Demonstrasi penggunaan alat sumber terbuka seperti Packer dan Terraform untuk terus memberikan perubahan infrastruktur ke lingkungan cloud favorit pengguna.
Materi tersebut didasarkan pada presentasi oleh Paul Stack pada konferensi musim gugur kami
DevOops 2017. Paul adalah pengembang infrastruktur yang dulu bekerja di HashiCorp dan berpartisipasi dalam mengembangkan alat yang digunakan oleh jutaan orang (misalnya, Terraform). Dia sering berbicara di konferensi dan menyampaikan praktik dari garis depan implementasi CI / CD, prinsip-prinsip organisasi yang tepat dari bagian operasi, dan mampu menjelaskan dengan jelas mengapa administrator melakukan ini. Sisa artikel ini diriwayatkan sebagai orang pertama.
Jadi, mari kita mulai segera dengan beberapa temuan kunci.
Server yang berjalan lama menyebalkan

Saya sebelumnya bekerja di sebuah organisasi di mana kami menggunakan Windows Server 2003 pada tahun 2008, dan hari ini mereka masih dalam produksi. Dan perusahaan semacam itu tidak sendirian. Menggunakan desktop jarak jauh pada server ini, mereka menginstal perangkat lunak secara manual, mengunduh file biner dari Internet. Ini adalah ide yang sangat buruk, karena servernya tidak tipikal. Anda tidak dapat menjamin bahwa hal yang sama terjadi dalam produksi seperti di lingkungan pengembangan Anda, di lingkungan menengah, di lingkungan QA.
Infrastruktur Tidak Berubah
Pada 2013, artikel Chad Foiler muncul di blog Chad Foiler berjudul "Lempar
server Anda dan bakar kode Anda: infrastruktur yang tidak dapat diubah dan komponen yang dapat dibuang" . Ini sebagian besar adalah percakapan bahwa infrastruktur abadi adalah jalan ke depan. Kami telah menciptakan infrastruktur, dan jika kami perlu mengubahnya, kami membuat infrastruktur baru. Pendekatan ini sangat umum di cloud, karena ini cepat dan murah. Jika Anda memiliki pusat data fisik, ini sedikit rumit. Jelas, jika Anda menjalankan virtualisasi pusat data, segalanya menjadi lebih mudah. Namun, jika Anda masih menjalankan server fisik setiap kali, dibutuhkan waktu lebih lama untuk memasukkan yang baru daripada memodifikasi yang sudah ada.
Infrastruktur Sekali Pakai
Menurut programmer fungsional, "immutable" sebenarnya adalah istilah yang salah untuk fenomena ini. Karena agar benar-benar tidak dapat diubah, infrastruktur Anda memerlukan sistem file hanya baca: tidak ada file yang akan ditulis secara lokal, tidak ada yang akan dapat menggunakan SSH atau RDP, dll. Jadi, nampaknya infrastruktur itu tidak berubah.
Terminologi itu dibahas di Twitter selama enam atau bahkan delapan hari oleh beberapa orang. Pada akhirnya, mereka sepakat bahwa "infrastruktur satu kali" adalah formulasi yang lebih tepat. Ketika siklus hidup "infrastruktur satu kali" berakhir, ia dapat dengan mudah dihancurkan. Anda tidak perlu mempertahankannya.
Saya akan memberikan analogi. Sapi pertanian umumnya tidak dianggap sebagai hewan peliharaan.

Ketika Anda memiliki ternak di pertanian, Anda tidak memberi mereka nama individu. Setiap individu memiliki nomor dan tag. Begitu pula dengan server. Jika Anda masih memiliki server yang dibuat secara manual dalam produksi pada tahun 2006, mereka memiliki nama yang signifikan, misalnya, "SQL Database on Production 01". Dan mereka memiliki arti yang sangat spesifik. Dan jika salah satu server crash, neraka dimulai.
Jika salah satu hewan dalam kawanan mati, peternak hanya membeli yang baru. Ini adalah "infrastruktur satu kali."
Pengiriman terus menerus
Jadi, bagaimana Anda menggabungkan ini dengan Pengiriman Berkelanjutan?
Semua yang saya bicarakan sekarang telah ada selama beberapa waktu. Saya hanya mencoba menggabungkan ide pengembangan infrastruktur dan pengembangan perangkat lunak.
Pengembang perangkat lunak telah lama berkomitmen untuk pengiriman berkelanjutan dan integrasi berkelanjutan. Sebagai contoh, Martin Fowler menulis tentang integrasi berkelanjutan di blog-nya pada awal 2000-an. Jez Humble telah lama mempromosikan pengiriman berkelanjutan.
Jika Anda melihat lebih dekat, tidak ada yang dibuat khusus untuk kode sumber perangkat lunak. Ada definisi standar dari Wikipedia:
pengiriman berkelanjutan adalah serangkaian praktik dan prinsip yang bertujuan untuk membuat, menguji, dan merilis perangkat lunak secepat mungkin .
Definisi ini tidak berarti aplikasi web atau API, ini tentang perangkat lunak secara umum. Membuat perangkat lunak teka-teki membutuhkan banyak potongan puzzle. Dengan cara ini Anda dapat mempraktikkan pengiriman berkelanjutan untuk kode infrastruktur dengan cara yang sama.
Pengembangan infrastruktur dan aplikasi adalah arah yang cukup dekat. Dan orang yang menulis kode aplikasi juga menulis kode infrastruktur (dan sebaliknya). Dunia-dunia ini mulai bersatu. Tidak ada lagi pemisahan dan perangkap khusus dari masing-masing dunia.
Prinsip dan Praktik Pengiriman Berkelanjutan
Pengiriman berkelanjutan memiliki sejumlah prinsip:
- Proses rilis / penyebaran perangkat lunak harus dapat diulang dan dapat diandalkan.
- Otomatiskan semuanya!
- Jika suatu prosedur sulit atau menyakitkan, lakukan lebih sering.
- Simpan semuanya di kontrol sumber.
- Selesai - berarti "belum dirilis".
- Padukan pekerjaan dengan kualitas!
- Setiap orang bertanggung jawab untuk proses rilis.
- Tingkatkan kontinuitas.
Tetapi yang lebih penting, pengiriman berkelanjutan memiliki empat praktik. Bawa mereka dan transfer langsung ke infrastruktur:
- Buat file biner hanya sekali. Bangun server Anda sekali. Di sini kita berbicara tentang "disposability" dari awal.
- Gunakan mekanisme penyebaran yang sama di setiap lingkungan. Jangan mempraktikkan penyebaran yang berbeda dalam pengembangan dan produksi. Anda harus menggunakan jalur yang sama di setiap lingkungan. Ini sangat penting.
- Uji penyebaran Anda. Saya telah membuat banyak aplikasi. Saya menciptakan banyak masalah karena saya tidak mengikuti mekanisme penyebaran. Anda harus selalu memeriksa apa yang terjadi. Dan saya tidak mengatakan bahwa Anda harus menghabiskan lima atau enam jam untuk pengujian skala besar. Cukup "tes asap". Anda memiliki bagian penting dari sistem, yang, seperti Anda ketahui, memungkinkan Anda dan perusahaan Anda menghasilkan uang. Jangan terlalu malas untuk memulai pengujian. Jika tidak, mungkin ada gangguan yang akan membebani perusahaan Anda.
- Dan akhirnya, hal yang paling penting. Jika ada yang rusak, segera hentikan dan perbaiki! Anda tidak bisa membiarkan masalah tumbuh dan menjadi semakin buruk. Anda harus memperbaikinya. Ini sangat penting.
Adakah yang membaca buku
Pengiriman berkelanjutan ?

