
Pada artikel ini, kita akan membangun model dasar dari jaringan saraf convolutional yang mampu melakukan
pengenalan emosi dalam gambar. Pengenalan emosi dalam kasus kami adalah tugas klasifikasi biner, yang tujuannya adalah untuk membagi gambar menjadi positif dan negatif.
Semua kode, dokumen buku catatan, dan materi lainnya, termasuk Dockerfile, dapat ditemukan di
sini .
Data
Langkah pertama dalam hampir semua tugas pembelajaran mesin adalah memahami data. Ayo lakukan.
Struktur dataset
Data mentah dapat diunduh di
sini (dalam dokumen
Baseline.ipynb , semua tindakan di bagian ini dilakukan secara otomatis). Awalnya, data ada di arsip format Zip *. Buka paketnya dan kenali struktur file yang diterima.
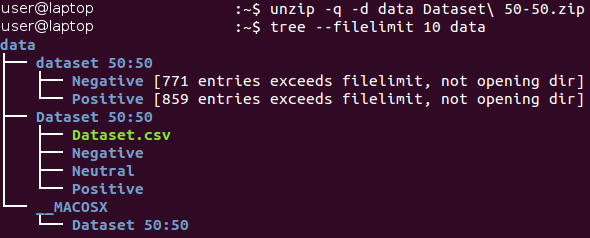
Semua gambar disimpan di dalam katalog “dataset 50:50” dan didistribusikan di antara dua subdirektori, nama yang sesuai dengan kelasnya - Negatif dan Positif. Harap perhatikan bahwa tugasnya sedikit
tidak seimbang - 53 persen gambar positif, dan hanya 47 persen negatif. Biasanya, data dalam masalah klasifikasi dianggap tidak seimbang jika jumlah contoh dalam kelas yang berbeda bervariasi sangat signifikan. Ada
beberapa cara untuk bekerja dengan data yang tidak seimbang - misalnya, oversampling, oversampling, perubahan faktor pembobotan data, dll. Dalam kasus kami, ketidakseimbangan tidak signifikan dan tidak boleh secara dramatis mempengaruhi proses pembelajaran. Hanya perlu diingat bahwa classifier naif, selalu menghasilkan nilai "positif", akan memberikan nilai akurasi sekitar 53 persen untuk kumpulan data ini.
Mari kita lihat beberapa gambar dari masing-masing kelas.
Negatif

 Positif
Positif


Pada pandangan pertama, gambar dari kelas yang berbeda sebenarnya berbeda satu sama lain. Namun, mari kita telaah lebih dalam dan coba temukan contoh buruk - gambar serupa milik kelas yang berbeda.
Sebagai contoh, kami memiliki sekitar 90 gambar ular berlabel negatif dan sekitar 40 gambar sangat mirip ular berlabel positif.
Gambar positif seekor ular Gambar negatif ular
Gambar negatif ular
Dualitas yang sama terjadi pada laba-laba (130 gambar negatif dan 20 positif), ketelanjangan (15 gambar negatif dan 45 positif), dan beberapa kelas lainnya. Orang merasa bahwa penandaan gambar dilakukan oleh orang yang berbeda, dan persepsi mereka tentang gambar yang sama mungkin berbeda. Karena itu, pelabelan mengandung inkonsistensi yang melekat. Dua gambar ular ini hampir identik, sementara para ahli yang berbeda menghubungkannya dengan kelas yang berbeda. Dengan demikian, kita dapat menyimpulkan bahwa hampir tidak mungkin untuk memastikan akurasi 100% ketika bekerja dengan tugas ini karena sifatnya. Kami percaya bahwa perkiraan akurasi yang lebih realistis adalah nilai 80 persen - nilai ini didasarkan pada proporsi gambar serupa yang ditemukan di kelas yang berbeda selama pemeriksaan visual pendahuluan.
