Keberhasilan dalam proyek pembelajaran mesin biasanya dikaitkan tidak hanya dengan kemampuan untuk menggunakan perpustakaan yang berbeda, tetapi juga dengan pemahaman tentang daerah di mana data berasal. Ilustrasi yang sangat baik dari tesis ini adalah solusi yang diusulkan oleh tim Alexei Kayuchenko, Sergey Belov, Alexander Drobotov dan Alexey Smirnov dalam kompetisi PIK Digital Day. Mereka mengambil tempat kedua, dan setelah beberapa minggu mereka berbicara tentang partisipasi mereka dan model yang dibangun dalam
pelatihan Yandex ML berikutnya.
Alexey Kayuchenko:
- Selamat sore! Kami akan berbicara tentang kompetisi PIK Digital Day di mana kami berpartisipasi. Sedikit tentang tim. Ada empat dari kita. Semua dengan latar belakang yang sama sekali berbeda, dari berbagai daerah. Bahkan, kami bertemu di final. Tim terbentuk hanya sehari sebelum final. Saya akan berbicara tentang jalannya kompetisi, organisasi kerja. Kemudian Seryozha akan keluar, dia akan memberi tahu tentang data, dan Sasha akan menceritakan tentang pengajuan, pekerjaan terakhir dan bagaimana kita bergerak di sepanjang papan peringkat.

Secara singkat tentang kompetisi. Tugas itu sangat diterapkan. PIC menyelenggarakan kompetisi ini dengan menyediakan data penjualan apartemen. Sebagai kumpulan data pelatihan, ada sebuah cerita dengan atribut selama 2 setengah tahun di Moskow dan wilayah Moskow. Kompetisi terdiri dari dua tahap. Itu adalah panggung online, di mana masing-masing peserta mencoba membuat model mereka sendiri, dan panggung offline, tidak begitu lama, hanya satu hari dari pagi hingga sore. Itu menghantam para pemimpin panggung online.
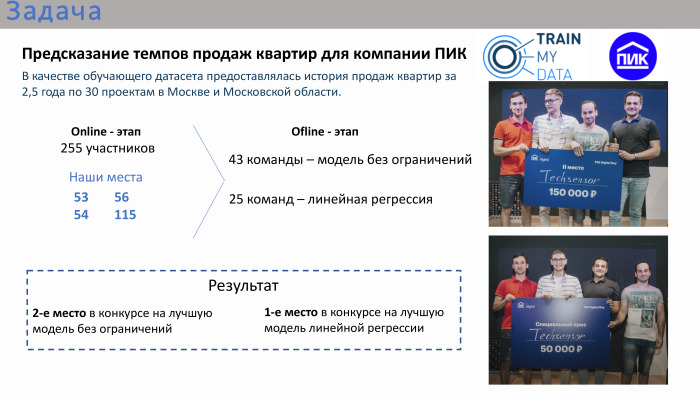
Menurut hasil kompetisi online, tempat kami bahkan tidak masuk 10 besar, dan bahkan tidak masuk 20 besar. Kami berada di sana di tempat 50+. Pada akhirnya, yaitu, panggung offline, ada 43 tim. Ada banyak tim yang terdiri dari satu orang, meskipun dimungkinkan untuk bersatu. Sekitar sepertiga dari tim memiliki lebih dari satu orang. Ada dua kompetisi di final. Kompetisi pertama adalah model tanpa batasan. Dimungkinkan untuk menggunakan algoritma apa pun: pembelajaran dalam, pembelajaran mesin. Secara paralel, kontes diadakan untuk solusi regresi linier terbaik. Penyelenggara menganggap bahwa regresi linier juga cukup diterapkan, karena kompetisi itu sendiri sangat diterapkan secara keseluruhan. Artinya, tugas itu diajukan - perlu untuk memprediksi volume penjualan apartemen, memiliki data historis selama 2,5 tahun sebelumnya dengan atribut.
Tim kami mengambil tempat kedua dalam kompetisi untuk model terbaik tanpa batasan dan tempat pertama dalam kompetisi untuk regresi terbaik. Hadiah ganda.

