
Salah satu konferensi Ilmu Data utama tahun ini dimulai di London hari ini. Saya akan mencoba untuk segera berbicara tentang apa yang menarik untuk didengar.
Awalnya berubah menjadi gugup: pada pagi yang sama, sebuah pertemuan massa Saksi-Saksi Yehuwa diselenggarakan di pusat yang sama, jadi tidak mudah untuk menemukan meja pendaftaran untuk polisi lalu lintas, dan ketika saya akhirnya menemukannya, antreannya panjang 150-200 meter. Namun demikian, setelah ~ 20 menit menunggu, ia menerima lencana yang diidam-idamkan dan pergi ke kelas master.
Privasi dalam analisis data
Lokakarya pertama didedikasikan untuk menjaga privasi dalam analisis data. Pada awalnya, saya terlambat, tetapi, tampaknya, saya tidak kehilangan banyak hal - mereka berbicara tentang betapa pentingnya privasi dan bagaimana penyerang dapat menggunakan informasi pribadi yang diungkapkan dengan buruk. Ngomong-ngomong, orang-orang cukup terhormat dari Google, LinkedIn dan Apple memberi tahu. Sebagai hasil dari kelas master meninggalkan kesan yang sangat positif, semua slide tersedia di
sini .
Ternyata konsep
Privasi Diferensial telah ada sejak lama, ide yang menambah kebisingan yang membuat sulit untuk menetapkan nilai-nilai individu yang sebenarnya, tetapi mempertahankan kemampuan untuk memulihkan distribusi umum. Sebenarnya, ada dua parameter:
e - betapa sulitnya untuk mengungkapkan data, dan
d - seberapa terdistorsi jawabannya.
Dalam konsep asli, diasumsikan bahwa antara analis dan data ada tautan menengah tertentu - "Kurator", dialah yang memproses semua permintaan dan menghasilkan jawaban sehingga suara itu mengaburkan data pribadi. Pada kenyataannya, model Privasi Diferensial Lokal sering digunakan, di mana data pengguna tetap pada perangkat pengguna (misalnya, ponsel atau PC), namun, ketika menanggapi permintaan pengembang, aplikasi mengirimkan paket data dari perangkat pribadi yang tidak memungkinkan untuk mengetahui apa sebenarnya Pengguna khusus ini menjawab. Meskipun, saat menggabungkan respons dari sejumlah besar pengguna, Anda dapat mengembalikan keseluruhan gambar dengan akurasi tinggi.
Contoh yang baik adalah survei "Sudahkah Anda melakukan aborsi"? Jika Anda melakukan survei "di dahi", maka tidak ada yang akan mengatakan yang sebenarnya. Tetapi jika Anda mengatur survei sebagai berikut: "lempar koin, jika ada elang, lalu lemparkan lagi dan katakan" ya "ke elang, tetapi" tidak "ke ekor, kalau tidak jawablah yang sebenarnya", mudah untuk mengembalikan distribusi yang sebenarnya sambil menjaga privasi individu. Pengembangan gagasan ini adalah mekanisme pengumpulan statistik sensitif
Google RAPPOR (Laporan Tata Cara Pelestarian Privasi yang Diakhiri Privasi), yang digunakan untuk mengumpulkan data tentang penggunaan Chrome dan fork-forknya.
Segera setelah rilis Chrome di open source, sejumlah besar orang muncul yang ingin membuat browser mereka sendiri dengan beranda ditimpa, mesin pencari, dadu iklan mereka sendiri, dll. Biasanya, pengguna dan Google tidak antusias dengan hal ini. Tindakan lebih lanjut umumnya dapat dimengerti: untuk mengetahui penggantian dan penghancuran yang paling umum secara administratif, tetapi yang tidak terduga keluar ... Kebijakan privasi Chrome tidak memungkinkan Google untuk mengambil dan mengumpulkan informasi tentang pengaturan halaman beranda pengguna dan mesin pencari :(
Untuk mengatasi keterbatasan ini dan menciptakan RAPPOR, yang berfungsi sebagai berikut:
- Data di halaman rumah dicatat dalam filter bloom kecil, sekitar 128 bit.
- Kebisingan putih permanen ditambahkan ke filter bloom ini. Permanen = sama untuk pengguna ini, tanpa menyimpan noise, beberapa permintaan dapat mengungkapkan data pengguna.
