 Kode proyek tersedia di repositori.
Kode proyek tersedia di repositori.Pendahuluan
Ketika saya membaca deskripsi penampilan karakter dalam buku, saya selalu tertarik pada bagaimana mereka terlihat dalam kehidupan. Sangat mungkin untuk membayangkan seseorang secara keseluruhan, tetapi deskripsi detail yang paling jelas adalah tugas yang sulit, dan hasilnya bervariasi dari orang ke orang. Sering kali saya tidak bisa membayangkan apa pun kecuali wajah karakter yang sangat buram sampai akhir pekerjaan. Hanya ketika buku itu diubah menjadi film, wajah buram itu penuh dengan detail. Misalnya, saya tidak pernah bisa membayangkan bagaimana wajah Rahel terlihat dari buku "
Girl on the Train ". Tetapi ketika film itu keluar, saya bisa mencocokkan wajah Emily Blunt dengan karakter Rachel. Tentu saja, orang yang terlibat dalam pemilihan aktor membutuhkan banyak waktu untuk menggambarkan karakter dalam naskah dengan benar.
Masalah ini menginspirasi dan memotivasi saya untuk menemukan solusi. Setelah itu, saya mulai mempelajari literatur tentang pembelajaran mendalam untuk mencari sesuatu yang serupa. Untungnya, ada beberapa studi tentang sintesis gambar dari teks. Berikut adalah beberapa yang saya bangun di atas:
[
proyek menggunakan jaringan permusuhan generatif, GSS (Jaringan permusuhan generatif, GAN) / kira-kira. perev. ]
Setelah mempelajari literatur, saya memilih arsitektur yang disederhanakan dibandingkan dengan StackGAN ++, dan mengatasi masalah saya dengan cukup baik. Di bagian berikut, saya akan menjelaskan bagaimana saya memecahkan masalah ini dan membagikan hasil awal. Saya juga akan menjelaskan beberapa detail pemrograman dan pelatihan yang saya habiskan banyak waktu.
Analisis data
Tidak diragukan lagi, aspek terpenting dari pekerjaan ini adalah data yang digunakan untuk melatih model. Seperti yang dikatakan Profesor Andrew Eun dalam kursus deeplearning.ai-nya: "Di bidang pembelajaran mesin, bukan orang yang memiliki algoritma terbaik, tetapi orang yang memiliki data terbaik." Maka mulailah pencarian saya untuk dataset pada wajah dengan deskripsi tekstual yang baik, kaya dan beragam. Saya menemukan set data yang berbeda - baik itu hanya wajah, atau wajah dengan nama, atau wajah dengan deskripsi warna mata dan bentuk wajah. Tetapi tidak ada yang saya butuhkan. Pilihan terakhir saya adalah menggunakan
proyek awal - menghasilkan deskripsi data struktural dalam bahasa alami. Tetapi opsi seperti itu akan menambah noise tambahan ke set data yang sudah sangat bising.
Waktu berlalu, dan pada beberapa titik proyek
Face2Text baru
muncul . Itu adalah kumpulan database deskripsi teks rinci tentang orang. Saya berterima kasih kepada penulis proyek untuk set data yang disediakan.
Set data berisi deskripsi tekstual dari 400 gambar yang dipilih secara acak dari database LFW (wajah yang ditandai). Deskripsi dibersihkan untuk menghilangkan karakteristik ambigu dan minor. Beberapa deskripsi tidak hanya berisi informasi tentang wajah-wajah, tetapi juga beberapa kesimpulan yang dibuat berdasarkan gambar - misalnya, "orang dalam foto mungkin adalah penjahat". Semua faktor ini, serta ukuran kecil dari kumpulan data, telah mengarah pada fakta bahwa proyek saya sejauh ini hanya menunjukkan bukti pengoperasian arsitektur. Selanjutnya, model ini dapat ditingkatkan ke set data yang lebih besar dan lebih beragam.
Arsitektur
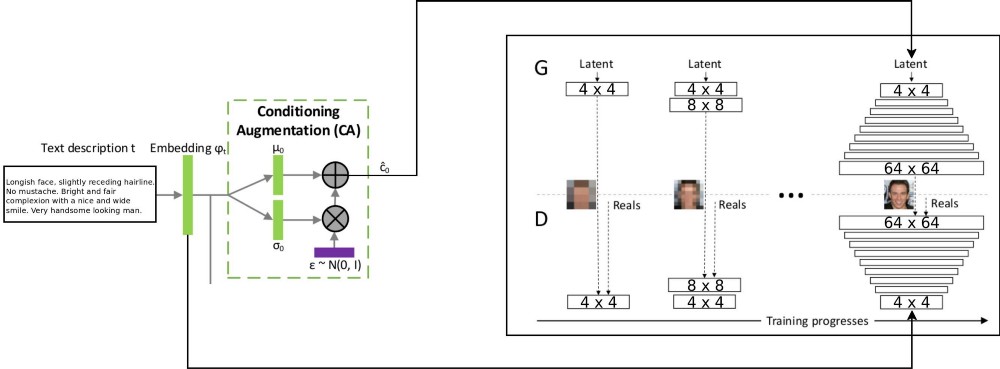
Arsitektur proyek T2F menggabungkan dua arsitektur stackGAN untuk pengkodean teks yang disempurnakan bersyarat, dan ProGAN (
pertumbuhan GSS progresif ) untuk mensintesis gambar wajah. Arsitektur stackgan ++ asli menggunakan beberapa GSS dengan resolusi spasial yang berbeda, dan saya memutuskan bahwa ini adalah pendekatan yang terlalu serius untuk tugas distribusi korespondensi. Tetapi ProGAN hanya menggunakan satu GSS, semakin terlatih pada resolusi yang lebih detail. Saya memutuskan untuk menggabungkan kedua pendekatan ini.