Saya dapat mengatakan tentang kursus umum organisasi bahwa final sangat menegangkan, cukup menegangkan. Misalnya, keputusan kemenangan kami diunggah hanya dua menit sebelum pertandingan dihentikan. Keputusan sebelumnya menempatkan kami, menurut pendapat saya, di tempat keempat atau kelima. Artinya, kami bekerja sampai akhir, tanpa bersantai. PIC mengatur segalanya dengan sangat baik. Ada meja-meja seperti itu, bahkan ada beranda sehingga Anda bisa duduk di jalan, menghirup udara segar. Makanan, kopi, semuanya disediakan. Gambar menunjukkan bahwa semua orang duduk dalam kelompok mereka, bekerja.
Sergey akan memberi tahu lebih banyak tentang data tersebut.
Sergey Belov:
- Terima kasih. PIC memberi kami beberapa file data. Dua yang utama adalah train.csv dan test.csv, di mana ada sekitar 50 fitur yang dihasilkan oleh PIC itu sendiri. Kereta api terdiri dari sekitar 10 ribu jalur, tes - 2 ribu.
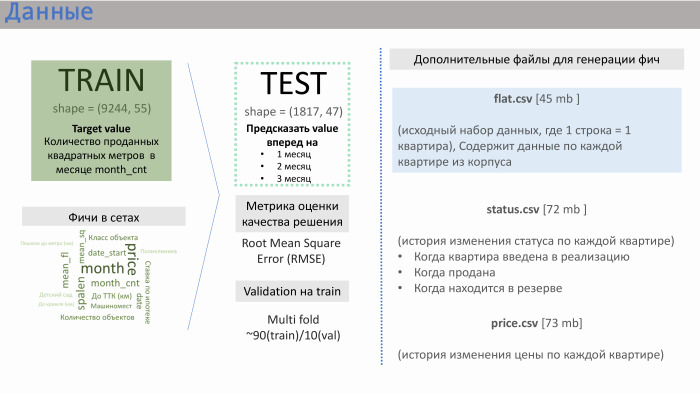
Apa yang disediakan string? Itu berisi data penjualan. Artinya, sebagai nilai (dalam hal ini, target), kami memiliki penjualan per meter persegi untuk rata-rata apartemen di atas bangunan tertentu. Ada sekitar 10 ribu garis seperti itu. Fitur dalam set yang dihasilkan PIK sendiri ditampilkan pada slide dengan perkiraan signifikansi yang kami dapatkan.
Saya dibantu di sini oleh pengalaman di perusahaan pengembangan. Fitur-fitur seperti jarak apartemen ke Kremlin atau ke Transport Ring, jumlah tempat parkir - mereka tidak banyak mempengaruhi penjualan. Pengaruh ini diberikan oleh kelas objek, dormansi, dan, yang paling penting, jumlah apartemen dalam implementasi saat ini. PIC tidak menghasilkan fitur ini, tetapi mereka memberi kami tiga file tambahan: flat.csv, status.csv dan price.csv. Dan kami memutuskan untuk melihat flat.csv, karena hanya ada data tentang jumlah apartemen, status mereka.
Dan jika seseorang bertanya-tanya apa yang menjadi keberhasilan keputusan kami, maka ini adalah kerja tim yang pasti. Sejak awal kompetisi ini, kami bekerja dengan sangat harmonis. Kami segera mendiskusikan di suatu tempat dalam waktu sekitar 20 menit apa yang akan kami lakukan. Kami sampai pada kesimpulan umum bahwa hal pertama yang Anda butuhkan untuk bekerja dengan data adalah karena setiap ilmuwan data memahami bahwa ada banyak data dalam data dan sering kali kemenangan disebabkan oleh beberapa fitur yang dihasilkan oleh tim. Setelah bekerja dengan data, kami terutama menggunakan berbagai model. Kami memutuskan untuk melihat hasil apa yang diberikan fitur kami di masing-masing model ini, dan kemudian kami fokus pada model yang tidak terbatas dan model regresi linier.