Pemisahan proses pelatihan / verifikasi
Kami selalu berusaha untuk menciptakan model terbaik. Namun, apa arti dari konsep ini? Ada banyak kriteria berbeda untuk ini, seperti: kualitas, lead time (belajar + mendapatkan output), dan konsumsi memori. Beberapa dari mereka dapat dengan mudah dan obyektif diukur (misalnya, waktu dan ukuran memori), sementara yang lain (kualitas) jauh lebih sulit untuk ditentukan. Misalnya, model Anda dapat menunjukkan akurasi 100 persen ketika belajar dari contoh yang telah digunakan berkali-kali, tetapi gagal bekerja dengan contoh baru. Masalah ini disebut
overfitting dan merupakan salah satu yang paling penting dalam pembelajaran mesin. Ada juga masalah
kekurangan dana : dalam hal ini, model tidak dapat belajar dari data yang disajikan dan menunjukkan prediksi yang buruk bahkan ketika menggunakan kumpulan data pelatihan tetap.
Untuk mengatasi masalah overfitting, teknik yang disebut
memegang bagian dari sampel digunakan . Gagasan utamanya adalah untuk membagi data sumber menjadi dua bagian:
- Satu set pelatihan , yang biasanya membentuk sebagian besar set data dan digunakan untuk melatih model.
- Set tes biasanya merupakan bagian kecil dari data sumber, yang dibagi menjadi dua bagian sebelum melakukan semua prosedur pelatihan. Set ini tidak digunakan sama sekali dalam pelatihan dan dianggap sebagai contoh baru untuk menguji model setelah selesai pelatihan.
Dengan menggunakan metode ini, kita dapat mengamati seberapa baik
generalisasi model kita (yaitu, ia bekerja dengan contoh-contoh yang sebelumnya tidak diketahui).
Artikel ini akan menggunakan rasio 4/1 untuk pelatihan dan set tes. Teknik lain yang kami gunakan adalah apa yang disebut
stratifikasi . Istilah ini mengacu pada partisi setiap kelas secara independen dari semua kelas lainnya. Pendekatan ini memungkinkan menjaga keseimbangan yang sama antara ukuran kelas dalam pelatihan dan set tes. Stratifikasi secara implisit menggunakan asumsi bahwa distribusi contoh tidak berubah ketika sumber data berubah dan tetap sama ketika menggunakan contoh baru.
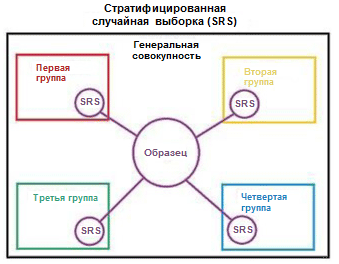
Kami menggambarkan konsep stratifikasi dengan contoh sederhana. Misalkan kita memiliki empat kelompok data / kelas dengan jumlah objek yang sesuai di dalamnya: anak-anak (5), remaja (10), dewasa (80) dan orang tua (5); lihat gambar di sebelah kanan (dari
Wikipedia ). Sekarang kita perlu memecah data ini menjadi dua set sampel dalam rasio 3/2. Ketika menggunakan stratifikasi contoh, pemilihan objek akan dilakukan secara independen dari masing-masing kelompok: 2 objek dari kelompok anak-anak, 4 objek dari kelompok remaja, 32 objek dari kelompok orang dewasa dan 2 objek dari kelompok orang tua. Set data baru berisi 40 objek, yang persis 2/5 dari data asli. Pada saat yang sama, keseimbangan antara kelas-kelas dalam dataset baru sesuai dengan keseimbangan mereka dalam data sumber.
Semua tindakan di atas diimplementasikan dalam satu fungsi, yang disebut
prep_data ; fungsi ini dapat ditemukan di file Python
utils.py . Fungsi ini memuat data, membaginya menjadi pelatihan dan set tes menggunakan nomor acak tetap (untuk pemutaran nanti), dan kemudian mendistribusikan data sesuai antara direktori pada hard drive untuk digunakan nanti.
Pretreatment dan Augmentasi
Dalam salah satu artikel sebelumnya, tindakan pra-pemrosesan dan kemungkinan alasan penggunaannya dalam bentuk augmentasi data dijelaskan. Jaringan saraf convolutional adalah model yang cukup kompleks, dan sejumlah besar data diperlukan untuk melatihnya. Dalam kasus kami, hanya ada 1.600 contoh - ini, tentu saja, tidak cukup.
Oleh karena itu, kami ingin memperluas set data yang digunakan oleh
augmentasi data. Sesuai dengan informasi yang terkandung dalam artikel tentang preprocessing data, perpustakaan Keras * menyediakan kemampuan untuk menambah data dengan cepat saat membacanya dari hard drive. Ini dapat dilakukan melalui kelas
ImageDataGenerator .
