
Hari ini di KDD 2018 adalah hari seminar - bersama dengan konferensi besar yang dimulai besok, beberapa kelompok mengumpulkan pendengar tentang beberapa topik tertentu. Sudah ke dua pesta semacam itu.
Analisis Rangkaian Waktu
Di pagi hari saya ingin pergi ke seminar tentang analisis
grafik , tetapi dia ditahan selama 45 menit, jadi saya beralih ke yang berikutnya, untuk menganalisis rangkaian waktu. Tiba-tiba, seorang
profesor pirang dari California membuka seminar dengan topik "Kecerdasan Buatan dalam Kedokteran". Aneh, karena untuk ini ada trek terpisah di kamar sebelah. Kemudian ternyata dia memiliki beberapa mahasiswa pascasarjana yang akan berbicara tentang rangkaian waktu di sini. Tapi, sebenarnya, to the point.
Kecerdasan Buatan dalam Kedokteran
Kesalahan medis adalah penyebab 10% kematian di AS, ini adalah salah satu dari tiga penyebab utama kematian di negara ini. Masalahnya adalah bahwa tidak ada cukup dokter; mereka yang kelebihan beban, dan komputer lebih cenderung menciptakan masalah bagi dokter daripada yang bisa mereka pecahkan, setidaknya yang dilakukan dokter. Namun, sebagian besar data tidak benar-benar digunakan untuk pengambilan keputusan. Semua ini harus diperjuangkan. Sebagai contoh, satu bakteri,
Clostridium difficile, sangat virulen dan kebal obat. Selama tahun lalu, dia telah menimbulkan kerusakan $ 4 miliar. Mari kita coba menilai risiko infeksi berdasarkan serangkaian catatan medis. Tidak seperti karya-karya sebelumnya, kami mengambil banyak tanda (vektor 10k untuk setiap hari) dan akan membangun model individual untuk setiap rumah sakit (dalam banyak hal, tampaknya, merupakan ukuran yang diperlukan, karena semua rumah sakit memiliki kumpulan data sendiri). Hasilnya, kami memperoleh akurasi sekitar 0,82 AUC dengan prognosis risiko CDI setelah 5 hari.
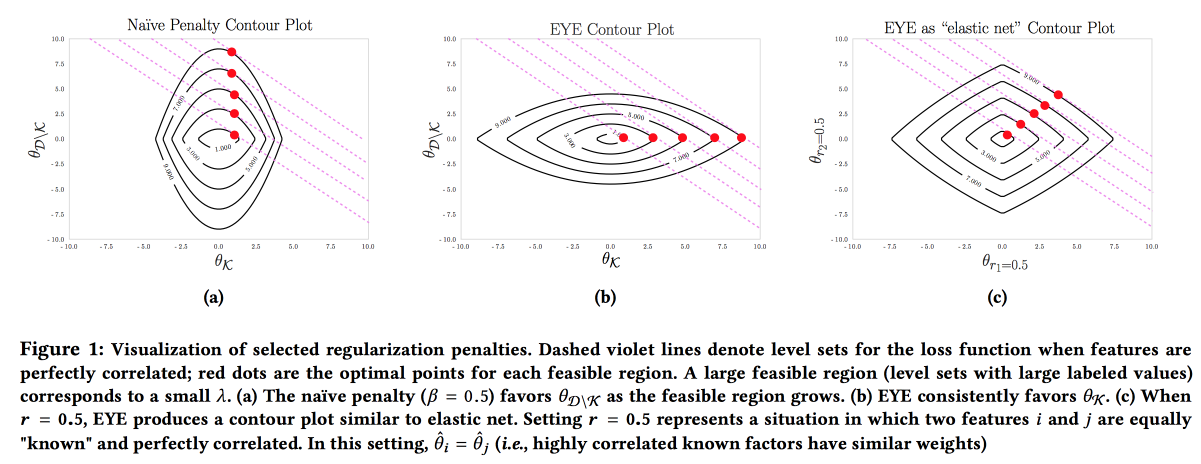
Adalah penting bahwa model itu akurat, dapat ditafsirkan, dan kuat, kita perlu menunjukkan apa yang bisa kita lakukan untuk mencegah penyakit. Model semacam itu dapat dibangun dengan secara aktif menggunakan pengetahuan dari bidang subjek. Ini adalah keinginan untuk interpretabilitas yang sering mengurangi jumlah fitur dan mengarah pada pembuatan model-model sederhana. Tetapi bahkan model sederhana dengan ruang besar fitur kehilangan interpretabilitas, dan penggunaan L1-regularisasi sering mengarah pada fakta bahwa model tersebut secara acak memilih salah satu fitur collinear. Akibatnya, dokter tidak percaya dengan model itu, meski AUC bagus. Para penulis mengusulkan menggunakan berbagai jenis
EYE regularisasi (estimasi hasil ahli). Mengingat apakah ada data yang diketahui tentang efek pada hasil, ternyata memfokuskan model pada fitur yang diperlukan. Ini memberikan hasil yang baik, bahkan jika ahli mengacaukan, apalagi, dengan membandingkan kualitas dengan peraturan standar, Anda dapat mengevaluasi seberapa ahli benar.