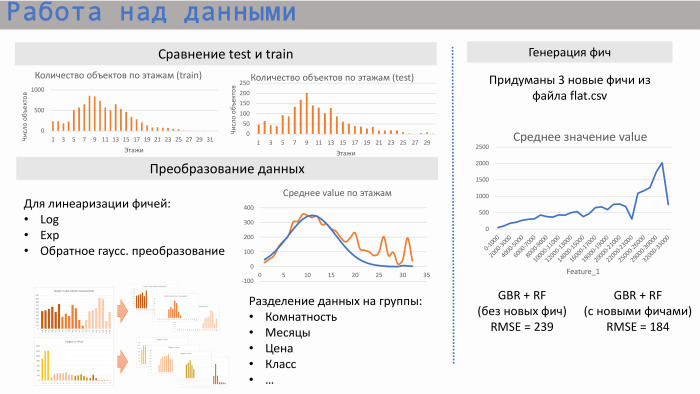
Kami mulai bekerja dengan data. Pertama-tama, kami melihat bagaimana tes rangkaian kereta berhubungan satu sama lain, yaitu, apakah area data ini bersinggungan. Ya, mereka berpotongan: dalam jumlah apartemen, dan di dormansi, dan dalam jumlah rata-rata tingkat tertentu.
Selanjutnya untuk regresi linier, kami mulai melakukan transformasi tertentu. Ini seperti logaritma standar eksponen. Misalnya, dalam kasus lantai tengah, ini adalah transformasi Gaussian terbalik untuk linierisasi. Kami juga memperhatikan bahwa terkadang lebih baik memisahkan data menjadi grup. Jika kita mengambil, misalnya, jarak dari apartemen ke metro atau kamarnya, maka ada pasar yang sedikit berbeda, dan lebih baik untuk membagi, membuat model yang berbeda untuk masing-masing kelompok tersebut.
Kami menghasilkan tiga fitur dari file flat.csv. Salah satunya disajikan di sini. Dapat dilihat bahwa ia memiliki hubungan linier yang cukup baik, di samping penurunan ini. Apa fitur ini? Itu sesuai dengan jumlah apartemen yang saat ini sedang dilaksanakan. Dan fitur ini bekerja sangat baik pada nilai yang rendah. Artinya, tidak mungkin ada lebih banyak apartemen yang terjual daripada jumlah yang ada dalam penjualan. Tetapi dalam file-file ini, pada kenyataannya, faktor manusia tertentu diletakkan, karena mereka sering disusun oleh manusia. Kami langsung melihat ada poin yang tersingkir dari area ini, karena mereka tersumbat sedikit salah.
Contoh dari scikit-learn. Model dari GBR dan Random Forest tanpa fitur memberi RMSE 239, dan dengan ketiga fitur ini - 184.
Sasha akan berbicara tentang model yang kami gunakan.
Alexander Drobotov:
- Beberapa kata tentang pendekatan kami. Seperti yang dikatakan orang-orang, kita semua berbeda, berasal dari berbagai daerah, pendidikan berbeda. Dan kami memiliki pendekatan yang berbeda. Pada tahap akhir, Lesha menggunakan XGBoost dari Yandex lebih banyak (kemungkinan besar, maksud saya CatBoost - red.), Seryozha - perpustakaan scikit-belajar, I - LightGBM dan regresi linier.

Model XGBoost, regresi linier dan Nabi adalah tiga opsi yang menunjukkan skor terbaik bagi kami. Untuk regresi linier, kami telah memadukan dua model, dan untuk kompetisi umum, XGBoost, dan kami menambahkan sedikit regresi linier.

