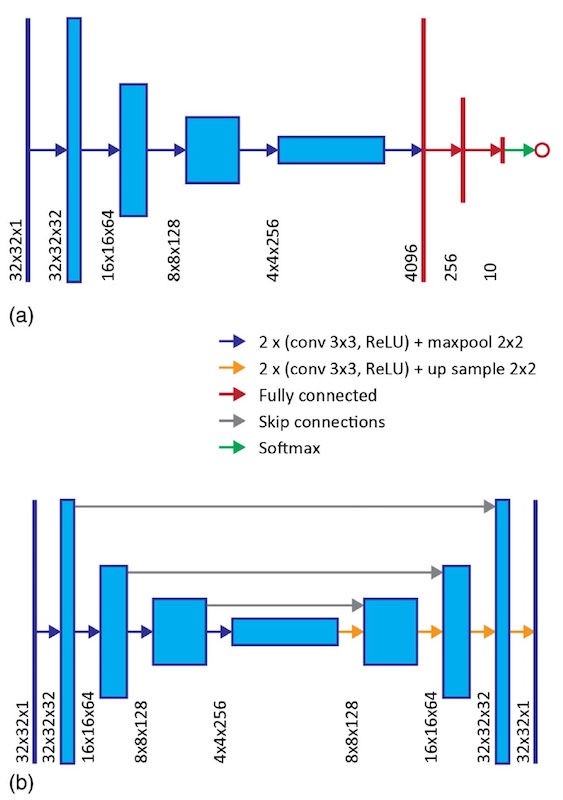 Gambar No. 3
Gambar No. 3Ingatlah bahwa basis 20.000 angka dibagi menjadi tiga kelompok (16.000 untuk pelatihan, 2.000 untuk pengujian dan 2.000 untuk pengujian).
Kelompok pelatihan diproses dalam batch 50 untuk jaringan rekonstruksi dan 500 untuk jaringan penentuan. Pada saat yang sama, para pihak berubah untuk menghindari
pelatihan ulang * .
Pelatihan ulang * - kasus ketika sistem menangani contoh-contoh dari set pelatihan dengan baik, tetapi tidak mengatasi dengan baik contoh-contoh dari tes.
Untuk meminimalkan kesalahan root-mean-square, algoritma optimasi dengan kecepatan belajar 1 x 10
-4 digunakan .
Jala melewati fase pelatihan tidak lebih dari 50 zaman (siklus backpropagation). Untuk setiap kasus, pelatihan diulang 10 kali untuk mengumpulkan data statistik tentang keakuratan sistem pelatihan.
Semua DNN diimplementasikan berdasarkan GPU NVIDIA GeForce GTX 1080Ti tunggal menggunakan pustaka Python TensorFlow 1.5.
Hasil penelitianRekonstruksiParameter pertama yang diputuskan oleh para ilmuwan untuk diteliti secara lebih rinci adalah kemampuan sistem untuk merekonstruksi data input.

Gambar di atas menunjukkan hasil rekonstruksi angka (0 ... 9), setelah melewati data melalui serat 0,1 m, 10 m dan panjang 1000 m.
Seperti yang dapat kita lihat, hasil dari prosedur ini sangat akurat, yang menegaskan kemampuan sistem U-net untuk mengisolasi fitur-fitur pembeda ekstrim dari gambar masa depan.
Tingkat ketepatan rekonstruksi juga diverifikasi. Indikator ini berkurang dengan bertambahnya panjang serat dari 96,9% (0,1 m) menjadi 90,0% (1000 m).
Penurunan akurasi disebabkan oleh fakta bahwa dengan panjang serat 1 km, timbul ketidakhomogenan suhu di dalamnya (ekspansi material akibat panas dan / atau perubahan indeks bias), yang mengubah jalur optik sinyal. Proses-proses ini mengarah pada fakta bahwa pola spekel di ujung distal menjadi tidak stabil, yang membuatnya lebih sulit untuk direkonstruksi menjadi gambar yang diinginkan.
Para peneliti mencatat bahwa paparan eksternal pada serat juga mengurangi tingkat akurasi rekonstruksi gambar. Oleh karena itu, dengan perbaikan sistem lebih lanjut, serat optik harus dilengkapi dengan isolasi termal dan media isotermal untuk mencapai tingkat akurasi rekonstruksi maksimum.