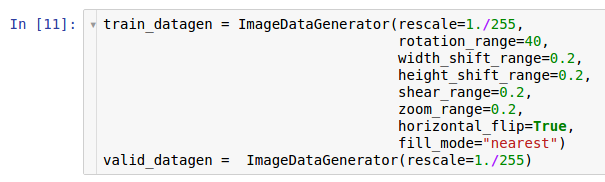
Dua contoh generator dibuat di sini. Contoh pertama adalah untuk pelatihan dan menggunakan banyak transformasi acak - seperti rotasi, shift, konvolusi, penskalaan, dan rotasi horizontal - sambil membaca data dari disk dan mentransfernya ke model. Akibatnya, model menerima contoh yang dikonversi, dan setiap contoh yang diterima oleh model adalah unik karena sifat acak konversi ini. Salinan kedua untuk verifikasi, dan hanya memperbesar gambar. Pembelajaran dan pengujian generator hanya memiliki satu transformasi umum - zooming. Untuk memastikan stabilitas komputasi model, perlu menggunakan rentang [0; 1] bukannya [0; 255].
Arsitektur model
Setelah mempelajari dan menyiapkan data awal, tahap pembuatan model mengikuti. Karena sejumlah kecil data tersedia bagi kami, kami akan membangun model yang relatif sederhana agar dapat melatihnya dengan tepat dan menghilangkan situasi overfitting. Mari kita coba
arsitektur gaya
VGG , tetapi gunakan lebih sedikit layer dan filter.
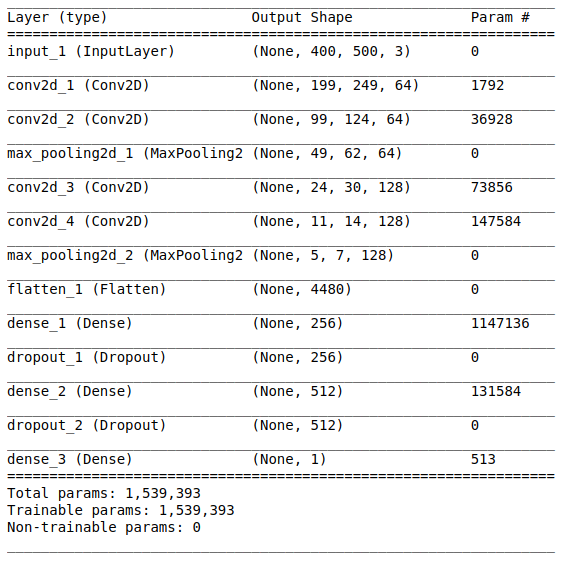

Arsitektur jaringan terdiri dari bagian-bagian berikut:
[Lapisan konvolusi + lapisan konvolusi + pemilihan nilai maksimum] × 2Bagian pertama berisi dua lapisan convolutional superimposed dengan 64 filter (dengan ukuran 3 dan langkah 2) dan lapisan untuk memilih nilai maksimum (dengan ukuran 2 dan langkah 2) yang terletak setelahnya. Bagian ini juga biasa disebut sebagai
unit ekstraksi fitur , karena filter secara efisien mengekstraksi fitur yang berarti dari data input (lihat artikel
Tinjauan Jaringan Syaraf Konvolusional untuk klasifikasi gambar untuk informasi lebih lanjut).
PerataanBagian ini wajib, karena tensor empat dimensi diperoleh pada keluaran bagian konvolusional (contoh, tinggi, lebar, dan saluran). Namun, untuk lapisan yang sepenuhnya terhubung, kita memerlukan tensor dua dimensi (contoh, fitur) sebagai input. Oleh karena itu, perlu untuk
menyelaraskan tensor di sekitar tiga sumbu terakhir untuk menggabungkannya menjadi satu sumbu. Bahkan, ini berarti bahwa kami mempertimbangkan setiap titik di setiap peta fitur sebagai properti terpisah dan menyelaraskannya ke dalam satu vektor. Gambar di bawah ini menunjukkan contoh gambar 4 × 4 dengan 128 saluran, yang disejajarkan dalam satu vektor yang diperluas dengan panjang 1024 elemen.
