Dipercayai bahwa pengembangan membutuhkan sekitar 10% dari waktu, dan debugging membutuhkan 90%. Mungkin pernyataan ini dilebih-lebihkan, tetapi pengembang mana pun akan setuju bahwa debugging adalah proses yang sangat intensif sumber daya, terutama dalam sistem multi-utas besar.
Dengan demikian, optimasi dan sistematisasi dari proses debugging dapat membawa manfaat yang signifikan dalam bentuk jam kerja yang disimpan, meningkatkan kecepatan penyelesaian masalah dan, pada akhirnya, meningkatkan loyalitas pengguna Anda.
 Sergey Shchegrikovich
Sergey Shchegrikovich (dotmailer) pada konferensi
DotNext 2018 Piter menyarankan untuk melihat debugging sebagai proses yang dapat dijelaskan dan dioptimalkan. Jika Anda masih belum memiliki rencana yang jelas untuk menemukan bug - di bawah potongan video dan transkrip teks dari laporan Sergey.
(Dan di akhir posting, kami menambahkan permohonan
John Skeet ke semua afiliasi, pastikan untuk melihat)
Tujuan saya adalah menjawab pertanyaan: bagaimana memperbaiki bug secara efisien dan apa yang harus menjadi fokus. Saya pikir jawaban untuk pertanyaan ini adalah sebuah proses. Proses debugging, yang terdiri dari aturan yang sangat sederhana, dan Anda mengetahuinya dengan baik, tetapi Anda mungkin menggunakannya tanpa sadar. Karena itu, tugas saya adalah mensistematisasikan mereka dan menunjukkan bagaimana menjadi lebih efektif menggunakan contoh.
Kami akan mengembangkan bahasa umum untuk komunikasi selama debugging, dan kami juga akan melihat jalur langsung untuk menemukan masalah utama. Pada contoh saya, saya akan menunjukkan apa yang terjadi karena pelanggaran aturan ini.
Utilitas Debug
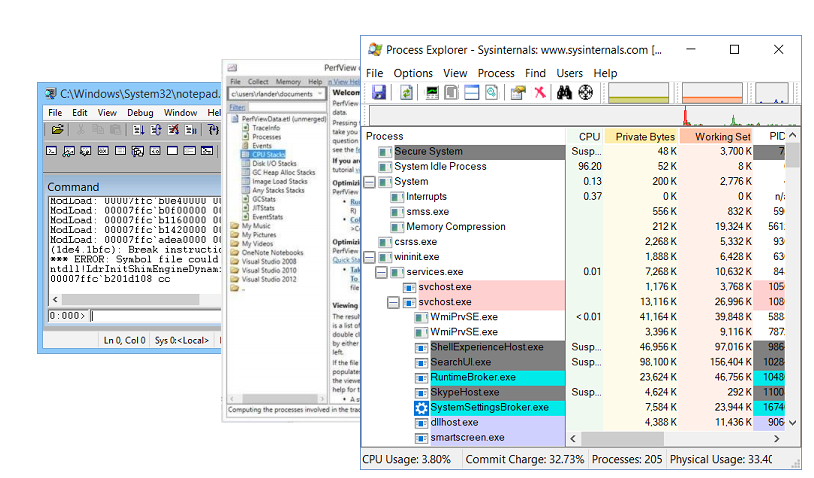
Tentu saja, debugging apa pun tidak dimungkinkan tanpa utilitas debugging. Favorit saya adalah:
- Windbg , yang di samping debugger itu sendiri, memiliki fungsi yang kaya untuk mempelajari dump memori. Memori dump adalah sepotong keadaan proses. Di dalamnya Anda dapat menemukan nilai bidang objek, tumpukan panggilan, tetapi, sayangnya, dump memori statis.
- PerfView adalah profiler yang ditulis di atas teknologi ETW .
- Sysinternals adalah utilitas yang ditulis oleh Mark Russinovich , yang memungkinkan Anda untuk menggali sedikit lebih jauh ke dalam perangkat sistem operasi.
Layanan jatuh
Mari kita mulai dengan contoh dari hidup saya di mana saya akan menunjukkan bagaimana sifat tidak sistematis dari proses debugging mengarah pada inefisiensi.
Mungkin, ini terjadi pada semua orang, ketika Anda datang ke perusahaan baru dalam tim baru untuk proyek baru, maka sejak hari pertama Anda ingin melakukan manfaat yang tidak dapat diperbaiki. Begitu juga dengan saya. Pada saat itu, kami memiliki layanan yang menerima html untuk input, dan gambar output untuk output.
Layanan ini ditulis di bawah .Net 3.0 dan sudah sangat lama. Layanan ini memiliki fitur kecil - macet. Jatuh sesering mungkin, sekitar sekali setiap dua atau tiga jam. Kami memperbaiki ini secara elegan - mengatur properti mulai ulang di properti layanan setelah musim gugur.
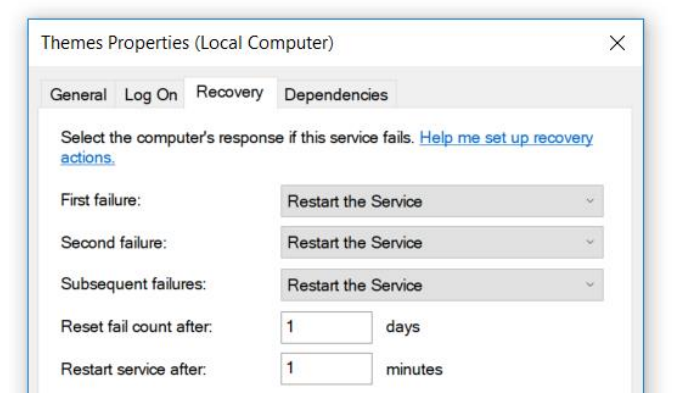
Layanan itu tidak penting bagi kami dan kami bisa bertahan. Tetapi saya bergabung dengan proyek dan hal pertama yang saya putuskan adalah memperbaikinya.
Di mana pengembang .NET pergi jika ada sesuatu yang tidak berfungsi? Mereka pergi ke EventViewer. Tetapi di sana saya tidak menemukan apa pun kecuali catatan bahwa layanan itu jatuh. Tidak ada pesan tentang kesalahan asli, atau tumpukan panggilan.
Ada alat yang terbukti untuk apa yang harus dilakukan selanjutnya - kami membungkus seluruh
main dalam
try-catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); }
Idenya sederhana:
try-catch akan bekerja, itu akan mengganggu kita, kita akan membacanya dan memperbaiki layanan. Kami mengkompilasi, menyebarkan ke produksi, layanan macet, tidak ada kesalahan. Tambahkan
catch lain.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); }
Kami ulangi prosesnya: layanan macet, tidak ada kesalahan dalam log. Hal terakhir yang dapat membantu
finally , yang selalu disebut.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); } finally { LogEndOfExecution(); }
Kami mengkompilasi, menyebarkan, layanan macet, tidak ada kesalahan. Tiga hari berlalu di belakang proses ini, sekarang pikiran sudah datang bahwa kita akhirnya harus mulai berpikir dan melakukan sesuatu yang lain. Anda dapat melakukan banyak hal: mencoba mereproduksi kesalahan pada mesin lokal, menonton dump memori, dll. Sepertinya dua hari lagi dan saya akan memperbaiki bug ini ...
Dua minggu telah berlalu.