Prosedur rekonstruksi juga dengan sempurna meratakan artefak pada gambar yang diproses.

Misalnya, sistem mengisolasi gambar (
2a ) dari spalle distal (
2g ), sementara secara bersamaan menghilangkan cacat yang diproyeksikan ke tepi proksimal serat (
2c dan
2e ). Selain itu, sistem mencoba menghilangkan artefak yang muncul akibat kontaminasi atau cacat pada sampel atau ketidaktepatan struktural serat itu sendiri.
Klasifikasi sampel cirfSistem dapat membuat ulang gambar, dan keakuratan proses ini sangat mengesankan. Sekarang kita beralih ke analisis seberapa akurat sistem dapat menentukan di mana gambar (angka), yaitu, untuk mengklasifikasikan data setelah rekonstruksi.
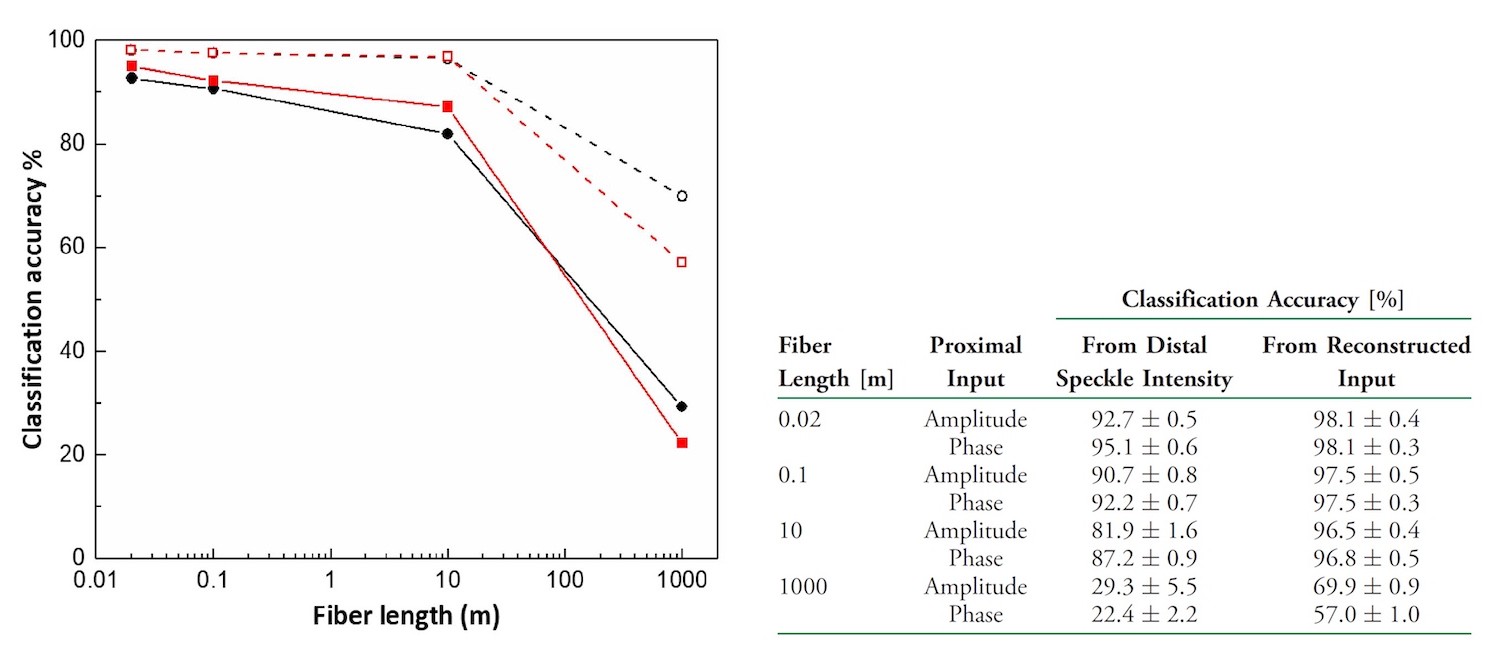
Dari grafik dan tabel di atas dapat dilihat bahwa akurasi klasifikasi menurun dengan meningkatnya panjang serat yang terlibat dalam transmisi. Tren yang serupa adalah dengan akurasi rekonstruksi. Terlepas dari apakah model atau fase amplitudo, akurasinya turun. Pada 2 cm serat - akurasi 90%. Ini adalah indikator yang baik, tetapi seratnya terlalu pendek. Namun dengan panjang 1 km, akurasi turun hingga 30%. Peneliti mengaitkan hal ini dengan meningkatnya kehilangan hamburan, mode kopling, dan penyimpangan spekel distal. Semua "gangguan" ini disebabkan oleh peningkatan panjang serat.
