Halo, Habr! Nama saya Sergey Prutskikh, saya bertanggung jawab atas arahan pemantauan Sberbank-Technology. Tujuan utama organisasi kami adalah pengembangan dan pengujian produk perangkat lunak untuk Sberbank. Untuk ini, perusahaan memiliki infrastruktur TI yang besar - 15 ribu server dibagi menjadi sekitar 1.500 lingkungan pengujian, yang terkait dengan lebih dari 500 sistem otomatis. Secara total, sekitar 10 ribu spesialis bekerja dengan mereka.
Pada 2015, kami mulai membuat layanan pemantauan terpusat. Apalagi semuanya terbatas tidak hanya pada implementasi. Itu perlu untuk menyusun banyak peraturan, instruksi, serta hubungan antara unit-unit Sbertech dalam kerangka pemantauan. Dalam posting ini saya akan memberi tahu Anda secara rinci bagaimana kami memilih platform, pada prinsip apa kami menciptakan segalanya dan apa yang akhirnya kami lakukan.

Tujuan utama dan ideologi proyek
Berikut adalah tujuan yang kami kejar dalam proyek ini:
- Memperoleh data yang dapat diandalkan tentang ukuran dan komposisi infrastruktur TI;
- Optimalisasi penggunaan fasilitas TI;
- Mengurangi biaya untuk mendukung dan mengoperasikan infrastruktur TI dari lingkungan pengembangan dan pengujian;
- Dukungan untuk infrastruktur TI dalam kesiapan untuk pengembangan dan pengujian;
- Memberi tahu para spesialis tentang masalah dalam pekerjaan di lingkungan pengujian;
- Audit kepatuhan lingkungan pengujian dan AFM industri bukanlah tugas yang sangat khas bagi kami;
- Pengumpulan data untuk laporan hasil pengujian, memberikan pengukuran parameter kritis pada semua tahap pengujian.
Ke depan, saya dapat mengatakan bahwa semua tujuan sampai tingkat tertentu telah selesai hingga saat ini. Dan beberapa masalah terkait, pemantauan juga membantu menyelesaikannya.
Selain tujuan, kami merumuskan prinsip-prinsip, ideologi, yang kami patuhi sepanjang proyek:
- Kepuasan pengguna adalah salah satu indikator utama pemantauan. Pada konferensi ITSMf 2017, saya berbicara tentang pemantauan infrastruktur TI, dan yang kelima TIDAK dalam laporan itu: “JANGAN memaksa karyawan Anda untuk bekerja dengan sistem pemantauan.” Intinya adalah memotivasi, bukan mewajibkan. Ini dicapai melalui KPI yang dibangun dengan benar. Di awal layanan, KPI tersebut mungkin belum muncul. Namun demikian, sangat penting dari hari-hari pertama pemantauan untuk mulai memberi manfaat bagi pelanggan potensial.
- Waktu minimum untuk penyempurnaan. Untuk ini kami menggunakan elemen Agile. Mereka membantu menyediakan fitur baru secepat mungkin dan menerima umpan balik dari pelanggan.
- Keterbukaan sistem, baik untuk perbaikan, yang dinyatakan dalam pembuatan jaminan tunggal, permintaan yang dapat ditulis oleh setiap karyawan, dan dalam hal memberikan informasi - layanan kami memungkinkan Anda untuk mendapatkan informasi tentang konfigurasi pemantauan, yang, sebagai suatu peraturan, disembunyikan.
- Integrasi tingkat tinggi ke dalam pekerjaan sehari-hari. Prioritas kami adalah mengimplementasikan fungsionalitas yang dibutuhkan pengguna setiap hari. Ini membantu dalam waktu yang relatif singkat untuk mempopulerkan layanan pemantauan di dalam perusahaan.
Pilihan sistem pemantauan
Di hampir semua proyek di mana saya berpartisipasi, cepat atau lambat sebuah tabel muncul membandingkan fungsi berbagai sistem, di mana sistem tertentu diberi keuntungan yang jelas.