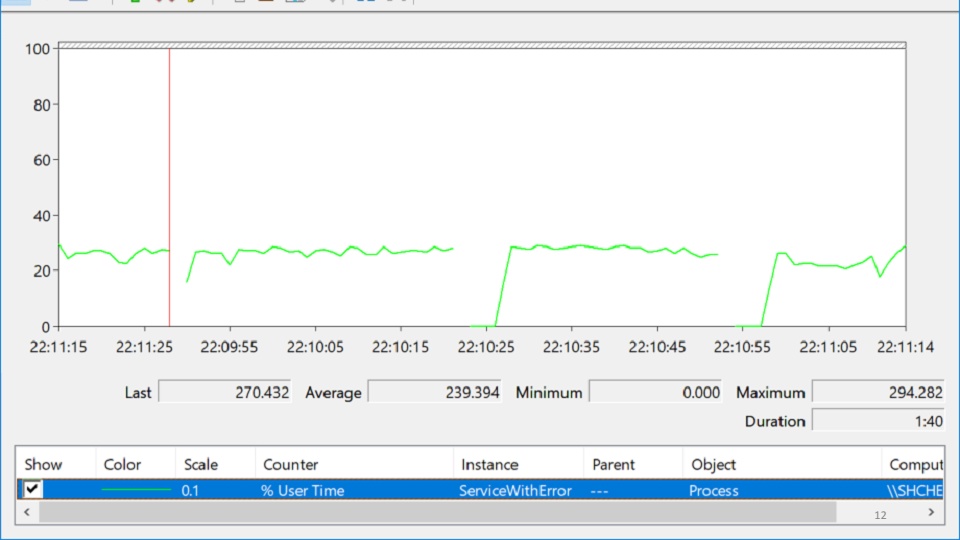
Saya mencari di PerformanceMonitor, di mana saya melihat layanan yang macet, lalu naik, lalu turun lagi. Kondisi ini disebut
keputusasaan dan terlihat seperti ini:
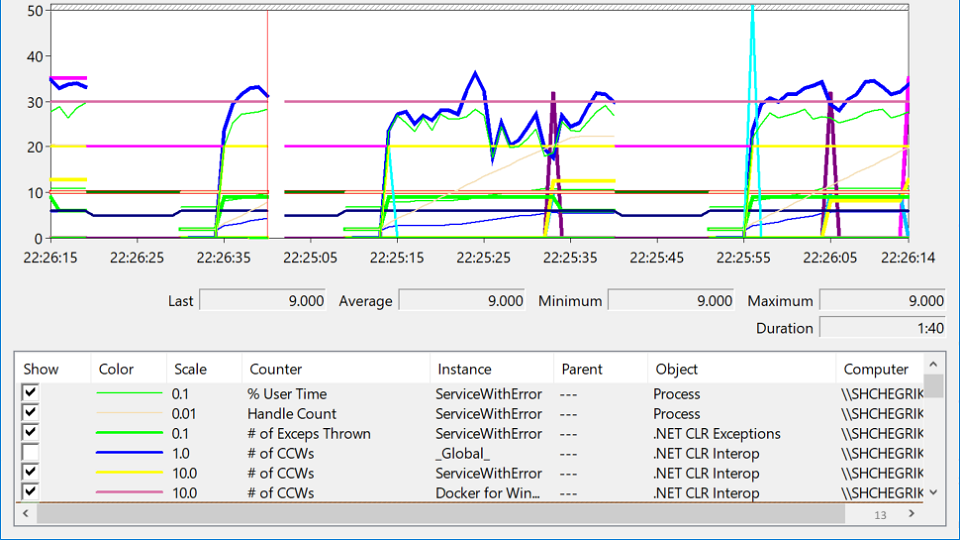
Dalam berbagai label ini, apakah Anda mencoba mencari tahu di mana masalahnya sebenarnya? Setelah beberapa jam meditasi, masalah tiba-tiba muncul:
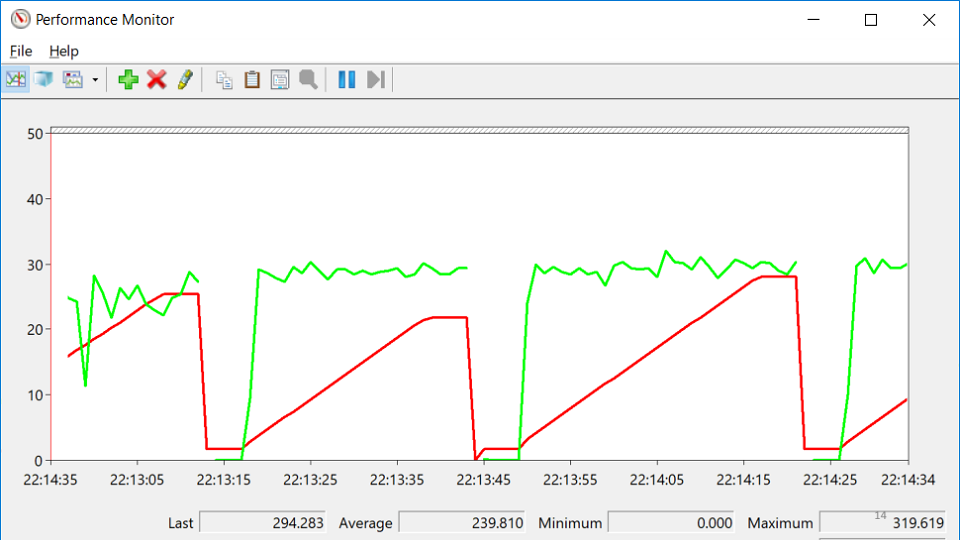
Garis merah adalah jumlah pegangan asli yang dimiliki proses. Pegangan asli adalah referensi ke sumber daya sistem operasi: file, registri, kunci registri, mutex, dll. Untuk beberapa kombinasi situasi yang aneh, penurunan dalam jumlah gagang bertepatan dengan saat-saat ketika layanan turun. Ini mengarah pada gagasan bahwa di suatu tempat ada kebocoran pegangan.
Kami mengambil dump memori, buka di WinDbg. Kami mulai menjalankan perintah. Mari kita coba untuk melihat antrian finalisasi objek-objek yang harus dibebaskan oleh aplikasi.
0:000> !FinalizeQueue
Di akhir daftar, saya menemukan browser web.
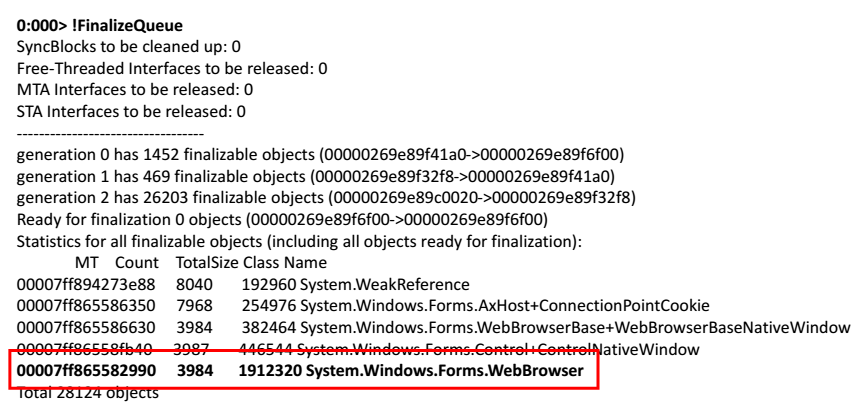
Solusinya sederhana - ambil WebBrowser dan panggil
dispose untuk itu:
private void Process() { using (var webBrowser = new WebBrowser()) {
Kesimpulan dari cerita ini dapat ditarik sebagai berikut: dua minggu terlalu lama dan terlalu lama untuk menemukan
dispose diundang; bahwa kami menemukan solusi untuk masalah ini - keberuntungan, karena tidak ada pendekatan khusus, tidak ada sifat sistematis.
Setelah itu, saya punya pertanyaan: bagaimana cara debut yang efektif dan apa yang harus dilakukan?
Untuk melakukan ini, Anda hanya perlu tahu tiga hal:
- Aturan Debugging
- Algoritma untuk menemukan kesalahan.
- Teknik debugging proaktif.
Aturan Debugging
- Ulangi kesalahan itu.
- Jika Anda belum memperbaiki kesalahan, maka itu tidak diperbaiki.
- Pahami sistemnya.
- Periksa colokannya.
- Bagilah dan taklukkan.
- Menyegarkan diri.
- Ini adalah bug Anda.
- Lima alasannya.
Ini adalah aturan yang cukup jelas yang menggambarkan diri mereka sendiri.
Ulangi kesalahan itu. Aturan yang sangat sederhana, karena jika Anda tidak dapat membuat kesalahan, maka tidak ada yang diperbaiki. Tetapi ada beberapa kasus yang berbeda, terutama untuk bug di lingkungan multi-threaded. Kami entah bagaimana memiliki kesalahan yang hanya muncul pada prosesor Itanium dan hanya pada server produksi. Oleh karena itu, tugas pertama dalam proses debugging adalah menemukan konfigurasi bangku tes tempat kesalahan akan direproduksi.
Jika Anda belum memperbaiki kesalahan, maka itu tidak diperbaiki. Kadang-kadang ini terjadi: pelacak bug berisi bug yang muncul setengah tahun yang lalu, tidak ada yang melihatnya sejak lama, dan ada keinginan untuk menutupnya. Tetapi pada saat ini kita kehilangan kesempatan untuk mengetahui, kesempatan untuk memahami cara kerja sistem kita dan apa yang sebenarnya terjadi padanya. Karenanya, bug apa pun adalah peluang baru untuk mempelajari sesuatu, mempelajari lebih lanjut tentang sistem Anda.
Pahami sistemnya. Brian Kernighan pernah berkata bahwa jika kita begitu pintar untuk menulis sistem ini, maka kita harus pintar dua kali lipat untuk memulai itu.