Ada penjelasan tentang aliran data melalui: deskripsi teks dikodekan ke dalam vektor akhir dengan menanamkan ke jaringan LSTM (Embedding) (psy_t) (lihat diagram). Kemudian, embedding ditransmisikan melalui blok Augmentasi Pengkondisian (satu lapisan linear) untuk mendapatkan bagian teks dari vektor eigen (menggunakan teknik reparameterisasi VAE) untuk GSS sebagai input. Bagian kedua vektor eigen adalah noise Gaussian acak. Vektor eigen yang dihasilkan diumpankan ke generator GSS, dan embedding diumpankan ke lapisan diskriminator terakhir untuk distribusi korespondensi bersyarat. Pelatihan proses GSS berjalan persis sama seperti pada artikel tentang ProGAN - berlapis, dengan peningkatan resolusi spasial. Lapisan baru diperkenalkan menggunakan teknik fade-in untuk menghindari penghapusan hasil pembelajaran sebelumnya.
Implementasi dan detail lainnya
Aplikasi ini ditulis dalam python menggunakan kerangka PyTorch. Saya dulu bekerja dengan paket tensorflow dan keras, tetapi sekarang saya ingin mencoba PyTorch. Saya suka menggunakan debugger python bawaan untuk bekerja dengan arsitektur jaringan - semua berkat strategi eksekusi awal. Tensorflow juga baru-baru ini mengaktifkan mode eksekusi bersemangat. Namun, saya tidak ingin menilai kerangka mana yang lebih baik, saya hanya ingin menekankan bahwa kode untuk proyek ini ditulis menggunakan PyTorch.
Cukup banyak bagian dari proyek yang menurut saya dapat digunakan kembali, terutama ProGAN. Oleh karena itu, saya menulis kode terpisah untuk mereka sebagai
perpanjangan dari modul PyTorch, dan itu dapat digunakan pada set data lain juga. Hanya perlu menunjukkan kedalaman dan ukuran fitur GSS. GSS dapat dilatih secara progresif untuk kumpulan data apa pun.
Detail Pelatihan
Saya melatih beberapa versi jaringan menggunakan hiperparameter yang berbeda. Rincian pekerjaan adalah sebagai berikut:
- Diskriminator tidak memiliki operasi batch-norma atau lapisan-norma, sehingga hilangnya WGAN-GP dapat tumbuh eksplosif. Saya menggunakan penalti melayang dengan lambda sama dengan 0,001.
- Untuk mengontrol keragaman Anda sendiri, yang diperoleh dari teks yang disandikan, perlu menggunakan jarak Kullback - Leibler dalam kerugian Generator.
- Untuk membuat gambar yang dihasilkan lebih cocok dengan distribusi teks yang masuk, lebih baik menggunakan versi WGAN dari diskriminator (Matching-Aware) yang sesuai.
- Waktu fade-in untuk level atas harus melebihi waktu fade-in untuk level atas. Saya menggunakan 85% sebagai nilai fade-in saat pelatihan.
- Saya menemukan bahwa contoh resolusi yang lebih tinggi (32 x 32 dan 64 x 64) menghasilkan lebih banyak kebisingan latar belakang daripada contoh resolusi yang lebih rendah. Saya pikir ini karena kurangnya data.
- Selama latihan progresif, lebih baik menghabiskan lebih banyak waktu untuk resolusi yang lebih rendah, dan mengurangi waktu yang dihabiskan untuk bekerja dengan resolusi yang lebih tinggi.
Video menunjukkan selang waktu Generator. Video ini dikompilasi dari gambar dengan resolusi spasial berbeda yang diperoleh selama pelatihan GSS.
Kesimpulan
Menurut hasil awal, dapat dinilai bahwa proyek T2F dapat dikerjakan dan memiliki aplikasi yang menarik. Misalkan dapat digunakan untuk menyusun photobots. Atau untuk kasus-kasus ketika perlu untuk meningkatkan imajinasi. Saya akan terus bekerja pada penskalaan proyek ini pada set data seperti Flicker8K, keterangan Coco, dan sebagainya.
Pertumbuhan GSS progresif adalah teknologi fenomenal untuk pelatihan GSS yang lebih cepat dan lebih stabil. Dapat dikombinasikan dengan berbagai teknologi modern yang disebutkan dalam artikel lain. GSS dapat digunakan di berbagai bidang MO.