 Perubahan Belu Distal
Perubahan Belu DistalRekaman dibuat dengan frame rate 83 fps. Sebagai percobaan pada serat 1 km, gambar kosong dikirim.
 (a) dan (b) - 2 frame diambil dari catatan di atas, (c) - perbandingannya.
(a) dan (b) - 2 frame diambil dari catatan di atas, (c) - perbandingannya.Frame ini direkam dengan selisih 2 detik. Dan seperti yang kita lihat pada gambar (c), perbedaan di antara mereka sangat signifikan. Perubahan tajam pada spekel dapat dikaitkan dengan fluktuasi suhu lingkungan atau aliran udara di atas perangkat (gambar No. 1), yang dapat menyebabkan gangguan kecil pada serat. Tetapi ketika panjang serat meningkat, kekuatan gangguan tersebut menjadi nyata.
Ternyata semua operasi sistem akan sia-sia karena "gangguan" ini. Namun, para ilmuwan tidak menghentikan kesulitan seperti itu, melainkan mendorong mereka untuk berpikir.
Diputuskan untuk melakukan studi perpindahan speckle dan bagaimana mereka mempengaruhi keakuratan klasifikasi gambar. Untuk ini, jaringan VGG dilatih berdasarkan 10.000 sampel (setengah dari yang tersedia), kemudian pengujian dilakukan, tetapi dengan separuh sampel lainnya. Proses itu diulangi, mengubah 2 kelompok sampel di beberapa tempat. Hasil penelitian menunjukkan bahwa tidak ada perubahan signifikan dalam akurasi klasifikasi, karena pergeseran spekel tidak disengaja, yang berarti bahwa JST mampu mempelajari, mengingat, dan menentukannya dalam proses.
Perbedaan antara amplitudo dan modulasi fasa diabaikan. Dengan panjang serat 10 m dan modulasi fase, klasifikasi sedikit lebih baik daripada dengan modulasi amplitudo. Ini disebabkan distribusi cahaya yang lebih seragam pada mode serat optik. Dengan modulasi amplitudo, jumlah mode yang terlibat dalam transmisi terbatas karena eksitasi spasial selektif dari serat.
Jika kita mempertimbangkan opsi panjang serat 1 km, maka modulasi amplitudo sudah melebihi fase. Ketika cahaya melewati serat panjang, semua mode terlibat dalam transmisi informasi sekaligus.
 Matriks kesalahan (matriks kebingungan)
Matriks kesalahan (matriks kebingungan)Untuk meningkatkan akurasi klasifikasi, JST juga dilatih menggunakan sampel yang sudah direkonstruksi. Matriks kesalahan juga diterapkan, yang secara signifikan meningkatkan akurasi klasifikasi.
Misalnya, dalam kasus serat 1 km panjang, ada kebingungan antara angka 4 dan 9, serta antara 3, 5, 6 dan 8.
Untuk mengonfirmasi, lihat saja hasil rekonstruksi.