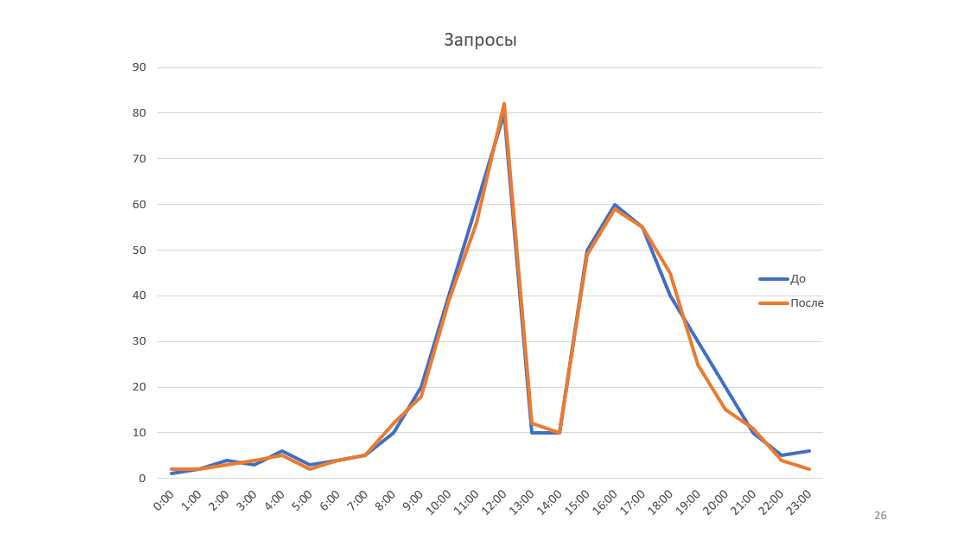
Contoh kecil untuk aturan. Pemantauan kami menggambar grafik:
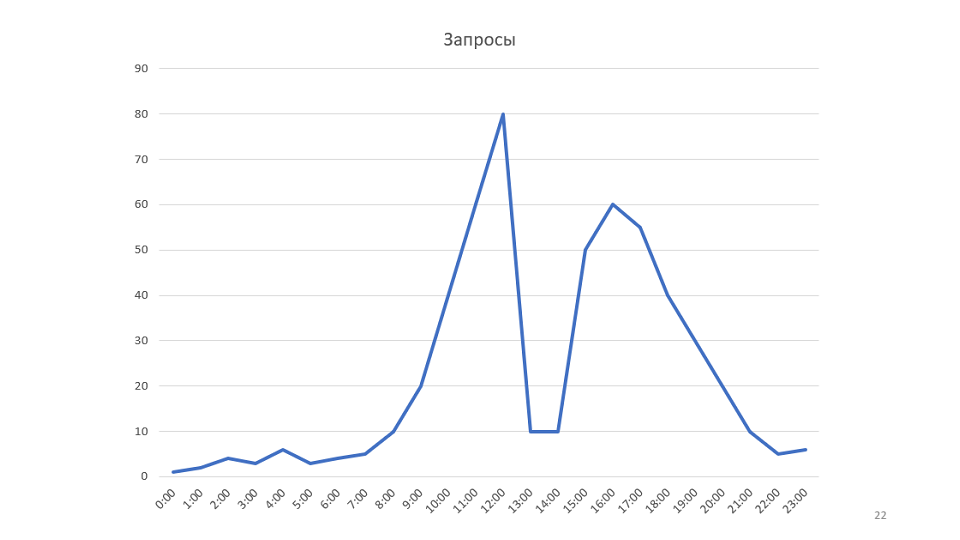
Ini adalah grafik jumlah permintaan yang diproses oleh layanan kami. Setelah melihatnya, kami datang dengan ide bahwa mungkin untuk meningkatkan kecepatan layanan. Dalam hal ini, jadwal meningkat, dimungkinkan untuk mengurangi jumlah server.
Optimalisasi kinerja web dilakukan cukup: kita mengambil PerfView, menjalankannya di mesin produksi, menghilangkan jejak dalam waktu 3-4 menit, kita mengambil jejak ini ke mesin lokal dan mulai mempelajarinya.
Salah satu statistik yang ditampilkan PerfView adalah pengumpul sampah.
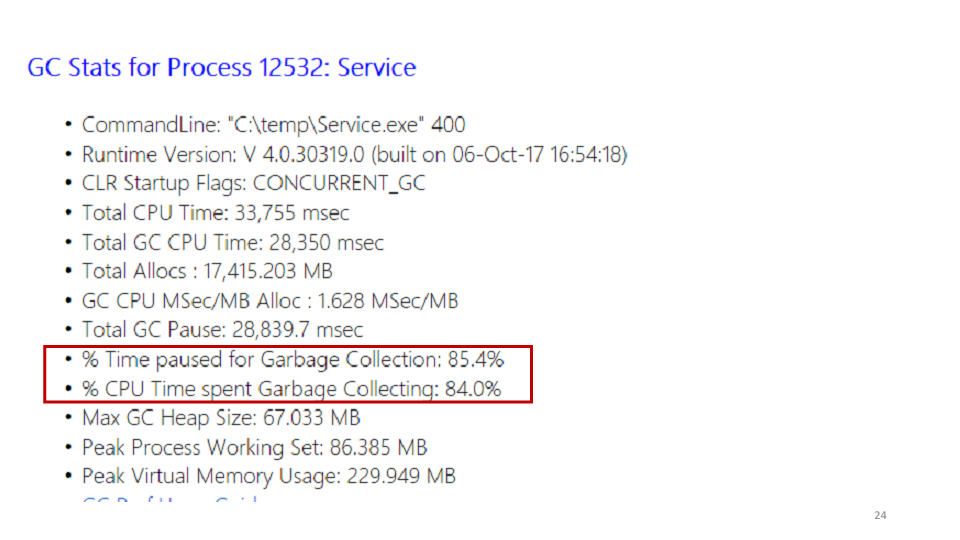
Melihat statistik ini, kami melihat bahwa layanan ini menghabiskan 85% waktunya mengumpulkan sampah. Anda dapat melihat di PerfView persis di mana waktu ini dihabiskan.
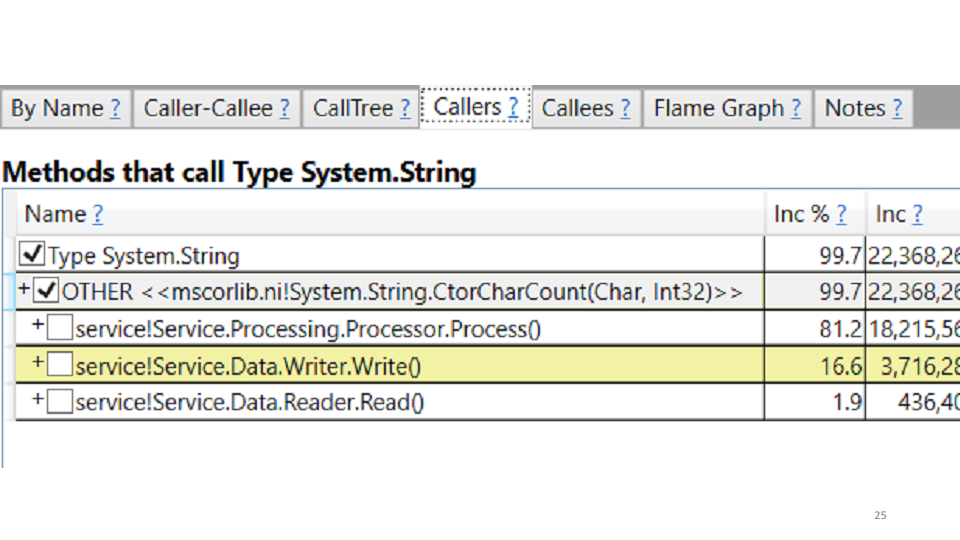
Dalam kasus kami, ini menciptakan string. Koreksi itu sendiri menunjukkan sendiri: kami mengganti semua string dengan StringBuilders. Secara lokal, kami mendapatkan peningkatan produktivitas 20-30%. Menyebarkan produksi, lihat hasilnya dibandingkan dengan jadwal lama:
Aturan "Memahami Sistem" tidak hanya tentang memahami bagaimana interaksi terjadi di sistem Anda, bagaimana pesan pergi, tetapi tentang mencoba memodelkan sistem Anda.
Dalam contoh, grafik menunjukkan bandwidth. Tetapi jika Anda melihat keseluruhan sistem dari sudut pandang teori antrian, ternyata throughput sistem kami hanya bergantung pada satu parameter - kecepatan kedatangan pesan baru. Faktanya, sistem tidak memiliki lebih dari 80 pesan sekaligus, jadi tidak ada cara untuk mengoptimalkan jadwal ini.
Periksa colokannya. Jika Anda membuka dokumentasi alat rumah, maka pasti akan tertulis di sana: jika alat tidak berfungsi, periksa apakah steker dimasukkan ke dalam stopkontak. Setelah beberapa jam di debugger, saya sering mendapati diri saya berpikir bahwa saya hanya perlu mengkompilasi ulang atau hanya mengambil versi terbaru.