Saya yakin perusahaan Anda akan membayar Anda salinan yang dapat Anda transfer dalam tim. Saya tidak mengatakan bahwa Anda harus duduk dan menghabiskan hari libur membacanya. Jika ya, Anda mungkin ingin keluar dari IT. Tetapi saya merekomendasikan untuk secara berkala menguasai bagian-bagian kecil dari buku ini, mencernanya dan memikirkan cara memindahkannya ke lingkungan Anda, ke budaya Anda dan ke proses Anda. Sepotong kecil sekaligus. Karena pasokan berkelanjutan adalah percakapan tentang peningkatan berkelanjutan. Tidak mudah untuk duduk di kantor bersama kolega dan bos dan memulai percakapan dengan pertanyaan: "Bagaimana kita akan menerapkan pengiriman berkelanjutan?", Kemudian tulis 10 hal di papan tulis dan setelah 10 hari pahami bahwa Anda menerapkannya. Ini membutuhkan banyak waktu, menyebabkan banyak protes, karena dengan diperkenalkannya perubahan budaya.
Hari ini kita akan menggunakan dua alat: Terraform dan Packer (keduanya adalah pengembangan Hashicorp). Diskusi lebih lanjut akan tentang mengapa kita harus menggunakan Terraform dan bagaimana mengintegrasikannya ke lingkungan kita. Bukan kebetulan saya berbicara tentang dua alat ini. Sampai baru-baru ini, saya juga bekerja di Hashicorp. Tetapi bahkan setelah saya meninggalkan Hashicorp, saya masih berkontribusi pada kode alat-alat ini, karena saya benar-benar merasa sangat berguna.
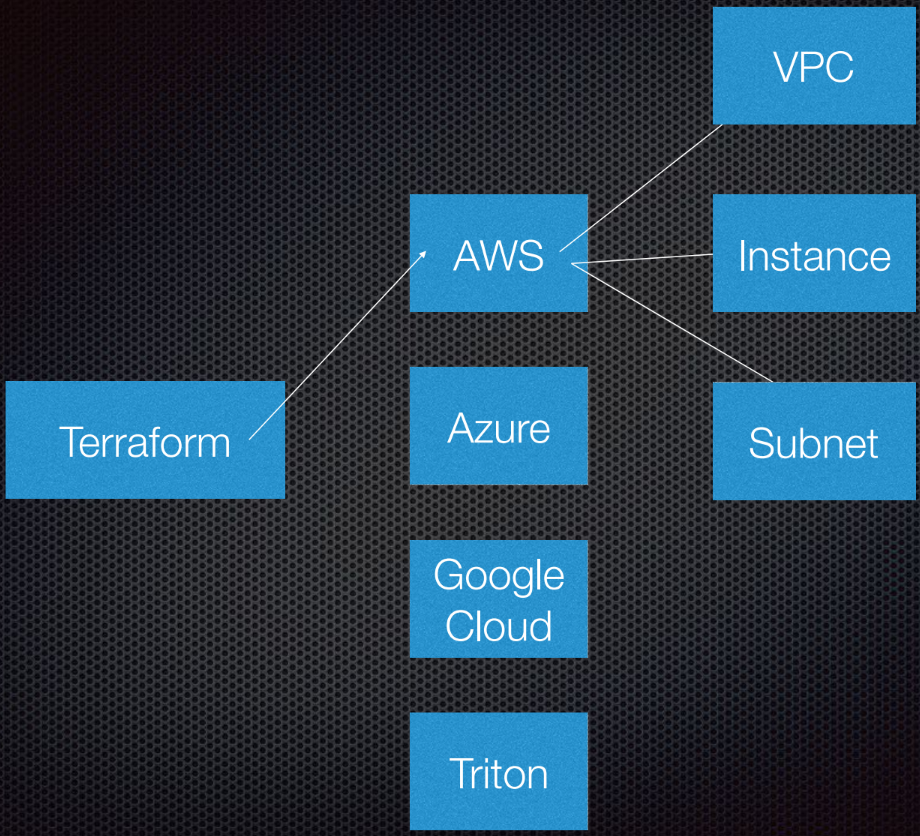
Terraform mendukung interaksi dengan penyedia. Penyedia adalah cloud, layanan Saas, dll.
Di dalam setiap penyedia layanan cloud, ada beberapa sumber daya, seperti subnet, VPC, load balancer, dll. Menggunakan DSL (bahasa khusus domain), Anda memberi tahu Terraform seperti apa infrastruktur Anda nantinya.
Terraform menggunakan teori grafik.

Anda mungkin tahu teori grafik. Node adalah bagian dari infrastruktur kami, seperti load balancer, subnet, atau VPC. Iga adalah hubungan antara sistem ini. Ini semua yang saya pribadi anggap perlu diketahui tentang teori grafik untuk menggunakan Terraform. Kami serahkan sisanya pada ahlinya.

Terraform sebenarnya menggunakan grafik terarah karena ia tahu tidak hanya hubungan, tetapi juga urutannya: bahwa A (misalkan A adalah VPC) harus disetel ke B, yang merupakan subnet. Dan B harus dibuat sebelum C (instance), karena ada prosedur yang ditentukan untuk membuat abstraksi di Amazon atau cloud lainnya.
Informasi lebih lanjut tentang topik ini tersedia di
YouTube oleh Paul Hinze, yang masih menjadi Direktur Infrastruktur di Hashicorp. Dengan referensi - percakapan yang hebat tentang infrastruktur dan teori grafik.
Berlatih
Menulis kode jauh lebih baik daripada mendiskusikan teori.
Saya sebelumnya membuat AMI (Gambar Mesin Amazon). Saya menggunakan Packer untuk membuatnya dan akan menunjukkan kepada Anda bagaimana melakukannya.
AMI adalah turunan dari server virtual di Amazon, sudah ditentukan sebelumnya (dalam hal konfigurasi, aplikasi, dll.) Dan dibuat dari gambar. Saya suka bahwa saya dapat membuat AMI baru. Pada dasarnya, AMI adalah wadah Docker saya.
Jadi, saya punya AMI, mereka punya ID. Pergi ke antarmuka Amazon, kami melihat bahwa kami hanya memiliki satu AMI dan tidak lebih:

Saya bisa menunjukkan kepada Anda apa yang ada dalam AMI ini. Semuanya sangat sederhana.
Saya memiliki templat file JSON:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] }
Kami memiliki variabel yang kami lewati, dan Packer memiliki daftar yang disebut Builder untuk area yang berbeda; ada banyak dari mereka. Builder menggunakan sumber AMI khusus, yang saya berikan dalam pengenal AMI. Saya memberinya nama pengguna dan kata sandi SSH, dan juga menunjukkan apakah ia memerlukan alamat IP publik sehingga orang dapat mengaksesnya dari luar. Dalam kasus kami, ini tidak terlalu penting, karena ini adalah contoh AWS untuk Packer.
Kami juga menetapkan nama dan tag AMI.
Anda tidak perlu menguraikan kode ini. Dia di sini hanya untuk menunjukkan kepada Anda bagaimana dia bekerja. Bagian terpenting di sini adalah versinya. Ini akan menjadi relevan nanti ketika kita memasuki Terraform.
Setelah builder memanggil instance, agen provisi diluncurkan di atasnya. Saya sebenarnya menginstal NCP dan nginx untuk menunjukkan kepada Anda apa yang dapat saya lakukan di sini. Saya menyalin beberapa file dan hanya mengatur konfigurasi nginx. Semuanya sangat sederhana. Lalu saya aktifkan nginx sehingga dimulai saat instance dimulai.
Jadi, saya punya server aplikasi dan berfungsi. Saya bisa menggunakannya di masa depan. Namun, saya selalu memeriksa templat Packer saya. Karena ini adalah konfigurasi JSON di mana Anda mungkin mengalami beberapa masalah.
Untuk melakukan ini, saya menjalankan perintah:
make validate
Saya mendapatkan jawaban bahwa templat Packer berhasil diverifikasi:
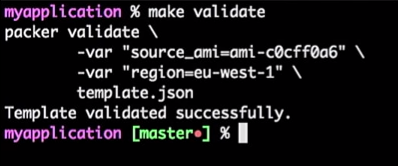
Ini hanya sebuah perintah, jadi saya bisa menghubungkannya ke alat CI (siapa pun). Bahkan, itu akan menjadi proses: jika pengembang mengubah templat, permintaan tarikan dihasilkan, alat CI akan memeriksa permintaan, melakukan yang setara dengan memeriksa templat dan menerbitkan templat jika berhasil verifikasi. Semua ini dapat digabungkan dalam "Master".
Kami mendapatkan aliran untuk template AMI - Anda hanya perlu meningkatkan versinya.
Misalkan pengembang telah membuat versi baru AMI.
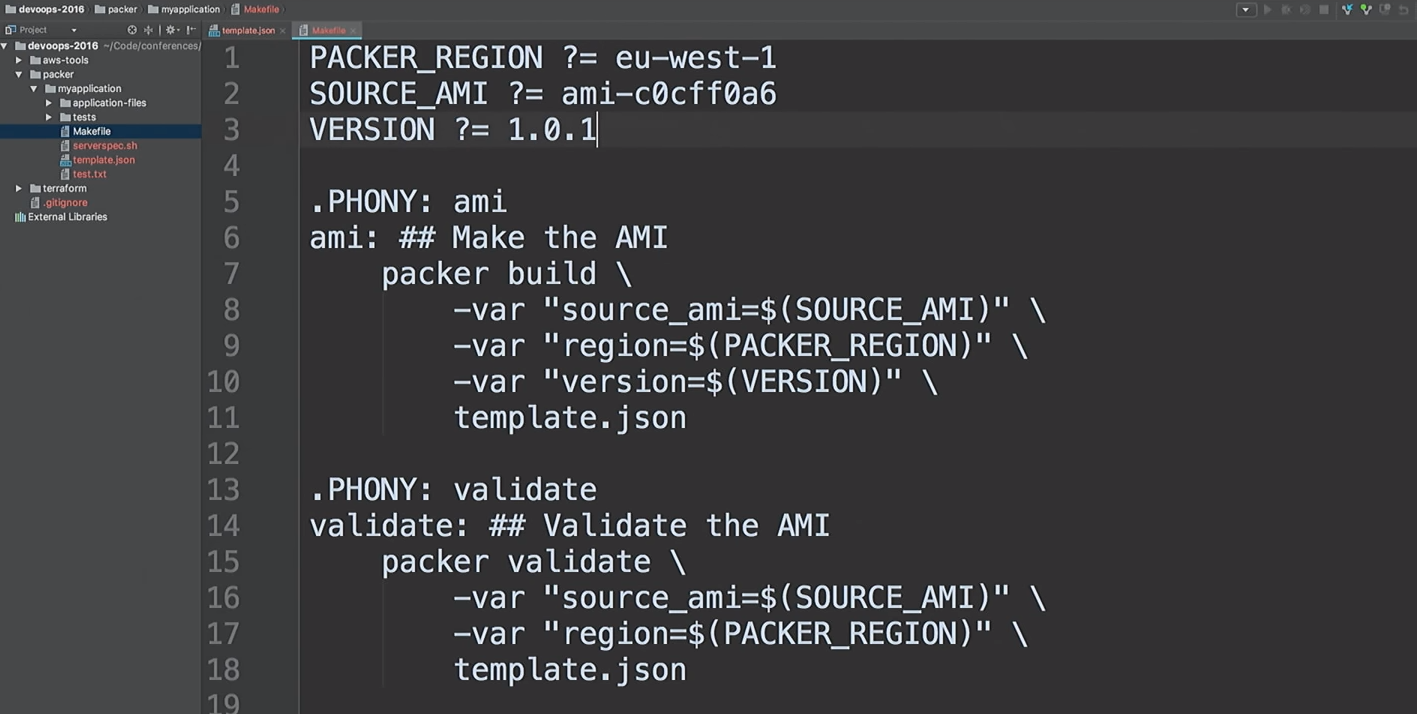
Saya hanya akan memperbaiki versi dalam file dari 1.0.0 ke 1.0.1 untuk menunjukkan kepada Anda perbedaan:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html>
Saya akan kembali ke baris perintah dan memulai pembuatan AMI.
Saya tidak suka menjalankan tim yang sama. Saya suka membuat AMI dengan cepat, jadi saya menggunakan makefiles. Mari kita lihat bersama
cat di makefile saya:
cat Makefile

Ini makefile saya. Saya bahkan memberikan Bantuan: Saya mengetik
make dan klik tab, dan itu menunjukkan kepada saya semua target.