 Bilangan 4 dan 9
Bilangan 4 dan 9 Bilangan 3, 5, 6 dan 8
Bilangan 3, 5, 6 dan 8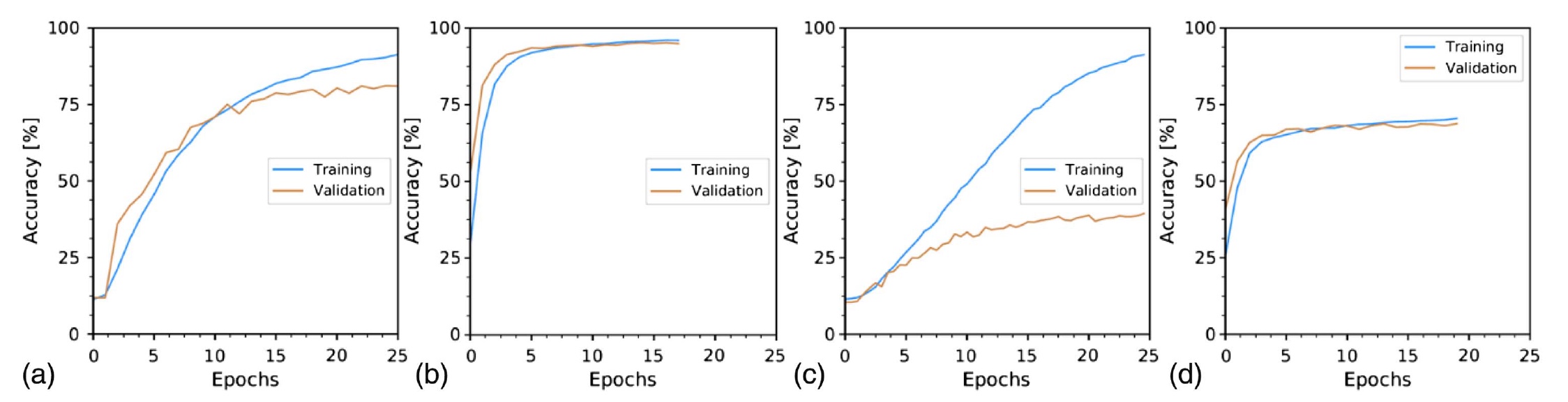
Grafik di atas menunjukkan perubahan dalam akurasi klasifikasi gambar dari waktu ke waktu:
a - 10 m serat dan bintik-bintik distal;
b - 10 m dari serat dan gambar yang direkonstruksi;
s - 1 km serat dan spekel distal;
d - 1 km dari serat dan gambar yang direkonstruksi.
Untuk seorang kenalan terperinci dengan nuansa penelitian, saya sangat merekomendasikan untuk melihat laporan para ilmuwan. Versi PDF juga tersedia di halaman yang sama (tombol "Dapatkan PDF").
EpilogStudi ini menunjukkan hasil yang sangat baik, yang menunjukkan perkembangan di masa depan dan implementasi praktis. Metode di atas dapat diterapkan untuk telekomunikasi (decoding dalam multiplexing) dan bahkan dalam kedokteran (endoskopi).
Setelah menghitung biaya waktu, para ilmuwan menemukan bahwa sebagian besar dari mereka pergi ke persiapan sistem, atau lebih tepatnya ke pelatihannya. Dan ini menunjukkan bahwa sistem yang sudah terlatih dapat menjalankan fungsinya dengan sangat cepat, hingga milidetik. Satu-satunya batasan adalah kekuatan perangkat keras.
Tentu saja, masih banyak yang harus dipelajari di bidang jaringan saraf tiruan berdasarkan pembelajaran yang mendalam. Namun kegunaannya sudah terlihat sekarang. Meningkatkan sistem yang ada, apa pun aplikasinya, sama pentingnya dengan menciptakan sistem baru. Lagi pula, tidak selalu perlu untuk menemukan kembali roda, jika Anda bisa memperbaikinya. Hal utama, seperti yang telah ditunjukkan oleh latihan, adalah berpikir di luar kebiasaan, belajar dari kesalahan kita sendiri dan orang lain, untuk menetapkan tugas yang kadang-kadang mustahil dan untuk percaya pada diri kita sendiri. Jika sebuah gagasan dapat bermanfaat bagi kemanusiaan, itu harus diwujudkan.
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami buat untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
3 bulan gratis ketika membayar untuk Dell R630 baru untuk jangka waktu enam bulan -
2 x Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 4x1TB HDD atau 2x240GB SSD / 1Gbps 10 TB - dari $ 99,33 sebulan , hanya sampai akhir Agustus, pesan bisa
disiniDell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?