Aturan "periksa colokan" adalah tentang fakta dan data. Debugging tidak dimulai dengan menjalankan WinDbg atau PerfView pada mesin produksi, itu dimulai dengan memeriksa fakta dan data. Jika layanan tidak merespons, itu mungkin tidak berjalan.
Bagilah dan taklukkan. Ini adalah aturan pertama dan mungkin satu-satunya yang menyertakan debugging sebagai suatu proses. Ini tentang hipotesis, promosi dan pengujian mereka.
Salah satu layanan kami tidak mau berhenti.
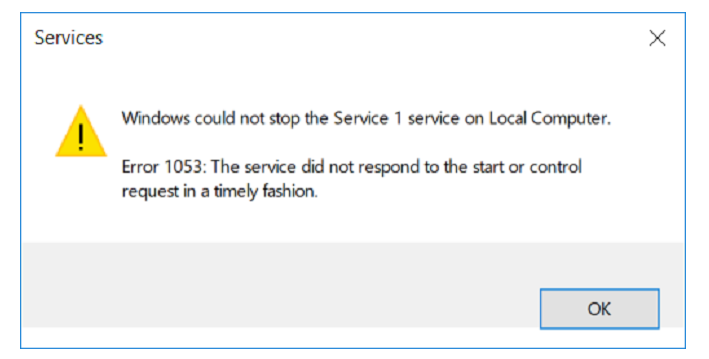
Kami membuat hipotesis: mungkin ada siklus dalam proyek yang memproses sesuatu tanpa henti.
Anda dapat menguji hipotesis dengan berbagai cara, satu opsi adalah mengambil dump memori. Kami mengeluarkan tumpukan panggilan dari dump dan semua utas menggunakan perintah
~*e!ClrStack . Kami mulai melihat dan melihat tiga aliran.
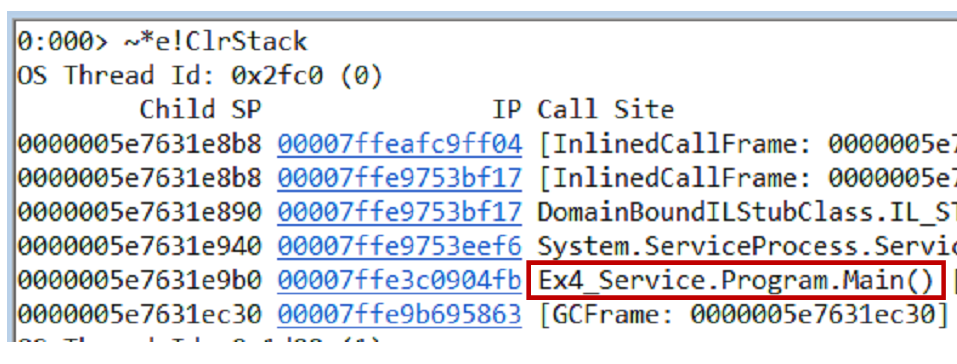
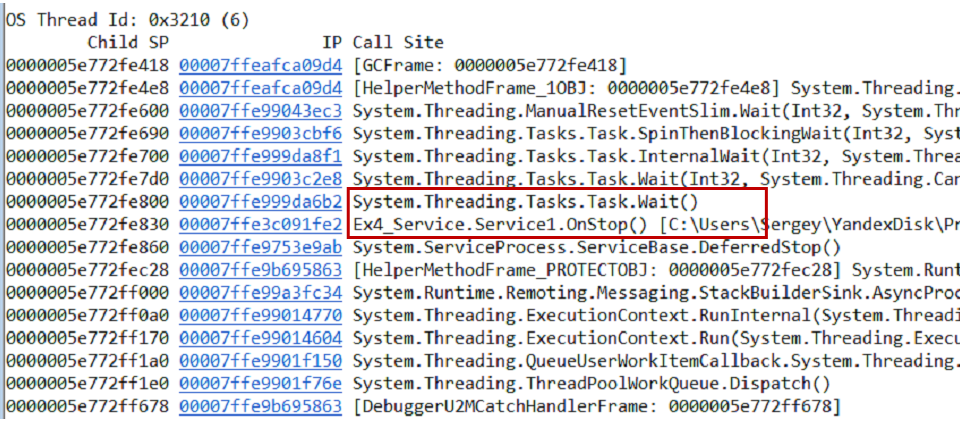
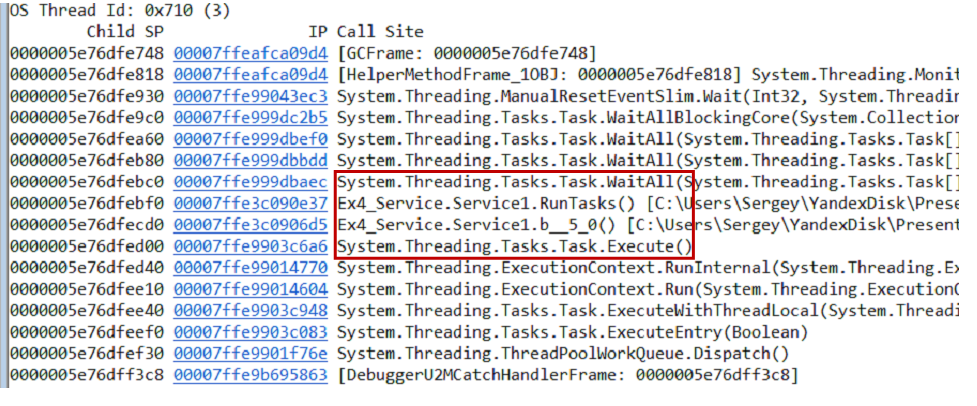
Utas pertama ada di Main, yang kedua ada di handler
OnStop() , dan utas ketiga menunggu beberapa tugas internal. Dengan demikian, hipotesis kami tidak dibenarkan. Tidak ada perulangan, semua utas sedang menunggu sesuatu. Kemungkinan besar jalan buntu.
Layanan kami berfungsi sebagai berikut. Ada dua tugas - inisialisasi dan kerja. Inisialisasi membuka koneksi ke database, pekerja mulai memproses data. Komunikasi di antara mereka terjadi melalui flag umum, yang diimplementasikan menggunakan
TaskCompletionSource .
Kami membuat hipotesis kedua: mungkin kami memiliki jalan buntu dari satu tugas untuk yang kedua. Untuk memeriksa ini, Anda dapat melihat setiap tugas secara terpisah melalui WinDbg.
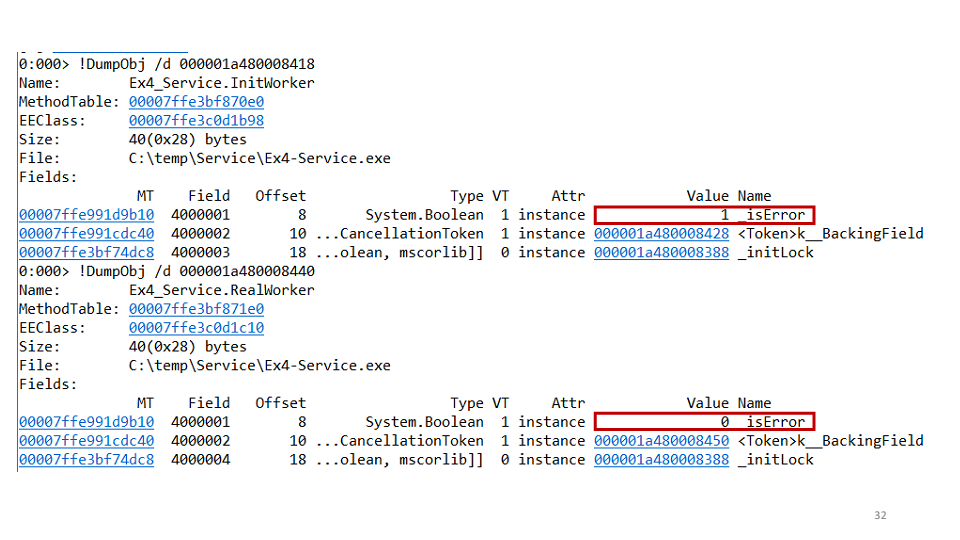
Ternyata salah satu tugas jatuh, dan yang kedua tidak. Dalam proyek tersebut, kami melihat kode berikut:
await openAsync(); _initLock.SetResult(true);
Ini berarti bahwa tugas inisialisasi membuka koneksi dan setelah itu menetapkan
TaskCompletionSource menjadi true. Tetapi bagaimana jika suatu Pengecualian jatuh di sini? Maka kita tidak punya waktu untuk mengatur
SetResult menjadi true, jadi perbaikan untuk bug ini seperti ini:
try { await openAsync(); _initLock.SetResult(true); } catch(Exception ex) { _initLock.SetException(ex); }
Dalam contoh ini, kami mengajukan dua hipotesis: loop tak terbatas dan jalan buntu. Aturan "membagi dan menaklukkan" membantu untuk melokalisasi kesalahan. Perkiraan yang berurutan memecahkan masalah seperti itu.