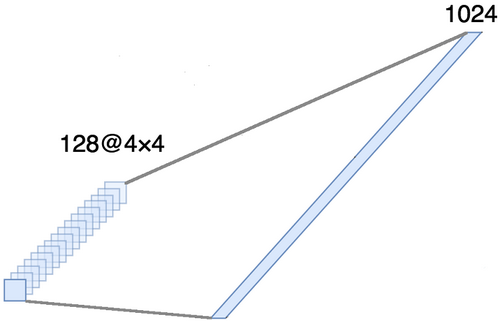 [Metode lapisan penuh + pengecualian] × 2
[Metode lapisan penuh + pengecualian] × 2Ini adalah bagian
klasifikasi dari jaringan. Dia mengambil tampilan yang selaras dari karakteristik gambar dan mencoba untuk mengklasifikasikannya dengan cara terbaik. Bagian dari jaringan ini terdiri dari dua blok yang dilapiskan yang terdiri dari lapisan yang sepenuhnya terhubung dan
metode pengecualian . Kami telah berkenalan dengan lapisan yang terhubung sepenuhnya - biasanya ini adalah lapisan dengan koneksi yang terhubung sepenuhnya. Tapi apa "metode pengecualian"? Metode eksklusi adalah
teknik regularisasi yang membantu mencegah overfitting. Salah satu tanda kemungkinan overfitting adalah nilai koefisien berat yang sangat berbeda (urutan besarnya). Ada banyak cara untuk mengatasi masalah ini, termasuk pengurangan berat badan dan metode eliminasi. Gagasan metode eliminasi adalah untuk memutus neuron acak selama pelatihan (daftar neuron yang terputus harus diperbarui setelah setiap paket / era pelatihan). Ini sangat kuat mencegah memperoleh nilai yang sama sekali berbeda untuk koefisien bobot - dengan cara ini jaringan diatur.
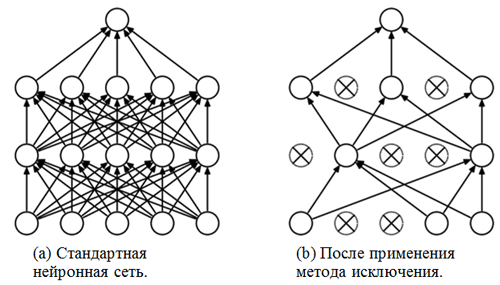
Contoh penerapan metode pengecualian (gambar diambil dari artikel
Metode pengecualian: cara mudah untuk mencegah overfitting di jaringan saraf ):
Modul SigmoidLapisan output harus sesuai dengan pernyataan masalah. Dalam kasus ini, kita berhadapan dengan masalah klasifikasi biner, oleh karena itu, kita memerlukan satu neuron keluaran dengan fungsi aktivasi
sigmoid , yang memperkirakan probabilitas P milik kelas dengan nomor 1 (dalam kasus kami, ini akan menjadi citra positif). Maka probabilitas milik kelas dengan angka 0 (gambar negatif) dapat dengan mudah dihitung sebagai 1 - P.
Opsi pengaturan dan pelatihan
Kami memilih arsitektur model dan menetapkannya menggunakan pustaka Keras untuk bahasa Python. Selain itu, sebelum memulai model pelatihan, perlu untuk
mengkompilasinya .

Pada tahap kompilasi, model disetel untuk pelatihan. Dalam hal ini, tiga parameter utama harus ditentukan:
- Pengoptimal . Dalam hal ini, kami menggunakan pengoptimal default Adam *, yang merupakan jenis algoritme penurunan gradien stokastik dengan momen dan kecepatan belajar adaptif (untuk informasi lebih lanjut lihat entri blog oleh S. Ruder Gambaran umum algoritma pengoptimalan penurunan gradien ).
- Fungsi kerugian . Tugas kita adalah masalah klasifikasi biner, jadi akan tepat untuk menggunakan entropi silang biner sebagai fungsi kerugian.
- Metrik . Ini adalah argumen opsional yang dengannya Anda dapat menentukan metrik tambahan untuk dilacak selama proses pelatihan. Dalam hal ini, kita perlu melacak akurasi bersama dengan fungsi tujuan.
Sekarang kita siap untuk melatih modelnya. Harap dicatat bahwa prosedur pelatihan dilakukan dengan menggunakan generator yang diinisialisasi pada bagian sebelumnya.
