Halo kolega.
Kami berharap dapat memulai terjemahan sebuah buku kecil, tetapi benar
- benar
dasar tentang implementasi kapabilitas AI dalam Python sebelum akhir Agustus.

Mr. Gift, mungkin, tidak membutuhkan iklan tambahan (untuk yang penasaran -
profil master di GitHub):

Artikel yang ditawarkan hari ini akan secara singkat berbicara tentang perpustakaan Ray, yang dikembangkan di University of California (Berkeley) dan disebutkan dalam buku Peter oleh petite. Kami berharap itu sebagai penggoda awal - apa yang Anda butuhkan. Selamat datang di bawah kucing
Dengan pengembangan algoritma dan teknik pembelajaran mesin, semakin banyak aplikasi pembelajaran mesin perlu dijalankan pada banyak mesin sekaligus, dan mereka tidak dapat melakukannya tanpa konkurensi. Namun, infrastruktur untuk melakukan pembelajaran mesin pada cluster masih terbentuk secara situasional. Sekarang sudah ada solusi yang baik (misalnya, server parameter atau pencarian hyperparameters) dan sistem terdistribusi berkualitas tinggi (misalnya, Spark atau Hadoop), awalnya dibuat bukan untuk bekerja dengan AI, tetapi praktisi sering membuat infrastruktur untuk sistem terdistribusi mereka sendiri dari awal. Banyak upaya ekstra dihabiskan untuk ini.
Sebagai contoh, perhatikan algoritma konseptual sederhana, katakanlah,
strategi evolusi untuk pembelajaran penguatan . Pada pseudo-code, algoritma ini cocok menjadi sekitar selusin baris, dan implementasinya dalam Python sedikit lebih besar. Namun, penggunaan efektif dari algoritma ini pada mesin atau cluster yang lebih besar membutuhkan rekayasa perangkat lunak yang jauh lebih canggih. Dalam implementasi algoritma ini dari penulis artikel ini, ada ribuan baris kode, di sini perlu untuk menentukan protokol komunikasi, serialisasi pesan dan strategi deserialisasi, serta berbagai metode pemrosesan data.
Salah satu tujuan
Ray adalah untuk membantu seorang praktisi mengubah algoritma prototipe yang berjalan pada laptop menjadi aplikasi terdistribusi tinggi yang bekerja secara efisien pada sebuah cluster (atau pada mesin multi-core tunggal) dengan menambahkan sedikit baris kode. Dalam hal kinerja, kerangka kerja seperti itu harus memiliki semua keuntungan dari sistem yang dioptimalkan secara manual dan tidak mengharuskan pengguna untuk berpikir tentang penjadwalan, transfer data, dan kerusakan mesin.
Kerangka AI gratisTautkan dengan kerangka kerja pembelajaran dalam lainnya : Ray sepenuhnya kompatibel dengan kerangka kerja pembelajaran dalam seperti TensorFlow, PyTorch, dan MXNet, jadi dalam banyak aplikasi itu benar-benar alami untuk menggunakan satu atau lebih kerangka kerja pembelajaran dalam lainnya dengan Ray (misalnya, di perpustakaan pembelajaran kami yang diperkuat secara aktif terapkan TensorFlow dan PyTorch).
Komunikasi dengan sistem terdistribusi lain : Saat ini, banyak sistem terdistribusi populer digunakan, namun, kebanyakan dari mereka dirancang tanpa mempertimbangkan tugas-tugas yang terkait dengan AI, oleh karena itu mereka tidak memiliki kinerja yang diperlukan untuk mendukung AI dan tidak memiliki API untuk mengekspresikan aspek-aspek yang diterapkan AI. Dalam sistem terdistribusi modern tidak ada (perlu, tergantung pada sistem) fitur yang diperlukan seperti:
- Dukungan tugas tingkat milidetik dan dukungan untuk jutaan tugas per detik
- Pararelisme bersarang (paralelisasi tugas di dalam tugas, misalnya, simulasi paralel saat mencari hyperparameters) (lihat gambar berikut)
- Ketergantungan sewenang-wenang antara tugas, secara dinamis selama eksekusi (misalnya, untuk tidak harus menunggu, menyesuaikan dengan kecepatan pekerja lambat)
- Tugas yang beroperasi pada status variabel bersama (misalnya, bobot dalam jaringan saraf atau simulator)
- Dukungan untuk sumber daya yang heterogen (CPU, GPU, dll.)
 Contoh sederhana konkurensi bersarang. Dalam aplikasi kami, dua percobaan dilakukan secara paralel (masing-masing adalah tugas jangka panjang), dan dalam setiap percobaan beberapa proses paralel disimulasikan (setiap proses juga merupakan tugas).
Contoh sederhana konkurensi bersarang. Dalam aplikasi kami, dua percobaan dilakukan secara paralel (masing-masing adalah tugas jangka panjang), dan dalam setiap percobaan beberapa proses paralel disimulasikan (setiap proses juga merupakan tugas).Ada dua cara utama untuk menggunakan Ray: melalui API tingkat rendah dan melalui perpustakaan tingkat tinggi. Perpustakaan tingkat tinggi dibangun di atas API tingkat rendah. Ini saat ini termasuk
Ray RLlib (perpustakaan terukur untuk pembelajaran penguatan) dan
Ray.tune , perpustakaan yang efisien untuk pencarian terdistribusi untuk hyperparameter.