Hal terpenting dalam aturan ini adalah hipotesis, karena seiring waktu mereka berubah menjadi pola. Dan tergantung pada hipotesis, kami menggunakan tindakan yang berbeda.
Menyegarkan diri. Aturan ini adalah Anda hanya perlu bangkit dari meja dan berjalan, minum air, jus atau kopi, melakukan apa saja, tetapi yang paling penting adalah mengalihkan perhatian dari masalah Anda.
Ada metode yang sangat bagus yang disebut bebek. Menurut metodenya, kita harus menceritakan tentang masalah
merunduk . Anda bisa menggunakan kolega sebagai
bebek . Apalagi dia tidak harus menjawab, cukup dengarkan dan setujui. Dan seringkali, setelah pembicaraan pertama tentang masalah, Anda sendiri menemukan solusinya.
Ini adalah bug Anda. Saya akan menceritakan tentang aturan ini dengan sebuah contoh.
Ada masalah dalam satu
AccessViolationException . Mencari di tumpukan panggilan, saya melihat bahwa itu terjadi ketika kami membuat permintaan LinqToSql di dalam klien sql.

Dari bug ini jelas bahwa di suatu tempat integritas memori dilanggar. Untungnya, saat itu kami sudah menggunakan sistem manajemen perubahan. Akibatnya, setelah beberapa jam, menjadi jelas apa yang terjadi: kami memasang .Net 4.5.2 di mesin produksi kami.
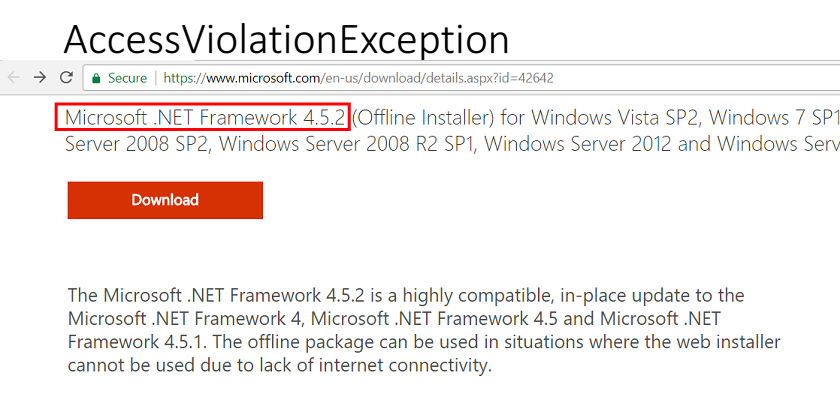
Oleh karena itu, kami mengirim bug ke Microsoft, mereka memeriksanya, kami berkomunikasi dengan mereka, mereka memperbaiki bug di .Net 4.6.1.
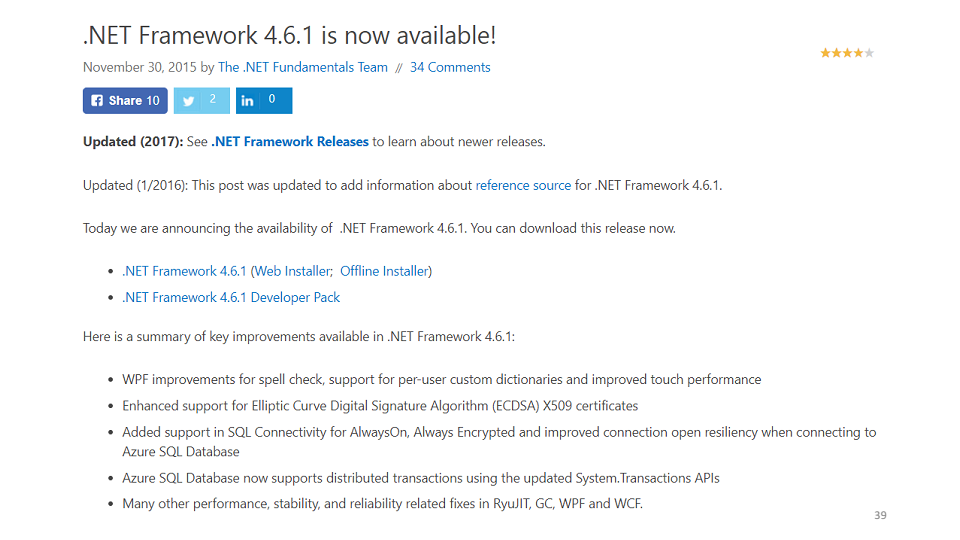
Bagi saya, ini menghasilkan 11 bulan bekerja dengan dukungan Microsoft, tentu saja, tidak setiap hari, tetapi butuh 11 bulan sejak awal untuk memperbaikinya. Selain itu, kami mengirimi mereka puluhan gigabytes dump memori, kami menempatkan ratusan rakitan pribadi untuk menangkap kesalahan ini. Dan selama ini, kami tidak bisa memberi tahu pelanggan kami bahwa Microsoft yang harus disalahkan, bukan kami. Karena itu, bug selalu menjadi milik Anda.
Lima alasannya. Kami di perusahaan kami menggunakan Elastis. Elastis bagus untuk agregasi log.
Anda datang untuk bekerja di pagi hari, dan kebohongan elastis.
Pertanyaan pertama adalah mengapa elastis? Segera menjadi jelas - Master Nodes jatuh. Mereka mengoordinasikan pekerjaan seluruh cluster dan ketika mereka jatuh, seluruh cluster berhenti merespons. Mengapa mereka tidak bangkit? Mungkin harus ada start otomatis? Setelah mencari jawabannya, kami menemukan bahwa versi plugin tidak cocok. Mengapa Master Nodes jatuh sama sekali? Mereka dibunuh oleh OOM Killer. Ini adalah hal seperti itu pada mesin linux, yang dalam kasus kekurangan memori menutup proses yang tidak perlu. Mengapa tidak ada cukup memori? Karena proses pembaruan telah dimulai, yang mengikuti dari log sistem. Mengapa itu berhasil sebelumnya, tetapi tidak sekarang? Dan karena kami menambahkan node baru seminggu sebelumnya, maka Master Nodes membutuhkan lebih banyak memori untuk menyimpan indeks, konfigurasi cluster.
Pertanyaan "mengapa?" membantu menemukan akar masalah. Dalam contoh, kita bisa mematikan jalur yang benar berkali-kali, tetapi perbaikan penuh terlihat seperti ini: kita memperbarui plugin, memulai layanan, menambah memori dan membuat catatan untuk masa depan, bahwa lain kali, ketika menambahkan node baru ke cluster, kita perlu memastikan bahwa ada cukup memori pada Master Nodes
Penerapan aturan-aturan ini memungkinkan Anda untuk mengungkapkan masalah nyata, menggeser fokus Anda untuk menyelesaikan masalah ini dan membantu untuk berkomunikasi. Tetapi akan lebih baik lagi jika aturan-aturan ini membentuk suatu sistem. Dan ada sistem seperti itu, itu disebut algoritma debugging.
Algoritma debugging
Untuk pertama kalinya, saya membaca tentang algoritma debug dalam aplikasi Debugging buku John Robbins. Ini menjelaskan proses debugging sebagai berikut:
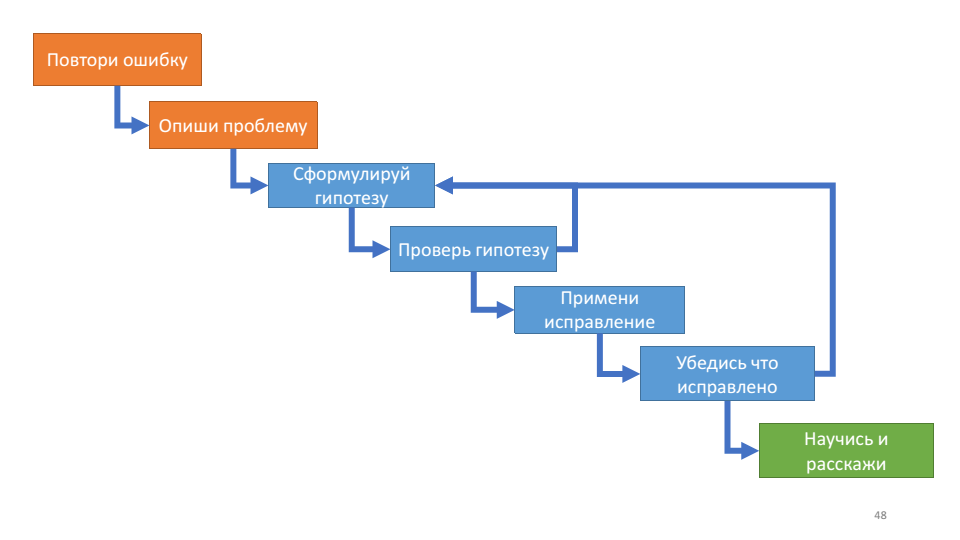
Algoritma ini berguna untuk loop dalam - bekerja dengan hipotesis.