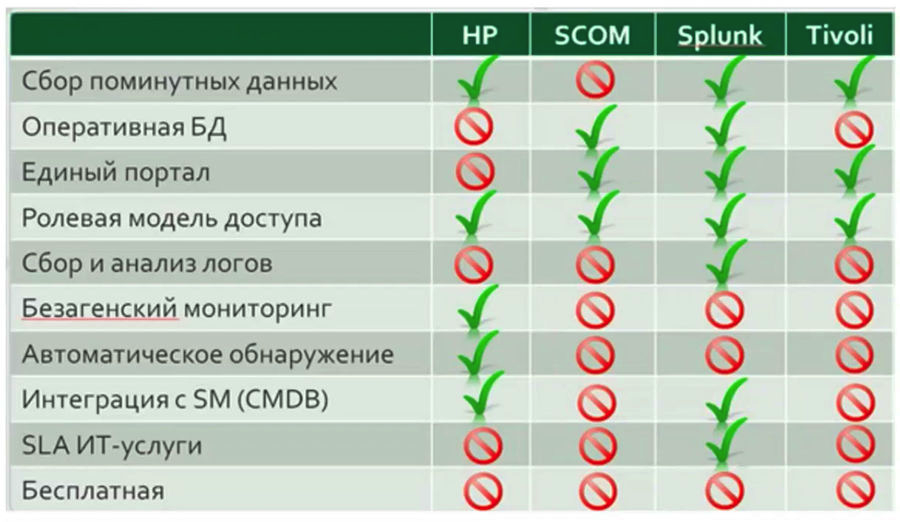
Menurut pendapat saya, analisis komparatif seperti itu
tidak dapat dilakukan sebelum mulai segera bekerja dengan layanan pemantauan, dan terlebih lagi, tidak ada gunanya membuat keputusan tentang memilih satu atau solusi lain berdasarkan analisis ini. Selama sistem di perusahaan Anda tidak berfungsi setidaknya untuk jangka waktu yang singkat, mustahil untuk menilai dengan jelas fungsi spesifik mana di perusahaan Anda yang akan diminati. Tabel seperti itu dapat membantu jika Anda ingin mengubah sistem pemantauan karena beberapa alasan.
Perbandingan dengan instalasi Zabbix lainnya
Anda dapat berbicara banyak tentang cara membandingkan ukuran beberapa instalasi sistem pemantauan, tetapi semua karakteristik yang dipilih untuk ini, menurut saya, cukup subyektif. Agar Anda memiliki gagasan yang lebih akurat tentang ukuran instalasi kami, saya memutuskan untuk memberikan contoh layanan serupa di perusahaan lain, yang dibicarakan oleh perwakilan Zabbix di konferensi Highload.
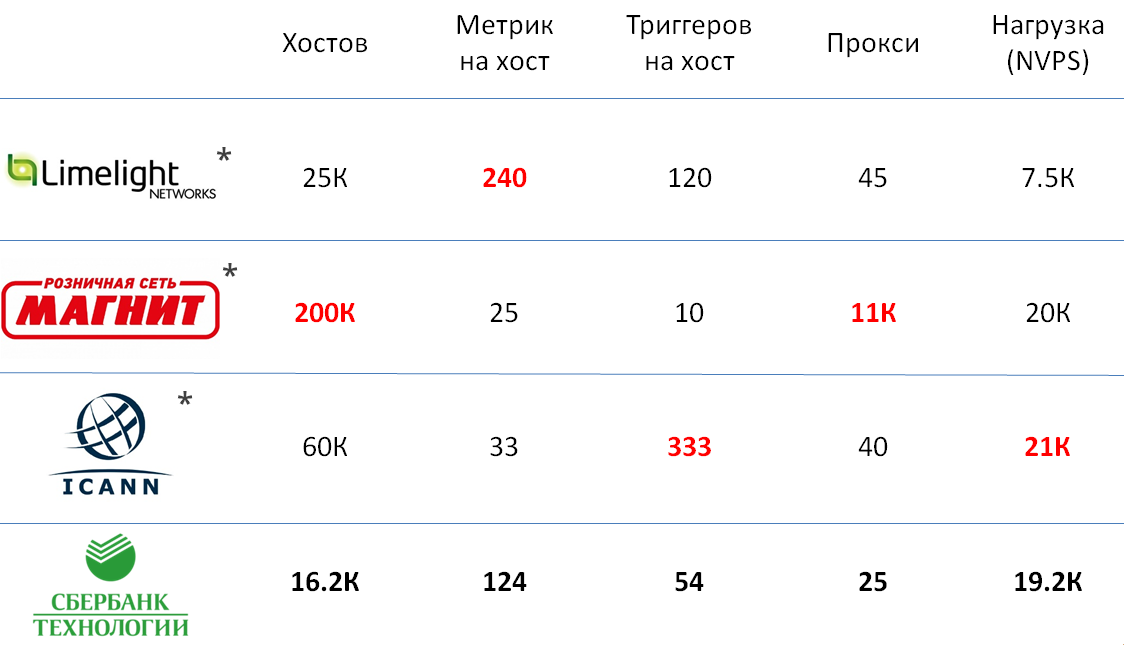
Seperti yang Anda lihat, instance Zabbix di Sbertech tidak jauh lebih rendah dari instalasi terbesar, dan dalam hal total beban, ini setara dengan mereka.
Manfaat Zabbix
Pada paruh kedua 2017, kami melakukan uji coba Zabbix untuk memantau infrastruktur PROM. Kemudian kami merumuskan sejumlah kriteria kualitatif yang kami kaitkan dengan keunggulan absolut Zabbix:
- Sumber terbuka Kemungkinan tak terbatas untuk pemrosesan dan kustomisasi.