Selanjutnya, kita lanjutkan ke analisis deret waktu. Ternyata bahwa untuk meningkatkan kualitas di dalamnya, penting untuk mencari invarian (pada kenyataannya - mengarah pada beberapa bentuk kanonik). Dalam sebuah
artikel baru -
baru ini, sekelompok profesor mengusulkan pendekatan berdasarkan dua jaringan konvolusional. Yang pertama, Sequence Transformer, membawa seri ke bentuk kanonik, dan yang kedua, Sequence Decoder, memecahkan masalah klasifikasi.
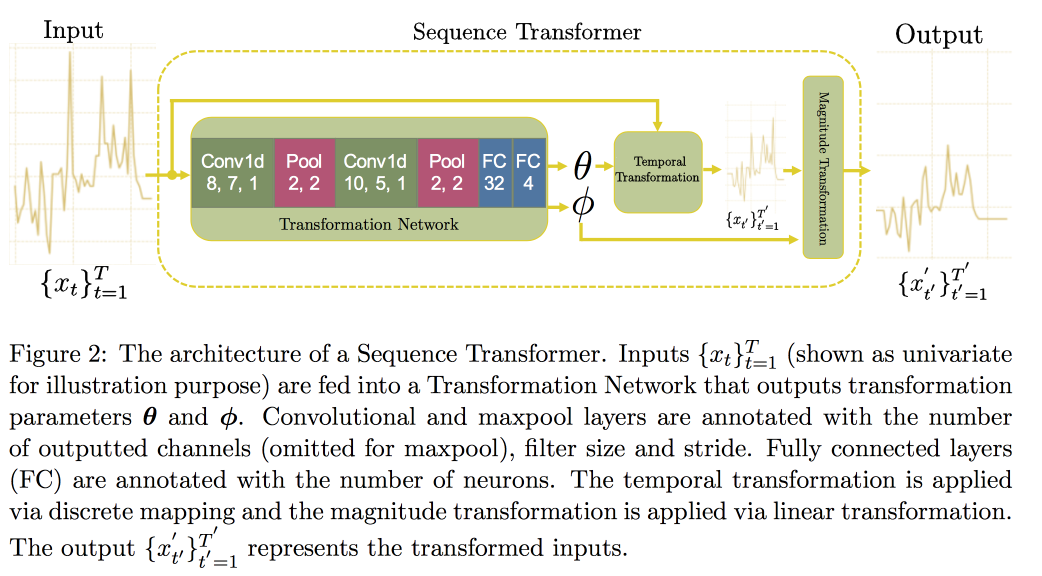
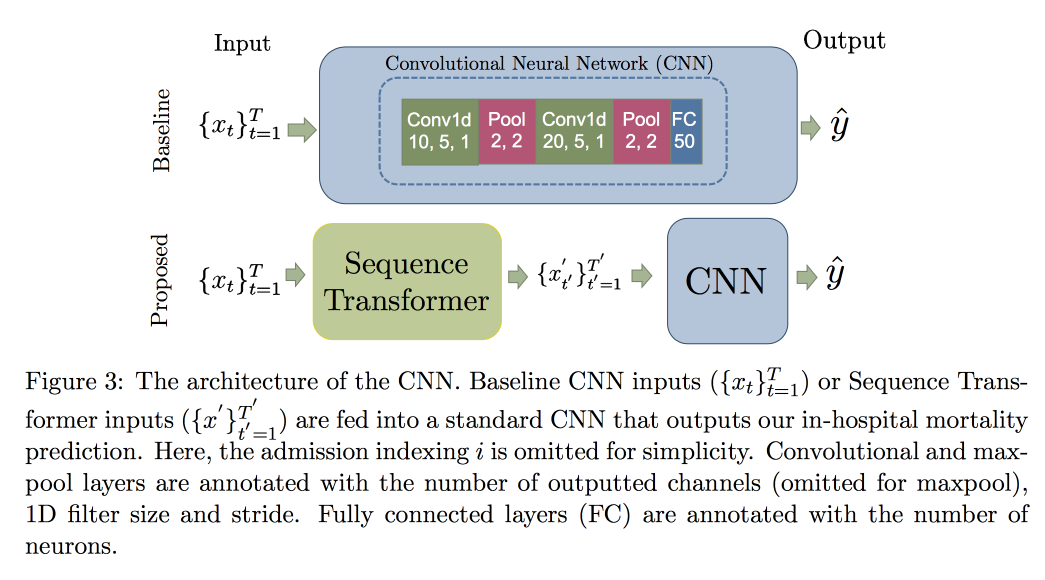
Penggunaan CNN, bukan RNN, dijelaskan oleh fakta bahwa mereka bekerja dengan baris dengan panjang tetap. Diperiksa pada
dataset MIMIC, mencoba memprediksi kematian di rumah sakit dalam waktu 48 jam. Hasilnya adalah peningkatan 0,02 AUC dibandingkan dengan CNN polos dengan lapisan tambahan, tetapi interval kepercayaan tumpang tindih.
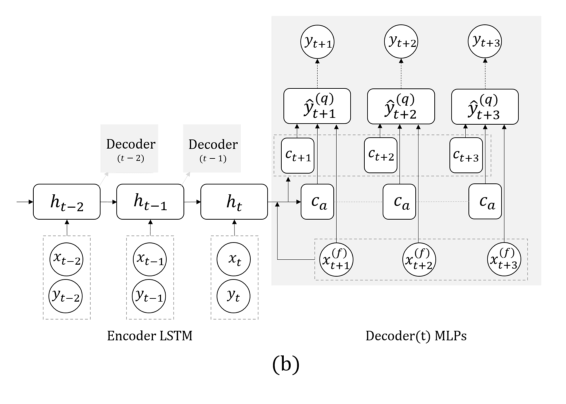
Sekarang tugas lain: kita hanya akan memperkirakan berdasarkan seri aktual, tanpa sinyal eksternal (yang memakan, dll.). Di sini, tim mengusulkan mengganti RNN untuk memprediksi beberapa langkah ke depan dengan grid dengan beberapa output, tanpa rekursi di antara mereka. Penjelasan untuk solusi ini adalah bahwa kesalahan tidak menumpuk