- Di atas kebisingan konstan, kebisingan individual yang dihasilkan untuk setiap permintaan ditumpangkan.
- Vektor bit yang dihasilkan dikirim ke Google, di mana dekripsi dari keseluruhan gambar dimulai.
- Pertama, dengan metode statistik kami mengurangi efek kebisingan dari gambaran keseluruhan.
- Selanjutnya, kami membuat vektor bit kandidat (pada prinsipnya situs / mesin pencari paling populer).
- Menggunakan vektor yang diperoleh sebagai dasar, kami membangun regresi linier untuk merekonstruksi gambar.
- Gabungkan regresi linier dengan LASSO untuk menekan kandidat yang tidak relevan.
Secara skematis, konstruksi filter terlihat seperti ini:

Pengalaman menerapkan RAPPOR ternyata sangat positif, dan jumlah statistik pribadi yang dikumpulkan dengan bantuannya berkembang pesat. Di antara faktor-faktor keberhasilan utama, penulis mengidentifikasi:
- Kesederhanaan dan kejelasan model.
- Keterbukaan dan dokumentasi kode.
- Kehadiran pada grafik akhir dari batas kesalahan.
Namun, pendekatan ini memiliki batasan yang signifikan: perlu ada daftar jawaban kandidat untuk dekripsi (itulah sebabnya O - Ordinal). Ketika Apple mulai mengumpulkan statistik tentang kata-kata dan emoji yang digunakan dalam pesan teks, menjadi jelas bahwa pendekatan ini tidak baik. Akibatnya, pada konferensi WDC-2016, salah satu fitur baru teratas yang diumumkan di iOS adalah penambahan privasi diferensial. Kombinasi dari struktur sketsa dengan kebisingan tambahan juga digunakan sebagai dasar, namun, banyak masalah teknis harus diselesaikan:
- Klien (telepon) harus dapat membangun dan menyimpan jawaban ini dalam waktu yang wajar.
- Selanjutnya, respons ini harus dikemas dalam pesan jaringan berukuran terbatas.
- Di pihak Apple, semua ini harus dikumpulkan dalam jumlah waktu yang wajar.
Sebagai hasilnya, kami membuat skema menggunakan
count-min-sketsa untuk pengkodean kata-kata, kemudian kami secara acak memilih respons hanya dari satu fungsi hash (tetapi dengan memperbaiki pilihan untuk pasangan pengguna / kata), vektor tersebut dikonversi menggunakan
transformasi Hadamard dan dikirim ke server saja. satu "bit" yang signifikan untuk fungsi hash yang dipilih.
Untuk mengembalikan hasilnya di server, perlu juga untuk meninjau hipotesis kandidat. Tapi, ternyata dengan ukuran kamus yang besar itu terlalu rumit bahkan untuk sebuah cluster. Itu perlu entah bagaimana secara heuristik memilih area pencarian yang paling menjanjikan. Percobaan dengan menggunakan bigrams sebagai titik awal, dari mana Anda dapat mengumpulkan mosaik, tidak berhasil - semua bigrams sama-sama populer. Pendekatan hash bigram + kata menyelesaikan masalah, tetapi menyebabkan pelanggaran privasi. Sebagai hasilnya, kami memilih pohon awalan: statistik dikumpulkan pada bagian awal kata dan kemudian pada keseluruhan kata.
Namun, analisis algoritma privasi yang digunakan oleh Apple oleh komunitas penelitian telah menunjukkan bahwa privasi masih
dapat dikompromikan dengan statistik jangka panjang.
LinkedIn berada dalam situasi yang lebih sulit dengan studinya tentang distribusi gaji pengguna. Faktanya adalah bahwa privasi diferensial berfungsi dengan baik ketika kami memiliki jumlah pengukuran yang sangat besar, jika tidak, tidak mungkin untuk mengurangi kebisingan secara andal. Dalam survei gaji, jumlah laporan terbatas, dan LinkedIn memutuskan untuk mengambil jalur yang berbeda: menggabungkan kriptografi teknis dan alat keamanan siber dengan konsep
k-Anonimitas : data pengguna dianggap cukup disamarkan jika Anda mengirimkannya dalam paket di mana ada jawaban k dengan atribut input yang sama (misalnya, lokasi dan profesi) yang berbeda hanya dalam variabel target (gaji).