- Keterbukaan mekanisme dan sumber pengumpulan metrik. Dalam solusi perusahaan komersial, banyak metrik tidak dapat dipahami - berbagai botnet, kebocoran memori, yang bahkan tidak dapat dijelaskan oleh dukungan teknis dari vendor. Zabbix tidak memiliki masalah seperti itu - Anda selalu dapat dengan jelas mengatakan bagaimana ia mengumpulkan metrik tertentu. Dengan demikian, kredibilitas sistem oleh administrator sistem meningkat.
- Kemudahan penskalaan relatif - terutama disebabkan oleh diperkenalkannya server proxy tambahan, tempat Anda dapat mentransfer sebagian dari beban. Jika Anda mencapai batas kinerja satu instance, dimungkinkan untuk menaikkan yang kedua dan menggabungkan keduanya di bawah satu sistem visualisasi (Grafana).
- API Keren - menurut saya, ini adalah salah satu keunggulan utama Zabbix. API berkualitas tinggi, dikembangkan dengan baik dan dapat dimengerti membuka peluang besar untuk integrasi dengan sistem terkait, otomatisasi, dll.
- Memantau objek dinamis adalah hal yang mudah, tetapi menyenangkan. Di Zabbix, pemantauan ini sederhana dan intuitif, memungkinkan Anda untuk mencapai hasil yang baik dengan sangat cepat. Objek dinamis adalah objek apa pun yang muncul dan hilang di server selama masa pakainya: sistem file, antarmuka jaringan, dan lainnya. Oleh karena itu, ada kebutuhan untuk mengotomatiskan pengaturan dan penghapusan objek-objek ini dari pemantauan.
- Sejumlah komponen yang relatif kecil. Dalam solusi komersial, setiap komponen adalah subsistem yang terpisah dengan basisnya sendiri, yang harus diinstal secara terpisah. Dan Zabbix adalah sistem tunggal, di mana semua metode pemantauan terkonsentrasi sekaligus: agen, agen, jaringan dan lainnya - hanya 14 jenis.
- Visualisasi data dengan Grafana. Integrasi dengan Grafana memungkinkan untuk membuat grafik dan membuat dasbor yang sangat nyaman.
- Ketersediaan pemantauan ketersediaan layanan TI. Zabbix memiliki subsistem bawaan yang dapat menghitung ketersediaan layanan TI untuk digunakan di masa depan dalam SLA.
- Fleksibilitas untuk membuat metrik dan nilai ambangnya. Di sini Zabbix memiliki banyak peluang untuk mengonfigurasi metrik pemantauan yang kompleks:
- Pertama-tama, itu adalah penciptaan metrik yang dihitung : berdasarkan beberapa metrik sederhana, satu kompleks dihitung.
- preprocessing dari nilai metrik tersedia - ini, misalnya, ketika Anda memuat beberapa array data besar ke Zabbix, dan kemudian, sebelum memasukkan metrik tertentu ke dalam basis data, Zabbix menganalisis array dan mengeluarkan data yang ingin Anda simpan sebagai metrik .
- metrik master. Dimungkinkan untuk mengumpulkan array data pada suatu objek dalam satu survei menjadi satu metrik besar, dan kemudian menggunakannya sebagai sumber data untuk metrik lainnya. Ini memungkinkan Anda mengurangi jumlah kueri dan menyinkronkan koleksi semua metrik dalam waktu.
- Kemungkinan pemantauan internal. Zabbix, sebagai produk open source, memiliki masalah kinerja. Namun, sistem pemantauan internal yang dipikirkan dengan matang membantu dengan cepat menangani masalah-masalah ini.
Kerugian Zabbix
Dalam keadilan, saya tidak bisa tidak menyebutkan utama, menurut pendapat saya, kekurangan Zabbix. Anda juga dapat membuat daftar yang layak:
- Otomatisasi backend tingkat rendah. Saya akan membuat reservasi bahwa saya tidak memiliki kesempatan untuk bereksperimen dengan semua varian DBMS. Perusahaan kami menggunakan Oracle DBMS sebagai backend Zabbix. Operasi massal dapat memakan waktu lebih dari satu jam - misalnya, memperbarui atau mengubah metrik, yang terkait dengan sejumlah besar objek (15 ribu node jaringan).
- Kurangnya alat manajemen agen pemantauan built-in. Produk semacam itu tersedia dalam produk komersial. Zabbix belum memiliki ini. Bahkan tidak ada pembaruan toolkit untuk agen. Tentu saja, semuanya dapat dilakukan secara independen, tetapi akan lebih baik untuk mengeluarkan fitur-fitur ini.
- Sejauh ini, elaborasi yang rendah dari pemantauan ketersediaan layanan TI. Sangat bagus bahwa ada pemantauan, tetapi perlu dikembangkan lebih lanjut. Sekarang tidak mungkin membatasi akses pengguna ke setiap bagian dari model sumber daya layanan (selanjutnya disebut CPM). Jika pohon CPM besar, antarmuka web mulai melambat. Dan kemungkinan untuk menyesuaikan perhitungan ketersediaan dalam subsistem ini masih rendah.
- Pembaruan panjang. Pembaruan basis data terakhir memakan waktu sekitar delapan jam. Saat ini, layanan pemantauan tidak tersedia. Atau, Anda dapat meminta skrip dukungan dan memperbarui secara terpisah.