selama rekursi. Gabungkan teknik ini dengan yang sebelumnya (cari invarian). Segera setelah presentasi profesor, postdoc berbicara secara rinci tentang model ini, jadi di sini kita berakhir, mencatat bahwa ketika memvalidasi penting untuk melihat tidak hanya pada kesalahan umum, tetapi juga pada kesalahan klasifikasi dari kasus berbahaya glukosa terlalu tinggi atau rendah.
Saya mengajukan pertanyaan tentang umpan balik dari model: sementara ini adalah pertanyaan yang sangat terbuka, mereka mengatakan bahwa kita harus mencoba memahami perubahan dalam distribusi gejala yang terjadi sebagai akibat dari fakta intervensi, dan yang merupakan pergeseran alami yang disebabkan oleh faktor eksternal. Sebenarnya, adanya perubahan seperti itu sangat menyulitkan situasi: tidak mungkin untuk melatih ulang model, karena kualitasnya menurun, pencampuran secara acak (tidak memperlakukan seseorang dan memeriksa apakah akan mati) tidak etis, tetapi untuk belajar dari data di mana semua orang diperlakukan sesuai dengan rekomendasi model dijamin bias ...
Pembuatan jalur sampel
Contoh bagaimana tidak membuat presentasi: sangat cepat, bahkan sulit untuk mendengar, dan untuk menangkap ide hampir tidak mungkin. Pekerjaan itu sendiri tersedia di
sini .