Akibatnya, konveyor kompleks dibangun di mana layanan yang berbeda mengirimkan potongan data satu sama lain, terus-menerus mengenkripsi sehingga satu mesin tidak dapat sepenuhnya membukanya. Akibatnya, pengguna dibagi berdasarkan atribut ke dalam kohort, dan ketika kohort mencapai ukuran minimum, statistiknya pergi ke HDFS untuk dianalisis.
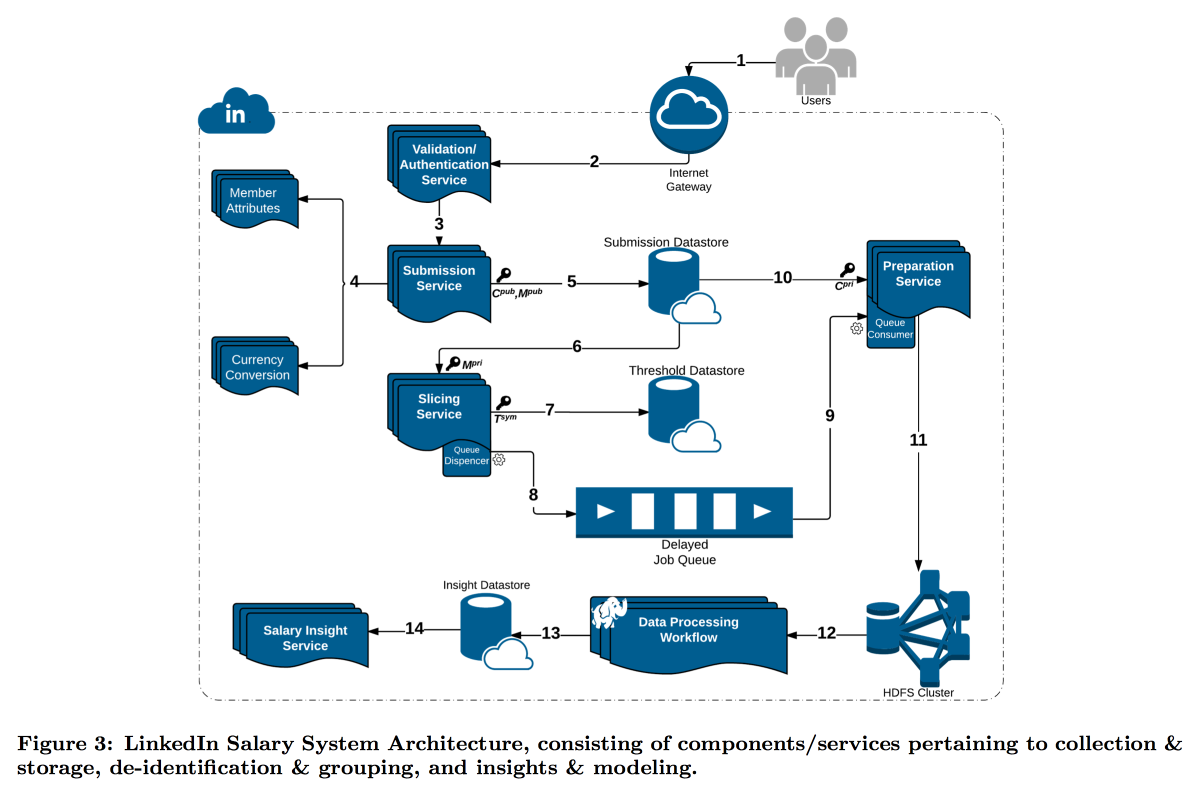
Stempel waktu perlu mendapat perhatian khusus: stempel waktu juga harus dianonimkan, jika tidak, Anda dapat mengetahui jawaban siapa yang merupakan log panggilan. Tetapi saya tidak ingin mengambil waktu sepenuhnya, karena menarik untuk mengikuti dinamika. Akibatnya, kami memutuskan untuk menambahkan stempel waktu ke atribut yang digunakan kohort, dan rata-rata nilainya di dalamnya.
