Belum lama berselang di pusat data tempat kami menyewa server, insiden kecil lain terjadi. Akibatnya, tidak ada konsekuensi serius bagi layanan kami, menurut metrik yang tersedia, kami dapat memahami apa yang terjadi dalam satu menit. Dan kemudian saya membayangkan bagaimana saya harus memutar otak saya jika hanya 2 metrik sederhana yang hilang. Di bawah potongan, sebuah cerita pendek dalam gambar.
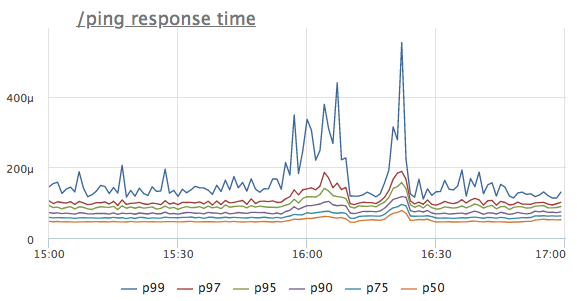
Bayangkan bahwa kita melihat anomali dalam timeline respons layanan tertentu. Untuk mempermudah, kami menggunakan / ping handler, yang tidak mengakses basis data atau layanan tetangga, tetapi mengembalikan '200 OK' (diperlukan untuk load balancers dan k8s untuk layanan pemeriksaan kesehatan)

Apa pemikiran pertama? Itu benar, layanan tidak memiliki sumber daya yang cukup, kemungkinan besar CPU! Kami melihat konsumsi prosesor:
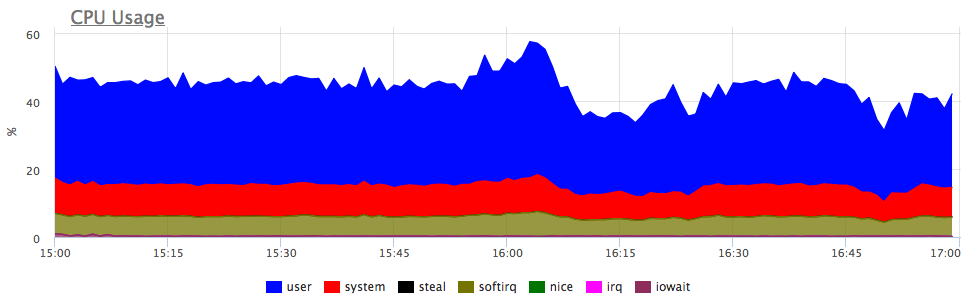
Ya, ada semburan serupa. Selanjutnya, kami melihat konsumsi oleh layanan di server:
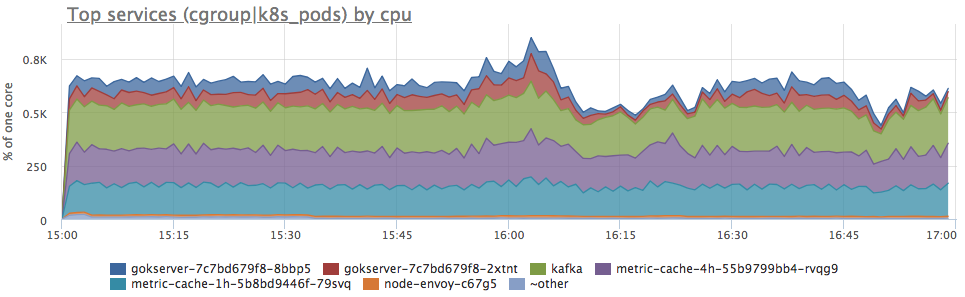
Kami melihat bahwa konsumsi proca telah meningkat secara proporsional untuk semua layanan. Anda tidak dapat mengatakan apa pun secara lebih jauh: Anda dapat melihat dan melihat apakah profil pemuatan telah berubah (karena semua komponen terhubung dan peningkatan permintaan input sebenarnya dapat menyebabkan peningkatan konsumsi sumber daya yang proporsional) atau memahami apa yang terjadi dengan sumber daya server.
Tentu saja, saya mencoba untuk melestarikan intrik sebaik mungkin, tetapi pada awal artikel, Anda mungkin sudah menebak bahwa server hanya mengurangi jumlah tick cpu yang tersedia. Dalam dmesg, tampilannya seperti ini:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
Secara kasar, kami telah mengurangi frekuensi karena terlalu panasnya prosesor. Kami melihat suhu:
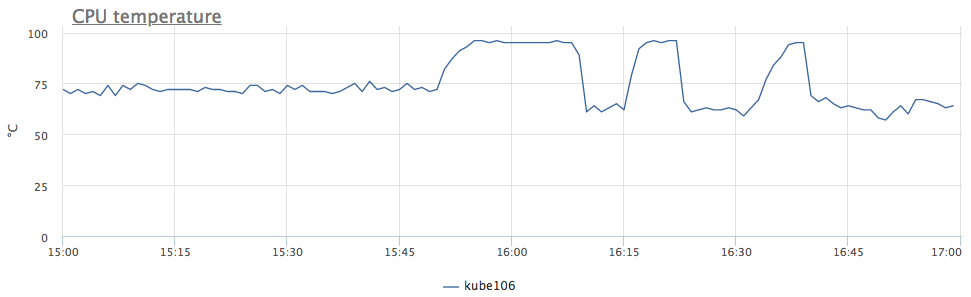
sekarang semuanya jelas. Karena kami memiliki perilaku serupa segera di 6 server, kami menyadari bahwa masalahnya ada di DC, dan tidak dalam segala hal, tetapi hanya di barisan rak tertentu.
Tetapi kembali ke metrik. Kami berpotensi ingin tahu apakah server akan kepanasan di masa mendatang, tetapi ini bukan alasan untuk menambahkan grafik suhu prosesor ke semua dasbor dan memeriksanya setiap saat.
Biasanya pemicu digunakan untuk melacak beberapa metrik untuk mengoptimalkan proses. Tetapi ambang berapa yang harus saya pilih untuk pemicu oleh suhu prosesor?
Karena sulitnya memilih ambang yang baik untuk pelatuk, banyak insinyur memimpikan detektor anomali, yang tanpa pengaturan akan menemukan dirinya sendiri, saya tidak tahu apa :)Pikiran pertama adalah mengatur suhu ambang di mana layanan kami mulai mengalami masalah. Dan jika Anda belum pernah mengalami overheat? Tentu saja Anda dapat melihat jadwal saya dan memutuskan sendiri bahwa 95 ° C adalah yang Anda butuhkan, tetapi mari kita berpikir sedikit lagi.
Masalah dengan kami bukan karena derajat, tetapi karena frekuensinya menurun! Mari kita terus melacak jumlah acara semacam itu.
Di linux, ini dapat dihapus dari sysfs:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Sejujurnya, kami bahkan tidak menampilkan metrik ini di mana pun, kami hanya memiliki pemicu otomatis untuk semua klien yang menyala ketika ambang "> 10 peristiwa / detik" tercapai. Menurut statistik kami, praktis tidak ada positif palsu di ambang ini.
Ya, pemicu ini jarang berhasil, tetapi ketika ini terjadi, itu membuat hidup sangat mudah!
Kami di okmeter.io sebagian besar waktu terlibat dalam pengembangan database pemicu otomatis kami, yang memudahkan pelanggan kami untuk menemukan masalah yang tidak mereka ketahui.