Mereka mengembangkan hasil perkiraan sebelumnya beberapa langkah ke depan. Ada dua ide utama dalam karya sebelumnya: alih-alih RNN, gunakan jaringan dengan beberapa output untuk titik waktu yang berbeda, plus alih-alih angka tertentu kami mencoba untuk memprediksi distribusi dan mengevaluasi kuantil. Ini semua disebut
MQ-RNN / CNN (Multi-Horizont forecasting Quantile regression).
Kali ini kami mencoba untuk memperbaiki perkiraan menggunakan postprocessing. Dianggap dua pendekatan. Sebagai bagian dari yang pertama, kami mencoba untuk “mengkalibrasi” distribusi jaringan saraf menggunakan data posterior dan mempelajari matriks kovarian keluaran dan pengamatan, yang disebut Covariance Shrinkage. Metode ini cukup sederhana dan berfungsi, tetapi saya ingin lebih. Pendekatan kedua adalah menggunakan model generatif untuk membangun "sampel jalur": mereka menggunakan pendekatan generatif untuk peramalan (GAN, VAE). Hasil yang bagus, tetapi tidak stabil diperoleh dengan bantuan
WaveNet, yang dikembangkan untuk
generasi suara.
Grafik Terstruktur Jaringan
Sebuah karya yang menarik tentang transfer "pengetahuan tentang area subjek" di jaringan saraf. Mereka menunjukkan contoh memprediksi tingkat kejahatan dalam ruang (berdasarkan wilayah kota) dan waktu (berdasarkan hari dan jam). Kesulitan utama: data jarang yang kuat dan keberadaan acara lokal yang langka. Akibatnya, banyak metode tidak berfungsi dengan baik, rata-rata masih mungkin ditebak setiap hari, tetapi tidak untuk area dan jam tertentu. Mari kita coba menggabungkan struktur tingkat tinggi dan mikropattern dalam satu jaringan saraf.
Kami membangun grafik komunikasi menggunakan kode pos dan menentukan pengaruh satu sama lain menggunakan
Proses Multivariat Hawkes . Selanjutnya, berdasarkan grafik yang diperoleh, kami membangun topologi jaringan saraf, menghubungkan blok-blok wilayah kota dengan kejahatan yang menunjukkan korelasi.
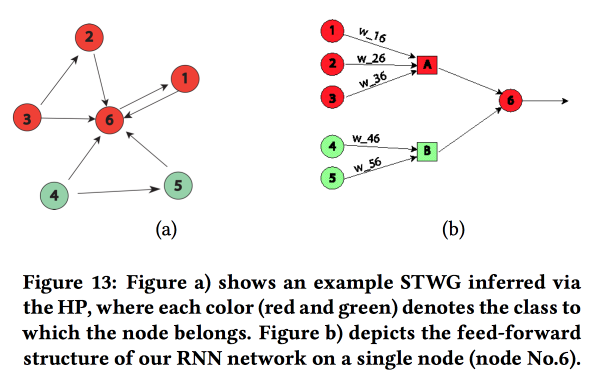
Kami membandingkan pendekatan ini dengan dua yang lain: pelatihan pada grid untuk kabupaten atau pada grid untuk sekelompok daerah dengan tingkat kejahatan yang sama, menunjukkan peningkatan akurasi. Untuk setiap wilayah, LSTM dua lapisan dengan dua lapisan yang terhubung penuh diperkenalkan.
Selain kejahatan, mereka juga menunjukkan contoh pekerjaan prediksi lalu lintas. Di sini, grafik untuk membangun jaringan sudah diambil secara geografis oleh kNN. Tidak sepenuhnya jelas berapa banyak hasil mereka dapat dibandingkan dengan yang lain (mereka secara bebas mengubah metrik dalam analisis), tetapi secara umum, heuristik untuk membangun jaringan terlihat memadai.
Pendekatan nonparametrik untuk peramalan ensemble
Ensembel adalah topik yang sangat populer, tetapi cara memperoleh hasil dari ramalan individu tidak selalu jelas. Dalam karya mereka, penulis mengusulkan
pendekatan baru .
Seringkali ansambel sederhana berfungsi dengan baik, bahkan lebih baik. dari
model Bayesian bermodel rata-rata dan rata-rata-NN. Regresi juga tidak buruk, tetapi sering memberikan hasil yang aneh dalam hal memilih bobot (misalnya, itu akan memberikan beberapa perkiraan bobot negatif, dll.). Bahkan, alasan untuk ini sering terletak pada kenyataan bahwa metode agregasi menggunakan beberapa asumsi tentang bagaimana kesalahan ramalan didistribusikan (misalnya, menurut Gauss atau normal), tetapi ketika digunakan, mereka lupa untuk memeriksa asumsi ini. Para penulis berusaha untuk mengusulkan pendekatan bebas asumsi.