Jumlah era adalah hiperparameter lain yang dapat disesuaikan. Di sini kami hanya menetapkan nilai 10. Kami juga ingin menyimpan model dan sejarah pembelajaran agar dapat mengunduhnya nanti.

Peringkat
Sekarang mari kita lihat seberapa baik model kita bekerja. Pertama-tama, kami mempertimbangkan perubahan metrik dalam proses pembelajaran.
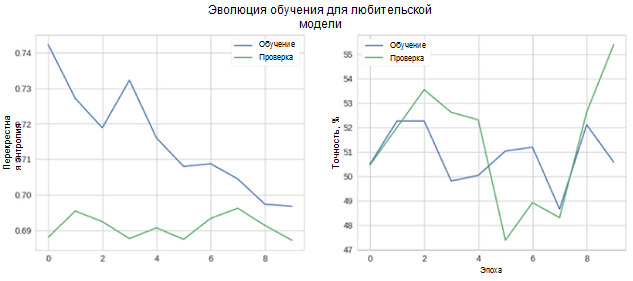
Pada gambar, Anda dapat melihat bahwa entropi verifikasi dan akurasi lintas tidak berkurang dari waktu ke waktu. Selain itu, metrik akurasi untuk pelatihan dan set tes hanya berfluktuasi di sekitar nilai classifier acak. Akurasi akhir untuk set tes adalah 55 persen, yang hanya sedikit lebih baik dari perkiraan acak.
Mari kita lihat bagaimana prediksi model didistribusikan antar kelas. Untuk tujuan ini, perlu membuat dan memvisualisasikan
matriks ketidakakuratan menggunakan fungsi yang sesuai dari paket Sklearn * untuk bahasa Python.
Setiap sel dalam matriks ketidakakuratan memiliki namanya sendiri:
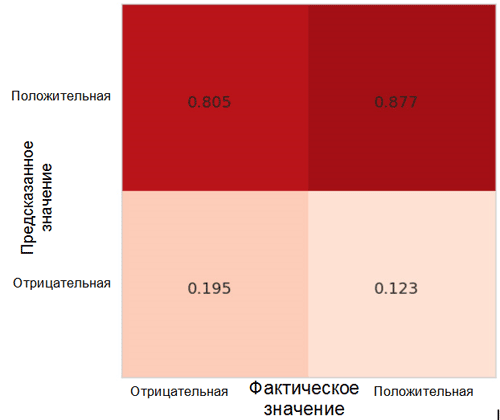
- True Positive Rate = TPR (sel kanan atas) mewakili proporsi contoh positif (kelas 1, yaitu, emosi positif dalam kasus kami), diklasifikasikan dengan benar sebagai positif.
- False Positive Rate = FPR (sel kanan bawah) mewakili proporsi contoh positif yang secara keliru diklasifikasikan sebagai negatif (kelas 0, yaitu, emosi negatif).
- True Negative Rate = TNR (sel kiri bawah) mewakili proporsi contoh negatif yang diklasifikasikan dengan benar sebagai negatif.
- False Negative Rate = FNR (sel kiri atas) mewakili proporsi contoh negatif yang salah diklasifikasikan sebagai positif.
Dalam kasus kami, baik TPR dan FPR mendekati 1. Ini berarti bahwa hampir semua objek diklasifikasikan sebagai positif. Dengan demikian, model kami tidak jauh dari model dasar naif dengan prediksi konstan dari kelas yang lebih besar (dalam kasus kami, ini adalah gambar positif).
Metrik menarik lainnya yang menarik untuk diamati adalah kurva kinerja penerima (kurva ROC) dan area di bawah kurva ini (ROC AUC). Definisi formal dari konsep-konsep ini dapat ditemukan di
sini . Singkatnya, kurva ROC menunjukkan seberapa baik classifier biner bekerja.
Pengklasifikasi dari jaringan saraf convolutional kami memiliki modul sigmoid sebagai output, yang memberikan probabilitas contoh ke kelas 1. Sekarang anggap bahwa pengklasifikasi kami menunjukkan pekerjaan yang baik dan memberikan nilai probabilitas rendah untuk contoh kelas 0 (histogram hijau pada gambar di bawah) nilai probabilitas tinggi untuk contoh Kelas 1 (histogram biru).