- Fungsionalitas sederhana dari subsistem visualisasi built-in. Grafana menyelesaikan masalah ini, tetapi visualisasi bawaan menyisakan banyak hal yang diinginkan.
- Pemantauan DBMS terintegrasi (ODBC). Faktanya adalah bahwa pemantauan tersebut membuka koneksi terpisah untuk Zabbix setiap kali metrik disurvei. Dan jika basis data Anda besar (dengan sejumlah besar metrik dikumpulkan), maka kumpulan koneksi di dalamnya mungkin menjadi penuh dan basis data akan berhenti merespons, termasuk untuk sistem target. Zabbix memiliki alat pemantauan alternatif (misalnya, DBforBIX), tetapi mengaturnya untuk sejumlah besar objek adalah tugas yang agak melelahkan. Plus untuk ini, Anda perlu menulis otomatisasi terpisah.
- Kurangnya fleksibilitas inventaris untuk infrastruktur TI. Di satu sisi, senang memilikinya. Di sisi lain, ini tampak seperti tab terpisah untuk objek pemantauan di mana ada seperangkat bidang inventaris dengan nama kode keras. Untuk mengubah sesuatu, Anda harus masuk ke kode sumber dari frontend. Juga tidak mungkin untuk mengubah jumlah bidang dan ukuran ini - ada risiko melanggar sesuatu selama pembaruan berikutnya.
- Kurangnya otomatisasi untuk membangun peta jaringan. Sebagai perbandingan, kami dapat mengutip HP OpenView Network Node Manager, yang sangat tahu cara membuat peta topologi jaringan secara otomatis. Zabbix harus membangun semuanya secara manual. Mungkin, karena alasan ini, fungsi ini praktis tidak diminati di antara kita.
- Kurangnya fleksibilitas dalam model peran. Zabbix hanya menyediakan empat peran pengguna dengan kemampuan tetap. Selain itu, tidak ada jalan keluar dari kotak untuk membatasi akses pengguna ke Zabbix API. Artinya, jika pengguna memiliki akses ke frontend, maka ia secara otomatis memiliki akses ke API. Bagi kami, ini mengarah pada fakta bahwa pengguna dengan permintaan yang tidak kompeten secara serius memuat sistem. Selain itu, tidak ada cara untuk memberikan akses pengguna, misalnya, membaca metrik tanpa akses, untuk mengedit pengaturan objek pemantauan.
Arsitektur sistem
Sekarang beberapa kata tentang indikator kuantitatif dan arsitektur sistem kami.
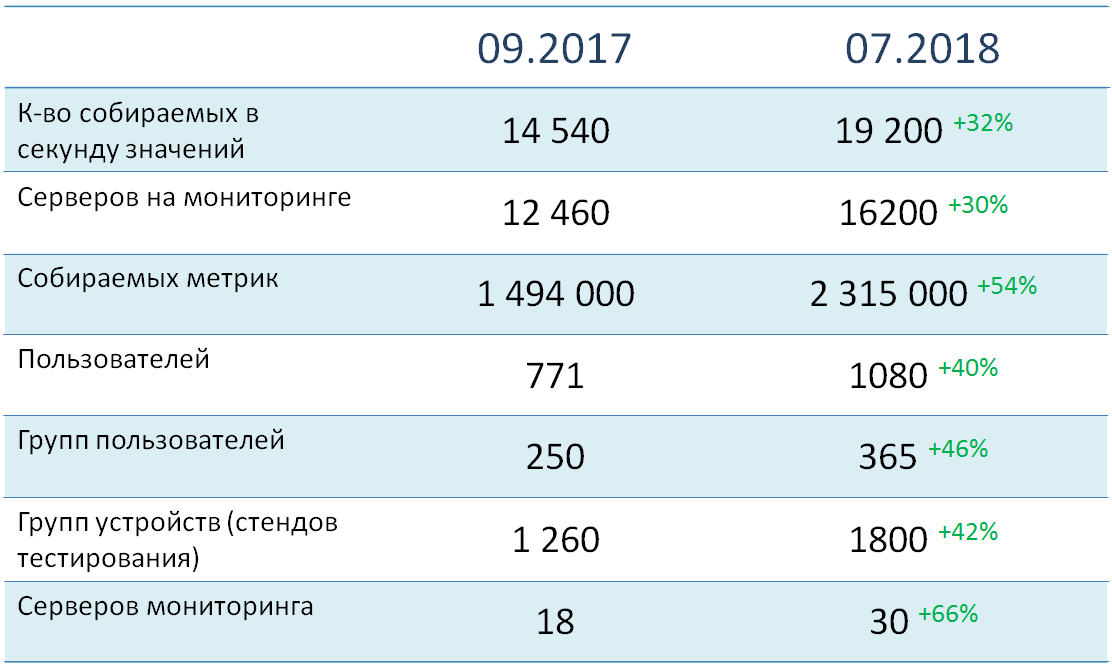
Saat ini, ada lebih dari 16 ribu objek (terutama server) yang sedang diawasi, yang darinya hampir dua setengah juta metrik dikumpulkan secara total. Total beban mereka pada sistem adalah sekitar 19 ribu nilai per detik. Semua objek pemantauan didistribusikan di lebih dari 1800 kelompok perangkat, yang sebagian besar sesuai dengan lingkungan pengujian tertentu. Saat ini, lebih dari 1000 pengguna terdaftar di sistem, yang dibagi menjadi 365 grup fungsional.