Hasilnya adalah fitur premium yang menarik dan beberapa pertanyaan terbuka yang menarik:
GDPR menyarankan bahwa, berdasarkan permintaan, kami harus dapat menghapus semua data pengguna, tetapi kami mencoba menyembunyikannya sehingga sekarang kami tidak dapat menemukan data siapa itu. Memiliki data pada sejumlah besar irisan / kohort yang berbeda, Anda dapat mengisolasi kecocokan dan memperluas daftar atribut terbuka
Pendekatan ini berfungsi untuk data besar, tetapi tidak bekerja dengan data kontinu. Praktik menunjukkan bahwa hanya pengambilan sampel data bukanlah ide yang baik, tetapi Microsoft di NIPS2017
mengusulkan solusi tentang cara bekerja dengannya. Sayangnya, detailnya tidak punya waktu untuk diungkapkan.
Analisis Grafik Besar
Lokakarya kedua tentang analisis grafik besar dimulai pada sore hari. Terlepas dari kenyataan bahwa dia juga dipimpin oleh orang-orang dari Google, dan ada lebih banyak harapan darinya, dia kurang menyukainya - mereka berbicara tentang teknologi tertutup mereka, kemudian jatuh ke banalisme dan filosofi umum, kemudian terjun ke detail liar, bahkan tidak punya waktu untuk merumuskan tugas. Meskipun demikian, saya dapat menangkap beberapa aspek menarik. Slide dapat ditemukan di
sini .
Pertama, saya menyukai skema yang disebut
pengelompokan ego-jaringan , saya pikir mungkin untuk membangun solusi yang menarik atas dasar itu. Idenya sangat sederhana:
- Kami menganggap grafik lokal dari sudut pandang pengguna tertentu, TETAPI dikurangi dirinya sendiri.
- Kami mengelompokkan grafik ini.
- Selanjutnya, kami “mengkloning” bagian atas pengguna kami, menambahkan sebuah instance ke setiap cluster dan tidak menghubungkan mereka satu sama lain dengan tepian.
Dalam grafik yang diubah serupa, banyak masalah diselesaikan lebih mudah dan algoritma peringkat bekerja lebih bersih. Sebagai contoh, jauh lebih mudah untuk mempartisi grafik seperti itu secara seimbang, dan ketika memberi peringkat pada rekomendasi teman-teman, node jembatan jauh lebih tidak berisik. Untuk tugas inilah rekomendasi teman-teman ENC dipertimbangkan / dipromosikan.
Tetapi secara umum, ENC hanyalah sebuah contoh, di Google seluruh departemen terlibat dalam pengembangan algoritma pada grafik dan memasok mereka ke departemen lain sebagai perpustakaan. Fungsi perpustakaan yang dinyatakan sangat mengesankan: perpustakaan impian untuk SNA, tetapi semuanya sudah ditutup. Dalam kasus terbaik, setiap blok dapat dicoba direproduksi oleh artikel. Dikatakan bahwa perpustakaan memiliki ratusan implementasi di dalam Google, termasuk pada grafik dengan lebih dari satu triliun tepi.
Lalu ada sekitar 20 menit promosi model MapReduce, seolah-olah kita tidak tahu betapa kerennya itu. Setelah itu orang-orang menunjukkan bahwa banyak masalah kompleks dapat diselesaikan (kurang-lebih) menggunakan model Random Sets Composable Core. Gagasan utama adalah bahwa data tentang tepi secara acak tersebar ke N node, di sana mereka ditarik ke memori dan masalah diselesaikan secara lokal, setelah itu hasil dari solusi ditransfer ke mesin pusat dan dikumpulkan. Dikatakan bahwa dengan cara ini Anda bisa dengan murah mendapatkan perkiraan yang baik untuk banyak masalah: komponen konektivitas, hutan spanning minimum, pencocokan maks, cakupan max, dll. Dalam beberapa kasus, pada saat yang sama, keduanya mapper dan mengurangi menyelesaikan masalah yang sama, tetapi mereka bisa sedikit berbeda. Sebuah contoh yang bagus tentang bagaimana menyebutkan solusi sederhana secara cerdas sehingga orang-orang memercayainya.
Lalu ada percakapan tentang apa yang akan saya lakukan di sini: Partisi Grafik Seimbang. Yaitu cara memotong grafik menjadi N bagian sehingga ukurannya kira-kira sama besar, dan jumlah ikatan di dalam bagian itu secara signifikan lebih besar daripada jumlah ikatan eksternal. Jika Anda dapat menyelesaikan masalah seperti itu dengan baik, maka banyak algoritma menjadi lebih mudah, dan bahkan tes A / B dapat berjalan lebih efisien, dengan kompensasi untuk efek virus. Tapi ceritanya sedikit kecewa, semuanya tampak seperti "rencana gnomish": menetapkan angka berdasarkan pengelompokan affine hierarkis, bergerak, menambah ketidakseimbangan. Tidak ada detail Tentang ini di KDD akan ada laporan terpisah dari mereka nanti, saya akan coba lanjutkan. Ditambah lagi ada
posting blog .