Dengan setiap putaran siklus kita dapat memeriksa diri kita sendiri: apakah kita tahu lebih banyak tentang sistem atau tidak? Jika kami mengajukan hipotesis, periksa, itu tidak berfungsi, kami tidak mempelajari hal baru tentang operasi sistem, maka mungkin saatnya untuk menyegarkan diri. Dua pertanyaan saat ini pada titik ini: hipotesis mana yang telah Anda uji dan hipotesis mana yang Anda uji sekarang.
Algoritma ini sangat sesuai dengan aturan debug yang kita bicarakan di atas: ulangi kesalahan - ini adalah bug Anda, jelaskan masalahnya - pahami sistemnya, rumuskan hipotesis - bagilah dan taklukkan, uji hipotesis - periksa steker, pastikan stekernya diperbaiki, lima alasannya.
Saya punya contoh yang bagus untuk algoritma ini. Pengecualian jatuh pada salah satu layanan web kami.
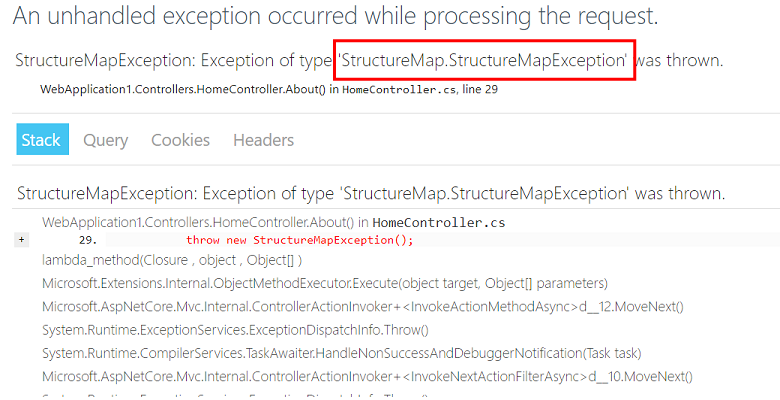
Pikiran pertama kita bukanlah masalah kita. Tapi menurut aturan, ini masih masalah kita.
Pertama, ulangi kesalahannya. Untuk setiap seribu permintaan, ada sekitar satu
StructureMapException , sehingga kami dapat mereproduksi masalahnya.
Kedua, kami mencoba menggambarkan masalahnya: jika pengguna membuat permintaan http untuk layanan kami saat ini ketika StructureMap mencoba membuat ketergantungan baru, maka pengecualian terjadi.
Ketiga, kami berhipotesis bahwa StructureMap adalah pembungkus dan ada sesuatu di dalamnya yang melempar pengecualian internal. Kami menguji hipotesis menggunakan procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
Ternyata di dalamnya ada
NullReferenceException .
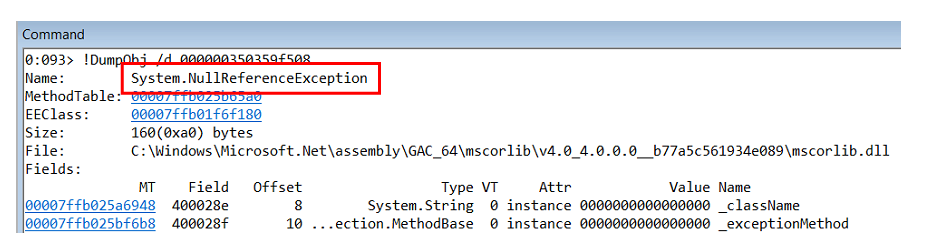
Mempelajari panggilan-tumpukan pengecualian ini, kami memahami bahwa itu terjadi di dalam objek-pembangun di StructureMap itu sendiri.
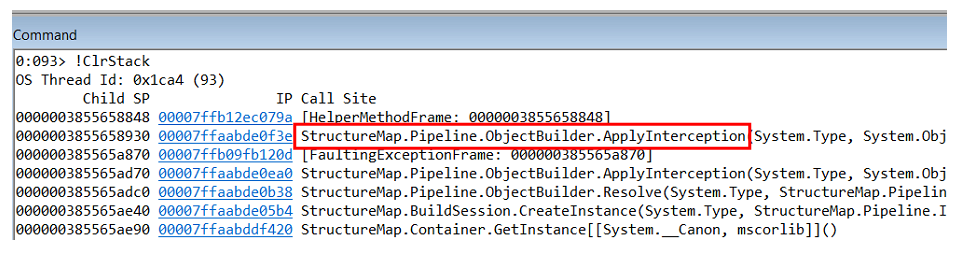
Tapi
NullReferenceException bukan masalah itu sendiri, tetapi konsekuensinya. Anda perlu memahami di mana itu terjadi dan siapa yang menghasilkannya.
Kami mengajukan hipotesis berikut: untuk beberapa alasan, kode kami mengembalikan dependensi nol. Mengingat bahwa di. Net semua objek di memori terletak satu per satu, jika kita melihat objek di tumpukan yang ada di depan
NullReferenceException , maka mereka mungkin akan menunjuk ke kode yang melemparkan pengecualian.
Di WinDbg ada perintah - Daftar Objek Dekat
!lno . Ini menunjukkan bahwa objek yang kita minati adalah fungsi lambda, yang digunakan dalam kode berikut.
public CompoundInterceptor FindInterceptor(Type type) { CompoundInterceptop interceptor; if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { lock (_locker) { if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type)); interceptor = new CompoundInterceptor(interceptorArray); _analyzedInterceptors.Add(type, interceptor); } } } return interceptor; }
Dalam kode ini, pertama-tama kita memeriksa apakah nilai dalam
Dictionary _analyzedInterceptors di
_analyzedInterceptors , jika kita tidak menemukannya, maka tambahkan nilai baru di dalam
lock .
Secara teori, kode ini tidak pernah dapat mengembalikan nol. Tetapi masalahnya di sini adalah
_analyzedInterceptors , yang menggunakan
Dictionary reguler di lingkungan multi-utas, bukan
ConcurrentDictionary .
Akar masalah ditemukan, kami memperbarui ke versi terbaru dari StructureMap, dikerahkan, memastikan bahwa semuanya sudah diperbaiki. Langkah terakhir dari algoritma kami adalah "belajar dan memberi tahu". Dalam kasus kami, pencarian dalam kode semua
Dictionary yang digunakan terkunci dan memeriksa bahwa semuanya digunakan dengan benar.
Jadi, algoritma debugging adalah algoritma intuitif yang secara signifikan menghemat waktu. Dia berfokus pada hipotesis - dan ini adalah hal terpenting dalam debugging.
Debugging Proaktif
Pada intinya, debugging proaktif menjawab pertanyaan "apa yang terjadi ketika bug muncul."
Pentingnya teknik debugging proaktif dapat dilihat pada diagram siklus hidup bug.
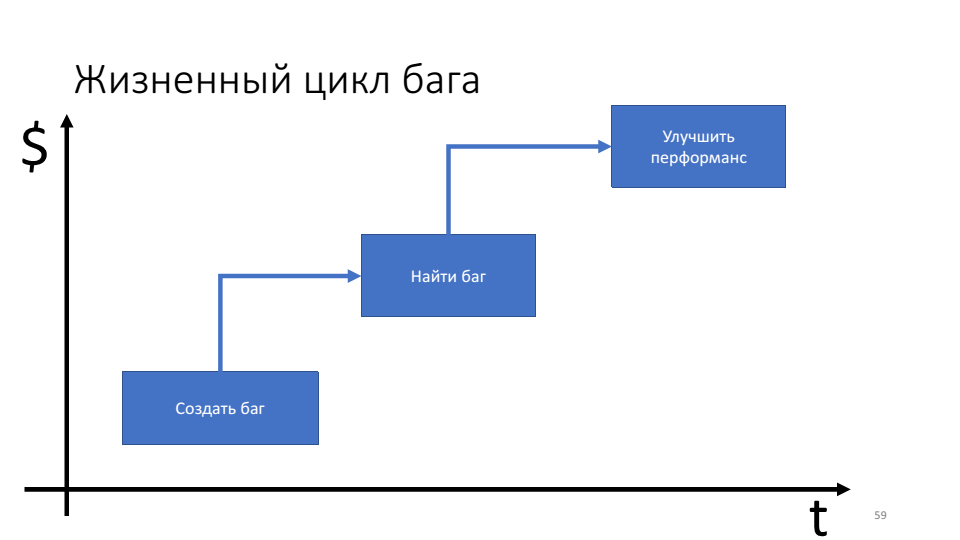
Masalahnya adalah semakin lama bug hidup, semakin banyak sumber daya (waktu) yang kita habiskan untuk itu.