Jadi, kita akan membuat versi AMI baru 1.0.1.
make ami

Kembali ke Terraform.
Saya menekankan bahwa ini bukan kode produksi. Ini sebuah demonstrasi. Ada cara untuk melakukan hal yang sama dengan lebih baik.
Saya menggunakan modul Terraform di mana-mana. Karena saya tidak lagi bekerja di Hashicorp, jadi saya bisa mengutarakan pendapat saya tentang modul. Bagi saya, modul berada pada level enkapsulasi. Misalnya, saya ingin merangkum semua yang berhubungan dengan VPC: jaringan, subnet, tabel perutean, dll.
Apa yang sedang terjadi di dalam? Pengembang yang bekerja dengan ini mungkin tidak peduli. Mereka perlu memiliki pemahaman dasar tentang bagaimana cloud bekerja, apa itu VPC. Tetapi tidak perlu mempelajari detailnya. Hanya orang yang benar-benar perlu mengganti modul yang harus memahaminya.
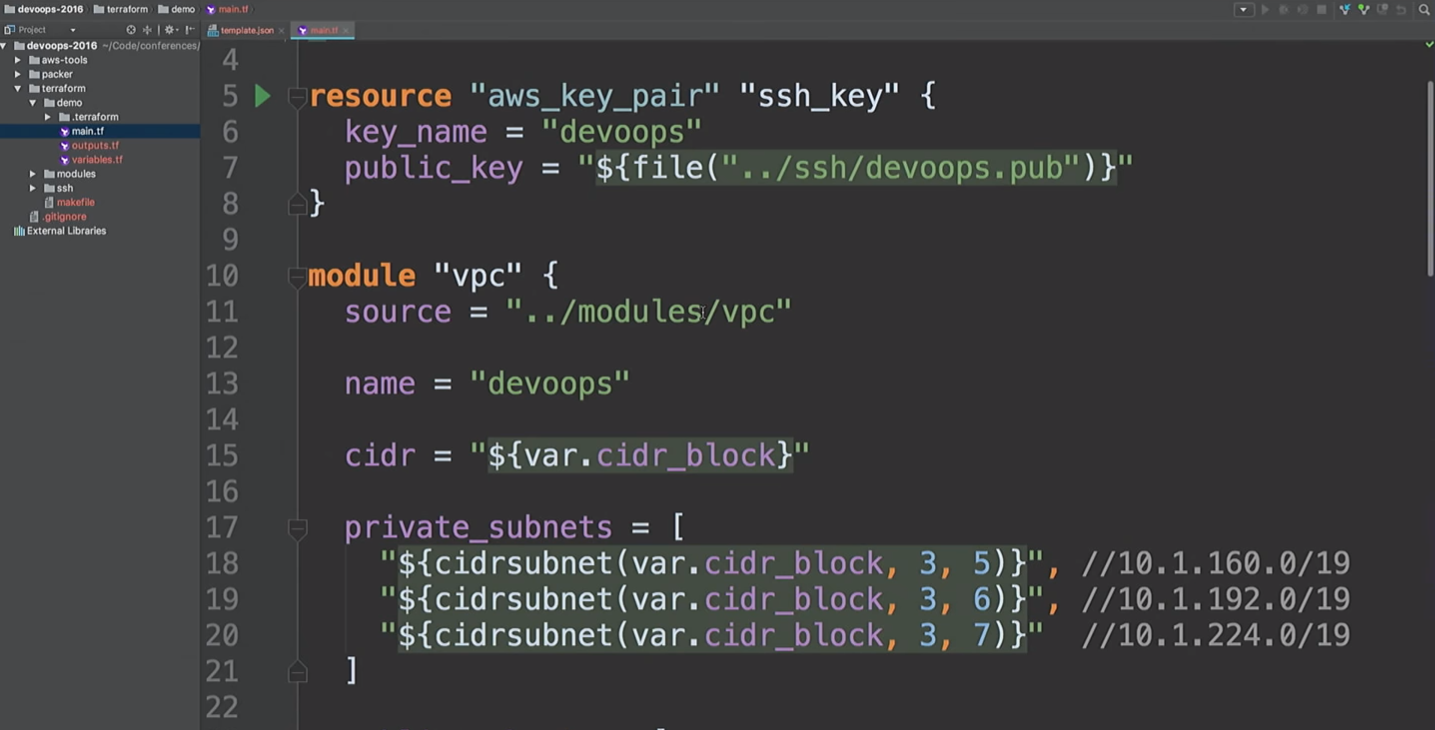

Di sini saya akan membuat sumber daya AWS dan modul VPC. Apa yang sedang terjadi di sini? Ambil
cidr_block tingkat
cidr_block dan buat tiga subnet pribadi dan tiga subnet publik. Berikut ini adalah daftar acilities_zones. Tetapi kita tidak tahu apa zona aksesibilitas ini.

Kami akan membuat VPN. Hanya saja, jangan gunakan modul VPN ini. Ini adalah openVPN, yang membuat satu instance AWS yang tidak memiliki sertifikat. Hanya menggunakan alamat IP publik dan disebutkan di sini hanya untuk menunjukkan kepada Anda bahwa kami dapat terhubung ke VPN. Ada alat yang lebih nyaman untuk membuat VPN. Butuh waktu sekitar 20 menit dan dua bir untuk menulis sendiri.
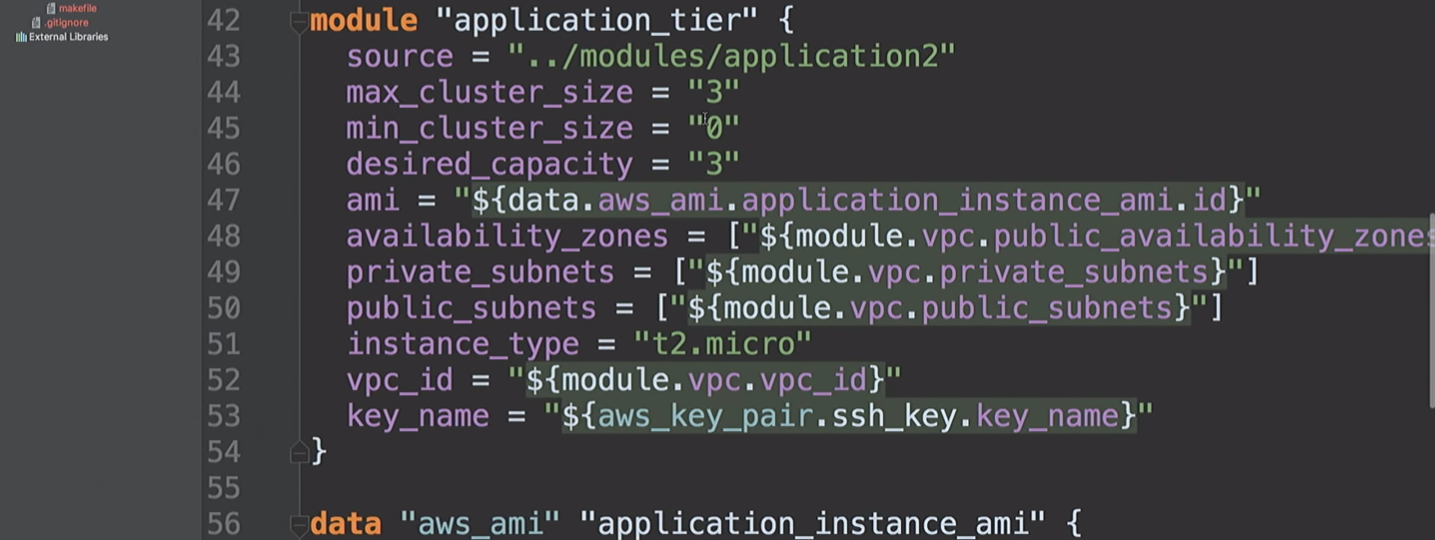


Lalu kami membuat
application_tier , yang merupakan grup penskalaan otomatis - penyeimbang beban. Beberapa konfigurasi startup didasarkan pada AMI-ID, dan menggabungkan beberapa subnet dan zona ketersediaan, dan juga menggunakan kunci SSH.
Mari kita kembali ke ini sebentar lagi.
Saya sudah menyebutkan zona ketersediaan. Mereka berbeda untuk akun AWS yang berbeda. Akun saya di AS di Timur mungkin memiliki akses ke zona A, B, dan D. Akun AWS Anda mungkin memiliki akses ke B, C dan E. Jadi, dengan memperbaiki nilai-nilai ini dalam kode, kami akan menghadapi masalah. Kami di Hashicorp menyarankan agar kami dapat membuat sumber data sedemikian sehingga kami dapat bertanya kepada Amazon apa yang tersedia bagi kami. Di bawah tenda, kami meminta deskripsi tentang zona ketersediaan, dan kemudian mengembalikan daftar semua zona untuk akun Anda. Berkat ini, kami dapat menggunakan sumber data untuk AMI.
Sekarang kita sampai ke bagian bawah demonstrasi saya. Saya membuat grup penskalaan otomatis yang menjalankan tiga instance. Secara default, mereka semua memiliki versi 1.0.0.
Ketika kami menggunakan versi baru AMI, saya akan memulai konfigurasi Terraform lagi, ini akan mengubah konfigurasi peluncuran, dan layanan baru akan menerima versi kode berikutnya, dll. Dan kita bisa mengendalikannya.