Seperti yang Anda lihat, kami membayar cukup banyak perhatian pada distribusi perangkat dan pengguna ke dalam grup. Ini memungkinkan Anda untuk secara signifikan meningkatkan akurasi peringatan dari layanan kami.
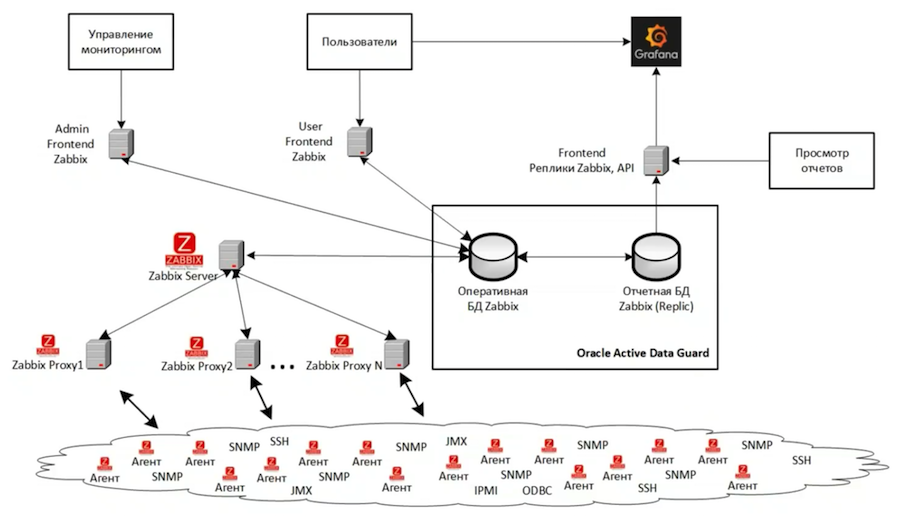
Secara total, kami memiliki tiga instance Zabbix. Diagram menunjukkan arsitektur yang terbesar dari mereka, yang memantau infrastruktur TI utama pengembangan dan pengujian. Contoh lain mengawasi infrastruktur pemantauan. Dan contoh ketiga digunakan bersama kami untuk pengembangan dan pengujian alat pemantauan baru. Seluruh struktur instance utama divirtualisasi berdasarkan VMWare. Secara umum, jika mungkin lebih baik tidak menggunakan sistem virtualisasi, karena jauh lebih sulit untuk mencari dan menyelesaikan masalah kinerja dalam hal infrastruktur virtual.
Backend didasarkan pada Oracle Active Data Guard dan terdiri dari dua database - utama dan replika. Kami memiliki tiga bidang:
- Untuk tugas administratif - ini dikonfigurasikan untuk melakukan operasi yang berat, kompleks, dan jangka panjang yang memuat server secara berat;
- Kustom - dengan pengaturan yang lebih ketat yang tidak memungkinkan pengguna untuk membebani sistem pemantauan utama terlalu banyak;
- Untuk pelaporan, ia melihat replika dan telah diadaptasi untuk berinteraksi dengan basis data read-only. Grafana terhubung dengannya, menyediakan visualisasi data pemantauan yang berkualitas tinggi.
Fitur Implementasi
Dalam cerita ini, saya memutuskan untuk tidak fokus pada fungsionalitas dasar yang diterapkan di hampir semua crash - perbaikan memperbaiki pemantauan, mengumpulkan informasi tentang kinerja atau ketersediaan sistem TI. Saya akan fokus pada fitur khas layanan kami.
Fitur-fitur ini terutama mencakup otomatisasi tingkat tinggi dari tugas-tugas tipikal. Kami praktis tidak menghabiskan waktu menyiapkan server untuk pemantauan, menyediakan akses ke hasil pemantauan, tetapi fokus terutama pada pengembangan layanan dan menambahkan fitur-fitur non-standar baru ke dalamnya. Lebih dari 200 skrip otomatisasi yang dikembangkan sejak layanan pemantauan dimasukkan ke dalam operasi uji coba sangat membantu kami dalam hal ini.
Tetapi sebelum mendaftarkan agen di Zabbix, masih perlu diinstal. Seperti yang saya tulis di atas, salah satu kelemahan Zabbix adalah kurangnya alat manajemen agen pemantauan. Karenanya, untuk memasang agen, kami telah mengorganisir pekerjaan terpisah sebagai bagian dari proses DevOps kami. Gambar di bawah ini menunjukkan diagram instalasi agen.