Kami mempertimbangkan dua proses acak: Data Generation Process (DGP) memodelkan kenyataan dan dapat bergantung pada waktu, dan Forecast Generation Process (FGP) memodelkan konstruksi perkiraan (ada banyak dari mereka - satu untuk setiap anggota ensemble). Perbedaan antara kedua proses ini juga merupakan proses acak, yang akan kami coba analisis.
- Kami mengumpulkan data historis dan menyusun kepadatan distribusi kesalahan untuk para prediktor menggunakan Estimasi Kerapatan Kernel.
- Selanjutnya, kami membuat prakiraan dan mengubahnya menjadi variabel acak dengan menambahkan kesalahan yang dibuat.
- Kemudian kami memecahkan masalah memaksimalkan kemungkinan.
Metode yang dihasilkan hampir seperti EMOS (Ensemble Model Output Statistics) dengan kesalahan Gaussian dan jauh lebih baik dengan non-Gaussian. Seringkali dalam kenyataannya, misalnya, (
Wikipedia Page Traffic Dataset ) adalah kesalahan non-Gaussian.
Nested LSTM: Pemodelan Taksonomi dan Dinamika Temporal di Jejaring Sosial Berbasis Lokasi
Karya tersebut dikirimkan oleh penulis dari Google. Kami mencoba memprediksi cek pengguna berikutnya. menggunakan sejarah chekin dan metadata tempat baru-baru ini, pertama-tama, hubungannya dengan tag / kategori. Kategori ini tiga tingkat, kami menggunakan dua tingkat atas: kategori induk menggambarkan niat pengguna (misalnya, keinginan untuk makan), dan kategori anak menggambarkan preferensi pengguna (misalnya, pengguna menyukai makanan Spanyol). Kategori anak perusahaan dari cek berikutnya harus ditunjukkan untuk mendapatkan lebih banyak pendapatan dari iklan online.
Kami menggunakan dua LSTM bersarang: yang atas, seperti biasa, sesuai dengan urutan pemeriksaan, dan yang bersarang - sesuai dengan transisi dalam pohon kategori dari induk ke anak.
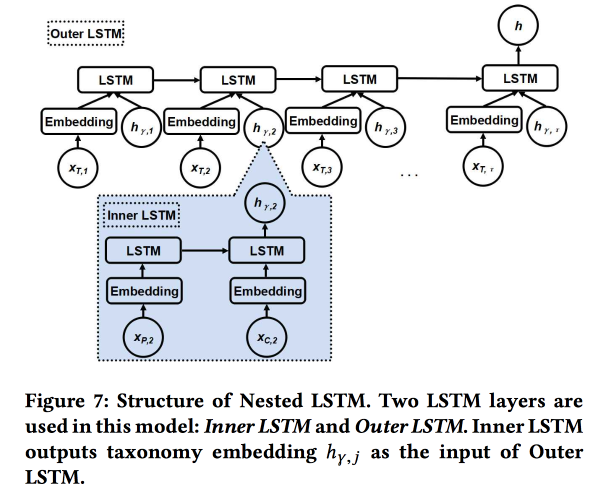
Ternyata 5-7% lebih baik dibandingkan dengan LSTM sederhana dengan embeddings kategori mentah. Selain itu, kami menunjukkan bahwa persimpangan transisi LSTM di pohon kategori terlihat lebih indah daripada yang sederhana dan lebih baik berkerumun.
Mengidentifikasi Pergeseran dalam Ruang Semantik Evolusi
Pidato
profesor China yang cukup ceria. Intinya adalah mencoba memahami bagaimana kata-kata mengubah artinya.
Sekarang semua orang berhasil melatih embeddings kata, mereka bekerja dengan baik, tetapi dilatih pada waktu yang berbeda tidak cocok untuk perbandingan - Anda perlu melakukan allining.
- Anda dapat mengambil yang lama untuk inisialisasi, tetapi ini tidak memberikan jaminan.
- Anda dapat mempelajari fungsi transformasi untuk allining, tetapi tidak selalu berfungsi, karena dimensi tidak selalu dibagi secara merata.