API Tingkat Rendah RayTujuan dari Ray API adalah untuk memberikan ekspresi alami dari pola dan aplikasi komputasi yang paling umum, tanpa terbatas pada pola tetap seperti MapReduce.
Grafik tugas dinamisPrimitif dasar dalam aplikasi (tugas) Ray adalah grafik tugas dinamis. Ini sangat berbeda dari grafik komputasi di TensorFlow. Sedangkan di TensorFlow grafik komputasi mewakili jaringan saraf dan dieksekusi berkali-kali di setiap aplikasi yang terpisah, di Ray grafik tugas sesuai dengan seluruh aplikasi dan dieksekusi hanya sekali. Grafik tugas tidak diketahui sebelumnya. Itu dibangun secara dinamis saat aplikasi sedang berjalan, dan pelaksanaan satu tugas dapat memicu pelaksanaan banyak tugas lainnya.
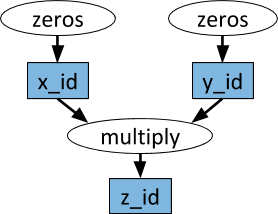 Contoh grafik komputasi. Dalam oval putih, tugas ditampilkan, dan dalam persegi panjang biru - benda. Tanda panah menunjukkan bahwa beberapa tugas bergantung pada objek, sementara yang lain membuat objek.
Contoh grafik komputasi. Dalam oval putih, tugas ditampilkan, dan dalam persegi panjang biru - benda. Tanda panah menunjukkan bahwa beberapa tugas bergantung pada objek, sementara yang lain membuat objek.Fungsi sewenang-wenang python dapat dilakukan sebagai tugas, dan dalam urutan apa pun mereka dapat bergantung pada output tugas lainnya. Lihat contoh di bawah ini.
AktorDengan bantuan fungsi jarak jauh saja dan penanganan tugas di atas, tidak mungkin untuk mencapai bahwa beberapa tugas secara bersamaan bekerja pada keadaan yang bisa ditukar pakai yang sama. Masalah seperti itu dengan pembelajaran mesin muncul dalam konteks yang berbeda, di mana keadaan simulator, bobot dalam jaringan saraf, atau sesuatu yang sama sekali berbeda dapat dibagi. Aktor abstraksi digunakan dalam Ray untuk merangkum keadaan bisa berubah yang dibagikan di antara banyak tugas. Berikut adalah contoh ilustrasi yang menunjukkan bagaimana melakukan ini dengan simulator Atari.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
Untuk semua kesederhanaannya, aktor ini sangat fleksibel dalam penggunaannya. Misalnya, simulator atau kebijakan jaringan saraf dapat diringkas dalam aktor, itu juga dapat digunakan untuk pelatihan terdistribusi (seperti dengan server parameter) atau untuk memberikan kebijakan dalam aplikasi "langsung".
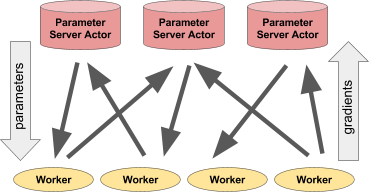 Kiri: Aktor memberikan ramalan / tindakan ke sejumlah proses klien. Kanan: Banyak aktor dari server parameter melakukan pelatihan terdistribusi untuk banyak alur kerja.Contoh server parameter
Kiri: Aktor memberikan ramalan / tindakan ke sejumlah proses klien. Kanan: Banyak aktor dari server parameter melakukan pelatihan terdistribusi untuk banyak alur kerja.Contoh server parameterServer parameter dapat diimplementasikan sebagai aktor Ray sebagai berikut:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
Ini adalah contoh yang
lebih lengkap .
Untuk instantiate server parameter, kami melakukan ini.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
Untuk membuat empat pekerja lama, terus mengekstraksi dan memperbarui parameter, kami akan melakukannya.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
Perpustakaan Tingkat Tinggi RayRay RLlib adalah perpustakaan pembelajaran penguatan skalabel yang dirancang untuk digunakan pada banyak mesin. Itu dapat diaktifkan menggunakan skrip pelatihan yang disediakan sebagai contoh, serta melalui API Pytho. Saat ini, ini termasuk implementasi algoritma:
- A3C
- Dqn
- Strategi evolusi
- PPO
Pekerjaan sedang dilakukan pada implementasi algoritma lain. RLlib sepenuhnya kompatibel dengan
OpenAI gym .
Ray.tune adalah perpustakaan yang efisien untuk pencarian hyperparameter yang terdistribusi. Ini menyediakan API Python untuk pembelajaran yang mendalam, pembelajaran penguatan, dan tugas-tugas lain yang membutuhkan banyak kekuatan pemrosesan. Ini adalah contoh ilustratif dari jenis ini:
from ray.tune import register_trainable, grid_search, run_experiments
Hasil saat ini dapat divisualisasikan secara dinamis menggunakan alat khusus, misalnya, Tensorboard dan VisKit dari rllab (atau langsung membaca log JSON). Ray.tune mendukung pencarian grid, pencarian acak, dan lebih banyak algoritma berhenti non-sepele seperti HyperBand.
Lebih banyak tentang Ray