Kami melihat bahwa Packer selesai dan kami memiliki AMI baru.
Saya kembali ke Amazon, menyegarkan halaman dan melihat AMI kedua.

Kembali ke Terraform.
Dimulai dengan versi 0.10, Terraform telah membagi penyedia menjadi repositori terpisah. Dan perintah
init terraform mendapatkan salinan dari penyedia yang diperlukan untuk dijalankan.

Penyedia dimuat. Kami siap bergerak maju.
Selanjutnya kita harus menjalankan
terraform get - load modul yang diperlukan. Mereka sekarang di mesin lokal saya. Jadi Terraform akan mendapatkan semua modul secara lokal. Secara umum, modul dapat disimpan di repositori mereka sendiri di GitHub atau di tempat lain. Itu sebabnya saya berbicara tentang modul VPC. Anda dapat memberi akses tim jaringan untuk membuat perubahan. Dan ini adalah API untuk tim pengembangan untuk bekerja dengannya. Sangat membantu.
Langkah selanjutnya adalah membuat grafik.
Mulai dengan
terraform plan

Terraform akan mengambil status lokal saat ini dan membandingkannya dengan akun AWS, yang menunjukkan perbedaan. Dalam kasus kami, dia akan menciptakan 35 sumber daya baru.
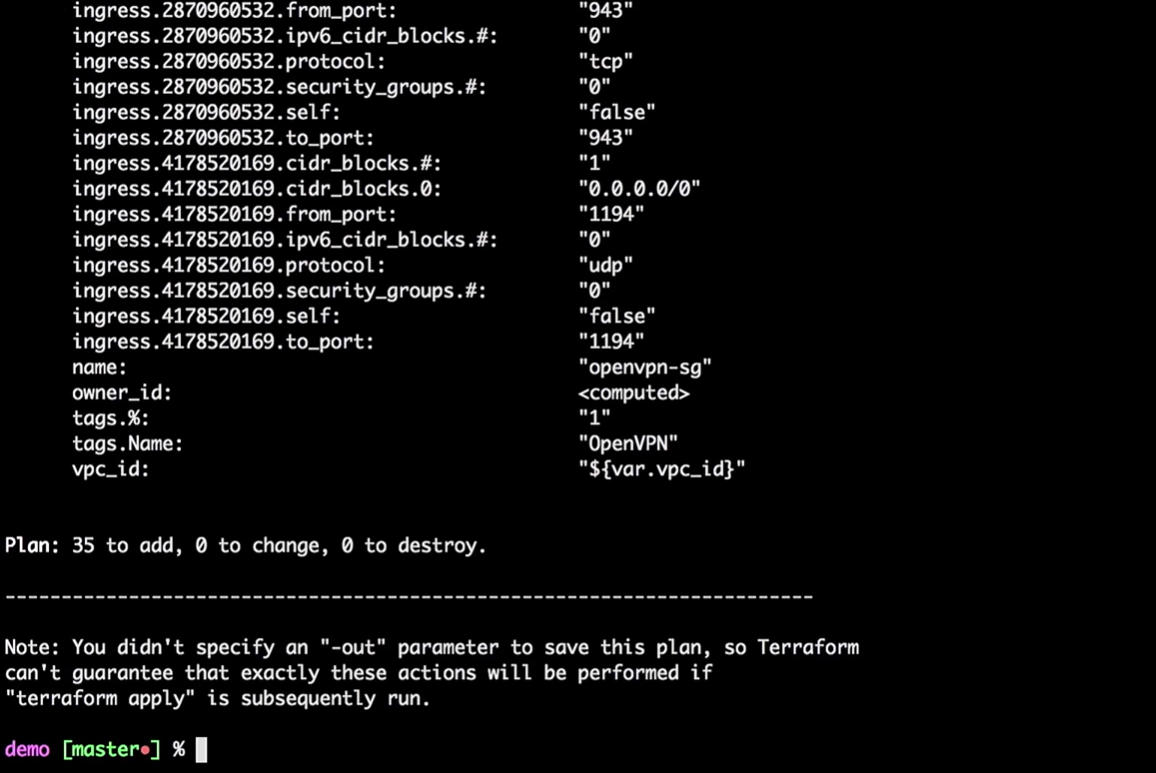
Sekarang kami menerapkan perubahan:
terraform apply
Anda tidak harus melakukan semua ini dari mesin lokal. Ini hanya perintah, meneruskan variabel ke Terraform. Anda dapat mengirimkan proses ini ke alat CI.
Jika Anda ingin memindahkan ini ke CI, Anda harus menggunakan kondisi jarak jauh. Saya ingin semua orang yang pernah menggunakan Terraform bekerja dengan negara terpencil. Tolong jangan gunakan negara bagian.
Salah satu teman saya mencatat bahwa bahkan setelah bertahun-tahun bekerja dengan Terraform, dia masih menemukan sesuatu yang baru. Misalnya, jika Anda membuat instance AWS, Anda harus memberikannya dengan kata sandi, dan itu dapat menyimpannya di negara Anda. Ketika saya bekerja di Hashicorp, kami berasumsi bahwa akan ada proses kolaboratif yang mengubah kata sandi ini. Karena itu, jangan mencoba menyimpan semuanya secara lokal. Dan kemudian Anda bisa memasukkan semua ini ke dalam alat CI.
Jadi, infrastruktur dibuat untuk saya.

Terraform dapat membuat grafik:
terraform graph
Seperti yang saya katakan, dia sedang membangun pohon. Bahkan, ini memberi Anda kesempatan untuk mengevaluasi apa yang terjadi di infrastruktur Anda. Dia akan menunjukkan kepada Anda hubungan antara semua bagian yang berbeda - semua simpul dan tepi. Karena koneksi memiliki arah, kita berbicara tentang grafik yang diarahkan.
Grafik akan menjadi daftar JSON yang dapat disimpan dalam file PNG atau DOC.
Kembali ke Terraform. Kami benar-benar membuat grup penskalaan otomatis.

Grup penskalaan otomatis memiliki kapasitas 3.