- Dan Anda dapat menggunakan topologi, bukan ruang vektor!
Pada akhirnya, esensi solusinya: kita membangun grafik knNN di tetangga kata dalam periode yang berbeda untuk menilai perubahan makna, dan mencoba memahami apakah ada perubahan signifikan. Untuk ini kami menggunakan model
Bayesian Surprise . Faktanya, kita melihat
divergensi KL dari distribusi hipotesis (sebelumnya) dan hipotesis yang diamati (posterior) - ini mengejutkan. Dengan kata-kata dan grafik cnn, kami menggunakan Dirichlet berdasarkan frekuensi tetangga di masa lalu sebagai distribusi a priori dan membandingkannya dengan multinomial nyata dalam sejarah baru-baru ini. Total:
- Kami memotong ceritanya.
- Kami membangun embedings (LINE dengan pelestarian inisialisasi).
- Kami mempertimbangkan KNN pada embed.
- Hargai kejutannya.
Kami memvalidasi dengan mengambil dua kata acak dengan frekuensi yang sama, dan bertukar satu sama lain - peningkatan kualitas sebagai kejutan adalah 80%. Kemudian kita mengambil 21 kata dengan makna yang diketahui dan melihat apakah kita dapat menemukannya secara otomatis. Sumber terbuka belum memiliki deskripsi terperinci tentang pendekatan ini, tetapi
ada satu di SIGIR 2018 .
AdKDD & TargetAd
Setelah makan siang, saya pindah ke sebuah seminar tentang periklanan online. Ada lebih banyak pembicara dari industri dan semua orang berpikir tentang cara menghasilkan lebih banyak uang.
Teknologi iklan di airbnb
Menjadi perusahaan besar dengan tim DS yang besar, AirBnB berinvestasi cukup banyak dalam mempromosikan dirinya sendiri dan penawaran internalnya di situs eksternal. Salah satu pengembang berbicara sedikit tentang tantangan.
Mari kita mulai dengan beriklan di mesin pencari: ketika mencari hotel di Google, dua halaman pertama adalah iklan :(. Tetapi pengguna bahkan sering tidak memahami ini, karena iklan itu sangat relevan. Skema standar: kami mencocokkan permintaan untuk iklan dengan kata kunci dan kami mendapatkan arti dari pola / pola ( kota, murah atau mewah, dll.)
Setelah para kandidat dipilih, kami mengatur pelelangan di antara mereka (sekarang
Generalized Second Price digunakan di mana-mana). Saat berpartisipasi dalam pelelangan, tujuannya adalah untuk memaksimalkan efek pada anggaran tetap, menggunakan model dengan kombinasi probabilitas klik dan penghasilan: Tawaran = P (klik | kueri pencarian) * nilai pemesanan. Poin penting: jangan menghabiskan semua uang terlalu cepat, jadi tambahkan Menghabiskan pacer.
AirBnB memiliki sistem yang kuat untuk pengujian A / B, tetapi itu tidak dapat diterapkan di sini, karena ia mengontrol sebagian besar proses Google. Di sana mereka berjanji untuk menambahkan lebih banyak alat untuk pengiklan, pemain besar benar-benar menantikan.
Masalah terpisah: kontak pengguna dengan iklan di beberapa tempat. Kami bepergian rata-rata beberapa kali setahun, siklus mempersiapkan perjalanan dan pemesanan sangat lama (minggu dan bahkan bulan), ada beberapa saluran di mana kami dapat menjangkau pengguna, dan kami perlu membagi anggaran dengan saluran. Topik ini sangat menyakitkan, ada metode sederhana (linear, hati-hati, dengan klik terakhir atau hasil
tes pengangkatan ). AirBnB mencoba dua pendekatan baru: berdasarkan pada model Markov dan
model Shapley .
Dengan model Markov, semuanya kurang lebih jelas: kami sedang membangun rantai diskrit, titik-titik yang terkait dengan titik kontak dengan iklan, ada juga simpul untuk konversi. Menurut data, kami memilih bobot untuk transisi, memberikan lebih banyak anggaran untuk simpul-simpul di mana probabilitas transisi lebih besar. Saya melemparkan mereka pertanyaan: mengapa menggunakan rantai Markov sederhana, sementara itu lebih logis untuk menggunakan MDP; Mereka berkata bahwa mereka sedang mengerjakan topik ini.