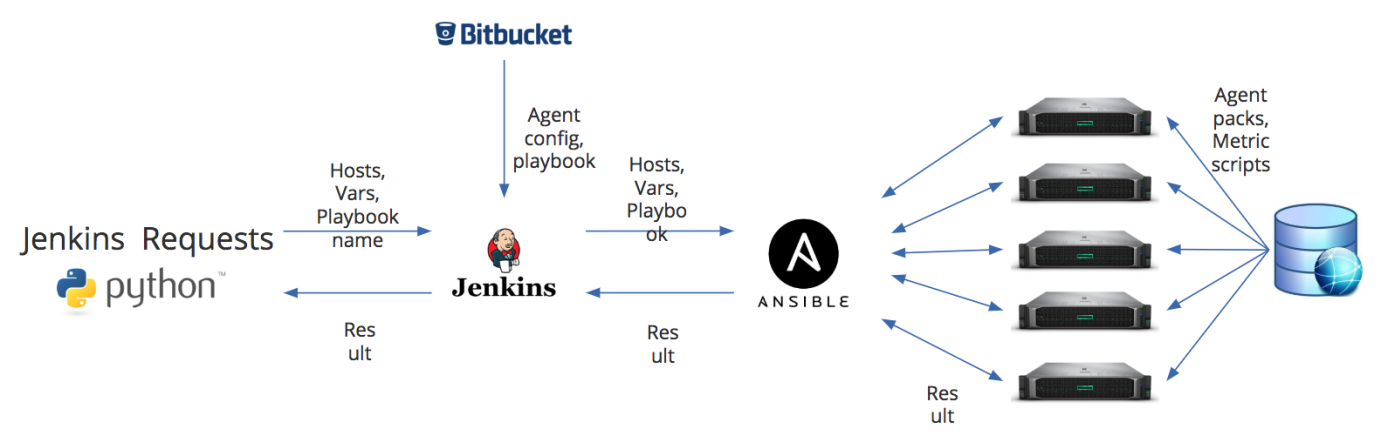
Kami memiliki dua titik masuk utama. Ini bisa berupa skrip Python - melalui REST API, ia meneruskan informasi ke pekerjaan Jenkins tentang host tempat Anda ingin menginstal atau memperbarui agen, daftar variabel tambahan, serta nama playbook yang harus Anda jalankan di Ansible. Atau data default dapat berasal dari Bitbucket. Namun dalam Jenkins, mereka dapat sepenuhnya diganti sesuai dengan variabel yang kami lewati. Dan ini membantu kami, misalnya, untuk memperbarui agen yang dipantau oleh server proxy yang berbeda. Keunikan dari proses kami adalah bahwa konfigurasi agen Zabbix hampir terbentuk dengan cepat.
Pelaporan
Sudah di awal proyek, menjadi jelas bahwa alat pelaporan standar yang disediakan oleh alat Zabbix tidak akan memungkinkan kita untuk memenuhi semua kebutuhan kita. Dalam hal ini, berdasarkan arsitektur layanan-mikro, subsistem pelaporan terpisah dilaksanakan, yang secara signifikan memperluas kemampuan laporan pemantauan dasar. Sekarang kami memiliki lebih dari dua puluh laporan yang beroperasi. Berikut adalah beberapa contoh bersama dengan tujuan yang sedang dilaksanakan:

Lansiran
Sepanjang pekerjaan layanan, peringatan email telah berkembang. Seperti apa bentuknya saat ini:
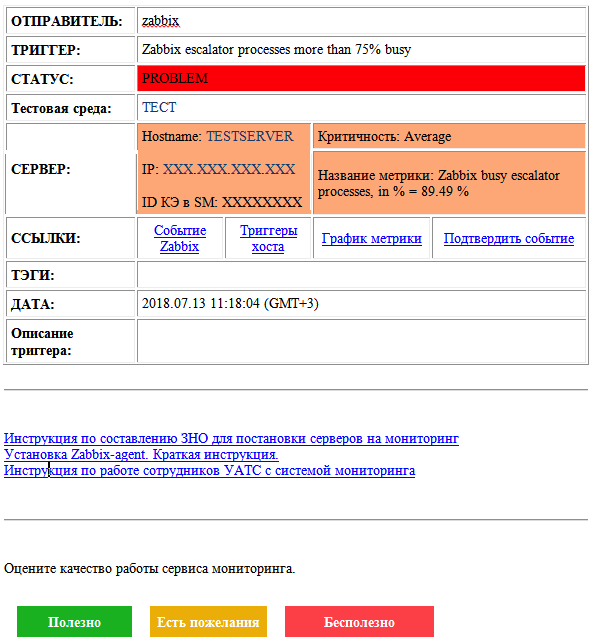
Ada informasi tentang masalah dan statusnya, serta tentang objek pemantauan. Ada tautan ke metrik dan acara terkait, bidang untuk menjelaskan masalah, tautan ke instruksi dan formulir umpan balik. Untuk kecelakaan yang lebih kritis, tentu saja kami juga memiliki distribusi SMS.