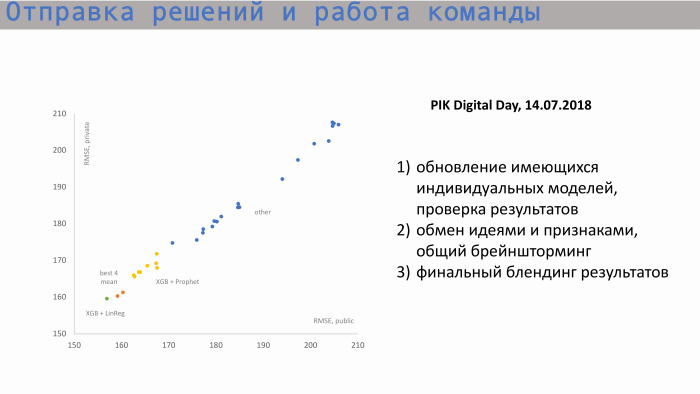
Inilah proses pengiriman keputusan dan kerja tim. Pada grafik di sebelah kiri, sumbu X adalah RMSE publik, nilai metrik, dan sumbu Y adalah skor pribadi, RMSE. Kami mulai dari posisi ini. Berikut adalah model individual dari masing-masing peserta. Kemudian, setelah bertukar ide dan membuat fitur baru, kami mulai mendekati skor terbaik kami. Nilai kami untuk masing-masing model kurang lebih sama. Model individu terbaik adalah XGBoost dan Nabi. Nabi menciptakan ramalan untuk akumulasi penjualan. Ada tanda seperti awal kotak. Yaitu, kami tahu berapa banyak apartemen yang kami miliki total, kami memahami apa nilai historis, dan nilai tambahan yang dicari ke nilai total. Nabi membuat ramalan untuk masa depan, mengeluarkan nilai pada periode berikut dan mengirimkannya ke XGBoost.
Perpaduan skor individu terbaik kami ada di sekitar sini, dua titik oranye ini. Tetapi skor ini tidak cukup bagi kami untuk mencapai puncak.
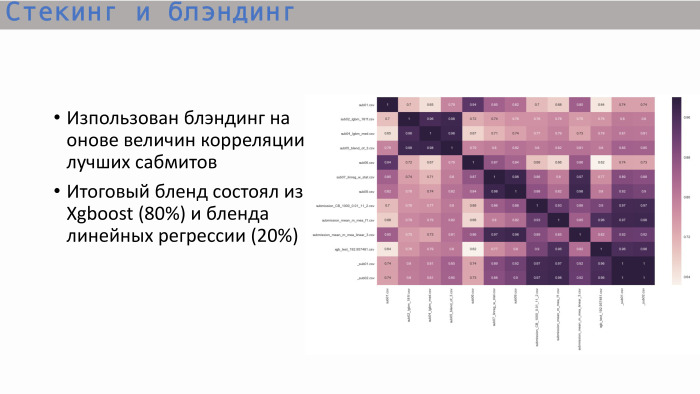
Setelah mempelajari matriks korelasi biasa dari pengiriman terbaik, kami melihat yang berikut: pohon - dan ini logis - menunjukkan korelasi yang dekat dengan persatuan, dan pohon terbaik memberikan XGBoost. Ini menunjukkan korelasi yang tidak terlalu tinggi dengan regresi linier. Kami memutuskan untuk menggabungkan kedua opsi ini dengan rasio 8 banding 2. Itulah cara kami mendapatkan solusi akhir terbaik.
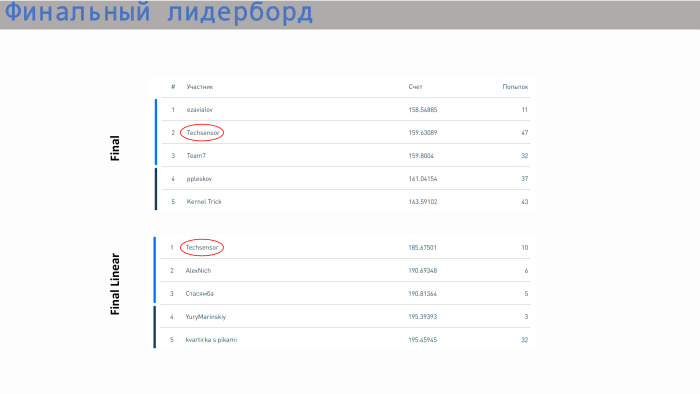
Ini adalah papan peringkat dengan hasil. Tim kami mengambil tempat kedua dalam model tak terbatas dan tempat pertama dalam model linier. Adapun skor - di sini semua nilai cukup dekat. Perbedaannya tidak terlalu besar. Regresi linier sudah mengambil langkah di bidang 5. Kami memiliki segalanya, terima kasih!