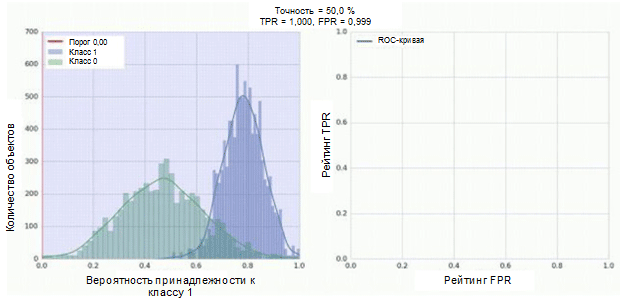
Kurva ROC menunjukkan bagaimana indikator TPR tergantung pada indikator FPR ketika memindahkan ambang klasifikasi dari 0 ke 1 (gambar kanan, bagian atas). Untuk pemahaman yang lebih baik tentang konsep ambang batas, ingatlah bahwa kita memiliki kemungkinan untuk menjadi anggota kelas 1 untuk setiap contoh. Namun, probabilitas belum merupakan label kelas. Oleh karena itu, harus dibandingkan dengan ambang batas untuk menentukan kelas mana yang dimiliki contoh. Misalnya, jika nilai ambang adalah 1, maka semua contoh harus diklasifikasikan sebagai milik kelas 0, karena nilai probabilitas tidak boleh lebih dari 1, dan nilai indikator FPR dan TPR dalam kasus ini adalah 0 (karena tidak ada sampel yang diklasifikasikan sebagai positif). ) Situasi ini sesuai dengan titik paling kiri pada kurva ROC. Di sisi lain dari kurva ada titik di mana nilai ambang adalah 0: ini berarti bahwa semua sampel diklasifikasikan sebagai milik kelas 1, dan nilai-nilai TPR dan FPR sama dengan 1. Poin-poin perantara menunjukkan perilaku ketergantungan TPR / FPR ketika nilai ambang batas berubah.
Garis diagonal pada grafik berhubungan dengan penggolong acak. Semakin baik classifier kita bekerja, semakin dekat kurva nya ke titik kiri atas grafik. Dengan demikian, indikator objektif kualitas classifier adalah area di bawah kurva ROC (indikator ROC AUC). Nilai indikator ini harus sedekat mungkin dengan 1. Nilai AUC 0,5 sesuai dengan penggolong acak.
AUC dalam model kami (lihat gambar di atas) adalah 0,57, yang jauh dari hasil terbaik.
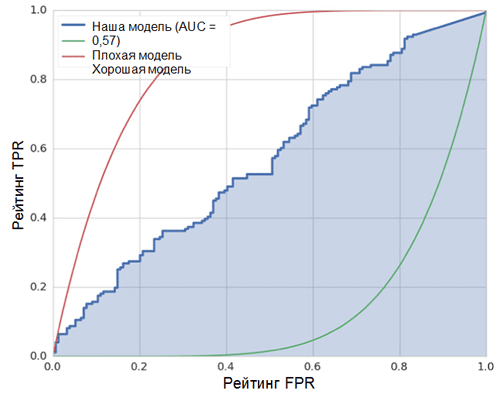
Semua metrik ini menunjukkan bahwa model yang dihasilkan hanya sedikit lebih baik daripada pengelompokan acak. Ada beberapa alasan untuk ini, yang utama dijelaskan di bawah ini:
- Jumlah data yang sangat kecil untuk pelatihan, tidak cukup untuk menyorot fitur karakteristik gambar. Bahkan augmentasi data tidak dapat membantu dalam kasus ini.
- Model jaringan saraf convolutional yang relatif kompleks (dibandingkan dengan model pembelajaran mesin lainnya) dengan sejumlah besar parameter.
Kesimpulan
Dalam artikel ini, kami membuat model jaringan saraf convolutional sederhana untuk mengenali emosi dalam gambar. Pada saat yang sama, pada tahap pelatihan, sejumlah metode digunakan untuk menambah data, dan model juga dievaluasi menggunakan seperangkat metrik seperti akurasi, kurva ROC, ROC AUC dan matriks ketidaktepatan. Model menunjukkan hasil, hanya beberapa yang terbaik acak. .