Lebih menarik dengan Shapley: pada kenyataannya, ini adalah skema yang telah lama dikenal untuk mengevaluasi efek aditif, di mana kombinasi efek yang berbeda dipertimbangkan, efek masing-masing dievaluasi, dan kemudian agregat untuk masing-masing efek individu ditentukan. Kesulitannya adalah bahwa ada sinergi antara efek (lebih jarang antagonisme), dan hasil penjumlahan tidak sama dengan jumlah hasil. Secara umum, teori yang agak menarik dan indah, saya
sarankan Anda membaca .
Dalam kasus AirBnB, penerapan model Shapley terlihat seperti ini:
- Kami memiliki dalam contoh data yang diamati dengan kombinasi efek yang berbeda dan hasil yang sebenarnya.
- Isi kekosongan dalam data (tidak semua kombinasi disajikan) menggunakan ML.
- Kami menghitung pinjaman untuk setiap jenis dampak Shapley.
Microsoft: Mendorong Batas {AI}
Selanjutnya sedikit tentang itu. karena Microsoft terlibat dalam periklanan, sekarang dari sisi situs, terutama Bing. Sedikit pembantaian:
- Pasar periklanan berkembang sangat pesat (secara eksponensial).
- Beriklan di satu halaman saling meng kanibal, Anda perlu menganalisis seluruh halaman.
- Konversi pada beberapa halaman lebih tinggi, meskipun kenyataannya CTP lebih buruk.
Ada sekitar 70 model dalam mesin iklan Bing, 2000 percobaan offline, 400 online. Satu perubahan signifikan dalam platform setiap minggu. Secara umum, mereka bekerja tanpa lelah. Apa saja perubahan di platform:
- Mitos satu metrik: itu tidak berhasil seperti itu, metrik tumbuh dan bersaing.
- Kami mendesain ulang sistem permintaan pencocokan iklan dari NLP ke DL, yang dihitung pada FPGA.
- Mereka menggunakan model federal dan bandit kontekstual: model internal menghasilkan probabilitas dan ketidakpastian, bandit dari atas membuat keputusan. Dia banyak berbicara tentang bandit, mereka digunakan untuk meluncurkan model dan meluncurkan dengan kecepatan jelajah, mereka menghindari fakta bahwa sering meningkatkan model mengarah pada pendapatan yang lebih rendah :(
- Sangat penting untuk mengevaluasi ketidakpastian (ya, tanpa itu Anda tidak dapat membangun bandit).
- Untuk pengiklan kecil, lembaga periklanan melalui bandit tidak berfungsi, ada sedikit statistik, perlu untuk membuat model terpisah untuk awal yang dingin.
- Penting untuk memantau kinerja pada kelompok pengguna yang berbeda, mereka memiliki sistem otomatis untuk mengiris sesuai dengan hasil percobaan.
Kami berbicara sedikit tentang analisis aliran keluar. Tidak selalu hipotesis penjual tentang penyebab arus keluar itu benar, Anda perlu menggali lebih dalam. Untuk melakukan ini, Anda harus membangun model yang dapat ditafsirkan (atau model khusus untuk menjelaskan perkiraan) dan banyak berpikir. Dan kemudian lakukan percobaan. Tetapi selalu sulit untuk melakukan percobaan dengan arus keluar, mereka merekomendasikan menggunakan metrik orde kedua dan
artikel dari Google .
Mereka juga menggunakan apa yang disebut Grafik Pengetahuan Komersial, yang menggambarkan bidang subjek: merek, produk, dll. Grafik dibangun sepenuhnya secara otomatis, tanpa pengawasan. Merek ditandai dengan kategori, ini penting, karena secara umum tidak selalu mungkin untuk tidak diawasi untuk mengisolasi merek secara keseluruhan, tetapi dalam kategori-topik tertentu sinyal lebih kuat. Sayangnya, saya tidak menemukan karya terbuka dengan metode mereka.
Iklan Google
Bung yang sama yang kemarin berbicara tentang hitungan mengatakan, semuanya sama sedih dan sombong. Berjalan di beberapa topik.