Aturan debugging dan algoritma debugging memfokuskan kita pada saat bug ditemukan dan kita bisa mencari tahu apa yang harus dilakukan selanjutnya. Bahkan, kami ingin mengalihkan fokus kami pada saat bug itu dibuat. Saya percaya bahwa kita harus melakukan Minimum Debuggable Product (MDP), yaitu produk yang memiliki set infrastruktur minimum yang diperlukan untuk debugging yang efisien dalam produksi.
MDP terdiri dari dua hal: fungsi kebugaran dan metode USE.
Fitur kebugaran. Mereka dipopulerkan oleh Neil Ford dan rekan penulis dalam buku Building Evolutionary Architecture. Pada intinya, fungsi kebugaran, menurut penulis buku ini, terlihat seperti ini: ada arsitektur aplikasi yang dapat kita potong pada sudut yang berbeda, mendapatkan properti arsitektur seperti
rawatan ,
kinerja , dll., Dan untuk setiap bagian seperti itu kita harus menulis tes - kebugaran -fungsi. Dengan demikian, fungsi kebugaran adalah tes arsitektur.
Dalam kasus MDP, fungsi kebugaran adalah tes debuggability. Anda dapat menggunakan apa pun yang Anda suka untuk menulis tes seperti itu: NUnit, MSTest, dan sebagainya. Tapi, karena debugging sering bekerja dengan alat eksternal, saya akan menunjukkan menggunakan Pester (kerangka pengujian unit powershell) sebagai contoh. Kelebihannya di sini adalah bahwa ia bekerja dengan baik dengan baris perintah.
Misalnya, di dalam perusahaan kami setuju bahwa kami akan menggunakan perpustakaan tertentu untuk login; saat login kita akan menggunakan pola tertentu; karakter pdb harus selalu diberikan ke server simbol. Ini akan menjadi konvensi yang akan kami uji dalam pengujian kami.
Describe 'Debuggability' { It 'Contains line numbers in PDBs' { Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") ` | ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } ` | Where-Object { $_ -like "*Line nubmers: TRUE*" } ` | Should -Not –BeNullOrEmpty } }
Tes ini memverifikasi bahwa semua karakter pdb diberikan ke server simbol dan diberikan dengan benar, yaitu yang berisi nomor baris di dalamnya. Untuk melakukan ini, ambil versi kompilasi dari produksi, temukan semua file exe dan dll, lewati semua binari ini melalui utilitas syschk.exe, yang termasuk dalam paket alat Debugging untuk windows. Utilitas syschk.exe memeriksa biner dengan server simbol dan, jika menemukan file pdb di sana, mencetak laporan tentang hal itu. Dalam laporan tersebut, kami mencari baris "Nomor baris: BENAR". Dan pada akhirnya kami memeriksa bahwa hasilnya tidak "nol atau kosong".
Tes-tes ini harus diintegrasikan ke dalam pipa penyebaran berkelanjutan. Setelah tes integrasi dan tes unit lulus, fungsi kebugaran diluncurkan.
Saya akan menunjukkan satu contoh lagi dengan memeriksa pustaka yang diperlukan dalam kode.
Describe 'Debuggability' { It 'Contains package for logging' { Get-ChildItem -Path . -Recurse -Name "packages.config" ` | ForEach-Object { Get-Content "$_" } ` | Where-Object { $_ -like "*nlog*" } ` | Should -Not –BeNullOrEmpty } }
Dalam pengujian, kami mengambil semua file packages.config dan mencoba mencari pustaka nlog di dalamnya. Demikian pula, kami dapat memverifikasi bahwa bidang id korelasi digunakan di dalam bidang nlog.
Metode PENGGUNAAN. Hal terakhir yang terdiri dari MDP adalah metrik yang perlu Anda kumpulkan.
Saya akan menunjukkan dengan contoh metode USE, yang dipopulerkan oleh Brendan Gregg.
Idenya sederhana: jika ada masalah dalam kode, cukup untuk mengambil tiga metrik: pemanfaatan (saturasi), kesalahan (kesalahan), yang akan membantu untuk memahami di mana masalahnya.Beberapa perusahaan, misalnya Circonus (mereka melakukan pemantauan lunak), membangun dashboard mereka dalam bentuk metrik yang ditunjuk.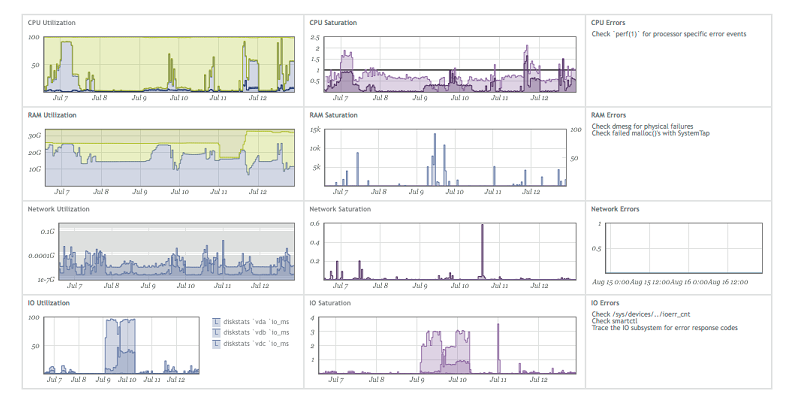 Jika Anda melihat secara rinci, misalnya, pada memori, kemudian gunakan adalah jumlah memori bebas, saturasi adalah jumlah akses disk, kesalahan adalah kesalahan yang telah muncul. Karena itu, untuk membuat produk nyaman untuk debugging, Anda perlu mengumpulkan metrik USE untuk semua fitur dan semua bagian dari subsistem.Jika Anda menggunakan fitur bisnis, maka, kemungkinan besar, Anda dapat membedakan tiga metrik di dalamnya:
Jika Anda melihat secara rinci, misalnya, pada memori, kemudian gunakan adalah jumlah memori bebas, saturasi adalah jumlah akses disk, kesalahan adalah kesalahan yang telah muncul. Karena itu, untuk membuat produk nyaman untuk debugging, Anda perlu mengumpulkan metrik USE untuk semua fitur dan semua bagian dari subsistem.Jika Anda menggunakan fitur bisnis, maka, kemungkinan besar, Anda dapat membedakan tiga metrik di dalamnya:- Penggunaan - waktu pemrosesan permintaan.
- Kejenuhan adalah panjang antrian.
- Kesalahan - segala situasi luar biasa.
Sebagai contoh, mari kita lihat grafik jumlah permintaan yang diproses yang dibuat oleh salah satu sistem kami. Seperti yang Anda lihat, layanan belum memproses permintaan selama tiga jam terakhir.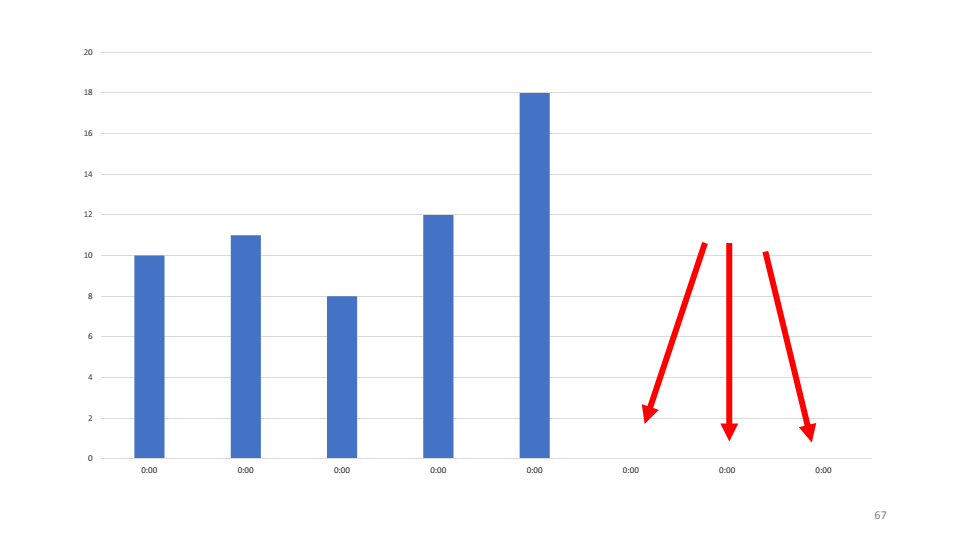 Hipotesis pertama yang kami buat adalah bahwa layanan telah jatuh dan kami harus memulainya kembali. Saat memeriksa, ternyata layanan tersebut berfungsi, ia menggunakan 4-5% dari CPU.