Pertanyaan yang menarik: dapatkah kita menggunakan Vault untuk mengelola rahasia di Terraform? Sayangnya, tidak. Tidak ada sumber data Vault untuk membaca rahasia di Terraform. Ada cara lain, seperti variabel lingkungan. Dengan bantuan mereka, Anda tidak perlu memasukkan rahasia ke dalam kode, Anda dapat membacanya sebagai variabel lingkungan.
Jadi, kami memiliki beberapa fasilitas infrastruktur:
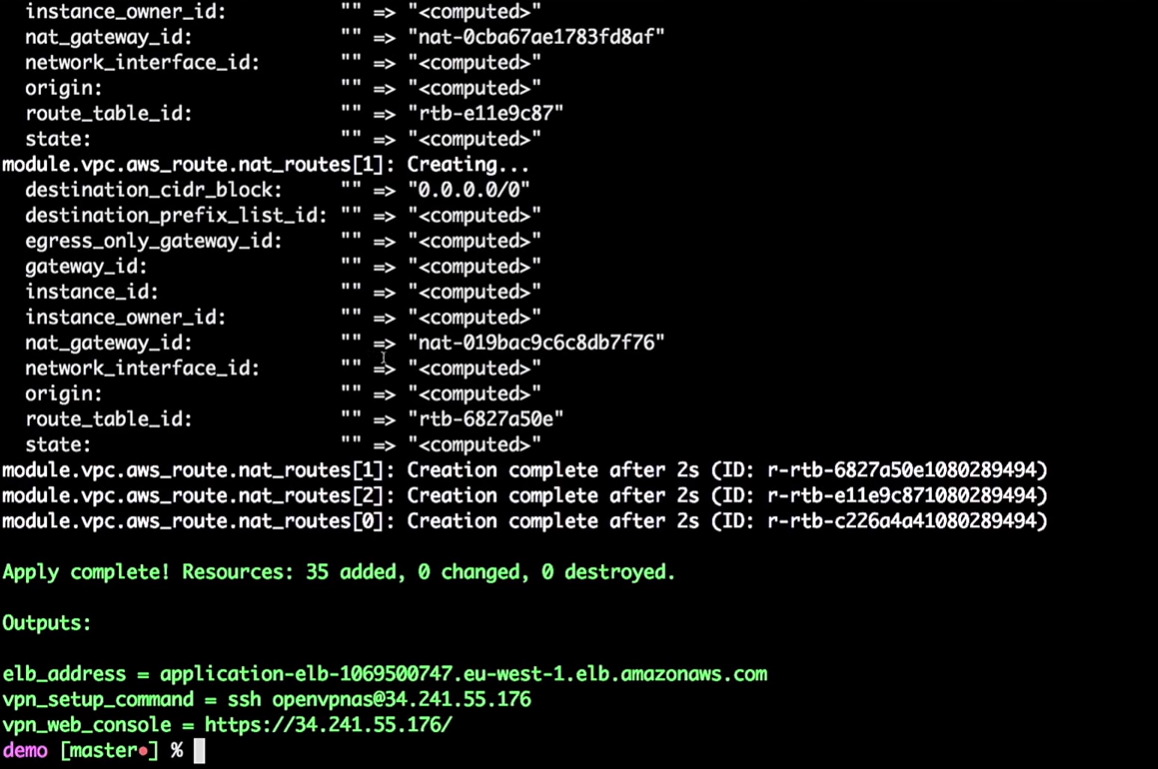
Saya memasukkan VPN sangat rahasia saya (jangan buka VPN saya).
Yang paling penting di sini adalah bahwa kita memiliki tiga contoh aplikasi. Benar, saya seharusnya mencatat versi aplikasi mana yang berjalan pada mereka. Ini sangat penting.
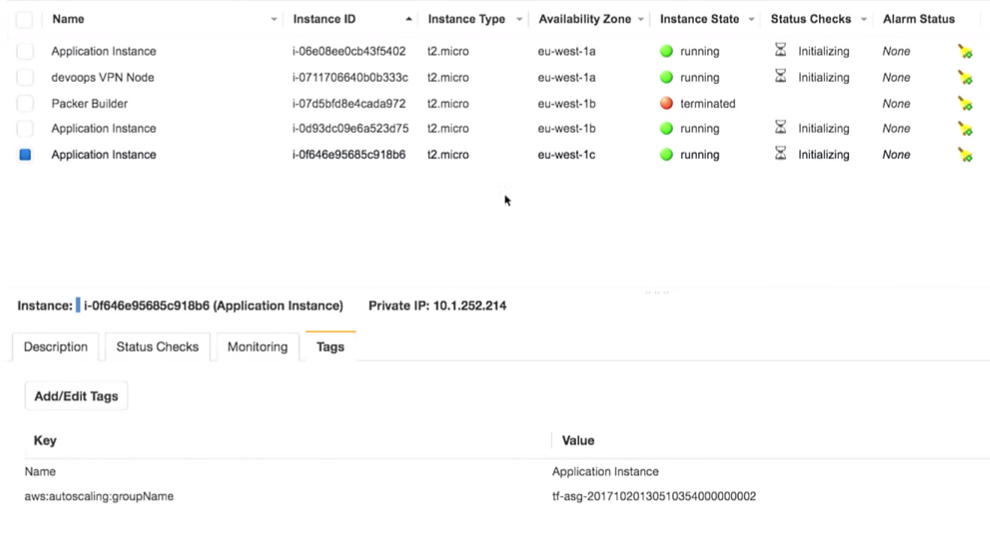
Semuanya benar-benar ada di belakang VPN:

Jika saya mengambil ini (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) dan menempelkannya ke bilah alamat browser, saya mendapatkan yang berikut ini:

Biarkan saya mengingatkan Anda bahwa saya terhubung ke VPN. Jika saya keluar, alamat yang ditentukan tidak akan tersedia.
Kami melihat versi 1.0.0. Dan tidak peduli berapa banyak kita menyegarkan halaman, kita mendapatkan 1.0.0.
Apa yang terjadi jika saya mengubah versi dari 1.0.0 ke 1.0.1 dalam kode?
filter { name = "tag:Version" values = ["1.0.1"] }
Jelas, alat CI akan memastikan Anda membuat versi yang tepat.
Saya perhatikan tidak ada pembaruan manual! Kami tidak sempurna, kami membuat kesalahan, dan kami dapat menempatkan versi 1.0.6 bukannya 1.0.1 saat memperbarui secara manual.
filter { name = "tag:Version" values = ["1.0.6"] }
Tapi mari kita beralih ke versi kita (1.0.1).
terraform plan
Status pembaruan Terraform:
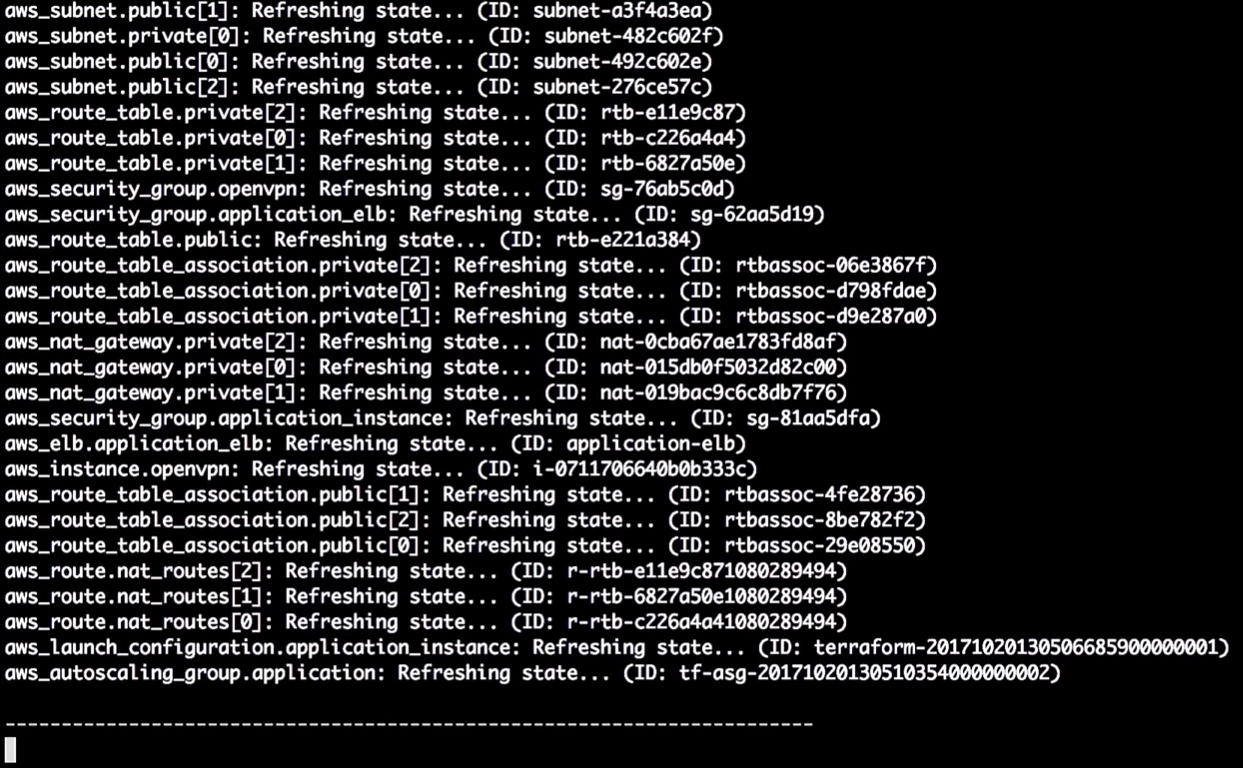

Jadi, pada saat ini dia mengatakan kepada saya bahwa dia akan mengubah versi dalam konfigurasi peluncuran. Karena perubahan pada pengenal, itu akan memaksa restart konfigurasi, dan grup penskalaan otomatis akan berubah (ini diperlukan untuk mengaktifkan konfigurasi peluncuran baru).
Ini tidak mengubah instance yang berjalan. Ini sangat penting. Anda dapat mengikuti proses ini dan mengujinya tanpa mengubah instance dalam produksi.
Catatan: Anda harus selalu membuat konfigurasi peluncuran baru sebelum menghancurkan yang lama, jika tidak akan ada kesalahan.
Mari kita terapkan perubahannya:
terraform apply
Sekarang kembali ke AWS. Ketika semua perubahan diterapkan, kami pergi ke grup penskalaan otomatis.
Mari kita beralih ke konfigurasi AWS. Kami melihat bahwa ada tiga contoh dengan satu konfigurasi peluncuran. Mereka sama.
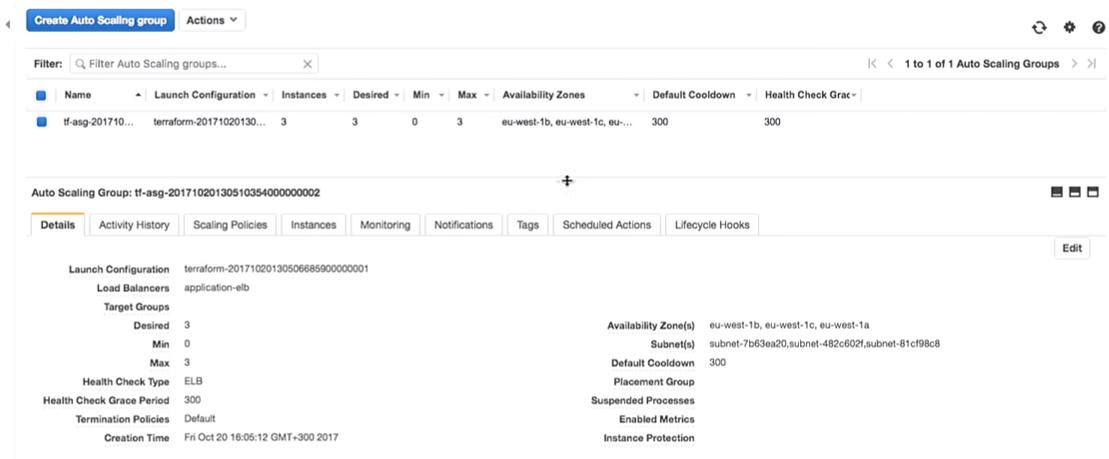
Amazon menjamin bahwa jika kita ingin menjalankan tiga contoh layanan, mereka memang akan diluncurkan. Itu sebabnya kami membayar mereka uang.
Mari kita beralih ke eksperimen.
Konfigurasi peluncuran baru telah dibuat. Karena itu, jika saya menghapus salah satu instance, sisanya tidak akan rusak. Ini penting. Namun, jika Anda menggunakan instance secara langsung, saat mengubah data pengguna, ini akan menghancurkan instance "live". Tolong jangan lakukan ini.
Jadi, hapus salah satu contoh:

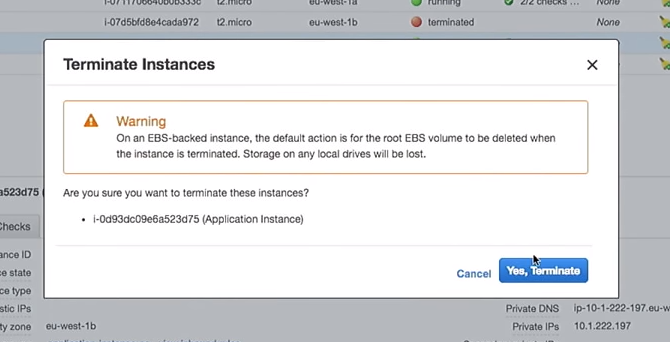
Apa yang akan terjadi pada grup penskalaan otomatis ketika dimatikan? Sebuah instance baru akan muncul di tempatnya.
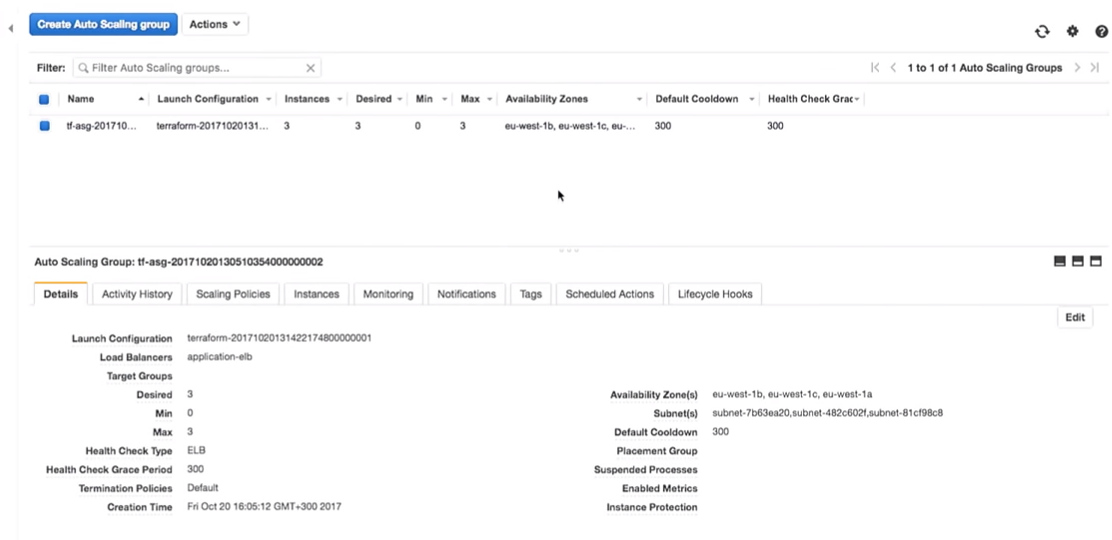
Di sini Anda menemukan diri Anda dalam situasi yang menarik. Mesin virtual akan diluncurkan dengan konfigurasi baru. Artinya, dalam sistem Anda mungkin memiliki beberapa gambar yang berbeda (dengan konfigurasi yang berbeda). Terkadang lebih baik untuk tidak segera menghapus konfigurasi startup yang lama agar dapat terhubung sesuai kebutuhan.
Di sini semuanya menjadi lebih menarik. Mengapa tidak melakukannya dengan skrip dan alat CI, dan tidak secara manual, seperti yang saya tunjukkan? Ada beberapa alat yang bisa melakukan ini, seperti alat AWS yang hilang di GitHub.

Dan apa yang dilakukan alat ini? Ini adalah skrip bash yang menelusuri semua instance dalam load balancer, menghancurkannya satu per satu, memastikan penciptaan yang baru di tempatnya.
Jika saya kehilangan salah satu instance saya dengan versi 1.0.0 dan yang baru muncul - 1.1.1, saya ingin membunuh semua 1.0.0, mentransfer semuanya ke versi baru. Karena saya selalu bergerak maju. Biarkan saya mengingatkan Anda, saya tidak suka ketika server aplikasi hidup untuk waktu yang lama.
Dalam salah satu proyek, setiap tujuh hari, saya memiliki skrip kontrol yang menghancurkan semua instance di akun saya. Jadi server itu tidak lebih dari tujuh hari. Hal lain (favorit saya) adalah menandai server sebagai "ternoda" menggunakan SSH dalam kotak dan menghancurkannya setiap jam menggunakan skrip - kami tidak ingin orang melakukannya secara manual.
Skrip kontrol semacam itu memungkinkan Anda untuk selalu memiliki versi terbaru dengan bug tetap dan pembaruan keamanan.
Anda dapat menggunakan skrip hanya dengan menjalankan:
aws-ha-relesae.sh -a my-scaling-group
-a adalah grup penskalaan otomatis Anda. Script akan melalui semua contoh grup penskalaan otomatis Anda dan menggantinya. Anda dapat menjalankannya tidak hanya secara manual, tetapi juga dari alat CI.
Anda dapat melakukan ini dalam QA atau dalam produksi. Anda dapat melakukan ini bahkan di akun AWS lokal Anda. Anda melakukan apa pun yang Anda inginkan, setiap kali menggunakan mekanisme yang sama.
Kembali ke Amazon. Kami memiliki contoh baru:

Setelah memperbarui halaman di browser, tempat kami sebelumnya melihat versi 1.0.0, kami mendapatkan:

Hal yang menarik adalah bahwa sejak kami membuat skrip pembuatan AMI, kami dapat menguji pembuatan AMI.
Ada beberapa alat hebat, seperti ServerScript atau Serverspec.
Serverspec memungkinkan Anda membuat spesifikasi bergaya-Ruby untuk menguji bagaimana server aplikasi Anda terlihat. Sebagai contoh, di bawah ini saya memberikan tes yang memeriksa apakah nginx diinstal pada server.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end
Nginx harus diinstal dan dijalankan pada server dan mendengarkan pada port 80. Anda dapat mengatakan bahwa pengguna X harus tersedia di server. Dan Anda dapat menempatkan semua tes ini di tempatnya. Jadi, ketika Anda membuat AMI, alat CI dapat memeriksa apakah AMI ini cocok untuk tujuan tertentu. Anda akan tahu bahwa AMI siap untuk diproduksi.
Alih-alih sebuah kesimpulan
Mary Poppendieck mungkin adalah salah satu wanita paling menakjubkan yang pernah saya dengar. Pada suatu waktu, dia berbicara tentang bagaimana pengembangan perangkat lunak lean telah berkembang selama bertahun-tahun. Dan bagaimana ia dikaitkan dengan 3M di tahun 60-an, ketika perusahaan benar-benar terlibat dalam pengembangan lean.
Dan dia mengajukan pertanyaan: berapa lama bagi organisasi Anda untuk menyebarkan perubahan yang terkait dengan satu baris kode? Bisakah Anda membuat proses ini andal dan berulang?
Biasanya, pertanyaan ini selalu menyangkut kode perangkat lunak. Berapa lama saya akan memperbaiki satu kesalahan dalam aplikasi ini ketika digunakan untuk produksi? Tetapi tidak ada alasan mengapa kita tidak dapat menggunakan pertanyaan yang sama untuk infrastruktur atau database.
Saya bekerja untuk sebuah perusahaan bernama OpenTable. Di dalamnya, kami menyebutnya durasi siklus. Dan di OpenTable dia berusia tujuh minggu. Dan ini relatif baik. Saya tahu perusahaan yang membutuhkan waktu berbulan-bulan untuk mengirim kode untuk produksi. Di OpenTable, kami meninjau proses selama empat tahun. Ini memakan banyak waktu, karena organisasi ini besar - 200 orang. Dan kami mengurangi waktu siklus menjadi tiga menit. Ini dimungkinkan berkat pengukuran efek transformasi kami.
Sekarang semuanya sudah ditulis. Kami memiliki begitu banyak alat dan contoh, ada GitHub. Karena itu, ambil ide dari konferensi seperti DevOops, terapkan dalam organisasi Anda. Jangan mencoba menerapkan semuanya. Ambil satu benda kecil dan jual. Tunjukkan pada seseorang. Dampak perubahan kecil dapat diukur, diukur, dan terus berjalan!
Paul Stack akan tiba di St. Petersburg pada konferensi DevOops 2018 dengan laporan "Pengujian sistem berkelanjutan dengan Kekacauan" . Paul akan berbicara tentang metodologi Chaos Engineering dan menunjukkan bagaimana menggunakan metodologi ini pada proyek nyata.