Bagian Satu: Alokasi Iklan Stochastic yang Kuat. Kami memiliki simpul yang dianggarkan (iklan) dan simpul online (pengguna), dan ada juga beberapa bobot di antaranya. Sekarang Anda harus memilih iklan mana yang menunjukkan simpul baru. Anda dapat melakukannya dengan rakus (selalu dengan berat maksimum), tetapi kemudian kami berisiko mengerjakan anggaran sebelum waktunya dan mendapatkan solusi yang tidak efektif (batas teoretis 1/2 dari yang optimal). Anda dapat menangani ini dengan cara yang berbeda, pada kenyataannya, di sini kita memiliki konflik tradisional antara revenu dan wellfair.
Saat memilih metode alokasi, seseorang dapat mengasumsikan urutan acak dari node online sesuai dengan beberapa distribusi, tetapi dalam praktiknya mungkin juga ada urutan permusuhan (mis. Dengan elemen dari beberapa efek yang berlawanan). Metode dalam kasus ini berbeda, mereka memberikan tautan ke artikel terbaru mereka:
1 dan
2 .
Bagian Dua: Pembelajaran sadar-sadar / Penetapan Harga yang Kuat. Sekarang kami mencoba menyelesaikan pertanyaan tentang memilih harga pemesanan untuk meningkatkan pendapatan situs iklan. Kami juga mempertimbangkan penggunaan lelang lainnya seperti
lelang Myerson ,
BINTAC , rollback ke lelang harga pertama jika terjadi kontak dengan reservasi. Mereka tidak masuk ke detail, mereka mengirim ke
artikel mereka .
Bagian Tiga: Bundling Online. Sekali lagi, kami memecahkan masalah peningkatan pendapatan, tetapi sekarang kami pergi dari sisi lain. Jika Anda dapat membeli iklan dalam jumlah besar (bundling offline), maka dalam banyak situasi Anda dapat menawarkan solusi yang lebih optimal. Tetapi Anda tidak dapat melakukan ini dalam lelang online, Anda harus membangun model yang kompleks dengan memori, dan dalam kondisi yang sulit RTB tidak mendorongnya.
Kemudian model ajaib muncul, di mana semua memori dikurangi menjadi satu digit (rekening bank), tetapi waktu habis, dan pembicara mulai dengan panik membalik-balik slide. , ,
.
Deep Policy optimization by Alibaba
«sponsored search». RL, — .
.
offline- , , online-, .
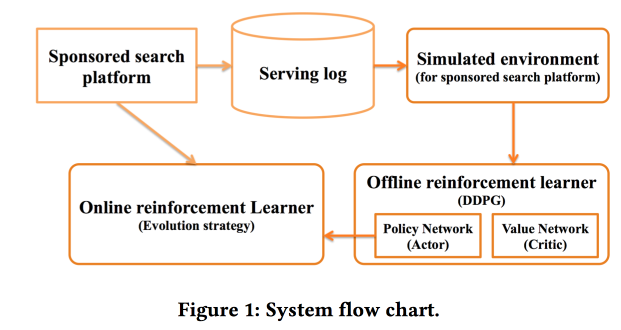
CTR ,
DDPG .
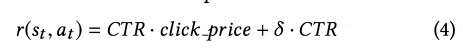
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
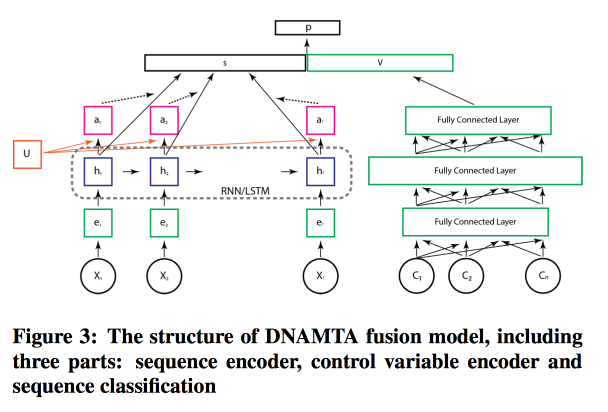
, attention- .
Kesimpulan
Kemudian ada sesi pembukaan patho dengan video IMAX dalam tradisi terbaik dari trailer blockbuster, banyak terima kasih kepada semua orang yang membantu mengatur semua ini - sebuah rekor KDD dalam segala hal (termasuk $ 1,2 juta dalam sponsor), kata-kata perpisahan dari Lord Bytes (Menteri Inovasi) UK) dan sesi poster yang tidak lagi memiliki kekuatan. Kita harus bersiap untuk besok.