Lansiran informatif semacam itu memungkinkan kami untuk meminimalkan komunikasi sebagian besar pengguna kami dengan Zabbix itu sendiri. Cukup menerima milis ini. Kami mengelompokkan pengguna dengan baik - ada 365 grup untuk 1080 orang. Oleh karena itu, buletin ternyata cukup bertitik - dan, karenanya, tidak mengganggu. Banyak pengguna kami hampir lupa bahwa kami memiliki, pada kenyataannya, Zabbix - mereka menggunakan buletin Grafana dan sistem visualisasi.
Integrasi dengan proses manajemen
Proyek ini awalnya melibatkan pemantauan integrasi dengan beberapa proses manajemen infrastruktur TI kami. Jika layanan pemantauan mencatat kecelakaan, Anda dapat membuat tiketnya - untuk tim yang bekerja lebih banyak dengan Jira. Untuk departemen layanan, dimungkinkan untuk membuat insiden di HP Service Manager:

Berdasarkan Zabbix, metodologi untuk mengoptimalkan pemanfaatan infrastruktur TI juga dikembangkan dan diotomatisasi. Tiga parameter utama dioptimalkan: jumlah CPU, RAM, dan hard drive. Teknik ini bekerja atas dasar rata-rata bergerak dan persentil 90 persen. Berdasarkan teknik ini, objek atau server apa pun jatuh ke dalam salah satu dari tiga kategori: kekurangan muatan, muatan optimal, kelebihan muatan.
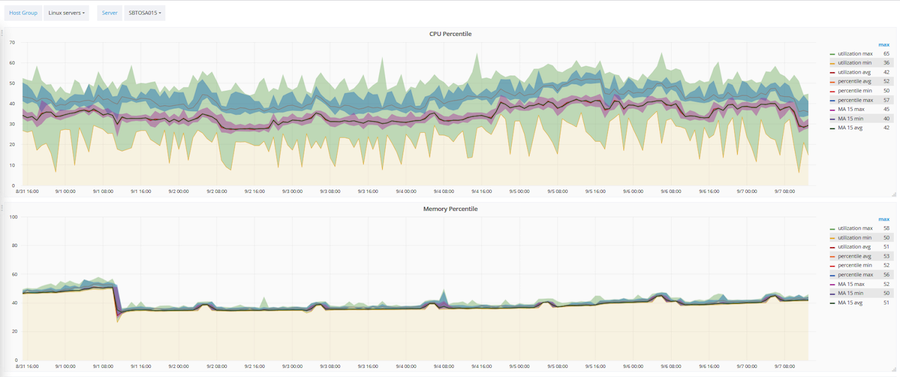
Di atas menunjukkan bagaimana teknik ini diterapkan ke server tertentu. Koridor merah muda adalah nilai moving average. Koridor hijau lebar - data mentah. Dan biru adalah persentil 90 persen.
Integrasi dengan database konfigurasi memungkinkan untuk mengotomatisasi sebagian besar tugas yang terkait dengan menyediakan akses dan membangun model sumber daya layanan. , . , , , .
Zabbix . , .
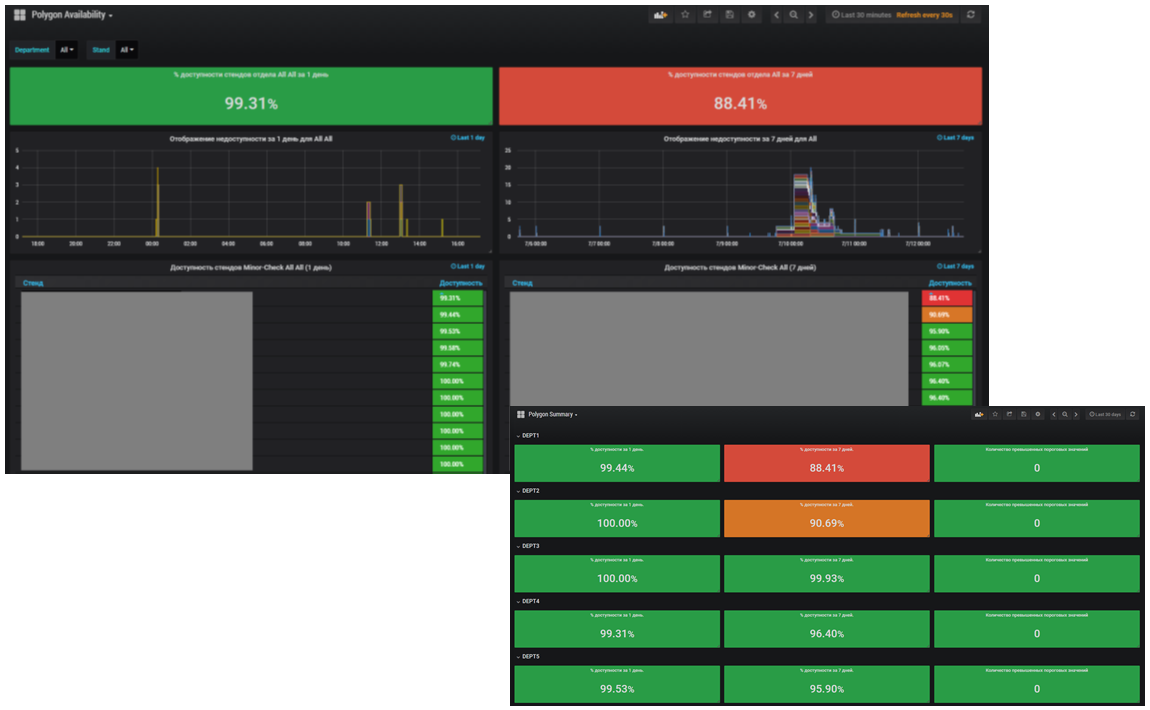
, . , . .