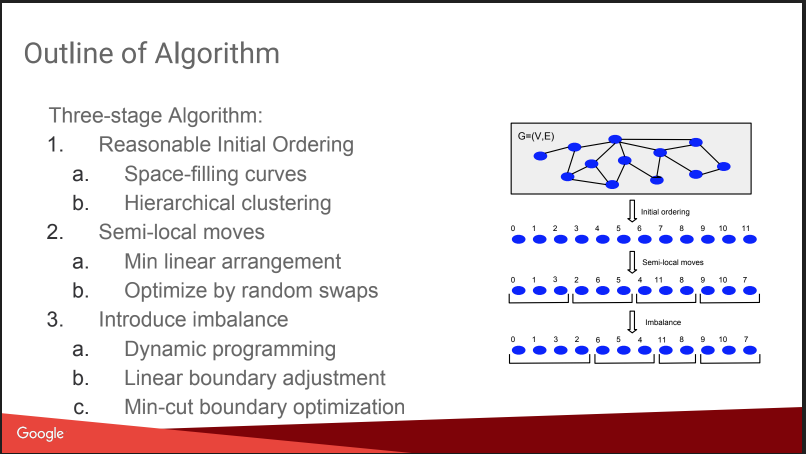
Meskipun demikian, mereka memberikan perbandingan dengan beberapa pesaing, beberapa di antaranya terbuka:
Spinner ,
UB13 dari FB,
Fennel dari Microsoft,
Metis . Anda juga bisa melihatnya.
Kemudian kami berbicara sedikit tentang detail teknis. Mereka menggunakan beberapa paradigma untuk bekerja dengan grafik:
- MapReduce di atas Flume. Saya tidak tahu bahwa itu mungkin - Flume tidak banyak ditulis di Internet untuk pengumpulan, tetapi tidak untuk menganalisis data. Saya pikir ini adalah penyimpangan intra-google. UPD: Saya tahu ini benar-benar produk internal Google, tidak ada hubungannya dengan Apache Flume, ada beberapa ersatz di cloud yang disebut dataflow
- MapReduce + Tabel Hash Terdistribusi. Mereka mengatakan bahwa itu membantu untuk secara signifikan mengurangi jumlah putaran MP, tetapi di Internet tidak banyak ditulis tentang teknik ini, misalnya, di sini
- Pregel - mereka mengatakan bahwa dia akan segera mati.
- ASYnchronous Message Passing adalah yang paling keren, tercepat, dan paling menjanjikan.
Gagasan ASYMP sangat mirip dengan Pregel:
- node didistribusikan, menjaga statusnya dan dapat mengirim pesan ke tetangga;
- antrian dibangun pada mesin dengan prioritas, apa yang harus dikirim (pesanan mungkin berbeda dari urutan penambahan);
- setelah menerima pesan, node mungkin atau mungkin tidak mengubah keadaan; ketika berubah, kami mengirim pesan ke tetangga;
- selesai ketika semua antrian kosong.
Misalnya, ketika mencari komponen yang terhubung, kami menginisialisasi semua simpul dengan bobot acak U [0,1], setelah itu kami mulai mengirim setidaknya tetangga satu sama lain. Karena itu, setelah menerima minimum dari tetangga, kami mencari minimum untuk mereka, dll., Hingga minimum distabilkan. Mereka mencatat poin penting untuk optimasi: untuk menutup pesan dari satu node (ini giliran), hanya menyisakan yang terakhir. Mereka juga berbicara tentang betapa mudahnya memulihkan dari kegagalan sembari mempertahankan status node.
Mereka mengatakan bahwa mereka membangun algoritma yang sangat cepat tanpa masalah, tampaknya benar - konsepnya sederhana dan rasional. Ada
publikasi .
Sebagai hasilnya, kesimpulannya menunjukkan dirinya: sedih untuk terus bercerita tentang teknologi tertutup, tetapi beberapa bagian yang berguna dapat diambil.