Hipotesis pertama yang kami buat adalah bahwa layanan telah jatuh dan kami harus memulainya kembali. Saat memeriksa, ternyata layanan tersebut berfungsi, ia menggunakan 4-5% dari CPU.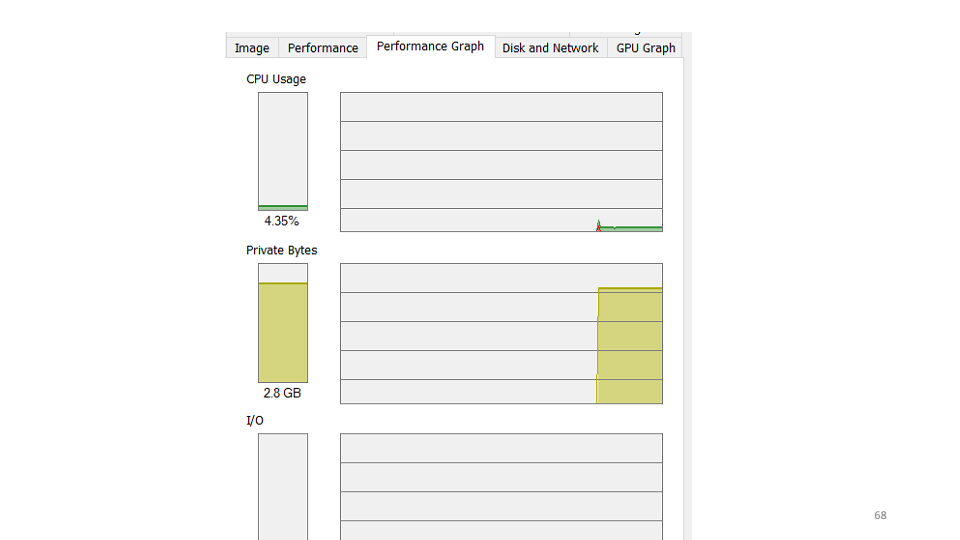 Hipotesis kedua adalah bahwa ada kesalahan dalam layanan yang tidak kita lihat. Kami akan menggunakan utilitas etrace.
Hipotesis kedua adalah bahwa ada kesalahan dalam layanan yang tidak kita lihat. Kami akan menggunakan utilitas etrace. etrace --kernel Process ^ --where ProcessName=Ex5-Service ^ --clr Exception
Utilitas ini memungkinkan Anda untuk berlangganan acara ETW secara realtime dan menampilkannya di layar.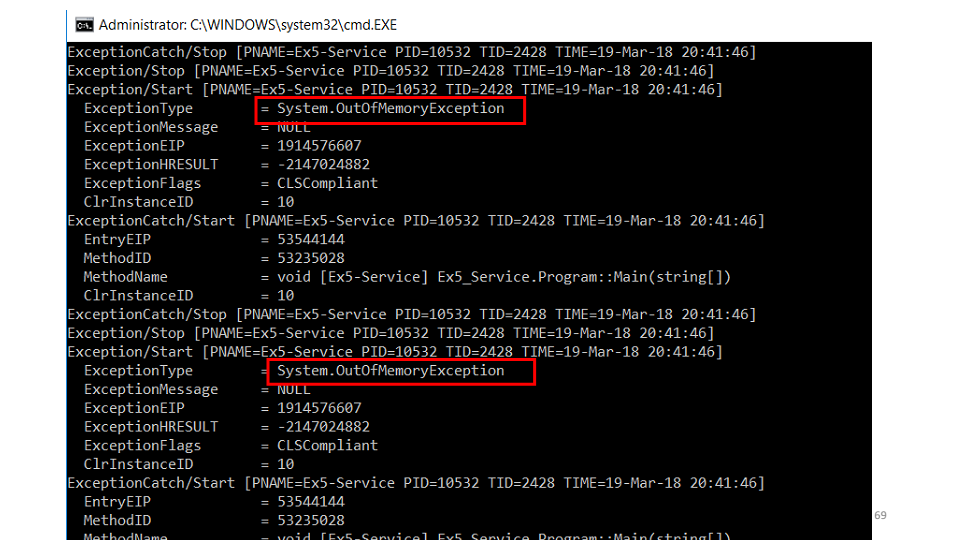 Kami melihat bahwa itu jatuh
Kami melihat bahwa itu jatuh OutOfMemoryException. Tapi, pertanyaan kedua, mengapa tidak ada di log? Jawabannya cepat - kami mencegatnya, mencoba membersihkan memori, menunggu sebentar dan mulai bekerja lagi. while (ShouldContinue()) { try { Do(); } catch (OutOfMemoryException) { Thread.Sleep(100); GC.CollectionCount(2); GC.WaitForPendingFinalizers(); } }
Hipotesis berikutnya adalah seseorang memakan seluruh ingatan. Menurut dump memori, sebagian besar objek berada di cache. public class Cache { private static ConcurrentDictionary<int, String> _items = new ... private static DateTime _nextClearTime = DateTime.UtcNow; public String GetFromCache(int key) { if (_nextClearTime < DateTime.UtcNow) { _nextClearTime = DateTime.UtcNow.AddHours(1); _items.Clear(); } return _items[key]; } }
Kode menunjukkan bahwa setiap jam cache harus dihapus. Tetapi ingatan itu tidak cukup, mereka bahkan tidak mencapai pembersihan. Mari kita lihat contoh metrik cache USE.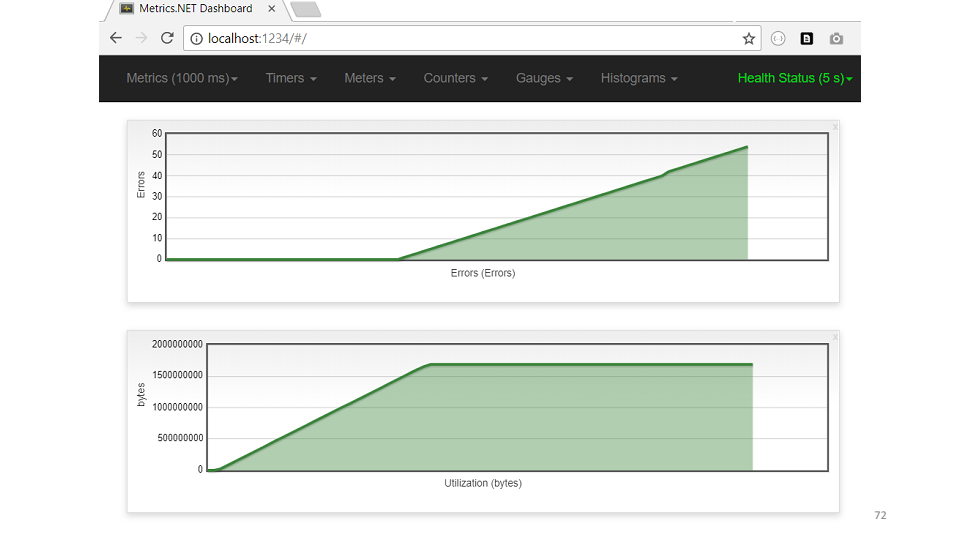 Menurut jadwal, segera terlihat - memori meningkat, kesalahan segera dimulai.Jadi, kesimpulan tentang apa itu debugging proaktif.
Menurut jadwal, segera terlihat - memori meningkat, kesalahan segera dimulai.Jadi, kesimpulan tentang apa itu debugging proaktif.- Debugging adalah persyaratan arsitektur. Sebenarnya, apa yang kami kembangkan adalah model sistem. Sistem itu sendiri adalah byte dan bit yang ada di memori pada server produksi. Debugging proaktif menyarankan Anda untuk memikirkan lingkungan operasional Anda.
- Kurangi jalur bug di sistem. Teknik debugging proaktif mencakup memeriksa semua metode publik dan argumennya; melemparkan Pengecualian segera setelah muncul, dan tidak men-debug sampai beberapa titik dan seterusnya.
- Minimum Produk Debuggable adalah alat yang baik untuk berkomunikasi satu sama lain dan mengembangkan persyaratan untuk debugging produk.
Jadi bagaimana cara memperbaiki bug secara efisien?
- Gunakan debugging proaktif.
- Ikuti algoritma.
- Uji hipotesis.
Kali ini sponsor iklan kami adalah Jon Skeet. Bahkan jika Anda tidak pergi ke Moskow untuk DotNext baru , videonya layak untuk dilihat (John berusaha keras).