, . 2017 :
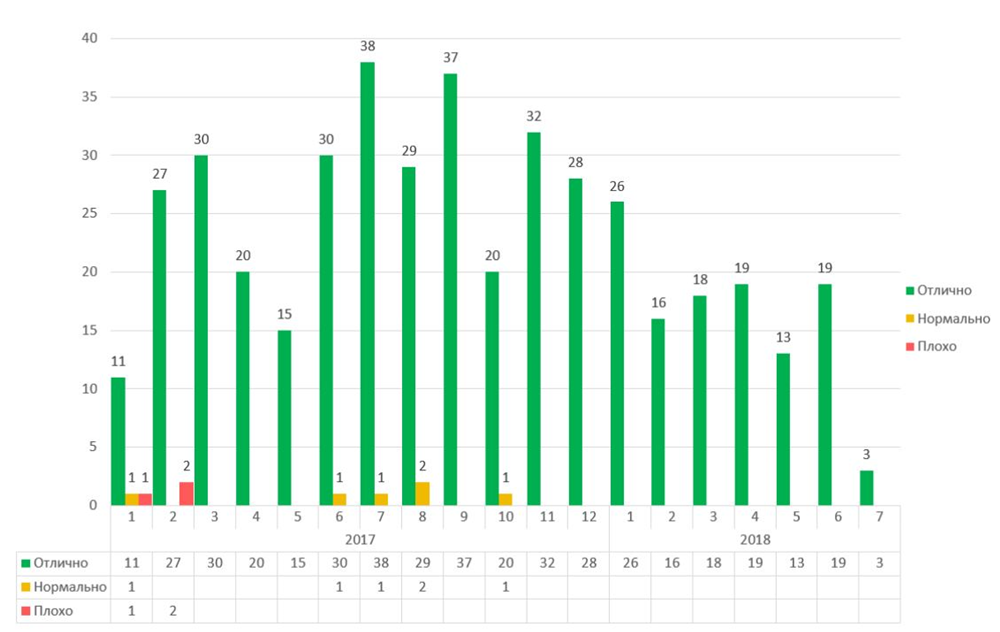
2017 .
, :
, . 70% . , , , .
2016 . . , , .
2016 . - , . . ,
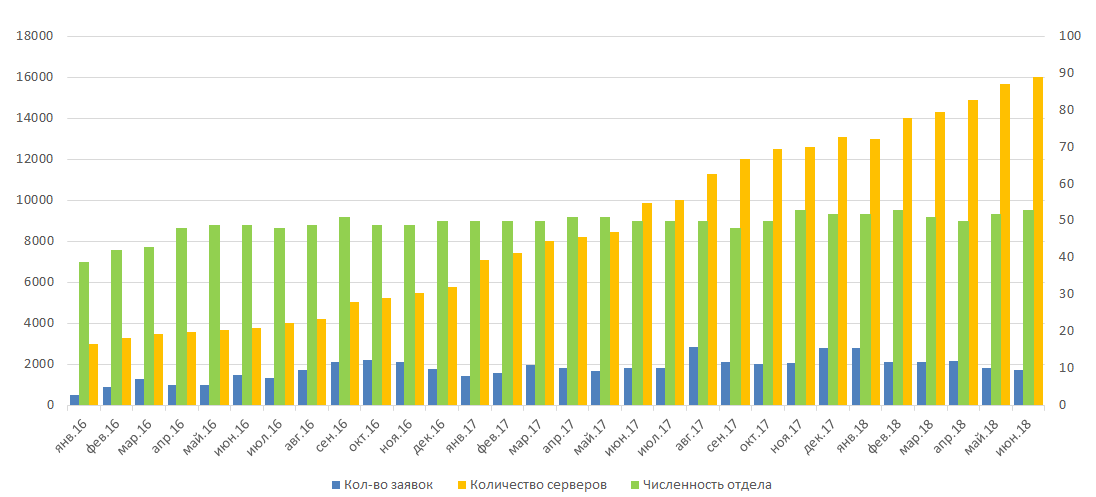
2016 , : 600 CPU, 7,5 50 .